Примечание.
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
В этом документе содержатся рекомендации, основанные на практическом опыте, по восстановлению данных Fabric в случае региональной катастрофы.
Пример сценария
Многие разделы руководства в этом документе используют следующий пример сценария для объяснения и иллюстрации. При необходимости обратитесь к этому сценарию.
Предположим, что у вас есть емкость C1 в регионе A с рабочей областью W1. Если вы включили аварийное восстановление для емкости C1, данные OneLake реплицируются в резервную копию в регионе B. Если регион A сталкивается с нарушениями, служба Fabric в C1 осуществляет переключение на регион B.
Примечание.
Это руководство по восстановлению применяется только в том случае, если основной регион имеет Azure-парный дополнительный регион и Fabric поддерживается в парном регионе.
Этот сценарий показан на следующем рисунке. В поле слева отображается нарушенный регион. Блок в середине представляет постоянную доступность данных после отработки отказа, а блок справа показывает полностью покрытую ситуацию после того, как клиент предпринимает действия по восстановлению служб до полной функциональности.
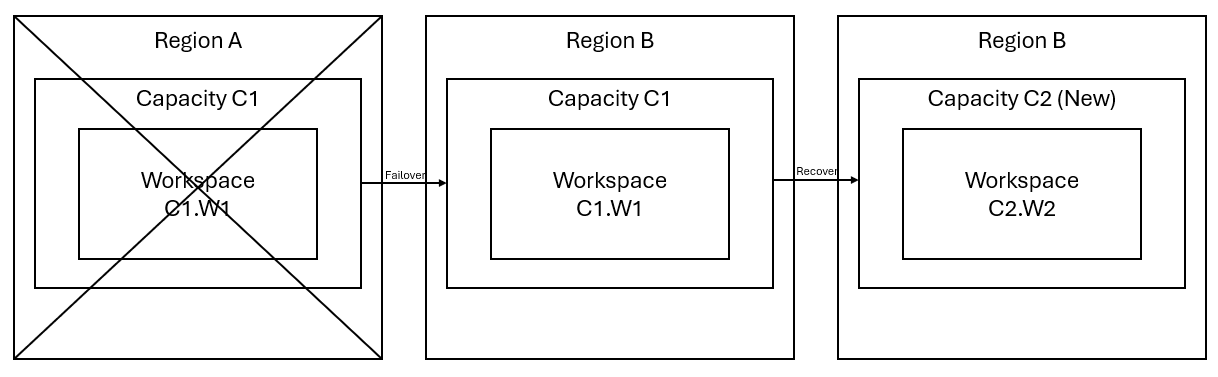
Ниже приведен общий план восстановления:
Создайте новую емкость Fabric C2 в новом регионе.
Создайте новую рабочую область W2 в C2, включая соответствующие элементы с теми же именами, что и в C1. W1.
Скопируйте данные из сбойного C1.W1 в C2.W2.
Следуйте выделенным инструкциям для каждого компонента, чтобы восстановить элементы до полной функции.
Этот план восстановления предполагает, что домашний регион клиента остается рабочим. Если в домашнем регионе клиента возникает сбой, шаги, описанные в этом документе, зависят от его восстановления, которые должны быть сначала инициированы и завершены Microsoft.
Планы восстановления, специфичные для опыта
В следующих разделах приведены пошаговые руководства по каждому интерфейсу Fabric, помогающие клиентам в процессе восстановления.
Инжиниринг данных
В этом руководстве описаны процедуры восстановления для интерфейса Инжиниринг данных. В ней рассматриваются архитектуры lakehouse, записные книжки и определения заданий Spark.
Лэйкхаус
Дома у озера из исходного региона остаются недоступными для заказчиков. Чтобы восстановить lakehouse (озерохранилище), клиенты могут повторно создать его в рабочей области C2.W2. Мы рекомендуем два подхода для восстановления лейкхаусов:
Подход 1. Использование пользовательского скрипта для копирования таблиц и файлов Delta Lakehouse
Клиенты могут воссоздать lakehouses, используя пользовательский скрипт на Scala.
Создайте lakehouse (например, LH1) в недавно созданной рабочей области C2.W2.
Создайте записную книжку в рабочей области C2. W2.
Чтобы восстановить таблицы и файлы из исходного lakehouse, обратитесь к данным с путями OneLake, такими как abfss (см. Connecting to Microsoft OneLake). В следующем примере кода (см. раздел Введение в служебные программы Microsoft Spark) в блокноте, чтобы получить пути ABFS файлов и таблиц из исходного озера-хранилища данных. (Замените C1. W1 с фактическим именем рабочей области)
notebookutils.fs.ls('abfs[s]://<C1.W1>@onelake.dfs.fabric.microsoft.com/<item>.<itemtype>/<Tables>/<fileName>')Используйте следующий пример кода для копирования таблиц и файлов в недавно созданный lakehouse.
Для таблиц Delta необходимо скопировать таблицу по одному за раз, чтобы восстановиться в новом лейкхаусе. В случае файлов Lakehouse можно скопировать полную структуру файлов со всеми базовыми папками с одним выполнением.
Обратитесь в службу поддержки, чтобы получить метку времени для переключения на резервную систему, необходимую в скрипте.
%%spark val source="abfs path to original Lakehouse file or table directory" val destination="abfs path to new Lakehouse file or table directory" val timestamp= //timestamp provided by Support notebookutils.fs.cp(source, destination, true) val filesToDelete = notebookutils.fs.ls(s"$source/_delta_log") .filter{sf => sf.isFile && sf.modifyTime > timestamp} for(fileToDelete <- filesToDelete) { val destFileToDelete = s"$destination/_delta_log/${fileToDelete.name}" println(s"Deleting file $destFileToDelete") notebookutils.fs.rm(destFileToDelete, false) } notebookutils.fs.write(s"$destination/_delta_log/_last_checkpoint", "", true)После запуска скрипта таблицы отображаются в новом lakehouse.
Подход 2. Использование Обозреватель службы хранилища Azure для копирования файлов и таблиц
Чтобы восстановить только определенные файлы или таблицы Lakehouse из оригинального Lakehouse, используйте Обозреватель службы хранилища Azure. Подробные инструкции см. в статье Integrate OneLake с помощью Обозреватель службы хранилища Azure. Для больших размеров данных используйте подход 1.
Примечание.
Два подхода, описанные выше, восстанавливают и метаданные, и данные для таблиц, форматированных в Delta, так как метаданные находятся и хранятся вместе с данными в OneLake. Для таблиц, не относящихся к разностным форматам (например, CSV, Parquet и т. д.), созданных с помощью скриптов и команд языка определения данных Spark (DDL), пользователь отвечает за обслуживание и повторное выполнение скриптов и команд Spark DDL для их восстановления.
Восстановление Fabric материализованных представлений озера
Материализованные представления Lake из исходного региона остаются недоступными для клиентов после отработки отказа. Расписания обновления и история выполнения не реплицируются в вторичный регион. Чтобы восстановить их, выполните следующие действия после восстановления данных Lakehouse.
- Восстановите таблицы Lakehouse с помощью метода 1 или подхода 2, описанного выше. Скопируйте только исходные таблицы.
- Восстановите записные книжки, содержащие определения MLV. Обратитесь к разделу "Ноутбук" для действий по восстановлению.
- Запустите восстановленные записные книжки для повторного создания MLV в новом Lakehouse. Сведения о создании материализованных представлений озера см. в разделе Создание материализованного представления озера. Если на предыдущем шаге также были скопированы MLVs, выполните команду CREATE OR REPLACE в процессе их воссоздания.
- Повторно создайте расписания обновления MLV вручную в новой рабочей области. Журнал расписания и метрики выполнения не восстанавливаются.
- Если ваши MLVs используются для наполнения семантических моделей или отчетов, проверьте и обновите ссылки на идентификатор Lakehouse и идентификатор набора данных при необходимости. Повторно подключите отчеты к обновленной семантической модели и проверьте свежесть данных.
Подсказка
Чтобы свести к минимуму изменения кода при выполнении записных книжек после отказа, используйте те же имена рабочей области и Lakehouse в новом регионе (особенно при использовании имени рабочей области или Lakehouse в правилах именования). Расписания обновления, история выполнения и операционные метрики начинаются заново в восстановленном регионе. Запланируйте базовый период при создании новых пороговых значений мониторинга.
Записная книжка
Записные книжки из основного региона остаются недоступными для клиентов, а код в записных книжках не реплицируется в дополнительный регион. Чтобы восстановить код записной книжки в новом регионе, существует два подхода к восстановлению содержимого кода записной книжки.
Подход 1. Избыточность, управляемая пользователем, с интеграцией Git (в общедоступной предварительной версии)
Лучший способ сделать это легко и быстро — использовать интеграцию с Fabric Git, а затем синхронизировать вашу записную книжку с репозиторием Azure DevOps. После переключения службы на другой регион можно использовать репозиторий для перестроения записной книжки в новой рабочей области, которую вы создали.
Настройте интеграцию Git для вашей рабочей среды и выберите Подключиться и синхронизировать с репозиторием ADO.

На следующем рисунке показана синхронизированная записная книжка.

Восстановите записную книжку из репозитория ADO.
В созданной рабочей области снова подключитесь к репозиторию ADO Azure.

Выберите кнопку управления версиями. Затем выберите соответствующую ветвь репозитория. Затем нажмите кнопку "Обновить все". Появится исходная записная книжка.
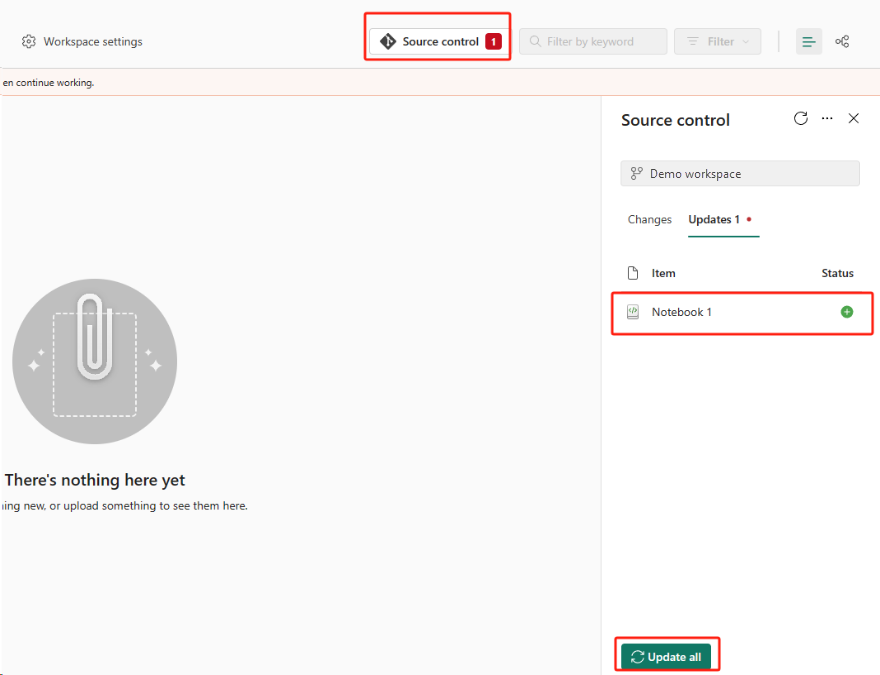

Если исходная записная книжка имеет озеро по умолчанию, пользователи могут обратиться к разделу Lakehouse, чтобы восстановить озеро, а затем подключить только что восстановленный lakehouse к вновь восстановленной записной книжке.

Интеграция Git не поддерживает синхронизацию файлов, папок или моментальных снимков записных книжек в обозревателе ресурсов записной книжки.
Если исходная записная книжка содержит файлы в обозревателе ресурсов записной книжки:
Не забудьте сохранить файлы или папки на локальный диск или в другом месте.
Повторно отправьте файл с локального диска или облачных дисков в восстановленную записную книжку.
Если в исходной записной книжке есть моментальный снимок записной книжки, сохраните моментальный снимок записной книжки в собственной системе управления версиями или локальном диске.


Дополнительные сведения об интеграции с Git см. в статье "Введение в интеграцию с Git".
Подход 2. Ручной подход к резервному копированию содержимого кода
Если вы не используете подход к интеграции с Git, вы можете сохранить последнюю версию кода, файлы в обозревателе ресурсов и моментальный снимок записной книжки в системе управления версиями, например Git, и вручную восстановить содержимое записной книжки после аварии:
Используйте функцию импорта записной книжки для импорта кода записной книжки, который требуется восстановить.

После импорта перейдите в нужную рабочую область (например, "C2". W2") для доступа к нему.
Если исходная записная книжка имеет озеро по умолчанию, обратитесь к разделу Lakehouse. Затем подключите вновь восстановленный lakehouse (с тем же содержимым, что и оригинальный lakehouse по умолчанию) к восстановленной записной книжке.
Если исходная записная книжка содержит файлы или папки в обозревателе ресурсов, повторно отправьте файлы или папки, сохраненные в системе управления версиями пользователя.
Определение задания Spark
Определения заданий Spark (SJD) из основного региона остаются недоступными для клиентов, а основной файл определения и файл ссылок в записной книжке будут реплицированы в дополнительный регион через OneLake. Если вы хотите восстановить SJD в новом регионе, выполните описанные ниже действия, чтобы восстановить SJD. Исторические запуски SJD не будут восстановлены.
Чтобы восстановить элементы SJD, скопируйте код из исходного региона с помощью Обозреватель службы хранилища Azure и вручную переподключите ссылки Lakehouse после аварии.
Создайте новый элемент SJD (например, SJD1) в новой рабочей области C2. W2 с теми же параметрами и конфигурациями, что и исходный элемент SJD (например, язык, среда и т. д.).
Используйте Обозреватель службы хранилища Azure для копирования Libs, Mains и моментальных снимков из исходного элемента SJD в новый элемент SJD.

Содержимое кода появится в только что созданном SJD. Вам потребуется вручную добавить ссылку на только что восстановленный Lakehouse в задание (см. инструкции по восстановлению Lakehouse). Пользователям потребуется повторно ввести исходные аргументы командной строки вручную.

Теперь вы можете запустить или запланировать только что восстановленный SJD.
Дополнительные сведения об Обозреватель службы хранилища Azure см. в разделе Интеграция OneLake с Обозреватель службы хранилища Azure.
GraphQL
Элементы GraphQL из основного региона недоступны после региональной аварии, а определения и конфигурации GraphQL не реплицируются в дополнительный регион. Чтобы восстановить GraphQL в новом регионе, используйте один из следующих подходов.
Подход 1. Избыточность, управляемая пользователем, с интеграцией Git (в общедоступной предварительной версии)
Лучший способ упростить этот процесс и быстро — использовать Fabric интеграцию Git, а затем синхронизировать GraphQL с репозиторием ADO. После переключения службы на другой регион вы можете использовать репозиторий, чтобы пересобрать GraphQL в новой рабочей области, которую вы создали.
Создайте новую рабочую область в целевой емкости и регионе.
Восстановите все зависимые источники данных, такие как Lakehouse, Warehouse или базы данных SQL, выполнив соответствующие действия по восстановлению.
Обновите определение GraphQL, чтобы указать на вновь восстановленные ресурсы, изменив ссылки для конкретной среды, такие как идентификаторы исходной рабочей области, идентификаторы исходных артефактов и сведения о подключении. Этот шаг гарантирует правильную привязку во время развертывания.
Повторное развертывание артефактов GraphQL из репозитория Git в новую рабочую область. Этот шаг воссоздает структуру и конфигурацию API с помощью обновленных определений.
Повторно примените параметры артефактов, включая роли, параметры управления доступом и конфигурацию аутентификации.
Повторно настройте ссылки на конечную точку, обновив все приложения и интеграции для использования новой конечной точки GraphQL.
Обновите все существующие конвейеры развертывания, которые указывали на старую рабочую область, чтобы они ссылались на вновь созданную рабочую область.
Проверьте сквозную функциональность API.
Подход 2. Подход вручную
Если вы не используете подход к интеграции с Git, можно использовать следующий подход вручную для восстановления GraphQL.
Создайте новую рабочую область в целевой емкости и регионе.
Восстановление всех зависимых источников данных, таких как Lakehouse, Warehouse или базы данных SQL.
Повторно создайте API GraphQL вручную в новой рабочей области, включая определения схемы, подключения к источнику данных и связи.
Повторно примените параметры артефактов, включая роли, параметры управления доступом и конфигурацию аутентификации.
Повторно настройте ссылки на конечную точку, обновив все приложения и интеграции для использования новой конечной точки GraphQL.
Обновите все существующие конвейеры развертывания, которые указывали на старую рабочую область, чтобы они ссылались на вновь созданную рабочую область.
Проверьте сквозную функциональность API.
Важные замечания
GraphQL использует внешние зависимости (например, Lakehouse, Warehouse и SQL), которые необходимо восстановить до развертывания GraphQL.
Определения GraphQL API включают ссылки, специфичные для среды (например,
sourceWorkspaceIdиsourceItemId). При восстановлении в новом регионе эти ссылки могут стать недопустимыми. Обновите их, чтобы они указывали на вновь подготовленные ресурсы.Автоматическое повторное связывание источников данных не гарантируется в сценариях аварийного восстановления, особенно при использовании сохраненных учетных данных или подключений между рабочими областями.
Другие параметры артефакта, такие как мониторинг, авторизация, RBAC, интроспекция и т. д., не сохраняются при переключении при отказе. Эти параметры необходимо повторно установить в новом регионе.
References
Обзор интеграции Fabric Git — Microsoft Fabric | Microsoft Learn
Управление версиями и конвейеры развертывания в API GraphQL — Microsoft Fabric | Microsoft Learn
Обработка и анализ данных
В этом руководстве описаны процедуры восстановления для опыта использования Data Science. В нем рассматриваются модели машинного обучения и эксперименты.
Модель машинного обучения и эксперимент
Элементы науки о данных из основного региона остаются недоступными для клиентов, а содержимое и метаданные в моделях машинного обучения и экспериментах не будут реплицироваться во вторичный регион. Чтобы полностью восстановить их в новом регионе, сохраните содержимое кода в системе управления версиями (например, Git) и повторно запустите содержимое кода после аварии.
Восстановите записную книжку. Ознакомьтесь с инструкциями по восстановлению записной книжки.
Конфигурация, исторические метрики и метаданные не будут копироваться в парный регион. Вам придется повторно запустить каждую версию кода для обработки и анализа данных, чтобы полностью восстановить модели машинного обучения и эксперименты после аварии.
Хранилище данных
В этом руководстве описаны процедуры восстановления для интерфейса Data Warehouse. Он охватывает склады.
Склад
Склады из исходного региона остаются недоступными для клиентов. Чтобы восстановить склады, выполните следующие два шага.
Создайте промежуточное озеро в рабочей области C2. W2 для данных, которые будут скопированы из исходного хранилища.
Заполните таблицы Delta хранилища, используя Warehouse Explorer и возможности T-SQL (см. Таблицы в хранилище данных в Microsoft Fabric).
Примечание.
Рекомендуется, чтобы вы держали код вашего хранилища (схему, таблицу, представление, хранимую процедуру, определения функций и коды безопасности) версиированным и сохраняли в безопасном месте (например, Git) в соответствии с вашими практиками разработки.
Прием данных с помощью кода Lakehouse и T-SQL
В созданной рабочей области C2. W2:
Создайте промежуточный озерный дом "LH2" в C2. W2.
Восстановите таблицы Delta в промежуточном lakehouse из исходного хранилища данных, выполнив шаги по восстановлению Lakehouse.
Создайте хранилище "WH2" в C2. W2.
Подключите промежуточное озеро в обозревателе хранилища.
В зависимости от способа развертывания определений таблиц перед импортом данных фактический T-SQL, используемый для импорта, может отличаться. Вы можете использовать метод INSERT INTO, SELECT INTO или CREATE TABLE AS SELECT для восстановления таблиц хранилища из lakehouses. Далее в примере мы будем использовать в качестве варианта INSERT INTO. (Если вы используете приведенный ниже код, замените примеры фактическими именами таблиц и столбцов)
USE WH1 INSERT INTO [dbo].[aggregate_sale_by_date_city]([Date],[City],[StateProvince],[SalesTerritory],[SumOfTotalExcludingTax],[SumOfTaxAmount],[SumOfTotalIncludingTax], [SumOfProfit]) SELECT [Date],[City],[StateProvince],[SalesTerritory],[SumOfTotalExcludingTax],[SumOfTaxAmount],[SumOfTotalIncludingTax], [SumOfProfit] FROM [LH11].[dbo].[aggregate_sale_by_date_city] GOНаконец, измените строка подключения в приложениях, использующих хранилище Fabric.
Примечание.
Для клиентов, которым требуется межрегиональное аварийное восстановление и полностью автоматизированная непрерывность бизнес-процессов, рекомендуется поддерживать две настройки для хранилищ Fabric в отдельных регионах Fabric и обеспечивать соответствие кода и данных, выполняя регулярные развертывания и загрузку данных на обеих площадках.
Зеркальная база данных
Зеркальные базы данных из первичного региона остаются недоступными для клиентов, и настройки не реплицируются во вторичный регион. Чтобы восстановить его в случае регионального сбоя, необходимо повторно создать зеркальную базу данных в другой рабочей области из другого региона.
Фабрика данных
Элементы фабрики данных из основного региона остаются недоступными для клиентов, а параметры и конфигурация в конвейерах или элементах потока данных 2-го поколения не будут реплицироваться в дополнительный регион. Чтобы восстановить эти элементы в случае регионального сбоя, необходимо повторно создать элементы Интеграция данных в другой рабочей области из другого региона. В следующих разделах описаны сведения.
Потоки данных 2-го поколения
Если вы хотите восстановить элемент потока данных 2-го поколения в новом регионе, необходимо экспортировать PQT-файл в систему управления версиями, например Git, а затем вручную восстановить содержимое потока данных 2-го поколения после аварии.
В элементе Dataflow 2-го поколения на вкладке "Главная" в редакторе Power Query выберите Экспорт шаблона.
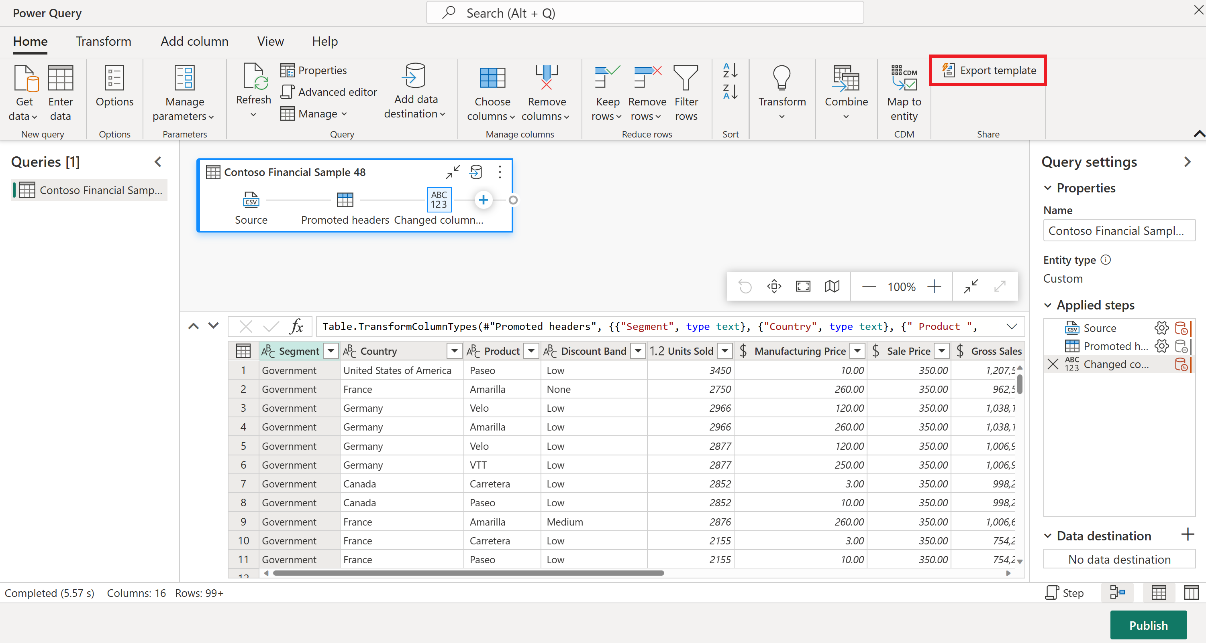
В диалоговом окне "Экспорт шаблона" введите имя (обязательно) и описание (необязательно) для этого шаблона. При готовности выберите ОК.
После аварии создайте элемент потока данных второго поколения в новой рабочей области «C2.W2».
В текущей области представления редактора Power Query выберите Import из шаблона Power Query.

В диалоговом окне "Открыть" перейдите к папке загрузки по умолчанию и выберите PQT-файл , сохраненный на предыдущих шагах. Щелкните Открыть.
Затем шаблон импортируется в новый элемент потока данных 2-го поколения.
Функция потоков данных 'Сохранить как' не поддерживается в случае восстановления после аварии.
Трубопроводы
Клиенты не могут получить доступ к конвейерам в случае региональной аварии, а конфигурации не реплицируются в парный регион. Рекомендуется создавать критически важные конвейеры в нескольких рабочих областях в разных регионах.
Создать копию задания
Пользователи CopyJob должны предпринять упреждающие меры для защиты от региональной катастрофы. Данный подход гарантирует, что копии заданий пользователя остаются доступными после региональной катастрофы.
Избыточность, управляемая пользователем, с интеграцией Git (в общедоступной предварительной версии)
Лучший способ упростить этот процесс и быстро — использовать интеграцию Fabric Git, а затем синхронизировать copyJob с репозиторием ADO. После перехода службы на другой регион, можно использовать репозиторий для перестройки задания CopyJob в созданной вами рабочей области.
Настройте интеграцию Git рабочей области и выберите подключиться и синхронизировать с репозиторием ADO.

На следующем рисунке показан синхронизированный файл CopyJob.

Восстановите файл CopyJob из репозитория ADO.
В созданной рабочей области снова подключитесь к репозиторию Azure ADO и синхронизируйте их. Все элементы Fabric в этом репозитории автоматически скачиваются в новое рабочее пространство.
Если исходный CopyJob использует Lakehouse, пользователи могут ссылаться на раздел Lakehouse для восстановления Lakehouse, а затем подключить только что восстановленный CopyJob к вновь восстановленному Lakehouse.
Дополнительные сведения об интеграции с Git см. в статье "Введение в интеграцию с Git".
Задание Apache Airflow
Пользователи задания Apache Airflow в Fabric должны предпринять упреждающие меры для защиты от региональной катастрофы.
Мы рекомендуем управлять избыточностью с помощью интеграции Fabric Git. Сначала синхронизируйте задание Airflow с репозиторием ADO. Если служба переключается на другой регион, можно использовать репозиторий для перестроения задачи Airflow в созданной рабочей области.
Ниже приведены шаги по достижению этого:
Настройте интеграцию Git рабочей области и выберите "Подключиться и синхронизировать" с репозиторием ADO.
После этого вы увидите, что задание Airflow синхронизировано с репозиторием ADO.
Если необходимо восстановить задание Airflow из репозитория ADO, создайте новую рабочую область, подключитесь и снова синхронизируйте его с репозиторием ADO Azure. Все элементы Fabric, в том числе Airflow, из этого репозитория будут автоматически загружены в вашу новую рабочую область.
Аналитика в режиме реального времени
В этом руководстве описаны процедуры восстановления для пользовательского опыта с системой Аналитики в режиме реального времени. В нем рассматриваются базы данных KQL, наборы запросов и потоки событий.
Activator
Элементы активатора из основного региона остаются недоступными для клиентов, а определения триггера активации не реплицируются в дополнительный регион. Пользователи активатора должны предпринять упреждающие шаги для подготовки к региональному аварийному восстановлению.
Чтобы обеспечить восстановление элементов активатора в случае региональной аварии, настройте интеграцию Fabric Git для резервного копирования определений триггеров и восстановления их в рабочей области в другом регионе.
- Настройте интеграцию Fabric Git для рабочей области, содержащей элемент Активатора, и синхронизируйте определения триггеров с репозиторием Git.
- Регулярно фиксируйте и синхронизируйте определения триггеров Activator.
- Во время восстановления создайте рабочую область в целевом регионе (C2). W2), подключите его к одному репозиторию и синхронизируйте для восстановления определений триггеров.
- Перенастройка и проверка всех источников данных и зависимостей активатора в новой рабочей области.
Примечание.
Стандартный процесс переключения при отказе в Fabric не применяется к элементам Activator. Восстановление ограничено резервным копированием и восстановлением определений триггеров на основе Git.
Дополнительные сведения об интеграции с Git см. в статье "Введение в интеграцию с Git".
Модель графа или набор запросов
Элементы модели графов и набора запросов к графу из основного региона остаются недоступными для клиентов, и эти элементы не реплицируются во вторичный регион. Чтобы восстановить, создайте или используйте ресурс в другом регионе и воссоздайте там элементы модели Graph и набора запросов Graph.
Создайте или используйте существующую мощность Fabric в другом регионе, на который не влияет авария.
Создайте новую рабочую область или используйте существующую в этой роли.
Повторно создайте элемент модели Graph во вторичной рабочей области, как указано в шаге 2. Перенастройка определения модели, включая узлы, края и т. д., чтобы соответствовать исходной модели Graph.
Если исходный лейкхаус находится в неработоемом регионе, сначала восстановите его, следуя разделу Lakehouse.
Подключите Lakehouse в качестве источника данных OneLake для недавно созданного элемента графовой модели. Используйте восстановленное озерохранилище, если оно было в неработающем регионе, или повторно подключитесь к существующему озерохранилищу, если оно остается доступным.
Перенастройка расписаний загрузки данных или подключений для модели Graph в новой рабочей области.
Повторно создайте элемент набора запросов Graph в вторичной рабочей области. Повторно внесите запросы и все сохраненные конфигурации запросов из исходного набора запросов Graph.
База данных/набор запросов KQL
Пользователи базы данных и набора запросов KQL должны предпринять упреждающие меры для защиты от региональной катастрофы. Следующий подход гарантирует, что в случае региональной аварии данные в наборах запросов к базам данных KQL остаются безопасными и доступными.
Чтобы гарантировать эффективное решение аварийного восстановления для баз данных и наборов запросов KQL, выполните следующие действия.
Создайте независимые базы данных KQL: настройте две или более независимые базы данных или наборы запросов KQL на выделенных платформах Fabric. Они должны быть настроены в двух разных регионах Azure (предпочтительно парные регионы Azure), для максимальной устойчивости.
Репликация действий управления: все действия управления, выполненные в одной базе данных KQL, должны быть зеркально отражены в другой. Это гарантирует, что обе базы данных остаются в синхронизации. Ключевые действия для репликации включают:
Таблицы. Убедитесь, что структуры таблиц и определения схемы согласованы между базами данных.
Сопоставление: дублируются все необходимые сопоставления. Убедитесь, что источники данных и пункты назначения правильно выровнены.
Политики. Убедитесь, что обе базы данных имеют аналогичные политики хранения, доступа и других соответствующих политик.
Управление проверкой подлинности и авторизацией. Для каждой реплики настройте необходимые разрешения. Убедитесь, что установлены соответствующие уровни авторизации, предоставляя доступ к требуемому персоналу при сохранении стандартов безопасности.
Параллельное прием данных. Чтобы обеспечить согласованность и готовность данных в нескольких регионах, загрузите один и тот же набор данных в каждую базу данных KQL одновременно с приемом данных.
Поток событий
Поток событий на платформе Fabric — это централизованное место для записи, преобразования и маршрутизации событий в режиме реального времени в различные целевые точки (например, lakehouses, базы данных с KQL, наборы запросов) с использованием интерфейса без кода. До тех пор, пока назначения поддерживаются аварийным восстановлением, потоки событий не теряют данные. Поэтому клиенты должны использовать возможности аварийного восстановления этих целевых систем для обеспечения доступности данных.
Клиенты также могут достичь геоизбыточности путем развертывания идентичных рабочих нагрузок Eventstream в нескольких Azure регионах в рамках многосайтовых активных и активных стратегий. Благодаря многосайтовому активно-активному подходу клиенты могут получить доступ к рабочей нагрузке в любом развернутом регионе. Этот подход является самым сложным и дорогостоящим подходом к аварийному восстановлению, но может сократить время восстановления до нуля в большинстве ситуаций. Чтобы добиться полной геоизбыточности, клиенты могут
Создайте реплики источников данных в разных регионах.
Создание элементов Eventstream в соответствующих регионах.
Подключите эти новые элементы к идентичным источникам данных.
Добавьте одинаковые назначения для каждого потока событий в разных регионах.
Бизнес-события, события Fabric и события Azure
Хотя бизнес-события, события Fabric и события Azure совместно используют одну и ту же инфраструктуру центра Real-Time в Microsoft Fabric, они имеют различные источники, поведение и требования к восстановлению, которые необходимо понимать перед планированием аварийного восстановления:
События Fabric — это подписки на события, которые реагируют на действия, инициируемые самими ресурсами Fabric, включая изменения в жизненном цикле элементов рабочей области (например, создание, обновление или удаление лейкхаусов, записных книг или хранилищ), выполнение заданий (например, запуски конвейеров или выполнение записных книг), а также операции с файлами и папками в OneLake. Эти подписки работают по модели push и являются временными. Подписки не реплицируются в дополнительный регион.
Azure События — это подписки на события, созданные учетными записями Хранилище BLOB-объектов Azure. Эти ресурсы Azure существуют независимо от какой-либо ёмкости Fabric или региона. Хотя сам ресурс Хранилище BLOB-объектов Azure может оставаться доступным во время регионального сбоя в Fabric, подписки, настроенные в Real-Time hub, не реплицируются во вторичный регион, и их необходимо создать заново.
Бизнес-события — это отдельная возможность в Fabric Real-Time Intelligence, которая позволяет командам определять, публиковать и действовать над значимыми бизнес-сигналами. Бизнес-события создаются в Fabric с помощью Activator, записных книжек Spark или User Data Functions, а затем публикуются в Real-Time hub, где последующие потребители, такие как Activator, Eventhouse или Power Automate, могут на них реагировать. Схемы событий управляются централизованно с помощью реестра схем. Eventhouse автоматически сохраняет каждое опубликованное бизнес-событие, поэтому его восстановление непосредственно влияет на доступность журнала событий бизнеса. Ни одна из конфигураций издателя или потребителя, определений схем или подписок не реплицируется в дополнительный регион.
Выполните следующие действия, чтобы восстановить бизнес-события, события Fabric и события Azure в новой рабочей области в регионе восстановления.
Для бизнес-событий:
Повторно создайте бизнес-событие, используемое издателями и потребителями, следуя статье "Создание бизнес-событий в центре Fabric Real-Time". Во время создания бизнес-события вы создадите ресурс набора схем событий. Ресурс Eventhouse является необязательным в зависимости от сценария.
Повторно создайте в новой рабочей области все элементы-издатели, которые генерируют бизнес-события, например ноутбуки Spark или функции пользовательских данных, следуя инструкциям в статьях: Использование функции пользовательских данных в качестве издателя бизнес-событий, Использование Activator в качестве издателя бизнес-событий, Использование ноутбука в качестве издателя бизнес-событий и Использование Eventstream в качестве издателя бизнес-событий.
Повторно создайте потребительские подписки в Real-Time Hub (например, правила Activator, триггеры записных книжек или потоки Power Automate), которые ранее реагировали на бизнес-события в затронутом регионе, следуя статьям Интеграция Eventhouse и панели мониторинга Real-Time с бизнес-событиями и Использование бизнес-событий из Activator.
Убедитесь, что события проходят по всей цепочке, проверив, что подписки активны и что данные поступают в ожидаемые целевые точки в регионе аварийного восстановления.
Для событий Fabric:
Повторно создайте подписки в Real-Time Hub, ссылающиеся на элементы рабочей области, задания или пути OneLake, которые были восстановлены в регионе восстановления, следуя инструкциям в статье Изучение событий Fabric в центре Fabric Real-Time.
Убедитесь, что события проходят по всей цепочке, проверив, что подписки активны и что данные поступают в ожидаемые целевые точки в регионе аварийного восстановления.
Для событий Azure:
Учетные записи Хранилище BLOB-объектов Azure не затрагиваются региональным сбоем Fabric. Повторно создайте подписки на события в концентраторе Real-Time, указывающие на те же учетные записи Хранилище BLOB-объектов Azure, следуя статье "Настройка оповещений о событиях Хранилище BLOB-объектов Azure в центре Real-Time".
Убедитесь, что события проходят по всей цепочке, проверив, что подписки активны и что данные поступают в ожидаемые целевые точки в регионе аварийного восстановления.
Примечание.
История событий Business Events зависит от восстановления Eventhouse. Бизнес-события, события Fabric и события Azure основаны на принудительной отправке и эфемерном режиме, поэтому данные об исторических событиях не восстанавливаются для этих типов. В новом регионе доступны только события, созданные после завершения восстановления.
Map
Элементы сопоставления из основного региона остаются недоступными для клиентов, и элементы сопоставления не реплицируются в вторичный регион.
Если вы хотите восстановить элемент Карты при аварии, настройте интеграцию Fabric Git и синхронизируйте элемент Карты с репозиторием Git.
Во время восстановления, после настройки нового региона или емкости в Fabric, можно использовать репозиторий для перестроения элемента карты в новой созданной рабочей области. Так как новая рабочая область пуста, Git sync получает содержимое из репозитория в пустую рабочую область. На этом шаге элемент карты возвращается к жизни.
Примечание.
Если исходный элемент карты имеет настроенный lakehouse или KQL-набор запросов, сперва обратитесь к разделу Lakehouse и разделу KQL-набор запросов, чтобы восстановить их. После разрешения этих зависимостей подключите вновь восстановленный lakehouse и набор запросов к вновь восстановленному элементу карты.
Онтология
Пользователи ontology должны предпринять упреждающие шаги для подготовки к региональному аварийному восстановлению. Описанный ниже подход гарантирует, что после региональной аварии ваша онтология остается восстанавливаемой и может быть быстро восстановлена.
Самый простой и быстрый способ обеспечения восстановления — использовать интеграцию с Fabric Git и синхронизировать онтологию с репозиторием Azure DevOps (ADO). Если служба переключается на другой регион, этот репозиторий можно использовать для перестроения онтологии в только что созданной рабочей области.
Элементы онтологии в основном регионе недоступны клиентам после региональной аварии, а элементы онтологии не реплицируются во вторичный регион.
Чтобы восстановить элемент Ontology во время аварии, настройте интеграцию Fabric Git и synchronize элемент Ontology с репозиторием ADO заранее.
При восстановлении, после настройки нового региона и емкости в Fabric, вы можете использовать репозиторий для восстановления элемента Онтологии в новой рабочей области. Так как новая рабочая область пуста, Git sync извлекает содержимое из репозитория в рабочую область, эффективно восстанавливая элемент Ontology.
Примечание.
Если исходный элемент Ontology имеет настроенный Lakehouse, сначала обратитесь к разделу Lakehouse, чтобы восстановить его. После того как эти зависимости устранены, подключите вновь восстановленный lakehouse к вновь восстановленному элементу Онтология.
Plan
В этой статье описаны процедуры восстановления для интерфейса плана в IQ. В нем описаны шаги, необходимые для восстановления ключевых компонентов, включая планирование, PowerTable, аналитику, InfoBridge и связанные ресурсы данных.
Интеграция Git для восстановления элементов плана
Предпочтительный подход заключается в синхронизации всех элементов плана с Azure DevOps (ADO) или репозиторием GitHub с помощью интеграции Fabric Git. После аварийного переключения используйте репозиторий, чтобы восстановить элементы в новой рабочей области.
До стихийного бедствия (превентивные меры):
В рабочей области W1 перейдите в раздел "Параметры рабочей области " и настройте интеграцию Git.
Выберите "Подключиться и синхронизировать" с репозиторием ADO или GitHub.
Выберите элементы плана для отправки в репозиторий и нажмите кнопку "Фиксация".

Убедитесь, что состояние Git элементов плана синхронизировано.
Установите дисциплину коммитов — делайте коммит после каждого значительного изменения в определении плана, чтобы репозиторий всегда отражал актуальное состояние.
Действия по восстановлению:
Создайте новую рабочую область W2 внутри емкости C2 в работоспособном регионе.
В рабочей области W2 перейдите к параметрам рабочей области и повторно подключитесь к одному репозиторию ADO/GitHub.
Выберите систему контроля версий. Выберите соответствующую ветвь репозитория и нажмите кнопку "Обновить все". Все элементы плана загружаются в W2.
Important
Восстановление структуры и параметров листа планирования выполняется с помощью интеграции Git. Данные, введенные в лист планирования, такие как входные значения, заметки и комментарии, не восстанавливаются автоматически. Для этого требуется восстановление Fabric SQL. Данные семантической модели также необходимо восстановить отдельно.
Следующие компоненты восстанавливаются после восстановления:
- Листы PowerTable: Параметры исходной таблицы, конфигурация столбцов, доступ к строкам, визуальные свойства (компоновка, форматы и многое другое), идентификация строк, параметры комментариев, медленно меняющиеся измерения (SCD), согласования, средства автоматизации и формы.
- Листы планирования: Свойства листа (форматирование, условное форматирование и многое другое), параметры комментариев, параметры обратной записи, входные столбцы данных, строки ввода данных, сценарии и закладки.
- InfoBridge: Источники InfoBridge, запросы InfoBridge, шаги преобразования, назначения обратной записи, параметры обратной записи, сопоставления связанных запросов, группы запросов, визуальные свойства (blend). Эти элементы не могут быть восстановлены: источники на основе файлов (CSV, Excel), перекрестные листы рабочей нагрузки, использующие источники на основе файлов.
- Аналитика: Все диаграммы и матрицы.
Восстановление SQL Fabric для плана
Данные, введенные в листы планирования, таблицы, используемые в PowerTable, и данные обратной записи хранятся в базах данных SQL и должны рассматриваться как часть стратегии аварийного восстановления. Сведения о восстановлении баз данных SQL см. в разделе базы данных SQL .
Восстановление метаданных плана. Каждый элемент плана связан с базой данных __fabric_plan_sys, в которой хранятся метаданные для функций планирования, включая комментарии, сценарии, входные данные и конфигурацию обратной записи. База данных __fabric_plan_sys не восстанавливается автоматически и должна быть явно восстановлена.
Восстановите базы данных обратной записи: если в вашем плане используются целевые объекты обратной записи SQL, необходимо также вручную восстановить связанные базы данных. Настроенные назначения для записи в SQL не восстанавливаются автоматически.
Восстановление таблиц, используемых в PowerTable: все таблицы, созданные с помощью PowerTable, хранятся в базе данных SQL Fabric. Эти таблицы необходимо также восстановить в ходе DR.
Агенты операций
Пользователи агента операций должны предпринять упреждающие шаги для подготовки к региональному аварийному восстановлению. Придерживаясь подхода, описанного в этом разделе, вы поможете обеспечить быстрое восстановление работы агентов после регионального сбоя.
Используйте интеграцию Fabric Git для синхронизации рабочей области с репозиторием. Этот подход позволяет воссоздать конфигурации агентов в новой рабочей области, если служба переключается на другой регион в рамках отработки отказа.
Элементы агента управления в основном регионе недоступны во время регионального сбоя. Конфигурации агента, модели поведения и журналы действий не реплицируются в дополнительный регион. Незавершённые операции, активные сеансы чата и ранее обработанные события, существовавшие на момент аварии, также будут потеряны.
Чтобы подготовиться к восстановлению, настройте интеграцию Fabric Git и синхронизируйте элементы агента с репозиторием ADO перед аварией.
При восстановлении настройте новый регион и емкость в Fabric, а затем используйте синхронизированный репозиторий для восстановления конфигураций агента в новой рабочей области. Синхронизация Git переносит сохранённое содержимое из репозитория в пустое рабочее пространство, тем самым воссоздавая элементы агента.
После восстановления конфигураций убедитесь, что все указанные базы данных Eventhouse (KQL) или зависящие от региона источники данных доступны в новом регионе. При необходимости обновите ссылки на конечные точки в конфигурациях агента. Наконец, перезапустите агентов и попросите пользователей начать новые чаты. Предыдущие беседы не могут быть возобновлены.
Транзакционная база данных
В этом руководстве описаны процедуры восстановления для взаимодействия с транзакционной базой данных.
SQL database
Чтобы защититься от регионального сбоя, пользователи баз данных SQL могут принимать упреждающие меры для периодического экспорта данных и использования экспортированных данных для повторного создания базы данных в новой рабочей области при необходимости.
Это можно сделать с помощью средства командной строки SqlPackage , который обеспечивает переносимость базы данных и упрощает развертывание базы данных.
- Используйте средство SqlPackage для экспорта базы данных в
.bacpacфайл. Дополнительные сведения см. в статье "Экспорт базы данных с помощью SqlPackage ". - Сохраните
.bacpacфайл в безопасном расположении, которое находится в другом регионе, отличном от базы данных. Примеры включают хранение файла.bacpacв Lakehouse, расположенном в другом регионе, с использованием учетной записи служба хранилища Azure с геоизбыточностью или другого защищенного носителя хранения в другом регионе. - Если база данных и регион SQL недоступны, можно использовать
.bacpacфайл с SqlPackage для повторного создания базы данных в рабочей области в новом регионе — Workspace C2. W2 в регионе B, как описано в приведенном выше сценарии. Выполните действия, описанные в статье "Импорт базы данных с помощью SqlPackage ", чтобы повторно создать базу данных с.bacpacфайлом.
Повторно созданная база данных является независимой от исходной базы данных и отражает состояние данных во время операции экспорта.
Соображения по возврату к основному состоянию
Созданная база данных является независимой базой данных. Данные, добавленные в созданную базу данных, не будут отражены в исходной базе данных. Если вы планируете вернуться к исходной базе данных, когда домашний регион станет доступным, необходимо будет вручную сверять данные из повторно созданной базы данных с исходной базой данных.
Platform
Платформа относится к базовым общим службам и архитектуре, которые применяются ко всем рабочим нагрузкам. В этом разделе описаны процедуры восстановления для общих опытов. В ней рассматриваются библиотеки переменных.
Библиотека переменных
библиотеки переменных Microsoft Fabric позволяют разработчикам настраивать конфигурации элементов в рабочей области и предоставлять общий доступ к ним, упрощая управление жизненным циклом контента. С точки зрения аварийного восстановления пользователи библиотеки переменных должны заранее защититься от региональной аварии. Это можно сделать с помощью интеграции Fabric Git, которая гарантирует, что после региональной аварии библиотека переменных пользователя остается доступной. Чтобы восстановить библиотеку переменных, рекомендуется следующее:
Используйте интеграцию Fabric Git для синхронизации библиотеки переменных с репозиторием ADO. В случае аварии репозиторий можно использовать для перестроения библиотеки переменных в созданной рабочей области. Выполните следующие действия.
В созданной рабочей области снова подключитесь к репозиторию Azure ADO и синхронизируйте их.
Все элементы Fabric в этом репозитории автоматически скачиваются в новое рабочее пространство.
После синхронизации элементов из Git откройте библиотеки переменных в новой рабочей области и вручную выберите нужный активный набор значений.
Управляемые клиентом ключи для рабочих областей Fabric
Вы можете использовать управляемые клиентом ключи (CMK), хранящиеся в Azure Key Vault, чтобы добавить дополнительный уровень шифрования на вершине ключей, управляемых Microsoft для неактивных данных. В случае, если Fabric становится недоступным или неработоспособным в регионе, его компоненты будут переключаться на резервную копию. Во время переключения на резервную систему функция CMK поддерживает операции только для чтения. Пока служба Azure Key Vault остается работоспособной, и разрешения для хранилища сохраняются, Fabric будет продолжать подключаться к ключу и обычно читать данные. Это означает, что во время переключения при отказе не поддерживаются следующие операции: включение и выключение настройки CMK рабочей области и обновление ключа.
OneLake
В этом разделе описаны процедуры восстановления для функций OneLake. Дополнительные сведения об аварийном восстановлении данных в OneLake см. в статье Аварийное восстановление OneLake.
Политики управления жизненным циклом
Если Fabric становится недоступной или перестает работать в каком-либо регионе, политика жизненного цикла OneLake по-прежнему остается доступной для чтения и обновления при отработке отказа. Все данные, перемещённые на прохладный или холодный уровень хранения, останутся на этом уровне хранения. Чтобы применить существующую политику к новой рабочей области восстановления, выполните следующие действия.
- Выберите команду «Экспорт политики» в исходной рабочей области и сохраните всю политику жизненного цикла.
- Вызов политики импорта в восстановленной рабочей области с экспортируемой политикой жизненного цикла в качестве текста запроса.
Правила инстанции ресурса
Правила для экземпляров ресурсов помогают безопасно контролировать доступ к данным в OneLake с помощью доверенных удостоверений ресурсов Azure. Во время переключения на резервный регион система продолжает обеспечивать соблюдение существующих правил доступа на чтение. Однако нельзя создавать, обновлять или удалять правила для экземпляров ресурсов, пока рабочая область снова не станет доступной для записи.
Дополнительные сведения
- руководство по аварийному восстановлению Microsoft Fabric