Примечание.
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
Это содержимое относится к:![]() версии 4.0 (GA) | Предыдущие версии:
версии 4.0 (GA) | Предыдущие версии:![]() версии 3.1 (GA)
версии 3.1 (GA)![]() версии 3.0 (вывод из эксплуатации)
версии 3.0 (вывод из эксплуатации)![]() версии 2.1 (вывод из эксплуатации)
версии 2.1 (вывод из эксплуатации)
Это содержимое относится к:![]() версии 3.1 (GA) | Последняя версия:
версии 3.1 (GA) | Последняя версия:![]() версии 4.0 (GA) | Предыдущие версии:
версии 4.0 (GA) | Предыдущие версии:![]() версии 3.0
версии 3.0![]() версии 2.1
версии 2.1
Это содержимое относится к:![]() версия 2.1 | Последняя версия:
версия 2.1 | Последняя версия:![]() версия 4.0 (GA)
версия 4.0 (GA)
Azure Аналитика документов в средстве Foundry поддерживает различные модели, которые можно использовать для добавления интеллектуальной обработки документов в приложения и потоки. Вы можете использовать предварительно созданную модель для конкретного домена или обучить пользовательскую модель, адаптированную к конкретным бизнес-потребностям и вариантам использования. Интеллектуальный анализ документов можно использовать с помощью REST API или клиентских библиотек для Python, C#, Java и JavaScript.
Примечание
Проекты обработки документов, включающие финансовые данные, защищенные данные о работоспособности, персональные данные или высокочувствительные данные, требуют тщательного внимания. Обязательно соблюдайте все национальные или региональные и отраслевые требования.
Общие сведения о модели
В следующей таблице показаны общедоступные модели для каждого стабильного API.
| Тип модели | Модель | 2024-11-30 (GA) | 2023-07-31 (GA) | 2022-08-31 (GA) | v2.1 (GA) |
|---|---|---|---|---|---|
| Модели анализа документов | Прочитать | ✔️ | ✔️ | ✔️ | Недоступно |
| Модели анализа документов | Макет | ✔️ | ✔️ | ✔️ | ✔️ |
| Модели анализа документов | Общий документ** | Поддерживается в Модель макета |
✔️ | ✔️ | Недоступно |
| Предварительно созданные модели | Банковский контроль | ✔️ | Недоступно | Недоступно | Недоступно |
| Предварительно созданные модели | Банковская выписка | ✔️ | Недоступно | Недоступно | Недоступно |
| Предварительно созданные модели | payStub | ✔️ | Недоступно | Недоступно | Недоступно |
| Предварительно созданные модели | Контракт | ✔️ | ✔️ | Недоступно | Недоступно |
| Предварительно созданные модели | Карточка медицинского страхования | ✔️ | ✔️ | ✔️ | Недоступно |
| Предварительно созданные модели | Удостоверение личности | ✔️ | ✔️ | ✔️ | ✔️ |
| Предварительно созданные модели | Счет | ✔️ | ✔️ | ✔️ | ✔️ |
| Предварительно созданные модели | Получения | ✔️ | ✔️ | ✔️ | ✔️ |
| Предварительно созданные модели | Унифицированный налог США* | ✔️ | Недоступно | Недоступно | Недоступно |
| Предварительно созданные модели | Налог США 1040* | ✔️ | ✔️ | Недоступно | Недоступно |
| Предварительно созданные модели | Налог США 1095* | ✔️ | Недоступно | Недоступно | Недоступно |
| Предварительно созданные модели | Налог США 1098* | ✔️ | Недоступно | Недоступно | Недоступно |
| Предварительно созданные модели | Налог США 1099* | ✔️ | Недоступно | Недоступно | Недоступно |
| Предварительно созданные модели | Налог W2 США | ✔️ | ✔️ | ✔️ | Недоступно |
| Предварительно созданные модели | Налог сша W4 | ✔️ | Недоступно | Недоступно | Недоступно |
| Предварительно созданные модели | США ипотека 1003 URLA | ✔️ | Недоступно | Недоступно | Недоступно |
| Предварительно созданные модели | Американская ипотека 1004 URAR | ✔️ | Недоступно | Недоступно | Недоступно |
| Предварительно созданные модели | Ипотека США 1005 | ✔️ | Недоступно | Недоступно | Недоступно |
| Предварительно созданные модели | Сводка по ипотеке США 1008 | ✔️ | Недоступно | Недоступно | Недоступно |
| Предварительно созданные модели | Раскрытие информации о закрытии ипотеки США | ✔️ | Недоступно | Недоступно | Недоступно |
| Предварительно созданные модели | Свидетельство о браке | ✔️ | Недоступно | Недоступно | Недоступно |
| Предварительно созданные модели | Кредитная карта | ✔️ | Недоступно | Недоступно | Недоступно |
| Предварительно созданные модели | Визитная карточка | Устаревший | ✔️ | ✔️ | ✔️ |
| Пользовательская модель классификации | Настраиваемый классификатор | ✔️ | ✔️ | Недоступно | Недоступно |
| Пользовательская модель извлечения | Настраиваемая нейронная сеть | ✔️ | ✔️ | ✔️ | Недоступно |
| Пользовательская модель извлечения | Пользовательский шаблон | ✔️ | ✔️ | ✔️ | ✔️ |
| Пользовательская модель извлечения | Пользовательская сборка | ✔️ | ✔️ | ✔️ | ✔️ |
| Все модели | Возможности надстройки | ✔️ | ✔️ | Недоступно | Недоступно |
* Содержит подмодели. Сведения о поддерживаемых вариантах и подтипах см. в сведениях о модели.
** Все возможности для общей модели документов доступны в модели макета. Общая модель больше не поддерживается.
Задержки
Задержка — это время, необходимое для обработки и обработки входящего запроса сервера API и доставки исходящего ответа клиенту. Время анализа документа зависит от размера (например, количества страниц) и связанного содержимого на каждой странице. Аналитика документов — это мультитенантная асинхронная служба, в которой задержка для аналогичных документов сравнима, но не всегда идентична. Иногда вариативность задержки и производительности связана с любой микрослужбой, без отслеживания состояния, которая обрабатывает изображения и большие документы в большом масштабе. Несмотря на то, что мы постоянно масштабируем оборудование и емкость и возможности масштабирования, могут возникнуть проблемы с задержкой во время выполнения.
Возможность дополнения
Для аналитики документов доступны следующие возможности надстройки. Для всех моделей, кроме модели визитной карточки, аналитика документов теперь поддерживает возможности надстроек, чтобы обеспечить более сложный анализ. Эти необязательные возможности можно включить и отключить в зависимости от сценария извлечения документов. Для версии API 2023-07-31 (GA) и более поздних версий API доступны следующие возможности надстройки:
ocrHighResolutionformulasstyleFontbarcodeslanguageskeyValuePairs-
queryFields(недоступно для налоговых моделей США) -
searchablePDF(доступно только для модели чтения)
| Возможность дополнения | Бесплатное дополнение | 2024-11-30 (GA) | 2023-07-31 (GA) | 2022-08-31 (GA) | v2.1 (GA) |
|---|---|---|---|---|---|
| Извлечение свойств шрифта | дополнение | ✔️ | ✔️ | Недоступно | Недоступно |
| Извлечение формул | Плагин | ✔️ | ✔️ | Недоступно | Недоступно |
| Извлечение высокого разрешения | Дополнение | ✔️ | ✔️ | Недоступно | Недоступно |
| Извлечение штрихкодов | Бесплатный | ✔️ | ✔️ | Недоступно | Недоступно |
| Обнаружение языка | Бесплатный | ✔️ | ✔️ | Недоступно | Недоступно |
| Пары «ключ-значение» | Бесплатный | ✔️ | Недоступно | Недоступно | Недоступно |
| Поля запроса | дополнение* | ✔️ | Недоступно | Недоступно | Недоступно |
| Pdf-файл, доступный для поиска | Надстройка* | ✔️ | Недоступно | Недоступно | Недоступно |
Функции анализа моделей
| Идентификатор модели | Извлечение содержимого | Поля запроса | Параграфы | Роли абзаца | Метки выделения | Таблицы | Пары "Ключ-значение" | Языки | Штрихкоды | Анализ документов | Формулы* | Шрифт стиля* | Высокое разрешение* | Pdf-файл, доступный для поиска |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
prebuilt-read |
✓ | ✓ | O | O | O | O | O | O | ||||||
prebuilt-layout |
✓ | ✓ | ✓ | ✓ | ✓ | ✓ | O | O | O | O | O | O | ||
prebuilt-contract |
✓ | ✓ | ✓ | ✓ | ✓ | O | O | ✓ | O | O | ||||
prebuilt-healthInsuranceCard.us |
✓ | ✓ | O | O | ✓ | O | O | O | ||||||
prebuilt-idDocument |
✓ | ✓ | O | O | ✓ | O | O | O | ||||||
prebuilt-invoice |
✓ | ✓ | ✓ | ✓ | O | O | O | ✓ | O | O | O | |||
prebuilt-receipt |
✓ | ✓ | O | O | ✓ | O | O | O | ||||||
prebuilt-marriageCertificate.us |
✓ | ✓ | ✓ | O | O | ✓ | O | O | O | |||||
prebuilt-creditCard |
✓ | ✓ | O | O | ✓ | O | O | O | ||||||
prebuilt-check.us |
✓ | ✓ | O | O | ✓ | O | O | O | ||||||
prebuilt-payStub.us |
✓ | ✓ | O | O | ✓ | O | O | O | ||||||
prebuilt-bankStatement |
✓ | ✓ | O | O | ✓ | O | O | O | ||||||
prebuilt-mortgage.us.1003 |
✓ | ✓ | ✓ | O | O | ✓ | O | O | O | |||||
prebuilt-mortgage.us.1004 |
✓ | ✓ | ✓ | O | O | ✓ | O | O | O | |||||
prebuilt-mortgage.us.1005 |
✓ | ✓ | ✓ | O | O | ✓ | O | O | O | |||||
prebuilt-mortgage.us.1008 |
✓ | ✓ | ✓ | O | O | ✓ | O | O | O | |||||
prebuilt-mortgage.us.closingDisclosure |
✓ | ✓ | ✓ | O | O | ✓ | O | O | O | |||||
prebuilt-tax.us |
✓ | ✓ | ✓ | O | O | ✓ | O | O | O | |||||
prebuilt-tax.us.w2 |
✓ | ✓ | ✓ | O | O | ✓ | O | O | O | |||||
prebuilt-tax.us.w4 |
✓ | ✓ | O | O | ✓ | O | O | O | ||||||
prebuilt-tax.us.1040 (различные) |
✓ | ✓ | ✓ | O | O | ✓ | O | O | O | |||||
prebuilt-tax.us.1095A |
✓ | ✓ | O | O | ✓ | O | O | O | ||||||
prebuilt-tax.us.1095C |
✓ | ✓ | O | O | ✓ | O | O | O | ||||||
prebuilt-tax.us.1098 |
✓ | ✓ | ✓ | O | O | ✓ | O | O | O | |||||
prebuilt-tax.us.1098E |
✓ | ✓ | ✓ | O | O | ✓ | O | O | O | |||||
prebuilt-tax.us.1098T |
✓ | ✓ | ✓ | O | O | ✓ | O | O | O | |||||
prebuilt-tax.us.1099 (различные) |
✓ | ✓ | ✓ | O | O | ✓ | O | O | O | |||||
prebuilt-tax.us.1099SSA |
✓ | ✓ | O | O | ✓ | O | O | O | ||||||
{ customModelName } |
✓ | ✓ | ✓ | ✓ | ✓ | ✓ | O | O | ✓ | O | O | O |
✓ - Включен O - Необязательный
* - Премиум функции влечет за собой дополнительные расходы
Поля запросов ценятся по-другому, чем другие функции надстройки. Дополнительные сведения см. в разделе "Цены".
Координаты ограничивающего прямоугольника и многоугольника
Ограничивающий прямоугольник (polygon в версиях 3.0 и более поздних версиях) — это абстрактный прямоугольник, который окружает текстовые элементы в документе. Ограничивающая рамка используется для ориентира при обнаружении объектов.
- Ограничивающий прямоугольник указывает позицию с помощью плоскости координат x и y, представленной в массиве из четырех числовых пар. Каждая пара представляет угол поля в следующем порядке: верхний левый, верхний правый, нижний правый, нижний левый.
- Координаты изображения представлены в пикселях. Для PDF координаты представлены в дюймах.
Поддержка языка
Универсальные модели в Аналитике документов, основанные на глубоком обучении, поддерживают многие языки. Модели могут извлекать многоязычный текст из изображений и документов, включая текстовые строки с смешанными языками. Поддержка языка зависит от функциональных возможностей службы аналитики документов. Полный список см. в следующих статьях:
- Поддержка языка: модели анализа документов
- Поддержка языка: предварительно созданные модели
- Поддержка языка: пользовательские модели
Региональная доступность
Аналитика документов широко доступна во многих из 60+ глобальных инфраструктурных регионов Azure.
Чтобы помочь выбрать регион, который лучше всего подходит для вас и ваших клиентов, см. Azure географии.
Сведения о модели
В этом разделе описываются выходные данные, которые можно ожидать от каждой модели. Вы можете расширить выходные данные большинства моделей с помощью функций надстройки.
Чтение OCR

API чтения использует оптическое распознавание символов (OCR) для анализа и извлечения строк и слов, их расположений, обнаруженных языков и стиля рукописного ввода при обнаружении.
Этот пример документа был обработан с помощью Document Intelligence Studio.

Анализ макета

Модель анализа макета анализирует и извлекает текст, таблицы, знаки выделения и другие элементы структуры, такие как заголовки, заголовки разделов, заголовки страниц и нижние колонтитулы страницы.
Этот пример документа был обработан с помощью Document Intelligence Studio.

Карточка медицинского страхования
![]()
Модель карты медицинского страхования объединяет мощные возможности OCR с моделями глубокого обучения для анализа и извлечения ключевых сведений из карт медицинского страхования США.
Этот пример карты медицинского страхования США был обработан с помощью Document Intelligence Studio.

Налоговые документы США

Модели налоговых документов США анализируют и извлекают ключевые поля и элементы строки из выбранной группы налоговых документов. API поддерживает анализ налоговых документов США на английском языке различных форматов и качества, включая захваченные телефоном изображения, сканированные документы и цифровые PDF-файлы. В настоящее время поддерживаются следующие модели:
| Модель | Описание | Идентификатор модели |
|---|---|---|
| Форма W-2 для налогов США | Извлечение сведений о налогооблагаемой компенсации. | prebuilt-tax.us.w2 |
| Форма W-4 для налогообложения США | Извлечение сведений о налогооблагаемой компенсации. | prebuilt-tax.us.w4 |
| Налог США 1040 | Извлечение сведений о проценте по ипотеке. |
prebuilt-tax.us.1040 (варианты) |
| Налог США 1095 | Извлеките сведения о медицинском страховании. |
prebuilt-tax.us.1095 (варианты) |
| Налог США 1098 | Извлечение сведений о процентах по ипотеке. |
prebuilt-tax.us.1098 (варианты) |
| Налог США 1099 | Извлечение дохода, полученного из источников, отличных от работодателя. |
prebuilt-tax.us.1099 (варианты) |
Этот пример документа W-2 был обработан с помощью Document Intelligence Studio.

Ипотечные документы США

Модели ипотечных документов США анализируют и извлекают ключевые поля, включающие заемщик, кредит и информацию о собственности из выбранной группы ипотечных документов. API поддерживает анализ документов ипотеки на английском языке США различных форматов и качества, включая захваченные телефоном изображения, сканированные документы и цифровые PDF-файлы. В настоящее время поддерживаются следующие модели.
| Модель | Описание | Идентификатор модели |
|---|---|---|
| Лицензионное соглашение 1003 End-User | Извлечение сведений о кредите, заемщике и собственности. | prebuilt-mortgage.us.1003 |
| 1004 Единый отчет об оценке жилых помещений (URAR) | Извлечение сведений о кредите, заемщике и собственности. | prebuilt-mortgage.us.1004 |
| 1005 Проверка занятости | Извлечение кредита, заемщика, сведений о собственности. | prebuilt-mortgage.us.1005 |
| Сводный документ 1008 | Извлеките данные о заемщике, продавце, недвижимости, ипотеке и андеррайтинге. | prebuilt-mortgage.us.1008 |
| Заключительное раскрытие информации | Извлечение затрат на закрытие сделки, транзакционных затрат и деталей кредита. | prebuilt-mortgage.us.closingDisclosure |
Этот образец документа закрытия по раскрытию информации был обработан с помощью Document Intelligence Studio.

Контракт
![]()
Модель контракта анализирует и извлекает ключевые поля и элементы линии из договорных соглашений, включая стороны, юрисдикции, идентификатор контракта и название. В настоящее время модель поддерживает документы контракта на английском языке.
Этот пример контракта был обработан с помощью Document Intelligence Studio.

Проверка банка США
![]()
Модель контракта анализирует и извлекает ключевые поля из чеков банков США, включая сведения о чеке, сведения о счете, сумму и назначение.
Этот пример проверки банка был обработан с помощью Document Intelligence Studio.

Выписка из банка в США
![]()
Модель анализа банковских выписок анализирует и извлекает ключевые поля и позиции строк из выписок банков США, включая номер счета, сведения о банке, детали выписки и сведения о транзакциях.
Этот пример банковской выписки был обработан с помощью Document Intelligence Studio.

payStub
![]()
Модель payStub анализирует и извлекает ключевые поля и элементы строки из документов и файлов с информацией, связанной с заработной платы.
Этот пример расчетного листка был обработан с помощью Document Intelligence Studio.

Счет

Модель счета автоматизирует обработку счетов для извлечения имени клиента, адреса выставления счетов, срока оплаты, суммы, позиций в счете и других ключевых данных.
Этот пример счета был обработан с помощью Document Intelligence Studio.

Квитанция

Используйте модель чеков для сканирования торговых чеков на предмет имени продавца, дат, позиций, количества и итогов в печатных и рукописных чеках. Версия 3.0 также поддерживает обработку квитанций об одностраничных отелях.
Этот пример квитанции был обработан с помощью Document Intelligence Studio.

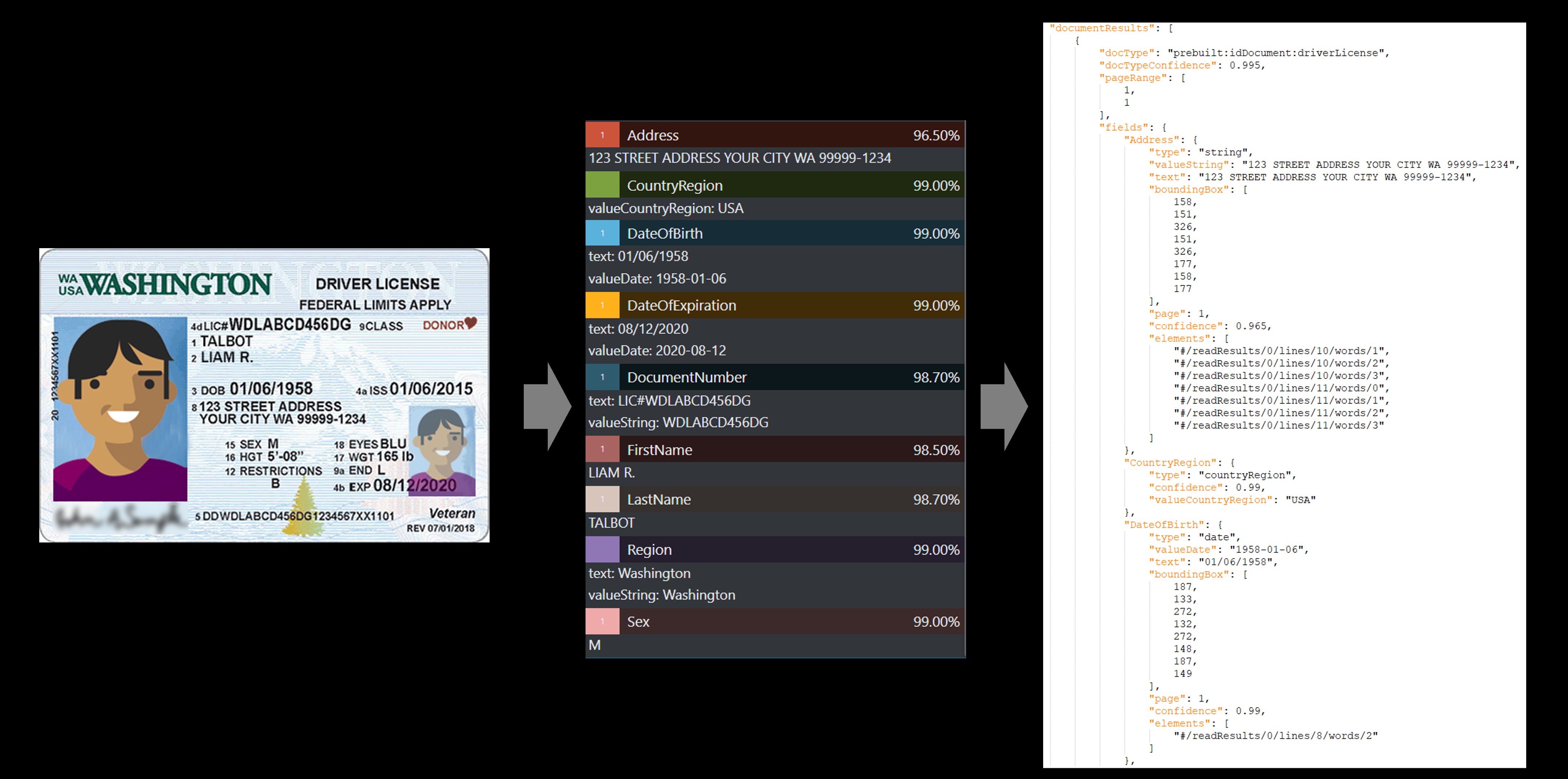
Удостоверение личности

Используйте модель удостоверения (ID) для обработки лицензий водителя США (все 50 штатов и округа Колумбия) и биографические страницы из международных паспортов (за исключением виз и других документов для путешествий) для извлечения ключевых полей.
Этот пример лицензии водителя США был обработан с помощью Document Intelligence Studio.

Свидетельство о браке
![]()
Используйте модель сертификата брака для обработки сертификатов брака США для извлечения ключевых полей, в том числе отдельных лиц, даты и расположения.
Этот пример сертификата о браке США был обработан с помощью Document Intelligence Studio.

Кредитная карта
![]()
Используйте модель кредитной карты для обработки кредитных и дебетовых карт для извлечения ключевых полей.
Этот пример кредитной карты был обработан с помощью Document Intelligence Studio.

Пользовательские модели

Пользовательские модели широко классифицируются по двум типам. Пользовательские модели классификации, поддерживающие классификацию типа документа и пользовательские модели извлечения, которые могут извлекать определенную схему из определенного типа документа.

Пользовательские модели документов анализируют и извлекают данные из форм и документов, относящихся к вашей организации. Они распознают поля формы в вашем уникальном контенте и извлекают пары "ключ-значение" и данные таблицы. Чтобы приступить к работе, вам потребуется только один пример типа формы.
Версия 3.0 и более поздние пользовательские модели поддерживают обнаружение подписей в пользовательских шаблонах (форме) и межстраничных таблицах как в шаблонах, так и в нейронных моделях. Обнаружение подписи ищет наличие подписи, а не удостоверение пользователя, который подписывает документ. Если модель возвращает неподписанный для обнаружения подписей, это означает, что модель не обнаружила подпись в определенном поле.
Этот пример пользовательского шаблона был обработан с помощью Document Intelligence Studio.

Настраиваемое извлечение

Пользовательская модель извлечения представлена в двух вариантах: пользовательский шаблон и пользовательская нейронная сеть. Чтобы создать пользовательскую модель извлечения, разметьте набор данных документов с нужными для извлечения значениями и обучите модель на размеченном наборе данных. Чтобы приступить к работе, вам потребуется только пять примеров одной формы или типа документа.
Этот пример пользовательского извлечения был обработан с помощью Document Intelligence Studio.

Настраиваемый классификатор

С помощью пользовательской модели классификации можно определить тип документа перед вызовом модели извлечения. Модель классификации доступна начиная с API 2023-07-31 (GA). Для обучения пользовательской модели классификации требуется по крайней мере два отдельных класса и не менее пяти выборок для каждого класса.
Составные модели
Собранная модель создаётся путём объединения коллекции пользовательских моделей в одну модель, построенную на основе ваших типов форм. Вы можете назначить несколько пользовательских моделей к составной модели, которые могут вызываться с использованием одного идентификатора модели. Вы можете назначить до 200 обученных пользовательских моделей одной составной модели.
Этот образец модели находится в Document Intelligence Studio.

Требования к входным данным
Поддерживаются следующие форматы файлов.
| Модель | Изображение: JPEG/JPG, PNG, BMP, TIFF, HEIF |
Office: Word (DOCX), Excel (XLSX), PowerPoint (PPTX), HTML |
|
|---|---|---|---|
| Прочитать | ✔ | ✔ | ✔ |
| Макет | ✔ | ✔ | ✔ |
| Общий документ | ✔ | ✔ | |
| Предварительно собранный | ✔ | ✔ | |
| Настраиваемое извлечение | ✔ | ✔ | |
| Настраиваемая классификация | ✔ | ✔ | ✔ |
- Фотографии и сканы: для получения наилучших результатов предоставьте одну четкую фотографию или высококачественный скан на каждый документ.
- PDF и TIFF: для PDF и TIFF можно обрабатывать до 2000 страниц. (С подпиской на бесплатный уровень обрабатываются только первые две страницы.)
- Размер файла: размер файла для анализа документов составляет 500 МБ для платного уровня (S0) и 4 МБ для бесплатного уровня (F0).
- Размеры изображения: размеры должны находиться в диапазоне от 50 пикселей до 10 000 пикселей x 10 000 пикселей.
- Блокировки паролей. Если pdf-файлы заблокированы паролем, необходимо удалить блокировку перед отправкой.
- Высота текста: минимальная высота извлеченного текста составляет 12 пикселей для изображения 1024 x 768 пикселей. Это измерение соответствует примерно 8-точечному тексту при 150 точках на дюйм.
- Обучение пользовательской модели: максимальное количество страниц для обучающих данных составляет 500 для пользовательской модели шаблона и 50 000 для пользовательской нейронной модели.
- Обучение пользовательской модели извлечения: общий размер обучающих данных составляет 50 МБ для модели шаблона и 1 ГБ для нейронной модели.
- Обучение пользовательской модели классификации: общий размер обучающих данных составляет 1 ГБ, не более 10 000 страниц. Для 2024-11-30 (GA) общий размер обучающих данных составляет 2 ГБ с максимум 10 000 страниц.
- Типы файлов Office (DOCX, XLSX, PPTX): максимальная длина строки составляет 8 миллионов символов.
Примечание
Инструмент разметки образцов не поддерживает формат файла BMP. Ограничение связано с инструментом, а не с сервисом интеллектуального анализа документов.
Миграция версий
Узнайте, как использовать аналитику документов версии 3.0 в приложениях, выполнив действия, описанные в руководстве по миграции Document Intelligence версии 3.1.
| Модель | Описание |
|---|---|
| Анализ документов | |
| Макет | Извлеките информацию о тексте и макете из документов. |
| Предварительно собранный | |
| Счет | Извлеките ключевые сведения из счетов на английском языке и испанском языке. |
| Получения | Извлеките ключевые сведения из квитанций на английском языке. |
| Удостоверение личности | Извлеките ключевые сведения из лицензий водителя США и международных паспортов. |
| Визитная карточка | Извлеките ключевые сведения из визитных карточек на английском языке. |
| Настраиваемые | |
| Пользовательские | Извлеките данные из форм и документов, относящихся к вашему бизнесу. Специализированные модели обучены для ваших специфичных данных и случаев использования. |
| Составлено | Создайте коллекцию пользовательских моделей и объедините их в единую модель, созданную на основе ваших типов форм. |
Макет
API макета анализирует и извлекает текст, таблицы и заголовки, метки выделения и сведения о структуре из документов.
Этот пример документа был обработан с помощью средства маркировки образца.

Счет
Модель счета анализирует и извлекает ключевые сведения из счетов о продажах. API анализирует счета в различных форматах и извлекает ключевые сведения, такие как имя клиента, адрес выставления счетов, дата выполнения и сумма.
Этот пример счета был обработан с помощью средства маркировки образца.

Квитанция
Модель квитанций анализирует и извлекает ключевые сведения из печатных и рукописных квитанций о продажах.
Этот пример чека был обработан с помощью инструмента маркировки образцов.
Документ удостоверяющий личность
Модель документа идентификатора анализирует и извлекает ключевые сведения из следующих документов:
- Лицензии водителя США (все 50 штатов и округ Колумбия)
- Биографические страницы из международных паспортов (за исключением виз и других документов для путешествий). API анализирует и извлекает документы, удостоверяющие личность.
Этот пример водительского удостоверения США был создан с помощью средства маркировки примеров.
Визитная карточка
Модель визитной карточки анализирует и извлекает ключевые сведения из изображений визитных карточек.
Этот образец визитки был обработан с помощью инструмента для маркировки образцов.

Настраиваемые
Пользовательские модели анализируют и извлекают данные из форм и документов, относящихся к вашему бизнесу. API — это программа машинного обучения, обученная распознавать поля формы в отдельном содержимом и извлекать пары ключей и значений и табличные данные. Чтобы приступить к работе, вам потребуется только пять примеров одного типа формы. Вы можете обучить настраиваемую модель с помощью помеченных наборов данных или без нее.
Этот пример настраиваемой модели был обработан с помощью средства создания примеров меток.

Собранная настраиваемая модель
Собранная модель создаётся путём объединения коллекции пользовательских моделей в одну модель, построенную на основе ваших типов форм. Вы можете назначить несколько пользовательских моделей к составной модели, которые могут вызываться с использованием одного идентификатора модели. Вы можете назначить до 100 обученных настраиваемых моделей в одну составную модель.
Эта созданная область модели была обработана с помощью средства "Пример меток".

Извлечение данных модели
| Модель | Извлечение текста | Обнаружение языка | Метки выделения | Таблицы | Параграфы | Роли абзаца | Пары ключ-значение | Поля |
|---|---|---|---|---|---|---|---|---|
| Макет | ✓ | ✓ | ✓ | ✓ | ✓ | |||
| Счет | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ||
| Получения | ✓ | ✓ | ✓ | |||||
| Удостоверение личности | ✓ | ✓ | ✓ | |||||
| Визитная карточка | ✓ | ✓ | ✓ | |||||
| Настраиваемая форма | ✓ | ✓ | ✓ | ✓ | ✓ |
Требования к входным данным
Поддерживаются следующие форматы файлов.
| Модель | Изображение: JPEG/JPG, PNG, BMP, TIFF, HEIF |
Office: Word (DOCX), Excel (XLSX), PowerPoint (PPTX), HTML |
|
|---|---|---|---|
| Прочитать | ✔ | ✔ | ✔ |
| Макет | ✔ | ✔ | ✔ |
| Общий документ | ✔ | ✔ | |
| Предварительно собранный | ✔ | ✔ | |
| Настраиваемое извлечение | ✔ | ✔ | |
| Настраиваемая классификация | ✔ | ✔ | ✔ |
- Фотографии и сканы: для получения наилучших результатов предоставьте одну четкую фотографию или высококачественный скан на каждый документ.
- PDF и TIFF: для PDF и TIFF можно обрабатывать до 2000 страниц. (С подпиской на бесплатный уровень обрабатываются только первые две страницы.)
- Размер файла: размер файла для анализа документов составляет 500 МБ для платного уровня (S0) и 4 МБ для бесплатного уровня (F0).
- Размеры изображения: размеры должны находиться в диапазоне от 50 пикселей до 10 000 пикселей x 10 000 пикселей.
- Блокировки паролей. Если pdf-файлы заблокированы паролем, необходимо удалить блокировку перед отправкой.
- Высота текста: минимальная высота извлеченного текста составляет 12 пикселей для изображения 1024 x 768 пикселей. Это измерение соответствует примерно 8-точечному тексту при 150 точках на дюйм.
- Обучение пользовательской модели: максимальное количество страниц для обучающих данных составляет 500 для пользовательской модели шаблона и 50 000 для пользовательской нейронной модели.
- Обучение пользовательской модели извлечения: общий размер обучающих данных составляет 50 МБ для модели шаблона и 1 ГБ для нейронной модели.
- Обучение пользовательской модели классификации: общий размер обучающих данных составляет 1 ГБ, не более 10 000 страниц. Для 2024-11-30 (GA) общий размер обучающих данных составляет 2 ГБ с максимум 10 000 страниц.
- Типы файлов Office (DOCX, XLSX, PPTX): максимальная длина строки составляет 8 миллионов символов.
Примечание
Инструмент разметки образцов не поддерживает формат файла BMP. Ограничение исходит от инструмента, а не от Document Intelligence.
Миграция версий
Вы можете узнать, как использовать аналитику документов версии 3.0 в приложениях, выполнив действия, описанные в руководстве по миграции Document Intelligence версии 3.1.
Связанное содержимое
- Обработайте собственные формы и документы с помощью Document Intelligence Studio.
- Завершите краткое руководство по анализу документов и создайте приложение для обработки документов на выбранном языке разработки.
- Обработайте собственные формы и документы с средством для маркировки документов с помощью искусственного интеллекта.
- Завершите краткое руководство по анализу документов и создайте приложение для обработки документов на выбранном языке разработки.