Примечание.
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
Обработка естественного языка включает методы анализа, понимания и создания человеческого языка на основе текстовых данных. Azure предоставляет управляемые службы на основе API и распределенные платформы с открытым кодом, которые решают рабочие нагрузки обработки естественного языка, которые зависят от анализа тональности и распознавания сущностей до классификации документов и суммирования текста. Это руководство поможет вам оценить и выбрать варианты обработки первичного естественного языка на Azure, чтобы обеспечить соответствие правильной технологии требованиям рабочей нагрузки.
Примечание.
В этом руководстве обсуждаются возможности обработки естественного языка, доступные через Azure Language и Apache Spark с использованием Spark NLP на Azure Databricks или Microsoft Fabric. Он не предоставляет рекомендации по выбору языковых моделей или проектированию Azure решений OpenAI. Некоторые описания платформ могут ссылаться на поддерживаемые интеграции с базовой моделью или речевой моделью в качестве сведений о реализации, но в этом руководстве основное внимание уделяется выбору службы обработки естественного языка. Дополнительные сведения см. в разделе "Выбор технологии служб искусственного интеллекта".
Общие сведения об обработке естественного языка и языковых моделях
Прежде чем оценивать службы Azure, понять, что такое обработка естественного языка, как она отличается от языковых моделей и какие задачи она решает.
Различает обработку естественного языка от языковых моделей
В этом разделе описывается граница между обработкой естественного языка и языковыми моделями, а также рассматриваются основные возможности, которые обеспечивают методы обработки естественного языка.
| Измерение | Обработка естественного языка | Языковые модели |
|---|---|---|
| Объем | Широкая область, включающая различные методы обработки текста, включая токенизацию, лемматизацию, распознавание сущностей, анализ тональности и классификацию документов. | Подмножество глубинного обучения в области обработки естественного языка, ориентированное на задачи высокого уровня понимания и генерации текста. |
| Примеры | Средства синтаксического анализа на основе правил, классификаторы TF-IDF (частотности терминов и обратной частотности документов), распознаватели именованных сущностей и анализаторы тональности. | GPT, BERT и аналогичные модели на основе трансформеров, которые создают текст, похожий на человеческий и учитывающий контекст. |
| Выходные данные | Структурированные сигналы, такие как метки, оценки, извлеченные диапазоны и синтаксический анализ. | Естественный язык, как текст, созданный с помощью Fluent, включая сводки, ответы и завершения. |
| Relationship | Родительский домен. Обработка естественного языка охватывает полный спектр методов обработки текста. | Инструмент в обработке естественного языка. Языковые модели повышают обработку естественного языка, не заменяя ее. Они обрабатывают более широкие когнитивные задачи, но не являются синонимами обработки естественного языка. |
Возможности обработки естественного языка
Классифицируйте документы, помечая их как конфиденциальные или нежелательные. Обработка естественного языка автоматически классифицирует документы на основе содержимого для поддержки соответствия требованиям и фильтрации рабочих процессов.
Подведите итог текста, определяя сущности в документе. Обработка естественного языка извлекает ключевые сущности для создания кратких сводок, которые захватывают наиболее важные сведения.
Пометьте документы с ключевыми словами с помощью определенных сущностей. После идентификации сущностей можно создать теги ключевых слов, упрощающие организацию документов. Используйте эти теги для поиска и извлечения, основанного на контенте.
Определение тем для навигации и обнаружения связанных документов. Обработка естественного языка определяет ключевые темы с помощью извлеченных сущностей, которые поддерживают классификацию документов и навигацию по темам.
Оценка тональности текста. Анализ тональности оценивает эмоциональный тон текста и классифицирует содержимое как положительное, отрицательное или нейтральное.
Передавайте выходные данные обработки естественного языка в последующие рабочие процессы. Результаты, такие как извлеченные сущности, оценки эмоциональной тональности и тематические метки, служат входными данными для обработки, индексирования поиска и аналитики.
Определение потенциальных вариантов использования
Бизнес-сценарии во многих отраслях получают преимущества от решений обработки естественного языка. В следующих случаях использования показано, как методы обработки естественного языка решают реальные проблемы, от обработки неструктурированных документов до обеспечения новых приложений в кибербезопасности и специальных возможностях.
Обработка документов и неструктурированного текста
Извлеките аналитику из документов, созданных компьютером. Обработка естественного языка обеспечивает обработку документов в сфере финансов, здравоохранения, розничной торговли, государственных организаций и других секторов. Вы можете анализировать цифровые документы для извлечения структурированных данных из неструктурированных входных данных. Для рукописных документов используйте Azure аналитику документов для преобразования рукописного содержимого в текст перед применением методов обработки естественного языка.
Применяйте независимые от отрасли задачи обработки естественного языка для обработки текста. Распознавание именованных сущностей (NER), классификация, сводка и извлечение связей помогают автоматически обрабатывать и анализировать неструктурированное содержимое документа. Эти задачи работают в разных доменах и не требуют настройки для конкретной отрасли.
Создание моделей для конкретного домена для специализированного анализа. Примерами этих задач являются модели стратификации рисков для здравоохранения, классификация онтологий для управления знаниями и сводки данных о продуктах и клиентах в розничной торговле. Обучение пользовательской модели в Azure language и Spark NLP помогает повысить точность этих форматов документов для конкретного домена.
Создайте автоматические отчеты из структурированных входных данных. Можно синтезировать и создавать комплексные текстовые отчеты из структурированных данных. Эта возможность помогает секторам, таким как финансы и соответствие требованиям, которые требуют тщательной документации.
Включение поиска, перевода и аналитики
Создайте графы знаний и включите семантический поиск с помощью получения информации. Обработка естественного языка поддерживает создание графа знаний и семантический поиск, что позволяет системам интерпретировать смысл запроса, а не полагаться только на сопоставление ключевых слов.
Поддержка обнаружения наркотиков и клинических испытаний с помощью графов медицинских знаний. Системы обработки естественного языка анализируют клинический текст. Графы медицинских знаний, созданные из этого текста, поддерживают конвейеры разработки лекарств и поиск соответствий для клинических испытаний. Эти графы соединяют такие сущности, как препараты, условия и результаты для ускорения исследовательских рабочих процессов. Text analytics для здравоохранения в службе Azure Language извлекает медицинские сущности, отношения и утверждения, которые можно использовать для создания этих графов.
Перевести текст для разговорного ИИ в клиентских приложениях. Перевод текста обеспечивает диалоговый ИИ в нескольких отраслях. Вы можете создавать многоязычные приложения, которые обрабатывают и отвечают на предпочитаемый язык пользователя. Spark NLP предоставляет возможности перевода напрямую. В Azure используйте Azure Translator, который является отдельной службой от Azure Language.
Анализ настроения и эмоционального интеллекта в восприятии бренда. Анализ тональности помогает отслеживать восприятие бренда и анализировать отзывы клиентов, выявляя положительные, отрицательные и нюансированные эмоциональные сигналы в тексте.
Расширение обработки естественного языка до новых доменов
Создание интерфейсов, активированных голосом, для Интернета вещей (IoT) и смарт-устройств. Обработка естественного языка обрабатывает текстовые выходные данные систем распознавания речи, чтобы понять намерение пользователя и извлечь смысл в сценариях Интернета вещей и смарт-устройств. Для голосовых сценариев требуется Azure Speech для преобразования речи в текст до обработки естественного языка.
Динамически настраивать выходные данные языка с помощью адаптивных языковых моделей. Адаптивные языковые модели динамически настраивают вывод на язык в соответствии с различными уровнями понимания аудитории, поддерживая доставку образовательного контента и доступность.
Обнаружение фишинга и ложной информации с помощью анализа текста кибербезопасности. Обработка естественного языка анализирует шаблоны взаимодействия и использование языка в режиме реального времени для выявления потенциальных угроз безопасности в цифровой коммуникации. Этот анализ помогает обнаруживать попытки фишинга и кампании по неверной информации.
Оценка языка Azure
Azure язык — это облачная служба, которая предоставляет функции обработки естественного языка для понимания и анализа текста. Доступ к нему можно получить с помощью портала Foundry, REST API и клиентских библиотек для Python, C#, Java и JavaScript без инфраструктуры для управления. Для разработки агента ИИ вы также можете получить доступ к этим возможностям с помощью сервера протокола контекста языковой модели Azure (MCP). Вы можете получить доступ к нему в виде удаленного сервера в каталоге инструментов Microsoft Foundry или как к локальному серверу.
Предварительно созданные компоненты
Предварительно созданные функции не требуют обучения модели и готовы к использованию:
NER: Определяет и классифицирует сущности в тексте в стандартные типы, такие как люди, организации, расположения и даты.
Обнаружение PII: Определяет и редактирует персонально идентифицируемую информацию (PII), включая конфиденциальные персональные и медицинские данные, в текстах и транскрипциях.
Обнаружение языка: Определяет язык документа в широком диапазоне языков и диалектов.
Анализ тональности и анализ мнений: Определяет положительные, отрицательные или нейтральные тональности в тексте и связывает мнения с определенными элементами, такими как атрибуты продукта или аспекты обслуживания.
Извлечение ключевых фраз: Вычисляет неструктурированный текст и возвращает список основных понятий и ключевых фраз.
Сводка: Сжимает документы и беседы с помощью извлекающих или абстрактных методов, что позволяет поддерживать сводки текста, чатов и контакт-центров.
Анализ текста для здоровья: Извлекает и аннотирует соответствующую информацию о здоровье из неструктурированного клинического текста, включая медицинские сущности, отношения и утверждения.
Обучение пользовательских моделей
Настраиваемые функции можно использовать для обучения моделей данных для обработки задач обработки естественного языка для конкретного домена:
- Распознавание именованных сущностей (CNER): Создание пользовательских моделей для извлечения категорий сущностей определенного домена из неструктурированного текста. Используйте CNER, если предварительно созданные категории NER не охватывают словарь домена.
сервер MCP и агенты языковой службы Azure
Примечание.
Сервер Azure Language MCP и как маршрутизация намерений, так и агенты для точного ответа на вопросы представлены в предварительной версии. Предварительные версии функций не включают соглашение об уровне обслуживания (SLA), и мы не рекомендуем их для рабочих нагрузок. Некоторые функции могут не поддерживаться или могут иметь ограниченные возможности. Дополнительные сведения см.: Дополнительные условия использования для предварительных версий Microsoft Azure.
язык Azure предоставляет предварительно созданные агенты и гибкие варианты развертывания для рабочих нагрузок обработки естественного языка:
Агент маршрутизации намерений: Управляет потоками бесед. Он понимает намерения пользователей и маршруты к точным ответам с помощью детерминированной, проверяемой логики. Используйте этот агент, если требуется прозрачная детерминированная маршрутизация диалога.
Точный агент ответа на вопросы: Обеспечивает точные, дословные ответы на критически важные для бизнеса вопросы при сохранении человеческого надзора и контроля качества. Используйте этот агент, если важна точность отклика и согласованность.
Вы можете получить доступ к обоим агентам через каталог инструментов Foundry. Дополнительную информацию см. в разделе Azure Language MCP сервер и агенты (предварительная версия).
Сервер MCP языка Azure поддерживает несколько вариантов развертывания:
Удаленный облачный сервер MCP: Каталог инструментов Foundry перечисляет этот сервер. Сервер предоставляет управляемый облаком доступ к возможностям языка Azure и не требует локальной инфраструктуры.
Локальный сервер MCP: Поддерживает локальные или самостоятельно управляемые развертывания для соблюдения требований соответствия, безопасности или расположения данных.
Контейнерное развертывание: Следующие функции поддерживают контейнерное развертывание для сценариев, требующих локальной обработки или изолированных сред. Полный список доступных контейнеров и их состояния доступности см. в разделе Azure поддержка контейнеров ИИ.
- анализ настроений
- Обнаружение языка
- Извлечение ключевых фраз
- НЭР
- Обнаружение PII
- CNER
- Анализ текста для сферы здравоохранения
- Сводка (предварительная версия)
Оценка Apache Spark с помощью Spark NLP
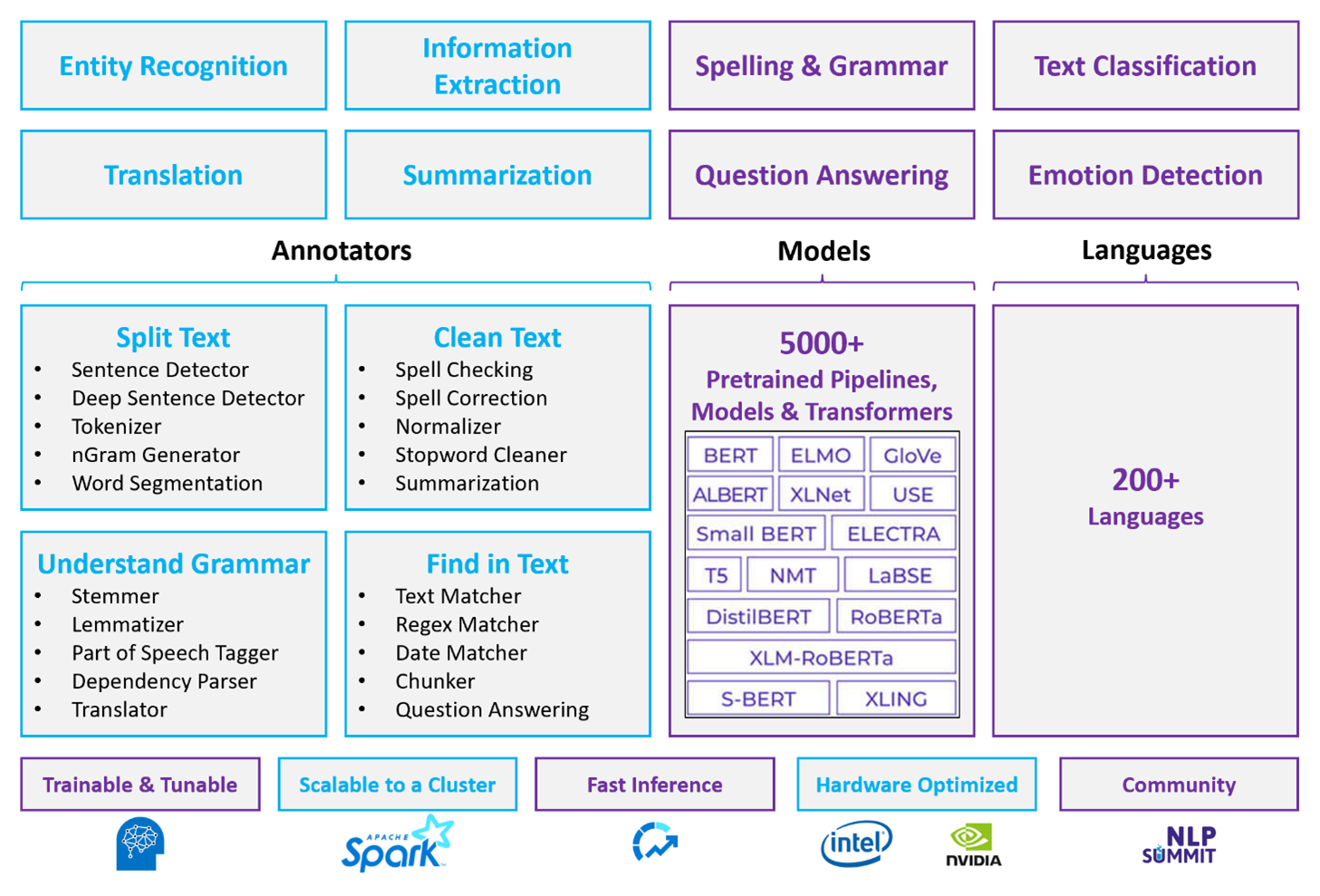
Apache Spark с Spark NLP — это распределенный подход с открытым исходным кодом к обработке естественного языка, работающий в масштабе кластера. Архитектура платформы, производительность и предварительно созданная экосистема модели Spark NLP делает ее надежным вариантом для крупномасштабных настраиваемых рабочих нагрузок обработки естественного языка в Azure Databricks или Fabric.
Общие сведения о платформе и архитектуре
Мы рекомендуем использовать Fabric или Azure Databricks для рабочих нагрузок обработки естественного языка на основе Apache Spark.
Apache Spark предоставляет параллельную обработку в памяти для аналитики больших данных. Fabric и Azure Databricks предоставляют доступ к возможностям обработки Apache Spark для крупномасштабных рабочих нагрузок обработки естественного языка.
Spark NLP работает в качестве собственного расширения Spark ML на фреймах данных. Эта интеграция обеспечивает единую обработку естественного языка и конвейеры машинного обучения с улучшенной производительностью в распределенных кластерах.
Spark NLP — это библиотека с открытым кодом с поддержкой Python, Java и Scala. Библиотека предоставляет функциональные возможности, сравнимые с spacy и набором средств естественного языка (NLTK), включая проверку орфографии, анализ тональности и классификацию документов.

Apache®, Apache Spark и логотип пламени являются зарегистрированными товарными знаками или товарными знаками Apache Software Foundation в Соединенных Штатах и/или других странах. Использование этих меток не подразумевает подтверждения от Apache Software Foundation.
Оценка производительности и масштабируемости
Общедоступные тесты показывают значительные улучшения скорости по сравнению с другими библиотеками обработки естественного языка. По сравнению с платформами, такими как spaCy и NLTK, Spark NLP демонстрирует более быстрое обучение и вывод в распределенных кластерах. Пользовательские модели, которые Spark NLP обучает, достигают уровней точности, которая сопоставима с уровнями других систем обработки естественного языка, что делает их подходящими для рабочих нагрузок, требующих скорости и точности.
Оптимизированные сборки для ЦП, GPU и микросхем Intel Xeon полностью используют кластеры Apache Spark. Эти сборки позволяют обучению и выводу эффективно масштабироваться по узлам кластера.
Внедрение MPNet и поддержка ONNX обеспечивают точную обработку с учетом контекста. MPNet создает плотное векторное представление, которое фиксирует семантические значения, и поддержка ONNX позволяет импортировать и запустить оптимизированные модели для вывода.
Использование предварительно созданных моделей и конвейеров
Предварительно созданные модели глубокого обучения обрабатывают NER, классификацию документов и обнаружение тональности. Библиотека поставляется с предварительно созданными моделями глубокого обучения.
Предварительно обученные языковые модели поддерживают внедрение слов, блоков, предложений и документов. Библиотека включает предварительно обученные языковые модели, поддерживающие уровни внедрения слов, блоков, предложений и документов. Эти внедрения обеспечивают плотное векторное представление, которое позволяет выполнять нижестоящие задачи, такие как поиск и классификация сходства.
Унифицированные конвейеры обработки естественного языка и машинного обучения поддерживают классификацию документов и прогнозирование рисков. Интеграция с Spark ML поддерживает унифицированные конвейеры обработки естественного языка и машинного обучения для таких задач, как классификация документов и прогнозирование рисков. Благодаря этому унифицированному подходу можно объединить обработку текста с традиционными моделями машинного обучения в одном конвейере, что снижает сложность архитектуры.
Устранение распространенных проблем обработки естественного языка
Оба решения Azure Language и Apache Spark с Spark NLP сталкиваются с общими проблемами при обработке естественного языка в крупном масштабе. Если вы понимаете эти проблемы, вы можете спланировать ресурсы, разработать конвейеры и установить ожидания точности перед принятием решения о любом из вариантов.
Обработка ресурсов
Для обработки текста свободной формы требуются значительные вычислительные ресурсы и время. Анализ текстовых документов свободной формы требует значительных вычислительных ресурсов и временных затрат. Для каждого документа требуется маркеризация, нормализация и вывод модели, прежде чем он создает доступные результаты.
Для рабочих нагрузок Spark NLP часто требуется развертывание вычислений GPU. Для крупномасштабных конвейеров NLP Spark кластеры с ускорением GPU в Azure Databricks или Fabric предоставляют возможности параллельной обработки, необходимые для обучения и вывода. Оптимизации, такие как квантизация модели Llama 3.x, помогают сократить объем памяти и повысить пропускную способность для этих интенсивных задач.
для языка Azure требуется планирование пропускной способности и управление квотами. Служба обрабатывает управление ресурсами, но вызовы API высокого объема требуют тщательного планирования пропускной способности. Отслеживайте частоту ваших запросов относительно лимитов сервисов и скоростных ограничений, чтобы избежать ограничения пропускной способности и гарантировать стабильную производительность обработки.
Стандартизация документов
Реальные документы редко следуют согласованной структуре. Эта несогласованность создает проблемы для потоков извлечения и требует целевых стратегий для поддержания точности в разных источниках.
Несогласованные форматы: Без стандартного формата документа извлечение конкретных фактов из текста свободной формы может оказаться трудным. Например, это может быть сложной задачей для извлечения номеров счетов и дат от разных поставщиков, так как макеты полей, метки и форматирование различаются в разных источниках.
Пользовательское обучение моделей: При обучении пользовательских моделей в Spark NLP и Azure Language, можно адаптироваться к форматам документов, специфичным для домена. При тренировке на репрезентативных образцах ваших реальных документов можно повысить точность извлечения полей, сущностей и шаблонов, которые построенные модели не обрабатывают эффективно.
Разнообразие и сложность данных
Разнообразные структуры документов и лингвистические нюансы добавляют сложность. Реальные текстовые данные доступны во многих форматах, стилях написания и языках. Для решения этих вариантов требуются модели, которые могут обрабатывать неоднозначность, сленг, аббревиацию и терминологию конкретного домена при сохранении точности.
Внедрение MPNet в Spark NLP обеспечивает расширенное контекстное понимание. Внедрение MPNet фиксирует контекстные связи между словами и фразами, что помогает конвейерам Spark NLP более эффективно обрабатывать нюансы текста. Эти внедрения создают плотные векторные представления, которые сохраняют семантические значения в разных форматах документов.
Пользовательские модели в языке Azure адаптируются к шаблонам текста для конкретного домена. С помощью CNER можно обучать модели на собственных помеченных данных, чтобы распознать шаблоны, относящиеся к вашему домену. Этот подход повышает надежность, обучая модели распознавать сущности и категории, которые предварительно созданные модели пропускают.
Применение ключевых критериев отбора
Используйте следующие критерии, чтобы определить, какой вариант обработки естественного языка Azure лучше всего соответствует вашим требованиям. Каждый критерий описывает характеристику рабочей нагрузки и определяет службу, которая её обслуживает.
Управляемые возможности обработки естественного языка: Используйте Azure Language API для распознавания сущностей, идентификации намерений, обнаружения темы или анализа тональности. Эти возможности доступны как управляемые службы с минимальной настройкой, и вам не нужно подготавливать или управлять инфраструктурой.
Престроенные или предварительно обученные модели: Использовать язык Azure, если планируется использовать предварительно созданные или предварительно обученные модели без управления инфраструктурой. Этот подход подходит для небольших и средних наборов данных и стандартных задач обработки естественного языка, где предварительно созданные модели обеспечивают достаточную точность. Она обеспечивает автоматическое масштабирование, встроенную безопасность и цены на звонки без затрат на управление кластерами.
Обучение пользовательских моделей на больших текстовых наборах данных: используйте Azure Databricks или Fabric с Spark NLP. Эти платформы обеспечивают вычислительную мощность и гибкость, необходимые для расширенного обучения модели на больших текстовых наборах данных. Вы также можете скачать модели с помощью NLP Spark, включая Llama 3.x и MPNet.
Примитивы низкоуровневой обработки естественного языка: Использовать Azure Databricks или Fabric с Spark NLP для токенизации, стемминга, лемматизации и TF-IDF. Кроме того, используйте библиотеку с открытым кодом, например spaCy или NLTK. Azure Language в Foundry Tools использует токенизацию внутри своего модельного конвейера, но не предоставляет эти шаги как автономные управляемые API.
Создание конвейеров обработки естественного языка с помощью Spark NLP
Spark NLP следует той же схеме разработки, что и традиционные модели машинного обучения Spark при запуске конвейера обработки естественного языка. Вы управляете обученными моделями с помощью MLflow для отслеживания экспериментов и развертывания в рабочей среде.

Сборка основных компонентов конвейера
Конвейер Spark NLP связывает аннотаторов поочередно. Каждый аннотатор преобразует выходные данные предыдущего этапа и преобразует необработанный текст в семантические векторы.
DocumentAssembler — это точка входа для каждого конвейера NLP Spark. Используйте
setCleanupModeдля применения необязательных предварительных обработки текста, таких как удаление тегов HTML или нормализация пробелов перед запуском подчиненных аннотаторов.SentenceDetector определяет границы предложений в собранном документе. Он возвращает обнаруженные предложения либо в виде
Arrayв одной строке, либо в виде отдельных строк, в зависимости от конфигурации конвейера. Точное обнаружение предложений важно, так как многие подчиненные аннотаторы работают на уровне предложения.Токенизатор делит необработанный текст на дискретные маркеры, такие как слова, числа и символы. Если для домена недостаточно правил по умолчанию, добавьте настраиваемые правила для обработки специализированного словаря, дефисированных терминов или шаблонов, относящихся к домену.
Нормализатор обрабатывает токены, применяя регулярные выражения и преобразования словаря. Он очищает текст для снижения шума перед внедрением. Например, можно удалить акценты, преобразовать в строчные буквы или применить пользовательские словарные сопоставления для стандартизации терминологии.
WordEmbeddings сопоставляет токены с семантическими векторами для контекстной обработки. Каждый маркер представлен в виде плотного вектора, который фиксирует его значение относительно других маркеров. Неразрешенные маркеры, которые не отображаются в словаре встраиваний, по умолчанию равны нулевым векторам.
Управление моделями с помощью MLflow
Spark NLP использует конвейеры Spark MLlib с родной поддержкой MLflow. Вам не нужно писать пользовательский код сериализации или интеграции.
MLflow управляет отслеживанием экспериментов, управлением версиями моделей и развертыванием. Во время учебных запусков можно записывать параметры конвейера, метрики и артефакты. MLflow отслеживает каждый эксперимент, чтобы сравнить результаты между итерациями и воспроизвести успешные конфигурации.
MLflow интегрируется непосредственно с Azure Databricks и Fabric. В Azure Databricks MLflow предварительно установлен и тесно интегрируется с рабочей областью. Fabric также предоставляет встроенную возможность использования MLflow с нативным отслеживанием экспериментов и автологированием, поэтому нет необходимости устанавливать MLflow отдельно. Если вы запускаете NLP Spark в другой среде на основе Apache Spark, вы можете установить MLflow отдельно и настроить его для отслеживания экспериментов на удаленном сервере отслеживания.
Используйте реестр моделей MLflow для повышения уровня моделей в рабочей среде и поддержании управления. Реестр моделей предоставляет центральный репозиторий для управления версиями моделей в конвейерах обработки естественного языка. В классических развертываниях модели переходят через этапы, такие как подготовку, эксплуатацию и архивирование. В Azure Databricks новые развертывания используют Models в каталоге Unity, что заменяет фиксированные этапы настраиваемыми псевдонимами и тегами для более гибкого управления жизненным циклом. На Fabric рабочая область предоставляет собственный реестр моделей на основе MLflow.
Матрица возможностей
В следующих таблицах приведены основные различия в возможностях между NLP Spark на Azure Databricks или Fabric и языке Azure.
Общие возможности
| Способность | NLP Spark (Azure Databricks или Fabric) | язык Azure |
|---|---|---|
| Предварительно обученные модели как услуга | Да | Да |
| REST API | Да | Да |
| Программируемость | Python, Scala | См. раздел "Поддерживаемые языки программирования". |
| Поддерживает обработку больших наборов данных и больших документов | Да | Ограничено 1 |
1.Azure Язык имеет ограничения размера документа на запрос, которые зависят от режима. Синхронные запросы поддерживают до 5120 символов на документ, а асинхронные запросы поддерживают до 125 000 символов на документ. Оба режима поддерживают до 25 документов на вызов API. Вы можете обрабатывать большие тома набора данных с помощью пакетной обработки и разбиения на страницы, но для отдельных документов, превышающих ограничение символов для выбранного режима, требуется фрагментирование. Дополнительные сведения см. в разделе Data и ограничения скорости для языка Azure.
Возможности аннотатора
| Способность | NLP Spark (Azure Databricks или Fabric) | язык Azure |
|---|---|---|
| Детектор предложений | Да | Нет |
| Детектор глубоких предложений | Да | Нет |
| Токенизатор | Да | Только внутренний (не представлен в виде самостоятельного API) |
| Генератор N-грамм | Да | Нет |
| сегментация слов | Да | Да |
| Стеммер | Да | Нет |
| Лемматизатор | Да | Нет |
| Тегирование частей речи | Да | Нет |
| Средство синтаксического анализа зависимостей | Да | Нет |
| Перевод | Да | Нет |
| Средство очистки стоп-слов | Да | Нет |
| Исправление орфографии | Да | Нет |
| Нормализатор | Да | Да |
| Сопоставление текста | Да | Нет |
| TF-IDF | Да | Нет |
| Сопоставление регулярных выражений | Да | Ограничено |
| Сопоставление дат | Да | Ограничено |
| Блокировщик | Да | Нет |
Высокоуровневые возможности обработки естественного языка
| Способность | NLP Spark (Azure Databricks или Fabric) | язык Azure |
|---|---|---|
| Проверка орфографии | Да | Нет |
| Резюмирование | Да | Да |
| Ответы на вопросы | Да | Да |
| Определение тональности | Да | Да |
| Определение эмоций | Да | Ограниченная версия 2 |
| Классификация токенов | Да | Ограниченное число 3 |
| Классификация текста | Да | Ограниченное число 3 |
| Текстовое представление | Да | Нет |
| НЭР | Да | Да (предварительно встроенное). CNER доступен с помощью пользовательских моделей. 3 |
| Обнаружение языка | Да | Да |
| Поддерживает языки, отличные от английского | Да. Ознакомьтесь с поддерживаемыми языками Spark NLP. | Да. См. раздел поддерживаемые Azure языки. |
2.Служба Azure Language поддерживает анализ мнений, который определяет настроения, связанные с конкретными аспектами текста, но не предоставляет специфическое определение эмоций (таких как классификация радости, гнева или печали).
3.Доступнос помощью пользовательских моделей. Вы обучаете модели распознавания именованных сущностей (CNER) или модели пользовательских сущностей на собственных помеченных данных.
Соавторы
Microsoft поддерживает эту статью. Следующие авторы написали эту статью.
Основные авторы:
- Ананя Хош Чоддхури | Главный архитектор облачных решений
- Kranthi Manchikanti | Старший инженер по решениям искусственного интеллекта
Другие участники:
- Фредди Айала | Архитектор облачных решений
- Tincy Elias | Старший архитектор облачных решений
- Мориц Стеллер | Старший архитектор облачных решений
Чтобы просмотреть закрытые профили LinkedIn, войдите в LinkedIn.
Дальнейшие действия
- Введение в ИИ на Azure
- Разработка решений для обработки естественного языка с помощью средств Foundry
Связанные ресурсы
документация по языку Azure:
- Обзор языка Azure
- Документация по Foundry
Документация по Spark NLP:
компоненты Azure:
Учебные материалы: