Примечание.
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
В этой статье описываются основные понятия и терминология Центров событий Azure. Общие сведения см. в разделе "Что такое Центры событий"?
Основные понятия на первый взгляд
| Понятие | Description |
|---|---|
| Пространство имен | Контейнер управления для одного или нескольких центров событий. Управляет доступом к сети и масштабированием. |
| Концентратор событий | Журнал только для добавления, в который хранятся события. Эквивалентен теме Kafka. |
| Раздел | Упорядоченная последовательность событий в концентраторе событий. Включает параллельную обработку. |
| Производитель или издатель | Приложение, которое отправляет события в концентратор событий. |
| Потребитель | Приложение, которое считывает события из концентратора событий. |
| Группа потребителей | Независимое представление потока событий. Несколько групп могут считывать одни и те же данные отдельно. |
| смещение | Положение события в разделе. Используется для отслеживания хода чтения. |
| Контрольная точка | Сохранение текущего смещения, чтобы потребители могли возобновить работу с того места, где остановились. |
Architecture
Пространство имен
Пространство имен Центров событий — это управляющий контейнер для Центров событий (или разделов в терминологии Kafka). Он предоставляет сетевые конечные точки и управляет доступом через такие функции, как фильтрация IP-адресов, конечные точки службы виртуальной сети и приватный канал.

Перегородки
Центры событий упорядочивают последовательности событий, отправленных в концентратор событий, в одну или несколько секций. По мере поступления новых событий они добавляются в конец этой последовательности.

Раздел можно рассматривать как журнал фиксации. Разделы содержат данные о событиях, включающие следующие сведения:
- Содержимое события
- Определяемый пользователем контейнер свойств, описывающий событие
- Метаданные, такие как смещение в разделе, номер в последовательности потока
- Метка времени на стороне службы, в которой она была принята

Преимущества использования секций
Служба "Центры событий" предназначена для обработки больших объемов событий, а секционирование помогает при этом двумя способами.
- Несмотря на то, что Центры событий — это служба PaaS, под ней есть физическая реальность. Сохранение журнала, сохраняющего порядок событий, требует, чтобы эти события хранились вместе в базовом хранилище и ее репликах, что приводит к потолку пропускной способности для такого журнала. Секционирование позволяет использовать несколько параллельных журналов для одного концентратора событий и, таким образом, увеличивает доступную пропускную способность ввода-вывода.
- Ваши приложения должны справляться с обработкой объема событий, отправляемых в концентратор событий. Это может быть сложно и требует значительных ресурсов для масштабной, параллельной обработки. Емкость одного процесса обработки событий ограничена, поэтому вам требуется несколько процессов. Разделы — это способ, как ваше решение распределяет эти процессы и при этом заботится о том, чтобы у каждого события был четкий ответственный за обработку.
Количество разделов
Количество разделов задается при создании концентратора событий. Оно должно быть между одним и максимальным числом секций, разрешенным для каждой ценовой категории. Для получения информации о лимите количества разделов для каждого уровня см. в этой статье.
Рекомендуем выбрать как минимум столько разделов, сколько потребуется при пиковой нагрузке вашего приложения для данного концентратора событий.
Для уровней, отличных от уровня "Премиум" и выделенных уровней, нельзя изменить число секций для концентратора событий после его создания. Для концентратора событий уровня "Премиум" или "Выделенный" после его создания можно увеличить число разделов, но их нельзя уменьшить. Распределение потоков по разделам изменится после завершения сопоставления ключей секций с разделами, поэтому следует избегать таких изменений, если относительный порядок событий важен для вашего приложения.
Установить для количества секций максимально допустимое значение может быть заманчиво, но всегда помните, что ваши потоки событий должны быть структурированы так, чтобы вы действительно могли воспользоваться преимуществами нескольких секций. Если требуется абсолютное сохранение порядка во всех событиях или только в небольшом количестве подпотоков, вам может не удасться воспользоваться преимуществами множества разделов. Кроме того, наличие большого количества разделов усложняет обработку.
Когда речь идет о ценообразовании, не важно, сколько разделов находится в концентраторе событий. Это зависит от количества единиц ценообразования (единиц пропускной способности для стандартного уровня, единиц обработки для уровня "Премиум" и единиц мощности для уровня "Выделенный") для пространства имен или выделенного кластера. Например, концентратор событий стандартного уровня с 32 секциями или с одной секцией влечет за собой одинаковую стоимость, если пространство имен имеет вместимость в один TU. Кроме того, можно масштабировать единицы транзакций (TUs) или единицы процесса (PUs) в вашем пространстве имен или единицы вычислительной мощности (CUs) в выделенном кластере независимо от количества разделов.
Раздел — это механизм организации данных, который обеспечивает параллельную публикацию и использование. Хотя она поддерживает параллельную обработку и масштабирование, общая емкость остается ограниченной за счёт масштабирования неймспейса. Балансируйте единицы масштабирования (единицы пропускной способности для стандартного уровня, единицы обработки для уровня "Премиум" или единицы емкости для выделенного уровня) и секции для достижения оптимального масштаба.
Начните с профиля рабочей нагрузки: средний размер полезных данных, события в секунду и чувствительность к снижению пропускной способности или пиков задержки. Используйте пропускную способность для секции ниже в качестве отправной точки, а затем проверьте с помощью нагрузочных тестов:
- Стандартный уровень: 1 МБ/с входящего трафика и около 2 МБ/с исходящего трафика на секцию.
- Уровни "Премиум" и "Выделенные": 1–2 МБ/с входящего трафика и 2–5 МБ/с исходящего трафика на раздел.
Оцените секции, разделив ожидаемые входящий трафик и исходящие данные по применимым тарифам на секции и принимая более крупный результат. Если наблюдаемая пропускная способность или задержка не соответствует ожиданиям, увеличьте секции (только категории "Премиум" и "Выделенные") и повторите тестирование.
Разделы также задают потолок для параллелизма потребителей. Принцип работы потолка зависит от типа потребителя:
-
Потребители эпохи (эксклюзивные) — используется
EventProcessorClient(.NET, Java) иEventHubConsumerClient(Python, JavaScript), что является рекомендуемым шаблоном для рабочих нагрузок AMQP. Только один потребитель эпохи может принадлежать заданной секции в группе потребителей одновременно. Если развертывать больше экземпляров процессора, чем разделов, дополнительные экземпляры не назначаются ни одному разделу и бездействуют до тех пор, пока существующий владелец не освободит один из них. Если новый потребитель подключается к более высокому уровню владения, служба отключает текущего владельца с ошибкойConsumerDisconnected, и новый потребитель становится владельцем. - Потребители без эпохи — до 5 получателей без эпохи могут одновременно считывать один раздел в группе потребителей. Каждый получатель видит одни и те же события (размыкание), поэтому этот режим не увеличивает пропускную способность обработки на секцию. Подключение потребителя эпохи к секции отключает всех потребителей, не относящихся к эпохе, в этой секции.
-
Потребители Kafka — потребители Kafka используют протокол координации группы (
group.id) вместо эпох AMQP, но модель владения секциями эквивалентна: каждая секция назначается ровно одному члену потребителя в группе потребителей одновременно. Когда новый участник присоединяется или существующий участник выходит, группа балансирует заново и перераспределяет назначения разделов. Если участников больше, чем разделов, избыточные участники не получают назначений и остаются бездействовать до тех пор, пока будущая перебалансировка не освободит раздел. Чтобы уменьшить ненужное перебалансирование, вызванное временными отключениями, задайте уникальныйgroup.instance.idдля каждого экземпляра потребителя (статическое членство).
На практике число партиций равно максимальному количеству параллельных потребителей на каждую группу потребителей, независимо от того, используются ли epoch потребители AMQP или Kafka потребители. Учитывайте это число секций при планировании горизонтального масштабирования.
Если приложение имеет сходство с определенной секцией, увеличение числа секций не является полезным. Дополнительные сведения см. в разделе Доступность и согласованность.
Сопоставление событий с разделами
Вы можете использовать ключ раздела, чтобы сопоставлять входные данные событий с определенными разделами для организации данных. Ключ секции — это указываемое отправителем значение, передаваемое в концентратор событий. Он обрабатывается через статическую хэш-функцию, которая создает распределение разделов. Если при публикации события не указать ключ раздела, используется назначение по принципу циклического перебора.
Издателю событий известен только ключ раздела, но не сам раздел, в который публикуются события. Благодаря разделению ключа и раздела отправителю не нужно знать слишком много о последующей обработке. Уникальный идентификатор устройства или пользователя является хорошим ключом раздела, но другие атрибуты, такие как географическое положение, также можно использовать для объединения связанных событий в один раздел.
Указание ключа раздела позволяет хранить связанные события в одном и том же разделе и в точно таком же порядке, в котором они прибыли. Ключ секции — это строка, которая является производной от контекста приложения и определяет взаимосвязь событий. Последовательность событий, определяемых ключом секции, называется потоком. Секция — это мультиплексное хранилище журналов для множества таких потоков.
Замечание
Хотя вы можете отправлять события непосредственно в разделы, мы не рекомендуем этого делать, особенно когда вам важна высокая доступность. Это понижает доступность концентратора событий до уровня раздела. Дополнительные сведения см. в статье Доступность и согласованность.
Производители событий
Производитель (или издатель) — это любое приложение, которое отправляет события в концентратор событий.
Параметры публикации
| Метод | Description |
|---|---|
| Azure SDK | .NET, Java, Python, JavaScript, Go |
| REST API | HTTP-запросы POST для упрощенных клиентов |
| Клиенты Kafka | Использование существующих производителей Kafka без изменений кода |
| AMQP 1.0 | Любой клиент AMQP, например Apache Qpid |
Ключевые поведенческие характеристики
- Пакетная или отдельная: публикация событий в один раз или в пакетах. Максимальное количество 1 МБ на операцию публикации.
- Ключи разделов: укажите ключ раздела для группировки связанных событий в одном разделе, чтобы обеспечить доставку в упорядоченном виде.
- Авторизация: используйте Microsoft Entra ID (OAuth2) или подписи для общего доступа (SAS) для управления доступом.

Политики издателя
Политики издателей обеспечивают детализированный контроль при наличии множества независимых издателей. Каждый издатель использует уникальный идентификатор:
//<my namespace>.servicebus.windows.net/<event hub name>/publishers/<my publisher name>
Имя издателя должно соответствовать маркеру SAS, используемому для проверки подлинности. При использовании политик издателя PartitionKey должен совпадать с именем издателя.
Потребители событий
Потребитель — это любое приложение, которое считывает события из концентратора событий. Центры событий используют модель извлечения — потребители запрашивают события, вместо того чтобы события передавались им автоматически.
Потребительские группы
Группа потребителей — это независимое представление потока событий. Несколько групп потребителей могут одновременно считывать один концентратор событий, каждый из которых отслеживает свою собственную позицию.
| Рекомендация | Recommendation |
|---|---|
| Читатели на раздел | Один активный читатель на каждый раздел в составе группы потребителей (до пяти в специальных сценариях) |
| Группа по умолчанию | Каждый концентратор событий имеет группу потребителей по умолчанию ($Default) |
| Несколько приложений | Создание отдельных групп потребителей для каждого приложения (аналитика, архивация, оповещение) |
//<my namespace>.servicebus.windows.net/<event hub name>/<Consumer Group #1>
//<my namespace>.servicebus.windows.net/<event hub name>/<Consumer Group #2>
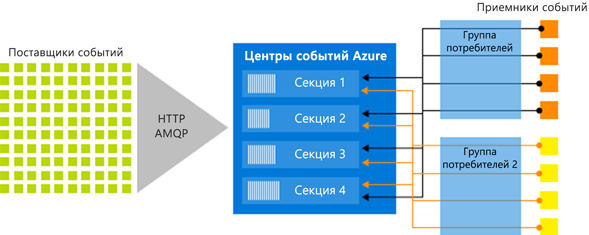
Смещения
Смещение — это положение события в секции— его можно считать курсором. Потребители используют смещения, чтобы указать, где начать чтение. Вы можете начать с:
- Определенное значение смещения
- метка времени;
- Начало или конец потока

Создание контрольных точек
Чекпоинтинг — это процесс, в котором потребитель сохраняет текущее смещение. Это позволяет:
- Возобновление: если потребитель отключается, он возобновляет работу с последней контрольной точки
- Переключение при отказе: новый экземпляр потребителя может начать с того места, где другой завершил
- Воспроизведение: обработка исторических событий через указание более раннего смещения
Это важно
В AMQP контрольные точки являются ответственностью потребителя. Служба Центров событий предоставляет смещения, но потребители должны хранить контрольные точки.
Следуйте этим рекомендациям при использовании хранилища BLOB-объектов Azure в качестве хранилища контрольных точек:
- Используйте отдельный контейнер для каждой группы потребителей. Вы можете использовать одну и ту же учетную запись хранения, но использовать один контейнер для каждой группы.
- Не используйте учетную запись хранения для других действий.
- Не используйте контейнер для ничего другого.
- Создайте учетную запись хранения в том же регионе, что и развернутое приложение. Если приложение находится в локальной среде, попробуйте выбрать ближайший регион.
На странице учетной записи хранения в портале Azure в разделе службы BLOB убедитесь, что следующие параметры отключены.
- Иерархическое пространство имен
- Обратимое удаление BLOB-объекта
- Управление версиями
Клиенты обработчика событий
Пакеты SDK Azure предоставляют интеллектуальные клиенты-потребители, которые обрабатывают управление секциями, балансировку нагрузки и контрольные точки автоматически:
| Language | Клиент |
|---|---|
| .NET | EventProcessorClient |
| Ява | EventProcessorClient |
| Питон | EventHubConsumerClient |
| JavaScript | EventHubConsumerClient |
Структура данных событий
Каждое событие содержит следующее:
- Текст: полезные данные события
- Смещение: позиция в разделе
- Порядковый номер: очередность в разделе
- Свойства пользователя: пользовательские метаданные
- Системные свойства: метаданные, назначаемые службой (время и т. д.)
Управление данными
Хранение событий
События автоматически удаляются в соответствии с временной политикой хранения.
| Тир | По умолчанию | Maximum |
|---|---|---|
| Стандарт | 1 час | 7 дней |
| Премия | 1 час | 90 дней |
| Dedicated | 1 час | 90 дней |
Основные моменты:
- События не могут быть явно удалены
- Изменения хранения применяются к существующим событиям
- События становятся недоступными именно после истечения срока хранения
Замечание
Центры событий — это подсистема потоковой передачи в режиме реального времени, а не база данных. Для долгосрочного хранения используйте "Запись центров событий" для архивации событий в службу хранилища Azure, Data Lake Storage или Azure Synapse.
Функция "Сбор" в Центрах событий
Захват автоматически сохраняет потоковые данные в Azure Blob Storage или Azure Data Lake Storage. Настройте минимальный размер и период времени для управления частотой захвата.

| Формат | Description |
|---|---|
| Avro | Формат по умолчанию для захваченных данных |
| Parquet | Доступно через редактор кода без кода на портале Azure (дополнительные сведения) |
сжатие логов
Сжатие журналов сохраняет только последнее событие для каждого уникального ключа, вместо использования хранения на основе времени. Полезно для поддержания актуального состояния без хранения полной истории.
Протоколы
Центры событий поддерживают несколько протоколов для гибкости между различными типами клиентов.
| Протокол | Отправить | Получать | Лучше всего подходит для |
|---|---|---|---|
| AMQP 1.0 | Да | Да | Высокая пропускная способность, низкая задержка, постоянные подключения |
| Apache Kafka | Да | Да | Существующие приложения Kafka (версия 1.0+) |
| HTTPS | Да | нет | Упрощенные клиенты, среды, ограниченные брандмауэром |
Сравнение протоколов
- AMQP: требуется постоянный двунаправленный сокет. Более высокая начальная стоимость, но более высокая производительность для частых операций. Используется SDK-пакетами Azure.
- Kafka: встроенная поддержка означает, что существующие приложения Kafka работают без изменений кода. Просто перенастроите сервер начальной загрузки, чтобы указать пространство имен Центров событий.
- HTTPS: простой HTTP POST для отправки. Нет поддержки. Хорошо подходит для случайной публикации с низким объемом.
Сведения об интеграции Kafka см. в разделе "Центры событий" для Apache Kafka.
Управление доступом
Майкрософт Ентра айди
Идентификатор Microsoft Entra предоставляет проверку подлинности OAuth 2.0 с помощью управления доступом на основе ролей (RBAC). Назначение встроенных ролей для управления доступом:
| Role | Permissions |
|---|---|
| Владелец данных Центров событий Azure | Полный доступ к отправке и получению событий |
| Отправитель данных Центров событий Azure | Отправлять только события |
| Приемник данных Центров событий Azure | Получать только события |
Дополнительные сведения см. в разделе "Авторизация доступа с помощью идентификатора Microsoft Entra".
Общедоступные ключи доступа (SAS)
Маркеры SAS предоставляют ограниченный доступ на уровне пространства имен или концентратора событий. Маркер SAS создается из ключа SAS и обычно предоставляет только разрешения на отправку или прослушивание .
Дополнительные сведения см. в разделе аутентификация с помощью подписи для совместного доступа.
Группы приложений
Группы приложений позволяют определять политики доступа к ресурсам (например, регулирование) для коллекций клиентских приложений, использующих контекст безопасности (политика SAS или идентификатор приложения Microsoft Entra).
Связанный контент
Начало работы
- Краткое руководство по .NET
- Краткое руководство по Java
- Краткое руководство по Python
- Краткое руководство для JavaScript
Подробнее
- Единицы масштабируемости и пропускной способности
- Доступность и согласованность
- Обзор отслеживания центров событий
- Центры событий для Apache Kafka