Примечание.
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
В Поиск с использованием ИИ Azure обогащение ИИ означает интеграцию с Средствами Foundry для обработки содержимого, которое в необработанной форме недоступно для поиска. Благодаря обогащению, анализ и вывод используются для создания поисково оптимизированного содержимого и структуры, где их ранее не существовало.
Так как поиск ИИ Azure используется для текстовых и векторных запросов, целью обогащения ИИ является улучшение полезности содержимого в сценариях, связанных с поиском. Необработанное содержимое должно быть текстом или изображениями (нельзя обогатить векторы), но выходные данные конвейера обогащения могут быть векторизированы и индексированы в индекс поиска с помощью навыков, таких как навык разделения текста для фрагментирования и навыка внедрения Azure OpenAI для кодирования векторов. Дополнительные сведения об использовании навыков в векторных сценариях см. в разделе "Интегрированные блоки данных" и "внедрение".
Обогащение ИИ основано на навыках.
Встроенные навыки нажмите Foundry Tools. Они применяют следующие преобразования и обработку к необработанному содержимому:
- Перевод и определение языка для многоязычного поиска.
- Распознавание сущностей для извлечения имен людей, мест и других сущностей из больших блоков текста.
- Извлечение ключевых фраз для выявления и вывода важных терминов.
- Оптическое распознавание символов (OCR) для распознавания печатного и рукописного текста в двоичных файлах.
- Анализ изображений для описания содержимого изображения и вывода описания в виде текстовых полей, доступных для поиска.
- Внедрение текста с помощью Azure OpenAI для интегрированной векторизации.
- Многомодальные встраивания с помощью Azure Vision в инструментах Foundry для векторизации текста и изображений.
Пользовательские навыки запускают внешний код. Вы можете использовать пользовательские навыки для любой пользовательской обработки, которую вы хотите включить в конвейер.
Обогащение ИИ — это расширение конвейера индексатора , который подключается к источникам данных Azure. Конвейер обогащения содержит все компоненты конвейера индексатора (индексатор, источник данных, индекс) и набор навыков , указывающий этапы атомарного обогащения.
На следующей схеме показана прогрессия обогащения ИИ:
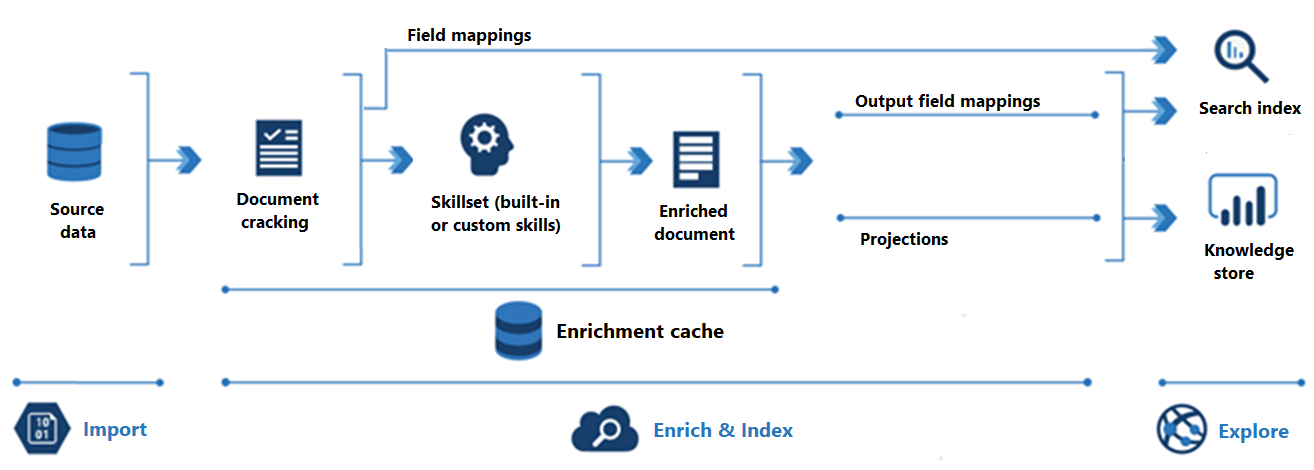
Импорт — это первый шаг. Здесь индексатор подключается к источнику данных и извлекает содержимое (документы) в службу поиска. Хранилище BLOB-объектов Azure является наиболее распространенным ресурсом, используемым в сценариях обогащения ИИ, но любой поддерживаемый источник данных может предоставлять содержимое.
Обогащение и индексирование охватывает большую часть процесса обогащения ИИ:
Обогащение начинается, когда индексатор взломает документы и извлекает изображения и текст. Тип обработки, который происходит далее, зависит от данных и навыков, добавленных в набор навыков. Изображения можно перенаправить в навыки, выполняющие обработку изображений. Текстовое содержимое помещается в очередь для обработки текста и естественного языка. Внутри системы навыки создают обогащенный документ , который собирает преобразования по мере их возникновения.
Обогащенное содержимое создается во время выполнения набора навыков и является временным, если вы не сохраните его. Вы можете включить кэш обогащения для сохранения выходных данных навыка с целью их повторного использования в будущих выполнениях набора навыков.
Чтобы поместить содержимое в поисковый индекс, индексатор должен иметь информацию о сопоставлении для отправки обогащенного содержимого в целевое поле. Сопоставления полей (явные или неявные) задают путь к данным из исходных данных в индекс поиска. Сопоставления полей вывода задают путь передачи данных из обогащенных документов в индекс.
Индексирование — это процесс, в котором необработанное и обогащенное содержимое включается в физические структуры поискового индекса (его файлы и папки). Лексический анализ и маркеризация происходят на этом шаге.
Исследование является последним шагом. Выходные данные всегда являются индексом поиска, который можно запрашивать из клиентского приложения. Результат может быть по желанию представлен в виде хранилища знаний, состоящего из больших двоичных объектов и таблиц в службе хранилища Azure, к которым осуществляется доступ с помощью средств исследования данных или последующих процессов. Если вы создаете хранилище знаний, проекции определяют путь данных для обогащенного содержимого. Одно и то же обогащенное содержимое может отображаться как в индексах, так и в хранилищах знаний.
Когда следует использовать обогащение с помощью ИИ
Обогащение полезно, если исходное содержимое является неструктурированным текстом, изображением или содержимым, которое требует обнаружения языка и перевода. Применение ИИ с помощью встроенных навыков может разблокировать это содержимое для полнотекстового поиска и приложений для обработки и анализа данных.
Вы также можете создавать пользовательские навыки для предоставления внешних процессов. Код с открытым исходным, сторонним или кодом первой стороны можно интегрировать в процесс обработки в качестве пользовательского навыка. Модели классификации, определяющие характерные характеристики различных типов документов, попадают в эту категорию, но любой внешний пакет, добавляющий значение в содержимое, может использоваться.
Варианты использования встроенных навыков
Встроенные навыки основаны на API средств Foundry: Azure Vision и Azure Language. Если ваши входные данные не являются небольшими, ожидается, что вы используете оплачиваемый ресурс Microsoft Foundry для выполнения больших объёмов работ.
Набор навыков , собранный с помощью встроенных навыков, хорошо подходит для следующих сценариев приложения:
Навыки обработки изображений включают оптическое распознавание символов (OCR) и идентификацию визуальных признаков, таких как обнаружение лиц, интерпретация изображений, распознавание изображений (известные люди и ориентиры) или атрибуты, такие как ориентация изображения. Эти навыки создают текстовые представления содержимого изображения для полнотекстового поиска в службе "Поиск ИИ Azure".
Машинный перевод предоставляется навыком перевода текста, часто сопряженным с обнаружением языка для решений с несколькими языками.
Обработка естественного языка анализирует фрагменты текста. Навыки в этой категории включают распознавание сущностей, обнаружение тональности (включая интеллектуальный анализ мнений) и обнаружение персональных данных. С помощью этих навыков неструктурированный текст может быть сопоставлен с полями в индексе, поддерживающими поиск и фильтрацию.
Варианты использования пользовательских навыков
Пользовательские навыки выполняют внешний код, который вы предоставляете и заключаете в веб-интерфейс пользовательского навыка. Несколько примеров пользовательских навыков можно найти в репозитории GitHub azure-search-power-skills .
Пользовательские навыки не всегда сложны. Например, если у вас есть существующий пакет, предоставляющий сопоставление шаблонов или модель классификации документов, его можно упаковать в пользовательский навык.
Хранение выходных данных
В службе "Поиск ИИ Azure" индексатор сохраняет выходные данные, которые он создает. Один запуск индексатора может создавать до трех структур данных, содержащих обогащенные и индексированные выходные данные.
| Хранилище данных | Required | Location | Description |
|---|---|---|---|
| индекс, доступный для поиска | Required | Search service | Используется для полнотекстового поиска и других форм запросов. Указание индекса является требованием индексатора. Содержимое индекса формируется из результатов работы навыков, а также из исходных полей, напрямую сопоставленных с полями в индексе. |
| хранилище знаний | Optional | служба хранилища Azure | Используется для прикладных программ, таких как интеллектуальный поиск знаний, наука о данных и многомодальный поиск. Хранилище знаний определяется в наборе навыков. Его определение определяет, будут ли обогащенные документы проецироваться как таблицы или объекты (файлы или блобы) в службе хранилища Azure. Для сценариев многомодального поиска можно сохранить извлеченные образы в хранилище знаний и ссылаться на них во время запроса, что позволяет возвращать изображения непосредственно клиентским приложениям. |
| кэш обогащения | Optional | служба хранилища Azure | Используется для кэширования обогащений для повторного использования в последующих выполнениях набора навыков. Кэш хранит импортированное непроцессированное содержимое (взломанные документы). Он также сохраняет обогащенные документы, созданные во время выполнения пакета навыков. Кэширование полезно, если вы используете анализ изображений или OCR, и вы хотите избежать времени и расходов на повторную обработку файлов изображений. |
Индексы и хранилища знаний полностью независимы друг от друга. Хотя необходимо прикрепить индекс для выполнения требований индексатора, если ваша единственная цель — хранилище знаний, после его заполнения можно игнорировать индекс.
Изучение содержимого
После определения и загрузки индекса поиска или хранилища знаний вы можете изучить свои данные.
Запрос индекса поиска
Запустите запросы, чтобы получить доступ к обогащенному содержимому, созданного конвейером. Индекс похож на любой другой, который можно создать для поиска ИИ Azure: вы можете дополнить анализ текста пользовательскими анализаторами, вызвать нечеткие поисковые запросы, добавить фильтры или поэкспериментировать с профилями оценки для настройки релевантности поиска.
Использование средств исследования данных в хранилище знаний
В службе хранилища Azure Хранилище знаний может принимать следующие формы: контейнеры больших двоичных объектов с документами JSON, контейнеры изображений как большие двоичные объекты, или таблицы в Table Storage. Вы можете использовать Обозреватель службы хранилища, Power BI или любое приложение, которое подключается к службе хранилища Azure для доступа к содержимому.
Контейнер BLOB-объектов полностью захватывает обогащенные документы, что полезно при создании потока данных для других процессов.
Таблица полезна, если вам нужны срезы обогащенных документов, или если вы хотите включить или исключить определенные части выходных данных. Для анализа в Power BI таблицы являются рекомендуемыми источниками данных для изучения и визуализации данных в Power BI.
Доступность и цены
Обогащение ИИ доступно в регионах, которые предлагают средства Foundry. Сведения о доступности обогащения ИИ см. в списке регионов.
Выставление счетов следует стандартной модели ценообразования. Затраты, связанные со встроенными навыками, возникают при указании ресурса Azure OpenAI в ресурсе Foundry Models или ключа ресурса Foundry в наборе навыков. Существуют также затраты, связанные с извлечением изображений, которые измеряются с помощью Поиск с использованием ИИ Azure. Однако извлечение текста и служебные навыки не оплачиваются. Дополнительные сведения см. в статье Как взимается плата за Поиск с использованием ИИ Azure.
Контрольный список: стандартный рабочий процесс
Конвейер обогащения состоит из индексаторов, которые имеют наборы навыков. После индексирования можно запросить индекс, чтобы проверить результаты.
Начните с подмножества данных в поддерживаемом источнике данных. Индексатор и конструктор наборов навыков — это итеративный процесс. Работа выполняется быстрее с небольшим репрезентативным набором данных.
Создайте источник данных, задающий подключение к данным.
Создайте набор навыков. Если ваш проект не является небольшим, необходимо подключить ресурс Foundry. Если вы создаете хранилище знаний, определите его в наборе навыков.
Создайте схему индекса, которая определяет индекс поиска.
Создайте и запустите индексатор , чтобы объединить все предыдущие компоненты. Этот шаг извлекает данные, запускает набор навыков и загружает индекс.
Индексатор — это также место, где вы указываете сопоставления полей и сопоставления выходных полей, которые устанавливают путь данных к индексу поиска.
При необходимости включите кэширование данных для обогащения в параметрах конфигурации индексатора. Этот этап позволяет позже повторно использовать существующие улучшения.
Выполните запросы, чтобы оценить результаты или запустить сеанс отладки для выполнения любых проблем с набором навыков.
Чтобы повторить любой из предыдущих шагов, сбросьте индексатор перед его запуском. Кроме того, можно удалить и повторно создать объекты на каждом запуске (рекомендуется, если вы используете бесплатный уровень). Если вы включили кэширование, индексатор извлекает данные из кэша, если исходные данные остаются неизменными и ваши изменения в конвейере не делают кэш недействительным.