Примечание.
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
В этой статье описывается объект синхронизации забора GPU, который можно использовать для истинной синхронизации GPU и GPU на аппаратном этапе планирования GPU 2. Эта функция поддерживается начиная с Windows 11 версии 24H2 (WDDM 3.2). Разработчики графических драйверов должны быть знакомы с WDDM 2.0 и аппаратным планированием GPU этапа 1.
Отслеживаемый объект синхронизации ограждения WDDM 2.x
Отслеживаемый объект синхронизации ограждения WDDM 2.x поддерживает следующие операции:
- ЦП ожидает отслеживаемого значения забора либо следующим образом:
- Опрос с помощью виртуального адреса ЦП (VA).
- Очередь ожидания блокировки внутри Dxgkrnl , которая получает сигнал, когда ЦП наблюдает новое отслеживаемое значение ограждения.
- Сигнал ЦП отслеживаемого значения.
- Сигнал GPU отслеживаемого значения путем записи в отслеживаемый забор GPU VA и повышение отслеживаемого забора сигнализирует прерывание, чтобы уведомить ЦП об обновлении значения.
То, что не поддерживается, было собственным в GPU ожиданием отслеживаемого значения забора. Вместо этого операционная система работала с GPU, которая зависит от ожидающего значения ЦП. Он выпустил эту работу только в GPU при сигнале значения.
Добавлен объект синхронизации собственного ограждения GPU
Начиная с версии WDDM 3.2, отслеживаемый объект ограждения был расширен для поддержки следующих добавленных функций:
- GPU ожидает отслеживаемого значения ограждения, что позволяет обеспечить высокую производительность синхронизации подсистемы и подсистемы без необходимости обхода ЦП.
- Уведомление об условном прерывании только для сигналов забора GPU с официантами ЦП. Эта функция обеспечивает значительную экономию энергии, позволяя ЦП входить в состояние низкой мощности, когда все работы GPU помещается в очередь.
- Забор хранилища значений в локальной памяти GPU (в отличие от системной памяти).
Разработка объекта синхронизации собственного ограждения GPU
На следующей схеме показана базовая архитектура собственного объекта ограждения GPU с акцентом на состояние объекта синхронизации, совместно используемое между ЦП и GPU.
: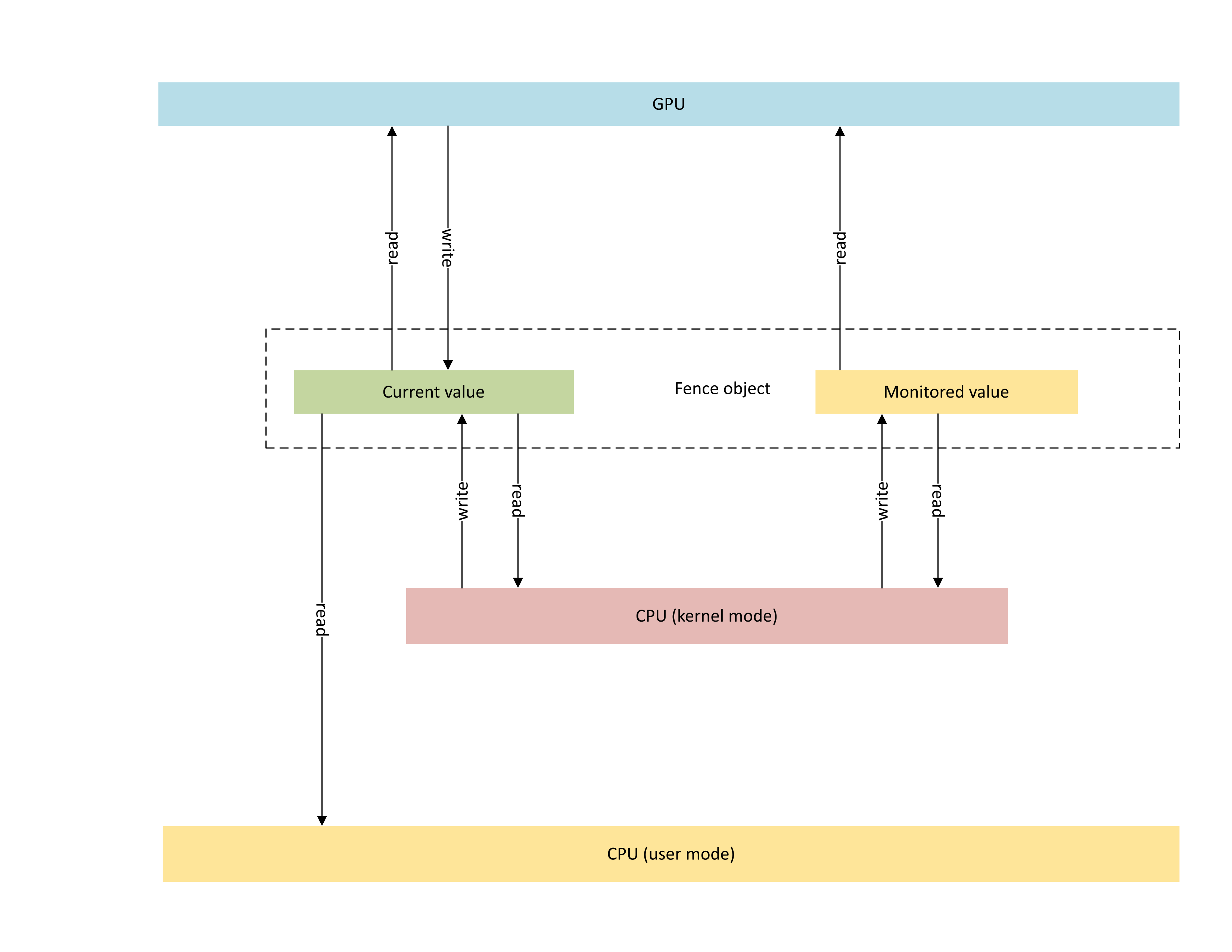
Схема включает два основных компонента:
Текущее значение (называемое CurrentValue в этой статье). Это расположение памяти содержит 64-разрядное значение ограждения. CurrentValue сопоставляется с ЦП (доступной для записи из режима ядра, доступной как для чтения из пользовательского, так и в режиме ядра) и GPU (доступно для чтения и записи с помощью виртуального адреса GPU). CurrentValue требует, чтобы 64-разрядные записи были атомарными как с ЦП, так и с точки зрения GPU. То есть обновления на 32-разрядные и высокие 32 бита не могут быть разорваны и должны быть видимы одновременно. Эта концепция уже присутствует в существующем отслеживаемом объекте ограждения.
Отслеживаемое значение (называемое MonitoredValue в этой статье). Это расположение памяти содержит наименьшее ожидание значения ЦП, вычитаемого по одному (1). MonitoredValue сопоставляется и доступен для ЦП (доступно для чтения и записи из режима ядра, без доступа к пользовательскому режиму) и GPU (доступно для чтения с помощью GPU VA, нет доступа на запись). ОС поддерживает список невыполненных официантов ЦП для заданного объекта ограждения, и он обновляет MonitoredValue , так как официанты добавляются и удаляются. Если выдающиеся официанты отсутствуют, то для этого значения задано значение UINT64_MAX. Эта концепция является новой для объекта синхронизации собственного ограждения GPU.
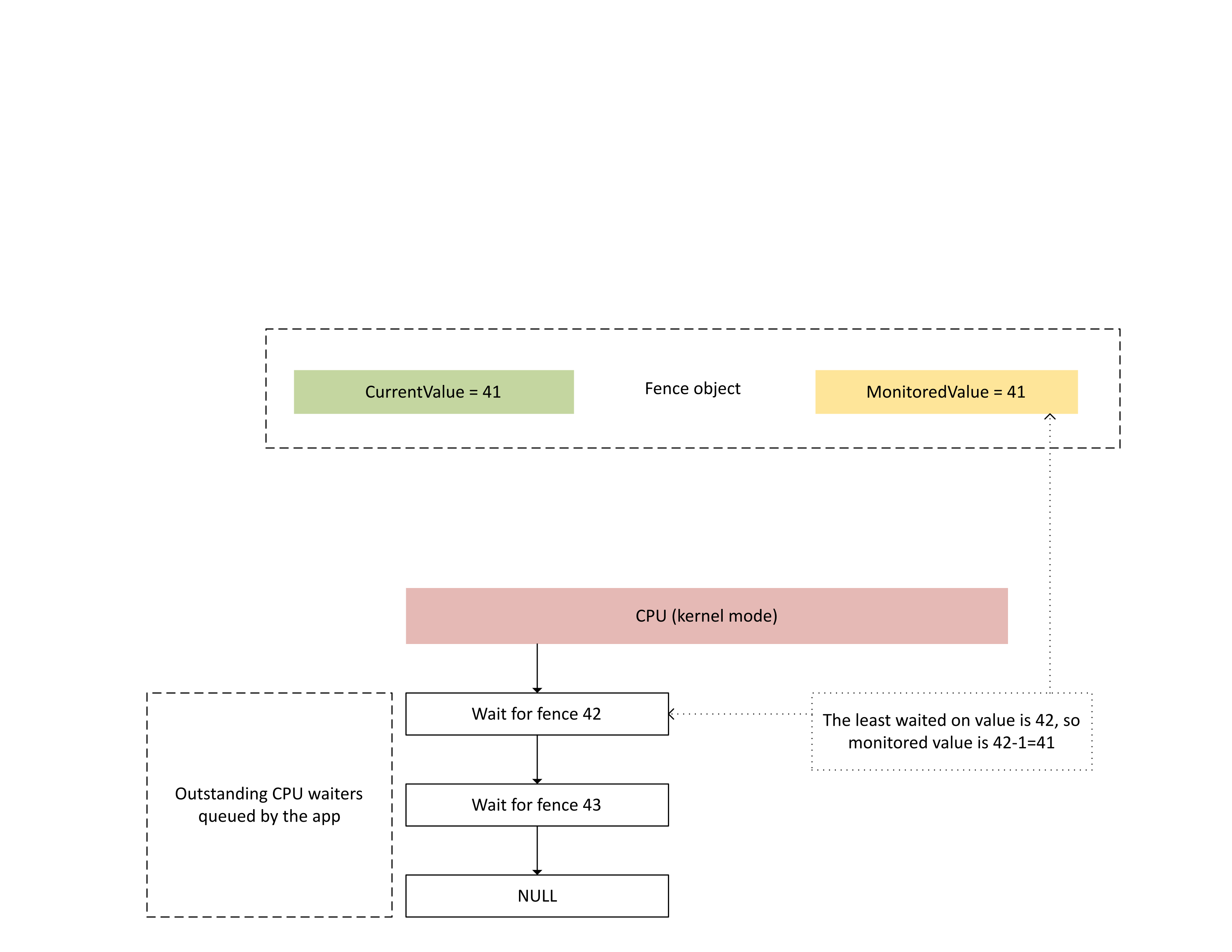
На следующей схеме показано, как Dxgkrnl отслеживает выдающиеся официанты ЦП в определенном отслеживаемом значении ограждения. В нем также показано заданное отслеживаемое значение ограждения в определенный момент времени. CurrentValue и MonitoredValue являются 41, что означает следующее:
- GPU выполнил все задачи до значения забора 41.
- ЦП не ожидает значения забора меньше или равно 41.
:
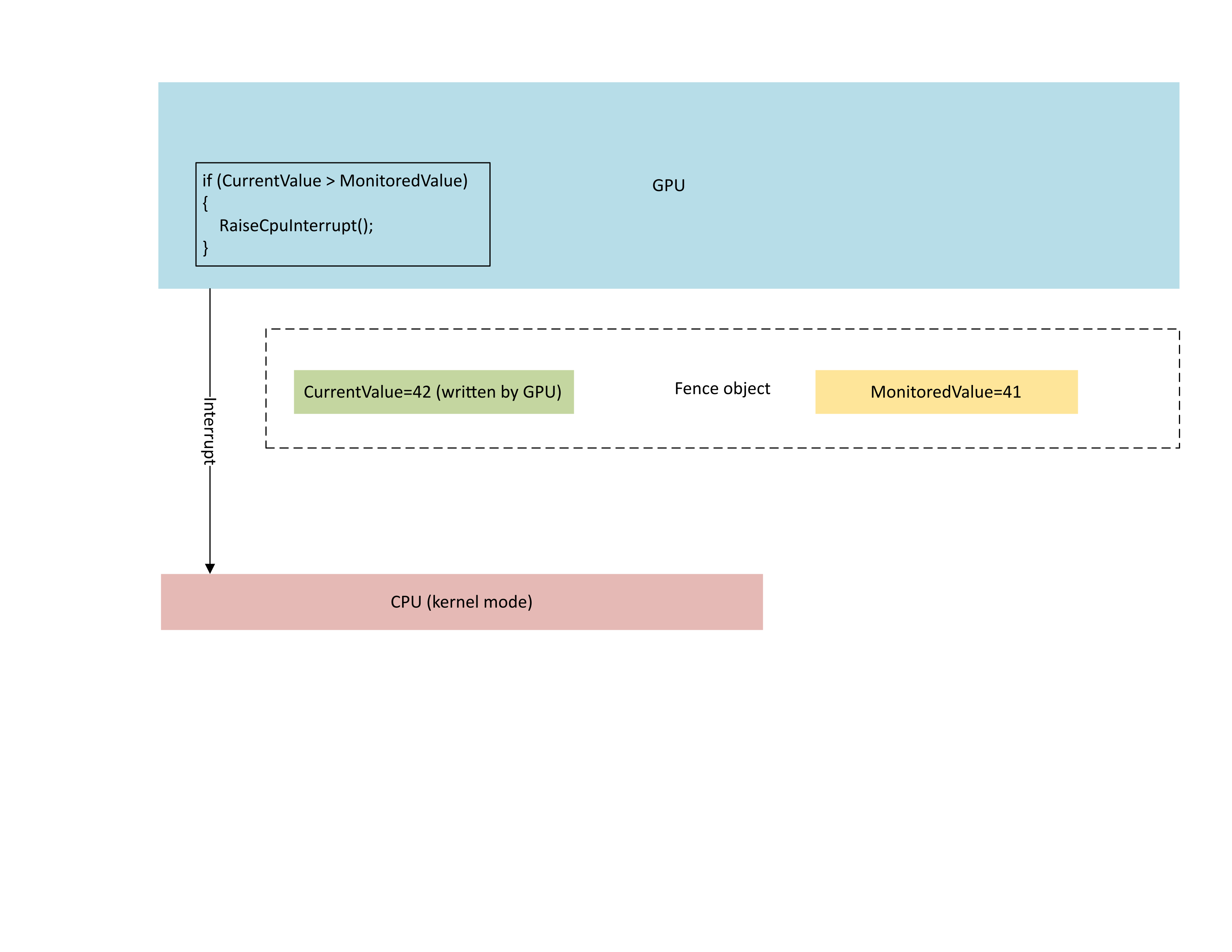
На следующей схеме показано, что обработчик управления контекстом GPU (CMP) условно вызывает прерывание ЦП, только если новое значение ограждения больше отслеживаемого значения. Такое прерывание означает, что выдающиеся официанты ЦП могут быть удовлетворены только что записанным значением.
:
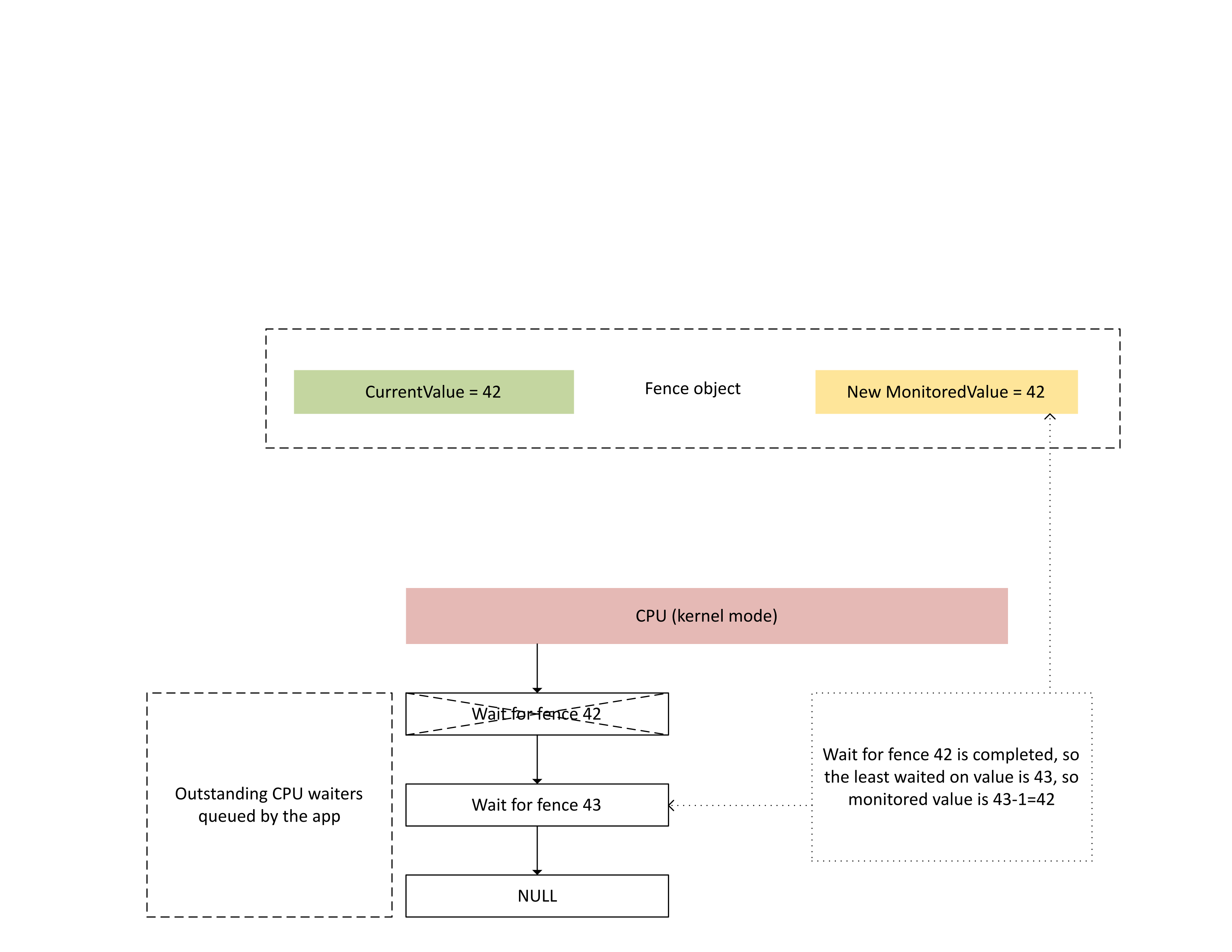
При обработке этого прерывания ЦП Dxgkrnl выполняет следующие действия, как показано на следующей схеме:
- Он разблокирует официантов ЦП, которые были удовлетворены недавно написанным забором.
- Он перемещает отслеживаемое значение в соответствии с наименьшим невыполненным значением, вычитанным на 1.
:
Хранилище физической памяти для текущих и отслеживаемых значений ограждения
Для заданного объекта забора CurrentValue и MonitoredValue хранятся в отдельных расположениях.
Объекты ограждения, которые не являются общими, имеют хранилище значений забора для разных объектов забора в одном процессе, упакованном на одной странице памяти. Значения упакованы в соответствии со значениями шага, указанными в заголовках KMD собственного забора, описанных далее в этой статье.
Объекты ограждения, доступные для совместного использования, имеют текущие и отслеживаемые значения, размещенные на страницах памяти, которые не используются другими объектами ограждения.
Текущее значение
Текущее значение может находиться в системной памяти или локальной памяти GPU в зависимости от типа ограждения, указанного D3DDDI_NATIVEFENCE_TYPE.
Текущее значение для перекрестных заборов адаптеров всегда находится в системной памяти.
Если текущее значение хранится в системной памяти, хранилище выделяется из внутреннего пула памяти системы.
Если текущее значение хранится в локальной памяти, хранилище выделяется из сегментов памяти, указанных в D3DKMDT_FENCESTORAGESURFACEDATA.
Отслеживаемое значение
Отслеживаемое значение также может находиться в локальной памяти системы или GPU в зависимости от D3DDDI_NATIVEFENCE_TYPE.
При хранении отслеживаемого значения в системной памяти ОС выделяет хранилище из внутреннего пула памяти системы.
При хранении отслеживаемого значения в локальной памяти ОС выделяет хранилище из сегментов памяти, указанных в D3DKMDT_FENCESTORAGESURFACEDATA.
При изменении условий ожидания ЦП ОС вызывает обратный вызов KMD DxgkDdiUpdateMonitoredValues, чтобы указать KMD обновить отслеживаемое значение до указанного значения.
Проблемы с синхронизацией
Ранее описанный механизм имеет внутреннее состояние расы между ЦП и GPU считывает и записывает текущее значение и отслеживаемое значение. Если особое внимание не выполняется, могут возникнуть следующие проблемы:
- GPU может считывать устаревший MonitoredValue и не вызывать прерывание, как ожидалось ЦП.
- Обработчик GPU может записать новое CurrentValue , пока CMP находится в середине принятия решения о состоянии прерывания. Это новое Значение CurrentValue может не вызывать прерывание, как ожидалось, или не отображается ЦП, так как оно извлекает текущее значение.
Синхронизация в GPU между подсистемой и CMP
Для повышения эффективности многие дискретные GPU реализуют отслеживаемую семантику сигнала забора с использованием теневых состояний, которые находятся в локальной памяти GPU между:
Модуль GPU, выполняющий поток буфера команд и условно вызывающий аппаратный сигнал к CMP.
Gpu CMP, который решает, следует ли вызывать прерывание ЦП.
В этом случае CMP должен синхронизировать доступ к памяти с подсистемой GPU, выполняющей запись памяти в значение забора. В частности, операция обновления теневого monitoredValue должна быть упорядочена с точки зрения CMP:
- Напишите новое monitoredValue (теневое хранилище GPU).
- Выполните барьер памяти для синхронизации доступа к памяти с обработчиком GPU.
- Чтение CurrentValue:
- Если CurrentValue>MonitoredValue, вызовет прерывание ЦП.
- Если CurrentValue<= MonitoredValue, не создайте прерывание ЦП.
Для правильного разрешения этого состояния гонки крайне важно, чтобы барьер памяти в шаге 2 правильно функционировал. Не должно быть ожидающей операции записи памяти в CurrentValue на шаге 3, которая возникла из команды, которая не видела обновление MonitoredValue на шаге 1. Эта ситуация приведет к прерыванию, если забор, написанный на шаге 3, был больше значения, обновленного на шаге 1.
Синхронизация между GPU и ЦП
ЦП должен выполнять обновления MonitoredValue и считывает CurrentValue таким образом, чтобы не потерять уведомление о прерывании для сигналов во время полета.
- Ос должна изменить MonitoredValue при добавлении нового официанта ЦП в систему или если существующий официант ЦП отключается.
- ОС вызывает DxgkDdiUpdateMonitoredValues , чтобы уведомить GPU о новом отслеживаемом значении.
- DxgkDdiUpdateMonitoredValue выполняется на уровне прерывания устройства и, таким образом, синхронизирован с отслеживаемой процедурой службы прерываний с сигнальным забором (ISR).
- DxgkDdiUpdateMonitoredValue должен гарантировать, что после возврата CurrentValue, считываемый любым ядром процессора, был записан GPU CMP после наблюдения за новым MonitoredValue.
- При возвращении из DxgkDdiUpdateMonitoredValue ОС перенаправляет CurrentValue и удовлетворяет всем официантам, которые разблокируются новым CurrentValue.
Это совершенно приемлемо для ЦП, чтобы наблюдать за новым CurrentValue , чем тот, который используется GPU, чтобы решить, следует ли вызывать прерывание. Эта ситуация иногда приводит к уведомлению о прерывании, которое не разблокирует никаких официантов. Что недопустимо для ЦП, чтобы не получать уведомление о прерывании для последнего > MonitoredValue).)
Отправка запросов к включению функций собственного ограждения в ОС
Драйверы должны запрашивать, включена ли встроенная функция ограждения в ОС во время инициализации драйвера. Начиная с WDDM 3.2 ос использует добавленный интерфейс IsFeatureEnabled для управления включением определенных функций, включая функцию собственного ограждения.
В результате KMD должен реализовать интерфейс IsFeatureEnabled . Реализация KMD должна запрашивать, включена ли ос функция DXGK_FEATURE_NATIVE_FENCE перед рекламой поддержки собственного ограждения в DXGK_VIDSCHCAPS. Ос завершается сбоем инициализации адаптера, если KMD объявляет поддержку собственного ограждения, если ос не включила эту функцию.
Дополнительные сведения об интерфейсе включения функций см. в разделе "Поддержка функций WDDM", а также сведения о поддержке функций WDDM.
DDIs для запроса включения функции собственного ограждения
Для KMD вводятся следующие интерфейсы, чтобы запрашивать, включена ли ОС встроенная функция ограждения:
- DXGKCB_FEATURE_NATIVEFENCE_CAPS_1
- DXGKARGCB_FEATURE_NATIVEFENCE_CAPS_1
- DXGKCBINT_FEATURE_NATIVEFENCE_1
ОС реализует добавленную таблицу интерфейса DXGKCB_FEATURE_NATIVEFENCE_CAPS_1, выделенную для версии 1 DXGK_FEATURE_NATIVE_FENCE. KMD должен запрашивать эту таблицу интерфейса функций, чтобы определить возможности ОС. В будущих выпусках ОС операционная система может представить будущие версии этой таблицы интерфейса, подробные сведения о поддержке новых возможностей.
Пример кода драйвера для запроса поддержки
В следующем примере кода показано, как драйверы должны использовать функцию DXGK_FEATURE_NATIVE_FENCE в интерфейсе DXGK_FEATURE_INTERFACE для запроса поддержки.
DXGK_FEATURE_INTERFACE FeatureInterface;
struct FEATURE_RESULT
{
bool Enabled;
DXGK_FEATURE_VERSION Version;
};
// Driver internal cache for state & version of queried features
struct FEATURE_STATE
{
struct
{
UINT NativeFenceEnabled : 1;
};
DXGK_FEATURE_VERSION NativeFenceVersion = 0;
// Interfaces
DXGKCBINT_FEATURE_NATIVEFENCE_1 NativeFenceInterface = {};
// Interface queried values
DXGKARGCB_FEATURE_NATIVEFENCE_CAPS_1 NativeFenceOSCaps1 = {};
};
// Helper function to query OS's feature enabled interface
FEATURE_RESULT IsFeatureEnabled(
DXGK_FEATURE_ID FeatureId
)
{
FEATURE_RESULT Result = {};
//
// If the feature interface functionality is available (e.g. supported by the OS)
//
DXGKARGCB_ISFEATUREENABLED2 Args = {};
Args.FeatureId = FeatureId;
if(NT_SUCCESS(FeatureInterface.IsFeatureEnabled(DxgkInterface.DeviceHandle, &Args)))
{
Result.Enabled = Args.Result.Enabled;
Result.Version = Args.Result.Version;
}
return Result;
}
// Actual code to query whether OS has enabled Native Fence support and corresponding OS caps
FEATURE_RESULT FeatureResult = IsFeatureEnabled(DXGK_FEATURE_NATIVE_FENCE);
FEATURE_STATE FeatureState = {};
FeatureState.NativeFenceEnabled = !!FeatureResult.Enabled;
if (FeatureResult.Enabled)
{
// Query OS caps for native fence feature, using the feature interface
DXGKARGCB_QUERYFEATUREINTERFACE QFIArgs = {};
QFIArgs.FeatureId = DXGK_FEATURE_NATIVE_FENCE;
QFIArgs.Interface = &FeatureState.NativeFenceInterface;
QFIArgs.InterfaceSize = sizeof(FeatureState.NativeFenceInterface);
QFIArgs.Version = FeatureResult.Version;
Status = FeatureInterface.QueryFeatureInterface(DxgkInterface.DeviceHandle, &QFIArgs);
if(NT_SUCCESS(Status))
{
FeatureState.NativeFenceVersion = FeatureResult.Version;
Status = FeatureState.NativeFenceInterface.GetOSCaps(&FeatureState.NativeFenceOSCaps1);
NT_ASSERT(NT_SUCCESS(Status));
}
else
{
// We should always succeed getting an interface from a successfully
// negotiated feature + version.
NT_ASSERT(FALSE);
}
}
Возможности собственного ограждения
Следующие интерфейсы обновляются или представлены для запроса собственных заборных заборов:
Поле NativeGpuFence добавляется в DXGK_VIDSCHCAPS. Если ОС включила функцию DXGK_FEATURE_NATIVE_FENCE, драйвер может объявить поддержку собственных функций ограждения GPU во время инициализации адаптера, установив для DXGK_VIDSCHCAPS::NativeGpuFence значение 1.
DXGKQAITYPE_NATIVE_FENCE_CAPS добавляется в DXGK_QUERYADAPTERINFOTYPE.
Dxgkrnl предоставляет эту функцию в пользовательском режиме с помощью добавленной D3DKMT_WDDM_3_1_CAPS ::NativeGpuFenceSupported structure/bit.
KMTQAITYPE_WDDM_3_1_CAPS добавляется в KMTQUERYADAPTERINFOTYPE.
Следующие сущности добавляются для KMD, чтобы указать свои возможности поддержки для функции забора собственного GPU.
Структура DXGK_NATIVE_FENCE_CAPS описывает собственные возможности ограждения GPU. Когда KMD задает бит MapToGpuSystemProcess этой структуры, она указывает ОС резервировать системное пространство виртуального адресного пространства GPU GPU для использования CMP и создавать сопоставления gpu VA в этом адресном пространстве для собственного ограждения CurrentValue и MonitoredValue. Эти виртуальные машины GPU позже передаются обратному вызову создания забора KMD как DXGKARG_CREATENATIVEFENCE::CurrentValueSystemProcessGpuVa и MonitoredValueSystemProcessGpuVa.
KMD возвращает заполненную DXGK_NATIVE_FENCE_CAPS структуру, когда ее функция DxgkDdiQueryAdapterInfo вызывается с добавленным типом сведений о адаптере запросов DXGKQAITYPE_NATIVE_FENCE_CAPS.
DDD-идентификаторы KMD для создания, открытия, закрытия и уничтожения собственного объекта ограждения
Следующие DD-интерфейсы, реализованные KMD, представлены для создания, открытия, закрытия и уничтожения собственного объекта ограждения. Dxgkrnl вызывает эти DDIs от имени компонентов пользовательского режима. Dxgkrnl вызывает их только в том случае, если ОС включила функцию DXGK_FEATURE_NATIVE_FENCE .
- DxgkDdiCreateNativeFence/DXGKARG_CREATENATIVEFENCE
- DxgkDdiOpenNativeFence/DXGKARG_OPENNATIVEFENCE
- DxgkDdiCloseNativeFence/DXGKARG_CLOSENATIVEFENCE
- DxgkDdiDeskNativeFence/DXGKARG_DESTROYNATIVEFENCE
Следующие DDIs были обновлены для поддержки объектов собственного ограждения:
В DRIVER_INITIALIZATION_DATA добавлены следующие члены. Драйверы, поддерживающие собственные объекты ограждения GPU, должны реализовать функции и предоставить Dxgkrnl указателями на них через эту структуру.
- PDXGKDDI_CREATENATIVEFENCE DxgkDdiCreateNativeFence (добавлено в WDDM 3.1)
- PDXGKDDI_DESTROYNATIVEFENCE DxgkDdiDewdNativeFence (добавлено в WDDM 3.1)
- PDXGKDDI_OPENNATIVEFENCE DxgkDdiCreateNativeFence (добавлено в WDDM 3.2)
- PDXGKDDI_CLOSENATIVEFENCE DxgkDdiCloseNativeFence (добавлено в WDDM 3.2)
- PDXGKDDI_SETNATIVEFENCELOGBUFFER DxgkDdiSetNativeFenceLogBuffer (добавлено в WDDM 3.2)
- PDXGKDDI_UPDATENATIVEFENCELOGS DxgkDdiUpdateNativeFenceLogs (добавлено в WDDM 3.2)
Глобальные и локальные дескрипторы для общих заборов
Представьте, что процесс A создает общий собственный забор и процесс B позже открывает этот забор.
При процессе A создает общий собственный забор, Dxgkrnl вызывает DxgkDdiCreateNativeFence с дескриптором драйвера адаптера, на котором создается этот забор. Дескриптор забора, созданный и возвращенный в hGlobalNativeFence, является глобальным дескриптором забора.
Dxgkrnl впоследствии следует вызову DxgkDdiOpenNativeFence, чтобы открыть конкретный локальный дескриптор A (hLocalNativeFenceA).
Когда процесс B открывает тот же общий собственный забор, Dxgkrnl вызывает DxgkDdiOpenNativeFence, чтобы открыть локальный дескриптор B для конкретного процесса (hLocalNativeFenceB).
Если процесс A уничтожает свой общий собственный экземпляр забора, Dxgkrnl видит, что есть еще ожидающая ссылка на этот глобальный забор, поэтому только вызывает dxgkDdiCloseNativeFence(hLocalNativeFenceA) для драйвера для очистки структур, относящихся к конкретному процессу. Дескриптор hGlobalNativeFence по-прежнему существует.
Когда процесс B уничтожает свой экземпляр забора, Dxgkrnl вызывает DxgkDdiCloseNativeFence(hLocalNativeFenceB), а затем DxgkDdiDe geometryNativeFence(hGlobalNativeFence), чтобы разрешить KMD уничтожить свои глобальные данные ограждения.
Сопоставления va gpu в адресном пространстве процесса разбиения по страницам для использования CMP
KMD задает ограничение DXGK_NATIVE_FENCE_CAPS::MapToGpuSystemProcess на оборудовании, требующее сопоставления виртуальных машин GPU собственного ограждения в адресном пространстве процесса gpu. Набор bit MapToGpuSystemProcess указывает ОС создать сопоставления VA GPU в адресном пространстве процесса разбиения на разбиение в адресное пространство собственного ограждения CurrentValue и MonitoredValue для использования CMP. Эти виртуальные машины GPU позже передаются в DxgkDdiCreateNativeFence как DXGKARG_CREATENATIVEFENCE::CurrentValueSystemProcessGpuVa и MonitoredValueSystemProcessGpuVa.
API ядра D3DKMT для создания, открытия и уничтожения собственных заборов
Следующие API-интерфейсы режима ядра D3DKMT представлены для создания и открытия собственного объекта ограждения.
- D3DKMTCreateNativeFence / D3DKMT_CREATENATIVEFENCE
- D3DKMTOpenNativeFenceFromNTHandle / D3DKMT_OPENNATIVEFENCEFROMNTHANDLE
Dxgkrnl вызывает существующую функцию D3DKMTDesynchronizationObject, чтобы закрыть и уничтожить (бесплатно) существующий собственный объект ограждения.
Поддерживаются структуры и перечисления, которые вводятся или обновляются:
- D3DDDI_NATIVEFENCEINFO
- D3DDDI_NATIVEFENCE_TYPE
- D3DDDI_SYNCHRONIZATIONOBJECT_FLAGS
- D3DDDI_NATIVEFENCE_MAPPING
DDI для поддержки размещения собственных значений ограждения в локальной памяти
Следующие DDIs были добавлены или изменены для поддержки размещения собственных значений ограждения в локальной памяти:
Собственный забор MonitoredValue и CurrentValue собственного типа ограждения D3DDDI_NATIVEFENCE_TYPE_INTRA_GPU можно поместить в память локального устройства. Для этого ОС попросит водителя указать сегменты памяти, в которых должно размещаться хранилище забора. DxgkDdiGetStandardAllocation расширен для предоставления такой информации.
D3DKMDT_STANDARDALLOCATION_FENCESTORAGE добавляется в DXGKARG_GETSTANDARDALLOCATIONDRIVERDATA.
Указание собственного ограждения хода выполнения для очередей оборудования
В следующем обновлении показано, как указать объект забора в собственной очереди оборудования:
Флаг NativeProgressFence добавляется для вызовов dxgkDdiCreateHwQueue.
- В поддерживаемых системах ОС обновляет забор хода выполнения оборудования до собственного забора. Если ОС задает NativeProgressFence, он указывает на KMD, что дескриптор DXGKARG_CREATEHWQUEUE::hHwQueueProgressFence указывает на дескриптор драйвера собственного объекта ограждения GPU, созданного ранее с помощью DxgkDdiCreateNativeFence.
Собственный забор сигнализирует о прерывании
Следующие изменения вносятся в механизм прерывания для поддержки сигнального прерывания собственного ограждения:
Перечисление DXGK_INTERRUPT_TYPE обновляется, чтобы иметь тип прерывания DXGK_INTERRUPT_NATIVE_FENCE_SIGNALED .
Структура DXGKARGCB_NOTIFY_INTERRUPT_DATA обновляется, чтобы включить структуру NativeFenceSignaled для обозначения собственного ограждения сигнального прерывания
NativeFenceSignaled используется для информирования ОС о том, что набор объектов GPU собственного ограждения, отслеживаемых ЦП, был сигнален на обработчике GPU. Если GPU может определить точное подмножество объектов с активными обработчиками ЦП, оно передает это подмножество через pSignaledNativeFenceArray. Дескриптор в этом массиве должен быть допустимым дескриптором hGlobalNativeFence, передаваемым в KMD в DxgkDdiCreateNativeFence. Передача дескриптора в разрушенный объект собственного ограждения вызывает проверку ошибок.
Структура DXGKCB_NOTIFY_INTERRUPT_DATA_FLAGS обновляется, чтобы включить член EvaluateLegacyMonitoredFences .
GPU может передавать значение NULL pSignaledNativeFenceArray в следующих условиях:
- Gpu не может определить точное подмножество объектов с активными официантами ЦП.
- Несколько прерываний сигнала свернуты вместе, что затрудняет определение сигнального набора с активными официантами.
Значение NULL указывает ОС сканировать все выдающиеся собственные средства ожидания объектов ограждения GPU.
Контракт между ОС и драйвером: если у ОС есть активный официант ЦП (как выражено MonitoredValue), а обработчик GPU сигнализирует объекту значение, требующее прерывания ЦП, GPU должен выполнить одно из следующих действий:
- Включите этот собственный дескриптор ограждения в pSignaledNativeFenceArray.
- Вызов прерывания NativeFenceSignaled с помощью pSignaledNativeFenceArray.
По умолчанию, когда KMD вызывает это прерывание с помощью null pSignaledNativeFenceArray, Dxgkrnl проверяет только все ожидающие собственные официанты заборов и не сканирует устаревшие отслеживаемые официанты забора. На оборудовании, которое не может различать устаревшие DXGK_INTERRUPT_MONITORED_FENCE_SIGNALED и DXGK_INTERRUPT_NATIVE_FENCE_SIGNALED, KMD всегда может вызывать только введенные DXGK_INTERRUPT_NATIVE_FENCE_SIGNALED прерывания с помощью pSignaledNativeFenceArray = NULL и EvaluateLegacyMonitoredFences = 1, что указывает операционной системе для сканирования всех официантов (устаревшие отслеживаемые официанты забора и собственные официанты заборов).
Указание KMD обновлять пакеты значений
Ниже приведены инструкции KMD об обновлении пакета текущих или отслеживаемых значений:
DxgkDdiUpdateCurrentValuesFromCpu / DXGKARG_UPDATECURRENTVALUESFROMCPU
DxgkDdiUpdateMonitoredValues / DXGKARG_UPDATEMONITOREDVALUES
Кроссплатформенный собственный забор
ОС должна поддерживать создание собственных заборов между адаптерами, так как существующие приложения DX12 создают и используют отслеживаемые заборы между адаптерами. Если базовые очереди и планирование для этих приложений переключаются на отправку в режиме пользователя, их отслеживаемые заборы также должны быть переключятся на собственные заборы (очереди пользовательского режима не могут поддерживать отслеживаемые заборы).
Межадаптерное ограждение должно быть создано с типом D3DDDI_NATIVEFENCE_TYPE_DEFAULT. В противном случае ошибка D3DKMTCreateNativeFence.
Все графические процессоры используют одну и ту же копию хранилища CurrentValue , которая всегда выделяется в системной памяти. Когда среда выполнения создает собственный забор между адаптерами на GPU1 и открывает его на GPU2, сопоставления va GPU на обоих GPU указывают на одно физическое хранилище CurrentValue .
Каждый GPU получает собственную копию MonitoredValue. Поэтому хранилище MonitoredValue может быть выделено в системной памяти или локальной памяти.
Межадаптерные собственные ограждения должны разрешать условие, в котором GPU1 ожидает собственного забора, что GPU2 сигнализирует. Сегодня нет концепции сигналов GPU к GPU; следовательно, ОПЕРАЦИОННая система явно разрешает это условие, сигналив GPU1 от ЦП. Этот сигнал выполняется путем установки MonitoredValue для межадаптерного забора значение 0 в течение всего времени существования. Затем, когда GPU2 сигнализирует о собственном заборе, он также вызывает прерывание ЦП, позволяя Dxgkrnl обновить CurrentValue на GPU1 (с помощью DxgkDdiUpdateCurrentValuesFromCpu с флагом NotificationOnly set TRUE) и разблокировать ожидающие обработчики ЦП/GPU этого GPU.
Хотя MonitoredValue всегда имеет значение 0 для собственных заборов между адаптерами, ожидание и сигналы, отправленные на том же GPU, по-прежнему пользуются более быстрыми преимуществами синхронизации GPU. Тем не менее, преимущество питания сокращения прерываний ЦП теряется, так как прерывания ЦП будут вызваны безоговорочно, даже если на другом GPU не было никаких официантов ЦП или официантов. Этот компромисс делается для поддержания стоимости проектирования и реализации кроссплатформенного собственного ограждения.
ОС поддерживает сценарий, в котором собственный объект забора создается на GPU1 и открыт на GPU2, где GPU1 поддерживает функцию и GPU2 не поддерживает. Объект забора открыт как обычный MonitoredFence на GPU2.
ОС поддерживает сценарий, в котором обычный отслеживаемый объект забора создается на GPU1 и открыт в качестве собственного забора на GPU2, который поддерживает эту функцию. Объект забора открыт как собственный забор на GPU2.
Сочетания ожидания и сигнала между адаптерами
В таблицах в следующих подразделах приведен пример системы iGPU и dGPU, а также перечислены различные конфигурации, которые могут быть доступны для собственного ожидания или сигнала от ЦП/GPU. Рассматриваются следующие два случая:
- Оба GPU поддерживают собственные ограждения.
- IGPU не поддерживает собственные ограждения, но dGPU поддерживает собственные заборы.
Второй сценарий также похож на тот случай, когда оба GPU поддерживают собственные ограждения, но собственный забор ожидания или сигнал отправляется в очередь режима ядра в iGPU.
Таблицы следует считывать, выбрав пару ожиданий и сигналов из столбцов, например WaitFromGPU - SignalFromGPU или WaitFromGPU - SignalFromCPU, et cetera.
Сценарий 1
В сценарии 1 dGPU и iGPU поддерживают собственные ограждения.
| iGPU WaitFromGPU (hFence, 10) | iGPU WaitFromCPU (hFence, 10) | dGPU SignalFromGpu (hFence, 10) | dGPU SignalFromCpu(hFence, 10) |
|---|---|---|---|
| UMD вставляет инструкцию hfence CurrentValue == 10 в буфер команд | Среда выполнения вызывает D3DKMTWaitForSynchronizationObjectFromCpu | ||
| VidSch отслеживает этот объект синхронизации в собственном списке официанта ЦП ЦП | |||
| UMD вставляет инструкцию сигнала записи hFence CurrentValue = 10 сигналов в буфер команд | Среда выполнения вызывает D3DKMTSignalSynchronizationObjectFromCpu | ||
| VidSch получает собственный забор сигналов ISR при записи CurrentValue (так как MonitoredValue == 0 всегда) | VidSch вызывает DxgkDdiUpdateCurrentValuesFromCpu(hFence, 10) | ||
| VidSch распространяет сигнал (hFence, 10) на iGPU | VidSch распространяет сигнал (hFence, 10) на iGPU | ||
| VidSch получает распространяемый сигнал и вызывает DxgkDdiUpdateCurrentValuesFromCpu(hFence, NotificationOnly=TRUE) | VidSch получает распространяемый сигнал и вызывает DxgkDdiUpdateCurrentValuesFromCpu(hFence, NotificationOnly=TRUE) | ||
| KMD повторно сканирует список выполнения для разблокировки канала HW, ожидающего hFence | VidSch разблокирует условие ожидания ЦП, сигналив KEVENT |
Сценарий 2a
В сценарии 2a iGPU не поддерживает собственные ограждения, но dGPU делает. Ожидание отправляется на iGPU и сигнал передается на dGPU.
| iGPU WaitFromGPU (hFence, 10) | iGPU WaitFromCPU (hFence, 10) | dGPU SignalFromGpu (hFence, 10) | dGPU SignalFromCpu(hFence, 10) |
|---|---|---|---|
| Среда выполнения вызывает D3DKMTWaitForSynchronizationObjectFromGpu | Среда выполнения вызывает D3DKMTWaitForSynchronizationObjectFromCpu | ||
| VidSch отслеживает этот объект синхронизации в отслеживаемом списке ожидания забора | VidSch отслеживает этот объект синхронизации в отслеживаемом заборе головы списка официантов ЦП | ||
| UMD вставляет инструкцию сигнала записи hFence CurrentValue = 10 сигналов в буфере команд | Среда выполнения вызывает D3DKMTSignalSynchronizationObjectFromCpu | ||
| VidSch получает NativeFenceSignaledISR при записи CurrentValue (так как MV == 0 всегда) | VidSch вызывает DxgkDdiUpdateCurrentValuesFromCpu(hFence, 10) | ||
| VidSch распространяет сигнал (hFence, 10) на iGPU | VidSch распространяет сигнал (hFence, 10) на iGPU | ||
| VidSch получает распространяемый сигнал и наблюдает новое значение ограждения | VidSch получает распространяемый сигнал и наблюдает новое значение ограждения | ||
| VidSch сканирует отслеживаемый список ожидания забора и разблокирует контексты программного обеспечения | VidSch сканирует отслеживаемую заборную головку списка официантов ЦП и разблокирует ожидание ЦП, сигналив KEVENT |
Сценарий 2b
В сценарии 2b поддержка собственного ограждения остается той же (iGPU не поддерживает dGPU). На этот раз сигнал отправляется на iGPU, а ожидание отправляется на dGPU.
| iGPU SignalFromGPU (hFence, 10) | iGPU SignalFromCPU (hFence, 10) | dGPU WaitFromGpu (hFence, 10) | dGPU WaitFromCpu(hFence, 10) |
|---|---|---|---|
| UMD вставляет инструкцию hfence CurrentValue == 10 в буфере команд | Среда выполнения вызывает D3DKMTWaitForSynchronizationObjectFromCpu | ||
| VidSch отслеживает этот объект синхронизации в собственном списке официанта ЦП ЦП | |||
| UMD вызывает D3DKMTSignalSynchronizationObjectFromGpu | UMD вызывает D3DKMTSignalSynchronizationObjectFromCpu | ||
| Если пакет находится в центре контекста программного обеспечения, VidSch обновляет значение забора непосредственно из ЦП | VidSch обновляет значение ограждения непосредственно из ЦП | ||
| VidSch распространяет сигнал (hFence, 10) на dGPU | VidSch распространяет сигнал (hFence, 10) на dGPU | ||
| VidSch получает распространяемый сигнал и вызывает DxgkDdiUpdateCurrentValuesFromCpu(hFence, NotificationOnly=TRUE) | VidSch получает распространяемый сигнал и вызывает DxgkDdiUpdateCurrentValuesFromCpu(hFence, NotificationOnly=TRUE) | ||
| KMD повторно сканирует список выполнения для разблокировки канала HW, ожидающего hFence | VidSch разблокирует условие ожидания ЦП, сигналив KEVENT |
Будущий сигнал между АДАПТЕРами GPU и GPU
Как описано в разделе о проблемах синхронизации, для межадаптерных собственных заборов мы теряем экономию энергии, так как прерывание ЦП вызывается безусловно.
В будущем выпуске ОС будет разрабатывать инфраструктуру, чтобы разрешить сигнал GPU на одном GPU прерывать другие GPU, записывая в общую память шлюза, позволяя другим GPU проснуться, обработать список выполнения и разблокировать готовые очереди HW.
Задача этой работы заключается в разработке:
- Общая память двери.
- Интеллектуальная полезные данные или дескриптор, которые GPU может записывать в дверь, что позволяет другим GPU определить, какой забор был сигналирован, чтобы он смог сканировать только подмножество HWQueues.
С таким сигналом между адаптерами может быть даже возможно, чтобы графические процессоры могли совместно использовать одну и ту же копию собственного хранилища забора (линейное распределение между адаптерами, аналогичное выделению между адаптерами), из которой все графические процессоры считывают и записывают в него.
Конструктор буфера журнала в собственном заборе
При использовании собственных заборов и отправки в пользовательском режиме Dxgkrnl не имеет видимости, когда собственный GPU ожидает и сигналов, вложенных из UMD, разблокируются на GPU для определенного HWQueue. С собственными заборами, отслеживаемый забор сигнализирует прерывание может быть подавлен для заданного забора.
:
Необходим способ повторного создания операций ограждения, как показано на этом изображении GPUView . Темно-розовые коробки сигналы и светло-розовые коробки ждет. Каждое поле начинается, когда операция была отправлена на ЦП в Dxgkrnl и заканчивается, когда Dxgkrnl завершает операцию на ЦП. Таким образом, мы можем изучать всю жизнь команды.
Таким образом, на высоком уровне условия HWQueue, необходимые для ведения журнала:
| Condition | Значение |
|---|---|
| FENCE_WAIT_QUEUED | Метка времени ЦП, когда UMD вставляет инструкцию ожидания GPU в очередь команд |
| FENCE_SIGNAL_QUEUED | Метка времени ЦП, когда UMD вставляет инструкцию сигнала GPU в очередь команд |
| FENCE_SIGNAL_EXECUTED | Метка времени GPU при выполнении команды сигнала на GPU для HWQueue |
| FENCE_WAIT_UNBLOCKED | Метка времени GPU о том, когда условие ожидания удовлетворено на GPU, и HWQueue разблокируется |
Идентификаторы DD буфера журнала в собственном заборе
Для поддержки собственных буферов журналов забора представлены следующие DDI, структуры и перечисления:
- DxgkDdiSetNativeFenceLogBuffer / DXGKARG_SETNATIVEFENCELOGBUFFER
- DxgkDdiUpdateNativeFenceLogs / DXGKARG_UPDATENATIVEFENCELOGS
- Буфер журнала, содержащий заголовок и массив записей журнала. Заголовок определяет, являются ли записи для ожидания или сигнала, и каждая запись определяет тип операции (выполнен или разблокирован):
Конструктор буфера журнала предназначен для собственных очередей отправки в режиме пользователя, где полезные данные буфера журнала записываются подсистемой GPU/CMP без участия dxgkrnl или KMD. Поэтому UMD вставляет инструкцию при создании буфера команд ожидания и сигнала, программирование GPU для записи полезных данных буфера журнала в запись буфера журнала при выполнении. Для отправки в режиме, отличном от пользователя (то есть очереди в режиме ядра), команды ожидания и сигналы — это команды программного обеспечения в Dxgkrnl, поэтому мы уже знаем метки времени и другие сведения об этих операциях, и нам не требуется оборудование/KMD для обновления буфера журнала. Для таких очередей режима ядра dxgkrnl не создаст буфер журнала.
Механизм буфера журнала
Dxgkrnl выделяет два выделенных буфера журнала 4 КБ на HWQueue.
- Один для ведения журнала ожидает.
- Один для сигналов ведения журнала.
Эти буферы журналов имеют сопоставления для ЦП в режиме ядра (LogBufferCpuVa), виртуальной машины GPU в адресном пространстве процесса (LogBufferGpuVa) и CMP VA (LogBufferSystemProcessGpuVa), чтобы они могли читать и записывать данные в KMD, обработчик GPU и CMP. Dxgkrnl вызывает DxgkDdiSetNativeFenceFenceLogBuffer дважды: один раз, чтобы задать буфер журнала для ожиданий ведения журнала и один раз задать буфер журнала для сигналов ведения журнала.
Сразу после вставки собственной инструкции ожидания или сигнала забора в список команд также вставляется команда, в которой GPU будет записывать полезные данные при определенной записи в буфер журнала.
После выполнения операции забора обработчик GPU отображает инструкцию UMD для записи полезных данных в заданной записи в буфер журнала. Кроме того, GPU также записывает текущий заборEndGpuTimestamp в эту запись буфера журнала.
Хотя UMD не может получить доступ к буферу журнала с поддержкой GPU, он управляет прогрессией буфера журнала. То есть UMD определяет следующую бесплатную запись для записи, если она есть, и программирует GPU с этой информацией. Когда GPU записывает в буфер журнала, он увеличивает значение FirstFreeEntryIndex в заголовке журнала. UMD должен гарантировать, что записи в записи журнала монотонно увеличиваются.
Рассмотрим следующий сценарий:
- Существует два HWQueues, HWQueueA и HWQueueB с соответствующими буферами журналов ограждения с gpu VAs of FenceLogA и FenceLogB. HWQueueA связан с буфером журнала для ожидания ведения журнала, а HWQueueB связан с буфером журнала для сигналов ведения журнала.
- Существует собственный объект ограждения с пользовательским режимом D3DKMT_HANDLE FenceF.
- Ожидание GPU в FenceF для Value V1 помещается в очередь В HWQueueA во время ЦПT1. При сборке буфера команд UMD вставляет команду, в которой GPU будет записывать полезные данные: LOG(FenceF, V1, DXGK_NATIVE_FENCE_LOG_OPERATION_WAIT_UNBLOCKED).
- Сигнал GPU к FenceF с значением V1 помещается в очередь в HWQueueB во время ЦП2. При сборке буфера команд UMD вставляет команду, в которой GPU будет записывать полезные данные: LOG(FenceF, V1, DXGK_NATIVE_FENCE_LOG_OPERATION_SIGNAL_EXECUTED).
После того как планировщик GPU выполнит сигнал GPU на HWQueueB во время GPU GPU GPUT1, он считывает полезные данные UMD и регистрирует событие в журнале забора ОС для HWQueueB:
DXGK_NATIVE_FENCE_LOG_ENTRY LogEntry = {};
LogEntry.hNativeFence = FenceF;
LogEntry.FenceValue = V1;
LogEntry.OperationType = DXGK_NATIVE_FENCE_LOG_OPERATION_SIGNAL_EXECUTED;
LogEntry.FenceEndGpuTimestamp = GPUT1; // Time when UMD submits a command to the GPU
После того, как планировщик GPU наблюдает за разблокировками HWQueueA во время GPU GPU GPUT2, он считывает полезные данные UMD и регистрирует событие в журнале забора ОС для HWQueueA:
DXGK_NATIVE_FENCE_LOG_ENTRY LogEntry = {};
LogEntry.hNativeFence = FenceF;
LogEntry.FenceValue = V1;
LogEntry.OperationType = DXGK_NATIVE_FENCE_LOG_OPERATION_WAIT_UNBLOCKED;
LogEntry.FenceObservedGpuTimestamp = GPUTo; // Time that GPU acknowledged UMD's submitted command and queued the fence wait on HW
LogEntry.FenceEndGpuTimestamp = GPUT2;
Dxgkrnl может уничтожить и воссоздать буфер журнала. Каждый раз, когда он делает, он вызывает DxgkDdiSetNativeFenceLogBuffer , чтобы сообщить KMD о новом расположении.
Метки времени ЦП для операций с очередями забора
Существует мало преимуществ для создания журнала UMD этих меток времени ЦП, учитывая следующее:
- Список команд можно записать несколько минут до выполнения gpu буфера команд, включающего список команд.
- Эти несколько минут могут быть неупорядоченными с другими объектами синхронизации, которые находятся в одном буфере команд.
Существует плата за включение меток времени ЦП в инструкции UMD к буферу журнала с записью GPU, поэтому метки времени ЦП не включаются в полезные данные записи журнала.
Вместо этого среда выполнения или UMD может выдавать событие трассировки времени ЦП во время записи списка команд. Средства могут таким образом создать временную шкалу забора и завершенных событий, объединив метку времени ЦП из этого нового события и метку времени GPU из записи буфера журнала.
Порядок операций на GPU при сигнале или разблокировки забора
UMD должен обеспечить, чтобы он поддерживал следующий порядок при сборке списка команд, указывающий GPU сигнализировать или разблокировать забор:
- Напишите новое значение забора, чтобы забора VA/CMP VA.
- Запишите полезные данные журнала в соответствующий буфер журнала GPU VA/CMP VA.
- При необходимости вызвать собственное ограждение, сигнальное прерывание.
Этот порядок операций гарантирует, что Dxgkrnl видит самые последние записи журнала при вызове прерывания в ОС.
Разрешено переполнение буфера журнала
GPU может перезаписать буфер журнала, перезаписав записи, которые еще не видели ОС. Это делается путем добавочного обходаCount.
Когда ОПЕРАЦИОННая система в конечном итоге считывает журнал, она может обнаружить, что превышено превышение, сравнивая новое значение WraparoundCount в заголовке журнала с его кэшируемым значением. Если произошло перерасход, ОС имеет следующие резервные параметры:
- Чтобы разблокировать заборы при возникновении переполнения, ОС проверяет все заборы и определяет, какие официанты были разблокированы.
- Если трассировка включена, ОС может вывести флаг в трассировке, чтобы уведомить пользователя о том, что события были потеряны. Кроме того, при включении трассировки ОС сначала увеличивает размер буфера журнала, чтобы предотвратить перезапуск в первую очередь.
Для реализации поддержки обратного давления при выполнении записей буфера журнала не требуется UMD.
Пустые или повторяющиеся метки времени буфера журнала
В распространенных случаях Dxgkrnl ожидает, что метки времени в записях журнала монотонно увеличиваются. Однако существуют сценарии, когда метки времени последующих записей журнала равны нулю или совпадают с предыдущими записями журнала.
Например, в сценарии с связанными адаптерами отображения один из сетевых адаптеров в LDA может пропустить операцию записи забора. В этом случае запись буфера журнала имеет нулевую метку времени. Dxgkrnl обрабатывает такой случай. Тем не менее, Dxgkrnl никогда не ожидает, что метка времени заданной записи журнала будет меньше предыдущей записи журнала; то есть метки времени никогда не могут переходить назад.
Синхронно обновление журнала собственного ограждения
Gpu записывает данные, чтобы обновить значение ограждения и соответствующий буфер журнала, должен обеспечить полное распространение операций записи перед чтением ЦП. Это требование требует использования барьеров памяти. Например:
- Signal Fence(N): запись N в качестве нового текущего значения
- Запись LOG, включая метку времени GPU
- MemoryBarrier
- Добавочное значение FirstFreeEntryIndex
- MemoryBarrier
- Отслеживаемое прерывание забора (N): чтение адреса "M" и сравнение значения с N для принятия решения о доставке прерывания ЦП
Слишком дорого вставлять два барьера для каждого сигнала GPU, особенно если вероятно, что проверка условного прерывания не удовлетворена, и не требуется прерывание ЦП. В результате дизайн перемещает стоимость вставки одного из барьеров памяти от GPU (производителя) к ЦП (потребителю). Dxgkrnl вызывает введенную функцию DxgkDdiUpdateNativeFenceLogs, чтобы kmD синхронно смыть ожидающие записи в журнале собственного ограждения по запросу (аналогично тому, как dxgkddiUpddiUpdateflipqueuelog был введен для журнала очереди HW flip queue flush).
Для операций GPU:
- Signal Fence(N): запись N в качестве нового текущего значения
- Запись LOG, включая метку времени GPU
- Добавочное значение FirstFreeEntryIndex
- MemoryBarrier => Обеспечение полного распространения FirstFreeEntryIndex
- Отслеживаемое прерывание забора (N): чтение адреса "M" и сравнение значения с N для принятия решения о доставке прерывания
Для операций ЦП:
В собственном заборе Dxgkrnl сигнализирует обработчик прерываний (DISPATCH_IRQL):
- Для каждого журнала HWQueue: чтение FirstFreeEntryIndex и определение, записываются ли новые записи.
- Для каждого журнала HWQueue с новыми записями: вызов dxgkDdiUpdateNativeFenceLogs и укажите дескриптор ядра для этих HWQueues. В этом DDI KMD вставляет барьер памяти для каждого заданного HWQueue, что гарантирует фиксацию всех записей журнала.
- Dxgkrnl считывает записи журнала для извлечения полезных данных метки времени.
Таким образом, если оборудование вставляет барьер памяти после записи в FirstFreeEntryIndex, Dxgkrnl всегда вызывает DDI KMD, позволяя KMD вставлять барьер памяти, прежде чем Dxgkrnl считывает все записи журнала.
Будущие требования к оборудованию
Большинство текущего оборудования поколения может поддерживать только запись дескриптора ядра объекта забора, который он сигнализирует в собственном заборе сигнализирует о прерывании. Эта конструкция описана ранее в машинном заборе, сигнализированного прерывания. В этом случае Dxgkrnl обрабатывает полезные данные прерывания следующим образом:
- ОС выполняет чтение (потенциально через PCI) значения забора.
- Зная, какой забор был сигнален и значение забора, ОС просыпается официантов ЦП, которые ожидают этого забора или значения.
- Отдельно для родительского устройства этого забора ОС сканирует буферы журнала всех его HWQueues. Затем ОС считывает последние записи буфера журнала, чтобы определить, какой HWQueue сделал сигнал и извлекает соответствующие полезные данные метки времени. Этот подход может избыточно считывать некоторые значения забора по стандарту PCI.
На будущих платформах Dxgkrnl предпочитает получать массив дескрипторов ядра HwQueue в собственном заборе сигнального прерывания. Такой подход позволяет ос:
- Прочитайте последние записи буфера журнала для этого HwQueue. Устройство пользователя не известно обработчику прерываний; поэтому этот дескриптор HwQueue должен быть дескриптором ядра.
- Проверьте буфер журнала для записей журнала, указывающих, какие заборы были сигнализируют, а также какие значения. Чтение только буфера журнала обеспечивает одно чтение по PCI вместо избыточного чтения значений ограждения и буфера журнала. Эта оптимизация завершается успешно, пока буфер журнала не был перезагрущен (удаление записей, которые Dxgkrnl никогда не считывается).
- Если ОС обнаруживает, что буфер журнала был переполнен, он возвращается к неоптимизированному пути, который считывает динамическое значение каждого ограждения, принадлежащее одному устройству. Производительность пропорциональна количеству заборов, принадлежащих устройству. Если значение забора находится в памяти видео, то эти операции чтения согласованы с кэшем в PCI.
- Зная, какие заборы были сигналированы и значения забора, ОС просыпается официантов ЦП, которые ожидают этих заборов или значений.
Оптимизированное собственное ограждение сигнализировало прерывание
Помимо изменений, описанных в машинном заборе, сигнализованных прерываний, также выполняется следующее изменение для поддержки оптимизированного подхода:
Если поддерживается оборудованием, то вместо заполнения массива дескрипторов ограждения, которые сигналировали, GPU должен упомянуть только маркер KMD HWQueue, запущенный при возникновении прерывания. Dxgkrnl сканирует буфер журнала забора для этого HWQueue и считывает все операции заборов, которые были завершены GPU с момента последнего обновления и разблокирует все соответствующие официанты ЦП. Если GPU не удалось определить, какой подмножество заборов было сигналировано, следует указать дескриптор NULL HWQueue. Когда Dxgkrnl видит дескриптор HWQueue NULL, он возвращается для повторного сканирования буфера журнала всех HWQueues на этом механизме, чтобы определить, какие заборы получили сигнал.
Поддержка этой оптимизации является необязательной; KMD должен задать ограничение DXGK_VIDSCHCAPS:OptimizedNativeFenceFenceSignaledInterrupt , если оно поддерживается оборудованием. Если не задана крышка OptimizedNativeFenceFenceSignaledInterrupt, то GPU/KMD должен следовать поведению, описанному в встроенном заборе, сигнализировав прерывание.
Пример оптимизированного собственного ограждения сигнализировал прерывание
HWQueueA: GPU Signal to Fence F1, Value V1 — Запись в запись > —> прерывание не требуется
HWQueueA: GPU Signal to Fence F1, Value V2 — Запись в запись > —> прерывание не требуется
HWQueueA: GPU Signal to Fence F2, Value V3 — Запись в запись > —> не требуется прерывание
HWQueueA: GPU Signal to Fence F2, Value V3 —> Запись в запись буфера журнала E4 —> прерывание, возникающее
DXGKARGCB_NOTIFY_INTERRUPT_DATA FenceSignalISR = {}; FenceSignalISR.NodeOrdinal = 0; FenceSignalISR.EngineOrdinal = 0; FenceSignalISR.hHWQueue = A;Dxgkrnl считывает буфер журнала для HWQueueA. Он считывает записи буфера журнала E1, E2, E3 и E4 для наблюдения за сигнализованными ограждениями F1 @ Value V1, F1 @ Value V2, F2 @ Value V3 и F2 @ Value V3, и разблокирует все официанты, ожидающие этих заборов и значений
Необязательное и обязательное ведение журнала
Поддержка ведения журнала в собственном заборе для DXGK_NATIVE_FENCE_LOG_TYPE_WAITS и DXGK_NATIVE_FENCE_LOG_TYPE_SIGNALS является обязательной.
В будущем другие типы ведения журнала могут быть добавлены только в том случае, если такие средства, как GPUView , позволяют выполнять подробное ведение журнала ETW в ОС. ОС должна информировать UMD и KMD о том, когда подробное ведение журнала включено и отключено, чтобы ведение журнала этих подробных событий было выборочно включено.