Примечание
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
ОБЛАСТЬ ПРИМЕНЕНИЯ: Фабрика данных Azure Azure Synapse Analytics
Фабрика данных Azure Azure Synapse Analytics
Совет
Попробуйте использовать фабрику данных в Microsoft Fabric, решение для аналитики с одним интерфейсом для предприятий. Microsoft Fabric охватывает все, от перемещения данных до обработки и анализа данных в режиме реального времени, бизнес-аналитики и отчетности. Узнайте, как бесплатно запустить новую пробную версию !
В этой статье описывается, как с помощью действия копирования в фабрике данных Azure копировать данные из конечной точки REST и обратно. Это продолжение статьи о действии копирования в Фабрике данных Azure, в которой представлены общие сведения о действии копирования.
Между соединителем REST, соединителем HTTP и соединителем веб-таблиц существуют следующие различия:
- Соединитель REST поддерживает копирование данных из API RESTful.
- Соединитель HTTP применяется для извлечения данных из любой конечной точки HTTP, например, для скачивания файла. Перед использованием этого соединителя REST вы можете использовать соединитель HTTP для копирования данных из API RESTful, что поддерживается, но менее функционально по сравнению с соединителем REST.
- Соединитель веб-таблиц извлекает содержимое таблицы со страницы HTML.
Поддерживаемые возможности
Соединитель REST поддерживает следующие возможности:
| Поддерживаемые возможности | ИНФРАКРАСНЫЙ |
|---|---|
| Действие копирования (источник/приемник) | (1) (2) |
| Сопоставление потока данных (источник/приемник) | (1) |
① Среда выполнения интеграции Azure ② Локальная среда выполнения интеграции
Список хранилищ данных, которые поддерживаются в качестве источников/приемников, см. в разделе Поддерживаемые хранилища данных.
Этот универсальный соединитель REST, в частности, поддерживает следующее.
- Копирование данных из конечной точки REST с помощью методов GET или POST и копирование данных в конечную точку REST с помощью методов POST, PUT или PATCH.
- Копирование данных с помощью одного из следующих методов аутентификации: Анонимный, Базовый, Сервисный принципал, Учетные данные клиента OAuth2, Системное управляемое удостоверение и Пользовательское управляемое удостоверение.
- Разбиение на страницы в интерфейсах REST API.
- Если источником является REST: копирование JSON ответа REST как есть или его разбор с помощью картирования схем. Поддерживается только ответ в формате JSON.
Совет
Чтобы проверить запрос для извлечения данных, прежде чем настраивать соединитель REST в Фабрике данных, ознакомьтесь с требованиями спецификации API в отношении заголовка и текста. Для проверки можно использовать такие инструменты, как Visual Studio, PowerShell Invoke-RestMethod или веб-браузер.
Предварительные требования
Если хранилище данных размещено в локальной сети, виртуальной сети Azure или виртуальном частном облаке Amazon, для подключения к нему нужно настроить локальную среду выполнения интеграции.
Если же хранилище данных представляет собой управляемую облачную службу данных, можно использовать Azure Integration Runtime. Если доступ предоставляется только по IP-адресам, утвержденным в правилах брандмауэра, вы можете добавить IP-адреса Azure Integration Runtime в список разрешений.
Вы также можете использовать функцию среды выполнения интеграции в управляемой виртуальной сети в Фабрике данных Azure для доступа к локальной сети без установки и настройки локальной среды выполнения интеграции.
Дополнительные сведения о вариантах и механизмах обеспечения сетевой безопасности, поддерживаемых Фабрикой данных, см. в статье Стратегии получения доступа к данным.
Начало работы
Чтобы выполнить действие копирования с конвейером, можно воспользоваться одним из приведенных ниже средств или пакетов SDK:
- средство копирования данных;
- Портал Azure
- Пакет SDK для .NET
- Пакет SDK для Python
- Azure PowerShell
- The REST API
- шаблон Azure Resource Manager.
Создание связанной службы REST с помощью пользовательского интерфейса
Выполните приведенные ниже действия, чтобы создать связанную службу для REST в пользовательском интерфейсе портала Azure.
Перейдите на вкладку "Управление" в Фабрике данных Azure или рабочей области Synapse и выберите "Связанные службы", затем щелкните "Создать".
Выполните поиск REST и выберите соединитель REST.
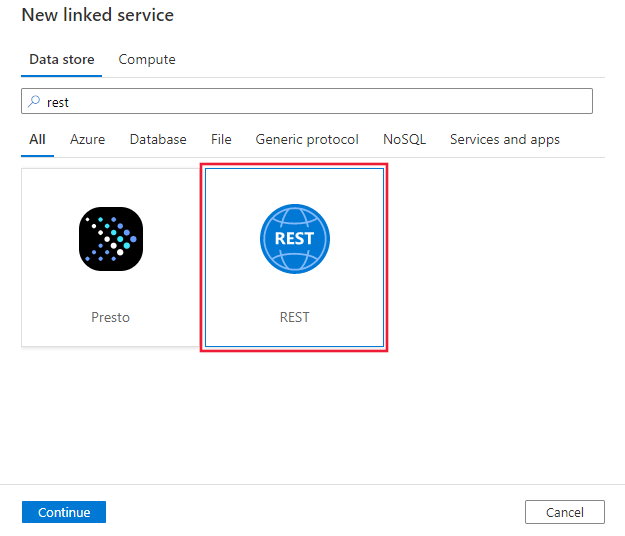
Настройте сведения о службе, проверьте подключение и создайте связанную службу.
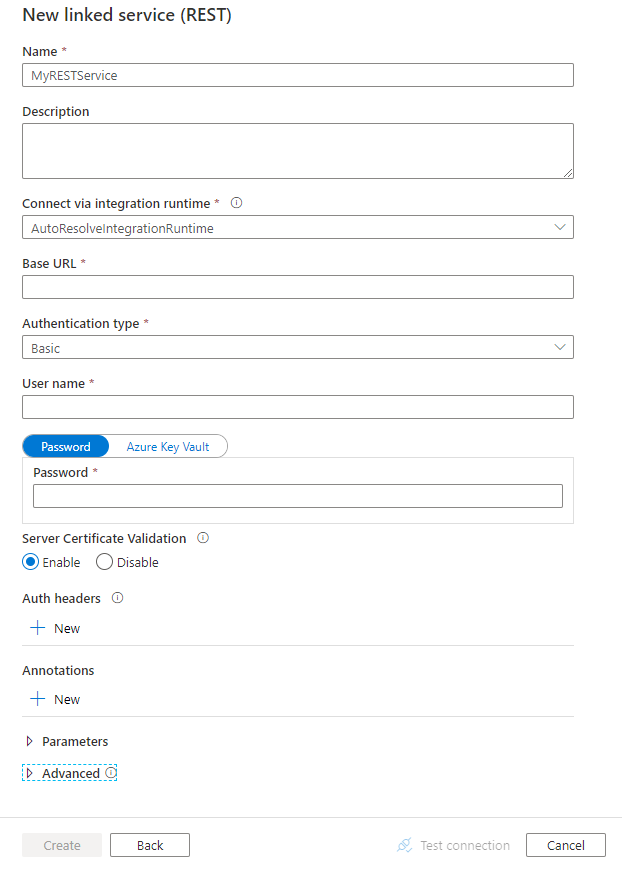


Сведения о конфигурации соединителя
В разделах ниже приведены сведения о свойствах, которые используются для определения сущностей Фабрики данных, относящихся к соединителю REST.
Свойства подключенной службы
Для связанной службы REST поддерживаются следующие свойства.
| Свойство | Описание: | Обязательное поле |
|---|---|---|
| тип | Для свойства type необходимо задать значение RestService. | Да |
| URL-адрес | Базовый URL-адрес службы REST. | Да |
| включитьПроверкуСертификатаСервера | Следует ли проверять TLS/SSL-сертификат на стороне сервера при подключении к конечной точке. | Нет (значение по умолчанию true) |
| тип аутентификации | Тип проверки подлинности, используемый для подключения к службе REST. Допустимые значения: Anonymous, Basic, AadServicePrincipal, OAuth2ClientCredential и ManagedServiceIdentity. Кроме того, можно настроить заголовки проверки подлинности в свойстве authHeaders. Обратитесь к соответствующим разделам ниже, в которых описываются дополнительные свойства и примеры. |
Да |
| authHeaders | Другие заголовки HTTP-запросов для проверки подлинности. Например, чтобы использовать проверку подлинности ключа API, можно выбрать тип проверки подлинности как "Анонимный" и указать ключ API в заголовке. |
Нет |
| connectVia | Среда выполнения интеграции, используемая для подключения к хранилищу данных. Дополнительные сведения см. в разделе Предварительные условия. Если не указано другое, это свойство по умолчанию использует интегрированную среду выполнения Azure. | Нет |
Сведения о различных типах проверки подлинности см. в соответствующих разделах.
- Обычная проверка подлинности
- Аутентификация сервисного принципала
- Проверка подлинности учетных данных клиента OAuth2
- Проверка подлинности с помощью назначенного системой управляемого удостоверения
- Аутентификация с использованием управляемого удостоверения, назначенного пользователем
- Анонимная проверка подлинности
Используйте базовую проверку подлинности
Задайте для свойства authenticationType значение Basic. В дополнение к общим свойствам, описанных в предыдущих разделах, укажите следующие свойства:
| Свойство | Описание: | Обязательное поле |
|---|---|---|
| userName | Имя пользователя для доступа к конечной точке REST. | Да |
| пароль | Пароль для пользователя (значение userName). Пометьте это поле как SecureString, чтобы безопасно хранить его в фабрике данных. Вы можете также указать секрет, хранящийся в Azure Key Vault. | Да |
Пример
{
"name": "RESTLinkedService",
"properties": {
"type": "RestService",
"typeProperties": {
"authenticationType": "Basic",
"url" : "<REST endpoint>",
"userName": "<user name>",
"password": {
"type": "SecureString",
"value": "<password>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Использование аутентификации служебной учетной записи
Задайте для свойства authenticationType значение AadServicePrincipal. В дополнение к общим свойствам, описанных в предыдущих разделах, укажите следующие свойства:
| Свойство | Описание: | Обязательное поле |
|---|---|---|
| ИдентификаторОсновногоСервиса | Укажите идентификатор клиента приложения Microsoft Entra. | Да |
| servicePrincipalCredentialType | Укажите тип учетных данных для использования при аутентификации принципала службы. Допустимые значения — ServicePrincipalKey и ServicePrincipalCert. |
Нет |
| Для ключа главного сервиса | ||
| Ключ главной службы | Укажите ключ приложения Microsoft Entra. Пометьте это поле как SecureString, чтобы безопасно хранить его в фабрике данных, или добавьте ссылку на секрет, хранящийся в Azure Key Vault. | Нет |
| Для ServicePrincipalCert | ||
| основной сервис со встроенным сертификатом | Укажите сертификат в кодировке Base64 приложения, зарегистрированного в идентификаторе Microsoft Entra ID, и убедитесь, что тип контента сертификата — PKCS #12. Пометьте это поле как SecureString, чтобы безопасно хранить его, или добавьте ссылку на секрет, хранящийся в Azure Key Vault. Перейдите в этот раздел , чтобы узнать, как сохранить сертификат в Azure Key Vault. | Нет |
| Интегрированный пароль сертификата службыPrincipal | Если ваш сертификат защищен паролем, укажите пароль сертификата. Пометьте это поле как SecureString, чтобы безопасно хранить его, или добавьте ссылку на секрет, хранящийся в Azure Key Vault. | Нет |
| арендатор | Укажите сведения о клиенте (доменное имя или идентификатор клиента), в котором находится приложение. Его можно получить, наведя указатель мыши на правый верхний угол страницы портала Azure. | Да |
| aadResourceId | Укажите ресурс Microsoft Entra, который запрашивает авторизацию, например https://management.core.windows.net. |
Да |
| тип облака Azure | Для проверки подлинности субъекта-службы укажите тип облачной среды Azure, в которой зарегистрировано приложение Microsoft Entra. Допустимые значения: AzurePublic, AzureChina, AzureUsGovernment и AzureGermany. По умолчанию используется облачная среда Фабрики данных. |
Нет |
Пример 1. Использование проверки подлинности с помощью ключа служебного принципала
{
"name": "RESTLinkedService",
"properties": {
"type": "RestService",
"typeProperties": {
"url": "<REST endpoint e.g. https://www.example.com/>",
"authenticationType": "AadServicePrincipal",
"servicePrincipalId": "<service principal id>",
"servicePrincipalCredentialType": "ServicePrincipalKey",
"servicePrincipalKey": {
"value": "<service principal key>",
"type": "SecureString"
},
"tenant": "<tenant info, e.g. microsoft.onmicrosoft.com>",
"aadResourceId": "<Azure AD resource URL e.g. https://management.core.windows.net>"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Пример 2. Использование проверки подлинности с использованием сертификата служебного принципала
{
"name": "RESTLinkedService",
"properties": {
"type": "RestService",
"typeProperties": {
"url": "<REST endpoint e.g. https://www.example.com/>",
"authenticationType": "AadServicePrincipal",
"servicePrincipalId": "<service principal id>",
"servicePrincipalCredentialType": "ServicePrincipalCert",
"servicePrincipalEmbeddedCert": {
"type": "SecureString",
"value": "<the base64 encoded certificate of your application registered in Microsoft Entra ID>"
},
"servicePrincipalEmbeddedCertPassword": {
"type": "SecureString",
"value": "<password of your certificate>"
},
"tenant": "<tenant info, e.g. microsoft.onmicrosoft.com>",
"aadResourceId": "<Azure AD resource URL e.g. https://management.core.windows.net>"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Сохраните сертификат служебного принципала в Azure Key Vault
У вас есть два варианта сохранения сертификата субъекта-службы в Azure Key Vault:
Вариант 1
Преобразуйте сертификат главного элемента службы в строку base64. Дополнительные сведения см. в этой статье.
Сохраните строку base64 в качестве секрета в Azure Key Vault.
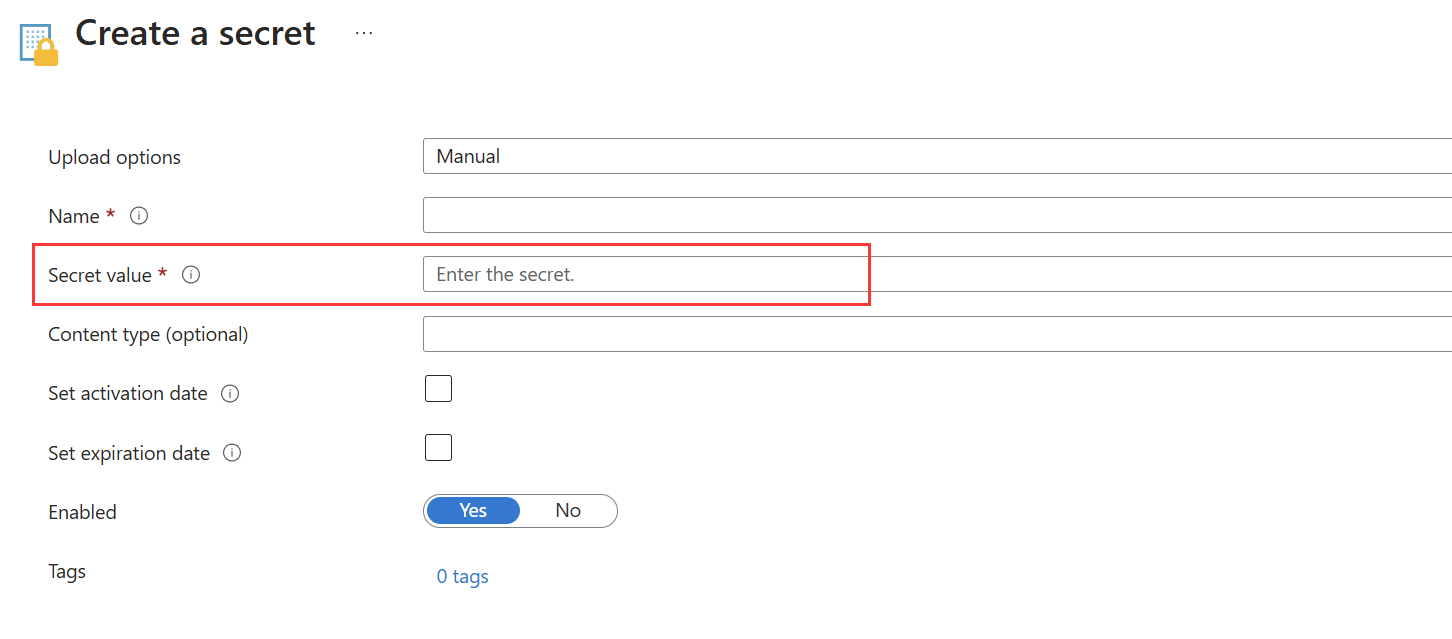
Вариант 2
Если сертификат не удается скачать из Azure Key Vault, этот шаблон можно использовать для сохранения преобразованного сертификата субъекта-службы в качестве секрета в Azure Key Vault.

Использование проверки подлинности учетных данных клиента OAuth2
Задайте для свойства authenticationType значение OAuth2ClientCredential. В дополнение к общим свойствам, описанных в предыдущих разделах, укажите следующие свойства:
| Свойство | Описание: | Обязательное поле |
|---|---|---|
| tokenEndpoint | Конечная точка токена на сервере авторизации для получения токена доступа. | Да |
| clientId | Идентификатор клиента, связанный с приложением. | Да |
| клиентский секрет | Секретный ключ клиента, связанный с вашим приложением. Пометьте это поле как SecureString, чтобы безопасно хранить его в фабрике данных. Вы можете также указать секрет, хранящийся в Azure Key Vault. | Да |
| область | Область необходимого доступа. Описывает, какой тип доступа будет запрашиваться. | Нет |
| ресурс | Целевая служба или ресурс, к которым будет запрашиваться доступ. | Нет |
Пример
{
"name": "RESTLinkedService",
"properties": {
"type": "RestService",
"typeProperties": {
"url": "<REST endpoint e.g. https://www.example.com/>",
"enableServerCertificateValidation": true,
"authenticationType": "OAuth2ClientCredential",
"clientId": "<client ID>",
"clientSecret": {
"type": "SecureString",
"value": "<client secret>"
},
"tokenEndpoint": "<token endpoint>",
"scope": "<scope>",
"resource": "<resource>"
}
}
}
Используйте аутентификацию с управляемым удостоверением, назначенным системой
Задайте для свойства authenticationType значение ManagedServiceIdentity. В дополнение к общим свойствам, описанных в предыдущих разделах, укажите следующие свойства:
| Свойство | Описание: | Обязательное поле |
|---|---|---|
| aadResourceId | Укажите ресурс Microsoft Entra, который запрашивает авторизацию, например https://management.core.windows.net. |
Да |
Пример
{
"name": "RESTLinkedService",
"properties": {
"type": "RestService",
"typeProperties": {
"url": "<REST endpoint e.g. https://www.example.com/>",
"authenticationType": "ManagedServiceIdentity",
"aadResourceId": "<AAD resource URL e.g. https://management.core.windows.net>"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Проверка подлинности с помощью управляемого удостоверения, назначаемого системой
Задайте для свойства authenticationType значение ManagedServiceIdentity. В дополнение к общим свойствам, описанных в предыдущих разделах, укажите следующие свойства:
| Свойство | Описание: | Обязательное поле |
|---|---|---|
| aadResourceId | Укажите ресурс Microsoft Entra, который запрашивает авторизацию, например https://management.core.windows.net. |
Да |
| учетные данные | Укажите назначаемое пользователем управляемое удостоверение в качестве объекта учетных данных. | Да |
Пример
{
"name": "RESTLinkedService",
"properties": {
"type": "RestService",
"typeProperties": {
"url": "<REST endpoint e.g. https://www.example.com/>",
"authenticationType": "ManagedServiceIdentity",
"aadResourceId": "<Azure AD resource URL e.g. https://management.core.windows.net>",
"credential": {
"referenceName": "credential1",
"type": "CredentialReference"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Использование заголовков проверки подлинности
Кроме того, можно настроить заголовки запроса для проверки подлинности вместе со встроенными типами проверки подлинности.
Пример. Использование проверки подлинности ключа API
{
"name": "RESTLinkedService",
"properties": {
"type": "RestService",
"typeProperties": {
"url": "<REST endpoint>",
"authenticationType": "Anonymous",
"authHeaders": {
"x-api-key": {
"type": "SecureString",
"value": "<API key>"
}
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Свойства набора данных
Этот раздел содержит список свойств, поддерживаемых набором данных REST.
Полный список разделов и свойств, доступных для определения наборов данных, см. в Наборы данных и связанные службы.
Для копирования данных из REST поддерживаются следующие свойства.
| Свойство | Описание: | Обязательное поле |
|---|---|---|
| тип | Для свойства type набора данных необходимо задать значение RestResource. | Да |
| relativeUrl | Относительный URL-адрес ресурса, который содержит данные. Если свойство не задано, используется только URL-адрес, указанный в определении связанной службы. HTTP-соединитель копирует данные из объединенного URL-адреса: [URL specified in linked service]/[relative URL specified in dataset]. |
Нет |
Если вы задали requestMethod, additionalHeaders, requestBody и paginationRules в наборе данных, он по-прежнему поддерживается as-is, хотя рекомендуется использовать новую модель для будущих операций.
Пример:
{
"name": "RESTDataset",
"properties": {
"type": "RestResource",
"typeProperties": {
"relativeUrl": "<relative url>"
},
"schema": [],
"linkedServiceName": {
"referenceName": "<REST linked service name>",
"type": "LinkedServiceReference"
}
}
}
Свойства операции копирования
Этот раздел содержит список свойств, поддерживаемых источником и приемником REST.
Полный список разделов и свойств, доступных для определения действий, см. в Конвейерах.
REST в качестве источника
В разделе source действия копирования поддерживаются следующие свойства:
| Свойство | Описание: | Обязательное поле |
|---|---|---|
| тип | Свойство type источника действия копирования должно иметь значение RestSource. | Да |
| метод запроса | Метод HTTP. Допустимые значения: GET (по умолчанию) и POST. | Нет |
| дополнительныеЗаголовки | Другие заголовки HTTP-запроса. | Нет |
| тело запроса | Текст HTTP-запроса. | Нет |
| правила разбивки страниц | Правила пагинации для составления последующих запросов страниц. Дополнительные сведения см. в разделе, посвященном поддержке разбиения на страницы. | Нет |
| тайм-аут HTTP-запроса | Время ожидания ( значение TimeSpan ) для HTTP-запроса, чтобы получить ответ. Это значение является временем ожидания для получения ответа, а не времени ожидания для чтения данных ответа. По умолчанию используется значение 00:01:40. | Нет |
| интервал запроса | Время ожидания перед отправкой запроса для следующей страницы. Значение по умолчанию — 00:00:01 | Нет |
Примечание.
Соединитель REST игнорирует любой заголовок Accept, указанный в additionalHeaders. Так как он поддерживает только ответы JSON, он автоматически задает для заголовка Accept: application/jsonзначение .
Разбиение на страницы не поддерживается для ответов REST API, где структура верхнего уровня представляет собой массив JSON.
Пример 1. Использование метода Get с разбиением на страницы
"activities":[
{
"name": "CopyFromREST",
"type": "Copy",
"inputs": [
{
"referenceName": "<REST input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "RestSource",
"additionalHeaders": {
"x-user-defined": "helloworld"
},
"paginationRules": {
"AbsoluteUrl": "$.paging.next"
},
"httpRequestTimeout": "00:01:00"
},
"sink": {
"type": "<sink type>"
}
}
}
]
Пример 2. Использование метода POST
"activities":[
{
"name": "CopyFromREST",
"type": "Copy",
"inputs": [
{
"referenceName": "<REST input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "RestSource",
"requestMethod": "Post",
"requestBody": "<body for POST REST request>",
"httpRequestTimeout": "00:01:00"
},
"sink": {
"type": "<sink type>"
}
}
}
]
REST как приемник
В разделе sink в действии копирования поддерживаются следующие свойства:
| Свойство | Описание: | Обязательное поле |
|---|---|---|
| тип | Свойство type блока назначения операции копирования должно иметь значение RestSink. | Да |
| метод запроса | Метод HTTP. Допустимые значения: POST (по умолчанию), PUT и PATCH. | Нет |
| дополнительныеЗаголовки | Другие заголовки HTTP-запроса. | Нет |
| тайм-аут HTTP-запроса | Время ожидания ( значение TimeSpan ) для HTTP-запроса, чтобы получить ответ. Это значение является временем ожидания для получения ответа, а не времени ожидания записи данных. По умолчанию используется значение 00:01:40. | Нет |
| интервал запроса | Интервал времени между разными запросами в миллисекундах. Интервал между запросами должен быть выражен числом в диапазоне от 10 до 60000. | Нет |
| ТипСжатияHTTP | Тип сжатия HTTP для использования при отправке данных с оптимальным уровнем сжатия. Допустимые значения: None и gzip. | Нет |
| writeBatchSize | Количество записей для записи в приемник REST на пакет. Значение по умолчанию — 10000. | Нет |
Соединитель REST в качестве приемника работает с API REST, принимающими JSON. Данные будут отправляться в JSON по следующему шаблону. При необходимости можно использовать сопоставление схем в действии копирования, чтобы преобразовать форму исходных данных в соответствии с ожидаемой нагрузкой данных API REST.
[
{ <data object> },
{ <data object> },
...
]
Пример:
"activities":[
{
"name": "CopyToREST",
"type": "Copy",
"inputs": [
{
"referenceName": "<input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<REST output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "<source type>"
},
"sink": {
"type": "RestSink",
"requestMethod": "POST",
"httpRequestTimeout": "00:01:40",
"requestInterval": 10,
"writeBatchSize": 10000,
"httpCompressionType": "none",
},
}
}
]
Сопоставление свойств потока данных
Интерфейс REST поддерживается в потоках данных как для интеграции наборов данных, так и для встроенных наборов данных.
Преобразование источника
| Свойство | Описание: | Обязательное поле |
|---|---|---|
| метод запроса | Метод HTTP. Допустимые значения: GET и POST. | Да |
| relativeUrl | Относительный URL-адрес ресурса, который содержит данные. Если свойство не задано, используется только URL-адрес, указанный в определении связанной службы. HTTP-соединитель копирует данные из объединенного URL-адреса: [URL specified in linked service]/[relative URL specified in dataset]. |
Нет |
| дополнительныеЗаголовки | Другие заголовки HTTP-запроса. | Нет |
| тайм-аут HTTP-запроса | Время ожидания ( значение TimeSpan ) для HTTP-запроса, чтобы получить ответ. Это значение является временем ожидания для получения ответа, а не времени ожидания записи данных. По умолчанию используется значение 00:01:40. | Нет |
| интервал запроса | Интервал времени между разными запросами в миллисекундах. Интервал между запросами должен быть выражен числом в диапазоне от 10 до 60000. | Нет |
| QueryParameters.параметр_запроса ИЛИ QueryParameters['параметр_запроса'] | "request_query_parameter" определяется пользователем и ссылается на одно имя параметра запроса в URL-адресе следующего запроса HTTP. | Нет |
Преобразование раковины
| Свойство | Описание: | Обязательное поле |
|---|---|---|
| дополнительныеЗаголовки | Другие заголовки HTTP-запроса. | Нет |
| тайм-аут HTTP-запроса | Время ожидания ( значение TimeSpan ) для HTTP-запроса, чтобы получить ответ. Это значение является временем ожидания для получения ответа, а не времени ожидания записи данных. По умолчанию используется значение 00:01:40. | Нет |
| интервал запроса | Интервал времени между разными запросами в миллисекундах. Интервал между запросами должен быть выражен числом в диапазоне от 10 до 60000. | Нет |
| ТипСжатияHTTP | Тип сжатия HTTP для использования при отправке данных с оптимальным уровнем сжатия. Допустимые значения: None и gzip. | Нет |
| writeBatchSize | Количество записей для записи в приемник REST на пакет. Значение по умолчанию — 10000. | Нет |
Вы можете задать методы delete (удалить), insert (вставить), update (обновить) и upsert (обновить или вставить), а также соответствующие данные строки для отправки в приемник REST для операций CRUD.
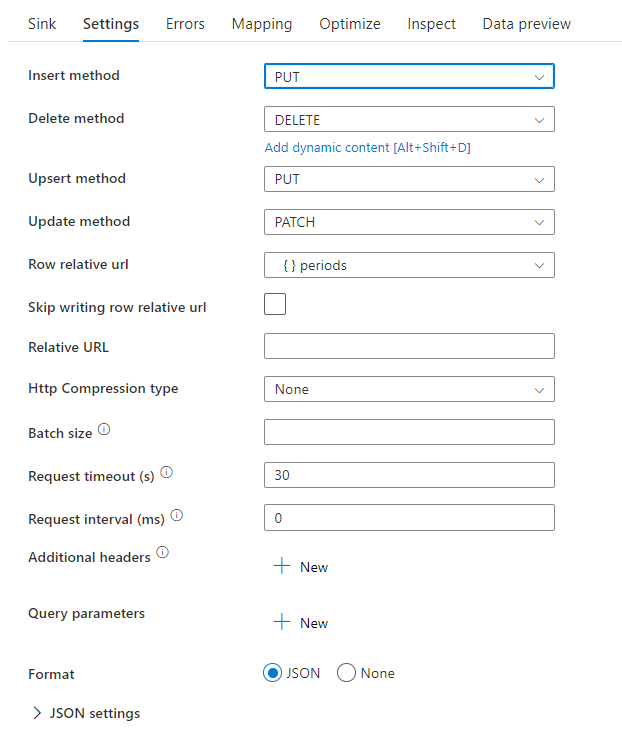
Простой скрипт потока данных
Обратите внимание на использование преобразования alter row перед приемником, чтобы указать ADF, какой тип действия следует предпринять с приемником REST. Вставка, обновление, обновление или добавление, удаление.
AlterRow1 sink(allowSchemaDrift: true,
validateSchema: false,
deletable:true,
insertable:true,
updateable:true,
upsertable:true,
rowRelativeUrl: 'periods',
insertHttpMethod: 'PUT',
deleteHttpMethod: 'DELETE',
upsertHttpMethod: 'PUT',
updateHttpMethod: 'PATCH',
timeout: 30,
requestFormat: ['type' -> 'json'],
skipDuplicateMapInputs: true,
skipDuplicateMapOutputs: true) ~> sink1
Примечание.
Поток данных создает в общей сложности вызовы API N+1 при обработке N-страниц. Это включает в себя один начальный вызов для вывода схемы, а затем вызовы N, соответствующие количеству страниц, полученных из источника.
Поддержка разбивки на страницы
При копировании данных из REST API, как правило, REST API ограничивает размер полезных данных ответа одного запроса в разумном количестве; при возврате большого объема данных он разбивает результат на несколько страниц и требует, чтобы вызывающие пользователи отправляли последовательные запросы, чтобы получить следующую страницу результата. Обычно запрос одной страницы является динамическим и состоит из сведений, возвращенных из ответа предыдущей страницы.
Этот универсальный соединитель REST поддерживает следующие шаблоны разбиения на страницы:
- абсолютный или относительный URL-адрес следующего запроса = значение свойства в текущем тексте ответа;
- абсолютный или относительный URL-адрес следующего запроса = значение заголовка в текущих заголовках ответа;
- параметр запроса следующего запроса = значение свойства в текущем тексте ответа;
- параметр запроса следующего запроса = значение заголовка в текущих заголовках ответа;
- заголовок следующего запроса = значение свойства в текущем тексте ответа;
- заголовок следующего запроса = значение заголовка в текущих заголовках ответа.
Правила разбиения на страницы определяются как словарь в наборе данных, содержащий одну или несколько пар "ключ–значение" с учетом регистра. Эта конфигурация будет использоваться для создания запроса, начиная со второй страницы. Соединитель будет прекращать итерацию при получении кода состояния HTTP 204 (Нет содержимого) или при возвращении значения null любым из выражений JSONPath в paginationRules.
Поддерживаемые ключи в правилах разбиения на страницы
| Ключ. | Описание: |
|---|---|
| AbsoluteUrl | Указывает URL-адрес для выполнения следующего запроса. Это может быть абсолютный или относительный URL-адрес. |
| QueryParameters.параметр_запроса ИЛИ QueryParameters['параметр_запроса'] | "request_query_parameter" определяется пользователем и ссылается на одно имя параметра запроса в URL-адресе следующего запроса HTTP. |
| Headers.заголовок_запроса ИЛИ Headers['заголовок_запроса'] | "заголовок_запроса" определяется пользователем и ссылается на одно имя заголовка в следующем запросе HTTP. |
| Условие_окончания:end_condition | "end_condition" определяется пользователем и указывает условие, которое завершит цикл разбиения на страницы в следующем HTTP-запросе. |
| МаксимальноеКоличествоЗапросов | Указывает максимальное число запросов разбиения на страницы. Если оставить это пустым, это будет означать отсутствие ограничений. |
| SupportRFC59888 | По умолчанию задано значение true, если правило разбиения на страницы не определено. Вы можете отключить это правило, задав для supportRFC5988 значение false или удалив это свойство из скрипта. |
Поддерживаемые значения в правилах разбиения на страницы
| значение | Описание: |
|---|---|
| Headers.заголовок_ответа ИЛИ Headers['заголовок_ответа'] | "заголовок_ответа" определяется пользователем и ссылается на одно имя заголовка в текущем ответе HTTP, значение которого будет использоваться для выдачи следующего запроса. |
| Выражение JSONPath, начинающееся с $ (представляет корневую часть текста ответа) | Текст ответа должен содержать только один объект JSON и массив объекта, так как текст ответа не поддерживается. Выражение JSONPath должно возвращать одно значение-примитив, которое будет использоваться для выдачи следующего запроса. |
Примечание.
Правила разбиения на страницы в потоках данных для сопоставления отличаются от них в действиях копирования в следующих аспектах:
- Диапазон не поддерживается в потоках данных для сопоставления.
-
['']не поддерживается в сопоставляющих потоках данных. Вместо этого используйте{}, чтобы экранировать специальный символ. напримерbody.{@odata.nextLink}, узел JSON@odata.nextLinkкоторого содержит специальный символ.. - Условие завершения поддерживается в потоках данных для сопоставления, но синтаксис условия отличается от него в действии копирования.
bodyиспользуется для указания текста ответа (вместо$).headerиспользуется для указания заголовка ответа (вместоheaders). Ниже приведены два примера, показывающие это различие:- Пример 1:
Действие копирования: "EndCondition:$.data": "Пусто"
Сопоставление потоков данных: "EndCondition:body.data": "Empty" - Пример 2:
Действие копирования: "EndCondition:headers.complete": "Exist"
Потоки данных для сопоставления: "EndCondition:header.complete": "Существует"
- Пример 1:
Примеры правил разбиения на страницы
В этом разделе приводится список примеров для параметров правил разбиения на страницы.
Пример 1. Переменные в QueryParameters
В этом примере приведены шаги настройки для отправки нескольких запросов, переменные которых находятся в QueryParameters.
Несколько запросов:
baseUrl/api/now/table/incident?sysparm_limit=1000&sysparm_offset=0,
baseUrl/api/now/table/incident?sysparm_limit=1000&sysparm_offset=1000,
......
baseUrl/api/now/table/incident?sysparm_limit=1000&sysparm_offset=10000
Шаг 1. Введите sysparm_offset={offset} в поле Базовый URL-адрес или Относительный URL-адрес, как показано на следующих снимках экрана:

или

Шаг 2. Задайте правила разбиения на страницы, как указано в варианте 1 или варианте 2:
Вариант 1: "QueryParameters.{offset}" : "RANGE:0:10000:1000"
Вариант 2: "AbsoluteUrl.{offset}" : "RANGE:0:10000:1000"
Пример 2. Переменные в AbsoluteUrl
В этом примере приведены шаги настройки для отправки нескольких запросов, переменные которых находятся в AbsoluteUrl.
Несколько запросов:
BaseUrl/api/now/table/t1
BaseUrl/api/now/table/t2
......
BaseUrl/api/now/table/t100
Шаг 1. Введите {id} в поле Базовый URL-адрес на странице настройки связанной службы или в поле Относительный URL-адрес в области подключения к набору данных.

или

Шаг 2. Задайте правила разбиения на страницы как "AbsoluteUrl.{id}" :"RANGE:1:100:1".
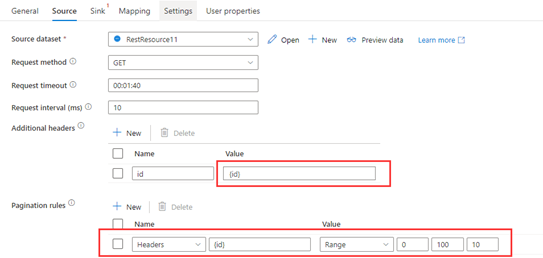
Пример 3: Переменные в заголовках
В этом примере приведены шаги настройки для отправки нескольких запросов, переменные которых находятся в заголовках.
Несколько запросов:
RequestUrl: https://example/table
Request 1: Header(id->0)
Request 2: Header(id->10)
......
Request 100: Header(id->100)
Шаг 1. Введите {id} в поле Дополнительные заголовки.
Шаг 2. Задайте правила разбиения на страницы как "Headers.{ id}" : "RANGE:0:100:10".
Пример 4:Переменные находятся в AbsoluteUrl/QueryParameters/Headers, конечная переменная не предопределена, и конечное условие основано на ответе
В этом примере приведены шаги по настройке для отправки нескольких запросов, переменные которых находятся в AbsoluteUrl/QueryParameters/Headers, но конечная переменная не определена. Для различных ответов в примерах 4.1–4.6 приведены различные параметры правил для условия завершения.
Несколько запросов:
Request 1: baseUrl/api/now/table/incident?sysparm_limit=1000&sysparm_offset=0,
Request 2: baseUrl/api/now/table/incident?sysparm_limit=1000&sysparm_offset=1000,
Request 3: baseUrl/api/now/table/incident?sysparm_limit=1000&sysparm_offset=2000,
......
В этом примере встречаются два ответа:
Ответ 1:
{
Data: [
{key1: val1, key2: val2
},
{key1: val3, key2: val4
}
]
}
Ответ 2:
{
Data: [
{key1: val5, key2: val6
},
{key1: val7, key2: val8
}
]
}
Шаг 1. Задайте диапазон правил разбиения на страницы, как показано в примере 1, и оставьте конец диапазона пустым в виде "AbsoluteUrl.{offset}": "RANGE:0::1000".
Шаг 2. Задайте разные правила условий завершения в зависимости от последнего ответа. См. примеры ниже:
Пример 4.1. Пагинация заканчивается, если значение определенного узла в ответе пусто
REST API возвращает последний ответ в следующей структуре:
{ Data: [] }Задайте правило условия завершения как "EndCondition:$.data": "Empty", чтобы завершить разбиение на страницы в том случае, если значение определенного узла в ответе пусто.

Пример 4.2: Разбиение на страницы завершается, если в ответе отсутствует значение определенного узла
REST API возвращает последний ответ в следующей структуре:
{}Установите правило конечного условия "EndCondition:$.data": "NonExist", чтобы завершить пагинацию, когда значение конкретного узла в ответе не существует.

Пример 4.3. Постраничная разбивка завершается, когда значение определенного узла существует в ответе
REST API возвращает последний ответ в следующей структуре:
{ Data: [ {key1: val991, key2: val992 }, {key1: val993, key2: val994 } ], Complete: true }Задайте правило условия завершения как "EndCondition:$.Complete": "Exist", чтобы завершить разбиение на страницы в том случае, если существует значение определенного узла в ответе.

Пример 4.4. Разбиение на страницы завершается, когда значение конкретного узла в ответе равно заданному пользователем константному значению
REST API возвращает ответ в следующей структуре:
{ Data: [ {key1: val1, key2: val2 }, {key1: val3, key2: val4 } ], Complete: false }......
А последний ответ имеет следующую структуру:
{ Data: [ {key1: val991, key2: val992 }, {key1: val993, key2: val994 } ], Complete: true }Задайте правило условия завершения как "EndCondition:$.Complete": "Const:true", чтобы завершить разбиение на страницы в том случае, если значение определенного узла в ответе равно определенному пользователем постоянному значению.

Пример 4.5. Разбиение на страницы завершается, если в ответе значение ключа заголовка равно определенному пользователем константному значению
Ключи заголовков в ответах REST API показаны в следующей структуре:
Заголовок ответа 1:
header(Complete->0)
......
Последний заголовок ответа:header(Complete->1)Задайте правило условия завершения как "EndCondition:headers.Complete": "Const:1", чтобы завершить разбиение на страницы в том случае, если значение ключа заголовка в ответе равно определенному пользователем постоянному значению.

Пример 4.6. Разбиение на страницы завершается, если ключ существует в заголовке ответа
Ключи заголовков в ответах REST API показаны в следующей структуре:
Заголовок ответа 1:
header()
......
Последний заголовок ответа:header(CompleteTime->20220920)Задайте правило условия завершения как "EndCondition:headers.CompleteTime": "Exist", чтобы завершить разбиение на страницы в том случае, если ключ существует в заголовке ответа.

Пример 5.Настройка конечного условия, чтобы избежать бесконечных запросов, если правило диапазона не определено
В этом примере приведены шаги по настройке для отправки нескольких запросов, когда правило диапазона не используется. Чтобы избежать бесконечных запросов, можно задать условие завершения, как показано в примерах 4.1–4.6. REST API возвращает ответ со следующей структурой. В этом случае URL-адрес следующей странице представлен в paging.next.
{
"data": [
{
"created_time": "2017-12-12T14:12:20+0000",
"name": "album1",
"id": "1809938745705498_1809939942372045"
},
{
"created_time": "2017-12-12T14:14:03+0000",
"name": "album2",
"id": "1809938745705498_1809941802371859"
},
{
"created_time": "2017-12-12T14:14:11+0000",
"name": "album3",
"id": "1809938745705498_1809941879038518"
}
],
"paging": {
"cursors": {
"after": "MTAxNTExOTQ1MjAwNzI5NDE=",
"before": "NDMyNzQyODI3OTQw"
},
"previous": "https://graph.facebook.com/me/albums?limit=25&before=NDMyNzQyODI3OTQw",
"next": "https://graph.facebook.com/me/albums?limit=25&after=MTAxNTExOTQ1MjAwNzI5NDE="
}
}
...
Последний ответ:
{
"data": [],
"paging": {
"cursors": {
"after": "MTAxNTExOTQ1MjAwNzI5NDE=",
"before": "NDMyNzQyODI3OTQw"
},
"previous": "https://graph.facebook.com/me/albums?limit=25&before=NDMyNzQyODI3OTQw",
"next": "Same with Last Request URL"
}
}
Шаг 1. Задайте правила разбиения на страницы как "AbsoluteUrl": "$.paging.next".
Шаг 2. Если next в последнем ответе постоянно равен последнему URL-адресу запроса и не пуст, будут отправляться бесконечные запросы. Чтобы избежать бесконечных запросов, можно использовать условие завершения. Поэтому задайте правило условия завершения, см. пример 4.1-4.6.
Пример 6. Установка максимального числа запросов для недопущения бесконечных запросов
Настройте MaxRequestNumber, чтобы не допустить бесконечные запросы, как показано на следующем снимке экрана:

Пример 7. Правило разбиения на страницы RFC 5988 поддерживается по умолчанию
Сервер будет автоматически получать следующий URL-адрес согласно ссылкам в стиле RFC 5988 в заголовке.

Совет
Если вы не хотите включать это правило разбиения на страницы по умолчанию, можно задать для supportRFC5988 значение false или просто удалить его в скрипте.
Пример 8a. Следующий URL-адрес запроса находится в тексте ответа при использовании разбиения на страницы в потоках данных сопоставления
В этом примере показано, как задать правило разбиения на страницы и правило условия завершения в потоках данных для сопоставления, если следующий URL-адрес запроса находится в тексте ответа.
Схема ответа приведена ниже:
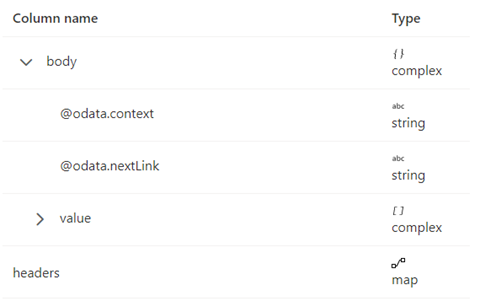
Правила разбиения на страницы должны быть заданы так, как показано на следующем снимке экрана:

По умолчанию разбиение на страницы останавливается, когда body.{@odata.nextLink}** имеет значение NULL или пусто.
Но если значение @odata.nextLink в последнем тексте ответа равно URL-адресу последнего запроса, это приведет к бесконечному циклу. Чтобы избежать этого условия, определите правила условий завершения.
Если значение в последнем ответе пусто, правило условия завершения можно задать следующим образом:

Если значение полного ключа в заголовке ответа равно true (что означает завершение разбиения на страницы), правило условия завершения можно задать следующим образом:
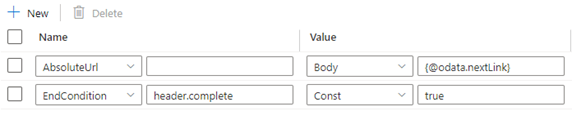
Пример 8b. Следующий URL-адрес запроса находится в тексте ответа при использовании разбиения на страницы в действии копирования
В этом примере показано, как задать правило разбиения на страницы в действии копирования, когда следующий URL-адрес запроса содержится в тексте ответа.
Схема ответа приведена ниже:
Правила разбиения на страницы должны быть заданы, как показано на следующем снимке экрана:

Пример 9. В ответе используется формат XML, а следующий URL-адрес запроса находится в тексте ответа при использовании разбиения на страницы в потоках данных для сопоставления
В этом примере показано, как задать правило разбиения на страницы в потоках данных для сопоставления, если в ответе используется формат XML, а следующий URL-адрес запроса находится в тексте ответа. Как показано на следующем снимке экрана, первый URL-адрес — https://< user.dfs.core.windows.NET/bugfix/test/movie_1.xml>
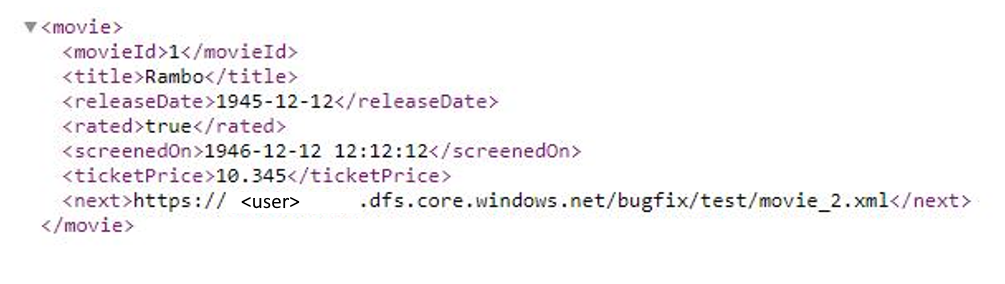
Схема ответа приведена ниже:
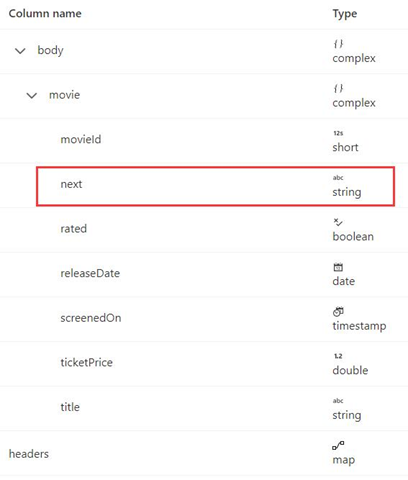
Синтаксис правила разбиения на страницы такой же, как и в примере 8, и должен быть задан следующим образом:

Экспорт ответа JSON "как есть"
Соединитель REST можно использовать для экспорта ответа JSON REST API as-is в различные системы хранения на основе файлов (приемники). Чтобы включить это поведение копирования, не зависящее от схемы, используйте сопоставление схем по умолчанию (не определяйте любое сопоставление на вкладке маппинга Copy Activity).
Сопоставление схем
Инструкции по копированию данных из конечной точки REST в табличный приемник см. в разделе о сопоставлении схем.
Связанный контент
В разделе Поддерживаемые хранилища данных и форматы приведен список хранилищ данных, которые поддерживаются в качестве источников и приемников для действия копирования в Фабрике данных Azure.