Примечание.
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
В этом кратком руководстве по быстрому старту вы используете мастер импорта данных Import data на портале Azure для начала работы с интегрированной векторизацией. Мастер разделяет ваше содержимое и вызывает модель встраивания, чтобы векторизировать фрагменты при индексировании и запросе.
В этом кратком руководстве используются текстовые PDF-файлы и простые изображения из репозитория azure-search-sample-data. Однако вы можете использовать различные файлы и завершить работу с этим кратким руководством.
Совет
У вас есть документы с большим количеством изображений? См. раздел Quickstart: многомодальный поиск на портале Azure для извлечения, хранения и поиска изображений вместе с текстом.
Необходимые условия
Учетная запись Azure с активной подпиской. Создайте учетную запись бесплатно.
Служба Поиск с использованием ИИ Azure. В этом кратком руководстве требуется уровень "Базовый" или более высокий для поддержки управляемых удостоверений.
Знакомство с мастером. См. мастер импорта данных на портале Azure.
Поддерживаемые источники данных
Мастер поддерживает несколько источников данных Azure. Однако в этом кратком руководстве рассматриваются только источники данных, работающие со целыми файлами, которые описаны в следующей таблице.
| Источник данных | Описание |
|---|---|
| Хранилище BLOB-объектов Azure | Этот источник данных работает с блобами и таблицами. Необходимо использовать учетную запись стандартной производительности (общего назначения версии 2). Уровни доступа могут быть горячими, прохладными или холодными. |
| Azure Data Lake Storage (ADLS) 2-го поколения | Это учетная запись служба хранилища Azure с включенным иерархическим пространством имен. Чтобы подтвердить наличие Data Lake Storage, перейдите на вкладку Properties на странице Overview. |
| Microsoft OneLake | Этот источник данных подключается к файлам и сочетаниям клавиш OneLake. |
Поддерживаемые модели внедрения
Портал поддерживает следующие модели внедрения для интегрированной векторизации. Инструкции по развертыванию приведены в следующем разделе.
| Поставщик | Поддерживаемые модели |
|---|---|
| учетная запись Azure AI многосервисная1 | Для текста и изображений: Azure Vision мультимодальный |
| Проект Microsoft, основанный на хабе Foundry | Для текста:
|
| проект Microsoft Foundry | Для текста:
|
| ресурс Azure OpenAI3, 4 | Для текста:
|
1 В целях выставления счетов необходимо присоединить учетную запись с несколькими службами к набору навыков Поиск с использованием ИИ Azure. Визард требует, чтобы ваша служба поиска и учетная запись нескольких служб находились в одном поддерживаемом регионе для навыка многомодальных внедрений Azure Vision.
2 Мастер поддерживает только бессерверные развертывания API для этой модели. Вы можете использовать использовать Azure CLI для подготовки бессерверного развертывания.
3 Конечная точка вашего ресурса Azure OpenAI должна иметь пользовательский поддомен, например https://my-unique-name.openai.azure.com. Если вы создали ресурс на портале Azure, этот поддомен был автоматически создан во время настройки ресурса.
4 ресурса Azure OpenAI (с доступом к моделям встраивания), созданные на портале Microsoft Foundry, не поддерживаются. На портале Azure необходимо создать ресурс OpenAI Azure.
Требования к общедоступной конечной точке
Все предыдущие ресурсы должны иметь общедоступный доступ, чтобы мастер смог получить к ним доступ. В противном случае мастер завершается ошибкой. После запуска мастера можно включить брандмауэры и частные конечные точки в компонентах интеграции для обеспечения безопасности. Дополнительные сведения см. в разделе "Безопасные подключения" в мастере импорта.
Если частные конечные точки уже присутствуют и их невозможно отключить, альтернативным вариантом является запуск соответствующего сквозного потока из скрипта или программы на виртуальной машине. Виртуальная машина должна находиться в той же виртуальной сети, что и частная конечная точка. Ниже приведен пример кода Python для интегрированной векторизации. В том же репозитории GitHub есть примеры на других языках программирования.
Настройка доступа
Перед началом работы убедитесь, что у вас есть разрешения на доступ к содержимому и операциям. В этом быстром старте используется Microsoft Entra ID для аутентификации и авторизации на основе ролей. Для назначения ролей необходимо быть владельцем или администратором доступа пользователей . Если использовать роли невозможно, используйте аутентификацию на основе ключей.
Настройте необходимые роли и условные роли , определенные в этом разделе.
Обязательные роли
Поиск с использованием ИИ Azure предоставляет конвейер поиска векторов. Настройте доступ для себя и службы поиска для чтения данных, запуска конвейера и взаимодействия с другими Azure ресурсами.
В службе Поиск с использованием ИИ Azure:
Назначьте следующие роли себе.
Участник службы поиска
Поставщик данных индекса поиска
Средство чтения индексов поиска
Условные роли
На следующих вкладках рассматриваются все ресурсы, совместимые с мастером для поиска векторов. Выберите только вкладки, которые применяются к выбранному источнику данных и модели внедрения.
- служба хранилища Azure
- Microsoft OneLake
- Azure OpenAI
- Microsoft Foundry
- Мультисервисная платформа Azure AI
Хранилище BLOB-объектов Azure и Azure Data Lake Storage 2-го поколения требуют, чтобы служба поиска имели доступ на чтение к контейнерам хранилища.
В учетной записи служба хранилища Azure:
- Назначьте средство чтения данных BLOB-объектов хранилища управляемому удостоверению службы поиска.
Подготовка примеров данных
В этом разделе вы подготавливаете примеры данных для выбранного источника данных.
Перейдите к учетной записи служба хранилища Azure на портале Azure.
В левой области выберитеконтейнеры> данных.
Создайте контейнер и отправьте документы PDF планов медицинского страхования, используемые для этого краткого руководства.
(Необязательно) Синхронизация удалений в контейнере с удалением в индексе поиска. Чтобы настроить индексатор для обнаружения удаления:
Включите мягкое удаление в учетной записи хранения. Если вы используете собственное мягкое удаление, следующий шаг не требуется.
Добавьте настраиваемые метаданные, которые индексатор может сканировать, чтобы определить, какие BLOB-объекты помечены для удаления. Присвойте пользовательскому свойству описательное имя. Например, присвойте свойству "IsDeleted" значение false. Повторите этот шаг для каждого блоба в контейнере. Если вы хотите удалить BLOB, измените свойство на true. Дополнительные сведения см. в разделе Обнаружение изменений и удаления при индексировании из служба хранилища Azure.
Подготовка модели внедрения
Примечание
Если вы используете Azure Vision, пропустите этот шаг. Многомодальные встраивания встроены в многосервисный аккаунт и не требуют развертывания модели.
Мастер поддерживает несколько моделей внедрения из Azure OpenAI и каталога моделей Microsoft Foundry. Сведения о развертывании моделей, необходимых для выбранной модели встраивания, см. в разделе Развертывание моделей Microsoft Foundry на портале Foundry.
Запуск мастера
Перейдите в службу поиска на портале Azure.
На странице "Обзор" выберите "Импорт данных".

Выберите источник данных: Хранилище BLOB-объектов Azure, ADLS 2-го поколения или OneLake.
Выберите RAG.
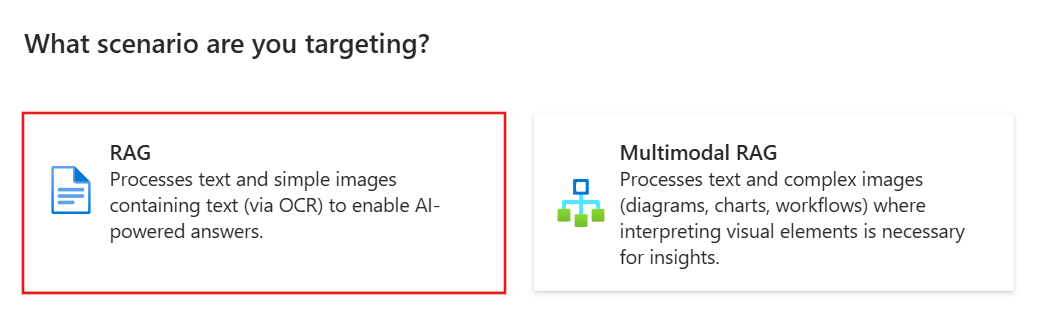

Запуск мастера
Мастер описывает несколько этапов настройки. В этом разделе рассматриваются все этапы последовательности.
Подключение к данным
На этом шаге вы подключаете Поиск с использованием ИИ Azure к выбранному источнику data source для приема содержимого и индексирования.
На странице Подключение к вашим данным выберите подписку Azure.
Выберите учетную запись хранения и контейнер, которые предоставляют образцы данных.
Если вы включили мягкое удаление и добавили настраиваемые метаданные в разделе Подготовка примерных данных, установите флажок "Включить отслеживание удаления".
При последующих запусках обновления поискового индекса индекс обновляется для удаления всех документов поиска, основанных на мягко удаленных больших двоичных объектах на служба хранилища Azure.
Большие двоичные объекты поддерживают либо обратимое удаление встроенных объектов, либо обратимое удаление с использованием пользовательских метаданных.
Если вы настроили большие двоичные объекты для обратимого удаления, укажите пару свойств метаданных name-value. Мы рекомендуем IsDeleted. Если Параметр IsDeleted имеет значение true для большого двоичного объекта, индексатор удаляет соответствующий документ поиска при следующем запуске индексатора.
Мастер не проверяет служба хранилища Azure на наличие допустимых параметров и не выдает ошибку, если требования не выполнены. Вместо этого обнаружение удаления не работает, и индекс поиска, скорее всего, собирает потерянные документы со временем.
Установите флажок "Проверка подлинности с помощью управляемого удостоверения ". Оставьте тип удостоверения назначенным системой.

Нажмите кнопку "Далее".


Векторизация текста
На этом шаге мастер использует выбранную модель внедрения для векторизации фрагментированных данных. Встроенное разбиение на блоки и параметры не подлежат изменению. Эффективные параметры:
"textSplitMode": "pages",
"maximumPageLength": 2000,
"pageOverlapLength": 500,
"maximumPagesToTake": 0, #unlimited
"unit": "characters"
На странице Vectorize your text выберите Azure OpenAI в качестве типа.
Выберите подписку Azure.
Выберите ресурс Azure OpenAI, а затем выберите модель, развернутую в Модели внедрения.
Для типа проверки подлинности выберите назначенное системой удостоверение.
Установите флажок, подтверждающий ваше согласие с условиями выставления счетов при использовании этих ресурсов.
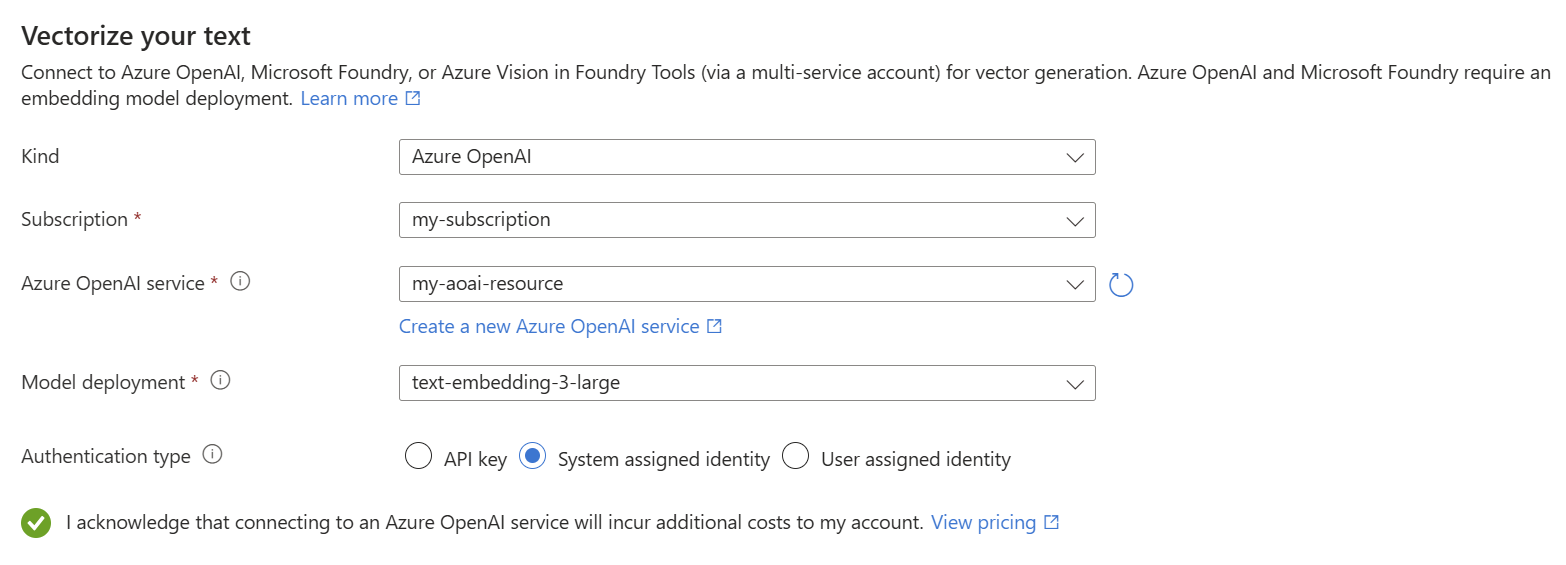
Нажмите кнопку "Далее".



Векторизация и обогащение изображений
PDF-файлы медицинского плана включают корпоративный логотип, но в противном случае изображения отсутствуют. Этот шаг можно пропустить, если вы используете примеры документов.
Однако если содержимое содержит полезные изображения, можно применить ИИ одним или обоими способами:
Используйте поддерживаемую модель встраивания изображений из каталога моделей Foundry Microsoft или API мультимодальных встраиваний Azure Vision (через учетную запись с множеством сервисов) для векторизации изображений.
Используйте оптическое распознавание символов (OCR) для извлечения текста из изображений. Этот опция вызывает навык OCR.
На странице "Векторизация и обогащение изображений " установите флажок "Векторизовать изображения ".
Для типа выберите поставщика моделей: Microsoft Foundry или Azure Vision in Foundry Tools.
Выберите свою Azure подписку, ресурс и развертывание модели внедрения (если применимо).
Для типа проверки подлинности выберите удостоверение, назначенное системой, если вы не используете проект, основанный на хабе. В противном случае оставьте его ключом API.
Установите флажок, подтверждающий осведомленность о финансовых последствиях использования данных ресурсов.

Нажмите кнопку "Далее".


Добавление семантического ранжирования
На странице "Дополнительные параметры" можно дополнительно добавить семантический рейтинг для повторного просмотра результатов в конце выполнения запроса. Переупорядочивание повышает наиболее семантически релевантные совпадения на верхние позиции.
Сопоставить новые поля
На странице "Дополнительные параметры " можно дополнительно добавить новые поля, при условии, что источник данных предоставляет метаданные или поля, которые не выбираются при первом проходе. По умолчанию мастер создает поля, описанные в следующей таблице.
| Поле | Применимо к | Описание |
|---|---|---|
| идентификатор_фрагмента | Векторы текста и изображения | Созданное строковое поле. Доступный для поиска, извлекаемый и сортируемый. Это ключ документа для индекса. |
| parent_id | Текстовые векторы | Созданное строковое поле. Подлежащие извлечению и фильтрации. Определяет родительский документ, из которого происходит блок. |
| чанк | Векторы текста и изображения | Строковое поле. Человекочитаемая версия блока данных. Доступный для поиска и извлечения, но не фильтруемый, не подлежащий фасетированию и не сортируемый. |
| Название | Векторы текста и изображения | Строковое поле. Заголовок документа, доступный для чтения, или номер страницы. Доступный для поиска и извлечения, но не фильтруемый, не подлежащий фасетированию и не сортируемый. |
| text_vector | Текстовые векторы | Collection(Edm.single). Векторное представление фрагмента. Доступный для поиска и извлечения, но не фильтруемый, не подлежащий фасетированию и не сортируемый. |
Вы не можете изменить созданные поля или их атрибуты, но можно добавить новые поля, если источник данных предоставляет их. Например, Хранилище BLOB-объектов Azure предоставляет коллекцию полей метаданных.
Чтобы добавить поля в схему индекса, выполните следующие действия.
На странице "Дополнительные параметры" в разделе "Индекс" выберите "Предварительный просмотр" и "Изменить".
Выберите "Добавить поле".
Выберите исходное поле из доступных полей, введите имя поля для индекса и примите (или переопределите) тип данных по умолчанию.
Если вы хотите восстановить схему до исходной версии, нажмите кнопку "Сброс".
Ключевые моменты этого шага:
Схема индекса предоставляет векторные и невекторные поля для блокированных данных.
Режим синтаксического анализа документов создает блоки (один документ поиска на блок).
Планирование индексирования
Для источников данных, где базовые данные являются переменными, можно запланировать индексирование для записи изменений с определенным интервалом или определенными датами и временем.
Чтобы запланировать индексирование:
На странице "Дополнительные параметры" в разделе "Расписание индексирования" укажите расписание выполнения индексатора. Мы рекомендуем использовать Once для этого краткого руководства.

Нажмите кнопку "Далее".

Завершение работы мастера
Последним шагом является проверка конфигурации и создание необходимых объектов для векторного поиска. При необходимости вернитесь на предыдущие страницы мастера, чтобы откорректировать конфигурацию.
Чтобы завершить работу мастера, выполните следующие действия.
На странице проверки и создания укажите префикс для объектов, создаваемых мастером. Распространенный префикс помогает оставаться упорядоченным.
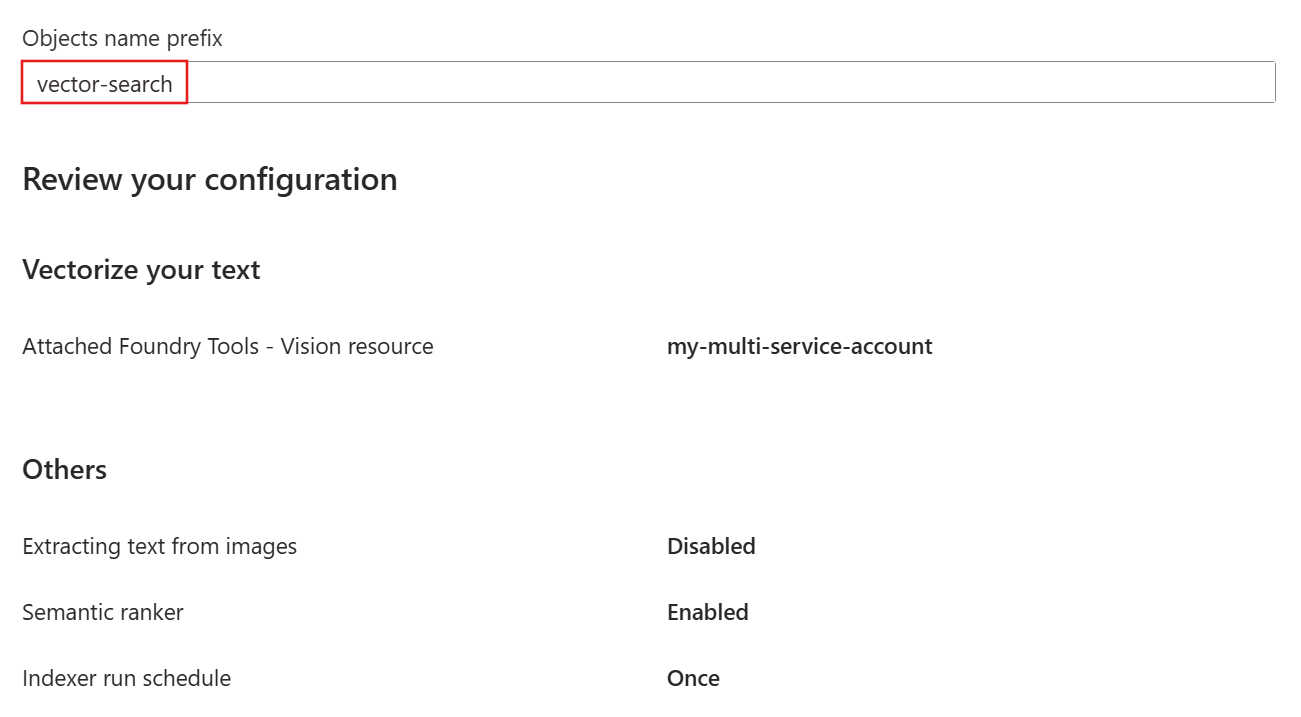
Нажмите кнопку "Создать".

Созданные мастером объекты
Когда мастер завершит настройку, он создает следующие объекты:
| Объект | Описание |
|---|---|
| Источник данных | Представляет подключение к выбранному источнику данных. |
| Индекс | Содержит векторные поля, векторизаторы, профили векторов и алгоритмы векторов. Невозможно изменить индекс по умолчанию во время рабочего процесса мастера. Индексы соответствуют последней предварительной версии REST API для использования предварительных функций. |
| набор навыков | Содержит следующие навыки и конфигурацию:
|
| Индексатор | Управляет конвейером индексирования с сопоставлениями полей и сопоставлениями выходных полей (если это применимо). |
Совет
Созданные мастером объекты имеют настраиваемые определения JSON. Чтобы просмотреть или изменить эти определения, выберите "Управление поиском " в левой области, где можно просматривать индексы, индексаторы, источники данных и наборы навыков.
Проверка результатов
Обозреватель поиска принимает текстовые строки в качестве входных данных, а затем векторизирует текст для выполнения векторного запроса.
Чтобы запросить индекс вектора, выполните следующий запрос:
На портале Azure перейдите к Search Management>Indexes и выберите индекс.
Выберите параметры запроса и выберите "Скрыть векторные значения" в результатах поиска. Этот шаг делает результаты более читаемыми.
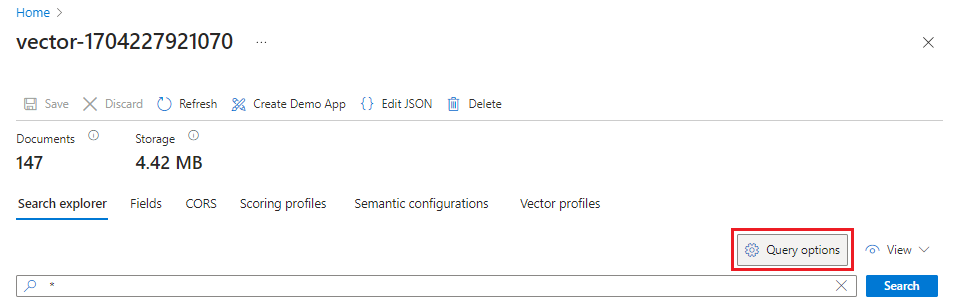
В меню "Вид " выберите представление JSON , чтобы можно было ввести текст для векторного запроса в параметре векторного
textзапроса.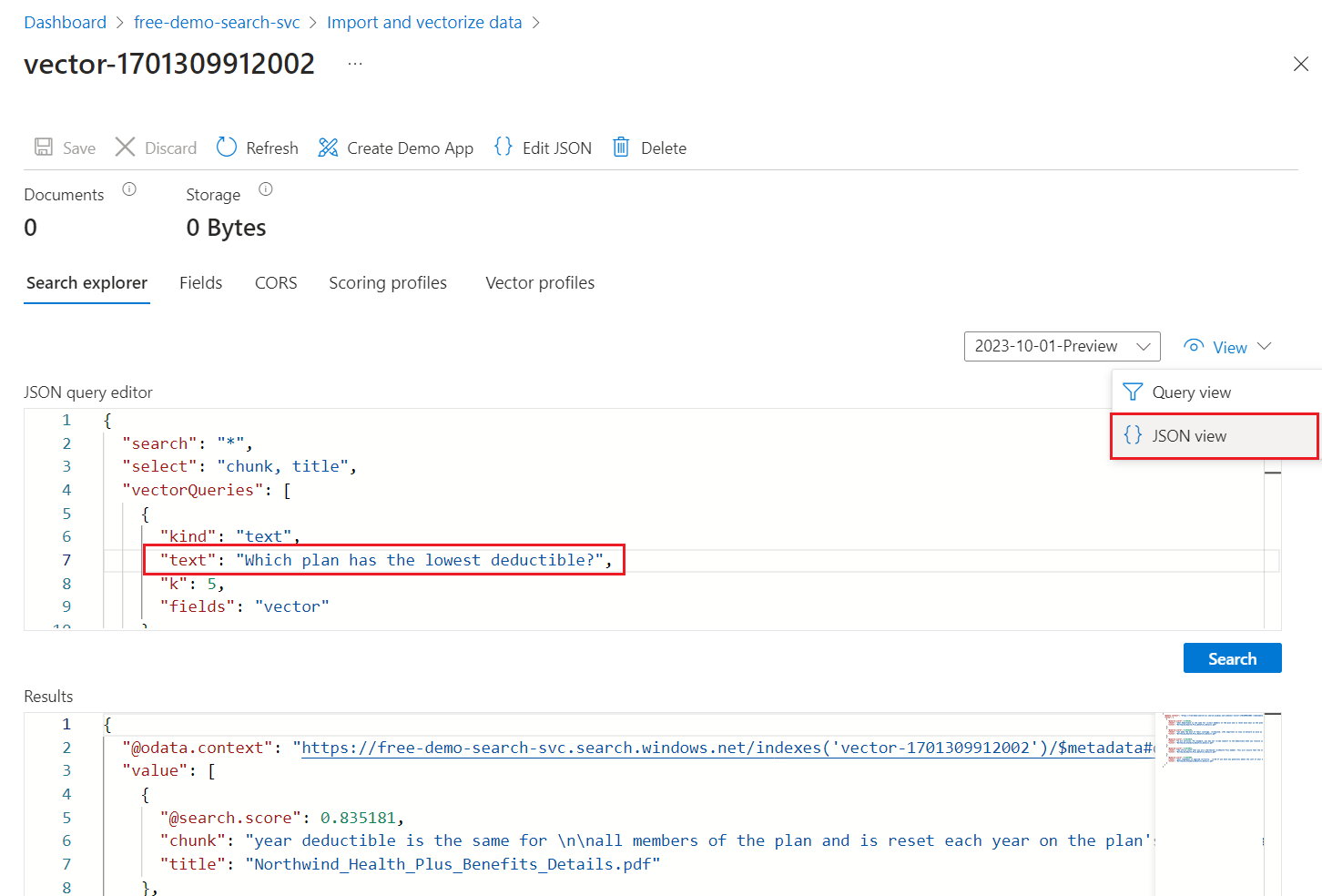
Запрос по умолчанию представляет собой пустой поиск (
"*"), но включает параметры для получения количества совпадений. Это гибридный запрос, который выполняет текстовые и векторные запросы параллельно. Он также включает семантическое ранжирование и указывает, какие поля возвращать в результатах с помощью оператораselect.{ "search": "*", "count": true, "vectorQueries": [ { "kind": "text", "text": "*", "fields": "text_vector,image_vector" } ], "queryType": "semantic", "semanticConfiguration": "my-demo-semantic-configuration", "captions": "extractive", "answers": "extractive|count-3", "queryLanguage": "en-us", "select": "chunk_id,text_parent_id,chunk,title,image_parent_id" }Замените оба заполнителя звездочками (
*) на вопрос, касающийся планов здравоохранения, например,Which plan has the lowest deductible?.{ "search": "Which plan has the lowest deductible?", "count": true, "vectorQueries": [ { "kind": "text", "text": "Which plan has the lowest deductible?", "fields": "text_vector,image_vector" } ], "queryType": "semantic", "semanticConfiguration": "my-demo-semantic-configuration", "captions": "extractive", "answers": "extractive|count-3", "queryLanguage": "en-us", "select": "chunk_id,text_parent_id,chunk,title" }Чтобы запустить запрос, выберите "Поиск".

Каждый документ является фрагментом исходного PDF-файла. В
titleполе показано, откуда поступает блок PDF. Каждыйchunkдлинный. Вы можете скопировать и вставить его в текстовый редактор, чтобы прочитать все значение.Чтобы просмотреть все фрагменты из определенного документа, добавьте фильтр для
title_parent_idполя для определенного PDF-файла. Вы можете проверить вкладку "Поля " индекса, чтобы убедиться, что поле можно фильтровать.{ "select": "chunk_id,text_parent_id,chunk,title", "filter": "text_parent_id eq 'aHR0cHM6Ly9oZWlkaXN0c3RvcmFnZWRlbW9lYXN0dXMuYmxvYi5jb3JlLndpbmRvd3MubmV0L2hlYWx0aC1wbGFuLXBkZnMvTm9ydGh3aW5kX1N0YW5kYXJkX0JlbmVmaXRzX0RldGFpbHMucGRm0'", "count": true, "vectorQueries": [ { "kind": "text", "text": "*", "k": 5, "fields": "text_vector" } ] }



Очистка ресурсов
При работе с собственной подпиской рекомендуется завершить проект, удалив ресурсы, которые больше не нужны. Ресурсы, которые остаются активными, могут обходиться вам в деньги.
На портале Azure выберите All resources или Resource groups на панели слева, чтобы найти ресурсы и управлять ими. Вы можете удалить ресурсы по отдельности или удалить группу ресурсов, чтобы удалить все ресурсы одновременно.
Следующий шаг
В этом кратком руководстве описан мастер импорта данных , который создает все необходимые объекты для интегрированной векторизации. Подробные сведения о каждом шаге см. в статье Set up integrated vectorization in Поиск с использованием ИИ Azure.