Примечание.
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
Узнайте, как использовать пакет SDK Azure для .NET для создания конвейера обогащения ИИ для извлечения содержимого и преобразований во время индексирования.
Наборы навыков добавляют обработку ИИ в необработанное содержимое, что делает его более универсальным и доступным для поиска. Когда вы узнаете, как работают наборы навыков, вы можете поддерживать широкий спектр преобразований, от анализа изображений до обработки естественного языка до настраиваемой обработки, которую вы предоставляете внешне.
Изучив это руководство, вы:
- Определите объекты в конвейере обогащения.
- Создание набора навыков. Вызов OCR, распознавание речи, распознавание сущностей и извлечение ключевых фраз.
- Выполните конвейер. Создание и загрузка индекса поиска.
- Проверьте результаты с помощью полнотекстового поиска.
Overview
В этом руководстве используется C# и клиентская библиотека Azure.Search.Documents для создания источника данных, индекса, индексатора и набора навыков.
Индексатор управляет каждым шагом в конвейере, начиная с извлечения содержимого образцов данных (неструктурированный текст и изображения) в контейнере blob на службе хранения Azure.
После извлечения содержимого набор навыков выполняет встроенные навыки от Корпорации Майкрософт для поиска и извлечения информации. Эти навыки включают оптическое распознавание символов (OCR) на изображениях, распознавание языка на тексте, извлечении ключевых фраз и распознавании сущностей (организации). Новая информация, созданная набором навыков, отправляется в поля в индексе. После заполнения индекса можно использовать поля в запросах, аспектах и фильтрах.
Prerequisites
Учетная запись Azure с активной подпиской. Создайте учетную запись бесплатно .
Note
Вы можете использовать бесплатную службу поиска для этого руководства. Уровень "Бесплатный" ограничивается тремя индексами, тремя индексаторами и тремя источниками данных. В этом руководстве создается по одному объекту из каждой категории. Перед началом работы убедитесь, что у вас есть место в службе, чтобы принять новые ресурсы.
Загрузка файлов
Скачайте ZIP-файл примера репозитория данных и извлеките его содержимое. Инструкции.
Загрузка образцов данных в службу хранилища Azure
В службе хранилища Azure создайте контейнер и назовите его смешанными типами контента.
Отправьте примеры файлов данных.
Получите строку подключения хранилища, чтобы настроить подключение в службе Поиск с использованием ИИ Azure.
В левой части экрана выберите ключи доступа.
Скопируйте строку подключения для первого или второго ключа. Строка подключения аналогична следующему примеру:
DefaultEndpointsProtocol=https;AccountName=<your account name>;AccountKey=<your account key>;EndpointSuffix=core.windows.net
Инструменты литейного производства
Встроенное обогащение искусственного интеллекта поддерживается средствами Foundry, включая Язык Azure и Azure Vision для естественного языка и обработки изображений. Для небольших рабочих нагрузок, таких как это руководство, можно использовать бесплатное выделение 20 транзакций на индексатор. Для больших рабочих задач присоедините ресурс Microsoft Foundry к набору навыков для тарифа "Стандартный".
Копирование URL-адреса службы поиска и ключа API
Для выполнения этого руководства потребуется конечная точка и ключ API для подключений к службе "Поиск ИИ Azure". Эти значения можно получить из портал Azure.
Перейдите в службу поиска в портал Azure.
В левой области выберите "Обзор " и скопируйте конечную точку. Он должен быть в следующем формате:
https://my-service.search.windows.netВ левой панели выберите Параметры> и Ключи, затем скопируйте администраторский ключ для полного доступа к службе. Существуют два взаимозаменяемых ключа администратора, предназначенных для обеспечения непрерывности бизнес-процессов на случай, если вам потребуется сменить один из них. Вы можете использовать либо один из ключей для запросов чтобы добавлять, изменять или удалять объекты.
Настройка среды
Начните с открытия Visual Studio и создания проекта консольного приложения.
Установка Azure.Search.Documents
Пакет SDK для поиска ИИ Azure состоит из клиентской библиотеки, которая позволяет управлять индексами, источниками данных, индексаторами и наборами навыков, а также отправлять документы и управлять ими, а также выполнять запросы без необходимости работать с подробными сведениями о HTTP и JSON. Эта клиентская библиотека распространяется как пакет NuGet.
Для этого проекта установите Azure.Search.Documents версии 11 или более поздней и Microsoft.Extensions.Configuration самой поздней версии.
В Visual Studio выберите Сервис>Диспетчер пакетов NuGet>Управление пакетами NuGet для решения...
Найдите Azure.Search.Document.
Выберите последнюю версию и нажмите кнопку "Установить".
Повторите предыдущие шаги для установки Microsoft.Extensions.Configuration и Microsoft.Extensions.Configuration.Json.
Добавьте сведения о подключении службы
Щелкните правой кнопкой мыши по проекту в обозревателе решений и выберите Добавить>Новый элемент....
Присвойте файлу имя
appsettings.jsonи нажмите Добавить.Добавьте файл в каталог выходных данных.
- Щелкните правой кнопкой мыши
appsettings.jsonи выберите пункт Свойства. - Измените значение параметра Копировать в выходной каталог на Копировать только новые.
- Щелкните правой кнопкой мыши
Скопируйте следующий код JSON в новый JSON-файл.
{ "SearchServiceUri": "<YourSearchServiceUri>", "SearchServiceAdminApiKey": "<YourSearchServiceAdminApiKey>", "SearchServiceQueryApiKey": "<YourSearchServiceQueryApiKey>", "AzureAIServicesKey": "<YourMultiRegionAzureAIServicesKey>", "AzureBlobConnectionString": "<YourAzureBlobConnectionString>" }
Укажите службу поиска и добавьте сведения об учетной записи хранения BLOB-объектов. Помните о том, что эти сведения можно получить на этапе предоставления услуг, указанном в предыдущем разделе.
В поле SearchServiceUri введите полный URL-адрес.
Добавить пространства имен
В файле Program.cs добавьте следующие пространства имен.
using Azure;
using Azure.Search.Documents.Indexes;
using Azure.Search.Documents.Indexes.Models;
using Microsoft.Extensions.Configuration;
using System;
using System.Collections.Generic;
using System.Linq;
namespace EnrichwithAI
Создание клиента
Создайте экземпляр класса SearchIndexClient и SearchIndexerClient в разделе Main.
public static void Main(string[] args)
{
// Create service client
IConfigurationBuilder builder = new ConfigurationBuilder().AddJsonFile("appsettings.json");
IConfigurationRoot configuration = builder.Build();
string searchServiceUri = configuration["SearchServiceUri"];
string adminApiKey = configuration["SearchServiceAdminApiKey"];
string azureAiServicesKey = configuration["AzureAIServicesKey"];
SearchIndexClient indexClient = new SearchIndexClient(new Uri(searchServiceUri), new AzureKeyCredential(adminApiKey));
SearchIndexerClient indexerClient = new SearchIndexerClient(new Uri(searchServiceUri), new AzureKeyCredential(adminApiKey));
}
Note
Клиенты подключатся к службе поиска. Чтобы избежать открытия слишком большого количества подключений, попробуйте по возможности предоставить общий доступ к одному экземпляру в приложении. Методы поддерживают такое использование, так как являются потокобезопасными.
Добавление функции для выхода из программы во время сбоя
Этот учебник поможет вам разобраться в каждом этапе работы конвейера индексирования. Если возникает критическая проблема, которая предотвращает создание программы источника данных, набора навыков, индекса или индексатора, программа выводит сообщение об ошибке и завершает работу, чтобы проблема могла быть понята и устранена.
Добавьте ExitProgram в Main, чтобы обработать сценарии, требующие завершения работы программы.
private static void ExitProgram(string message)
{
Console.WriteLine("{0}", message);
Console.WriteLine("Press any key to exit the program...");
Console.ReadKey();
Environment.Exit(0);
}
Создание конвейера
В поиске ИИ Azure обработка ИИ выполняется во время индексирования (или приема данных). В этой части пошагового руководства описано, как создать четыре объекта: источник данных, определение индекса, набор навыков и индексатор.
Шаг 1. Создание источника данных
SearchIndexerClient имеет свойство DataSourceName, которое можно задать для объекта SearchIndexerDataSourceConnection. Этот объект предоставляет все методы, необходимые для создания, перечисления, обновления или удаления источников данных поиска ИИ Azure.
Создайте новый экземпляр SearchIndexerDataSourceConnection, вызвав indexerClient.CreateOrUpdateDataSourceConnection(dataSource). Следующий код создает источник данных типа AzureBlob.
private static SearchIndexerDataSourceConnection CreateOrUpdateDataSource(SearchIndexerClient indexerClient, IConfigurationRoot configuration)
{
SearchIndexerDataSourceConnection dataSource = new SearchIndexerDataSourceConnection(
name: "demodata",
type: SearchIndexerDataSourceType.AzureBlob,
connectionString: configuration["AzureBlobConnectionString"],
container: new SearchIndexerDataContainer("mixed-content-type"))
{
Description = "Demo files to demonstrate Azure AI Search capabilities."
};
// The data source does not need to be deleted if it was already created
// since we are using the CreateOrUpdate method
try
{
indexerClient.CreateOrUpdateDataSourceConnection(dataSource);
}
catch (Exception ex)
{
Console.WriteLine("Failed to create or update the data source\n Exception message: {0}\n", ex.Message);
ExitProgram("Cannot continue without a data source");
}
return dataSource;
}
Для успешного запроса метод возвращает созданный источник данных. При возникновении проблемы с запросом, например недопустимым параметром, метод вызывает исключение.
Теперь добавьте строку в раздел Main, чтобы вызвать только что добавленную функцию CreateOrUpdateDataSource.
// Create or Update the data source
Console.WriteLine("Creating or updating the data source...");
SearchIndexerDataSourceConnection dataSource = CreateOrUpdateDataSource(indexerClient, configuration);
Выполните сборку и запуск решения. Так как это первый запрос, проверьте портал Azure, чтобы убедиться, что источник данных был создан в службе "Поиск ИИ Azure". На странице обзора службы поиска проверьте наличие нового элемента в списке "Источники данных". Возможно, потребуется дождаться нескольких минут, пока страница портал Azure будет обновлена.

Шаг 2. Создание набора навыков
В рамках этого раздела вы определите набор требуемых шагов обогащения данных. Каждый шаг обогащения называется навыком, а набор шагов обогащения — набором навыков. В этом руководстве используются встроенные навыки из набора умений :
Оптическое распознавание символов для распознавания печатного и рукописного текста в файлах изображений.
Слияние текста для объединения текста из коллекции полей в одно поле "объединённое содержимое".
Распознавание языка для определения языка содержимого.
Распознавание сущностей для извлечения названий организаций из содержимого в BLOB-контейнере.
Разделение текста для разбиения объемного содержимого на более мелкие фрагменты перед вызовом навыка извлечения ключевых фраз и навыка распознавания сущностей. Функции извлечения ключевых фраз и распознавания сущностей принимают входные данные объемом не более 50 000 символов. Некоторые примеры файлов следует разделить, чтобы удовлетворить это ограничение.
Извлечение ключевых фраз для получения основных ключевых фраз.
Во время первоначальной обработки поиск Azure AI взломает каждый документ, чтобы извлечь содержимое из разных форматов файлов. Текст из исходного файла помещается в созданное поле content, по одному для каждого документа. Поэтому задайте для входных данных "/document/content", чтобы использовать этот текст. Содержимое изображения помещается в созданное поле normalized_images, указанное в наборе навыков как /document/normalized_images/*.
Выходные данные могут быть сопоставлены с индексом, использоваться в качестве входных данных для последующего навыка или и тем, и другим, как в случае с языковым кодом. В индексе код языка полезен для фильтрации. В качестве входных данных код языка используется навыками анализа текста, чтобы указать лингвистические правила для разбивки слов.
Общие сведения о наборах навыков см. в статье How to create a skillset in an enrichment pipeline (Способ создания набора навыков в конвейере обогащения).
Навык OCR
OcrSkill извлекает текст из изображений. При использовании этого навыка предполагается наличие поля normalized_images. Чтобы создать это поле, позже в руководстве мы задали конфигурацию "imageAction" в определении "generateNormalizedImages" индексатора.
private static OcrSkill CreateOcrSkill()
{
List<InputFieldMappingEntry> inputMappings = new List<InputFieldMappingEntry>();
inputMappings.Add(new InputFieldMappingEntry("image")
{
Source = "/document/normalized_images/*"
});
List<OutputFieldMappingEntry> outputMappings = new List<OutputFieldMappingEntry>();
outputMappings.Add(new OutputFieldMappingEntry("text")
{
TargetName = "text"
});
OcrSkill ocrSkill = new OcrSkill(inputMappings, outputMappings)
{
Description = "Extract text (plain and structured) from image",
Context = "/document/normalized_images/*",
DefaultLanguageCode = OcrSkillLanguage.En,
ShouldDetectOrientation = true
};
return ocrSkill;
}
Навык слияния
В этом разделе вы создаете MergeSkill, который объединяет поле содержимого документа с текстом, созданным навыком OCR.
private static MergeSkill CreateMergeSkill()
{
List<InputFieldMappingEntry> inputMappings = new List<InputFieldMappingEntry>();
inputMappings.Add(new InputFieldMappingEntry("text")
{
Source = "/document/content"
});
inputMappings.Add(new InputFieldMappingEntry("itemsToInsert")
{
Source = "/document/normalized_images/*/text"
});
inputMappings.Add(new InputFieldMappingEntry("offsets")
{
Source = "/document/normalized_images/*/contentOffset"
});
List<OutputFieldMappingEntry> outputMappings = new List<OutputFieldMappingEntry>();
outputMappings.Add(new OutputFieldMappingEntry("mergedText")
{
TargetName = "merged_text"
});
MergeSkill mergeSkill = new MergeSkill(inputMappings, outputMappings)
{
Description = "Create merged_text which includes all the textual representation of each image inserted at the right location in the content field.",
Context = "/document",
InsertPreTag = " ",
InsertPostTag = " "
};
return mergeSkill;
}
Навык распознавания языка
LanguageDetectionSkill определяет язык введенного текста и сообщает один код языка для каждого документа, отправленного по запросу. Мы используем выходные данные навыка распознавания языка в рамках входных данных навыка разделения текста.
private static LanguageDetectionSkill CreateLanguageDetectionSkill()
{
List<InputFieldMappingEntry> inputMappings = new List<InputFieldMappingEntry>();
inputMappings.Add(new InputFieldMappingEntry("text")
{
Source = "/document/merged_text"
});
List<OutputFieldMappingEntry> outputMappings = new List<OutputFieldMappingEntry>();
outputMappings.Add(new OutputFieldMappingEntry("languageCode")
{
TargetName = "languageCode"
});
LanguageDetectionSkill languageDetectionSkill = new LanguageDetectionSkill(inputMappings, outputMappings)
{
Description = "Detect the language used in the document",
Context = "/document"
};
return languageDetectionSkill;
}
Навык разделения текста
Следующее SplitSkill средство разделяет текст по страницам и ограничивает длину страницы до 4000 символов, как измеряется String.Length. Алгоритм пытается разделить текст на блоки, размер которых не превышает maximumPageLength. В этом случае алгоритм делает все возможное, чтобы разорвать предложение на границе предложения, поэтому размер блока может быть немного меньше maximumPageLength.
private static SplitSkill CreateSplitSkill()
{
List<InputFieldMappingEntry> inputMappings = new List<InputFieldMappingEntry>();
inputMappings.Add(new InputFieldMappingEntry("text")
{
Source = "/document/merged_text"
});
inputMappings.Add(new InputFieldMappingEntry("languageCode")
{
Source = "/document/languageCode"
});
List<OutputFieldMappingEntry> outputMappings = new List<OutputFieldMappingEntry>();
outputMappings.Add(new OutputFieldMappingEntry("textItems")
{
TargetName = "pages",
});
SplitSkill splitSkill = new SplitSkill(inputMappings, outputMappings)
{
Description = "Split content into pages",
Context = "/document",
TextSplitMode = TextSplitMode.Pages,
MaximumPageLength = 4000,
DefaultLanguageCode = SplitSkillLanguage.En
};
return splitSkill;
}
Навык распознавания сущностей
Этот экземпляр EntityRecognitionSkill настроен для распознавания типа категории organization.
EntityRecognitionSkill может также распознавать типы категорий person и location.
Обратите внимание, что в поле context задается значение "/document/pages/*" со звездочкой. Это означает, что этап обогащения вызывается для каждой страницы в "/document/pages".
private static EntityRecognitionSkill CreateEntityRecognitionSkill()
{
List<InputFieldMappingEntry> inputMappings = new List<InputFieldMappingEntry>();
inputMappings.Add(new InputFieldMappingEntry("text")
{
Source = "/document/pages/*"
});
List<OutputFieldMappingEntry> outputMappings = new List<OutputFieldMappingEntry>();
outputMappings.Add(new OutputFieldMappingEntry("organizations")
{
TargetName = "organizations"
});
// Specify the V3 version of the EntityRecognitionSkill
var skillVersion = EntityRecognitionSkill.SkillVersion.V3;
var entityRecognitionSkill = new EntityRecognitionSkill(inputMappings, outputMappings, skillVersion)
{
Description = "Recognize organizations",
Context = "/document/pages/*",
DefaultLanguageCode = EntityRecognitionSkillLanguage.En
};
entityRecognitionSkill.Categories.Add(EntityCategory.Organization);
return entityRecognitionSkill;
}
Навык извлечения ключевых фраз
Как и созданный только что экземпляр EntityRecognitionSkill, KeyPhraseExtractionSkill вызывается для каждой страницы документа.
private static KeyPhraseExtractionSkill CreateKeyPhraseExtractionSkill()
{
List<InputFieldMappingEntry> inputMappings = new List<InputFieldMappingEntry>();
inputMappings.Add(new InputFieldMappingEntry("text")
{
Source = "/document/pages/*"
});
inputMappings.Add(new InputFieldMappingEntry("languageCode")
{
Source = "/document/languageCode"
});
List<OutputFieldMappingEntry> outputMappings = new List<OutputFieldMappingEntry>();
outputMappings.Add(new OutputFieldMappingEntry("keyPhrases")
{
TargetName = "keyPhrases"
});
KeyPhraseExtractionSkill keyPhraseExtractionSkill = new KeyPhraseExtractionSkill(inputMappings, outputMappings)
{
Description = "Extract the key phrases",
Context = "/document/pages/*",
DefaultLanguageCode = KeyPhraseExtractionSkillLanguage.En
};
return keyPhraseExtractionSkill;
}
Формировать и развивать навыки
Выполните сборку SearchIndexerSkillset, используя созданные вами навыки.
private static SearchIndexerSkillset CreateOrUpdateDemoSkillSet(SearchIndexerClient indexerClient, IList<SearchIndexerSkill> skills,string azureAiServicesKey)
{
SearchIndexerSkillset skillset = new SearchIndexerSkillset("demoskillset", skills)
{
// Foundry Tools was formerly known as Cognitive Services.
// The APIs still use the old name, so we need to create a CognitiveServicesAccountKey object.
Description = "Demo skillset",
CognitiveServicesAccount = new CognitiveServicesAccountKey(azureAiServicesKey)
};
// Create the skillset in your search service.
// The skillset does not need to be deleted if it was already created
// since we are using the CreateOrUpdate method
try
{
indexerClient.CreateOrUpdateSkillset(skillset);
}
catch (RequestFailedException ex)
{
Console.WriteLine("Failed to create the skillset\n Exception message: {0}\n", ex.Message);
ExitProgram("Cannot continue without a skillset");
}
return skillset;
}
Добавьте в раздел Main следующие строки.
// Create the skills
Console.WriteLine("Creating the skills...");
OcrSkill ocrSkill = CreateOcrSkill();
MergeSkill mergeSkill = CreateMergeSkill();
EntityRecognitionSkill entityRecognitionSkill = CreateEntityRecognitionSkill();
LanguageDetectionSkill languageDetectionSkill = CreateLanguageDetectionSkill();
SplitSkill splitSkill = CreateSplitSkill();
KeyPhraseExtractionSkill keyPhraseExtractionSkill = CreateKeyPhraseExtractionSkill();
// Create the skillset
Console.WriteLine("Creating or updating the skillset...");
List<SearchIndexerSkill> skills = new List<SearchIndexerSkill>();
skills.Add(ocrSkill);
skills.Add(mergeSkill);
skills.Add(languageDetectionSkill);
skills.Add(splitSkill);
skills.Add(entityRecognitionSkill);
skills.Add(keyPhraseExtractionSkill);
SearchIndexerSkillset skillset = CreateOrUpdateDemoSkillSet(indexerClient, skills, azureAiServicesKey);
Шаг 3. Создание индекса
В этом разделе вы определите схему индекса, указав поля для включения в индекс поиска, а также атрибуты поиска для каждого поля. Поля имеют тип и могут принимать атрибуты, определяющие их использование (поиск, сортировка и т. д.). Имена полей в индексе не обязательно совпадают с именами полей в источнике. На следующем этапе вы добавите сопоставления полей в индексаторе, чтобы связать поля "источник — назначение". Для этого шага определите индекс, используя соглашения об именовании полей, относящиеся к вашему поисковому приложению.
В этом упражнении используются следующие поля и типы полей:
| Имена полей | Типы полей |
|---|---|
id |
Edm.String |
content |
Edm.String |
languageCode |
Edm.String |
keyPhrases |
Список<Edm.String> |
organizations |
Список<Edm.String> |
Создание класса DemoIndex
Поля для этого индекса определяются с помощью класса модели. Каждое свойство класса модели имеет атрибуты, которые определяют связанные с поиском характеристики соответствующего поля индекса.
Мы добавим класс модели в новый файл C#. Щелкните проект правой кнопкой мыши и выберите "Добавить>новый элемент", выберите "Класс" и назовите файлDemoIndex.cs, а затем нажмите кнопку "Добавить".
Обязательно укажите, что нужно использовать типы из пространств имен Azure.Search.Documents.Indexes и System.Text.Json.Serialization.
Добавьте следующее определение DemoIndex.cs класса модели и добавьте его в то же пространство имен, где создается индекс.
using Azure.Search.Documents.Indexes;
using System.Text.Json.Serialization;
namespace EnrichwithAI
{
// The SerializePropertyNamesAsCamelCase is currently unsupported as of this writing.
// Replace it with JsonPropertyName
public class DemoIndex
{
[SearchableField(IsSortable = true, IsKey = true)]
[JsonPropertyName("id")]
public string Id { get; set; }
[SearchableField]
[JsonPropertyName("content")]
public string Content { get; set; }
[SearchableField]
[JsonPropertyName("languageCode")]
public string LanguageCode { get; set; }
[SearchableField]
[JsonPropertyName("keyPhrases")]
public string[] KeyPhrases { get; set; }
[SearchableField]
[JsonPropertyName("organizations")]
public string[] Organizations { get; set; }
}
}
Теперь, когда вы определили класс модели, можно легко создать определение индекса в файле Program.cs. У этого индекса будет имя demoindex. Если индекс уже существует с таким именем, он удаляется.
private static SearchIndex CreateDemoIndex(SearchIndexClient indexClient)
{
FieldBuilder builder = new FieldBuilder();
var index = new SearchIndex("demoindex")
{
Fields = builder.Build(typeof(DemoIndex))
};
try
{
indexClient.GetIndex(index.Name);
indexClient.DeleteIndex(index.Name);
}
catch (RequestFailedException ex) when (ex.Status == 404)
{
//if the specified index not exist, 404 will be thrown.
}
try
{
indexClient.CreateIndex(index);
}
catch (RequestFailedException ex)
{
Console.WriteLine("Failed to create the index\n Exception message: {0}\n", ex.Message);
ExitProgram("Cannot continue without an index");
}
return index;
}
Во время тестирования вы можете обнаружить, что вы пытаетесь создать индекс более одного раза. Перед тем как пытаться создать индекс, который вы собираетесь создать, убедитесь, что он уже не существует.
Добавьте в раздел Main следующие строки.
// Create the index
Console.WriteLine("Creating the index...");
SearchIndex demoIndex = CreateDemoIndex(indexClient);
Добавьте следующую директиву using для разрешения уточненной ссылки.
using Index = Azure.Search.Documents.Indexes.Models;
Дополнительные сведения об основных понятиях индекса см. в статье Создание индекса (REST API).
Шаг 4. Создание и запуск индексатора
Пока вы создали источник данных, набор навыков и индекс. Эти три компонента становятся частью индексатора, который объединяет каждую часть в единую многофазную операцию. Чтобы связать их вместе в индексаторе, необходимо определить сопоставления полей.
Обработка FieldMappings выполняется перед набором навыков. Исходные поля из источника данных сопоставляются с целевыми полями в индексе. Если имена и типы полей одинаковы с обоих сторон, сопоставление не требуется.
Обработка OutputFieldMappings выполняется после набора навыков. Добавляются ссылки на элементы sourceFieldNames, которые не существуют, пока они не будут созданы при анализе или обогащении документов. TargetFieldName — это поле в индексе.
Помимо привязки входных данных к выходным данным, вы можете использовать сопоставления полей для преобразования структур данных в плоские структуры. Для получения дополнительных сведений см. раздел Сопоставление обогащенных полей с индексом, поддерживающим поиск.
private static SearchIndexer CreateDemoIndexer(SearchIndexerClient indexerClient, SearchIndexerDataSourceConnection dataSource, SearchIndexerSkillset skillSet, SearchIndex index)
{
IndexingParameters indexingParameters = new IndexingParameters()
{
MaxFailedItems = -1,
MaxFailedItemsPerBatch = -1,
};
indexingParameters.Configuration.Add("dataToExtract", "contentAndMetadata");
indexingParameters.Configuration.Add("imageAction", "generateNormalizedImages");
SearchIndexer indexer = new SearchIndexer("demoindexer", dataSource.Name, index.Name)
{
Description = "Demo Indexer",
SkillsetName = skillSet.Name,
Parameters = indexingParameters
};
FieldMappingFunction mappingFunction = new FieldMappingFunction("base64Encode");
mappingFunction.Parameters.Add("useHttpServerUtilityUrlTokenEncode", true);
indexer.FieldMappings.Add(new FieldMapping("metadata_storage_path")
{
TargetFieldName = "id",
MappingFunction = mappingFunction
});
indexer.FieldMappings.Add(new FieldMapping("content")
{
TargetFieldName = "content"
});
indexer.OutputFieldMappings.Add(new FieldMapping("/document/pages/*/organizations/*")
{
TargetFieldName = "organizations"
});
indexer.OutputFieldMappings.Add(new FieldMapping("/document/pages/*/keyPhrases/*")
{
TargetFieldName = "keyPhrases"
});
indexer.OutputFieldMappings.Add(new FieldMapping("/document/languageCode")
{
TargetFieldName = "languageCode"
});
try
{
indexerClient.GetIndexer(indexer.Name);
indexerClient.DeleteIndexer(indexer.Name);
}
catch (RequestFailedException ex) when (ex.Status == 404)
{
//if the specified indexer not exist, 404 will be thrown.
}
try
{
indexerClient.CreateIndexer(indexer);
}
catch (RequestFailedException ex)
{
Console.WriteLine("Failed to create the indexer\n Exception message: {0}\n", ex.Message);
ExitProgram("Cannot continue without creating an indexer");
}
return indexer;
}
Добавьте в раздел Main следующие строки.
// Create the indexer, map fields, and execute transformations
Console.WriteLine("Creating the indexer and executing the pipeline...");
SearchIndexer demoIndexer = CreateDemoIndexer(indexerClient, dataSource, skillset, demoIndex);
Обработка индексатора займет некоторое время. Несмотря на то что набор данных невелик, аналитические навыки требуют интенсивных вычислений. Некоторые навыки, такие как анализ изображений, являются длительными в выполнении.
Tip
Создание индексатора вызывает конвейер. Если есть проблемы с получением данных, сопоставлением входных и выходных данных или порядком операций, они появятся на этом этапе.
Подробнее о создании индексатора
Код задает "maxFailedItems" значение -1, что указывает подсистеме индексирования игнорировать ошибки во время импорта данных. Это полезно, потому что в демонстрационном источнике данных мало документов. Для большего источника данных необходимо установить значение больше 0.
Также обратите внимание, что для "dataToExtract" задано значение "contentAndMetadata". Этот оператор указывает индексатору автоматически извлекать содержимое из разных форматов файлов, а также метаданные, относящиеся к каждому файлу.
Когда содержимое будет извлечено, вы можете установить imageAction для извлечения текста из изображений, найденных в источнике данных.
"imageAction" с заданной конфигурацией "generateNormalizedImages" вместе с навыком распознавания текста и навыком объединения текста инструктирует индексатор извлекать текст из изображений (например слово "стоп" из знака остановки движения) и вставлять его как часть поля содержимого. Это относится как к изображениям, встроенным в документы (например, изображение внутри PDF-файлов), так и к изображениям, найденным в источнике данных, например к файлу JPG.
Мониторинг индексирования
После определения индексатора он запускается автоматически при отправке запроса. В зависимости от того, какие навыки определены, индексирование может занять больше времени, чем ожидалось. Определить, запущен ли еще индексатор, можно с помощью метода GetStatus.
private static void CheckIndexerOverallStatus(SearchIndexerClient indexerClient, SearchIndexer indexer)
{
try
{
var demoIndexerExecutionInfo = indexerClient.GetIndexerStatus(indexer.Name);
switch (demoIndexerExecutionInfo.Value.Status)
{
case IndexerStatus.Error:
ExitProgram("Indexer has error status. Check the Azure portal to further understand the error.");
break;
case IndexerStatus.Running:
Console.WriteLine("Indexer is running");
break;
case IndexerStatus.Unknown:
Console.WriteLine("Indexer status is unknown");
break;
default:
Console.WriteLine("No indexer information");
break;
}
}
catch (RequestFailedException ex)
{
Console.WriteLine("Failed to get indexer overall status\n Exception message: {0}\n", ex.Message);
}
}
demoIndexerExecutionInfo представляет текущее состояние и журнал выполнения индексатора.
Предупреждения часто встречаются при некоторых комбинациях исходных файлов и навыков и не всегда указывают на проблему. В этом руководстве предупреждения являются неопасными (например, нет текстовых входных данных из файлов JPEG).
Добавьте в раздел Main следующие строки.
// Check indexer overall status
Console.WriteLine("Check the indexer overall status...");
CheckIndexerOverallStatus(indexerClient, demoIndexer);
Search
В консольных приложениях службы поиска ИИ Azure мы обычно добавляем 2-секундную задержку перед выполнением запросов, возвращающих результаты, но так как обогащение занимает несколько минут, мы закроем консольное приложение и используем другой подход.
Самый простой вариант — обозреватель поиска на портале Azure. Сначала можно запустить пустой запрос, возвращающий все документы, или более целевой поиск, который возвращает содержимое нового поля, созданного конвейером.
На портале Azure на страницах службы поиска развернитеуправление поиском>индексы.
Найдите в списке
demoindex. Он должен содержать 14 документов. Если число документов равно нулю, то индексатор либо еще выполняется, либо страница еще не обновилась.Выберите
demoindex. Обозреватель поиска — это первая вкладка.Поиск в содержимом можно начать сразу после загрузки первого документа. Чтобы проверить наличие содержимого, выполните неопределенный запрос, нажав кнопку Поиск. Этот запрос возвращает все текущие проиндексированные документы, и вы получаете представление о том, что содержит индекс.
Чтобы получить более управляемые результаты, перейдите в представление JSON и задайте параметры, чтобы выбрать поля:
{ "search": "*", "count": true, "select": "id, languageCode, organizations" }
Сброс и повторный запуск
На ранних экспериментальных этапах разработки наиболее практичный подход к итерации проектирования заключается в удалении объектов из службы "Поиск ИИ Azure" и позволении вашему коду заново их строить. Имена ресурсов уникальны. Удаление объекта позволяет воссоздать его с использованием того же имени.
Пример кода для этого учебника проверяет имеющиеся объекты и удаляет их, чтобы вы могли повторно выполнить код. Вы также можете использовать портал Azure для удаления индексов, индексаторов, источников данных и наборов навыков.
Takeaways
В этом руководстве описано, как создать расширенный конвейер индексирования путем создания таких компонентов, как источник данных, набор навыков, индекс и индексатор.
Вы получили сведения о встроенных навыках, а также об определении набора навыков и механизме построения цепочек навыков путем сопоставления входных и выходных данных. Вы также узнали, что outputFieldMappings в определении индексатора требуется для маршрутизации обогащенных значений из конвейера в индекс, доступный для поиска в службе ИИ Azure.
Наконец, вы узнали, как тестировать результаты и сбросить систему для дальнейших итераций. Вы узнали, что отправка запросов к индексу возвращает результат, созданный обогащенным конвейером индексирования. Вы также узнали, как проверить состояние индексатора, и какие объекты нужно удалить перед повторным запуском конвейера.
Очистите ресурсы
Если вы работаете в рамках своей подписки, после завершения проекта целесообразно удалить ресурсы, которые вам больше не нужны. Оставленные без присмотра ресурсы могут стоить вам денег. Вы можете удалить ресурсы по отдельности или удалить группу ресурсов, чтобы удалить весь набор ресурсов.
Ресурсы можно найти и управлять ими в портал Azure, используя ссылку "Все ресурсы" или "Группы ресурсов" в области навигации слева.
Дальнейшие шаги
Теперь, когда вы знакомы со всеми объектами в конвейере обогащения с помощью ИИ, давайте более подробно рассмотрим определения набора навыков и отдельные навыки.
Узнайте, как вызывать REST API, создающие платформу обогащения данных ИИ для извлечения контента и его преобразования во время индексирования.
Наборы навыков добавляют обработку ИИ в необработанное содержимое, что делает его более универсальным и доступным для поиска. Когда вы узнаете, как работают наборы навыков, вы можете поддерживать широкий спектр преобразований, от анализа изображений до обработки естественного языка до настраиваемой обработки, которую вы предоставляете внешне.
Изучив это руководство, вы:
- Определите объекты в конвейере обогащения.
- Создание набора навыков. Вызов OCR, распознавание речи, распознавание сущностей и извлечение ключевых фраз.
- Выполните конвейер. Создание и загрузка индекса поиска.
- Проверьте результаты с помощью полнотекстового поиска.
Overview
В этом руководстве используется клиент REST и REST API поиска Azure AI для создания источника данных, индекса, индексатора и набора навыков.
Индексатор управляет каждым шагом в конвейере, начиная с извлечения содержимого образцов данных (неструктурированный текст и изображения) в контейнере blob на службе хранения Azure.
После извлечения содержимого набор навыков выполняет встроенные навыки от Корпорации Майкрософт для поиска и извлечения информации. Эти навыки включают оптическое распознавание символов (OCR) на изображениях, распознавание языка на тексте, извлечении ключевых фраз и распознавании сущностей (организации). Новая информация, созданная набором навыков, отправляется в поля в индексе. После заполнения индекса можно использовать поля в запросах, аспектах и фильтрах.
Prerequisites
Учетная запись Azure с активной подпиской. Создайте учетную запись бесплатно .
Visual Studio Code с клиентом REST
Note
Вы можете использовать бесплатную службу поиска для этого руководства. Уровень "Бесплатный" ограничивается тремя индексами, тремя индексаторами и тремя источниками данных. В этом руководстве создается по одному объекту из каждой категории. Перед началом работы убедитесь, что у вас есть место в службе, чтобы принять новые ресурсы.
Загрузка файлов
Скачайте ZIP-файл примера репозитория данных и извлеките его содержимое. Инструкции.
Загрузка образцов данных в службу хранилища Azure
В хранилище Azure создайте новый контейнер и назовите его cog-search-demo.
Отправьте примеры файлов данных.
Получите строку подключения хранилища, чтобы настроить подключение в службе Поиск с использованием ИИ Azure.
В левой части экрана выберите ключи доступа.
Скопируйте строку подключения для первого или второго ключа. Строка подключения аналогична следующему примеру:
DefaultEndpointsProtocol=https;AccountName=<your account name>;AccountKey=<your account key>;EndpointSuffix=core.windows.net
Инструменты литейного производства
Встроенное обогащение искусственного интеллекта поддерживается средствами Foundry, включая Язык Azure и Azure Vision для естественного языка и обработки изображений. Для небольших рабочих нагрузок, таких как в этом руководстве, можно использовать бесплатное выделение двадцати транзакций на индексатор. Для больших рабочих задач присоедините ресурс Microsoft Foundry к набору навыков для тарифа "Стандартный".
Копирование URL-адреса службы поиска и ключа API
Для выполнения этого руководства потребуется конечная точка и ключ API для подключений к службе "Поиск ИИ Azure". Эти значения можно получить из портал Azure.
Перейдите в службу поиска в портал Azure.
В левой области выберите "Обзор " и скопируйте конечную точку. Он должен быть в следующем формате:
https://my-service.search.windows.netВ левой панели выберите Параметры> и Ключи, затем скопируйте администраторский ключ для полного доступа к службе. Существуют два взаимозаменяемых ключа администратора, предназначенных для обеспечения непрерывности бизнес-процессов на случай, если вам потребуется сменить один из них. Вы можете использовать либо один из ключей для запросов чтобы добавлять, изменять или удалять объекты.
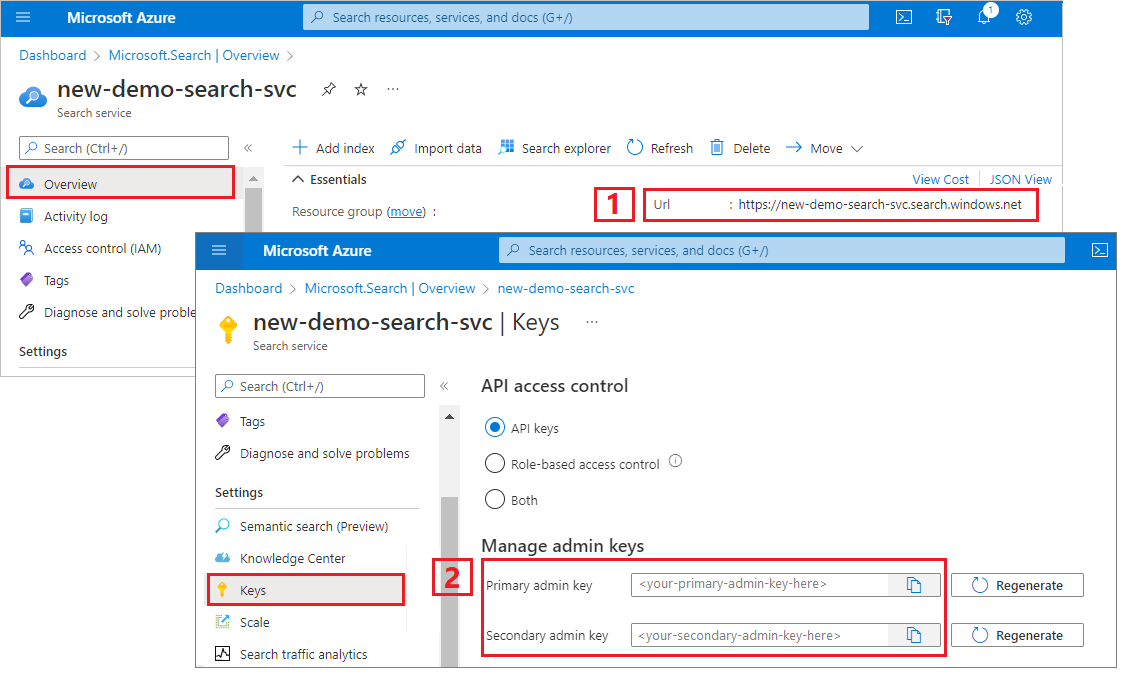
Настройка REST-файла
Запустите Visual Studio Code и откройте файл skillset-tutorial.rest . См. краткое руководство. Полнотекстовый поиск , если вам нужна помощь с клиентом REST.
Укажите значения для переменных: конечная точка службы поиска, ключ API администратора службы поиска, имя индекса, строка подключения к вашей учетной записи хранилища Azure и имя контейнера BLOB-объектов.
Создание конвейера
Обогащение ИИ зависит от индексатора. В этой части пошагового руководства описано, как создать четыре объекта: источник данных, определение индекса, набор навыков и индексатор.
Шаг 1. Создание источника данных
Вызовите Создать источник данных, чтобы задать строку подключения к контейнеру Blob, содержащему примеры файлов данных.
### Create a data source
POST {{baseUrl}}/datasources?api-version=2025-09-01 HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"name": "cog-search-demo-ds",
"description": null,
"type": "azureblob",
"subtype": null,
"credentials": {
"connectionString": "{{storageConnectionString}}"
},
"container": {
"name": "{{blobContainer}}",
"query": null
},
"dataChangeDetectionPolicy": null,
"dataDeletionDetectionPolicy": null
}
Шаг 2. Создание набора навыков
Вызовите Создать набор навыков, чтобы указать, какие шаги обогащения применяются к вашему контенту. Навыки выполняются параллельно, если не существует зависимости.
### Create a skillset
POST {{baseUrl}}/skillsets?api-version=2025-09-01 HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"name": "cog-search-demo-ss",
"description": "Apply OCR, detect language, extract entities, and extract key-phrases.",
"cognitiveServices": null,
"skills":
[
{
"@odata.type": "#Microsoft.Skills.Vision.OcrSkill",
"context": "/document/normalized_images/*",
"defaultLanguageCode": "en",
"detectOrientation": true,
"inputs": [
{
"name": "image",
"source": "/document/normalized_images/*"
}
],
"outputs": [
{
"name": "text"
}
]
},
{
"@odata.type": "#Microsoft.Skills.Text.MergeSkill",
"description": "Create merged_text, which includes all the textual representation of each image inserted at the right location in the content field. This is useful for PDF and other file formats that supported embedded images.",
"context": "/document",
"insertPreTag": " ",
"insertPostTag": " ",
"inputs": [
{
"name":"text",
"source": "/document/content"
},
{
"name": "itemsToInsert",
"source": "/document/normalized_images/*/text"
},
{
"name":"offsets",
"source": "/document/normalized_images/*/contentOffset"
}
],
"outputs": [
{
"name": "mergedText",
"targetName" : "merged_text"
}
]
},
{
"@odata.type": "#Microsoft.Skills.Text.SplitSkill",
"textSplitMode": "pages",
"maximumPageLength": 4000,
"defaultLanguageCode": "en",
"context": "/document",
"inputs": [
{
"name": "text",
"source": "/document/merged_text"
}
],
"outputs": [
{
"name": "textItems",
"targetName": "pages"
}
]
},
{
"@odata.type": "#Microsoft.Skills.Text.LanguageDetectionSkill",
"description": "If you have multilingual content, adding a language code is useful for filtering",
"context": "/document",
"inputs": [
{
"name": "text",
"source": "/document/merged_text"
}
],
"outputs": [
{
"name": "languageName",
"targetName": "language"
}
]
},
{
"@odata.type": "#Microsoft.Skills.Text.KeyPhraseExtractionSkill",
"context": "/document/pages/*",
"inputs": [
{
"name": "text",
"source": "/document/pages/*"
}
],
"outputs": [
{
"name": "keyPhrases",
"targetName": "keyPhrases"
}
]
},
{
"@odata.type": "#Microsoft.Skills.Text.V3.EntityRecognitionSkill",
"categories": ["Organization"],
"context": "/document",
"inputs": [
{
"name": "text",
"source": "/document/merged_text"
}
],
"outputs": [
{
"name": "organizations",
"targetName": "organizations"
}
]
},
{
"@odata.type": "#Microsoft.Skills.Text.V3.EntityRecognitionSkill",
"categories": ["Location"],
"context": "/document",
"inputs": [
{
"name": "text",
"source": "/document/merged_text"
}
],
"outputs": [
{
"name": "locations",
"targetName": "locations"
}
]
},
{
"@odata.type": "#Microsoft.Skills.Text.V3.EntityRecognitionSkill",
"categories": ["Person"],
"context": "/document",
"inputs": [
{
"name": "text",
"source": "/document/merged_text"
}
],
"outputs": [
{
"name": "persons",
"targetName": "persons"
}
]
}
]
}
Ключевые моменты:
Текст запроса задает следующие встроенные навыки:
Skill Description Оптическое распознавание символов Распознает текст и числа в файлах изображений. Слияние текста Создает объединенное содержимое, которое повторно объединяет ранее разделенное содержимое, полезное для документов с внедренными изображениями (PDF, DOCX и т. д.). Изображения и текст отделяются во время этапа взлома документа. Навык слияния объединяет их, вставляя любой распознанный текст, подписи к изображениям или теги, созданные в процессе обогащения, на том же месте, где изображение было извлечено из документа. При работе с объединенным содержимым в наборе навыков этот узел включает весь текст в документе, включая текстовые документы, которые никогда не проходят анализ OCR или изображений. Распознавание языка. Обнаруживает язык и выводит имя языка или код. В многоязычных наборах данных поле языка может быть полезно для фильтров. Распознавание сущностей Извлекает имена людей, организаций и расположений из объединенного содержимого. Разделение текста Разбивает большое объединенное содержимое на небольшие блоки перед вызовом функции извлечения ключевых фраз. Этот метод выделения ключевых фраз принимает входные данные, состоящие из 50 000 символов или меньше. Некоторые примеры файлов следует разделить, чтобы удовлетворить это ограничение. Извлечение ключевых фраз. Извлекает ключевые фразы, которые встречаются чаще всего. Каждый навык работает с содержимым документа. Во время обработки поиск Azure AI взломает каждый документ для чтения содержимого из разных форматов файлов. Найденный текст в исходном файле помещается в созданное поле
content, по одному для каждого документа. Входные данные принимают следующий вид:"/document/content".Мы используем навык разделения текста для разбиения больших файлов на страницы, поэтому контекстом для навыка извлечения ключевых фраз будет
"document/pages/*"(для каждой страницы в документе), а не"/document/content".
Note
Выходные данные могут быть сопоставлены с индексом, использоваться в качестве входных данных для последующего навыка или и тем, и другим, как в случае с языковым кодом. В индексе код языка полезен для фильтрации. Общие сведения о наборах навыков см. в статье How to create a skillset in an enrichment pipeline (Способ создания набора навыков в конвейере обогащения).
Шаг 3. Создание индекса
Вызовите функцию Create Index для предоставления схемы, используемой для создания инвертированных индексов и других конструкций в службе "Поиск ИИ Azure".
Самым большим компонентом индекса является коллекция полей, где тип данных и атрибуты определяют содержимое и поведение в поиске ИИ Azure. Убедитесь, что у вас есть поля для недавно созданных выходных данных.
### Create an index
POST {{baseUrl}}/indexes?api-version=2025-09-01 HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"name": "cog-search-demo-idx",
"defaultScoringProfile": "",
"fields": [
{
"name": "content",
"type": "Edm.String",
"searchable": true,
"sortable": false,
"filterable": false,
"facetable": false
},
{
"name": "text",
"type": "Collection(Edm.String)",
"facetable": false,
"filterable": true,
"searchable": true,
"sortable": false
},
{
"name": "language",
"type": "Edm.String",
"searchable": false,
"sortable": true,
"filterable": true,
"facetable": false
},
{
"name": "keyPhrases",
"type": "Collection(Edm.String)",
"searchable": true,
"sortable": false,
"filterable": true,
"facetable": true
},
{
"name": "organizations",
"type": "Collection(Edm.String)",
"searchable": true,
"sortable": false,
"filterable": true,
"facetable": true
},
{
"name": "persons",
"type": "Collection(Edm.String)",
"searchable": true,
"sortable": false,
"filterable": true,
"facetable": true
},
{
"name": "locations",
"type": "Collection(Edm.String)",
"searchable": true,
"sortable": false,
"filterable": true,
"facetable": true
},
{
"name": "metadata_storage_path",
"type": "Edm.String",
"key": true,
"searchable": true,
"sortable": false,
"filterable": false,
"facetable": false
},
{
"name": "metadata_storage_name",
"type": "Edm.String",
"searchable": true,
"sortable": false,
"filterable": false,
"facetable": false
}
]
}
Шаг 4. Создание и запуск индексатора
Вызовите функцию Create Indexer, чтобы управлять конвейером. Три компонента, которые вы создали ранее (источник данных, набор навыков и индекс) предоставляют входные данные для индексатора. Создание индексатора в службе "Поиск ИИ Azure" — это событие, которое помещает весь конвейер в движение.
Выполнение этого действия может занять несколько минут. Несмотря на то что набор данных невелик, аналитические навыки требуют интенсивных вычислений.
### Create and run an indexer
POST {{baseUrl}}/indexers?api-version=2025-09-01 HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"name": "cog-search-demo-idxr",
"description": "",
"dataSourceName" : "cog-search-demo-ds",
"targetIndexName" : "cog-search-demo-idx",
"skillsetName" : "cog-search-demo-ss",
"fieldMappings" : [
{
"sourceFieldName" : "metadata_storage_path",
"targetFieldName" : "metadata_storage_path",
"mappingFunction" : { "name" : "base64Encode" }
},
{
"sourceFieldName": "metadata_storage_name",
"targetFieldName": "metadata_storage_name"
}
],
"outputFieldMappings" :
[
{
"sourceFieldName": "/document/merged_text",
"targetFieldName": "content"
},
{
"sourceFieldName" : "/document/normalized_images/*/text",
"targetFieldName" : "text"
},
{
"sourceFieldName" : "/document/organizations",
"targetFieldName" : "organizations"
},
{
"sourceFieldName": "/document/language",
"targetFieldName": "language"
},
{
"sourceFieldName" : "/document/persons",
"targetFieldName" : "persons"
},
{
"sourceFieldName" : "/document/locations",
"targetFieldName" : "locations"
},
{
"sourceFieldName" : "/document/pages/*/keyPhrases/*",
"targetFieldName" : "keyPhrases"
}
],
"parameters":
{
"batchSize": 1,
"maxFailedItems":-1,
"maxFailedItemsPerBatch":-1,
"configuration":
{
"dataToExtract": "contentAndMetadata",
"imageAction": "generateNormalizedImages"
}
}
}
Ключевые моменты:
Текст запроса содержит ссылки на предыдущие объекты, свойства конфигурации, необходимые для обработки изображений, и два типа сопоставлений полей.
"fieldMappings"обрабатываются перед набором навыков, отправляя содержимое из источника данных в целевые поля в индексе. Сопоставления полей используются для отправки существующего немодифицированного содержимого в индекс. Если имена и типы полей одинаковы с обоих сторон, сопоставление не требуется."outputFieldMappings"предназначены для полей, созданных с помощью навыков, после выполнения набора навыков. Ссылки наsourceFieldNameвoutputFieldMappingsне существуют до того момента, пока не будут созданы в процессе распознавания или обогащения документа.targetFieldNameобозначает поле в индексе, определенное в схеме индекса.Параметр
"maxFailedItems"имеет значение -1, что указывает подсистеме индексирования игнорировать ошибки во время импорта данных. Это допустимо, так как в демонстрационном источнике данных мало документов. Для большего источника данных необходимо установить значение больше 0.Инструкция
"dataToExtract":"contentAndMetadata"сообщает индексатору автоматически извлекать значения из свойства содержимого большого двоичного объекта и метаданных каждого объекта.Параметр
imageActionсообщает индексатору извлекать текст из изображений, найденных в источнике данных. Конфигурация"imageAction":"generateNormalizedImages"вместе с навыком распознавания текста и навыком объединения текста инструктирует индексатор извлекать текст из изображений (например слово "стоп" из знака остановки движения) и вставлять его как часть поля содержимого. Это поведение применяется как к внедренным изображениям (подумайте о изображении внутри PDF-файла), так и к автономным файлам изображений, например к ФАЙЛу JPG.
Note
Создание индексатора вызывает конвейер. Если есть проблемы с получением данных, сопоставлением входных и выходных данных или порядком операций, они появятся на этом этапе. Чтобы повторно запустить конвейер с изменениями кода или скрипта, вам может потребоваться сначала удалить объекты. Для получения дополнительной информации см. Сброс и повторный запуск.
Мониторинг индексирования
Индексирование и обогащение начинаются сразу же после отправки запроса на создание индексатора. В зависимости от сложности набора навыков и операций индексирование может занять некоторое время.
Чтобы узнать, работает ли индексатор, вызовите состояние индексатора, чтобы проверить состояние индексатора.
### Get Indexer Status (wait several minutes for the indexer to complete)
GET {{baseUrl}}/indexers/cog-search-demo-idxr/status?api-version=2025-09-01 HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
Ключевые моменты:
Предупреждения распространены в некоторых сценариях и не всегда указывают на проблему. Например, если контейнер блобов содержит файлы изображений, а конвейер не обрабатывает изображения, вы получите предупреждение, что изображения не были обработаны.
В этом примере PNG-файл не содержит текста. Все пять навыков на основе текста (распознавание речи, распознавание сущностей расположений, организаций, людей и извлечение ключевых фраз) не выполняются в этом файле. Полученное уведомление отображается в журнале выполнения.
Проверка результатов
Теперь, когда вы создали индекс, содержащий содержимое, созданное СИ, вызовите поиск документов для выполнения некоторых запросов, чтобы просмотреть результаты.
### Query the index\
POST {{baseUrl}}/indexes/cog-search-demo-idx/docs/search?api-version=2025-09-01 HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"search": "*",
"select": "metadata_storage_name,language,organizations",
"count": true
}
Фильтры помогают сузить результаты до интересующих элементов:
### Filter by organization
POST {{baseUrl}}/indexes/cog-search-demo-idx/docs/search?api-version=2025-09-01 HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"search": "*",
"filter": "organizations/any(organizations: organizations eq 'Microsoft')",
"select": "metadata_storage_name,organizations",
"count": true
}
Эти запросы иллюстрируют несколько способов работы с синтаксисом запросов и фильтрами в новых полях, созданных поиском ИИ Azure. Дополнительные примеры запросов см. в разделах с примерами для REST API поиска документов, запросов с простым синтаксисом и запросов full Lucene.
Сброс и повторный запуск
На ранних этапах разработки итерация по проектированию распространена. Сброс и повторное выполнение помогает выполнить итерацию.
Takeaways
В этом руководстве показано, как использовать REST API для создания конвейера обогащения ИИ: источника данных, набора навыков, индекса и индексатора.
Были представлены встроенные навыки, а также определение набора навыков, которое показывает механику цепочки навыков через входы и выходы. Вы также узнали, что outputFieldMappings в определении индексатора требуется для маршрутизации обогащенных значений из конвейера в индекс, доступный для поиска в службе ИИ Azure.
Наконец, вы узнали, как тестировать результаты и сбросить систему для дальнейших итераций. Вы узнали, что отправка запросов к индексу возвращает результат, созданный обогащенным конвейером индексирования.
Очистите ресурсы
Если вы работаете в рамках своей подписки, после завершения проекта целесообразно удалить ресурсы, которые вам больше не нужны. Оставленные без присмотра ресурсы могут стоить вам денег. Вы можете удалить ресурсы по отдельности или удалить группу ресурсов, чтобы удалить весь набор ресурсов.
Ресурсы можно найти и управлять ими в портал Azure, используя ссылку "Все ресурсы" или "Группы ресурсов" в области навигации слева.
Дальнейшие шаги
Теперь, когда вы знакомы со всеми объектами в конвейере обогащения ИИ, ознакомьтесь с определениями набора навыков и отдельными навыками.