ОБЛАСТЬ ПРИМЕНЕНИЯ: Расширение Azure CLI для машинного обучения версии 2 (текущая версия)Python SDK azure-ai-ml версии 2 (текущая версия)
Расширение Azure CLI для машинного обучения версии 2 (текущая версия)Python SDK azure-ai-ml версии 2 (текущая версия)
Из этой статьи вы узнаете, как импортировать данные в платформу Машинное обучение Azure из внешних источников. Успешный импорт данных автоматически создает и регистрирует ресурс данных Машинного обучения Azure с именем, указанным во время этого импорта. Ресурс данных по Машинному обучению Azure напоминает закладку веб-браузера (избранные). Вам не нужно запоминать длинные пути хранения (URI), указывающие на наиболее часто используемые данные. Вместо этого можно создать ресурс данных, а затем получить доступ к ним с помощью понятного имени.
Импорт данных создает кэш исходных данных, а также метаданные для более быстрого и надежного доступа к данным в заданиях обучения машинного обучения Azure. Кэш данных избегает ограничений сети и подключений. Кэшированные данные управляются версиями для обеспечения воспроизводимости. Эта функция предоставляет возможности управления версиями для данных, импортированных из источников SQL Server. Кроме того, кэшированные данные предоставляют родословную данных для задач аудита. Импорт данных использует конвейеры Фабрики данных Azure (ADF) за кулисами, что означает, что можно избежать сложного взаимодействия с ADF. Машинное обучение Azure также обрабатывает управление размером пула вычислительных ресурсов ADF, подготовкой вычислительных ресурсов и их деактивацией. Это управление оптимизирует передачу данных путем определения правильной параллелизации.
Передаваемые данные секционируются и безопасно хранятся в виде файлов parquet в хранилище Azure. Это хранилище позволяет ускорить обработку во время обучения. Затраты на вычисления ADF включают только время, используемое для передачи данных. Затраты на хранение включают только время, необходимое для кэширования данных, так как кэшированные данные являются копией данных, импортированных из внешнего источника. Хранилище Azure размещает внешний источник.
Функция кэширования включает предварительные затраты на вычисления и хранение. Однако она окупается и может сэкономить деньги, так как сокращает постоянные затраты на вычислительные ресурсы по сравнению с прямыми подключениями к внешним источникам данных во время обучения. Он кэширует данные в виде файлов parquet, что делает обучение заданий быстрее и надежнее при истечении времени ожидания подключения для больших наборов данных. Это кэширование приводит к меньшему количеству повторных запусков и меньшему количеству сбоев обучения.
Вы можете импортировать данные из Amazon S3, SQL Azure и Snowflake.
Внимание
Эта функция сейчас доступна в виде общедоступной предварительной версии. Эта предварительная версия предоставляется без соглашения об уровне обслуживания. Ее не следует использовать для производственных рабочих нагрузок. Некоторые функции могут не поддерживаться или их возможности могут быть ограничены.
Дополнительные сведения см. в статье Дополнительные условия использования Предварительных версий Microsoft Azure.
Предварительные условия
Для создания ресурсов данных и работы с ними требуются компоненты, указанные ниже.
Примечание.
Для успешного импорта данных убедитесь, что установлен последний пакет azure-ai-ml (версия 1.31.0 или более поздней версии) для пакета SDK, а также расширение ml (версия 2.37.0 или более поздней версии). Требуется Python 3.9 или более поздней версии.
Если у вас есть более старый пакет SDK или расширение CLI, удалите старый и установите новый с помощью кода, показанного в разделе вкладки. Следуйте инструкциям по пакету SDK и CLI, как показано здесь:
Версии кода
az extension remove -n ml
az extension add -n ml --yes
az extension show -n ml #(the version value needs to be 2.37.0 or later)
pip install azure-ai-ml
pip show azure-ai-ml #(the version value needs to be 1.31.0 or later)
Импорт из внешней базы данных в качестве ресурса данных mltable
Примечание.
Внешние базы данных включают Snowflake и SQL Azure.
Следующие примеры кода могут импортировать данные из внешних баз данных. Функция connection , которая обрабатывает действие импорта, определяет метаданные внешнего источника данных базы данных. В этом примере код импортирует данные из ресурса Snowflake. Подключение указывает на источник Snowflake. При незначительном изменении подключение может указывать на источник базы данных SQL Azure или другой поддерживаемый источник базы данных. Импортированный ресурс type из внешнего источника базы данных является mltable.
YAML Создание файла<file-name>.yml:
$schema: http://azureml/sdk-2-0/DataImport.json
# Supported connections include:
# Connection: azureml:<workspace_connection_name>
# Supported paths include:
# Datastore: azureml://datastores/<data_store_name>/paths/<my_path>/${{name}}
type: mltable
name: <name>
source:
type: database
query: <query>
connection: <connection>
path: <path>
Затем выполните следующую команду в CLI:
> az ml data import -f <file-name>.yml
from azure.ai.ml.entities import DataImport
from azure.ai.ml.data_transfer import Database
from azure.ai.ml import MLClient
from azure.identity import DefaultAzureCredential
# Supported connections include:
# Connection: azureml:<workspace_connection_name>
# Supported paths include:
# path: azureml://datastores/<data_store_name>/paths/<my_path>/${{name}}
ml_client = MLClient.from_config(credential=DefaultAzureCredential())
data_import = DataImport(
name="<name>",
source=Database(connection="<connection>", query="<query>"),
path="<path>"
)
ml_client.data.import_data(data_import=data_import)
Примечание.
В примере, приведенном здесь, описывается процесс для базы данных Snowflake. Однако этот процесс охватывает другие форматы внешних баз данных, такие как SQL Azure и т. д.
Перейдите в Студию машинного обучения Azure.
В разделе "Ресурсы " в области навигации слева выберите "Данные". Затем выберите вкладку "Импорт данных". Затем нажмите кнопку "Создать", как показано на снимке экрана:
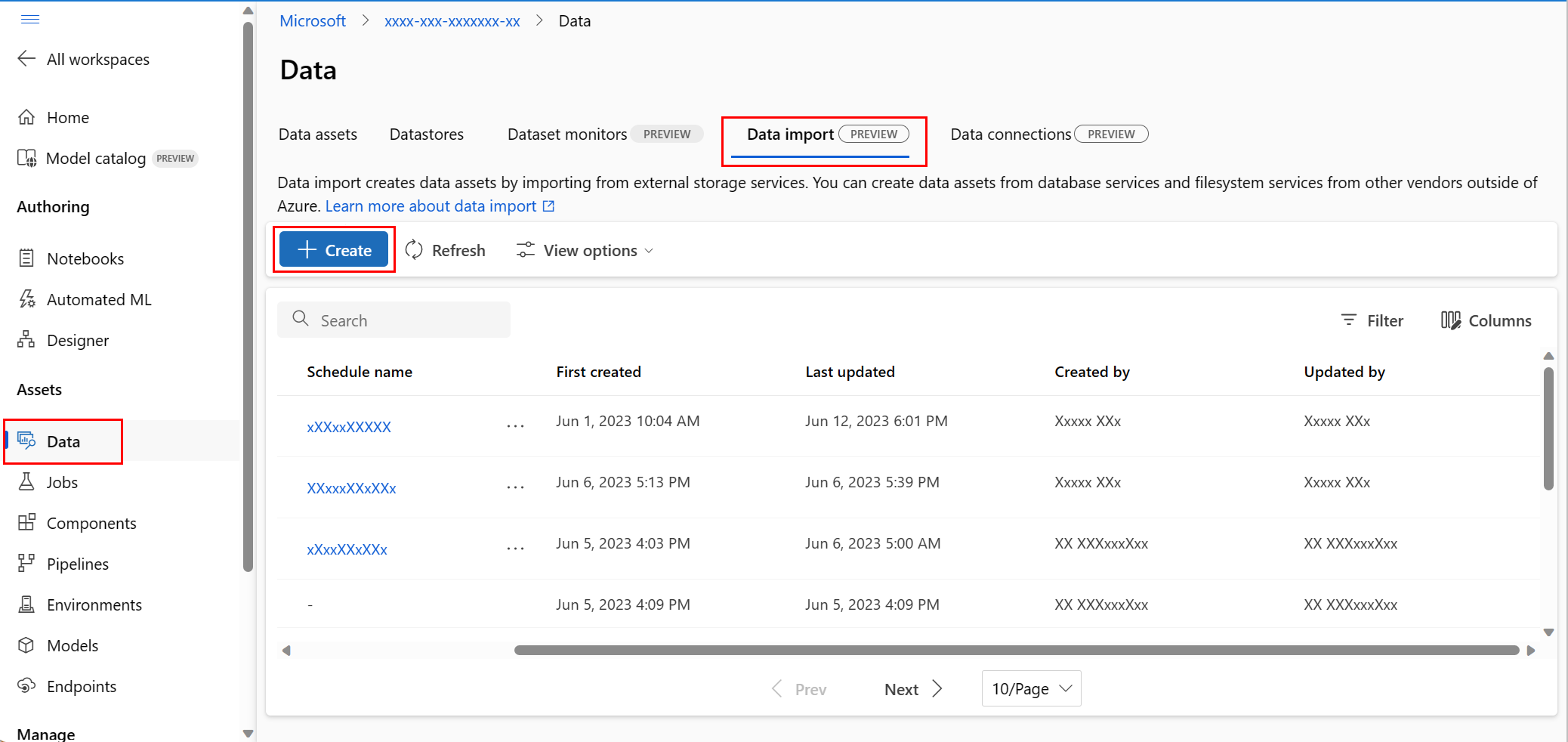
На экране источника данных выберите Snowflake и нажмите кнопку "Далее", как показано на снимке экрана:
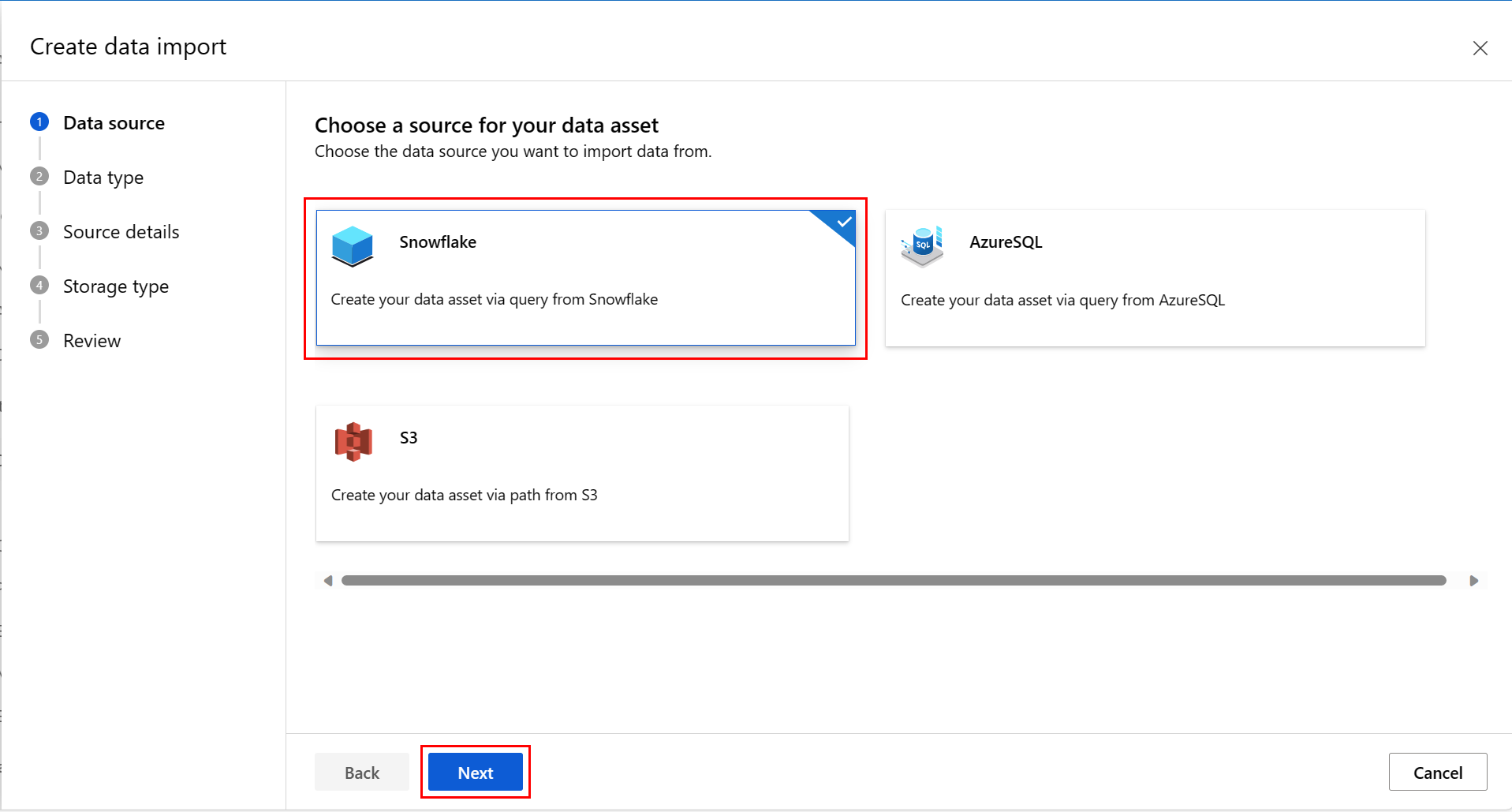
На экране "Тип данных" введите значения. Значение Type по умолчанию — Table (mltable). Затем нажмите кнопку "Далее", как показано на этом снимке экрана:

На экране "Создание импорта данных " введите значения и нажмите кнопку "Далее", как показано на следующем снимке экрана:
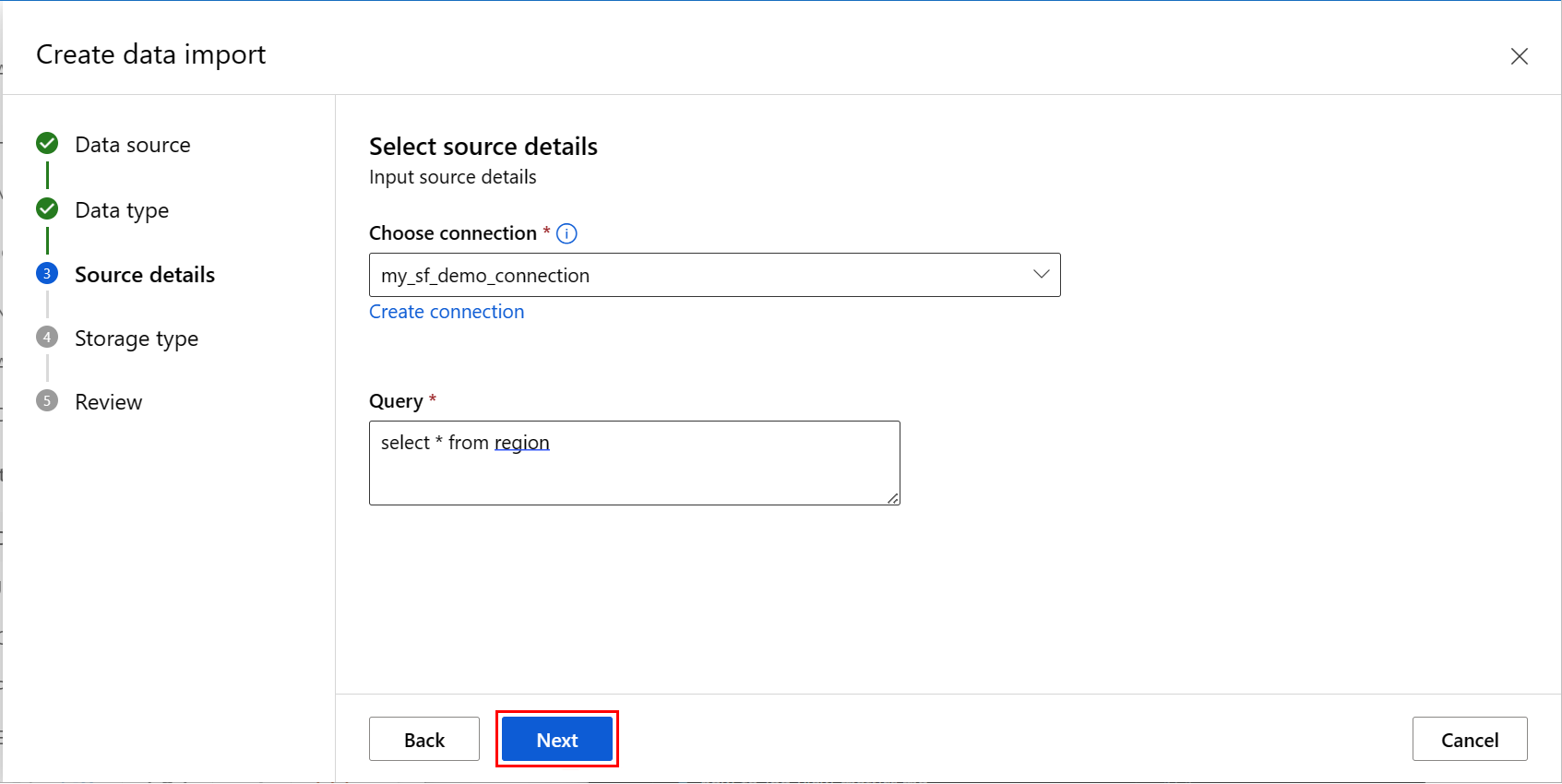
Введите значения на экране выбора хранилища данных и нажмите кнопку "Далее", как показано на следующем снимке экрана.
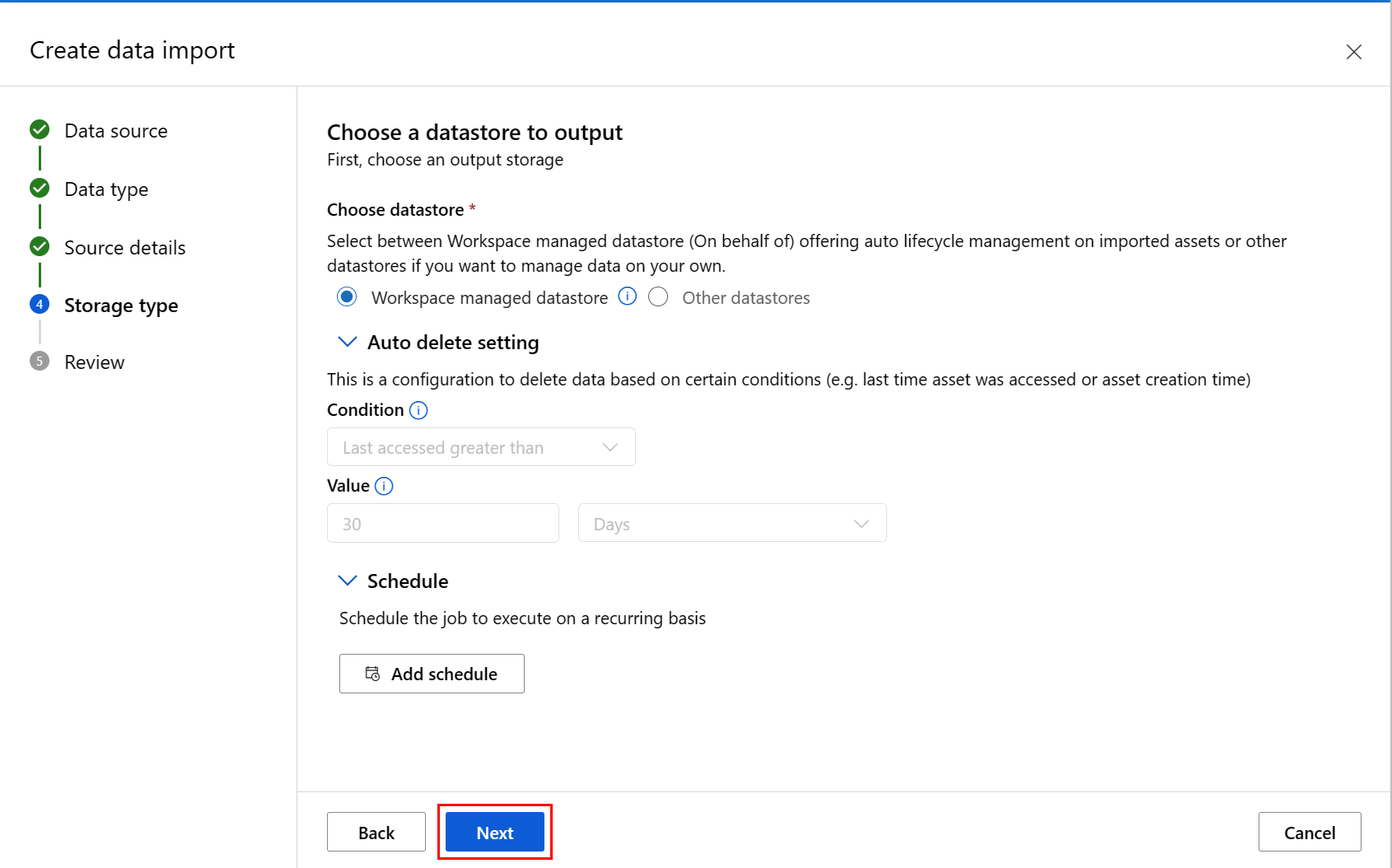
Управляемое хранилище данных рабочей области выбрано по умолчанию; путь автоматически назначается системой при выборе управляемого хранилища данных. Если выбрать Хранилище данных, управляемое рабочей областью, появится раскрывающееся меню Настройка автоматического удаления. Он предлагает период времени удаления данных в течение 30 дней по умолчанию, а также способ управления импортированными ресурсами данных объясняет, как изменить это значение.
Примечание.
Чтобы выбрать собственное хранилище данных, выберите другие хранилища данных. В этом случае необходимо выбрать путь к расположению кэша данных.
Можно добавить расписание. Выберите "Добавить расписание ", как показано на следующем снимке экрана:
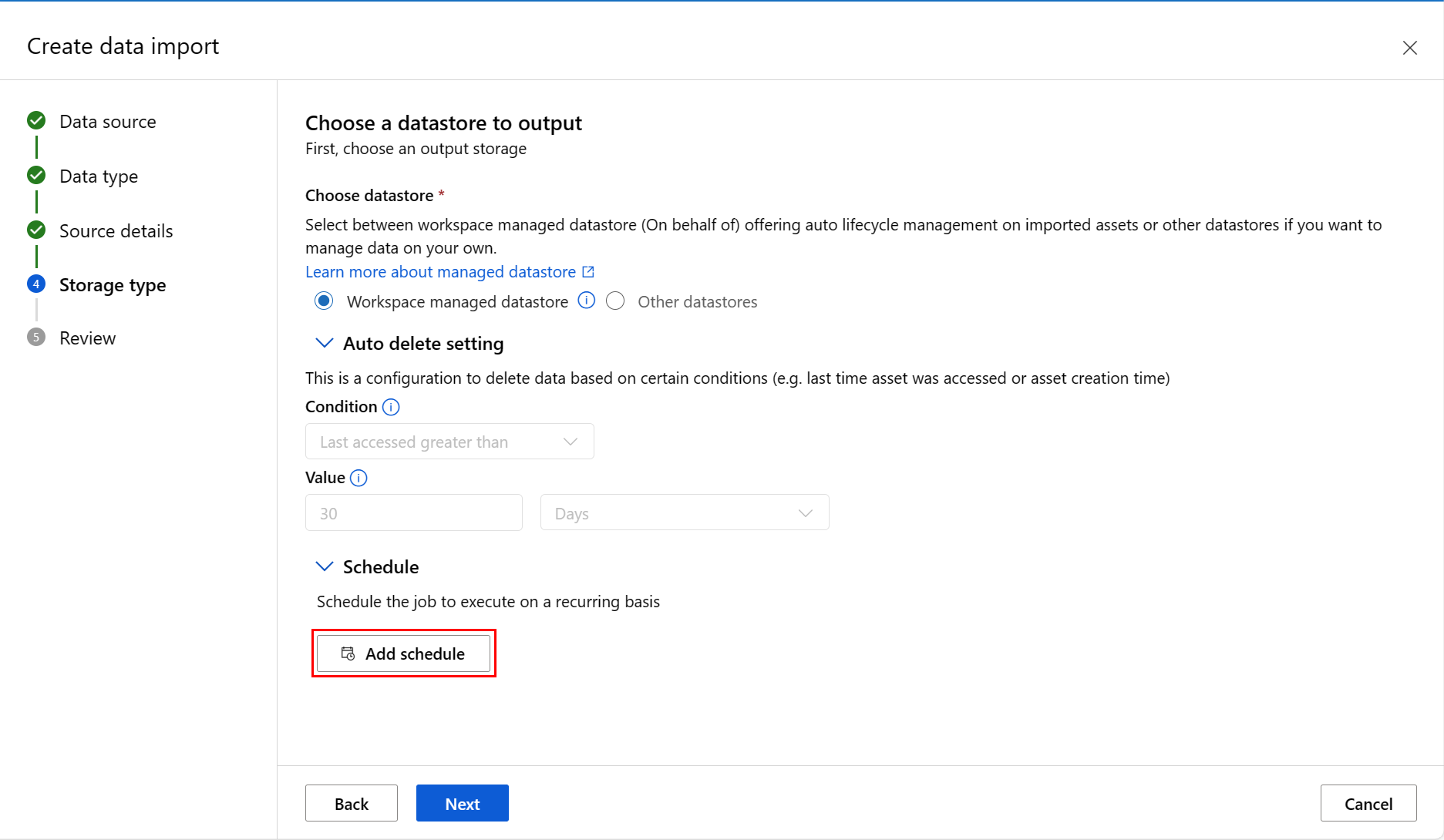
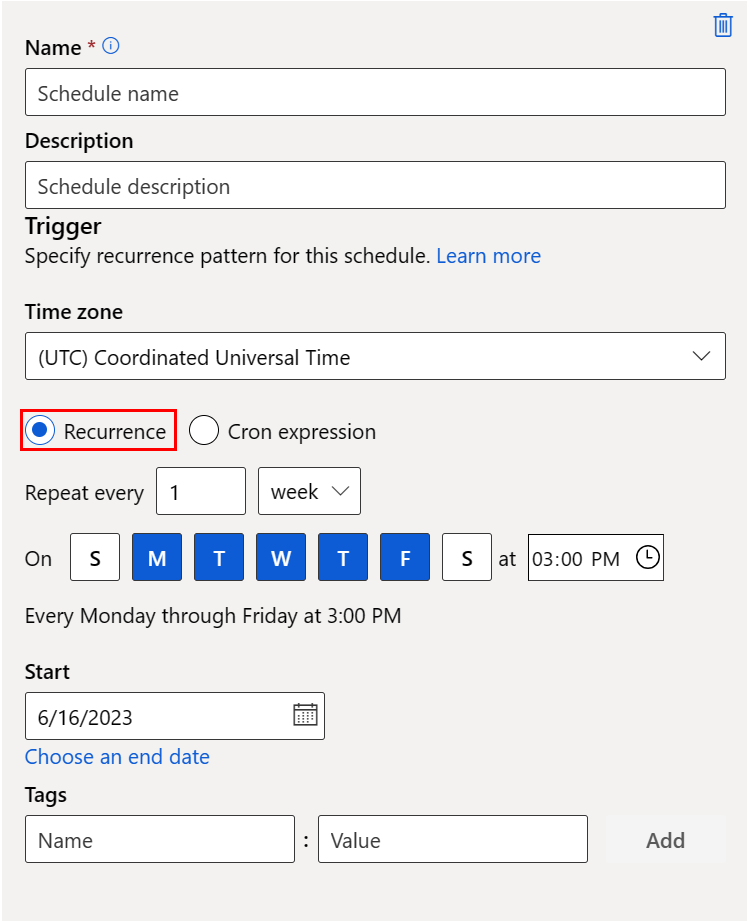
Откроется новая панель, в которой можно определить расписание повторения или расписание Cron . На этом снимка экрана показана панель расписания повторения :
-
Имя: уникальный идентификатор расписания в рабочей области.
-
Описание: описание расписания.
-
Триггер: шаблон повторения расписания, который включает следующие свойства.
-
Часовой пояс: расчет времени триггера основан на этом часовом поясе; (UTC) По умолчанию координированное универсальное время.
-
Повторение или выражение Cron: выберите тип повторения, чтобы указать повторяющийся шаблон. В разделе "Повторение" можно указать частоту повторения по минутам, часам, дням, неделям или месяцам.
-
Начало: расписание сначала становится активным на этой дате. По умолчанию дата создания этого расписания.
-
Конец: расписание становится неактивным после этой даты. По умолчанию это NONE, что означает, что расписание всегда активно, пока вы не отключите его вручную.
-
Теги: выбранные теги расписания.
Примечание.
Start задает дату и время начала расписания с учетом часового пояса. Если опущено "Пуск", время начала равно времени создания расписания. Если время начала в прошлом, первое задание запускается в следующее вычисленное время запуска.
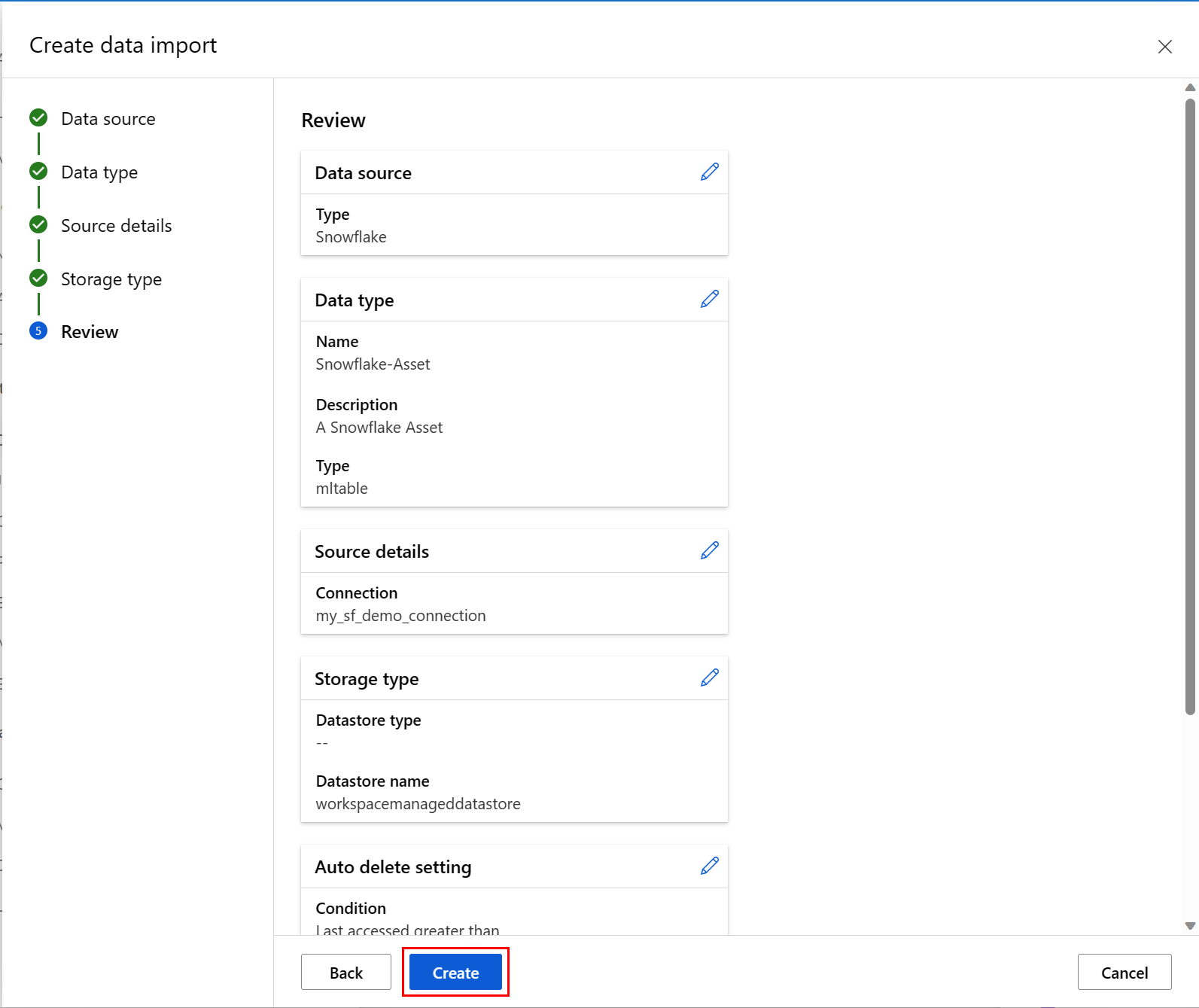
На следующем снимка экрана показан последний экран этого процесса. Просмотрите выбранные варианты и нажмите кнопку "Создать". На этом экране и других экранах этого процесса нажмите кнопку "Назад ", чтобы перейти на более ранние экраны, чтобы изменить выбор значений.
На следующем снимке экрана показана панель для расписания Cron:
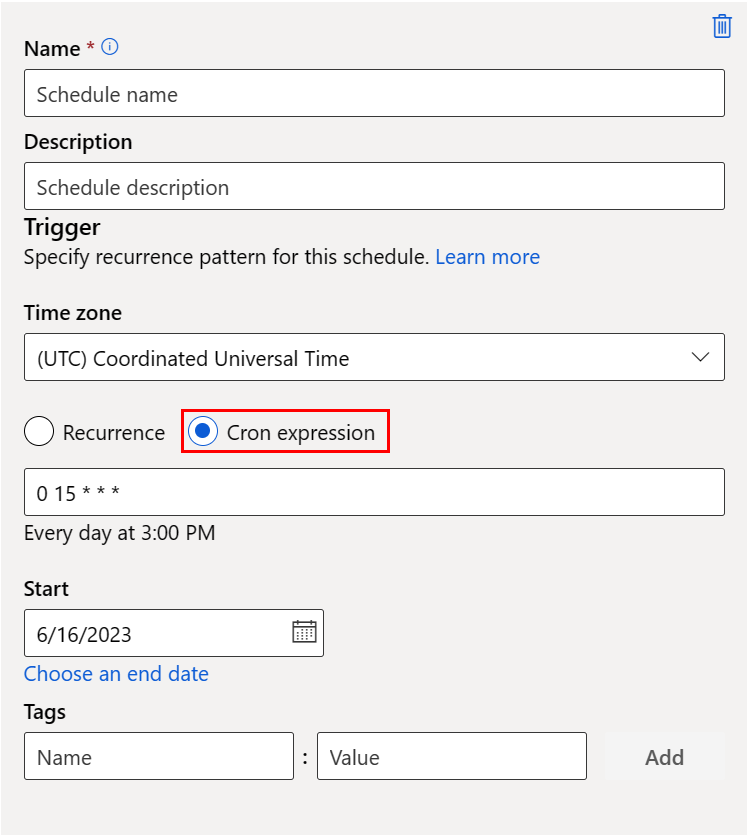
Имя: уникальный идентификатор расписания в рабочей области.
Описание: описание расписания.
Триггер: шаблон повторения расписания, который включает следующие свойства.
Часовой пояс: расчет времени триггера основан на этом часовом поясе; (UTC) По умолчанию координированное универсальное время.
Повторение или выражение Cron: выберите выражение cron, чтобы указать сведения о cron.
(обязательно)expression использует стандартное выражение crontab для выражения повторяющегося расписания. Одно выражение состоит из пяти полей с разделителями-пробелами:
MINUTES HOURS DAYS MONTHS DAYS-OF-WEEK
Один подстановочный символ (*), который охватывает все значения поля. Значение * в контексте дней — это все дни месяца (который зависит от конкретного месяца и года).
В expression: "15 16 * * 1" приведенном выше примере означает 4:15 вечера каждый понедельник.
В следующей таблице перечислены допустимые значения для каждого поля:
| Поле |
Диапазон |
Комментарий |
MINUTES |
0-59 |
- |
HOURS |
0-23 |
- |
DAYS |
- |
Не поддерживается. Значение игнорируется и обрабатывается как *. |
MONTHS |
- |
Не поддерживается. Значение игнорируется и обрабатывается как *. |
DAYS-OF-WEEK |
0–6 |
Ноль (0) означает воскресенье. Принимаются также названия дней. |
Дополнительные сведения о выражениях crontab см. вики-сайте Crontab Expression на сайте GitHub.
Внимание
DAYS и MONTH не поддерживаются. Если передать одно из этих значений, он игнорируется как *.
-
Начало: расписание сначала становится активным на этой дате. По умолчанию дата создания этого расписания.
-
Конец: расписание становится неактивным после этой даты. По умолчанию это NONE, что означает, что расписание всегда активно, пока вы не отключите его вручную.
-
Теги: выбранные теги расписания.
Примечание.
Start задает дату и время начала расписания с учетом часового пояса. Если опущено "Пуск", время начала равно времени создания расписания. Если время начала в прошлом, первое задание запускается в следующее вычисленное время запуска.
На следующем снимка экрана показан последний экран этого процесса. Просмотрите выбранные варианты и нажмите кнопку "Создать". На этом экране и других экранах этого процесса нажмите кнопку "Назад ", чтобы перейти на более ранние экраны, чтобы изменить выбор значений.
Импорт данных из внешней файловой системы в качестве ресурса данных папки
Примечание.
Ресурс данных Amazon S3 может служить внешним ресурсом файловой системы.
Обработчик connection, который выполняет действие импорта данных, определяет характеристики внешнего источника данных. Подключение определяет контейнер Amazon S3 в качестве целевого объекта. Подключение ожидает допустимого path значения. Значение ресурса, импортированное из внешнего источника файловой системы, имеет значение typeuri_folder.
Следующий пример кода импортирует данные из ресурса Amazon S3.
YAML Создание файла<file-name>.yml:
$schema: http://azureml/sdk-2-0/DataImport.json
# Supported connections include:
# Connection: azureml:<workspace_connection_name>
# Supported paths include:
# path: azureml://datastores/<data_store_name>/paths/<my_path>/${{name}}
type: uri_folder
name: <name>
source:
type: file_system
path: <path_on_source>
connection: <connection>
path: <path>
Затем выполните следующую команду в интерфейсе командной строки:
> az ml data import -f <file-name>.yml
from azure.ai.ml.entities import DataImport
from azure.ai.ml.data_transfer import FileSystem
from azure.ai.ml import MLClient
from azure.identity import DefaultAzureCredential
# Supported connections include:
# Connection: azureml:<workspace_connection_name>
# Supported paths include:
# path: azureml://datastores/<data_store_name>/paths/<my_path>/${{name}}
ml_client = MLClient.from_config(credential=DefaultAzureCredential())
data_import = DataImport(
name="<name>",
source=FileSystem(connection="<connection>", path="<path_on_source>"),
path="<path>"
)
ml_client.data.import_data(data_import=data_import)
Перейдите в Студию машинного обучения Azure.
В разделе "Ресурсы " в области навигации слева выберите "Данные". Затем выберите вкладку "Импорт данных". Затем нажмите кнопку "Создать ", как показано на следующем снимке экрана:
На экране источника данных выберите S3 и нажмите кнопку "Далее", как показано на следующем снимке экрана:
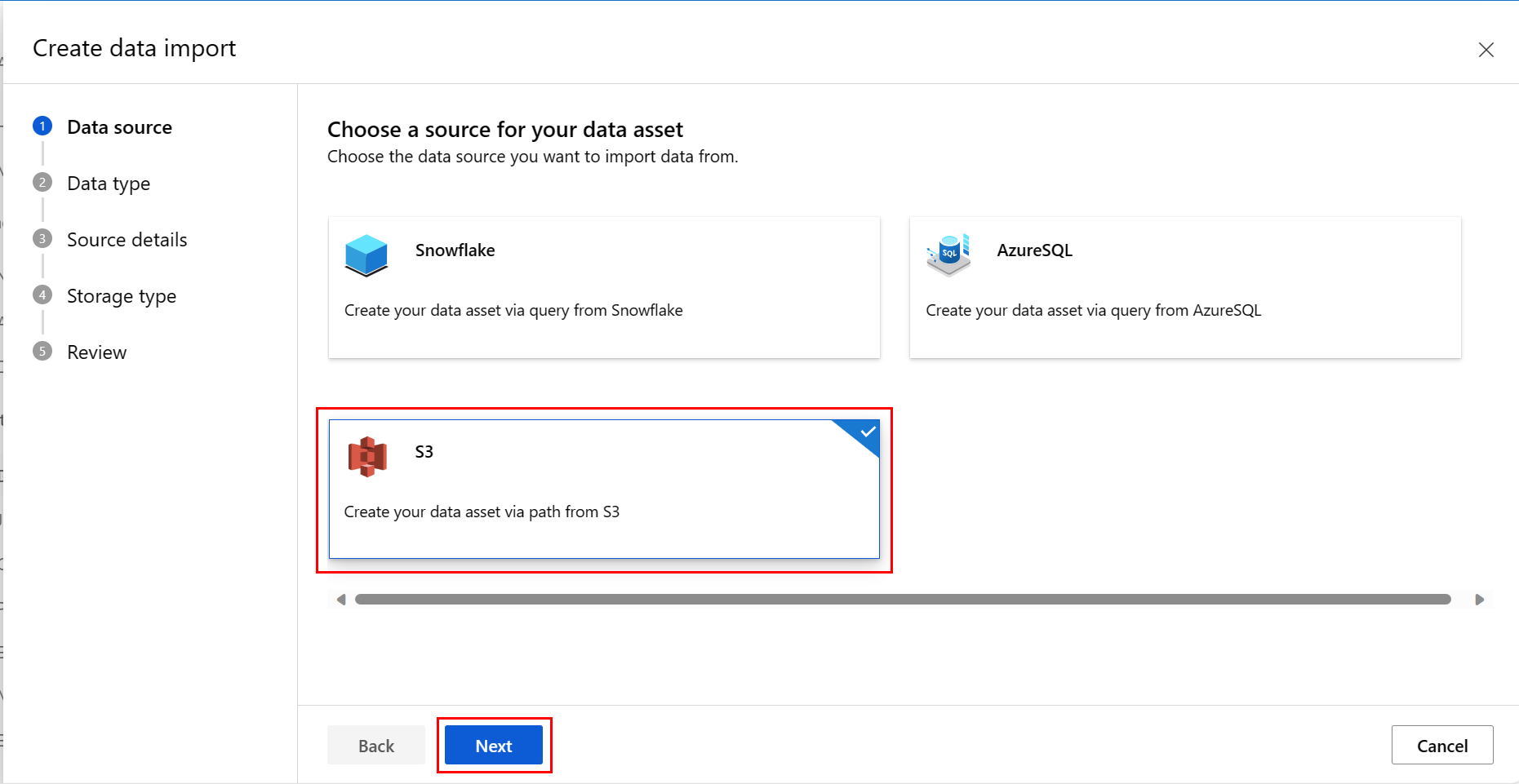
На экране "Тип данных" введите значения. Значение Тип по умолчанию устанавливается в Папка (uri_folder). Затем нажмите кнопку "Далее", как показано на следующем снимке экрана:

На экране "Создание импорта данных " введите значения и нажмите кнопку "Далее", как показано на следующем снимке экрана:
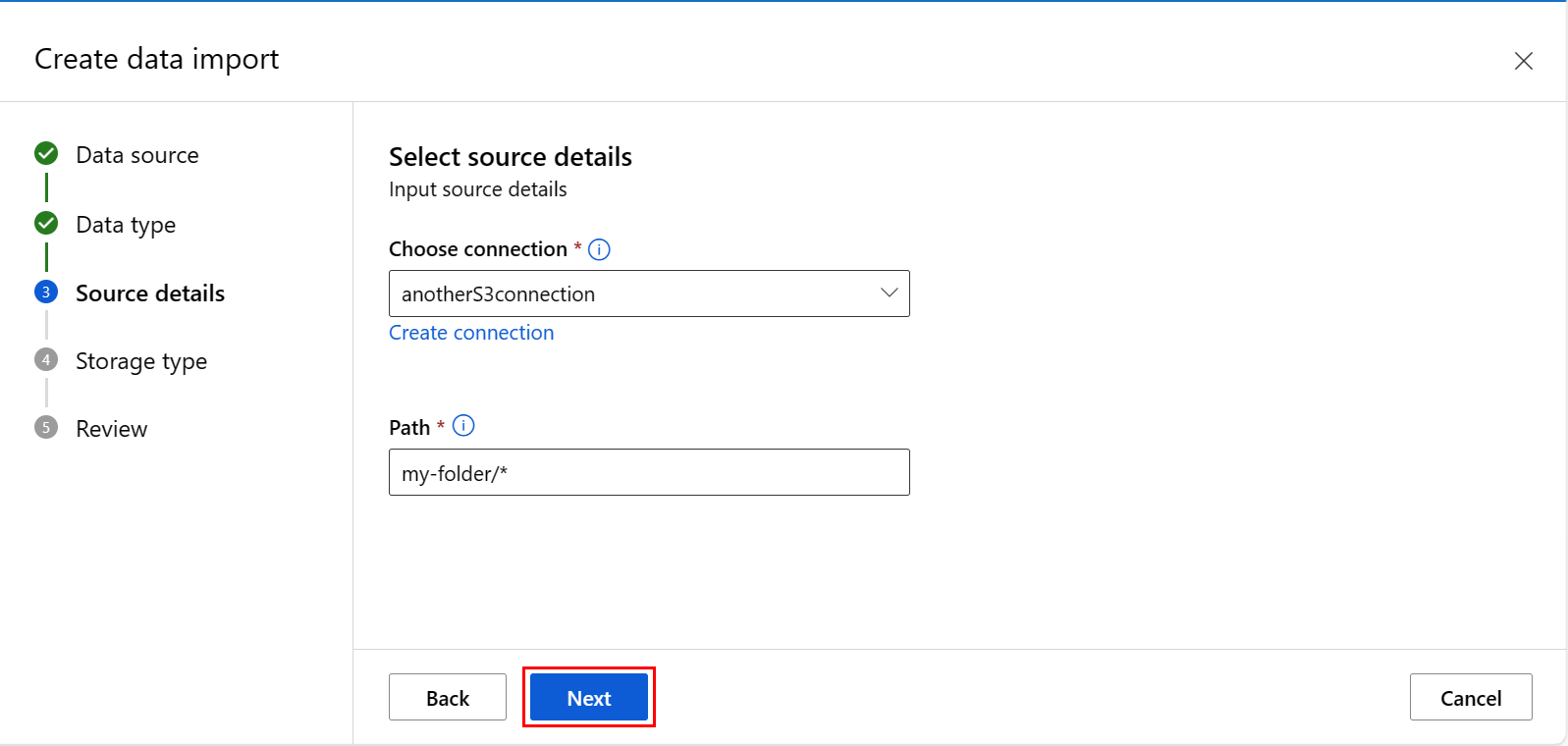
Введите значения на экране выбора хранилища данных и нажмите кнопку "Далее", как показано на следующем снимке экрана.
Управляемое хранилище данных рабочей области выбрано по умолчанию; путь автоматически назначается системой при выборе управляемого хранилища данных. Если выбрать Хранилище данных, управляемое рабочей областью, появится раскрывающееся меню Настройка автоматического удаления. Он предлагает период времени удаления данных в течение 30 дней по умолчанию, а также способ управления импортированными ресурсами данных объясняет, как изменить это значение.
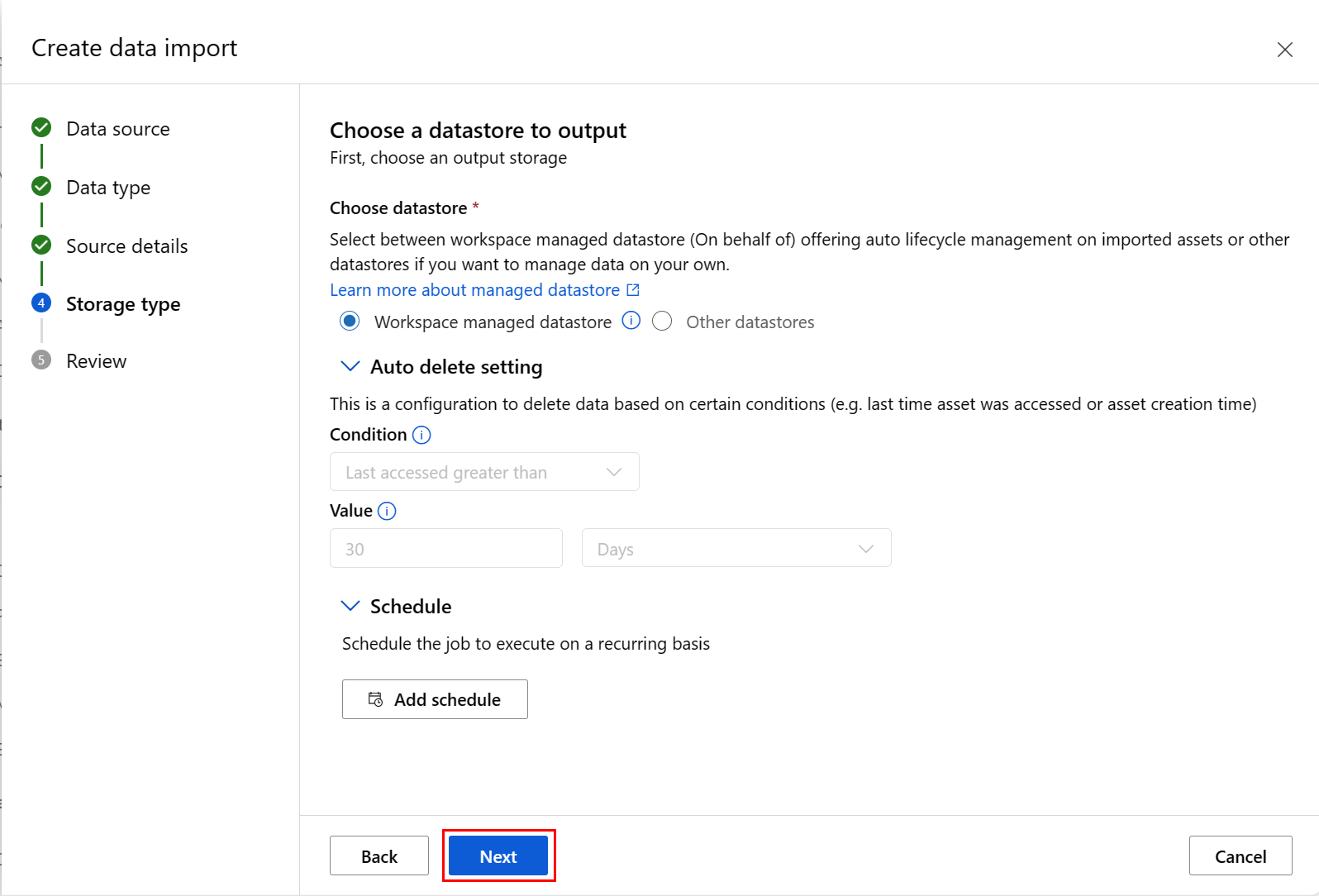
Можно добавить расписание. Выберите "Добавить расписание ", как показано на следующем снимке экрана:
Откроется новая панель, в которой можно определить расписание повторения или расписание Cron . На следующем снимке экрана показана панель расписания повторяемости.
-
Имя: уникальный идентификатор расписания в рабочей области.
-
Описание: описание расписания.
-
Триггер: шаблон повторения расписания, который включает следующие свойства.
-
Часовой пояс: расчет времени триггера основан на этом часовом поясе; (UTC) По умолчанию координированное универсальное время.
-
Повторение или выражение Cron: выберите тип повторения, чтобы указать повторяющийся шаблон. В разделе "Повторение" можно указать частоту повторения по минутам, часам, дням, неделям или месяцам.
-
Начало: расписание сначала становится активным на этой дате. По умолчанию дата создания этого расписания.
-
Конец: расписание становится неактивным после этой даты. По умолчанию это NONE, что означает, что расписание всегда активно, пока вы не отключите его вручную.
-
Теги: выбранные теги расписания.
Примечание.
Start задает дату и время начала расписания с учетом часового пояса. Если опущено "Пуск", время начала равно времени создания расписания. Если время начала в прошлом, первое задание запускается в следующее вычисленное время запуска.
Просмотрите выбранные варианты на последнем экране этого процесса и нажмите кнопку "Создать". На этом экране и на других экранах этого процесса выберите "Назад ", чтобы перейти на более ранние экраны, если вы хотите изменить выбор значений.
Просмотрите выбранные варианты и нажмите кнопку "Создать". На этом экране и других экранах этого процесса нажмите кнопку "Назад ", чтобы перейти на более ранние экраны, чтобы изменить выбор значений.
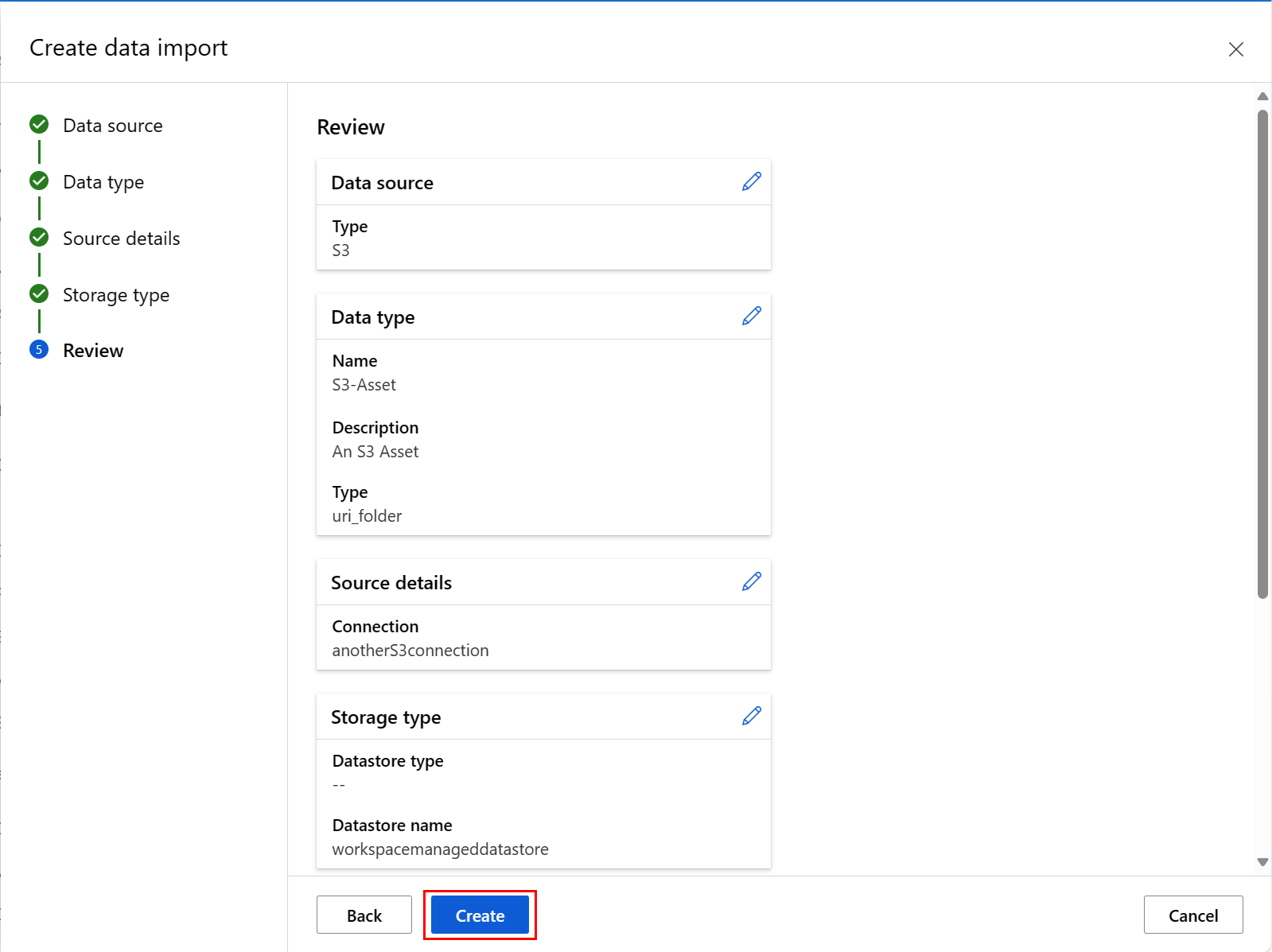
На следующем снимке экрана показана панель для расписания Cron:
Имя: уникальный идентификатор расписания в рабочей области.
Описание: описание расписания.
Триггер: шаблон повторения расписания, который включает следующие свойства.
Часовой пояс: расчет времени триггера основан на этом часовом поясе; (UTC) По умолчанию координированное универсальное время.
Повторение или выражение Cron: выберите выражение cron, чтобы указать сведения о cron.
(обязательно)expression использует стандартное выражение crontab для выражения повторяющегося расписания. Одно выражение состоит из пяти полей с разделителями-пробелами:
MINUTES HOURS DAYS MONTHS DAYS-OF-WEEK
Один подстановочный символ (*), который охватывает все значения поля. Значение * в контексте дней — это все дни месяца (который зависит от конкретного месяца и года).
В expression: "15 16 * * 1" приведенном выше примере означает 4:15 вечера каждый понедельник.
В следующей таблице перечислены допустимые значения для каждого поля:
| Поле |
Диапазон |
Комментарий |
MINUTES |
0-59 |
- |
HOURS |
0-23 |
- |
DAYS |
- |
Не поддерживается. Значение игнорируется и обрабатывается как *. |
MONTHS |
- |
Не поддерживается. Значение игнорируется и обрабатывается как *. |
DAYS-OF-WEEK |
0–6 |
Ноль (0) означает воскресенье. Принимаются также названия дней. |
Дополнительные сведения о выражениях crontab см. вики-сайте Crontab Expression на сайте GitHub.
Внимание
DAYS и MONTH не поддерживаются. Если передать одно из этих значений, он игнорируется как *.
-
Начало: расписание сначала становится активным на этой дате. По умолчанию дата создания этого расписания.
-
Конец: расписание становится неактивным после этой даты. По умолчанию это NONE, что означает, что расписание всегда активно, пока вы не отключите его вручную.
-
Теги: выбранные теги расписания.
Примечание.
Start задает дату и время начала расписания с учетом часового пояса. Если опущено "Пуск", время начала равно времени создания расписания. Если время начала в прошлом, первое задание запускается в следующее вычисленное время запуска.
На следующем снимка экрана показан последний экран этого процесса. Просмотрите выбранные варианты и нажмите кнопку "Создать". На этом экране и других экранах этого процесса нажмите кнопку "Назад ", чтобы перейти на более ранние экраны, чтобы изменить выбор значений.
Проверка состояния импорта внешних источников данных
Действие импорта данных — это асинхронное действие. Это может занять много времени. После отправки действия импорта данных с помощью интерфейса командной строки или пакета SDK служба машинного обучения Azure может потребовать несколько минут для подключения к внешнему источнику данных. Затем служба запускает импорт данных и обрабатывает кэширование и регистрацию данных. Время, необходимое для импорта данных, также зависит от размера исходного набора данных.
Пример ниже возвращает статус активности по импорту данных, которые были отправлены. Команда или метод используют имя ресурса данных в качестве входных данных для определения состояния материализации данных.
> az ml data list-materialization-status --name <name>
from azure.ai.ml.entities import DataImport
from azure.ai.ml import MLClient
from azure.identity import DefaultAzureCredential
ml_client = MLClient.from_config(credential=DefaultAzureCredential())
ml_client.data.list_materialization_status(name="<name>")
Следующие шаги













