Примечание.
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
Примечание
Поиск с использованием ИИ Azure доступна через портал Azure, REST API и Azure SDKs. Он также лежит в основе Foundry IQ — управляемого слоя знаний, который преобразует корпоративный контент в многократно используемые базы знаний с учетом разрешений доступа для агентов на портале Microsoft Foundry.
В этой статье объясняется, как обновить существующий индекс в Поиск с использованием ИИ Azure с изменениями схемы или изменениями содержимого с помощью добавочного индексирования.
Совет
Чтобы немедленно обновить документы, перейдите к разделу "Обновить содержимое". Сведения об изменениях схемы см. в разделе "Обновление схемы индекса".
Необходимые условия
Служба Поиск с использованием ИИ Azure (любой уровень). Create a service или find an existing one.
Существующий индекс поиска с документами. В этой статье предполагается, что вы уже создали индекс и загруженные документы.
Разрешения на обновление или перестроение индексов:
- Проверка подлинности на основе ключей: ключ API администратора для службы поиска.
- Проверка подлинности на основе ролей: роль участника индекса поиска для обновлений документов или участника службы поиска для изменений схемы.
Для разработки пакета SDK установите клиентская библиотека поиска Azure:
- Python: azure-search-documents
- .NET: Azure. Search.Documents
- JavaScript: @azure/search-documents
- Java: azure-search-documents
Совет
Во время активной разработки обычно происходит удаление и перестроение индексов при итерации по проектированию индексов. Работа с небольшим репрезентативным образцом данных, чтобы повторное индексирование выполнялось быстрее. Для изменений в рабочей схеме создайте и протестируйте новый индекс параллельно, а затем используйте псевдоним индекса для замены индексов без изменения кода приложения.
Обновление содержимого
Добавочное индексирование и синхронизация индекса с изменениями исходных данных является фундаментальным для большинства приложений поиска. В этом разделе описывается рабочий процесс добавления, удаления или перезаписи содержимого индекса поиска через REST API, но Azure SDKs обеспечивают эквивалентную функциональность.
Текст запроса содержит один или несколько документов для индексирования. В запросе каждый документ в индексе:
- Определяется уникальным ключом, чувствительным к регистру.
- Ассоциируется с действием: "upload" (загрузка), "delete" (удаление), "merge" (объединение) или "mergeOrUpload" (объединение или загрузка).
- Заполнено набором пар "имя-значение" для каждого поля, добавляемого или обновляемого.
{
"value": [
{
"@search.action": "upload (default) | merge | mergeOrUpload | delete",
"key_field_name": "unique_key_of_document", (key/value pair for key field from index schema)
"field_name": field_value (name/value pairs matching index schema)
...
},
...
]
}
Reference:Documents — Index
Сначала используйте API для загрузки документов, таких как Documents — Index (REST) или эквивалентный API в Azure SDKs. Дополнительные сведения о методах индексирования см. в разделе "Загрузка документов".
Для большого обновления рекомендуется пакетирование (до 1000 документов на пакет или около 16 МБ на пакет, в зависимости от того, какой предел приходится первым) и значительно повышает производительность индексирования.
@search.actionЗадайте параметр в API, чтобы определить влияние на существующие документы. ИспользуйтеmergeOrUploadдля добавочных обновлений (наиболее распространенных),deleteдля удаления документов илиmergeчастичного обновления полей в существующих документах.Действие Эффект Удалить Удаляет весь документ из индекса. Если вы хотите удалить отдельное поле, используйте операцию слияния, задав соответствующему полю значение NULL. Удаленные документы и поля не сразу освобождают место в индексе. Каждые несколько минут фоновый процесс выполняет физическое удаление. Независимо от того, используется ли портал Azure или API для возврата статистики индекса, вы можете ожидать небольшую задержку перед удалением на портале Azure и через API. Дополнительные сведения см. в разделе "Удаление документов в индексе поиска". Объединить Обновляет документ, который уже существует, и не удается найти документ. Слияние заменяет существующие значения. По этой причине обязательно проверьте поля коллекции, содержащие несколько значений, таких как поля типа Collection(Edm.String). Например, еслиtagsполе начинается со значения["budget"]и выполняется слияние с["economy", "pool"], конечное значениеtagsполя равно["economy", "pool"]. Этого не будет["budget", "economy", "pool"].
Такое же поведение применяется к сложным коллекциям. Если документ содержит сложное поле коллекции с именем "Комнаты" со значением[{ "Type": "Budget Room", "BaseRate": 75.0 }], и выполняется слияние со значением[{ "Type": "Standard Room" }, { "Type": "Budget Room", "BaseRate": 60.5 }], окончательное значение поля "Комнаты" будет[{ "Type": "Standard Room" }, { "Type": "Budget Room", "BaseRate": 60.5 }]. Он не будет добавлять или объединять новые и существующие значения.объединитьИлиЗагрузить Ведет себя как функция слияния, если документ существует, и как загрузка, если документ новый. Это наиболее распространенное действие для добавочных обновлений. Загрузить Аналогично операции "вставить или обновить", когда документ вставляется, если он новый, и обновляется или заменяется, если он уже существует. Если в документе отсутствуют значения, необходимые для индекса, то значение поля документа устанавливается в NULL.
Запросы продолжают выполняться во время индексирования, но при обновлении или удалении существующих полей можно ожидать смешанных результатов и более высокой частоты регулирования.
Примечание
Нет гарантий заказа, для которого сначала выполняется действие в тексте запроса. Не рекомендуется использовать несколько действий слияния, связанных с одним документом в одном тексте запроса. Если для одного документа требуется несколько действий слияния, выполните слияние на стороне клиента перед обновлением документа в индексе поиска.
Ответы
Код состояния 200 возвращается для успешного ответа, т. е. все элементы надёжно хранятся и начнут индексироваться. Индексирование выполняется в фоновом режиме и делает новые документы доступными (т. е. запрашиваемыми и доступными для поиска) через несколько секунд после завершения операции индексирования. Конкретная задержка зависит от нагрузки на службу.
Об успешном индексировании свидетельствует свойство состояния, в котором установлено значение true для всех элементов, и свойство statusCode, установленное в значение 201 (для только что загруженных документов) или 200 (для объединенных или удаленных документов).
{
"value": [
{
"key": "unique_key_of_new_document",
"status": true,
"errorMessage": null,
"statusCode": 201
},
{
"key": "unique_key_of_merged_document",
"status": true,
"errorMessage": null,
"statusCode": 200
},
{
"key": "unique_key_of_deleted_document",
"status": true,
"errorMessage": null,
"statusCode": 200
}
]
}
Код состояния 207 возвращается, когда по крайней мере один элемент не был успешно индексирован. Элементы, которые не были индексированы, имеют поле состояния, равное false. Свойства errorMessage и statusCode указывают причину ошибки индексирования.
{
"value": [
{
"key": "unique_key_of_document_1",
"status": false,
"errorMessage": "The search service is too busy to process this document. Please try again later.",
"statusCode": 503
},
{
"key": "unique_key_of_document_2",
"status": false,
"errorMessage": "Document not found.",
"statusCode": 404
},
{
"key": "unique_key_of_document_3",
"status": false,
"errorMessage": "Index is temporarily unavailable because it was updated with the 'allowIndexDowntime' flag set to 'true'. Please try again later.",
"statusCode": 422
}
]
}
Свойство errorMessage указывает причину ошибки индексирования, если это возможно.
В следующей таблице описаны различные коды состояния каждого документа, которые можно вернуть в ответе. Некоторые коды состояния указывают на проблемы с самим запросом, а другие указывают на временные условия ошибки. Последний вы должны повторить после задержки.
| Код состояния | Смысл | Возможность повторной попытки | Заметки |
|---|---|---|---|
| 200 | Документ был успешно изменен или удален. | n/a | Операции удаления являются идемпотентными. То есть, даже если ключ документа не существует в индексе, попытка удаления с этим ключом приводит к коду состояния 200. |
| 201 | Документ был успешно создан. | n/a | |
| 400 | В документе произошла ошибка, которая препятствовала индексации. | Нет | Сообщение об ошибке в ответе указывает, что неправильно с документом. |
| 404 | Документ не удалось объединить, так как заданный ключ не существует в индексе. | Нет | Эта ошибка не возникает при загрузке, так как она создает новые документы, и не возникает при удалении, так как оно идемпотентно. |
| 409 | Конфликт версии обнаружен при попытке индексировать документ. | Да | Это может произойти при попытке индексировать один и тот же документ несколько раз одновременно. |
| 422 | Индекс временно недоступен, так как он был обновлен с флагом AllowIndexDowntime с значением true. | Да | |
| 429 | Слишком много запросов | Да | Если этот код ошибки возникает во время индексирования, обычно это означает, что вы работаете с низким уровнем хранилища. По мере того как вы приближаетесь к ограничениям хранения, служба может ввести состояние, в котором нельзя добавлять или обновлять до тех пор, пока не удалите некоторые документы. Дополнительные сведения см. в разделе "Планирование емкости" и управление ими, если требуется больше хранилища или освободить место, удалив документы. |
| 503 | Служба поиска временно недоступна, возможно, из-за тяжелой нагрузки. | Да | Код должен подождать перед повторной попыткой в этом случае, иначе вы рискуете увеличить время недоступности службы. |
Если клиентский код часто встречает ответ 207, одна из возможных причин заключается в том, что система находится под нагрузкой. Это можно подтвердить, проверив свойство statusCode для 503. Если код состояния равен 503, рекомендуется ограничивать запросы индексирования. В противном случае, если индексирование трафика не утихает, система может начать отклонять все запросы с ошибками 503.
Код состояния 429 указывает, что превышена квота на количество документов на индекс. Необходимо либо обновить для более высоких ограничений емкости , либо создать новый индекс.
Примечание
При отправке значений DateTimeOffset со сведениями часового пояса в индекс Поиск с использованием ИИ Azure нормализует эти значения в формате UTC. Например, 2024-01-13T14:03:00-08:00 хранится как 2024-01-13T22:03:00Z. Если необходимо сохранить сведения часового пояса, добавьте дополнительный столбец в индекс для этой точки данных.
Советы по инкрементальному индексированию
Индексаторы автоматизируют добавочное индексирование. Если вы можете использовать индексатор, а если источник данных поддерживает отслеживание изменений, можно запустить индексатор в повторяющееся расписание для добавления, обновления или перезаписи содержимого для поиска, чтобы он синхронизировался с внешними данными.
Если вы выполняете вызовы индекса непосредственно через push API, используйте
mergeOrUploadв качестве действия поиска.Нагрузка должна содержать ключи или идентификаторы каждого документа, которые необходимо добавить, обновить или удалить.
Если индекс содержит векторные поля и вы присвоите
storedсвойству значение false, убедитесь, что вектор указан в частичном обновлении документа, даже если значение не изменилось. Побочный эффект установки параметраstoredв значение false заключается в том, что векторы удаляются при операции переиндексации. Предоставление вектора в содержимом документа предотвращает это.Чтобы обновить содержимое простых полей и подполей в сложных типах, укажите только поля, которые нужно изменить. Например, если нужно обновить только поле описания, полезная нагрузка должна состоять из ключа документа и измененного описания. Опущение других полей сохраняет существующие значения.
Чтобы объединить внесенные изменения в коллекцию строк, предоставьте полное значение.
tagsПомните пример поля из предыдущего раздела. Новые значения перезаписывают старые значения для всего поля и не объединяются в содержимое поля.
Ниже приведен пример REST API , демонстрирующий следующие советы:
### Get Stay-Kay City Hotel by ID
GET {{baseUrl}}/indexes/hotels-vector-quickstart/docs('1')?api-version=2026-04-01 HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
### Change the description, city, and tags for Stay-Kay City Hotel
POST {{baseUrl}}/indexes/hotels-vector-quickstart/docs/search.index?api-version=2026-04-01 HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"value": [
{
"@search.action": "mergeOrUpload",
"HotelId": "1",
"Description": "I'm overwriting the description for Stay-Kay City Hotel.",
"Tags": ["my old item", "my new item"],
"Address": {
"City": "Gotham City"
}
}
]
}
### Retrieve the same document, confirm the overwrites and retention of all other values
GET {{baseUrl}}/indexes/hotels-vector-quickstart/docs('1')?api-version=2026-04-01 HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
Справочник:Документы — индекс, Поиск документа
Примеры пакета SDK
В следующих примерах показано, как обновить документы с помощью Azure SDKs.
from azure.core.credentials import AzureKeyCredential
from azure.search.documents import SearchClient
# Set up the client
service_name = "<your-search-service-name>"
index_name = "hotels-sample"
api_key = "<your-admin-api-key>"
endpoint = f"https://{service_name}.search.windows.net"
credential = AzureKeyCredential(api_key)
client = SearchClient(endpoint=endpoint, index_name=index_name, credential=credential)
# Update documents using merge_or_upload
documents = [
{
"HotelId": "1",
"Description": "Updated description for the hotel.",
"Tags": ["updated", "renovated"]
}
]
result = client.merge_or_upload_documents(documents=documents)
print(f"Updated {len(result)} document(s)")
Обновление схемы индекса
Схема индекса определяет структуры физических данных, созданные в службе поиска, поэтому нет большого количества изменений схемы, которые можно внести без полного перестроения.
Обновления без перестроения
В следующем списке перечислены изменения схемы, которые можно легко ввести в существующий индекс. Как правило, список включает новые поля и функциональные возможности, используемые во время выполнения запроса.
- Добавление описания индекса
- Добавление нового поля
- Установка атрибута
retrievableв существующем поле - Обновите
searchAnalyzerв поле с существующимindexAnalyzer - Добавьте новое определение анализатора в индекс (который можно применить к новым полям)
- Добавление, обновление или удаление оценочных профилей
- Добавление, обновление или удаление карт синонимов
- Добавление, обновление или удаление семантических конфигураций
- Добавление, обновление или удаление параметров CORS
Порядок операций:
Обновите схему с изменениями из предыдущего списка.
Обновите схему индекса в службе поиска.
Обновите содержимое индекса , чтобы соответствовать измененной схеме, если вы добавили новое поле. Для всех остальных изменений существующее индексированное содержимое используется без изменений.
При обновлении схемы индекса для включения нового поля существующие документы в индексе получают значение NULL для этого поля. В следующем задании индексирования значения из внешних исходных данных заменяют значения NULL, добавленные Поиск с использованием ИИ Azure.
Во время обновлений не должно быть сбоев в работе запросов, но результаты запросов будут отличаться по мере вступления обновлений в силу.
Обновления, требующие перестроения
Для некоторых изменений требуется удаление и перестроение индекса, заменив текущий индекс новым.
| Действие | Описание |
|---|---|
| Удаление поля | Чтобы физически удалить все следы поля, необходимо перестроить индекс. Если немедленное перестроение нецелесообразно, вы можете изменить код приложения для перенаправления доступа из устаревшего поля или использовать параметры запроса searchFields и select, чтобы выбрать, по каким полям осуществляется поиск и какие поля возвращаются. Физически определение поля и содержимое остаются в индексе до следующего перестроения, когда применяется схема, которая не указывает на поле. |
| Изменение определения поля | Изменение имени поля, типа данных или определенных атрибутов индекса (доступных для поиска, фильтруемых, сортируемых, доступных для разбиения на аспекты) требует полного перестроения. |
| Назначьте анализатор полю | Анализаторы определяются в индексе, назначены полям, а затем вызываются во время индексирования, чтобы сообщить, как создаются маркеры. В любой момент можно добавить новое определение анализатора в индекс, но при создании поля можно назначить только анализатор. Это верно для свойств анализатора и indexAnalyzer . Свойство searchAnalyzer является исключением (вы можете назначить это свойство существующему полю). |
| Обновление или удаление определения анализатора в индексе | Вы не можете удалить или изменить существующую конфигурацию анализатора (анализатор, токенизатор, фильтр маркеров или фильтр символов) в индексе, если вы не перестроите весь индекс. |
| Добавление поля в средство предложения | Если поле уже существует и вы хотите добавить его в конструкцию предложения , перестройте индекс. |
| Обновление службы или уровня | Если вам нужна дополнительная емкость, проверьте, можно ли обновить службу или перейти на более высокую ценовую категорию. В противном случае необходимо создать новую службу и перестроить индексы с нуля. Чтобы автоматизировать этот процесс, можно использовать пример кода, который выполняет резервное копирование индекса в ряд JSON-файлов. Затем можно повторно создать индекс в указанной службе поиска. |
Порядок операций:
Получите определение индекса в случае, если он необходим для последующей ссылки, или использовать в качестве основы для новой версии.
Рекомендуется использовать решение резервного копирования и восстановления для сохранения копии содержимого индекса. Существуют решения в C# и в Python. Рекомендуется использовать Python версию, так как она обновлена.
Если у вас есть емкость в службе поиска, сохраните существующий индекс при создании и тестировании нового.
Удалите существующий индекс. Запросы, предназначенные для индекса, немедленно удаляются. Помните, что удаление индекса является необратимым, уничтожая физическое хранилище для коллекции полей и других конструкций.
Разместите переработанный индекс, где тело запроса включает измененные определения полей и конфигурации.
Загрузите индекс с документами из внешнего источника. Документы индексируются с помощью определений полей и конфигураций новой схемы.
При создании индекса физическое хранилище выделяется для каждого поля в схеме индекса с инвертируемым индексом, созданным для каждого поля поиска, и векторным индексом, созданным для каждого векторного поля. Поля, которые недоступны для поиска, могут использоваться в фильтрах или выражениях, но не имеют инвертированных индексов и не являются полнотекстовых или нечеткими для поиска. При перестроении индекса эти инвертированные индексы и векторные индексы удаляются и повторно создаются на основе предоставленной схемы индекса.
Чтобы свести к минимуму нарушение кода приложения, рекомендуется создать псевдоним индекса. Код приложения ссылается на псевдоним, но можно обновить имя индекса, на который указывает псевдоним.
Добавление описания индекса
Индекс имеет description свойство, которое можно указать и использовать, когда система должна получить доступ к нескольким индексам и принять решение на основе описания. Рассмотрим сервер протокола контекста модели (MCP), который должен выбрать правильный индекс во время выполнения. Решение может основываться на описании, а не только на имени индекса.
Описание индекса — это обновление схемы, и его можно добавить, не перестроив весь индекс.
- Длина строки составляет 4000 символов.
- Содержимое должно быть удобочитаемым в Юникоде. Ваш вариант использования должен определить, какой язык следует использовать.
Вы можете добавить описание индекса с помощью портала Azure, последнего стабильного REST API или пакета Azure SDK, который предоставляет эту функцию.
Портал Azure поддерживает последний api предварительной версии.
Перейдите в службу поиска на портале Azure.
В разделе"Индексы управления >поиском" выберите индекс.
Выберите "Изменить JSON".
Вставка
"description", за которой следует описание. Значение должно быть меньше 4000 символов и в Юникоде.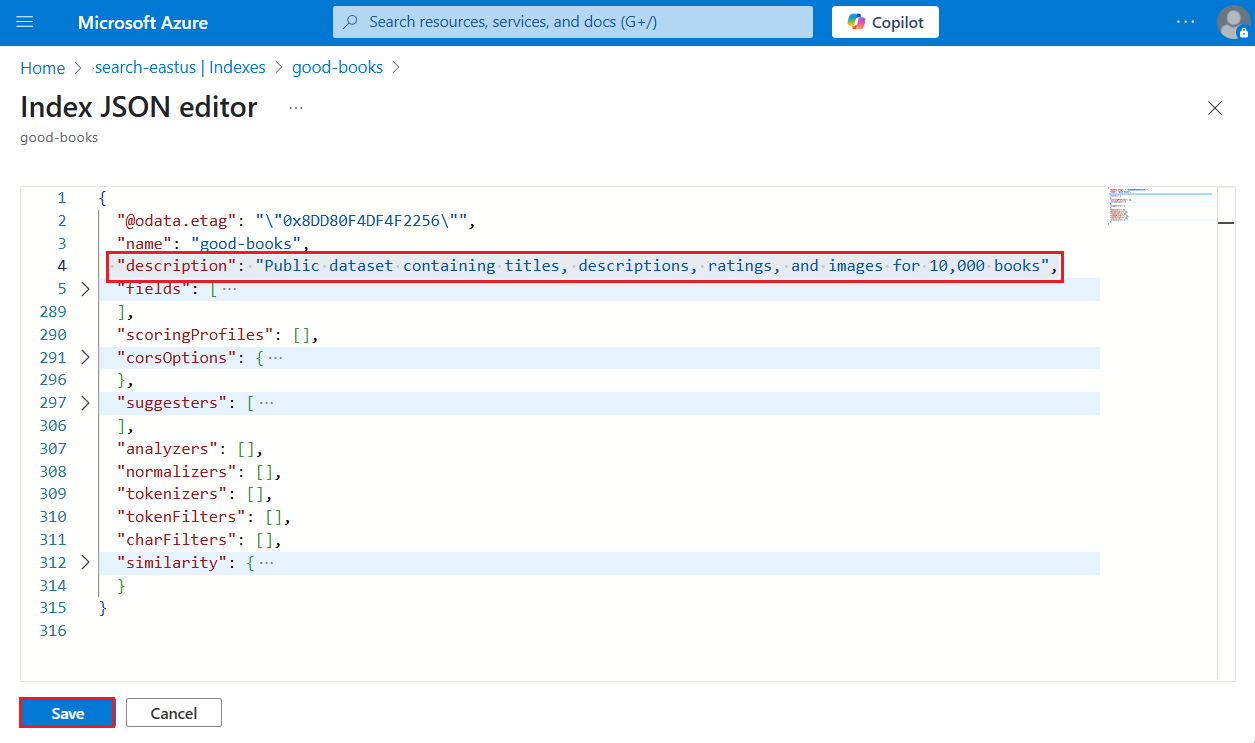
Сохраните индекс.
Балансировка рабочих нагрузок
Индексирование не выполняется в фоновом режиме, но служба поиска будет балансировать все задания индексирования по текущим запросам. Во время индексирования можно отслеживать запросы на портале Azure, чтобы обеспечить своевременное выполнение запросов.
Если индексирование рабочих нагрузок вводит неприемлемые уровни задержки запросов, проводите анализ производительности и просмотрите эти советы по устранению рисков.
Проверка обновлений
Запрос индекса можно начать сразу после загрузки первого документа. Если вы знаете идентификатор документа, REST API поиска документа возвращает конкретный документ. Для более широкого тестирования следует ждать, пока индекс не будет полностью загружен, а затем использовать запросы для проверки контекста, который вы ожидаете увидеть.
Обозреватель поиска или клиент REST можно использовать для проверки обновленного содержимого.
Если вы добавили или переименовали поле, используйте select, чтобы вернуть это поле.
"search": "*",
"select": "document-id, my-new-field, some-old-field",
"count": true
Портал Azure предоставляет размер индекса и размер векторного индекса. Эти значения можно проверить после обновления индекса, но не забудьте ожидать небольшую задержку, так как служба обрабатывает изменение и учтите, что обновление портала может занять несколько минут.
Устранение неполадок повторной индексации
В следующей таблице перечислены распространенные проблемы при обновлении или перестроении индексов и их устранении.
| Проблема | Причина | Разрешение |
|---|---|---|
| Ответ 207 с смешанными результатами | Некоторые документы были успешны, другие провалились. | Проверьте statusCode для каждого документа в ответе. Если возникает ошибка 503, ограничьте частоту запросов и повторите попытку. |
| Конфликт версии 409 | Одновременные обновления в одном документе. | Последовательно применяйте обновления к тому же документу или реализуйте повторную попытку с экспоненциальной задержкой. |
| 429 слишком много запросов | Превышена квота хранилища или слишком много одновременных запросов. | Удалите документы, чтобы освободить место, или обновите тарифный план для увеличения емкости. |
| Служба 503 недоступна | Служба под тяжелой нагрузкой. | Подождите и повторите попытку с экспоненциальной задержкой. Рассмотрите возможность уменьшения размера пакета. |
| Количество документов без изменений после удаления | Удаление асинхронно. | Подождите 2–3 минуты, пока фоновый процесс завершит физическое удаление. |
| Новое поле возвращает значение NULL | Поле добавлено в схему, но документы не переиндексированы. | Запустите индексатор или отправьте обновленные документы, чтобы заполнить новое поле. |
| Отклонено изменение схемы | Попытка несовместимого изменения (переименование, изменение типа). | Удалите и постройте индекс заново. Используйте псевдоним индекса для минимизации простоя. |
См. также
- Обзор индексатора
- Удаление документов из индекса поиска
- Индексирование больших наборов данных в масштабе
- Индексация на портале Azure
- индексатор База данных SQL Azure
- Azure Cosmos DB для индексатора NoSQL
- Azure индексатор BLOB-объектов
- Azure индексатор таблиц
- Данные, конфиденциальность и встроенная защита