Примечание
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
Это важно
Поддержка соединителя Power Query была представлена в качестве общедоступной предварительной версии в рамках дополнительных условий использования для предварительных версий Microsoft Azure, но теперь прекращена. Если у вас есть решение поиска, использующее соединитель Power Query, перейдите к альтернативному решению.
Миграция к 28 ноября 2022 г.
Предварительная версия соединителя Power Query была анонсирована в мае 2021 г. и не будет доведена до статуса общедоступной версии. Следующие рекомендации по миграции доступны для Snowflake и PostgreSQL. Если вы используете другой соединитель и нуждаетесь в инструкциях по миграции, используйте контактные данные электронной почты, предоставленные в предварительной версии, чтобы запросить справку или открыть запрос в службу поддержки Azure.
Предпосылки
- Учетная запись хранения Azure. Если у вас нет учетной записи хранения, создайте учетную запись хранения.
- Фабрика данных Azure. Если у вас его нет, создайте фабрику данных. См. цены на конвейеры Data Factory перед внедрением, чтобы понять связанные затраты. Кроме того, ознакомьтесь с ценами на Фабрику данных с помощью примеров.
Перенос конвейера данных Snowflake
В этом разделе объясняется, как скопировать данные из базы данных Snowflake в индекс Когнитивного поиска Azure. Нет процесса прямого индексирования из Snowflake в Когнитивный поиск Azure, поэтому этот раздел включает промежуточный этап, который копирует содержимое базы данных в контейнер BLOB Azure Storage. Затем вы будете индексировать из этого подготовительного контейнера с помощью платформы Data Factory.
Шаг 1. Получение сведений о базе данных Snowflake
Перейдите в Snowflake и войдите в учетную запись Snowflake . Учетная запись Snowflake выглядит как https://< account_name.snowflakecomputing.com>.
После входа соберите следующие сведения из левой области. Эти сведения будут использоваться на следующем шаге:
- В поле "Данные" выберите "Базы данных " и скопируйте имя источника базы данных.
- В разделе "Администратор" выберите "Пользователи" и "Роли" и скопируйте имя пользователя. Убедитесь, что у пользователя есть разрешения на чтение.
- В разделе "Администратор" выберите "Учетные записи" и скопируйте значение LOCATOR учетной записи.
- Из URL-адреса Snowflake, схожего с
https://app.snowflake.com/<region_name>/xy12345/organization). скопируйте имя региона. Например, вhttps://app.snowflake.com/south-central-us.azure/xy12345/organizationназвание региона:south-central-us.azure. - В разделе "Администратор" выберите "Хранилища" и скопируйте имя хранилища, связанного с базой данных, которую вы будете использовать в качестве источника.
Шаг 2. Настройка связанной службы Snowflake
Войдите в Azure Data Factory Studio с помощью учетной записи Azure.
Выберите фабрику данных и нажмите кнопку "Продолжить".
В меню слева выберите значок "Управление ".
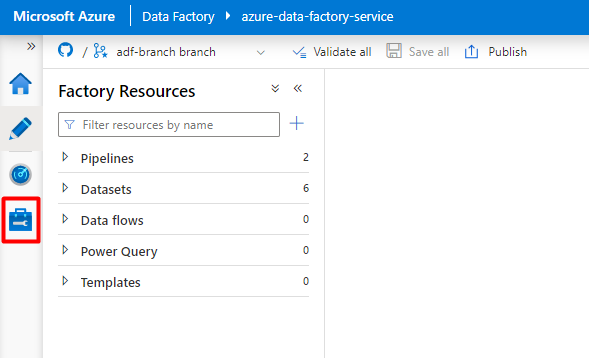
В разделе "Связанные службы" выберите "Создать".
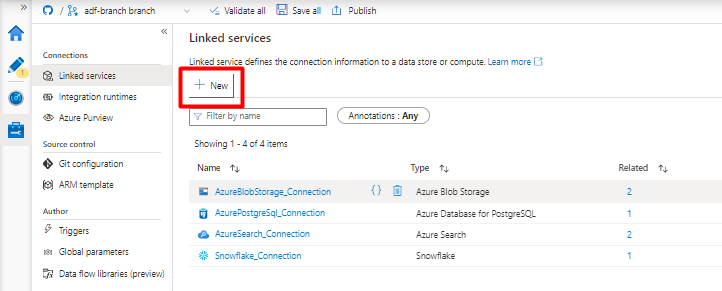
На правой панели в поиске хранилища данных введите "snowflake". Выберите плитку Snowflake и нажмите кнопку "Продолжить".
Заполните форму новой связанной службы данными, собранными на предыдущем шаге. Имя учетной записи содержит значение LOCATOR и регион (например:
xy56789south-central-us.azure).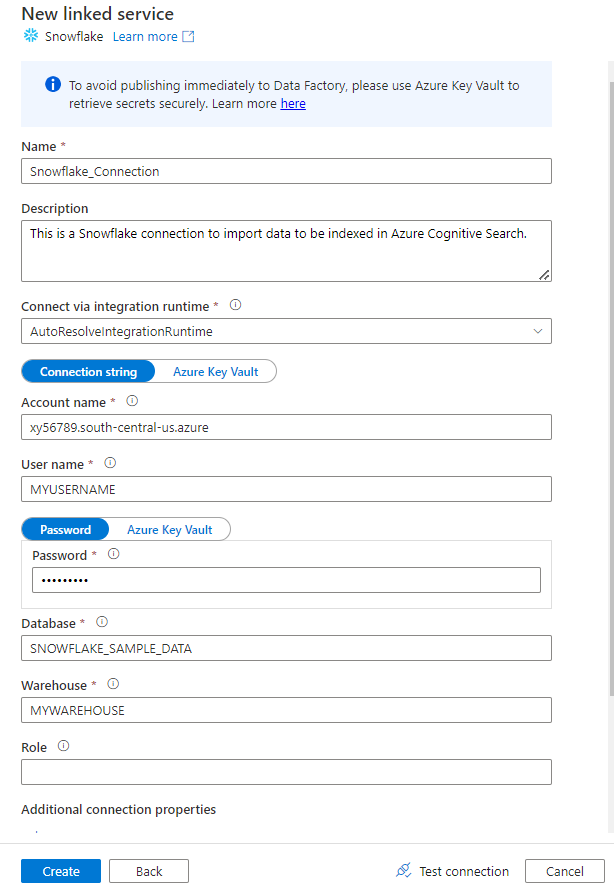
После завершения формы выберите "Проверить подключение".
Если тест выполнен успешно, нажмите кнопку "Создать".
Шаг 3. Настройка набора данных Snowflake
В меню слева выберите значок "Автор ".
Выберите наборы данных, а затем выберите меню "Действия с многоточием" (
...).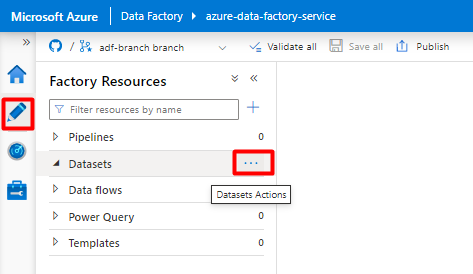
Выберите новый набор данных.
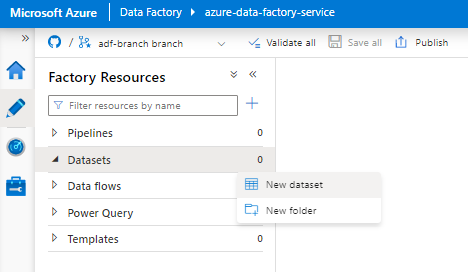
На правой панели в поиске хранилища данных введите "snowflake". Выберите плитку Snowflake и нажмите кнопку "Продолжить".
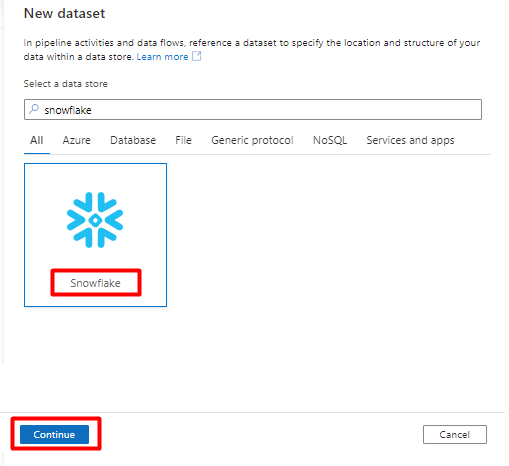
В разделе "Свойства набора":
- Выберите связанную службу, созданную на шаге 2.
- Выберите таблицу, которую вы хотите импортировать, и нажмите кнопку "ОК".
Выберите Сохранить.
Шаг 4. Создание нового индекса в Когнитивном поиске Azure
Создайте новый индекс в службе Когнитивного поиска Azure с той же схемой, что и для данных Snowflake.
Вы можете изменить индекс, который вы используете в настоящее время для соединителя Snowflake Power Connector. На портале Azure найдите индекс и выберите "Определение индекса" (JSON). Выберите определение и скопируйте его в текст нового запроса индекса.
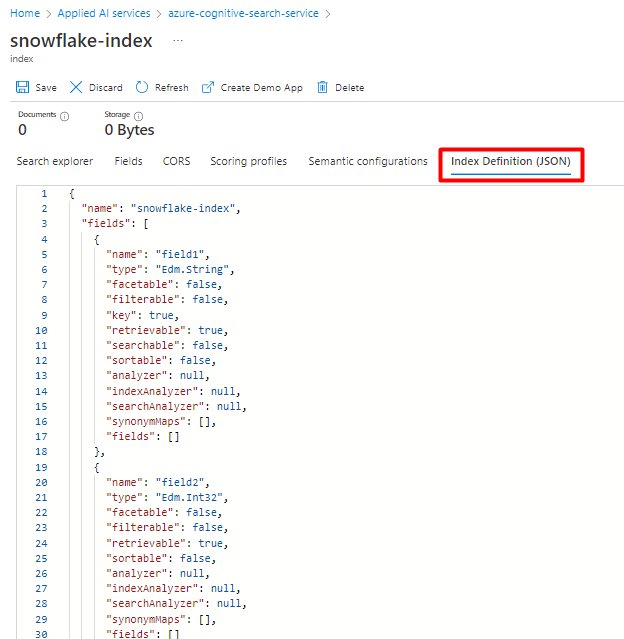
Шаг 5. Настройка связанной службы Когнитивного поиска Azure
В меню слева выберите значок "Управление ".
В разделе "Связанные службы" выберите "Создать".
На правой панели в поиске хранилища данных введите "поиск". Выберите плитку "Поиск Azure" и нажмите кнопку "Продолжить".
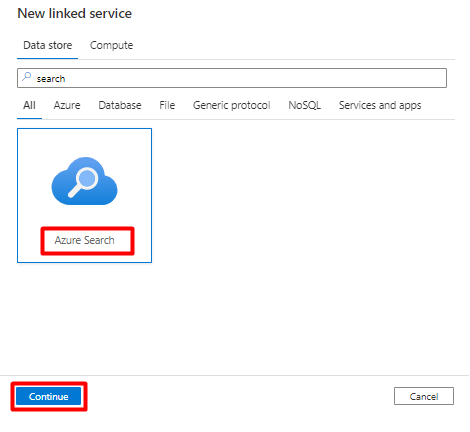
Заполните параметры нового подключённого сервиса:
- Выберите подписку Azure, в которой находится служба Когнитивного поиска Azure.
- Выберите службу Когнитивного поиска Azure, которая содержит индексатор вашего соединителя Power Query.
- Выберите Создать.
Шаг 6. Настройка набора данных Когнитивного поиска Azure
В меню слева выберите значок "Автор ".
Выберите наборы данных, а затем выберите меню "Действия с многоточием" (
...).
Выберите новый набор данных.
На правой панели в поиске хранилища данных введите "поиск". Выберите плитку "Поиск Azure" и нажмите кнопку "Продолжить".
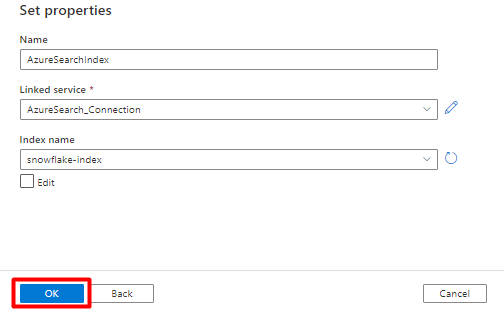
В свойствах Set:
Выберите Сохранить.
Шаг 7. Настройка связанной службы хранилища BLOB-объектов Azure
В меню слева выберите значок "Управление ".
В разделе "Связанные службы" выберите "Создать".
На правой панели в поиске хранилища данных введите "хранилище". Выберите плитку хранилища BLOB-объектов Azure и нажмите кнопку "Продолжить".
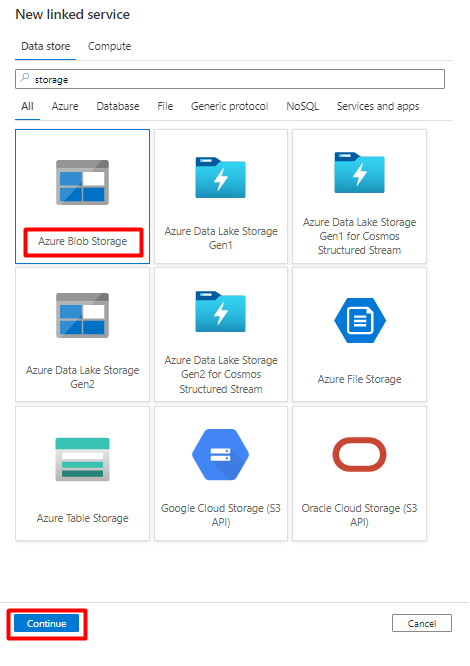
Заполните значения нового связанного сервиса :
Выберите тип проверки подлинности: URI SAS. Только этот тип проверки подлинности можно использовать для импорта данных из Snowflake в хранилище BLOB-объектов Azure.
Создайте URL-адрес SAS для учетной записи хранения, которую вы будете использовать для промежуточного хранения. Вставьте SAS URL-адрес Blob в поле URL-адреса SAS.
Выберите Создать.
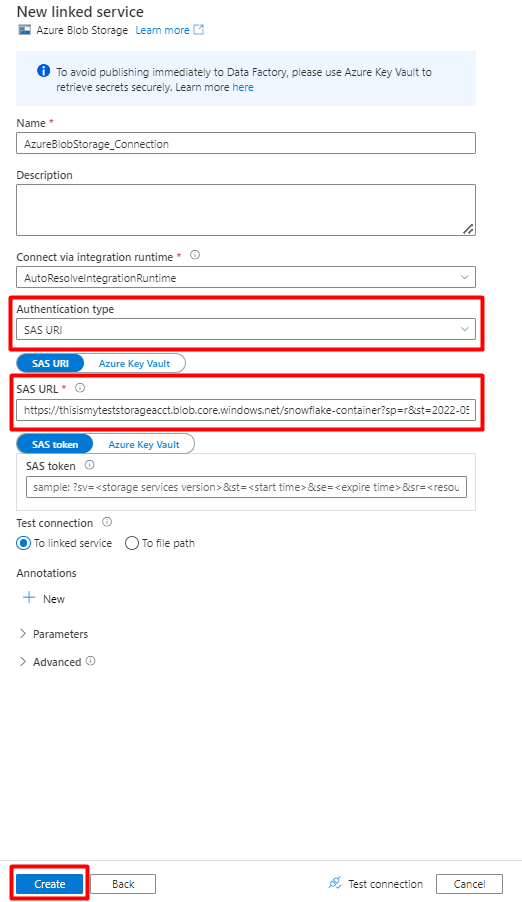
Шаг 8. Настройка набора данных хранилища
В меню слева выберите значок "Автор ".
Выберите наборы данных, а затем выберите меню действий (многоточие) (
...).
Выберите новый набор данных.
На правой панели в поиске хранилища данных введите "хранилище". Выберите плитку хранилища BLOB-объектов Azure и выберите «Продолжить».
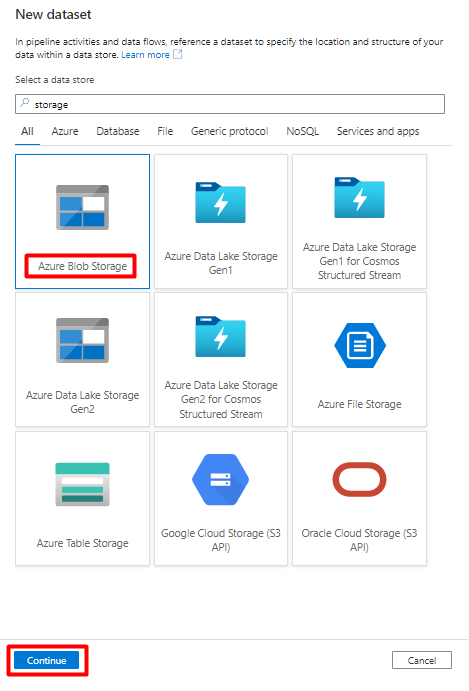
Выберите формат Разделенный текст и нажмите Продолжить.
В разделе "Свойства набора":
В разделе "Связанная служба" выберите связанную службу, созданную на шаге 7.
В разделе "Путь к файлу" выберите контейнер, который будет приемником промежуточного процесса, и нажмите кнопку "ОК".
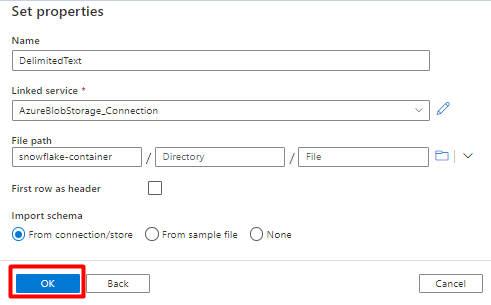
В Разделитель строк выберите перевод строки (\n).
Установите флажок "Первая строка как заголовок".
Выберите Сохранить.
Шаг 9. Настройка конвейера
В меню слева выберите значок "Автор ".
Выберите "Конвейеры" и выберите меню "Действия конвейеров" (
...).
Выберите Создать конвейер.
Создайте и настройте действия фабрики данных , которые копируются из Snowflake в контейнер службы хранилища Azure:
Разверните раздел Перемещение и преобразование и перетащите действие Копирование данных на пустой холст редактора конвейера.
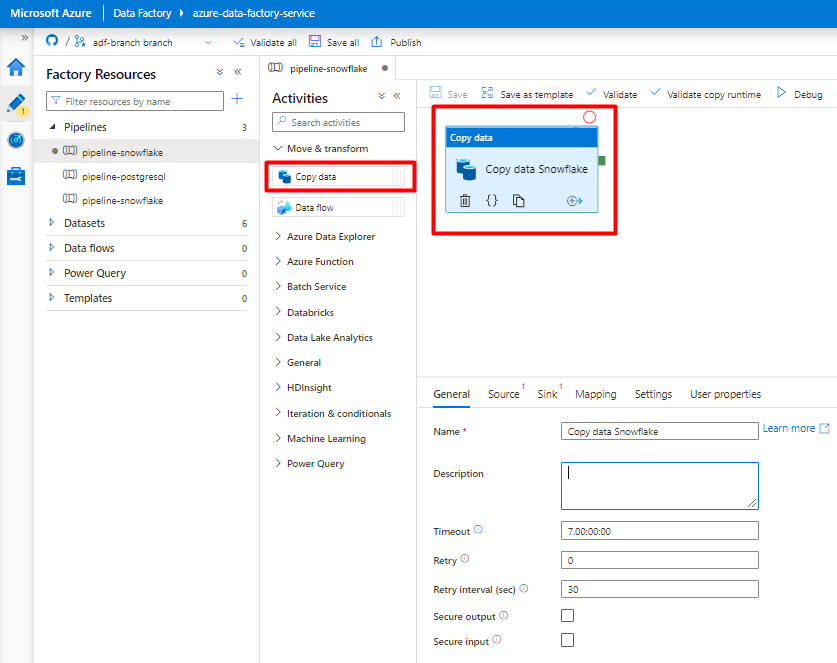
Откройте вкладку "Общие ". Примите значения по умолчанию, если вам не нужно настраивать выполнение.
На вкладке "Источник" выберите таблицу Snowflake. Оставьте остальные параметры значениями по умолчанию.
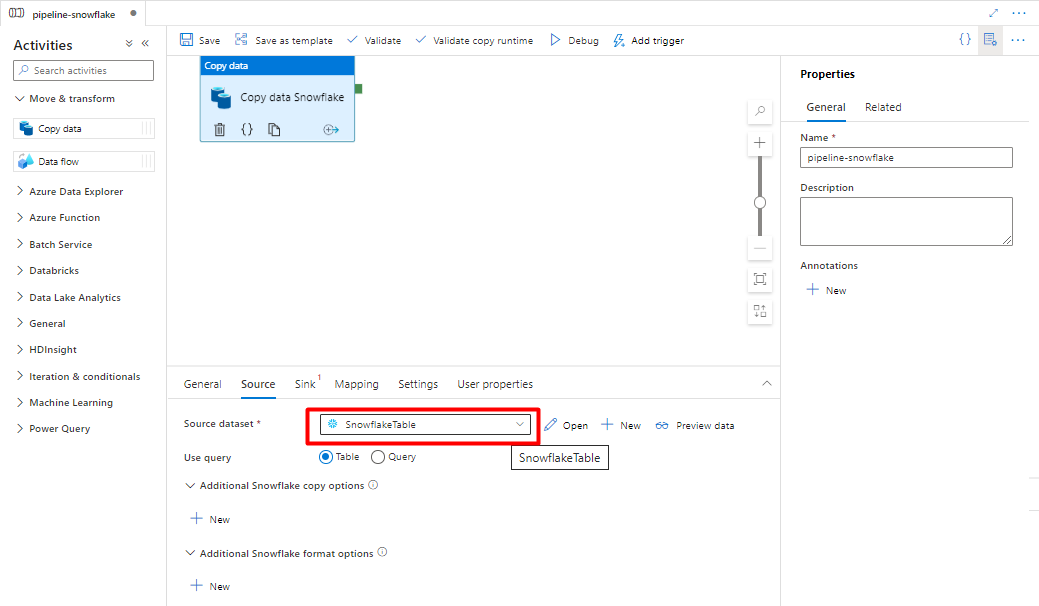
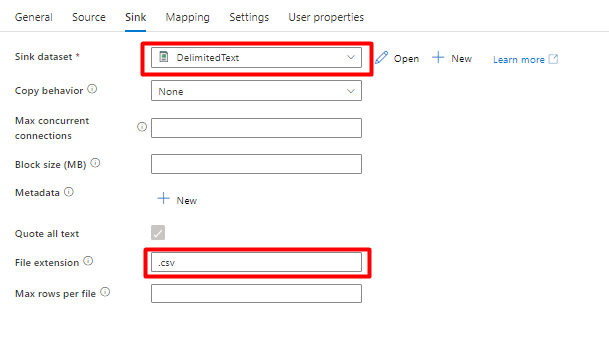
На вкладке "Приемник" :
Выберите набор данных Storage DelimitedText, созданный на шаге 8.
В расширение файла добавьте .csv.
Оставьте остальные параметры значениями по умолчанию.
Выберите Сохранить.
Настройте задачи, которые копируют данные из BLOB-объекта в службе хранения Azure в индекс поиска.
Разверните раздел перемещения и преобразования и перетащите действие копирования данных на пустой холст редактора конвейера.
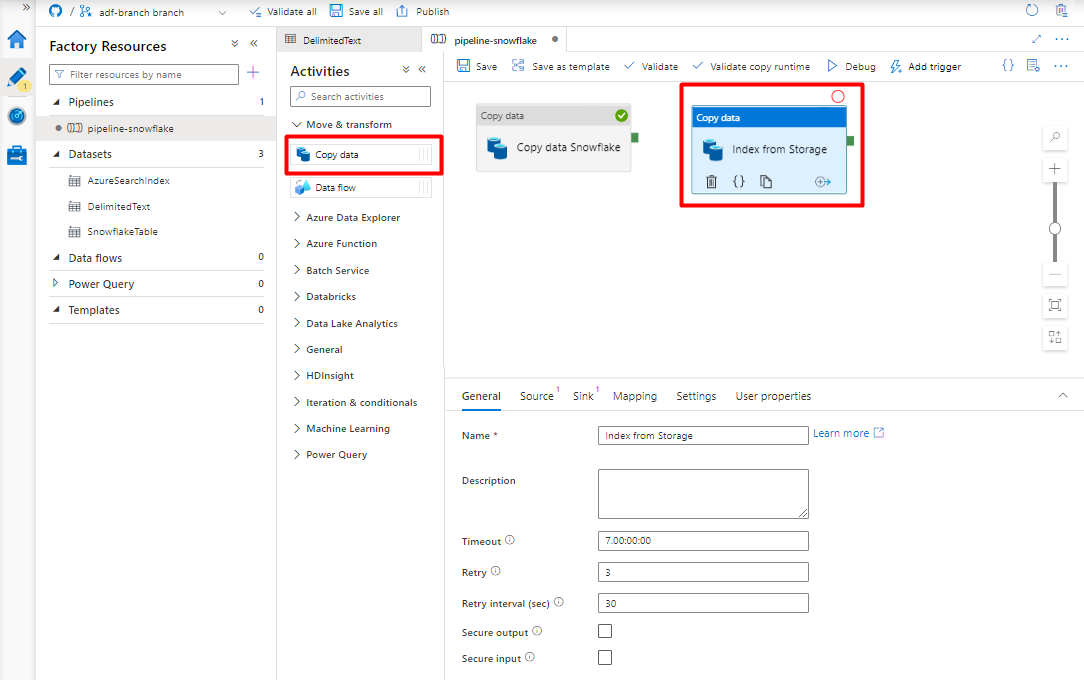
На вкладке "Общие " примите значения по умолчанию, если вам не нужно настраивать выполнение.
На вкладке "Источник":
- Выберите набор данных Storage DelimitedText, созданный на шаге 8.
- В типе пути к файлу выберите путь к файлу с подстановочными знаками.
- Оставьте все оставшиеся поля со значениями по умолчанию.
На вкладке "Синх" выберите индекс Когнитивного поиска Azure. Оставьте остальные параметры значениями по умолчанию.
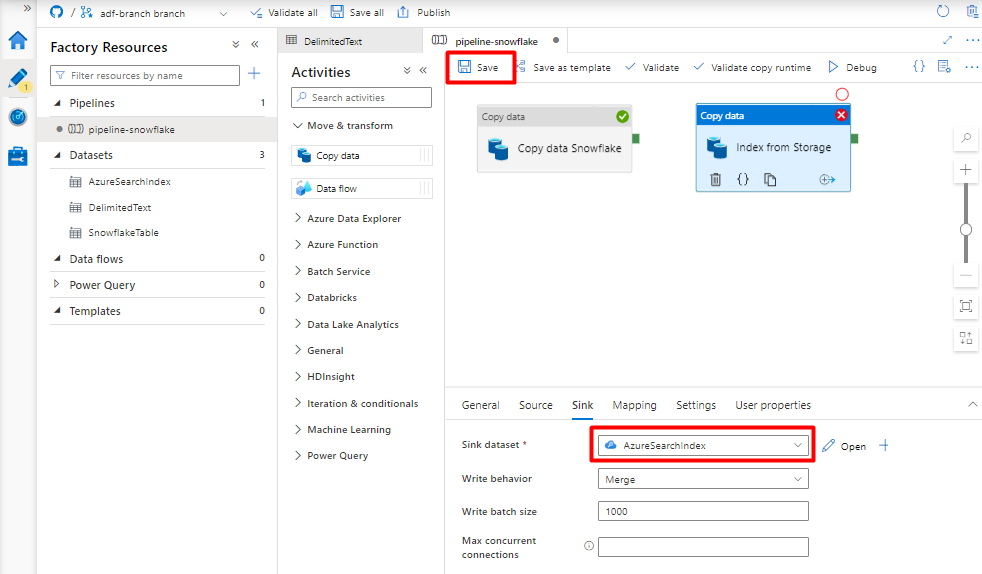
Выберите Сохранить.
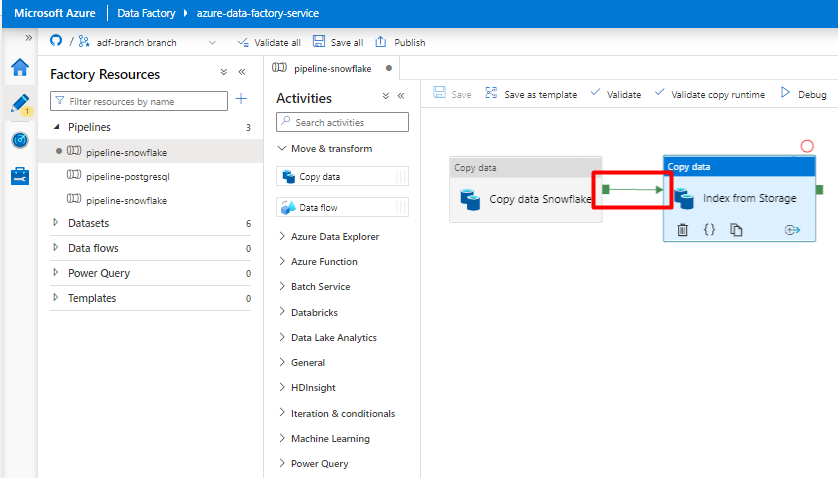
Шаг 10. Настройка порядка действий
В редакторе холста конвейера выберите маленький зеленый квадрат на краю элемента действия конвейера. Перетащите его в действие "Индексы из учетной записи хранения в Когнитивный поиск Azure", чтобы задать порядок выполнения.
Выберите Сохранить.
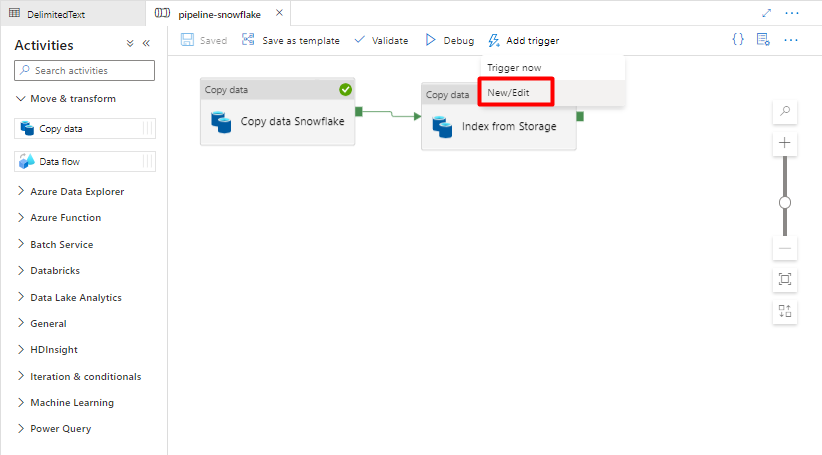
Шаг 11. Добавление триггера конвейера
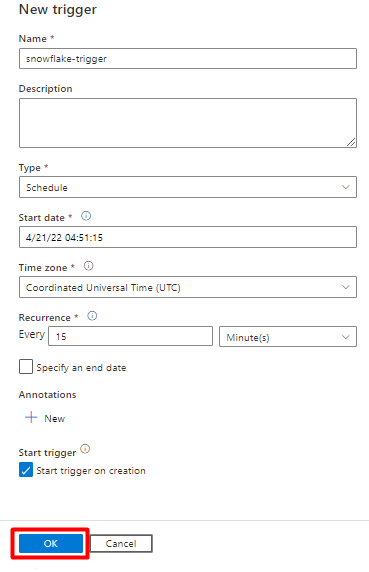
Выберите "Добавить триггер ", чтобы запланировать запуск конвейера, и выберите "Создать или изменить".
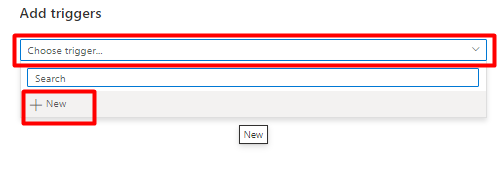
В раскрывающемся списке "Выбор триггера" нажмите кнопку "Создать".
Просмотрите параметры триггера для запуска конвейера и нажмите кнопку "ОК".
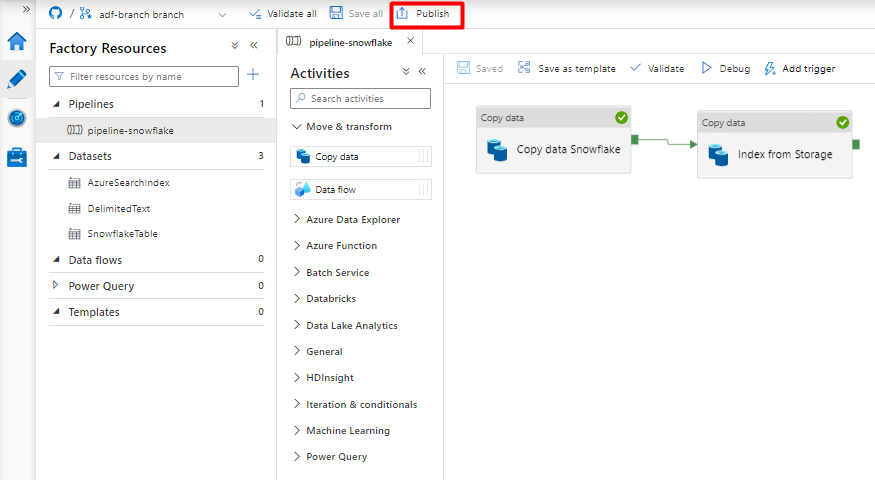
Выберите Сохранить.
Выберите Опубликовать.
Перенос конвейера данных PostgreSQL
В этом разделе объясняется, как скопировать данные из базы данных PostgreSQL в индекс Когнитивного поиска Azure. Нет процесса прямого индексирования из PostgreSQL в службу поиска Azure Cognitive Search, поэтому в этом разделе описан этап промежуточной обработки, который копирует содержимое базы данных в контейнер блобов облачного хранилища Azure. Затем вы будете индексировать из этого промежуточного контейнера с помощью конвейера Data Factory.
Шаг 1. Настройка связанной службы PostgreSQL
Войдите в Azure Data Factory Studio с помощью учетной записи Azure.
Выберите фабрику данных и нажмите кнопку "Продолжить".
В меню слева выберите значок "Управление ".
В разделе "Связанные службы" выберите "Создать".
На правой панели в поиске хранилища данных введите postgresql. Выберите плитку PostgreSQL , представляющую расположение базы данных PostgreSQL (Azure или другое) и нажмите кнопку "Продолжить". В этом примере база данных PostgreSQL находится в Azure.

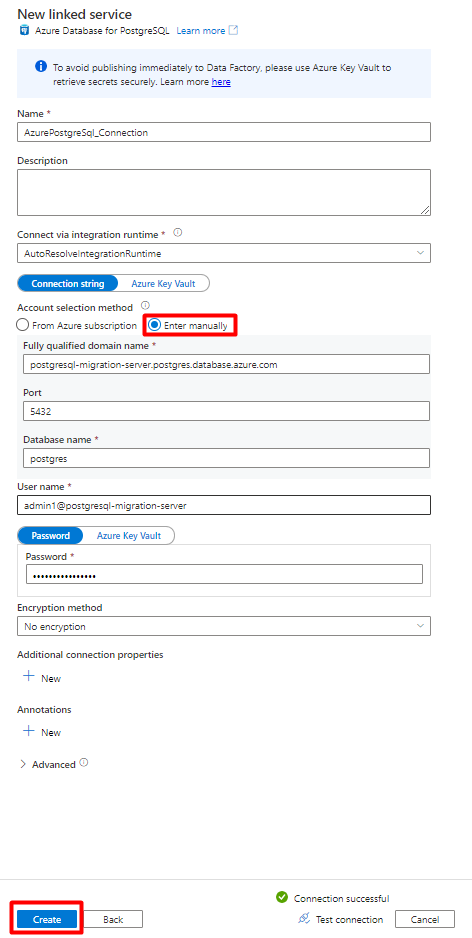
Заполните значения нового связанного сервиса:
В методе выбора учетной записи выберите Ввести вручную.
На странице обзора базы данных Azure для PostgreSQL на портале Azure вставьте следующие значения в соответствующее поле:
- Добавьте имя сервера в полное доменное имя.
- Добавьте имя администратора в имя пользователя.
- Добавьте базу данных в имя базы данных.
- Введите имя пользователя администратора и пароль для имени пользователя и пароля.
- Выберите Создать.
Шаг 2. Настройка набора данных PostgreSQL
В меню слева выберите значок "Автор ".
Выберите наборы данных, а затем выберите меню "Действия с многоточием" (
...).
Выберите новый набор данных.
На правой панели в поиске хранилища данных введите postgresql. Выберите плитку Azure PostgreSQL . Выберите Продолжить.
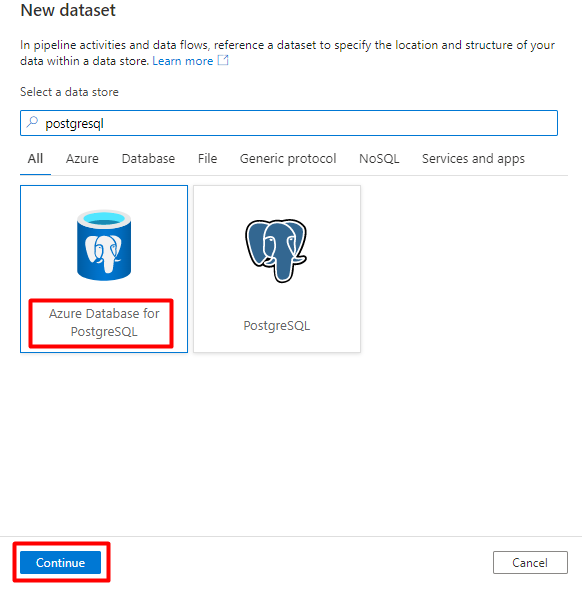
Заполните значения установленных свойств:
Выберите связанную службу PostgreSQL, созданную на шаге 1.
Выберите таблицу, в которые вы хотите импортировать или индексировать.
Нажмите ОК.
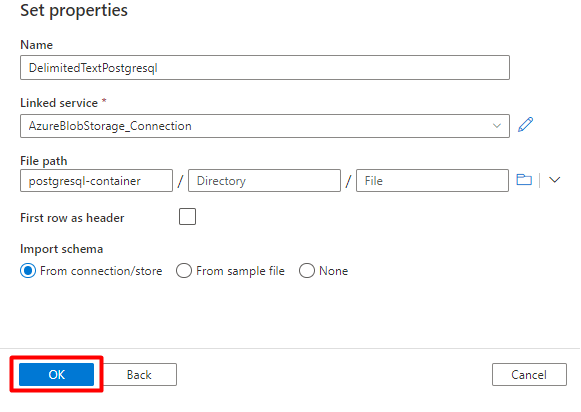
Выберите Сохранить.
Шаг 3. Создание нового индекса в Когнитивном поиске Azure
Создайте новый индекс в службе Когнитивного поиска Azure с той же схемой, что и для данных PostgreSQL.
Вы можете использовать повторно индекс, который вы сейчас используете для Мощного Соединителя PostgreSQL. На портале Azure найдите индекс и выберите "Определение индекса" (JSON). Выберите определение и скопируйте его в текст нового запроса индекса.
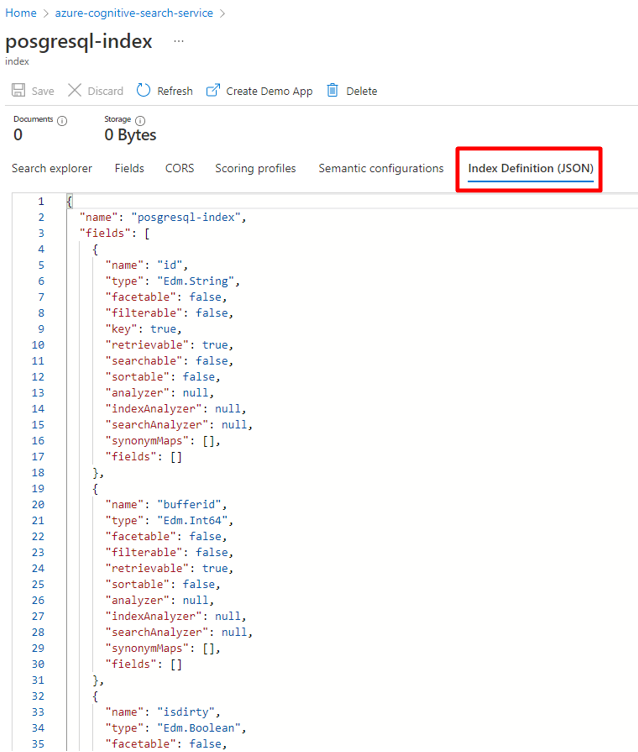
Шаг 4. Настройка связанной службы Когнитивного поиска Azure
В меню слева выберите значок "Управление ".
В разделе "Связанные службы" выберите "Создать".
На правой панели в поиске хранилища данных введите "поиск". Выберите плитку "Поиск Azure" и нажмите кнопку "Продолжить".
Заполните значения нового связанного сервиса:
- Выберите подписку Azure, в которой находится служба Когнитивного поиска Azure.
- Выберите службу Когнитивного поиска Azure, в которой используется ваш индексатор соединителя Power Query.
- Выберите Создать.
Шаг 5. Настройка набора данных Когнитивного поиска Azure
В меню слева выберите значок "Автор ".
Выберите наборы данных, а затем выберите меню с многоточием для действий с наборами данных (
...).
Выберите новый набор данных.
На правой панели в поиске хранилища данных введите "поиск". Выберите плитку "Поиск Azure" и нажмите кнопку "Продолжить".
В свойствах Set:
Выберите Сохранить.
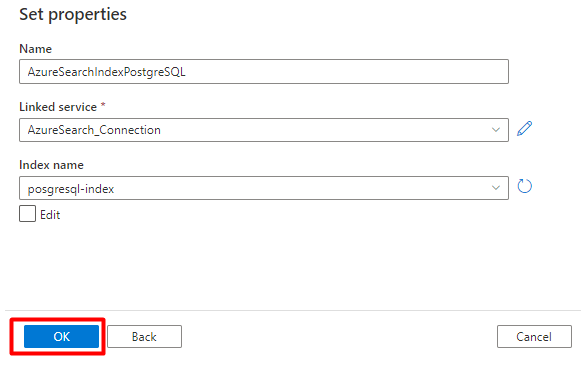
Шаг 6. Настройка подключенного сервиса хранилища BLOB-объектов Azure
В меню слева выберите значок "Управление ".
В разделе "Связанные службы" выберите "Создать".
На правой панели в поиске хранилища данных введите "хранилище". Выберите элемент хранилища BLOB-объектов Azure и нажмите "Продолжить".
Заполните значения новой связанной службы:
Выберите тип проверки подлинности: URI SAS. Только этот метод можно использовать для импорта данных из PostgreSQL в хранилище BLOB-объектов Azure.
Создайте URL-адрес SAS для учетной записи хранения, используемой для размещения, и скопируйте URL-адрес SAS объекта Blob в поле SAS URL.
Выберите Создать.
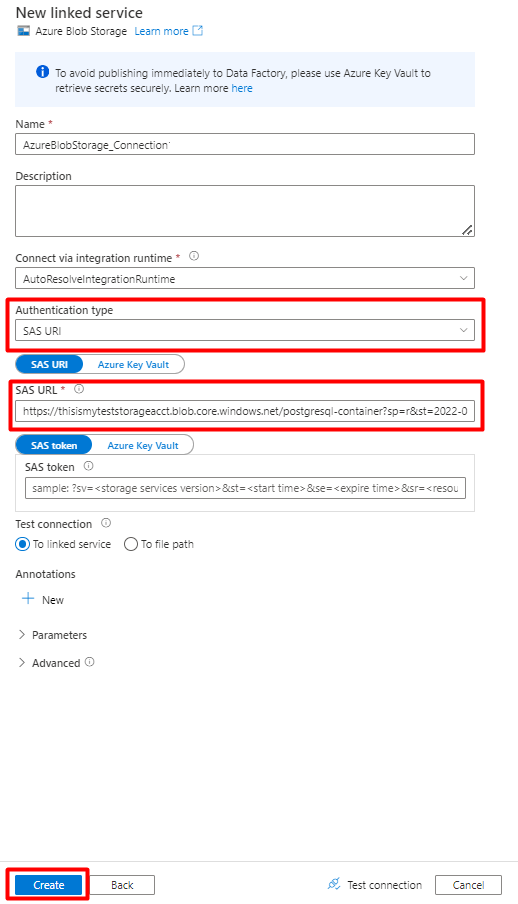
Шаг 7. Настройка набора данных хранилища
В меню слева выберите значок "Автор ".
Выберите наборы данных, а затем выберите меню действий "многоточие" (
...).
Выберите новый набор данных.
На правой панели в поиске хранилища данных введите "хранилище". Выберите плитку Azure Blob Storage и выберите Продолжить.
Выберите формат Делимитированный текст и Продолжить.
В разделителе строк выберите переход на новую строку (\n).
Установите флажок "Первая строка как заголовок".
Выберите Сохранить.
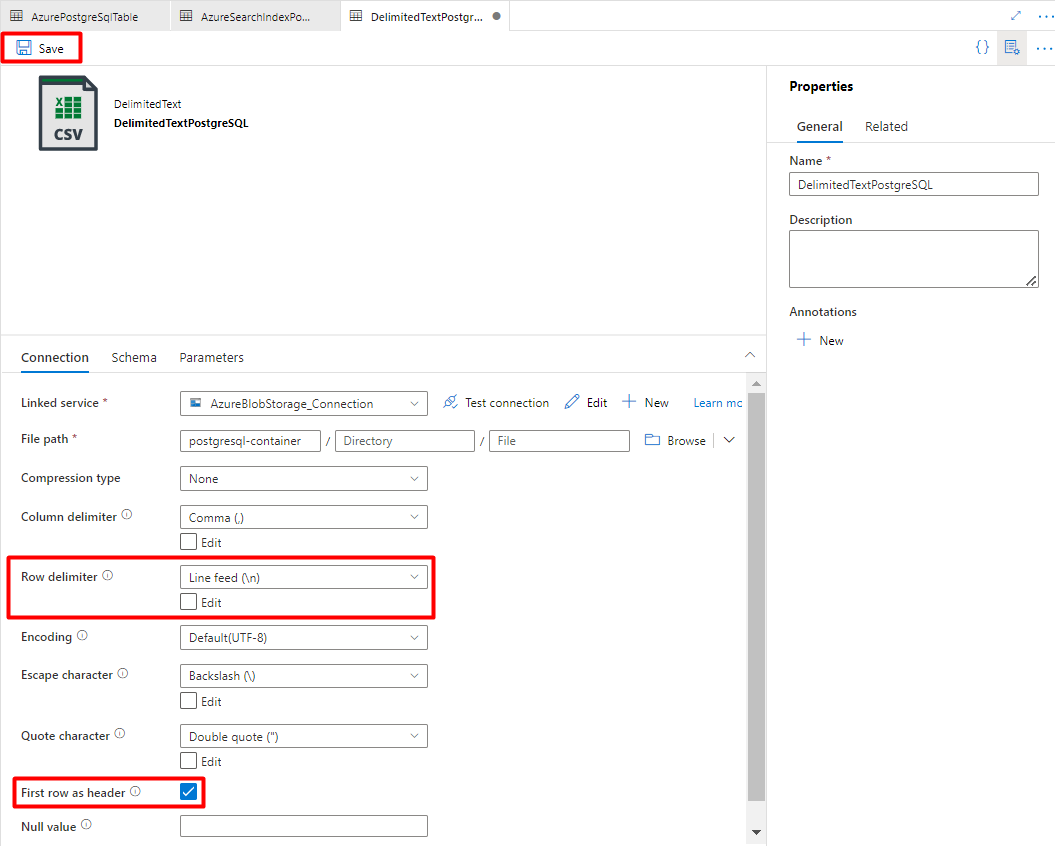
Шаг 8. Настройка конвейера
В меню слева выберите значок "Автор ".
Выберите "Конвейеры" и выберите меню "Действия конвейеров" (
...).
Выберите Создать конвейер.
Создайте и настройте активности Data Factory, которые копируют данные из PostgreSQL в контейнер хранилища Azure.
Разверните раздел Перемещения и преобразования и перетащите действие Копирования данных на пустой холст редактора конвейера.
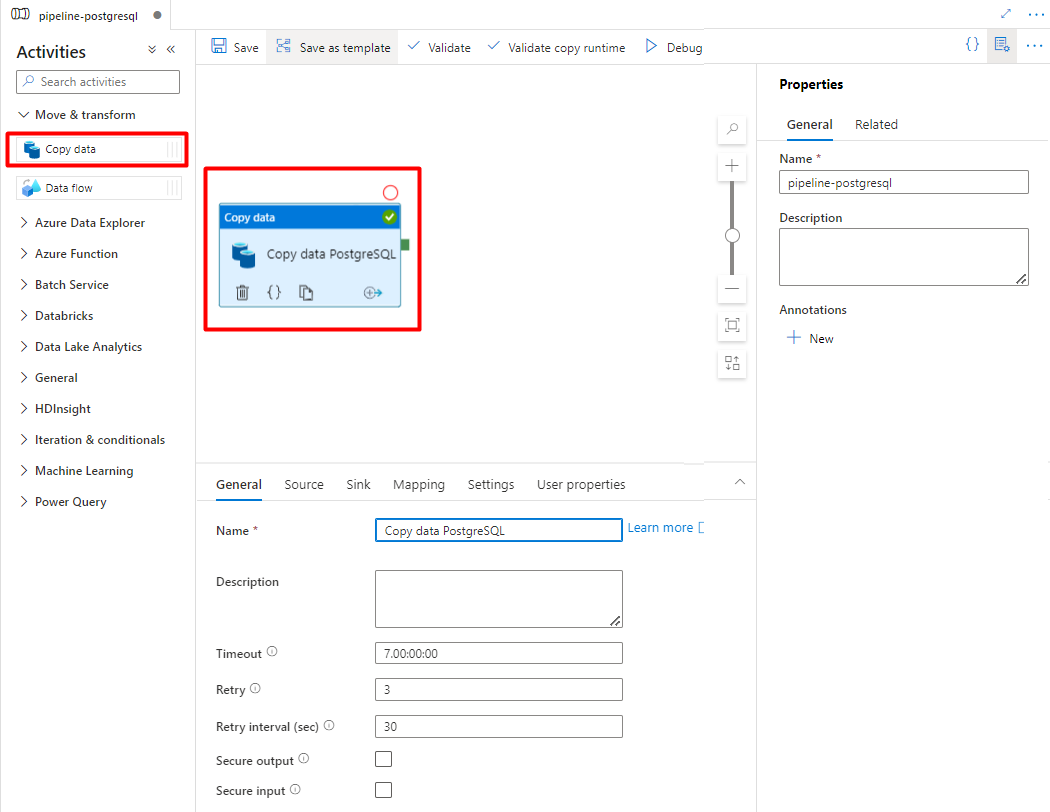
Откройте вкладку "Общие ", примите значения по умолчанию, если вам не нужно настроить выполнение.
На вкладке "Источник" выберите таблицу PostgreSQL. Оставьте остальные параметры значениями по умолчанию.
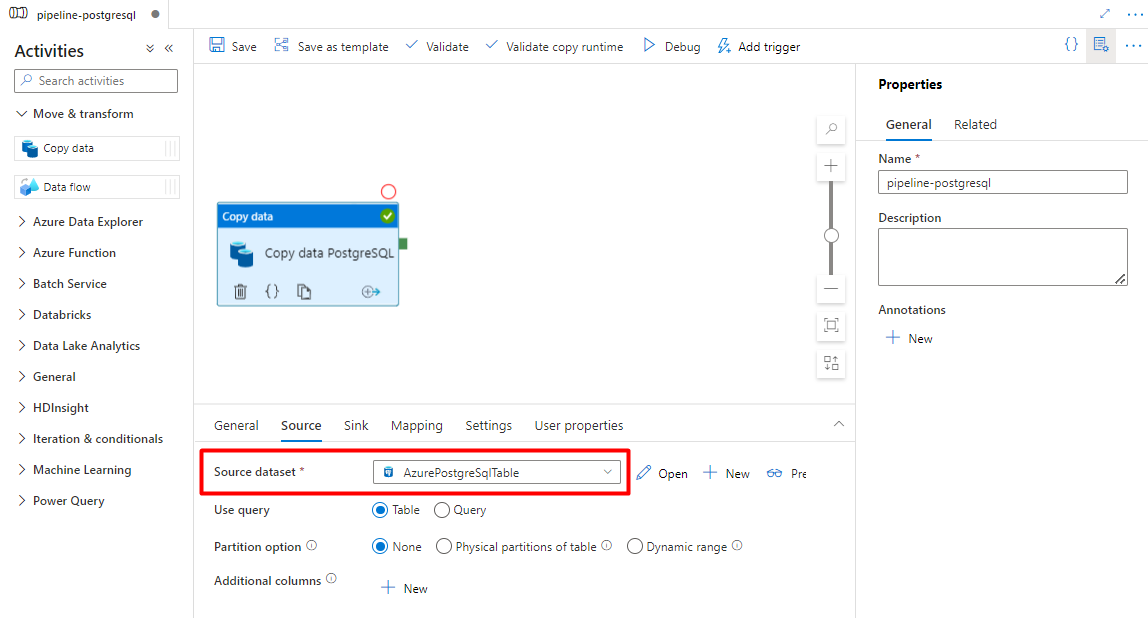
На вкладке "Sink":
Выберите набор данных PostgreSQL с разделителями хранилища, настроенный на шаге 7.
В расширении файла добавьте .csv
Оставьте остальные параметры значениями по умолчанию.
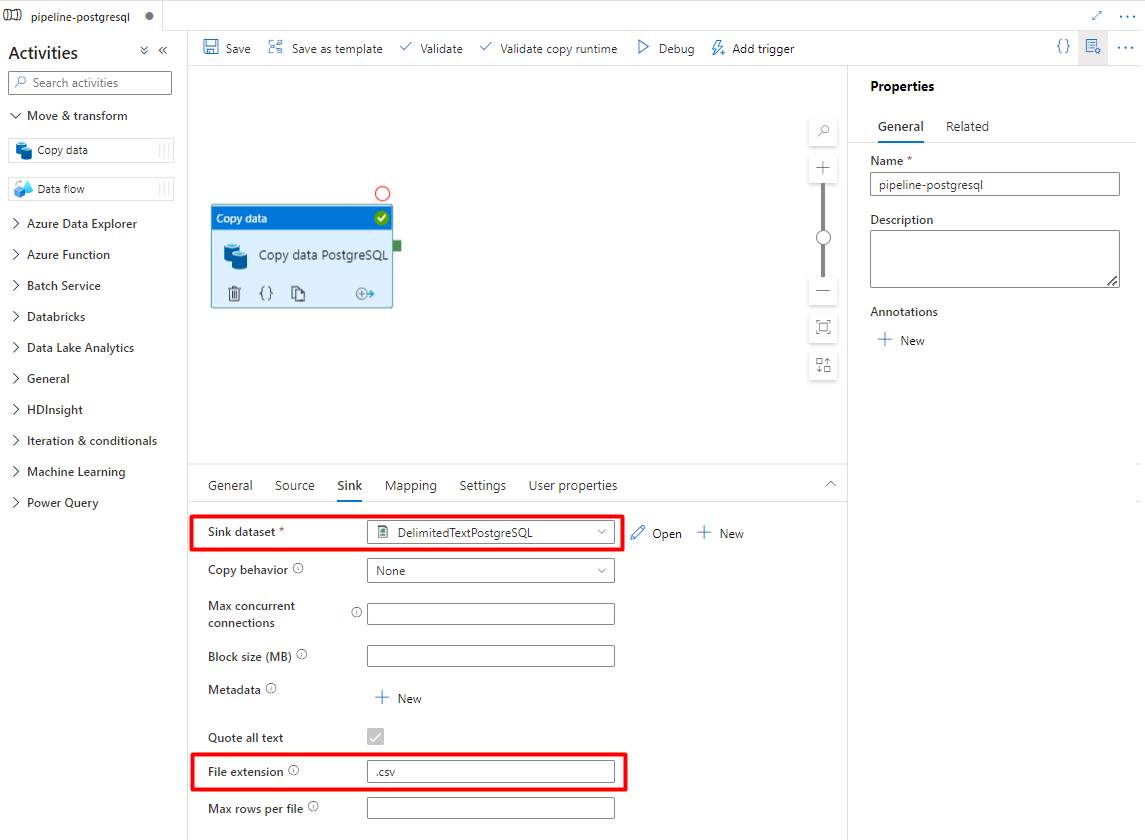
Выберите Сохранить.
Настройте действия, которые копируются из службы хранилища Azure в индекс поиска:
Разверните раздел перемещения и преобразования и перетащите действие копирования данных на пустой холст редактора конвейера.
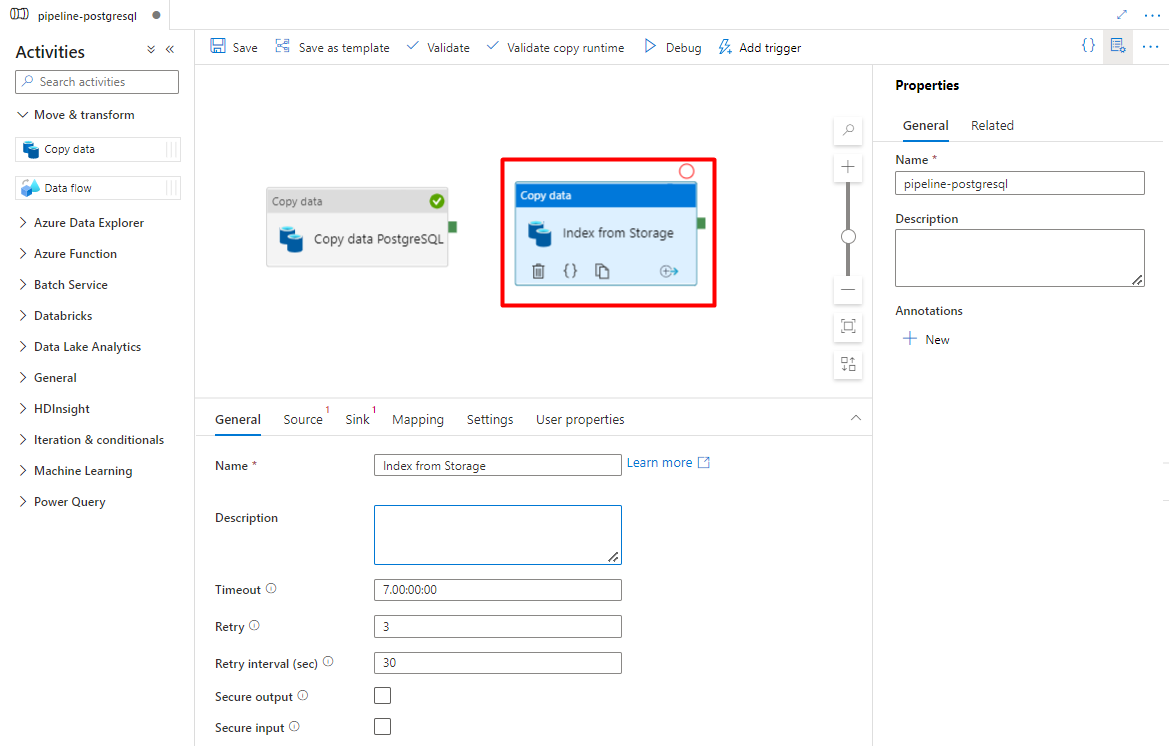
На вкладке "Общие " оставьте значения по умолчанию, если вам не нужно настраивать выполнение.
На вкладке "Источник":
- Выберите набор данных источника хранилища, настроенный на шаге 7.
- В поле Тип пути к файлу выберите Путь с подстановочными знаками.
- Оставьте все оставшиеся поля со значениями по умолчанию.
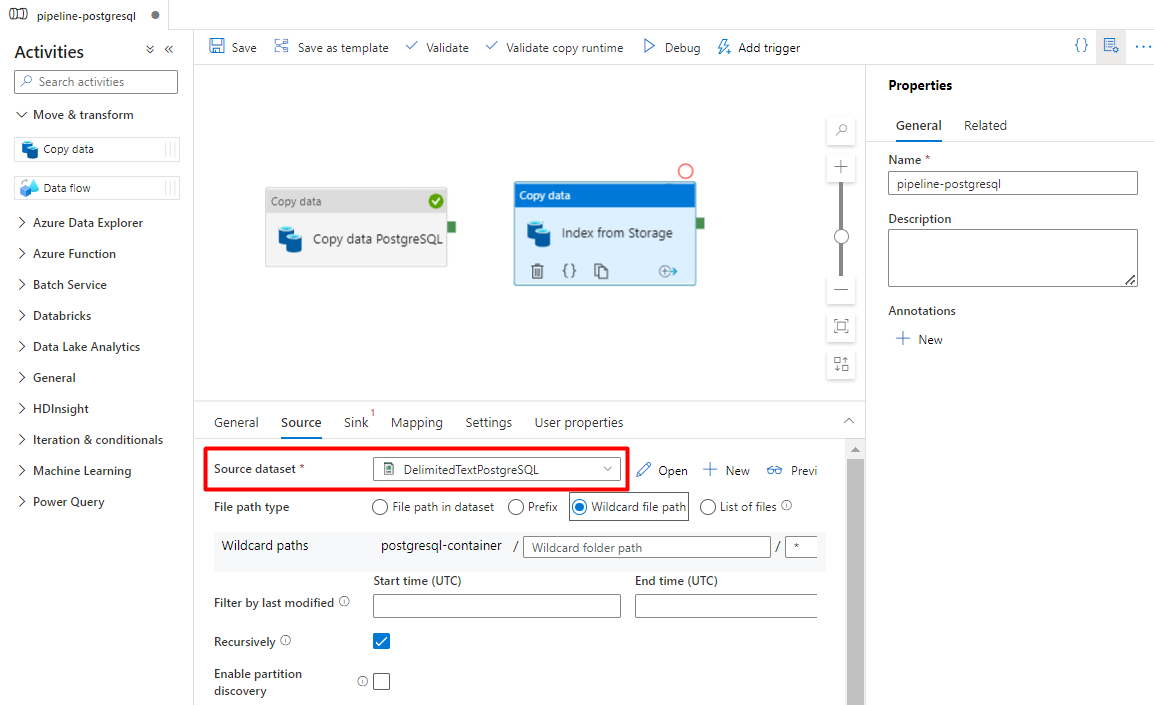
На вкладке Sink выберите индекс Когнитивного поиска Azure. Оставьте остальные параметры значениями по умолчанию.
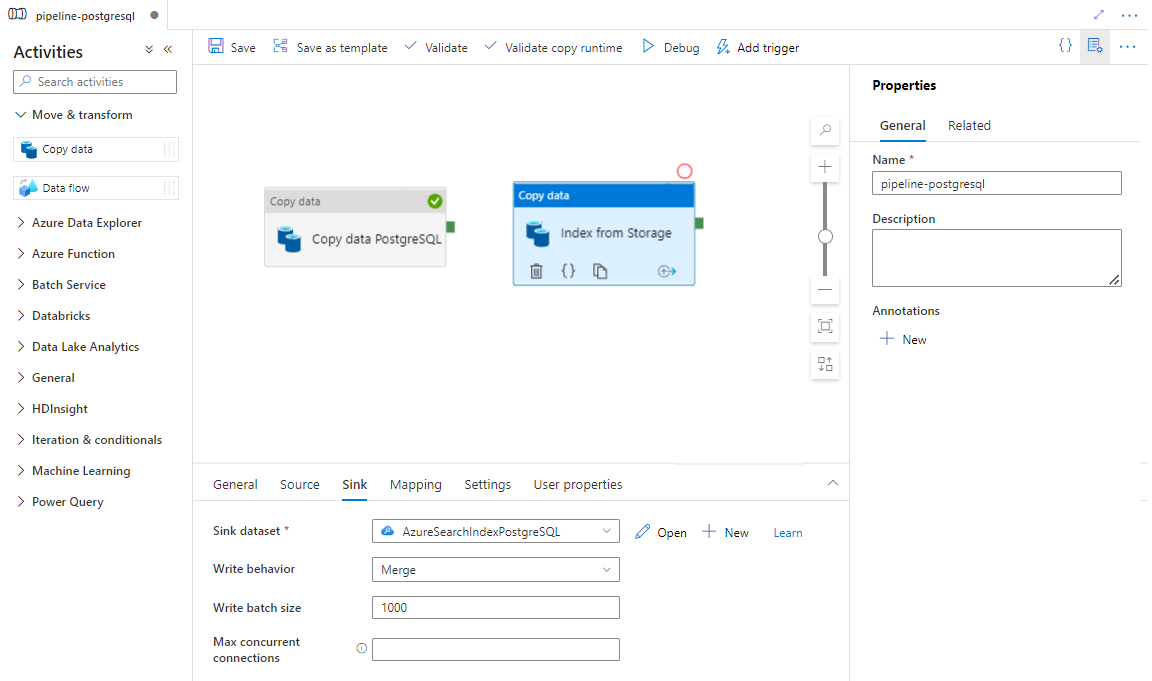
Выберите Сохранить.
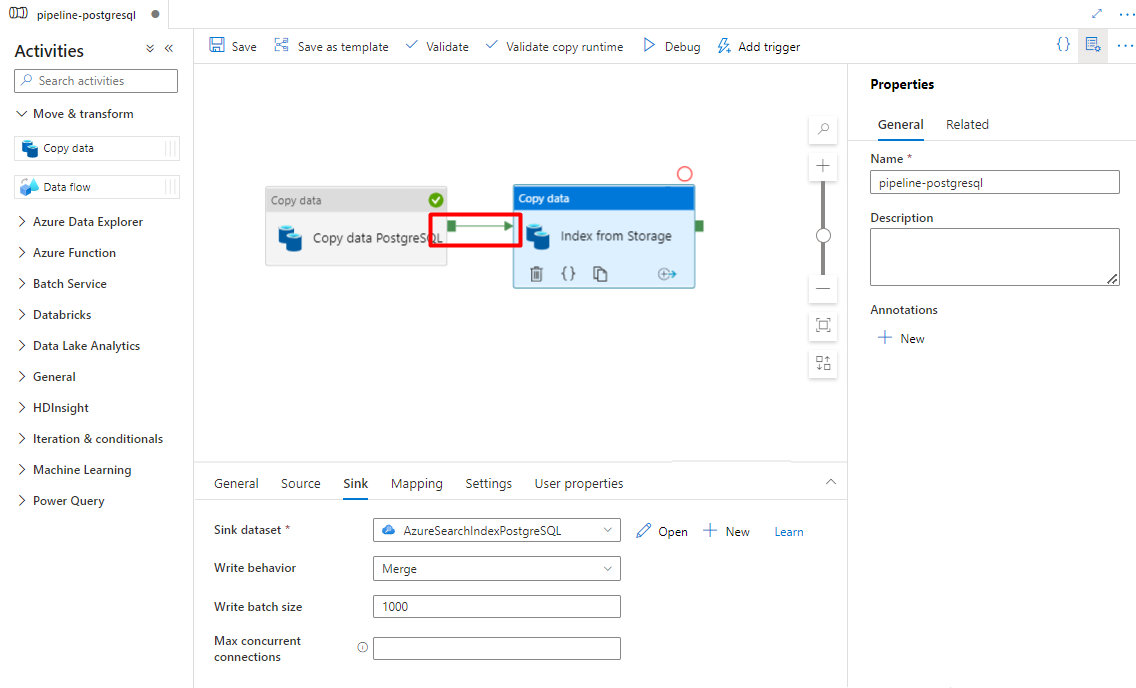
Шаг 9. Настройка порядка действий
В редакторе холста конвейера выберите маленький зеленый квадрат в краю действия конвейера. Перетащите его в действие "Индексы из учетной записи хранения в Когнитивный поиск Azure", чтобы задать порядок выполнения.
Выберите Сохранить.
Шаг 10. Добавление триггера конвейера
Выберите "Добавить триггер ", чтобы запланировать запуск конвейера, и выберите "Создать или изменить".
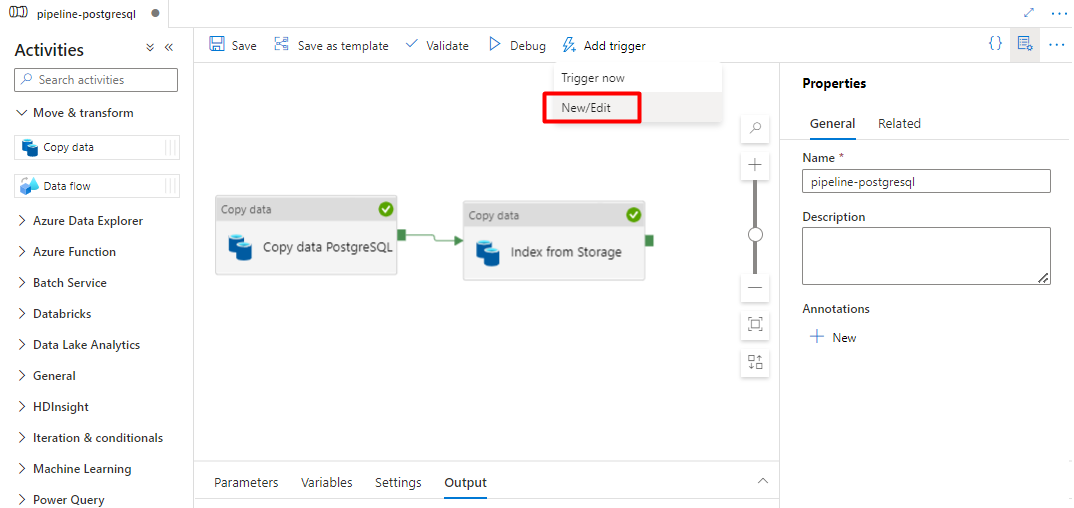
В раскрывающемся списке "Выбор триггера" нажмите кнопку "Создать".
Просмотрите параметры триггера для запуска конвейера и нажмите кнопку "ОК".
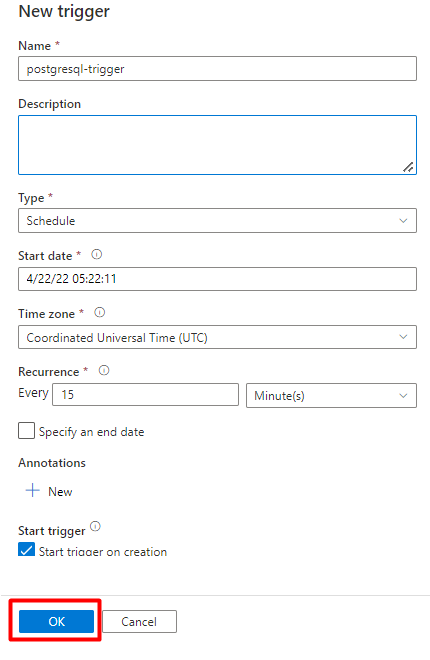
Выберите Сохранить.
Выберите Опубликовать.
Устаревшее содержимое для предварительной версии соединителя Power Query
Соединитель Power Query используется с индексатором поиска для автоматизации приема данных из различных источников данных, в том числе для других поставщиков облачных служб. Он использует Power Query для получения данных.
Источники данных, поддерживаемые в предварительной версии, включают:
- Amazon Redshift
- Elasticsearch
- PostgreSQL
- Объекты Salesforce
- Отчеты Salesforce
- Smartsheet
- Снежинка
Поддерживаемые функции
Соединители Power Query используются в индексаторах. Индексатор в Когнитивном поиске Azure — это обходчик, который извлекает искомые данные и метаданные из внешнего источника данных и заполняет индекс на основе сопоставлений полей между индексом и источником данных. Этот подход иногда называется "моделью извлечения", так как служба извлекает данные без необходимости писать код, добавляющий данные в индекс. Индексаторы предоставляют удобный способ для пользователей индексировать содержимое из своего источника данных без необходимости самим разрабатывать поискового робота или модель отправки данных.
Индексаторы, ссылающиеся на источники данных Power Query, имеют тот же уровень поддержки наборов навыков, расписаний, логики обнаружения изменений высокого уровня и большинства параметров, которые поддерживают другие индексаторы.
Предпосылки
Хотя вы больше не можете использовать эту функцию, она имела следующие требования во время предварительной версии:
Служба Когнитивного поиска Azure в поддерживаемом регионе.
Предварительная регистрация. Эта функция должна быть включена на серверной части.
Учетная запись хранения объектов BLOB Azure, используемая в качестве промежуточного решения для данных. Данные будут передаваться из источника данных, а затем в хранилище BLOB-объектов, а затем в индекс. Это требование действует только для первой ограниченной предварительной версии.
Региональная доступность
Предварительная версия доступна только в службах поиска в следующих регионах:
- Центральная часть США
- Восточная часть США
- Восточная часть США 2
- Центрально-северная часть США
- Северная Европа
- Центрально-южная часть США
- Центрально-западная часть США
- Западная Европа
- Западная часть США
- Западная часть США 2
Ограничения предварительной версии
В этом разделе описываются ограничения, относящиеся к текущей версии предварительной версии.
Извлечение двоичных данных из источника данных не поддерживается.
Сеанс отладки не поддерживается.
Начало работы с порталом Azure
Портал Azure предоставляет поддержку соединителей Power Query. С помощью данных выборки и чтения метаданных в контейнере мастер импорта данных в Когнитивном поиске Azure может создать индекс по умолчанию, сопоставить исходные поля с целевыми полями индекса и загрузить индекс в одну операцию. В зависимости от размера и сложности исходных данных, у вас может быть готовый индекс полнотекстового поиска всего за считанные минуты.
В следующем видео показано, как настроить соединитель Power Query в Когнитивном поиске Azure.
Шаг 1. Подготовка исходных данных
Убедитесь, что источник данных содержит данные. Мастер импорта данных считывает метаданные и выполняет выборку данных для вывода схемы индекса, но также загружает данные из источника данных. Если данные отсутствуют, мастер остановится и выдаст ошибку.
Шаг 2. Запуск мастера импорта данных
После утверждения предварительной версии команда Когнитивного поиска Azure предоставит вам ссылку на портал Azure, использующую флаг функции, чтобы получить доступ к соединителям Power Query. Откройте эту страницу и запустите мастер с панели команд на странице службы "Когнитивный поиск Azure", выбрав "Импорт данных".
Шаг 3. Выбор источника данных
Существует несколько источников данных, которые можно извлечь из этой предварительной версии. Все источники данных, использующие Power Query, будут содержать элемент Powered By Power Query на плитке. Выберите источник данных.
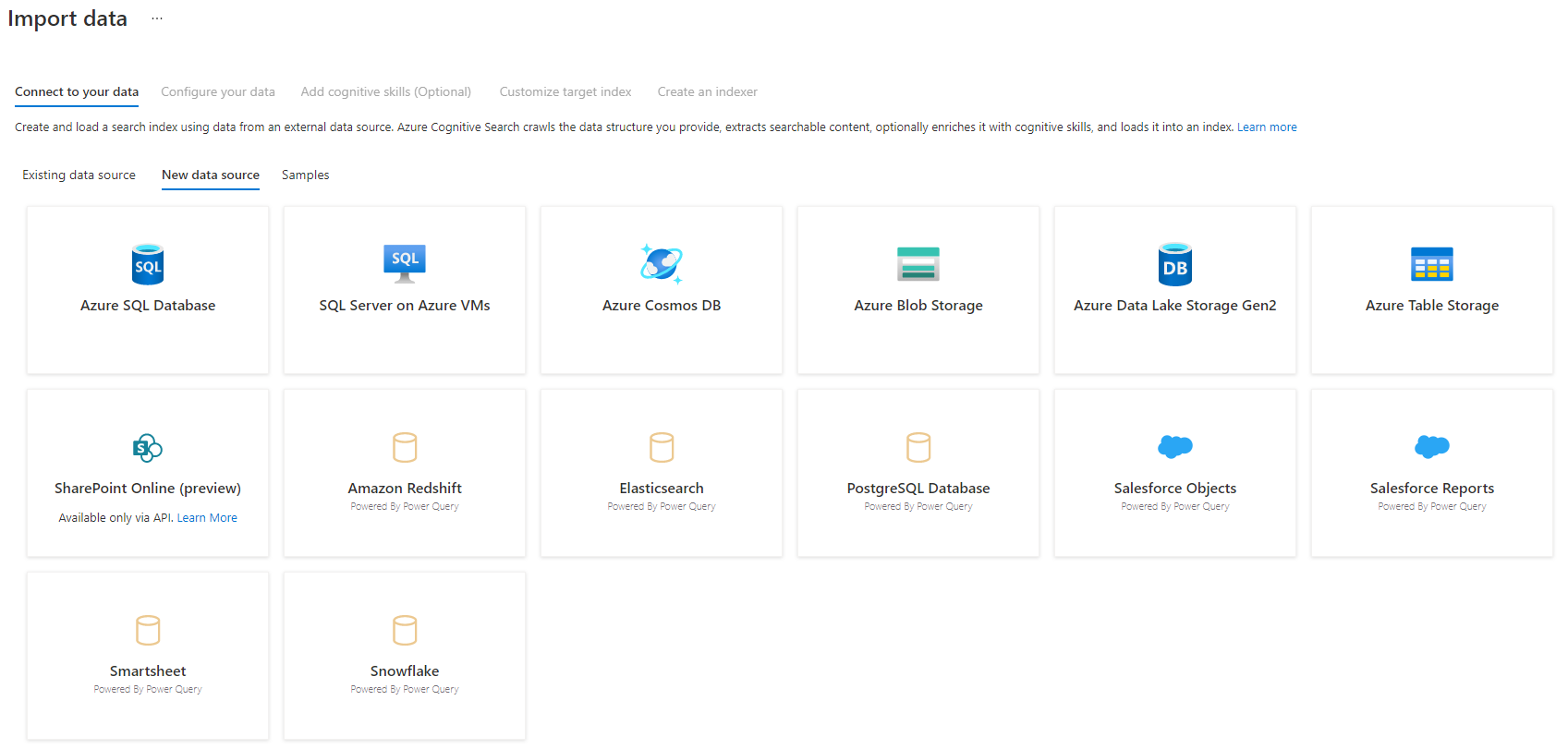
После выбора источника данных нажмите кнопку Далее: настройте данные , чтобы перейти к следующему разделу.
Шаг 4. Настройка данных
На этом шаге вы настроите подключение. Для каждого источника данных потребуются разные сведения. Для некоторых источников данных документация Power Query предоставляет более подробные сведения о том, как подключиться к вашим данным.
После предоставления учетных данных подключения нажмите кнопку "Далее".
Шаг 5. Выбор данных
Мастер импорта будет просматривать различные таблицы, доступные в источнике данных. На этом шаге вы проверите одну таблицу, содержащую данные, которые необходимо импортировать в индекс.
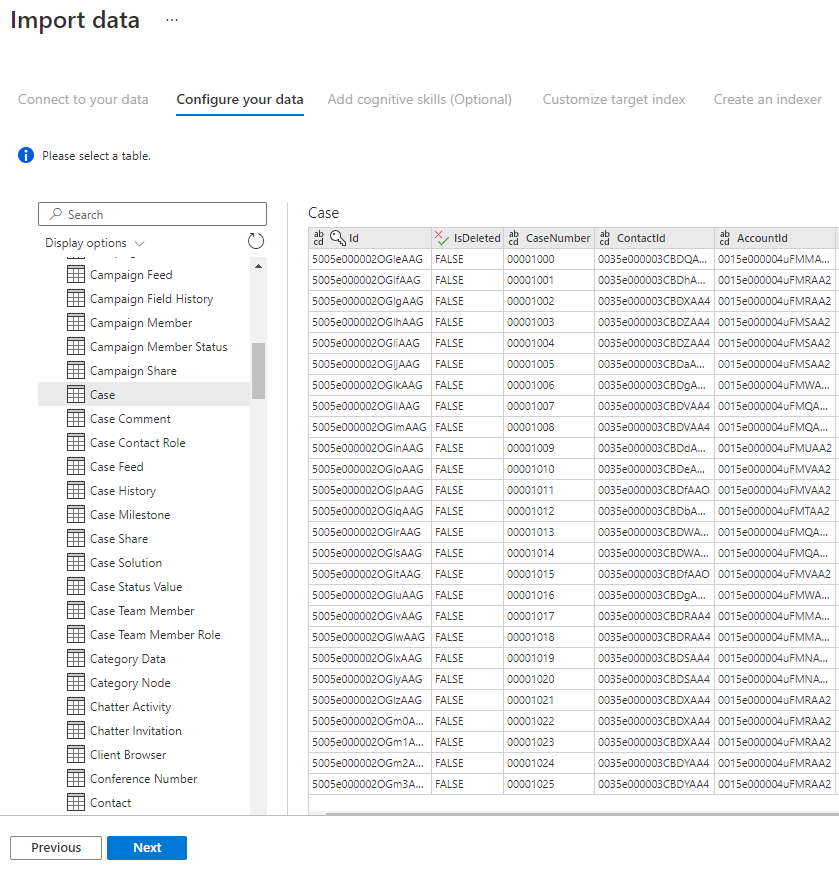
Выбрав таблицу, нажмите кнопку "Далее".
Шаг 6. Преобразование данных (необязательно)
Соединители Power Query предоставляют широкий интерфейс пользовательского интерфейса, который позволяет управлять данными, чтобы отправлять правильные данные в индекс. Можно удалить столбцы, отфильтровать строки и многое другое.
Перед импортом данных в Когнитивный поиск Azure не требуется преобразовывать данные.
Дополнительные сведения о преобразовании данных с помощью Power Query см. в разделе "Использование Power Query" в Power BI Desktop.
После преобразования данных нажмите кнопку "Далее".
Шаг 7. Добавление хранилища BLOB-объектов Azure
В предварительной версии соединителя Power Query на данный момент требуется предоставить учетную запись объектного хранилища BLOB. Этот шаг существует только на этапе начального ограниченного просмотра. Эта учетная запись хранилища BLOB-объектов будет служить временным хранилищем для данных, перемещающихся из источника данных в индекс Когнитивного поиска Azure.
Рекомендуется предоставить строку подключения учетной записи хранения с полным доступом:
{ "connectionString" : "DefaultEndpointsProtocol=https;AccountName=<your storage account>;AccountKey=<your account key>;" }
Строку подключения можно получить на портале Azure, перейдя к колонке > "Параметры > учетной записи хранения" (для классических учетных записей хранения) или > "Параметры доступа" (для учетных записей хранения Azure Resource Manager).
После указания имени источника данных и строки подключения нажмите кнопку "Далее: Добавить когнитивные навыки (необязательно)".
Шаг 8. Добавление когнитивных навыков (необязательно)
Обогащение ИИ — это расширение индексаторов, которые можно использовать для повышения возможностей поиска содержимого.
Вы можете добавить любые обогащения, которые добавляют преимущества в ваш сценарий. По завершении нажмите кнопку Далее: настроить целевой индекс.
Шаг 9. Настройка целевого индекса
На странице индекса вы увидите список полей с типом данных и рядом флажков для задания атрибутов индекса. Мастер может создать список полей на основе метаданных и выборки исходных данных.
Вы можете массово выбрать атрибуты, установив флажок в верхней части столбца атрибутов. Выберите "Доступное" и "Поисковое" для каждого поля, которое должно быть возвращено клиентскому приложению и подлежит полнотекстовой обработке поиска. Вы заметите, что целые числа не подлежат полнотекстовому или нечеткому поиску (числа рассматриваются дословно и часто полезны в фильтрах).
Дополнительные сведения см. в описании атрибутов индекса и анализаторов языка.
Ознакомьтесь с выбранными вариантами. После запуска мастера создаются структуры физических данных, и вы не сможете изменять большинство свойств для этих полей, не удаляя и не создавая все объекты.
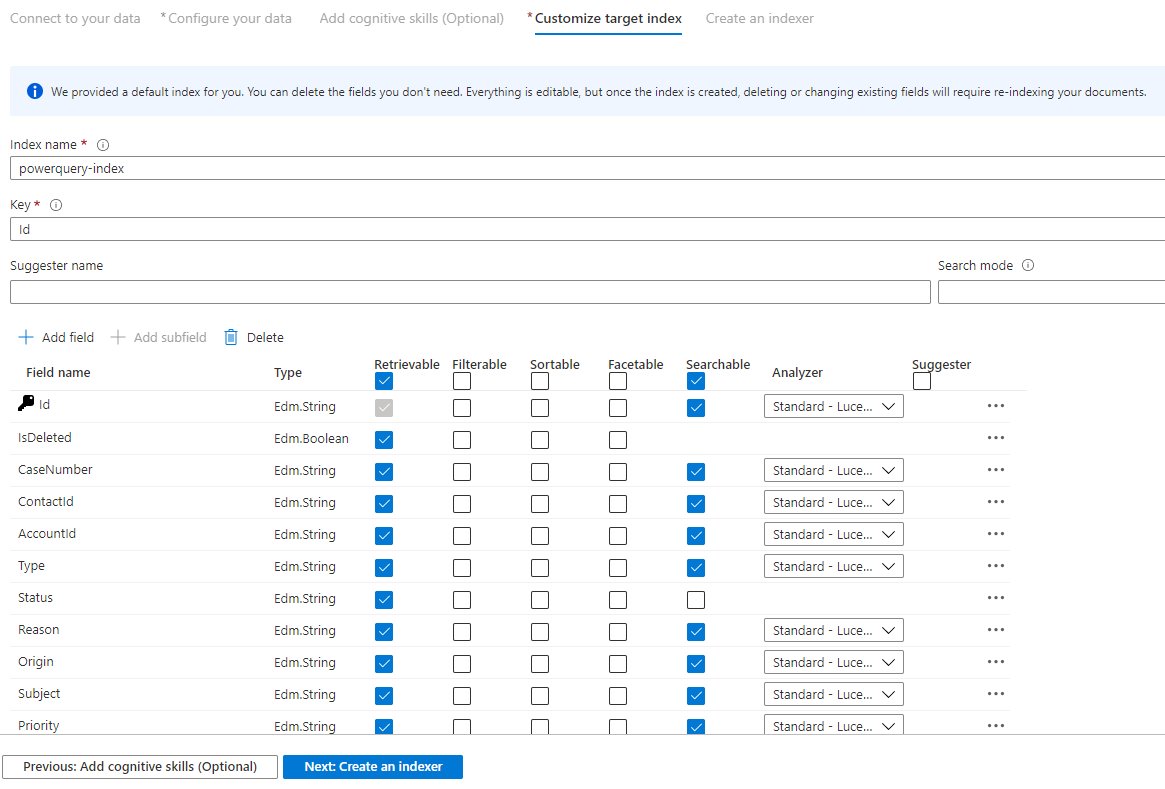
По завершении нажмите кнопку "Далее: создать индексатор".
Шаг 10. Создание индексатора
Последний шаг создает индексатор. Именование индексатора позволяет ему существовать как самостоятельному ресурсу, которым можно управлять и запланировать независимо от объекта индекса и объекта источника данных, созданного в той же последовательности мастера.
Выходные данные мастера импорта данных — это индексатор, который выполняет обход источника данных и импортирует данные, выбранные в индекс в Когнитивном поиске Azure.
При создании индексатора можно при необходимости запустить индексатор по расписанию и добавить обнаружение изменений. Чтобы добавить обнаружение изменений, назначьте столбец "контрольная метка".
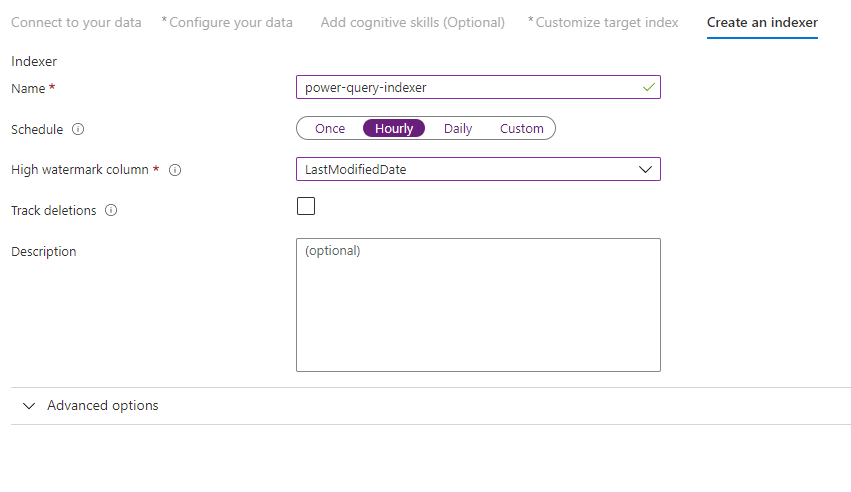
После завершения заполнения этой страницы нажмите кнопку "Отправить".
Политика обнаружения изменений уровня контрольной точки
Эта политика обнаружения изменений зависит от столбца с контрольной меткой, фиксирующего версию или время последнего обновления строки.
Требования
- Все вставки указывают значение для столбца.
- при всех обновлениях элементов также изменяется значение столбца;
- значение этого столбца растет с каждой вставкой или обновлением;
Неподдерживаемые имена столбцов
Имена полей в индексе Когнитивного поиска Azure должны соответствовать определенным требованиям. Одним из этих требований является то, что некоторые символы, такие как "/", не допускаются. Если имя столбца в базе данных не соответствует этим требованиям, обнаружение схемы индекса не распознает столбец как допустимое имя поля, и вы не увидите, что столбец указан в качестве предлагаемого поля для индекса. Как правило, использование сопоставлений полей решает эту проблему, но сопоставления полей не поддерживаются на портале.
Чтобы индексировать содержимое из столбца в таблице с неподдерживаемым именем поля, переименуйте столбец во время этапа преобразования данных импорта. Например, можно переименовать столбец с именем "Код выставления счетов/ZIP-код" в "zipcode". При переименовании столбца обнаружение схемы индекса распознает его как допустимое имя поля и добавит его в качестве предложения в определение индекса.
Дальнейшие действия
В этой статье объясняется, как извлекать данные с помощью соединителей Power Query. Так как эта предварительная версия отключена, она также объясняет, как перенести существующие решения в поддерживаемый сценарий.
Чтобы узнать больше об индексаторах, см. "Индексаторы в Когнитивном поиске Azure".