Примечание.
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
В этой статье вы узнаете, как настроить индексатор файлов OneLake для извлечения данных, доступных для поиска, и метаданных из lakehouse поверх Microsoft OneLake.
Чтобы настроить и запустить индексатор, можно использовать следующее:
- REST API источника данных с API индексатора REST
- Пакет Azure SDK, предоставляющий функцию
- Мастер импорта данных на портале Azure.
В этой статье используются REST API для иллюстрации каждого шага.
Необходимые условия
Рабочее пространство Fabric. Следуйте инструкциям из этого руководства, чтобы создать рабочую область Fabric.
Озеро в рабочей области Fabric. Следуйте инструкциям из этого руководства, чтобы создать lakehouse.
Текстовые данные. Если у вас есть двоичные данные, можно использовать анализ изображений обогащения ИИ для извлечения текста или создания описания изображений. Содержимое файла не может превышать ограничения индексатора для уровня службы поиска.
Неструктурированное содержимое в расположении файлов озера. Вы можете добавить данные, выполнив следующие действия.
- Загрузить в lakehouse напрямую
- Использовать конвейеры данных из Microsoft Fabric
- Добавьте ярлыки из внешних источников данных, таких как Amazon S3 или Google Cloud Storage.
Служба поиска ИИ, базовая ценовая категория или более поздняя, настроенная для управляемого удостоверения системы или назначаемого пользователем управляемого удостоверения. Служба поиска на основе ИИ должна находиться в том же клиенте, что и рабочая область Microsoft Fabric.
Назначение роли администратора или участника в рабочей области Microsoft Fabric, в которой находится lakehouse. Действия описаны в разделе "Предоставление разрешений " этой статьи.
Разрешить приложениям вне экосистемы Fabric доступ к данным OneLake.
Клиент REST для формирования вызовов REST, аналогичных тем, которые показаны в этой статье.
Ограничения
Типы файлов Parquet (включая Delta Parquet) не поддерживаются в настоящее время.
Удаление файлов не поддерживается для сочетаний клавиш Amazon S3 и Google Cloud Storage.
Этот индексатор не поддерживает содержимое местоположения таблицы рабочей области OneLake.
Этот индексатор не поддерживает SQL-запросы, но запрос, используемый в конфигурации источника данных, предназначен исключительно для добавления папки или ярлыка для доступа.
Нет поддержки приема файлов из рабочей области "Моя рабочая область" в OneLake, так как это личный репозиторий для каждого пользователя.
Индексирование файлов из Fabric с метками конфиденциальности, например lakehouses, не поддерживается. Однако, когда метки конфиденциальности применяются непосредственно к отдельным документам, поддерживается прием защищенного содержимого и связанных с ним меток. В этих случаях Поиск с использованием ИИ Azure может извлекать и учитывать метки конфиденциальности и содержимое помеченных документов через интеграцию с Purview.
Разрешения на основе ролей рабочей области в Microsoft OneLake могут повлиять на доступ индексатора к файлам. Убедитесь, что сервисный принципал Поиск с использованием ИИ Azure (управляемое удостоверение) имеет достаточные разрешения на доступ к файлам, которые вы планируете получить в целевой рабочей среде Microsoft Fabric.
Поддерживаемые задачи
Этот индексатор можно использовать для следующих задач:
- Индексирование и добавочное индексирование данных: Индексатор может индексировать файлы и связанные метаданные из путей к данным в лейкхаусе. Он обнаруживает новые и обновленные файлы и метаданные с помощью встроенного обнаружения изменений. Вы можете настроить обновление данных по расписанию или по запросу.
- Обнаружение удаления: Индексатор может обнаруживать удаления с помощью пользовательских метаданных для большинства файлов и ярлыков. Для этого требуется добавить метаданные в файлы для обозначения того, что они были "обратимо удалены", что позволяет удалить их из индекса поиска. В настоящее время невозможно обнаружить удаления в файлах ярлыков Google Cloud Storage или Amazon S3, так как пользовательские метаданные не поддерживаются для этих источников данных.
- Применение обогащения искусственного интеллекта с помощью наборов навыков:Skillsets полностью поддерживается индексатором файлов OneLake. Сюда входят ключевые функции, такие как встроенная векторизация , которая добавляет блоки данных и шаги внедрения.
- Режимы синтаксического анализа: Индексатор поддерживает режимы синтаксического анализа JSON , если требуется проанализировать массивы JSON или строки в отдельные документы поиска. Он также поддерживает режим синтаксического анализа Markdown.
- Совместимость с другими функциями: Индексатор OneLake предназначен для эффективной работы с другими функциями индексатора, такими как сеансы отладки, кэш индексатора для добавочных обогащений и хранилища знаний.
Поддерживаемые форматы документов
Индексатор файлов OneLake может извлекать текст из следующих форматов документов:
- CSV (см. индексирование BLOB-объектов CSV)
- EML
- EPUB
- GZ
- HTML
- JSON (см. индексирование блобов JSON)
- KML (XML для географических представлений)
- Markdown
- форматы Microsoft Office: DOCX/DOC/DOCM, XLSX/XLS/XLSM, PPTX/PPT/PPTM, MSG (Outlook электронной почты), XML (WORD XML версии 2003 и 2006)
- Форматы открытых документов: ODT, ODS, ODP
- Обычные текстовые файлы (см. также индексирование обычного текста)
- RTF (Формат обогащённого текста)
- XML
- ZIP
Поддерживаемые сочетания клавиш
Следующие сочетания клавиш OneLake поддерживаются индексатором файлов OneLake:
Ярлык OneLake (ссылка на другой экземпляр OneLake)
Важно
Если не соблюдаются какие-либо предварительные условия или предпринимается попытка выполнить операцию, подпадающую под документированные ограничения, то при перечислении элементов в lakehouse возникнут ошибки.
Подготовка данных к индексации
Перед настройкой индексирования просмотрите исходные данные, чтобы определить, следует ли вносить изменения в данные в lakehouse. Индексатор может индексировать содержимое из одного контейнера одновременно. По умолчанию обрабатываются все файлы в контейнере. У вас есть несколько вариантов для более выборочной обработки:
Поместите файлы в виртуальную папку. Определение источника данных индексатора включает параметр "query", который может быть вложенным папкой Lakehouse или ярлыком. Если это значение указано, индексируются только те файлы в вложенной папке или ярлыке в lakehouse.
Включение или исключение файлов по типу файла. Список поддерживаемых форматов документов поможет определить, какие файлы следует исключить. Например, может потребоваться исключить изображения или звуковые файлы, которые не предоставляют доступный для поиска текст. Эта возможность управляется с помощью параметров конфигурации в индексаторе.
Включите или исключите произвольные файлы. Если вы хотите пропустить определенный файл по какой-либо причине, вы можете добавить свойства и значения метаданных в файлы в lakehouse. При обнаружении этого свойства индексатор пропускает файл или его содержимое в выполнении индексирования.
Включение и исключение файлов рассматриваются на шаге конфигурации индексатора . Если вы не задаете критерии, индексатор сообщает неподходящий файл как ошибку и перемещается дальше. Если возникает достаточно ошибок, обработка может остановиться. Вы можете указать допустимое значение ошибки в параметрах конфигурации индексатора.
Индексатор обычно создает один документ поиска для каждого файла, где текстовое содержимое и метаданные записываются в качестве полей, доступных для поиска в индексе. Если файлы являются целыми файлами, их можно проанализировать в нескольких документах поиска. Например, можно проанализировать строки в CSV-файле , чтобы создать один документ поиска для каждой строки. Если необходимо разделить один документ на небольшие фрагменты для векторизации данных, рекомендуется использовать встроенную векторизацию.
Индексирование метаданных файла
Метаданные файла также могут быть индексированы, и это полезно, если вы считаете, что какие-либо из стандартных или пользовательских свойств метаданных полезны в фильтрах и запросах.
Свойства метаданных, указанные пользователем, извлекаются подробно. Чтобы получить значения, необходимо определить поле в индексе поиска типа Edm.String с тем же именем, что и ключ метаданных объекта blob. Например, если большой двоичный объект имеет ключ метаданных Priority со значением High, необходимо определить поле, названное Priority в индексе поиска, и это поле будет заполнено значением High.
Свойства метаданных стандартного файла можно извлечь в аналогичные именованные и типизированные поля, как показано ниже. Индексатор файлов OneLake автоматически создает внутренние сопоставления полей для этих свойств метаданных, преобразуя исходное дефисированное имя ("metadata-storage-name") в символизованное эквивалентное имя ("metadata_storage_name").
Вам по-прежнему нужно добавить подчёркнутые поля в определение индекса, но можно опустить сопоставление полей индексатора, так как индексатор автоматически делает связь.
metadata_storage_name (
Edm.String) — имя файла. Например, если у вас есть файл /mydatalake/my-folder/subfolder/resume.pdf, значение этого поля равноresume.pdf.metadata_storage_path (
Edm.String) — полный URI блоба, включая учетную запись хранения. Напримерhttps://myaccount.blob.core.windows.net/my-container/my-folder/subfolder/resume.pdfmetadata_storage_content_type (
Edm.String) — тип контента, указанный кодом, используемым для отправки BLOB. Например,application/octet-stream.metadata_storage_last_modified (
Edm.DateTimeOffset) — метка времени последнего изменения для BLOB. Поиск с использованием ИИ Azure использует эту метку времени для идентификации измененных двоичных больших объектов, чтобы избежать повторного индексирования всех данных после первоначального индексирования.metadata_storage_size (
Edm.Int64) — размер blob в байтах.metadata_storage_content_md5 (
Edm.String) — хэш MD5 содержимого BLOB, если он доступен.
Наконец, все свойства метаданных, относящиеся к формату документа индексированных файлов, также могут быть представлены в схеме индекса. Дополнительные сведения о метаданных, относящихся к содержимому, см. в разделе "Свойства метаданных содержимого".
Важно указать, что вам не нужно определять поля для всех указанных выше свойств в индексе поиска— просто захватывать необходимые свойства для приложения.
Предоставление разрешений
Индексатор OneLake использует аутентификацию с использованием токена и доступ, основанный на ролях, для подключения к OneLake. Разрешения назначаются в OneLake. Нет требований к разрешениям для физических хранилищ данных, поддерживающих ярлыки. Например, если вы индексируете из AWS, вам не нужно предоставлять разрешения службы поиска в AWS.
Минимальное назначение ролей для удостоверения службы поиска — участник.
Настройте системное или управляемое пользователем идентификатор для службы поиска с использованием ИИ.
На следующем снимке экрана показана идентичность, управляемая системой, для службы поиска с именем "onelake-demo".
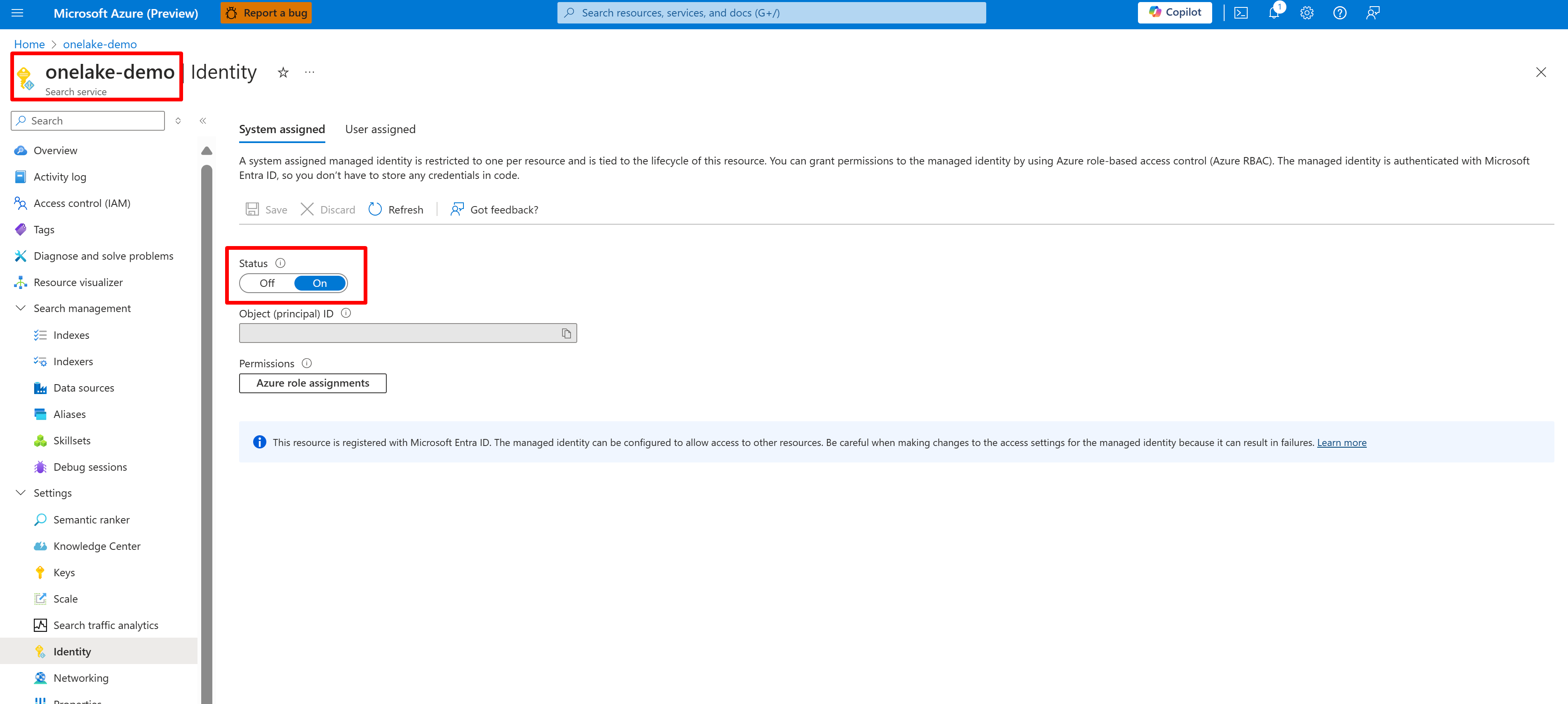
Снимок экрана показывает управляемое пользователем удостоверение для той же службы поиска.

Предоставьте разрешение на доступ к службе поиска в рабочем пространстве Fabric. Служба поиска делает подключение от имени индексатора.
Если вы используете управляемое удостоверение, назначенное системой, найдите имя службы поиска на основе ИИ. Для управляемого удостоверения, назначаемого пользователем, найдите имя ресурса удостоверения.
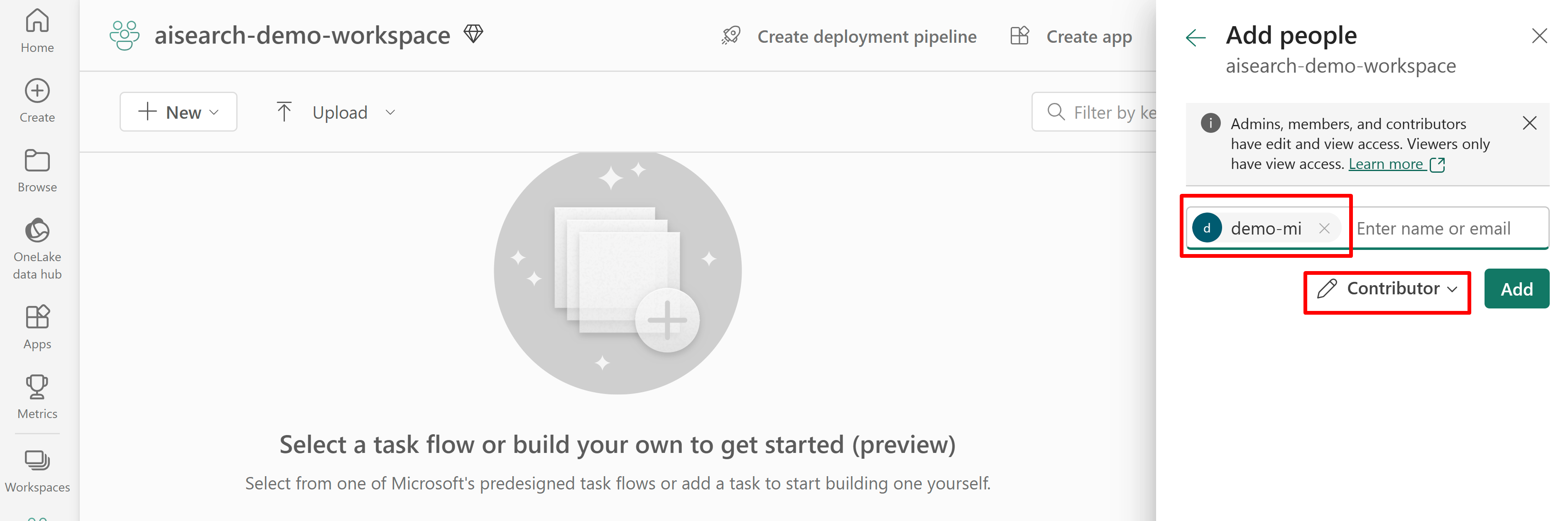
На следующем снимка экрана показано назначение роли участника с помощью системного управляемого удостоверения.

Снимок экрана: назначение роли участника с помощью управляемого удостоверения, назначаемого пользователем:




Настройте совместную приватную ссылку (требуется, если используется приватная ссылка уровня рабочей области Fabric)
Если ваша рабочая область Fabric защищена с помощью приватной ссылки, Поиск с использованием ИИ Azure не сможет получить доступ к данным lakehouse через общедоступный Интернет, и вы не сможете настроить индексатор или его необходимые зависимости, такие как источник данных. Чтобы включить доступ, необходимо настроить частную ссылку для общего доступа между Поиск с использованием ИИ Azure и рабочей областью Fabric.
Определение источника данных
Источник данных определяется как независимый ресурс, чтобы его можно было использовать несколькими индексаторами.
Используйте REST API создания или обновления источника данных , чтобы задать его определение. Это наиболее важные шаги определения.
Установите
"type"на"onelake"(обязательно).Получите GUID рабочей области Microsoft Fabric и GUID Lakehouse.
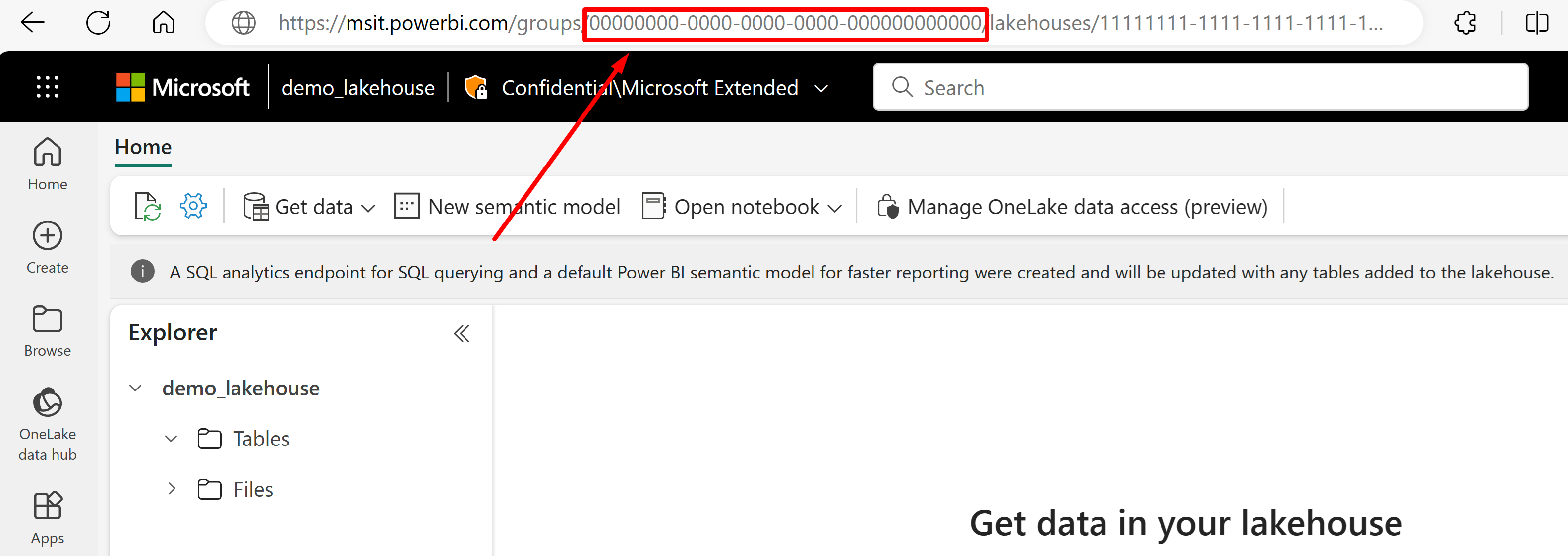
В Power BI откройте "lakehouse", из которого вы хотите импортировать данные. Обратите внимание на URL-адрес Lakehouse в браузере. Он должен выглядеть примерно так: "https://msit.powerbi.com/groups/00000000-0000-0000-0000-000000000000/lakehouses/11111111-1111-1111-1111-111111111111". URL-адрес содержит GUID рабочей области и GUID озерохранилища. Если рабочая область Fabric защищена приватным каналом, URL-адрес начинается с "https://{FabricWorkspaceGuid}.z{xy}.blob.fabric.microsoft.com".
Скопируйте GUID рабочей области, который указан справа от "групп" в URL-адресе. В этом примере это будет 00000000-0000-0000-0000-000000000000. В REST-файле создайте переменную среды
{FabricWorkspaceGuid}и установите для нее значение GUID рабочей области. Если в рабочей области используется приватная ссылка, GUID рабочей области будет отображаться в другом расположении в URL-адресе. Не забудьте ссылаться на правильную часть URL-адреса в зависимости от вашей конфигурации.
Скопируйте GUID Lakehouse, который указан сразу после "lakehouses" в URL-адресе. В этом примере это будет 11111111-1111-1111-1111-1111-1111111111. В вашем файле REST создайте переменную среды
{LakehouseGuid}и присвойте ей значение GUID Lakehouse.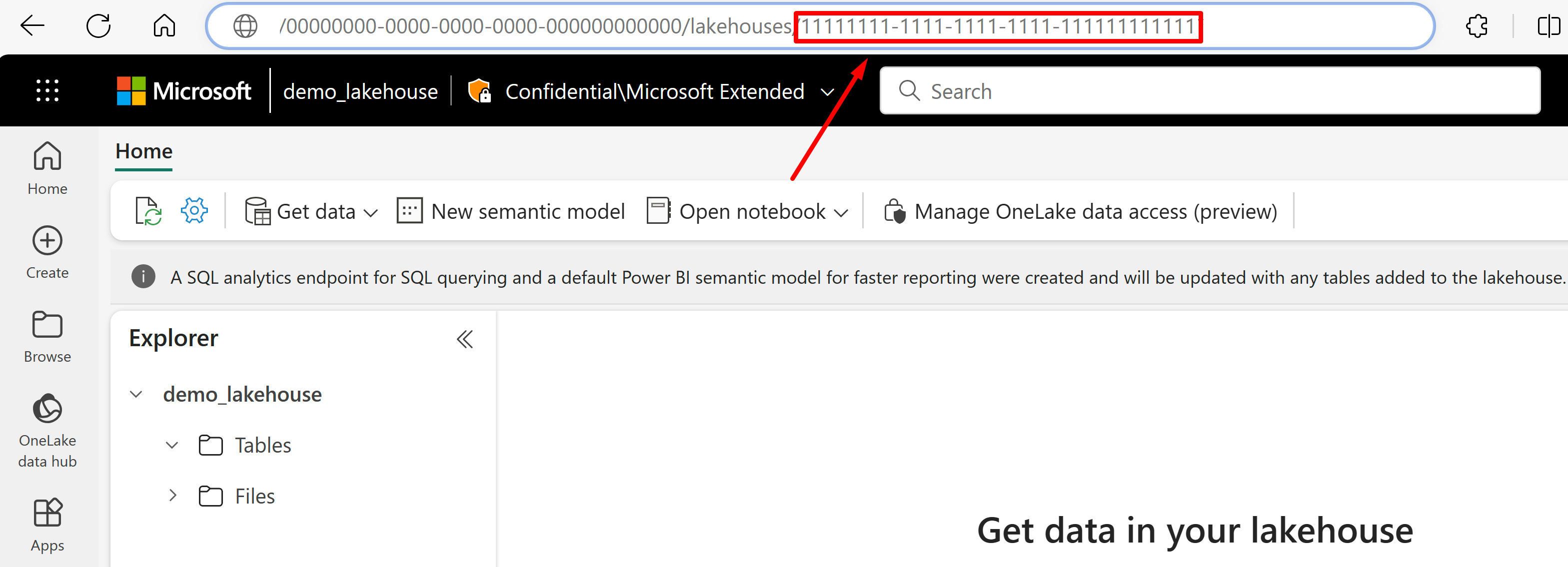
Установите
"credentials"на GUID рабочей области Microsoft Fabric, заменив{FabricWorkspaceGuid}значением, скопированным на предыдущем шаге. Это OneLake для доступа к управляемому удостоверению, которое вы настроите позже в этом руководстве."credentials": { "connectionString": "ResourceId={FabricWorkspaceGuid}" }


Для настройки с использованием совместного приватного канала WorkspaceEndpoint используется вместо ResourceIdнего. Учитывайте это при настройке системного удостоверения или настройки управляемых пользователем удостоверений.
"credentials": {
"connectionString": "WorkspaceEndpoint=https://{FabricWorkspaceGuid}.z{xy}.blob.fabric.microsoft.com"
}
Установите
"container.name"в качестве GUID для Lakehouse, заменив{LakehouseGuid}значением, скопированным на предыдущем шаге. При необходимости используйте"query"для указания вложенной папки или ярлыка lakehouse."container": { "name": "{LakehouseGuid}", "query": "{optionalLakehouseFolderOrShortcut}" }Задайте метод проверки подлинности с помощью управляемого удостоверения, назначаемого пользователем, или перейдите к следующему шагу для управляемого системой удостоверения.
{ "name": "{dataSourceName}", "description": "description", "type": "onelake", "credentials": { "connectionString": "ResourceId={FabricWorkspaceGuid}" }, "container": { "name": "{LakehouseGuid}", "query": "{optionalLakehouseFolderOrShortcut}" }, "identity": { "@odata.type": "Microsoft.Azure.Search.DataUserAssignedIdentity", "userAssignedIdentity": "{userAssignedManagedIdentity}" } }Это значение
userAssignedIdentityможно найти, получив доступ к ресурсу{userAssignedManagedIdentity}, в разделе "Свойства", и оно называетсяId.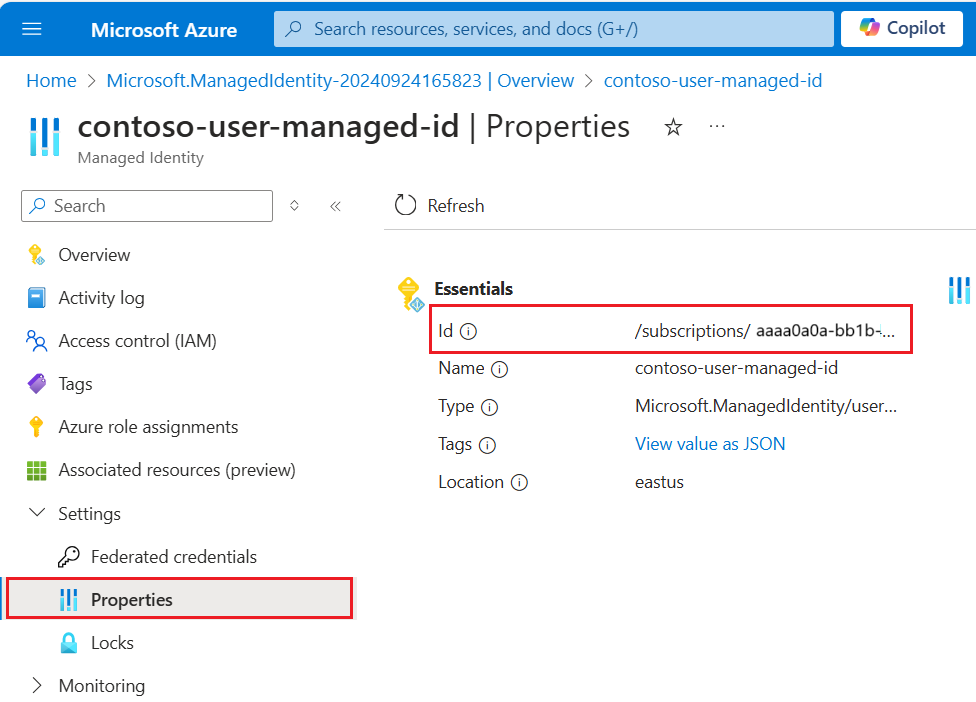
Пример
{ "name": "mydatasource", "description": "description", "type": "onelake", "credentials": { "connectionString": "ResourceId=a0a0a0a0-bbbb-cccc-dddd-e1e1e1e1e1e1" }, "container": { "name": "11111111-1111-1111-1111-111111111111", "query": "folder_name" }, "identity": { "@odata.type": "Microsoft.Azure.Search.DataUserAssignedIdentity", "userAssignedIdentity": "/subscriptions/333333-3333-3333-3333-33333333/resourcegroups/myresourcegroup/providers/Microsoft.ManagedIdentity/userAssignedIdentities/demo-mi" } }При необходимости используйте управляемое удостоверение, назначаемое системой, вместо этого. Идентификатор удаляется из определения при использовании управляемого удостоверения, назначаемого системой.
{ "name": "{dataSourceName}", "description": "description", "type": "onelake", "credentials": { "connectionString": "ResourceId={FabricWorkspaceGuid}" }, "container": { "name": "{LakehouseGuid}", "query": "{optionalLakehouseFolderOrShortcut}" } }Пример
{ "name": "mydatasource", "description": "description", "type": "onelake", "credentials": { "connectionString": "ResourceId=a0a0a0a0-bbbb-cccc-dddd-e1e1e1e1e1e1" }, "container": { "name": "11111111-1111-1111-1111-111111111111", "query": "folder_name" } }

Обнаружение удалений с помощью пользовательских метаданных
Определение источника данных индексатора файлов OneLake может включать политику мягкого удаления, если вы хотите, чтобы индексатор удалял документ поиска, когда исходный документ помечен для удаления.
Чтобы включить автоматическое удаление файлов, используйте настраиваемые метаданные, чтобы указать, следует ли удалить документ поиска из индекса.
Рабочий процесс требует трех отдельных действий:
- "Мягкое удаление" файла в OneLake
- Индексатор удаляет документ поиска в индексе
- "Жесткое удаление" файла в OneLake
"Мягкое удаление" сообщает индексатору, что делать (удалить документ поиска). Если сначала удалить физический файл в OneLake, индексатору будет нечего считывать, и соответствующий документ поиска в индексе останется без связи.
В OneLake и Поиск с использованием ИИ Azure есть шаги, которые нужно выполнить, но нет зависимостей от других функций.
В файле Lakehouse добавьте в файл пользовательскую пару "ключ-значение метаданных", чтобы указать, что файл помечен для удаления. Например, можно присвоить свойству IsDeleted значение false. Если вы хотите удалить файл, измените его на true.
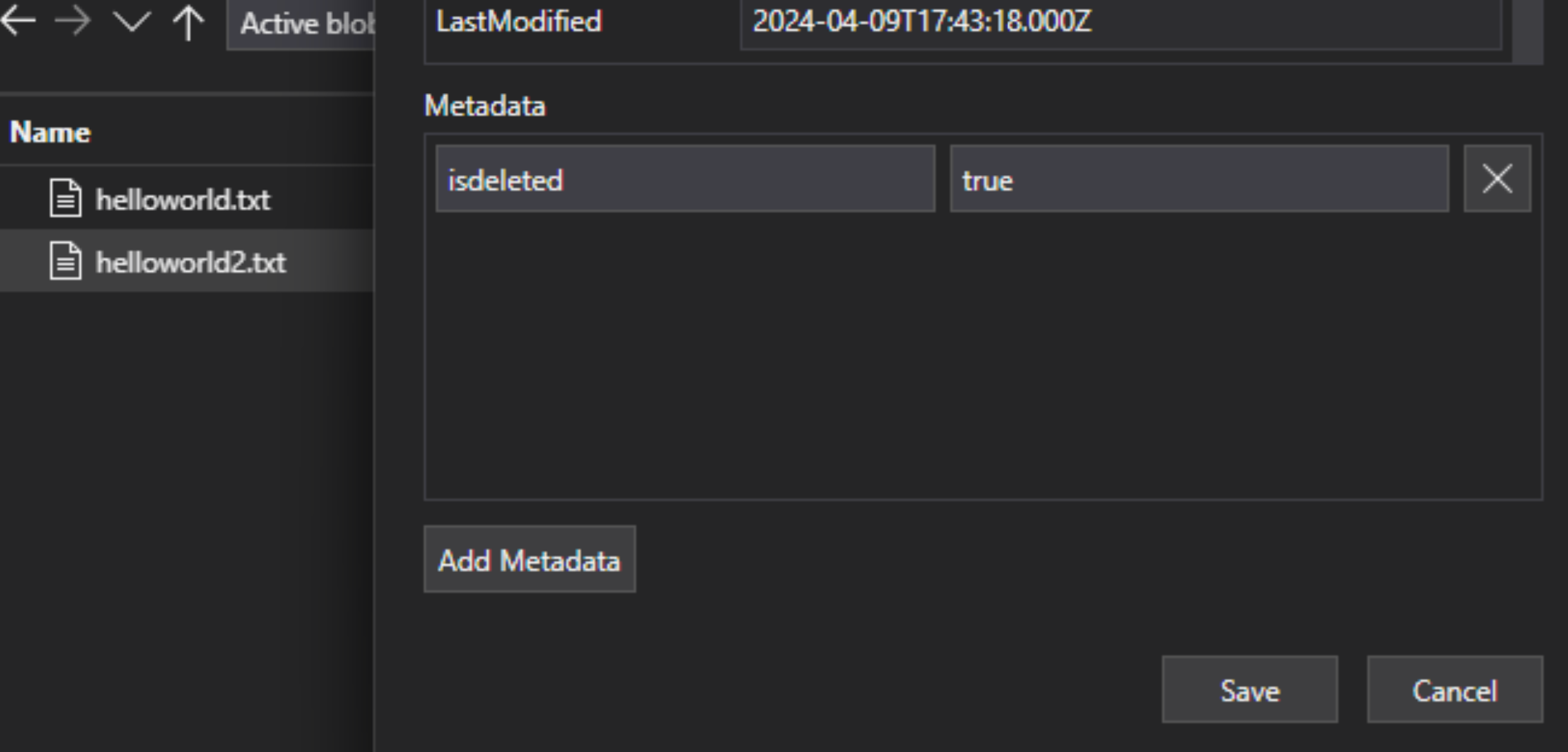
В Поиск с использованием ИИ Azure измените определение источника данных, чтобы включить свойство dataDeletionDetectionPolicy. Например, следующая политика считает файл удаленным, если он имеет свойство метаданных IsDeleted со значением true:
PUT https://[service name].search.windows.net/datasources/file-datasource?api-version=2025-09-01 { "name" : "onelake-datasource", "type" : "onelake", "credentials": { "connectionString": "ResourceId={FabricWorkspaceGuid}" }, "container": { "name": "{LakehouseGuid}", "query": "{optionalLakehouseFolderOrShortcut}" }, "dataDeletionDetectionPolicy" : { "@odata.type" :"#Microsoft.Azure.Search.SoftDeleteColumnDeletionDetectionPolicy", "softDeleteColumnName" : "IsDeleted", "softDeleteMarkerValue" : "true" } }

После того как индексатор завершит работу и удалит документ из индекса поиска, можно удалить физический файл в озере данных.
Некоторые ключевые моменты включают:
Планирование запуска индексатора помогает автоматизировать этот процесс. Мы рекомендуем планировать все сценарии добавочного индексирования.
Если политика обнаружения удаления не была задана при первом запуске индексатора, необходимо сбросить индексатор , чтобы он считывал обновленную конфигурацию.
Помните, что обнаружение удаления не поддерживается для сочетаний клавиш Amazon S3 и Google Cloud Storage из-за зависимости от пользовательских метаданных.
Добавление полей поиска в индекс
В индексе поиска добавьте поля для приема содержимого и метаданных файлов озера данных OneLake.
Создайте или обновите индекс , чтобы определить поля поиска, в которые хранятся содержимое и метаданные файла:
{ "name" : "my-search-index", "fields": [ { "name": "ID", "type": "Edm.String", "key": true, "searchable": false }, { "name": "content", "type": "Edm.String", "searchable": true, "filterable": false }, { "name": "metadata_storage_name", "type": "Edm.String", "searchable": false, "filterable": true, "sortable": true }, { "name": "metadata_storage_size", "type": "Edm.Int64", "searchable": false, "filterable": true, "sortable": true }, { "name": "metadata_storage_content_type", "type": "Edm.String", "searchable": false, "filterable": true, "sortable": true } ] }Создайте поле ключа документа ("key": true"). Для файла в роли содержимого лучшие кандидаты — это метаданные свойства.
metadata_storage_path(по умолчанию) полный путь к объекту или файлу. Поле ключа ("ID" в этом примере) заполняется значениями из metadata_storage_path, так как это значение по умолчанию.metadata_storage_name, доступный только в том случае, если имена уникальны. Если вы хотите, чтобы это поле было ключом, перейдите"key": trueк этому определению поля.Пользовательское свойство метаданных, которое вы добавляете в файлы. Этот параметр требует, чтобы процесс отправки файлов добавлял это свойство метаданных ко всем BLOB-объектам. Так как ключ является обязательным свойством, файлы, в которых отсутствует значение, не индексируются. Если в качестве ключа используется пользовательское свойство метаданных, не вносите изменения в это свойство. Индексаторы добавляют повторяющиеся документы для одного файла, если свойство ключа изменяется.
Свойства метаданных часто включают символы, такие как
/и-недопустимые для ключей документов. Так как у индексатора есть свойство base64EncodeKeys (true по умолчанию), оно автоматически кодирует свойство метаданных, не требуя настройки конфигурации или отображения полей.Добавьте поле content для хранения извлеченного текста из каждого файла через свойство content файла. Вам не требуется использовать это имя, но это позволяет воспользоваться преимуществами неявных сопоставлений полей.
Добавьте поля для стандартных свойств метаданных. Индексатор может считывать настраиваемые свойства метаданных, стандартные свойства метаданных и свойства метаданных, относящиеся к содержимому .
Настройка и запуск индексатора файлов OneLake
После создания индекса и источника данных вы можете создать индексатор. Конфигурация индексатора задает входные данные, параметры и свойства, управляющие поведением во время выполнения. Можно также указать, какие части контейнера (объекта типа BLOB) следует индексировать.
Создайте или обновите индексатор , предоставив ему имя и ссылаясь на источник данных и целевой индекс:
{ "name" : "my-onelake-indexer", "dataSourceName" : "my-onelake-datasource", "targetIndexName" : "my-search-index", "parameters": { "batchSize": null, "maxFailedItems": null, "maxFailedItemsPerBatch": null, "base64EncodeKeys": null, "configuration": { "indexedFileNameExtensions" : ".pdf,.docx", "excludedFileNameExtensions" : ".png,.jpeg", "dataToExtract": "contentAndMetadata", "parsingMode": "default" } }, "schedule" : { }, "fieldMappings" : [ ] }Установите значение batchSize, если значение по умолчанию (10 документов) либо плохо использует, либо перегружает доступные ресурсы. Размеры пакетов по умолчанию относятся к источнику данных. Индексирование файлов задает размер пакета в 10 документов при распознавании большего среднего размера документа.
В разделе "Конфигурация" укажите, какие файлы индексируются на основе типа файла, или оставьте неопределенным, чтобы получить все файлы.
Для
"indexedFileNameExtensions", укажите список расширений файлов, разделенный запятыми (с точкой впереди). Сделайте то же самое для"excludedFileNameExtensions", чтобы указать, какие расширения следует пропустить. Если одно и то же расширение находится в обоих списках, он исключен из индексирования.В разделе "Конфигурация" задайте параметр dataToExtract, чтобы контролировать, какие части файлов индексируются:
contentAndMetadata — значение по умолчанию. Он указывает, что все метаданные и текстовое содержимое, извлеченные из файла, индексируются.
StorageMetadata указывает, что индексируются только стандартные свойства файлов и пользовательские метаданные . Хотя свойства задокументированы для объектов Blob Azure, свойства файла в OneLake такие же, кроме метаданных, связанных с SAS.
"allMetadata" указывает, что стандартные свойства файлов и все метаданные для найденных типов контента извлекаются из содержимого файла и индексируются.
В разделе "Конфигурация" установите параметр "parsingMode", если файлы должны быть сопоставлены с несколькими документами поиска, или если они состоят из обычного текста, документов JSON или CSV-файлов.
Укажите сопоставления полей , если существуют различия в имени или типе поля, или если в индексе поиска требуется несколько версий исходного поля.
В индексировании файлов часто можно опустить сопоставления полей, так как индексатор имеет встроенную поддержку сопоставления свойств "содержимого" и метаданных с аналогичными именованными и типизированными полями в индексе. Для свойств метаданных индексатор автоматически заменяет дефисы на подчеркивания в индексе поиска.
Дополнительные сведения о других свойствах см. в разделе "Создание индексатора". Полный список описаний параметров см. в разделе "Создание индексатора ( REST) в REST API. Параметры одинаковы для Microsoft OneLake.
По умолчанию индексатор запускается автоматически при его создании. Это поведение можно изменить, задав для параметра "Отключено" значение true. Если вы создаете индексатор в отключенном состоянии, запустите индексатор по запросу , когда вы будете готовы к использованию или поместите его в расписание.
Проверка состояния индексатора
Узнайте о нескольких подходах к мониторингу состояния индексатора и журнала выполнения здесь.
Обработка ошибок
Ошибки, которые часто возникают во время индексирования, включают неподдерживаемые типы контента, отсутствующие содержимое или перегруженные файлы. По умолчанию индексатор файлов OneLake останавливается, как только он обнаруживает файл с неподдерживаемым типом контента. Однако индексирование может потребоваться продолжить, даже если возникают ошибки, а затем отлаживать отдельные документы позже.
Временные ошибки являются распространенными для решений, связанных с несколькими платформами и продуктами. Однако если индексатор работает по расписанию (например, каждые 5 минут), он должен иметь возможность восстановиться после этих ошибок при следующем запуске.
Существует пять свойств индексатора, которые управляют ответом индексатора при возникновении ошибок.
{
"parameters" : {
"maxFailedItems" : 10,
"maxFailedItemsPerBatch" : 10,
"configuration" : {
"failOnUnsupportedContentType" : false,
"failOnUnprocessableDocument" : false,
"indexStorageMetadataOnlyForOversizedDocuments": false
}
}
}
| Параметр | Допустимые значения | Описание |
|---|---|---|
| максимальное количество ошибок | -1, null или 0, положительное целое число | Продолжайте индексирование, если ошибки происходят в любой момент обработки, при анализе больших двоичных объектов или при добавлении документов в индекс. Задайте для этих свойств число допустимых сбоев. Значение -1 позволяет обрабатывать независимо от количества ошибок. В противном случае значение является положительным целым числом. |
| МаксимальныйКоличествоОшибочныхЭлементовЗаПартию | -1, null или 0, положительное целое число | Аналогично приведенному выше, но используется для пакетного индексирования. |
| FailOnUnsupportedContentType | истинно или ложно | Если индексатор не может определить тип контента, укажите, следует ли продолжить или завершить задание. |
| FailOnНепроцессируемыйДокумент | истина или ложь | Если индексатор не может обработать документ другого поддерживаемого типа контента, укажите, следует ли продолжить или завершить задание. |
| индексХранилищеМетаданныеТолькоДляДокументовБольшогоРазмера | истина или ложь | Чрезмерно крупные двоичные объекты по умолчанию рассматриваются как ошибки. Если этот параметр имеет значение true, индексатор пытается индексировать его метаданные, даже если содержимое не может быть индексировано. Ограничения на размер блоба см. в разделе Ограничения службы. |
Дальнейшие действия
Просмотрите, как работает мастер импорта данных и попробуйте использовать его для этого индексатора. Встроенную векторизацию можно использовать для сегментирования и создания эмбеддингов для векторного или гибридного поиска по схеме по умолчанию.