Примечание.
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
ОБЛАСТЬ ПРИМЕНЕНИЯ: Расширение машинного обучения Azure CLI версии 2 (current)Python SDK azure-ai-ml версии 2 (current)
Расширение машинного обучения Azure CLI версии 2 (current)Python SDK azure-ai-ml версии 2 (current)
В этой статье раскрываются следующие темы.
- Чтение данных из хранилища Azure в задании Машинное обучение Azure.
- Как записывать данные из задания Машинное обучение Azure в служба хранилища Azure.
- Разница между режимами подключения и скачивания .
- Как использовать удостоверение пользователя и управляемое удостоверение для доступа к данным.
- Параметры подключения, доступные в задании.
- Оптимальные параметры подключения для распространенных сценариев.
- Как получить доступ к ресурсам данных версии 1.
Необходимые компоненты
Подписка Azure. Если у вас еще нет подписки Azure, создайте бесплатную учетную запись, прежде чем начинать работу. Попробуйте бесплатную или платную версию Машинного обучения Azure.
Рабочая область Машинного обучения Azure
Быстрое начало
Перед изучением подробных параметров, доступных при доступе к данным, мы сначала описываем соответствующие фрагменты кода для доступа к данным.
Чтение данных из хранилища Azure в задании Машинное обучение Azure
В этом примере вы отправляете задание Машинное обучение Azure, которое обращается к данным из общедоступной учетной записи хранения BLOB-объектов. Однако фрагмент кода можно адаптировать для доступа к собственным данным в частной учетной записи служба хранилища Azure. Обновите путь, как описано здесь. Машинное обучение Azure легко обрабатывает проверку подлинности в облачном хранилище с помощью сквозного руководства Microsoft Entra. При отправке задания можно выбрать следующее:
- Удостоверение пользователя: передача удостоверения Microsoft Entra для доступа к данным
- Управляемое удостоверение: используйте управляемое удостоверение целевого объекта вычислений для доступа к данным.
- Нет. Не указывайте удостоверение для доступа к данным. Использование None при использовании хранилищ данных на основе учетных данных (маркера ключа или SAS) или при доступе к общедоступным данным
Совет
Если вы используете ключи или маркеры SAS для проверки подлинности, рекомендуется создать хранилище данных Машинного обучения Azure. Среда выполнения автоматически подключается к хранилищу без предоставления учетных данных.
from azure.ai.ml import command, Input, MLClient, UserIdentityConfiguration, ManagedIdentityConfiguration
from azure.ai.ml.entities import Data
from azure.ai.ml.constants import AssetTypes, InputOutputModes
from azure.identity import DefaultAzureCredential
# Set your subscription, resource group and workspace name:
subscription_id = "<SUBSCRIPTION_ID>"
resource_group = "<RESOURCE_GROUP>"
workspace = "<AML_WORKSPACE_NAME>"
# connect to the AzureML workspace
ml_client = MLClient(
DefaultAzureCredential(), subscription_id, resource_group, workspace
)
# ==============================================================
# Set the URI path for the data.
# Supported `path` formats for input include:
# local: `./<path>
# Blob: wasbs://<container_name>@<account_name>.blob.core.windows.net/<path>
# ADLS: abfss://<file_system>@<account_name>.dfs.core.windows.net/<path>
# Datastore: azureml://datastores/<data_store_name>/paths/<path>
# Data Asset: azureml:<my_data>:<version>
# Supported `path` format for output is:
# Datastore: azureml://datastores/<data_store_name>/paths/<path>
# We set the input path to a file on a public blob container
# ==============================================================
path = "wasbs://data@azuremlexampledata.blob.core.windows.net/titanic.csv"
# ==============================================================
# What type of data does the path point to? Options include:
# data_type = AssetTypes.URI_FILE # a specific file
# data_type = AssetTypes.URI_FOLDER # a folder
# data_type = AssetTypes.MLTABLE # an mltable
# The path we set above is a specific file
# ==============================================================
data_type = AssetTypes.URI_FILE
# ==============================================================
# Set the mode. The popular modes include:
# mode = InputOutputModes.RO_MOUNT # Read-only mount on the compute target
# mode = InputOutputModes.DOWNLOAD # Download the data to the compute target
# ==============================================================
mode = InputOutputModes.RO_MOUNT
# ==============================================================
# You can set the identity you want to use in a job to access the data. Options include:
# identity = UserIdentityConfiguration() # Use the user's identity
# identity = ManagedIdentityConfiguration() # Use the compute target managed identity
# ==============================================================
# This example accesses public data, so we don't need an identity.
# You also set identity to None if you use a credential-based datastore
identity = None
# Set the input for the job:
inputs = {
"input_data": Input(type=data_type, path=path, mode=mode)
}
# This command job uses the head Linux command to print the first 10 lines of the file
job = command(
command="head ${{inputs.input_data}}",
inputs=inputs,
environment="azureml://registries/azureml/environments/sklearn-1.1/versions/4",
compute="cpu-cluster",
identity=identity,
)
# Submit the command
ml_client.jobs.create_or_update(job)
Запись данных из задания Машинное обучение Azure в служба хранилища Azure
В этом примере вы отправляете задание Машинное обучение Azure, которое записывает данные в хранилище данных по умолчанию Машинное обучение Azure. При необходимости можно задать name значение ресурса данных для создания ресурса данных в выходных данных.
from azure.ai.ml import command, Input, Output, MLClient
from azure.ai.ml.constants import AssetTypes, InputOutputModes
from azure.identity import DefaultAzureCredential
# Set your subscription, resource group and workspace name:
subscription_id = "<SUBSCRIPTION_ID>"
resource_group = "<RESOURCE_GROUP>"
workspace = "<AML_WORKSPACE_NAME>"
# connect to the AzureML workspace
ml_client = MLClient(
DefaultAzureCredential(), subscription_id, resource_group, workspace
)
# ==============================================================
# Set the URI path for the data.
# Supported `path` formats for input include:
# local: `./<path>
# Blob: wasbs://<container_name>@<account_name>.blob.core.windows.net/<path>
# ADLS: abfss://<file_system>@<account_name>.dfs.core.windows.net/<path>
# Datastore: azureml://datastores/<data_store_name>/paths/<path>
# Data Asset: azureml:<my_data>:<version>
# Supported `path` format for output is:
# Datastore: azureml://datastores/<data_store_name>/paths/<path>
# As an example, we set the input path to a file on a public blob container
# As an example, we set the output path to a folder in the default datastore
# ==============================================================
input_path = "wasbs://data@azuremlexampledata.blob.core.windows.net/titanic.csv"
output_path = "azureml://datastores/workspaceblobstore/paths/quickstart-output/titanic.csv"
# ==============================================================
# What type of data are you pointing to?
# AssetTypes.URI_FILE (a specific file)
# AssetTypes.URI_FOLDER (a folder)
# AssetTypes.MLTABLE (a table)
# The path we set above is a specific file
# ==============================================================
data_type = AssetTypes.URI_FILE
# ==============================================================
# Set the input mode. The most commonly-used modes:
# InputOutputModes.RO_MOUNT
# InputOutputModes.DOWNLOAD
# Set the mode to Read Only (RO) to mount the data
# ==============================================================
input_mode = InputOutputModes.RO_MOUNT
# ==============================================================
# Set the output mode. The most commonly-used modes:
# InputOutputModes.RW_MOUNT
# InputOutputModes.UPLOAD
# Set the mode to Read Write (RW) to mount the data
# ==============================================================
output_mode = InputOutputModes.RW_MOUNT
# Set the input and output for the job:
inputs = {
"input_data": Input(type=data_type, path=input_path, mode=input_mode)
}
outputs = {
"output_data": Output(type=data_type,
path=output_path,
mode=output_mode,
# optional: if you want to create a data asset from the output,
# then uncomment `name` (`name` can be set without setting `version`, and in this way, we will set `version` automatically for you)
# name = "<name_of_data_asset>", # use `name` and `version` to create a data asset from the output
# version = "<version>",
)
}
# This command job copies the data to your default Datastore
job = command(
command="cp ${{inputs.input_data}} ${{outputs.output_data}}",
inputs=inputs,
outputs=outputs,
environment="azureml://registries/azureml/environments/sklearn-1.1/versions/4",
compute="cpu-cluster",
)
# Submit the command
ml_client.jobs.create_or_update(job)
Среда выполнения данных Машинное обучение Azure
При отправке задания среда выполнения данных Машинное обучение Azure управляет загрузкой данных из расположения хранилища в целевой объект вычислений. Среда выполнения данных Машинное обучение Azure оптимизирована для ускорения и эффективности задач машинного обучения. Основные преимущества:
- Данные загружаются на языке Rust, который известен высокой скоростью и высокой эффективностью памяти. Для параллельных скачивание данных Rust избегает проблем с блокировкой глобального интерпретатора Python (GIL)
- Легкий вес; Rust не имеет зависимостей от других технологий , например JVM. В результате среда выполнения быстро устанавливается и не очищает дополнительные ресурсы (ЦП, память) на целевом объекте вычислений.
- Загрузка данных с несколькими процессами (параллельно)
- Предварительно загружает данные как фоновую задачу на одном или нескольких ЦП, для лучшего использования GPU при выполнении глубокого обучения.
- Простая обработка проверки подлинности в облачном хранилище
- Предоставляет параметры для подключения данных (потока) или скачивания всех данных. Дополнительные сведения см. в разделах "Подключение (потоковая передача") и "Скачать ".
- Простая интеграция с fsspec — единый интерфейс pythonic для локальных, удаленных и внедренных файловых систем и хранилища байтов.
Совет
Мы рекомендуем применить среду выполнения данных машинного обучения Azure вместо создания собственной возможности подключения и скачивания в коде обучения (клиента). Мы наблюдали ограничения пропускной способности хранилища, когда клиентский код использует Python для скачивания данных из хранилища из-за проблем с глобальной блокировкой интерпретаторов (GIL).
Пути
При предоставлении входных или выходных данных заданию необходимо указать path параметр, указывающий расположение данных. В этой таблице показаны различные расположения данных, поддерживаемые Машинным обучением Azure, и приведены path примеры параметров:
| Расположение | Примеры | Входные данные | Выходные данные |
|---|---|---|---|
| Путь к локальному компьютеру | ./home/username/data/my_data |
У | Н |
| Путь на общедоступном сервере HTTP(S) | https://raw.githubusercontent.com/pandas-dev/pandas/main/doc/data/titanic.csv |
У | Н |
| Путь к службе хранилища Azure | wasbs://<container_name>@<account_name>.blob.core.windows.net/<path>abfss://<file_system>@<account_name>.dfs.core.windows.net/<path> |
Y, только для проверки подлинности на основе удостоверений | Н |
| Путь к хранилищу данных Машинное обучение Azure | azureml://datastores/<data_store_name>/paths/<path> |
У | У |
| Путь к ресурсу данных | azureml:<my_data>:<version> |
У | N, но вы можете использовать name и version создать ресурс данных из выходных данных |
Режимы
При запуске задания с входными и выходными данными можно выбрать из следующих параметров режима :
ro_mount: подключите расположение хранилища как доступное только для чтения в целевом объекте вычислений локального диска (SSD).rw_mount: подключите расположение хранилища в качестве записи на локальном диске (SSD).download: скачайте данные из расположения хранилища в целевой объект вычислений локального диска (SSD).upload: отправка данных из целевого объекта вычислений в расположение хранилища.eval_mount/eval_download:эти режимы уникальны для MLTable. В некоторых сценариях mlTable может давать файлы, которые могут находиться в учетной записи хранения, отличной от учетной записи хранения, в которую размещается файл MLTable. Кроме того, mlTable может подмножество или перемешить данные, расположенные в ресурсе хранилища. Это представление подмножества или перетасовки становится видимым только в том случае, если среда выполнения данных Машинного обучения Azure оценивает файл MLTable. Например, на этой схеме показано, как MLTable, используемая сeval_mountилиeval_download, может принимать изображения из двух разных контейнеров хранилища и файл аннотаций, расположенный в другой учетной записи хранения, а затем монтировать или загружать в файловую систему удаленной вычислительной цели.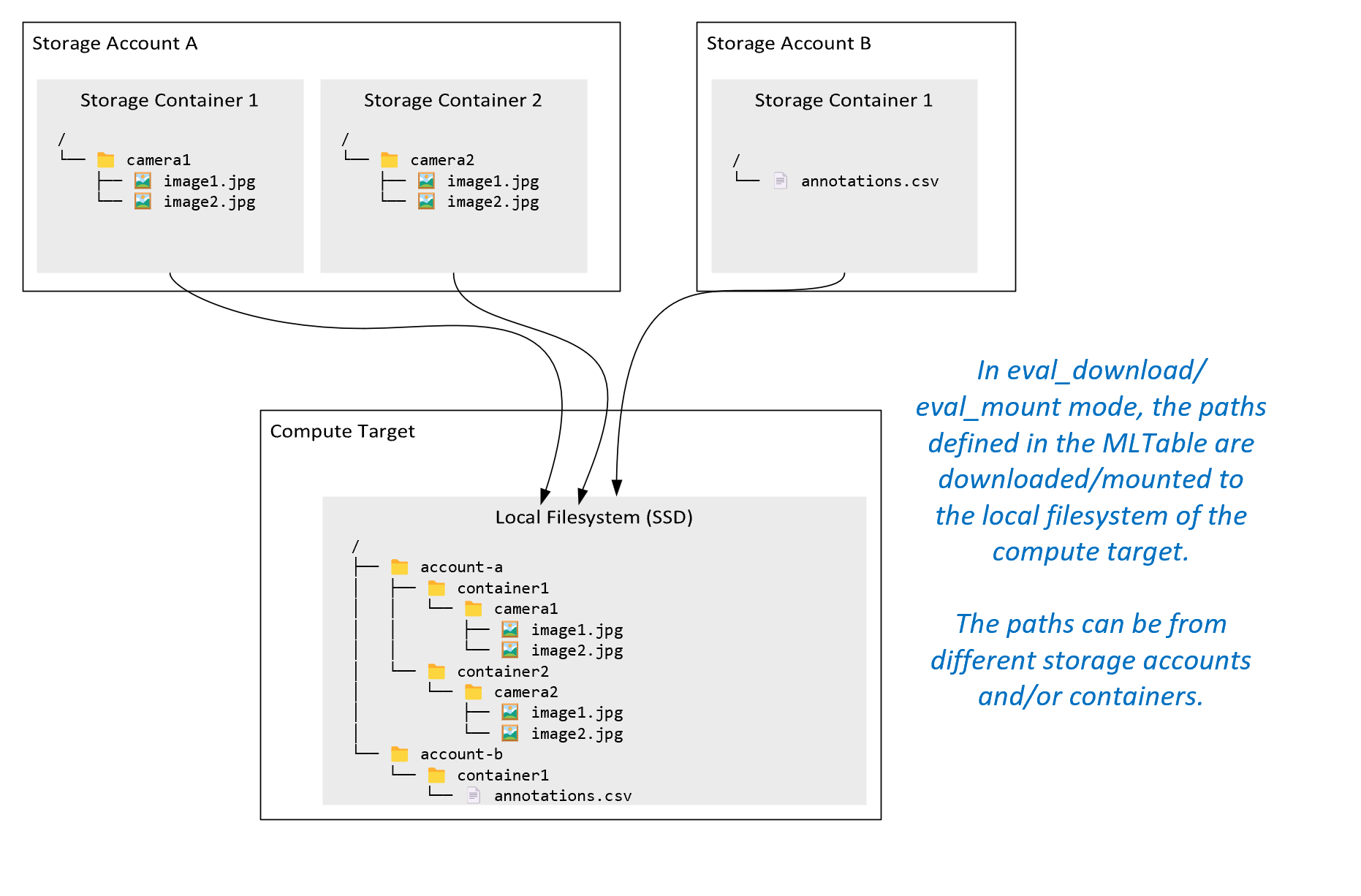
Затем
camera1папка,camera2папка иannotations.csvфайл доступны в файловой системе целевого объекта вычислений в структуре папок:/INPUT_DATA ├── account-a │ ├── container1 │ │ └── camera1 │ │ ├── image1.jpg │ │ └── image2.jpg │ └── container2 │ └── camera2 │ ├── image1.jpg │ └── image2.jpg └── account-b └── container1 └── annotations.csvdirect: вы можете считывать данные непосредственно из URI через другие API, а не проходить через среду выполнения Машинное обучение Azure данных. Например, может потребоваться получить доступ к данным в контейнере s3 (с URL-адресомhttpsстиля или пути виртуального размещения) с помощью клиента boto s3. Вы можете получить универсальный код ресурса (URI) входных данных в виде строки сdirectпомощью режима. Вы видите использование прямого режима в заданиях Spark, так какspark.read_*()методы знают, как обрабатывать URI. Для заданий, отличных от Spark, вы несете ответственность за управление учетными данными доступа. Например, необходимо явно использовать вычислительный MSI или другой доступ брокера.

В этой таблице показаны возможные режимы для различных сочетаний типов,ввода и вывода:
| Тип | Ввод-вывод | upload |
download |
ro_mount |
rw_mount |
direct |
eval_download |
eval_mount |
|---|---|---|---|---|---|---|---|---|
uri_folder |
Входные данные | ✓ | ✓ | ✓ | ||||
uri_file |
Входные данные | ✓ | ✓ | ✓ | ||||
mltable |
Входные данные | ✓ | ✓ | ✓ | ✓ | ✓ | ||
uri_folder |
Выходные данные | ✓ | ✓ | |||||
uri_file |
Выходные данные | ✓ | ✓ | |||||
mltable |
Выходные данные | ✓ | ✓ | ✓ |
Загрузка
В режиме загрузки все входные данные копируются на локальный диск (SSD) целевого объекта вычислений. Среда выполнения данных Машинное обучение Azure запускает скрипт обучения пользователей после копирования всех данных. При запуске скрипта пользователя он считывает данные с локального диска так же, как и любые другие файлы. По завершении задания данные удаляются с диска целевого объекта вычислений.
| Достоинства | Недостатки |
|---|---|
| При запуске обучения все данные доступны на локальном диске (SSD) целевого объекта вычислений для сценария обучения. Нет необходимости в службе хранилища Azure или сетевого взаимодействия. | Набор данных должен полностью соответствовать целевому диску вычислений. |
| После запуска пользовательского скрипта нет зависимостей от надежности хранилища или сети. | Весь набор данных скачивается (если обучение должно случайным образом выбрать только небольшую часть данных, большая часть загрузки будет потеряна). |
| Машинное обучение Azure среда выполнения данных может параллелизировать скачивание (значительное различие во многих небольших файлах) и максимальную пропускную способность сети или хранилища. | Задание ожидает, пока все данные не скачиваются на локальный диск целевого объекта вычислений. Для отправленного задания глубокого обучения графические процессоры бездействуют до тех пор, пока данные не будут готовы. |
| Неустранимые издержки, добавленные уровнем FUSE (roundtrip: вызов пространства пользователя в скрипте пользователя → ядром → управляющей программы → ядра → ответом на скрипт пользователя в пространстве пользователя) | Изменения хранилища не отражаются на данных после скачивания. |
Когда следует использовать скачивание
- Данные достаточно малы, чтобы поместиться на диск целевого объекта вычислений без вмешательства в другие учебные курсы
- Обучение использует большинство или все наборы данных
- Обучение считывает файлы из набора данных более одного раза
- Обучение должно переходить к случайным позициям большого файла
- Это нормально ждать, пока все скачивание данных перед началом обучения
Доступные параметры загрузки
Параметры скачивания можно настроить с помощью этих переменных среды в задании:
| Имя переменной среды | Тип | Значение по умолчанию | Описание |
|---|---|---|---|
RSLEX_DOWNLOADER_THREADS |
u64 | NUMBER_OF_CPU_CORES * 4 |
Количество одновременных потоков, которые можно использовать |
AZUREML_DATASET_HTTP_RETRY_COUNT |
u64 | 7 | Количество повторных попыток отдельного хранилища или http запроса на восстановление после временных ошибок. |
В задании можно изменить указанные выше значения по умолчанию, задав переменные среды, например:
Для краткости мы покажем, как определить переменные среды в задании.
from azure.ai.ml import command
env_var = {
"RSLEX_DOWNLOADER_THREADS": 64,
"AZUREML_DATASET_HTTP_RETRY_COUNT": 10
}
job = command(
environment_variables=env_var
)
Скачивание метрик производительности
Размер виртуальной машины целевого объекта вычислений влияет на время загрузки данных. В частности:
- Количество ядер. Чем больше ядер доступно, тем больше параллелизма и, следовательно, быстрее скачивать скорость.
- Ожидаемая пропускная способность сети. Каждая виртуальная машина в Azure имеет максимальную пропускную способность из сетевой карты (сетевой карты).
Примечание.
Для виртуальных машин GPU A100 среда выполнения данных Машинное обучение Azure может насыщать сетевую карту (сетевую карту интерфейса) при скачивании данных в целевой объект вычислений (~24 Гбит/с): теоретически максимальная пропускная способность.
В этой таблице показана производительность загрузки, Машинное обучение Azure среда выполнения данных может обрабатывать файл размером 100 ГБ на виртуальной Standard_D15_v2 машине (пропускная способность 25 Гбит/с):
| Структура данных | Только скачивание (с) | Скачивание и вычисление MD5 (с) | Достигнута пропускная способность (Гбит/с) |
|---|---|---|---|
| 10 x 10 ГБ файлов | 55.74 | 260.97 | 14.35 Гбит/с |
| 100 x 1 ГБ Файлов | 58.09 | 259.47 | 13,77 Гбит/с |
| 1 x 100 ГБ-файл | 96.13 | 300,61 | 8.32 Гбит/с |
Мы видим, что более крупный файл, разбитый на небольшие файлы, может повысить производительность загрузки из-за параллелизма. Рекомендуется избегать слишком маленьких файлов (менее 4 МБ), так как время, необходимое для отправки запросов на хранение, увеличивается относительно времени, затраченного на загрузку полезных данных. Дополнительные сведения см. в статье " Многие небольшие файлы".
Подключение (потоковая передача)
В режиме подключения возможность Машинное обучение Azure данных использует функцию FUSE (файловая система в пространстве пользователя) Linux для создания эмулированной файловой системы. Вместо скачивания всех данных на локальный диск (SSD) целевого объекта вычислений среда выполнения может реагировать на действия скрипта пользователя в режиме реального времени. Например, "open file", "read 2-KB chunk from position X", "list directory content" (Содержимое каталога списка).
| Достоинства | Недостатки |
|---|---|
| Данные, превышающие емкость локального диска целевого объекта вычислений, можно использовать (не ограничено вычислительным оборудованием). | Добавлена нагрузка на модуль FUSE Linux. |
| Задержка в начале обучения (в отличие от режима загрузки). | Зависимость от поведения кода пользователя (если обучающий код, который последовательно считывает небольшие файлы в одном потоке, также запрашивает данные из хранилища, это может не максимизировать пропускную способность сети или хранилища). |
| Дополнительные доступные параметры для настройки сценария использования. | Нет поддержки окон. |
| Только данные, необходимые для обучения, считываются из хранилища. |
Когда следует использовать подключение
- Данные большие и не помещаются на локальный диск целевого объекта вычислений.
- Каждому отдельному вычислительному узлу в кластере не нужно считывать весь набор данных (случайный файл или строки в выборе CSV-файла и т. д.).
- Задержки, ожидающие загрузки всех данных до начала обучения, могут стать проблемой (время простоя GPU).
Доступные параметры подключения
Параметры подключения можно настроить с помощью этих переменных среды в задании:
| Имя переменной Env | Тип | Значение по умолчанию | Описание |
|---|---|---|---|
DATASET_MOUNT_ATTRIBUTE_CACHE_TTL |
u64 | Не задано (срок действия кэша никогда не истекает) | Время в миллисекундах, необходимое для сохранения getattr результатов вызова в кэше, и для предотвращения последующих запросов этих сведений из хранилища снова. |
DATASET_RESERVED_FREE_DISK_SPACE |
u64 | 150 МБ | Предназначено для конфигурации системы, чтобы обеспечить работоспособность вычислений. Независимо от значений других параметров, Машинное обучение Azure среда выполнения данных не использует последние RESERVED_FREE_DISK_SPACE байты дискового пространства. |
DATASET_MOUNT_CACHE_SIZE |
usize | Не ограничено | Определяет, сколько дискового пространства может использовать. Положительное значение задает абсолютное значение в байтах. Отрицательное значение задает объем свободного места на диске. Эта таблица предоставляет дополнительные параметры кэша дисков. Поддерживает KBи MBGB модификаторы для удобства. |
DATASET_MOUNT_FILE_CACHE_PRUNE_THRESHOLD |
f64 | 1.0 | Подключение тома запускает очистку кэша при заполнении AVAILABLE_CACHE_SIZE * DATASET_MOUNT_FILE_CACHE_PRUNE_THRESHOLDкэша. Должно быть от 0 до 1.
< Установка 1 активирует запуск фонового кэша ранее.
AVAILABLE_CACHE_SIZE не является переменной среды, которую можно изменить или просмотреть напрямую. В этом контексте он ссылается на "число байтов, которые система вычисляет как доступное для кэширования". Это значение зависит от таких факторов, как размер диска, объем дискового пространства, необходимого для работоспособности системы, и конфигураций, заданных в переменных среды (например DATASET_RESERVED_FREE_DISK_SPACE , и DATASET_MOUNT_CACHE_SIZE). |
DATASET_MOUNT_FILE_CACHE_PRUNE_TARGET |
f64 | 0,7 | Запуск кэша пытается освободить по крайней мере (1-DATASET_MOUNT_FILE_CACHE_PRUNE_TARGET) пространство кэша. |
DATASET_MOUNT_READ_BLOCK_SIZE |
usize | 2 МБ | Размер блока чтения потоковой передачи. Если файл достаточно велик, запросите по крайней мере DATASET_MOUNT_READ_BLOCK_SIZE данные из хранилища и кэш, даже если требуется использовать операцию чтения меньше. |
DATASET_MOUNT_READ_BUFFER_BLOCK_COUNT |
usize | 32 | Количество блоков для предварительной выборки (блок чтения k |
DATASET_MOUNT_READ_THREADS |
usize | NUMBER_OF_CORES * 4 |
Количество фоновых потоков предварительной выборки. |
DATASET_MOUNT_BLOCK_BASED_CACHE_ENABLED |
булевая переменная (bool) | неправда | Включите кэширование на основе блоков. |
DATASET_MOUNT_MEMORY_CACHE_SIZE |
usize | 128 МБ | Применяется только к кэшированию на основе блоков. Размер кэширования на основе блоков ОЗУ может использоваться. Значение 0 полностью отключает кэширование памяти. |
DATASET_MOUNT_BLOCK_FILE_CACHE_ENABLED |
булевая переменная (bool) | правда | Применяется только к кэшированию на основе блоков. Если задано значение true, кэширование на основе блоков на основе блоков использует локальный жесткий диск. |
DATASET_MOUNT_BLOCK_FILE_CACHE_MAX_QUEUE_SIZE |
usize | 512 МБ | Применяется только к кэшированию на основе блоков. Кэширование на основе блоков записывает кэшированный блок на локальный диск в фоновом режиме. Этот параметр определяет, сколько памяти можно использовать для хранения блоков, ожидающих очистки локального кэша дисков. |
DATASET_MOUNT_BLOCK_FILE_CACHE_WRITE_THREADS |
usize | NUMBER_OF_CORES * 2 |
Применяется только к кэшированию на основе блоков. Количество фоновых потоков на основе кэширования на основе блоков используется для записи скачанных блоков на локальный диск целевого объекта вычислений. |
DATASET_UNMOUNT_TIMEOUT_SECONDS |
u64 | 30 | Время в секундах для unmount завершения всех ожидающих операций (например, вызовов очистки) перед принудительной завершением цикла сообщения подключения. |
В задании можно изменить указанные выше значения по умолчанию, задав переменные среды, например:
from azure.ai.ml import command
env_var = {
"DATASET_MOUNT_BLOCK_FILE_CACHE_ENABLED": True
}
job = command(
environment_variables=env_var
)
Режим открытия на основе блоков
Режим открытия на основе блоков разбивает каждый файл на блоки предопределенного размера (за исключением последнего блока). Запрос на чтение из указанной позиции запрашивает соответствующий блок из хранилища и возвращает запрошенные данные немедленно. Чтение также активирует фоновую предварительную выборку следующих блоков N с помощью нескольких потоков (оптимизировано для последовательного чтения). Скачанные блоки кэшируются в двух уровнях кэша (ОЗУ и локальный диск).
| Достоинства | Недостатки |
|---|---|
| Быстрая доставка данных в скрипт обучения (меньше блокировок для блоков, которые еще не запрашивались). | Случайные операции чтения могут тратить предварительно подготовленные блоки. |
| Дополнительные рабочие нагрузки на фоновые потоки (предварительная выборка или кэширование). Затем обучение может продолжиться. | Добавлена дополнительная нагрузка для перехода между кэшами по сравнению с прямыми считываниями из файла в локальном кэше дисков (например, в режиме кэша всего файла). |
| Только запрошенные данные (а также предварительная выборка) считываются из хранилища. | |
| Для небольших данных используется быстрый кэш на основе ОЗУ. |
Когда следует использовать режим открытия на основе блоков
Рекомендуется для большинства сценариев, за исключением случаев, когда требуется быстрое чтение из случайных расположений файлов. В этих случаях используйте режим открытия полного кэша файлов.
Открытый режим всего кэша файлов
При открытии файла в папке подключения (например, f = open(path, args)в целом) вызов блокируется, пока весь файл не будет загружен в папку кэша целевого объекта вычислений на диске. Все последующие вызовы чтения перенаправляются в кэшированный файл, поэтому взаимодействие с хранилищем не требуется. Если в кэше недостаточно свободного места для размещения текущего файла, подключение пытается обрезать, удалив наименее недавно использованный файл из кэша. В случаях, когда файл не может помещаться на диск (в отношении параметров кэша), среда выполнения данных возвращается в режим потоковой передачи.
| Достоинства | Недостатки |
|---|---|
| После открытия файла нет зависимостей надежности хранилища и пропускной способности. | Открытый вызов блокируется до скачивания всего файла. |
| Быстрые случайные операции чтения (считывание блоков из случайных мест файла). | Весь файл считывается из хранилища, даже если некоторые части файла могут не потребоваться. |
Сценарии использования
Если случайные операции чтения необходимы для относительно больших файлов, превышающих 128 МБ.
Использование
Задайте переменную DATASET_MOUNT_BLOCK_BASED_CACHE_ENABLEDfalse среды в задании:
from azure.ai.ml import command
env_var = {
"DATASET_MOUNT_BLOCK_BASED_CACHE_ENABLED": False
}
job = command(
environment_variables=env_var
)
Подключение: перечисление файлов
При работе с миллионами файлов избежать рекурсивного описания , например ls -R /mnt/dataset/folder/. Рекурсивное перечисление активирует множество вызовов для перечисления содержимого каталога родительского каталога. Затем требуется отдельный рекурсивный вызов для каждого каталога внутри, на всех дочерних уровнях. Как правило, служба хранилища Azure позволяет возвращать только 5000 элементов в одном запросе списка. В результате рекурсивный список папок 1M, содержащих 10 файлов, каждый из которых требует 1,000,000 / 5000 + 1,000,000 = 1,000,200 запросов к хранилищу. Для сравнения, 1000 папок с 10 000 файлами потребуется только 1001 запрос на хранение для рекурсивного списка.
Машинное обучение Azure дескриптор подключения перечисляет ленивый способ. Поэтому для перечисления множества небольших файлов лучше использовать итеративный вызов клиентской библиотеки (например, os.scandir() в Python), а не вызов клиентской библиотеки, возвращающий полный список (например, os.listdir() в Python). Вызов итеративной клиентской библиотеки возвращает генератор, то есть не нужно ждать, пока весь список не загружается. Затем он может продолжаться быстрее.
В этой таблице сравнивается время, необходимое для Python os.scandir() и os.listdir() функций для перечисления папки, содержащей ~4M-файлы в неструктурированной структуре:
| Метрика | os.scandir() |
os.listdir() |
|---|---|---|
| Время получения первой записи (с) | 0.67 | 553.79 |
| Время получения первых 50k записей (с) | 9,56 | 562.73 |
| Время получения всех записей (с) | 558.35 | 582.14 |
Оптимальные параметры подключения для распространенных сценариев
Для некоторых распространенных сценариев мы показываем оптимальные параметры подключения, которые необходимо задать в задании Машинное обучение Azure.
Считывание большого файла последовательно один раз (строки обработки в CSV-файле)
Включите эти параметры подключения в environment_variables раздел задания Машинное обучение Azure:
Примечание.
Чтобы использовать бессерверные вычисления, удалите compute="cpu-cluster", его в этом коде.
from azure.ai.ml import command
env_var = {
"DATASET_MOUNT_BLOCK_BASED_CACHE_ENABLED": True, # Enable block-based caching
"DATASET_MOUNT_BLOCK_FILE_CACHE_ENABLED": False, # Disable caching on disk
"DATASET_MOUNT_MEMORY_CACHE_SIZE": 0, # Disabling in-memory caching
# Increase the number of blocks used for prefetch. This leads to use of more RAM (2 MB * #value set).
# Can adjust up and down for fine-tuning, depending on the actual data processing pattern.
# An optimal setting based on our test ~= the number of prefetching threads (#CPU_CORES * 4 by default)
"DATASET_MOUNT_READ_BUFFER_BLOCK_COUNT": 80,
}
job = command(
environment_variables=env_var
)
Чтение большого файла один раз из нескольких потоков (обработка секционированного CSV-файла в нескольких потоках)
Включите эти параметры подключения в environment_variables раздел задания Машинное обучение Azure:
from azure.ai.ml import command
env_var = {
"DATASET_MOUNT_BLOCK_BASED_CACHE_ENABLED": True, # Enable block-based caching
"DATASET_MOUNT_BLOCK_FILE_CACHE_ENABLED": False, # Disable caching on disk
"DATASET_MOUNT_MEMORY_CACHE_SIZE": 0, # Disabling in-memory caching
}
job = command(
environment_variables=env_var
)
Чтение миллионов небольших файлов (изображений) из нескольких потоков один раз (одно эпохальное обучение на изображениях)
Включите эти параметры подключения в environment_variables раздел задания Машинное обучение Azure:
from azure.ai.ml import command
env_var = {
"DATASET_MOUNT_BLOCK_BASED_CACHE_ENABLED": True, # Enable block-based caching
"DATASET_MOUNT_BLOCK_FILE_CACHE_ENABLED": False, # Disable caching on disk
"DATASET_MOUNT_MEMORY_CACHE_SIZE": 0, # Disabling in-memory caching
}
job = command(
environment_variables=env_var
)
Чтение миллионов небольших файлов (изображений) из нескольких потоков несколько раз (обучение нескольких эпох на изображениях)
Включите эти параметры подключения в environment_variables раздел задания Машинное обучение Azure:
from azure.ai.ml import command
env_var = {
"DATASET_MOUNT_BLOCK_BASED_CACHE_ENABLED": True, # Enable block-based caching
}
job = command(
environment_variables=env_var
)
Чтение большого файла случайным поиском (например, обслуживание базы данных из подключенной папки)
Включите эти параметры подключения в environment_variables раздел задания Машинное обучение Azure:
from azure.ai.ml import command
env_var = {
"DATASET_MOUNT_BLOCK_BASED_CACHE_ENABLED": False, # Disable block-based caching
}
job = command(
environment_variables=env_var
)
Диагностика и устранение узких мест загрузки данных
Когда задание Машинное обучение Azure выполняется с данными, mode входные данные определяют, как байты считываются из хранилища и кэшируются на локальном диске SSD целевого объекта вычислений. Для режима загрузки все данные сначала сохраняются в кэше на диск, а затем начинается исполнение пользовательского кода. Некоторые факторы влияют на максимальную скорость загрузки:
- Число параллельных потоков
- Количество файлов
- Размер файла
Для режима подключения пользовательский код должен начать открывать файлы, прежде чем данные начнут кэшироваться. Различные параметры подключения приводят к различным поведением чтения и кэширования. Различные факторы влияют на скорость загрузки данных из хранилища:
- Локальность данных для вычислений: расположение хранилища и целевого объекта вычислений должно совпадать. Если целевой объект хранения и вычислений находятся в разных регионах, производительность снижается, так как данные должны передаваться между регионами. Дополнительные сведения о том, как обеспечить совместное размещение данных с вычислительными ресурсами, посетите Colocate data with compute.
-
Размер целевого объекта вычислений: небольшие вычисления имеют меньшее количество ядер (меньше параллелизма) и меньшую ожидаемую пропускную способность сети по сравнению с большими размерами вычислительных ресурсов. Оба фактора влияют на производительность загрузки данных.
- Например, если вы используете небольшой размер виртуальной машины, например
Standard_D2_v2(2 ядра, 1500 Мбит/с), и вы пытаетесь загрузить 50 000 МБ (50 ГБ) данных, то лучшее время загрузки данных составляет около 270 секунд (при условии, что вы насыщаете сетевой адаптер пропускной способностью 187,5 МБ/с). В отличие от этого(Standard_D5_v216 ядер, 12 000 Мбит/с) загрузит те же данные в ~33 с (при условии, что вы насыщаете сетевой адаптер пропускной способностью 1500 МБ/с).
- Например, если вы используете небольшой размер виртуальной машины, например
- Уровень хранилища. Для большинства сценариев , включая крупные языковые модели (LLM) — стандартное хранилище обеспечивает лучший профиль затрат и производительности. Тем не менее, если у вас много небольших файлов, хранилище класса Premium предлагает лучший профиль затрат и производительности. Дополнительные сведения см. в параметрах служба хранилища Azure.
- Загрузка хранилища. Если учетная запись хранения находится под высокой нагрузкой , например, многие узлы GPU в кластере, запрашивающие данные, рискуете получить емкость исходящего трафика. Дополнительные сведения см. в статье о загрузке хранилища. Если у вас есть несколько небольших файлов, которым требуется доступ параллельно, вы можете получить ограничения на хранение запросов. Ознакомьтесь с актуальными сведениями об ограничениях емкости исходящего трафика и запросов на хранение в целевых объектах масштабирования для стандартных учетных записей хранения.
- Шаблон доступа к данным в пользовательском коде: при использовании режима подключения данные извлекается на основе действий открытия и чтения в коде. Например, при чтении случайных разделов большого файла параметры предварительной выборки данных по умолчанию могут привести к скачиванию блоков, которые не будут считываться. Возможно, потребуется настроить некоторые параметры, чтобы достичь максимальной пропускной способности. Дополнительные сведения см. в разделе "Параметры оптимального подключения" для распространенных сценариев.
Использование журналов для диагностики проблем
Чтобы получить доступ к журналам среды выполнения данных из задания, выполните следующие действия.
- На странице задания выберите вкладку "Выходные данные+Журналы ".
- Выберите папку system_logs , а затем data_capability папку.
- Вы увидите два файла журнала:
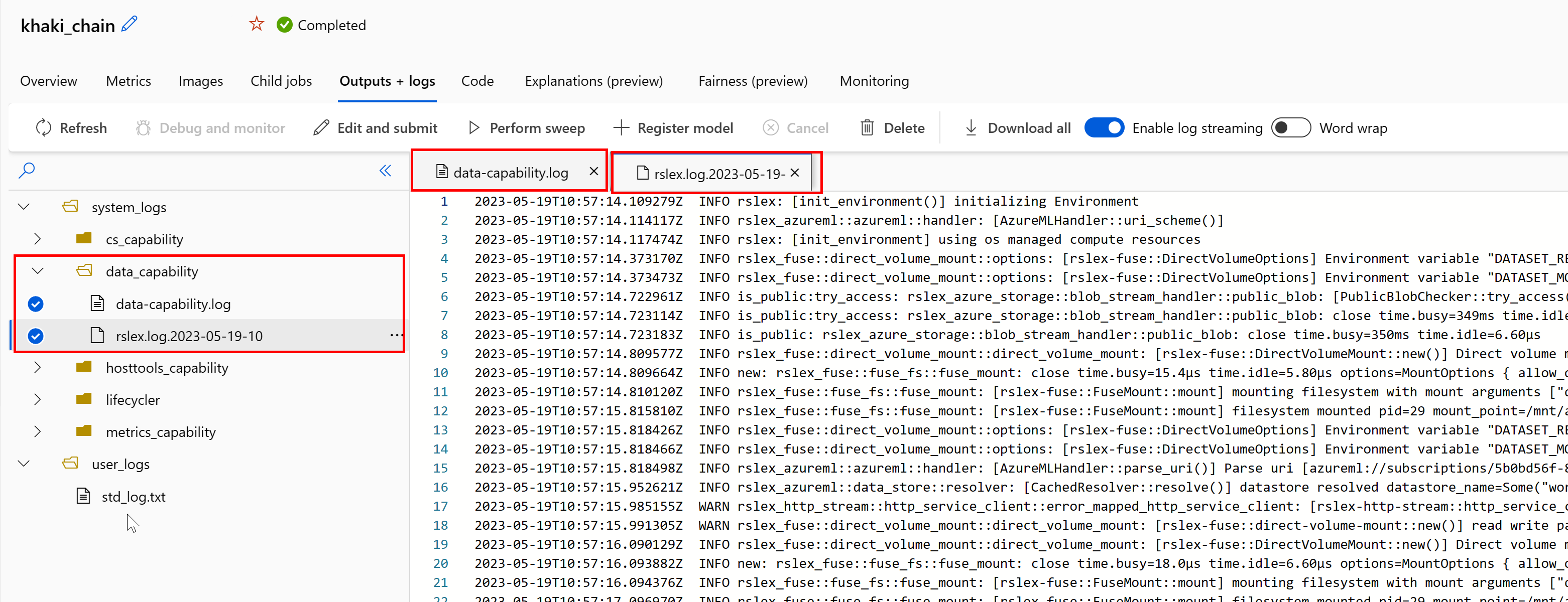

В файле журнала data-capability.log показаны общие сведения о времени, затраченном на загрузку ключевых данных. Например, при скачивании данных среда выполнения регистрирует время начала и окончания действия скачивания:
INFO 2023-05-18 17:14:47,790 sdk_logger.py:44 [28] - ActivityStarted, download
INFO 2023-05-18 17:14:50,295 sdk_logger.py:44 [28] - ActivityCompleted: Activity=download, HowEnded=Success, Duration=2504.39 [ms]
Если пропускная способность загрузки составляет часть ожидаемой пропускной способности сети для размера виртуальной машины, можно проверить файл журнала rslex.log.<TIMESTAMP>. Этот файл содержит все подробное ведение журнала из среды выполнения на основе Rust; например, параллелизация:
2023-05-18T14:08:25.388670Z INFO copy_uri:copy_uri:copy_dataset:write_streams_to_files:collect:reduce:reduce_and_combine:reduce:get_iter: rslex::prefetching: close time.busy=23.2µs time.idle=1.90µs sessionId=012ea46a-341c-4258-8aba-90bde4fdfb51 source=Dataset[Partitions: 1, Sources: 1] file_name_column=None break_on_first_error=true skip_existing_files=false parallelization_degree=4 self=Dataset[Partitions: 1, Sources: 1] parallelization_degree=4 self=Dataset[Partitions: 1, Sources: 1] parallelization_degree=4 self=Dataset[Partitions: 1, Sources: 1] parallelization_degree=4 i=0 index=0
2023-05-18T14:08:25.388731Z INFO copy_uri:copy_uri:copy_dataset:write_streams_to_files:collect:reduce:reduce_and_combine:reduce: rslex::dataset_crossbeam: close time.busy=90.9µs time.idle=9.10µs sessionId=012ea46a-341c-4258-8aba-90bde4fdfb51 source=Dataset[Partitions: 1, Sources: 1] file_name_column=None break_on_first_error=true skip_existing_files=false parallelization_degree=4 self=Dataset[Partitions: 1, Sources: 1] parallelization_degree=4 self=Dataset[Partitions: 1, Sources: 1] parallelization_degree=4 self=Dataset[Partitions: 1, Sources: 1] parallelization_degree=4 i=0
2023-05-18T14:08:25.388762Z INFO copy_uri:copy_uri:copy_dataset:write_streams_to_files:collect:reduce:reduce_and_combine:combine: rslex::dataset_crossbeam: close time.busy=1.22ms time.idle=9.50µs sessionId=012ea46a-341c-4258-8aba-90bde4fdfb51 source=Dataset[Partitions: 1, Sources: 1] file_name_column=None break_on_first_error=true skip_existing_files=false parallelization_degree=4 self=Dataset[Partitions: 1, Sources: 1] parallelization_degree=4 self=Dataset[Partitions: 1, Sources: 1] parallelization_degree=4 self=Dataset[Partitions: 1, Sources: 1] parallelization_degree=4
Файл rslex.log содержит сведения обо всех копированиях файлов, независимо от того, выбрали ли вы режимы подключения или скачивания. Он также описывает используемые параметры (переменные среды). Чтобы начать отладку, проверьте, заданы ли параметры оптимального подключения для распространенных сценариев.
Мониторинг хранилища Azure
В портал Azure можно выбрать учетную запись хранения, а затем метрики, чтобы просмотреть метрики хранилища:

Затем вы настроите SuccessE2ELatency с помощью SuccessServerLatency. Если метрики показывают высокий уровень SuccessE2ELatency и низкую производительность SuccessServerLatency, у вас есть ограниченные доступные потоки, или вы выполняете низкое количество ресурсов, таких как ЦП, память или пропускная способность сети, необходимо:
- Используйте представление мониторинга в Студия машинного обучения Azure, чтобы проверить использование ЦП и памяти задания. Если вы не используете ЦП и память, рассмотрите возможность увеличения размера целевой виртуальной машины вычислений.
- Рассмотрите возможность увеличения
RSLEX_DOWNLOADER_THREADS, если вы скачивание, и вы не используете ЦП и память. Если вы используете подключение, необходимо увеличитьDATASET_MOUNT_READ_BUFFER_BLOCK_COUNTобъем предварительной выборки и увеличить числоDATASET_MOUNT_READ_THREADSпотоков чтения.
Если метрики показывают низкую задержку SuccessE2ELatency и низкий уровень SuccessServerLatency, но клиент испытывает высокую задержку, у вас есть задержка в запросе на хранение, который достигает службы. Необходимо проверить следующее:
- Установлено ли слишком низкое количество потоков, используемых для подключения и скачивания (
DATASET_MOUNT_READ_THREADS/RSLEX_DOWNLOADER_THREADS), относительно количества ядер, доступных в целевом объекте вычислений. Если параметр слишком мал, увеличьте количество потоков. - Задано ли слишком большое количество повторных попыток для скачивания (
AZUREML_DATASET_HTTP_RETRY_COUNT). Если да, уменьшите количество повторных попыток.
Мониторинг использования диска во время задания
В Студия машинного обучения Azure можно также отслеживать операции ввода-вывода и использования целевого диска вычислений во время выполнения задания. Перейдите к заданию и перейдите на вкладку "Мониторинг ". Эта вкладка предоставляет аналитические сведения о ресурсах задания на 30-дневной скользящей основе. Например:

Примечание.
Мониторинг заданий поддерживает только вычислительные ресурсы, которыми Машинное обучение Azure управляет. Задания со средой выполнения менее 5 минут не будут иметь достаточно данных для заполнения этого представления.
Машинное обучение Azure среда выполнения данных не использует последние RESERVED_FREE_DISK_SPACE байты дискового пространства, чтобы обеспечить работоспособность вычислений (значение 150MBпо умолчанию — ). Если диск заполнен, код записывает файлы на диск без объявления файлов в качестве выходных данных. Поэтому проверьте код, чтобы убедиться, что данные не записываются ошибочно на временный диск. Если необходимо записать файлы на временный диск, и этот ресурс становится полным, рассмотрите следующее:
- Увеличение размера виртуальной машины до одного с большим временным диском
- Настройка TTL для кэшированных данных (
DATASET_MOUNT_ATTRIBUTE_CACHE_TTL) для очистки данных с диска
Колокат данных с вычислительными ресурсами
Внимание
Если хранилище и вычислительные ресурсы находятся в разных регионах, производительность снижается, так как данные должны передаваться между регионами. Это увеличивает затраты. Убедитесь, что учетная запись хранения и вычислительные ресурсы находятся в одном регионе.
Если данные и Машинное обучение Azure рабочая область хранятся в разных регионах, рекомендуется скопировать данные в учетную запись хранения в том же регионе с помощью программы azcopy. AzCopy использует API-интерфейсы "сервер — сервер", чтобы данные копировались непосредственно между серверами хранения. Эти операции копирования не используют пропускную способность сети компьютера. Вы можете увеличить пропускную способность этих операций с помощью переменной AZCOPY_CONCURRENCY_VALUE среды. Дополнительные сведения см. в разделе "Увеличение параллелизма".
Загрузка хранилища
Одна учетная запись хранения может регулироваться при высокой нагрузке, когда:
- Задание использует множество узлов GPU
- У вашей учетной записи хранения есть множество параллельных пользователей и приложений, которые получают доступ к данным при выполнении задания.
В этом разделе показано вычисление, чтобы определить, может ли регулирование стать проблемой для рабочей нагрузки и как приблизиться к сокращению регулирования.
Вычисление ограничений пропускной способности
Учетная запись служба хранилища Azure имеет ограничение исходящего трафика по умолчанию в 120 Гбит/с. Виртуальные машины Azure имеют разные пропускную способность сети, которые влияют на теоретические числа вычислительных узлов, необходимых для достижения максимальной емкости исходящего трафика по умолчанию :
| Размер | Карточка GPU | Виртуальные ЦП | Память, ГиБ | Временное хранилище (SSD): ГиБ | Количество карт GPU | Память GPU: ГиБ | Ожидаемая пропускная способность сети (Гбит/с) | Максимальное значение по умолчанию для исходящего трафика учетной записи хранения (Gbit/s)* | Количество узлов для попадания в емкость исходящего трафика по умолчанию |
|---|---|---|---|---|---|---|---|---|---|
| Standard_ND96asr_v4 | A100 | 96 | 900 | 6 000 | 8 | 40 | двадцать четыре | 120 | 5 |
| Standard_ND96amsr_A100_v4 | A100 | 96 | 1900 | 6400 | 8 | 80 | двадцать четыре | 120 | 5 |
| Standard_NC6s_v3 | V100 | 6 | 112 | 736 | 1 | 16 | двадцать четыре | 120 | 5 |
| Standard_NC12s_v3 | V100 | 12 | 224 | 1474 | 2 | 32 | двадцать четыре | 120 | 5 |
| Standard_NC24s_v3 | V100 | двадцать четыре | 448 | 2948 | 4 | 64 | двадцать четыре | 120 | 5 |
| Standard_NC24rs_v3 | V100 | двадцать четыре | 448 | 2948 | 4 | 64 | двадцать четыре | 120 | 5 |
| Standard_NC4as_T4_v3 | T4 | 4 | 28 | 180 | 1 | 16 | 8 | 120 | 15 |
| Standard_NC8as_T4_v3 | T4 | 8 | 56 | 360 | 1 | 16 | 8 | 120 | 15 |
| Standard_NC16as_T4_v3 | T4 | 16 | 110 | 360 | 1 | 16 | 8 | 120 | 15 |
| Standard_NC64as_T4_v3 | T4 | 64 | 440 | 2880 | 4 | 64 | 32 | 120 | 3 |
Оба номера SKU A100/V100 имеют максимальную пропускную способность сети на узел 24 Гбит/с. Если каждый узел, считывающий данные из одной учетной записи, может считывать близко к теоретическим максимуму 24 Гбит/с, емкость исходящего трафика будет происходить с пятью узлами. Использование шести или более вычислительных узлов приведет к снижению пропускной способности данных на всех узлах.
Внимание
Если для рабочей нагрузки требуется более шести узлов A100/V100 или вы считаете, что вы превысите емкость исходящего трафика по умолчанию (120Gbit/s), обратитесь в службу поддержки (через портал Azure) и попросите увеличить ограничение исходящего трафика хранилища.
Масштабирование между несколькими учетными записями хранения
Вы можете превысить максимальную емкость исходящего трафика хранилища, и (или) вы можете ударить по ограничениям скорости запроса. Если возникают эти проблемы, мы рекомендуем сначала обратиться в службу поддержки, чтобы увеличить эти ограничения в учетной записи хранения.
Если вы не можете увеличить максимальную емкость исходящего трафика или ограничение скорости запроса, следует рассмотреть возможность репликации данных в нескольких учетных записях хранения. Скопируйте данные в несколько учетных записей с помощью Фабрика данных Azure, служба хранилища Azure Обозревателя или azcopyподключения всех учетных записей в задании обучения. Скачиваются только доступ к данным на подключении. Таким образом, учебный код может считывать RANK из переменной среды, чтобы выбрать, из какого из нескольких входных данных подключается, из которого требуется считывать. Определение задания передает список учетных записей хранения:
$schema: https://azuremlschemas.azureedge.net/latest/commandJob.schema.json
code: src
command: >-
python train.py
--epochs ${{inputs.epochs}}
--learning-rate ${{inputs.learning_rate}}
--data ${{inputs.cifar_storage1}}, ${{inputs.cifar_storage2}}
inputs:
epochs: 1
learning_rate: 0.2
cifar_storage1:
type: uri_folder
path: azureml://datastores/storage1/paths/cifar
cifar_storage2:
type: uri_folder
path: azureml://datastores/storage2/paths/cifar
environment: azureml:AzureML-pytorch-1.9-ubuntu18.04-py37-cuda11-gpu@latest
compute: azureml:gpu-cluster
distribution:
type: pytorch
process_count_per_instance: 1
resources:
instance_count: 2
display_name: pytorch-cifar-distributed-example
experiment_name: pytorch-cifar-distributed-example
description: Train a basic convolutional neural network (CNN) with PyTorch on the CIFAR-10 dataset, distributed via PyTorch.
Затем ваш обучающий код Python может использовать RANK для получения учетной записи хранения, относящуюся к следующему узлу:
import argparse
import os
parser = argparse.ArgumentParser()
parser.add_argument('--data', nargs='+')
args = parser.parse_args()
world_size = int(os.environ["WORLD_SIZE"])
rank = int(os.environ["RANK"])
local_rank = int(os.environ["LOCAL_RANK"])
data_path_for_this_rank = args.data[rank]
Проблема с большим количеством небольших файлов
Чтение файлов из хранилища включает выполнение запросов для каждого файла. Количество запросов для каждого файла зависит от размеров файлов и параметров программного обеспечения, обрабатывающего чтение файла.
Файлы считываются в блоках размером 1–4 МБ. Файлы меньше блока считываются с одним запросом (GET file.jpg 0–4 МБ), а файлы размером больше одного запроса на блок (GET file.jpg 0–4 МБ, GET file.jpg 4–8 МБ). В этой таблице показано, что файлы меньше блока размером 4 МБ, что приводит к большему объему запросов на хранение по сравнению с большими файлами:
| # Файлы | Размер файла | Общий размер данных | Размер блока | # Запросы на хранение |
|---|---|---|---|---|
| 2 000 000 | 500 КБ | 1 TБ | 4 МБ | 2 000 000 |
| 1 000 | 1 ГБ | 1 TБ | 4 МБ | 256 000 |
Для небольших файлов интервал задержки в основном включает обработку запросов к хранилищу вместо передачи данных. Поэтому мы предлагаем эти рекомендации, чтобы увеличить размер файла:
- Для неструктурированных данных (изображений, видео и т. д.), архивирования небольших файлов (zip/tar) для хранения их в виде большего файла, который можно считывать в нескольких блоках. Эти большие архивные файлы можно открыть в вычислительном ресурсе, и PyTorch Archive DataPipes может извлечь меньшие файлы.
- Для структурированных данных (CSV, parquet и т. д.) изучите процесс ETL, чтобы убедиться, что он объединяет файлы для увеличения размера. Spark имеет
repartition()иcoalesce()методы, помогающие увеличить размер файлов.
Если вы не можете увеличить размер файла, изучите параметры служба хранилища Azure.
параметры служба хранилища Azure
служба хранилища Azure предлагает два уровня — стандартный и премиум:
| Хранилище | Сценарий |
|---|---|
| Большой двоичный объект Azure — стандартный (HDD) | Данные структурированы в больших больших двоичных объектах — изображениях, видео и т. д. |
| Большой двоичный объект Azure — премиум (SSD) | Высокий уровень транзакций, небольшие объекты или требования к задержке хранилища с низкой скоростью хранения |
Совет
Для "многих" небольших файлов (величина КБ) рекомендуется использовать премиум (SSD), так как стоимость хранилища меньше затрат на выполнение вычислений GPU.
Чтение ресурсов данных версии 1
В этом разделе описывается чтение сущностей V1 FileDataset и TabularDataset данных в задании версии 2.
Чтение FileDataset
В объекте Input укажите type как AssetTypes.MLTABLE и mode как InputOutputModes.EVAL_MOUNT:
Примечание.
Чтобы использовать бессерверные вычисления, удалите compute="cpu-cluster", его в этом коде.
Дополнительные сведения об объекте MLClient, параметрах инициализации объектов MLClient и способах подключения к рабочей области см. в разделе "Подключение к рабочей области".
from azure.ai.ml import command
from azure.ai.ml.entities import Data
from azure.ai.ml import Input
from azure.ai.ml.constants import AssetTypes, InputOutputModes
from azure.ai.ml import MLClient
ml_client = MLClient.from_config(credential=DefaultAzureCredential())
filedataset_asset = ml_client.data.get(name="<filedataset_name>", version="<version>")
my_job_inputs = {
"input_data": Input(
type=AssetTypes.MLTABLE,
path=filedataset_asset.id,
mode=InputOutputModes.EVAL_MOUNT
)
}
job = command(
code="./src", # Local path where the code is stored
command="ls ${{inputs.input_data}}",
inputs=my_job_inputs,
environment="<environment_name>:<version>",
compute="cpu-cluster",
)
# Submit the command
returned_job = ml_client.jobs.create_or_update(job)
# Get a URL for the job status
returned_job.services["Studio"].endpoint
Чтение TabularDataset
В объекте Input укажите type как AssetTypes.MLTABLEи mode как InputOutputModes.DIRECT:
Примечание.
Чтобы использовать бессерверные вычисления, удалите compute="cpu-cluster", его в этом коде.
from azure.ai.ml import command
from azure.ai.ml.entities import Data
from azure.ai.ml import Input
from azure.ai.ml.constants import AssetTypes, InputOutputModes
from azure.ai.ml import MLClient
ml_client = MLClient.from_config(credential=DefaultAzureCredential())
filedataset_asset = ml_client.data.get(name="<tabulardataset_name>", version="<version>")
my_job_inputs = {
"input_data": Input(
type=AssetTypes.MLTABLE,
path=filedataset_asset.id,
mode=InputOutputModes.DIRECT
)
}
job = command(
code="./src", # Local path where the code is stored
command="python train.py --inputs ${{inputs.input_data}}",
inputs=my_job_inputs,
environment="<environment_name>:<version>",
compute="cpu-cluster",
)
# Submit the command
returned_job = ml_client.jobs.create_or_update(job)
# Get a URL for the status of the job
returned_job.services["Studio"].endpoint