Примечание.
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
В этой статье вы узнаете, как настроить профессиональный голос на портале Microsoft Foundry.
Важно
Профессиональная настройка голосовой связи в настоящее время доступна только в некоторых регионах. После того как ваша голосовая модель обучена в поддерживаемом регионе, вы можете скопировать профессиональную голосовую модель в ресурс Microsoft Foundry в другом регионе по мере необходимости. Дополнительные сведения см. в сносках в таблице службы "Речь".
Длительность обучения зависит от того, сколько данных вы используете. Это занимает около 10 часов вычислений в среднем, чтобы точно настроить профессиональный голос. С помощью ресурса Microsoft Foundry standard (S0) можно одновременно обучить четыре голоса. Если вы достигнете предела, подождите, пока не менее одна из ваших голосовых моделей завершит обучение, а затем повторите попытку.
Примечание
Хотя общее количество часов, необходимых для каждого метода обучения, может различаться, одинаковая цена за единицу применяется ко всем. Дополнительные сведения см. в разделе о ценах на настраиваемую нейронную подготовку.
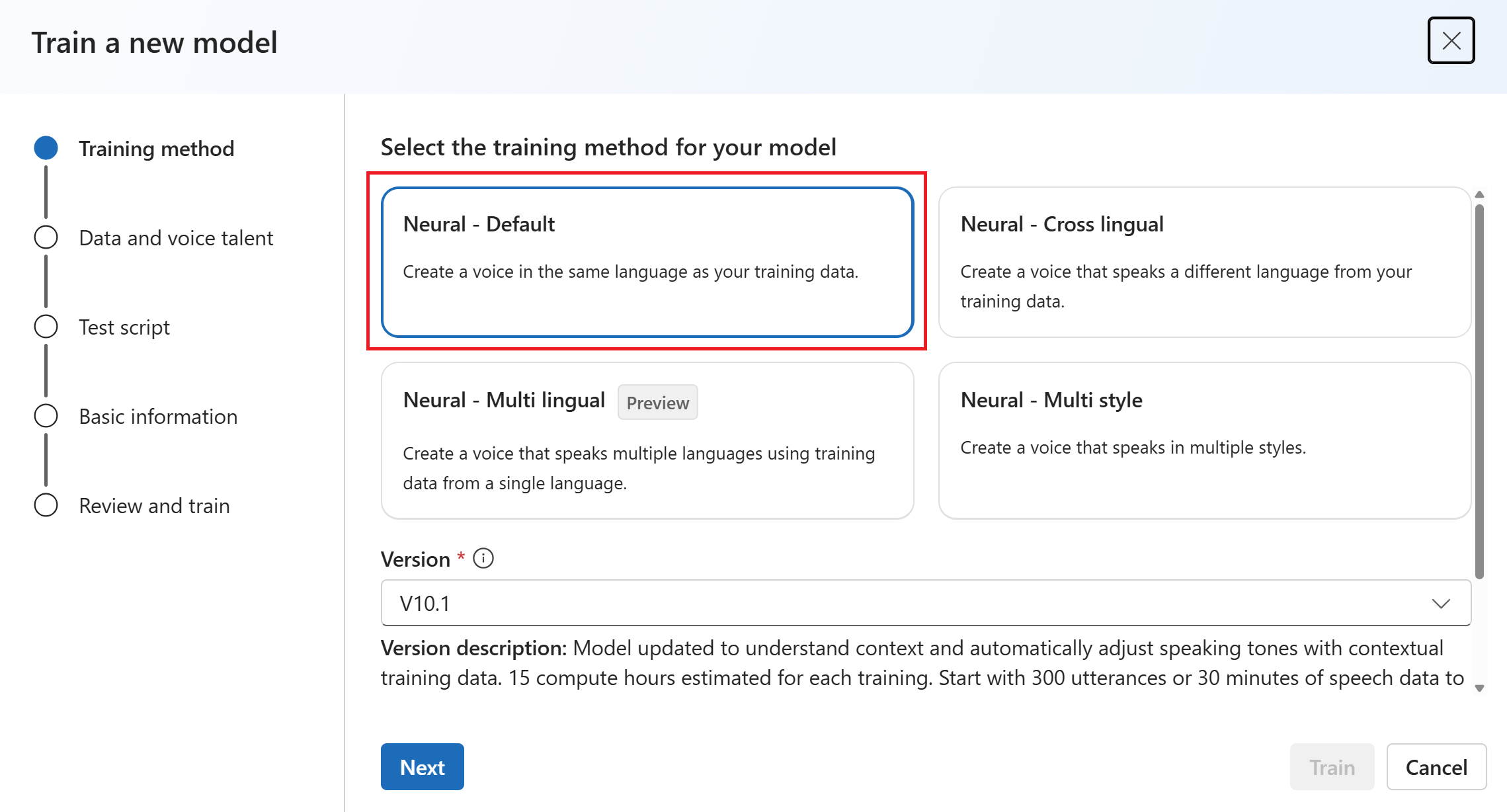
Выбор метода обучения
После проверки файлов данных используйте их для создания пользовательской голосовой модели. При создании пользовательского голоса вы можете обучить его одним из следующих методов:
Нейронный: создавайте голос на том же языке, что и язык ваших данных обучения.
Нейронный — HD голос: создайте HD голос на языке ваших обучающих данных. Голоса Azure Neural HD на базе LLM оптимизированы для динамических диалогов. Дополнительные сведения об нейронных голосах HD см. здесь.
Нейронная — многоязычная: создайте голос, который может говорить на нескольких языках, используя данные обучения для одного языка. Например, с
en-USосновными учебными данными можно создать голос, который говоритen-US,de-DEzh-CNи т. д. вторичные языки.Основной язык обучающих данных и вторичных языков должен находиться на языках, которые поддерживаются для обучения многоязычной голосовой связи. Вам не нужно подготавливать обучающие данные на дополнительных языках.
Нейронная — много стилей: создайте пользовательский голос, который выступает в нескольких стилях и эмоциях, не добавляя новые обучающие данные. Несколько стилей голоса полезны для игровых персонажей, беседных чат-ботов, аудиокниг, средств чтения содержимого и многое другое.
Чтобы создать несколько стилей голоса, необходимо подготовить набор общих обучающих данных, по крайней мере 300 речевых фрагментов. Выберите один или несколько предустановленных стилей речи целевого объекта. Вы также можете создать несколько пользовательских стилей, предоставив примеры стилей, по крайней мере 100 речевых фрагментов на стиль, в качестве дополнительных обучающих данных для одного голоса. Поддерживаемые стили предустановок зависят от разных языков. Просмотрите доступные стили предустановок на разных языках.
Нейронный — кросслингвальный: создайте голос, который говорит на другом языке, отличном от обучающих данных. Например, используя
zh-CNобучающие данные, можно создать голос, который произноситen-US.Язык обучающих данных и целевого языка должен быть одним из языков, которые поддерживаются для перекрестного обучения голосовой связи. Вам не нужно подготавливать обучающие данные на целевом языке, но тестовый скрипт должен находиться на целевом языке.
Язык обучающих данных должен быть одним из языков, поддерживаемых для пользовательского голосового, кросслингвального или нескольких стилей обучения.
Обучение пользовательской голосовой модели
Чтобы создать пользовательский голос на портале Foundry Microsoft, выполните следующие действия для одного из следующих методов:
- Нейронный
- Нейронная — голосовая связь HD
- Нейронная — многоязычная
- Нейронная — многостильная
- Нейронная — межъязыковая
Войдите на портал Microsoft Foundry.
Выберите Тонкая настройка в левой области и выберите Тонкая настройка службы ИИ.
Выберите задачу профессиональной настройки голосовой связи (по имени модели), которую вы начали, как описано в статье о создании профессиональной голосовой связи.
Выберите "Обучение модели>+ Обучение модели".
Выберите Neural в качестве метода обучения для модели. Сведения об использовании другого метода обучения см. в разделе Нейронная — кросслингвальная, Нейронная — многостильная, Нейронная — многоязычная или Нейронная — голосовая связь HD.
Выберите версию рецепта обучения для модели. По умолчанию выбрана последняя версия. Поддерживаемые функции и время обучения могут отличаться по версии. Как правило, мы рекомендуем последнюю версию. В некоторых случаях можно выбрать более раннюю версию, чтобы сократить время обучения. Дополнительные сведения о двуязычной подготовке и различиях между языковыми стандартами см. в Bilingual training.
Нажмите кнопку "Далее".
Выберите данные, которые вы хотите использовать для обучения. Дублирующиеся звуковые имена удаляются из обучения. Убедитесь, что данные, которые вы выбрали, не содержат одинаковые имена звука в нескольких .zip файлах.
Вы можете выбрать только успешно обработанные наборы данных для обучения. Если в списке не отображается набор обучения, проверьте состояние обработки данных.
Выберите файл диктора с заявлением о голосовом таланте, соответствующий диктору в ваших тренировочных данных.
Нажмите кнопку "Далее".
Выберите тестовый скрипт и нажмите кнопку "Далее".
- Каждое обучение создает 100 примеров звуковых файлов автоматически, чтобы протестировать модель с помощью скрипта по умолчанию.
- Кроме того, можно выбрать " Добавить собственный скрипт теста " и предоставить собственный скрипт тестирования до 100 речевых фрагментов, чтобы протестировать модель без дополнительных затрат. Созданные звуковые файлы — это сочетание скриптов автоматического тестирования и пользовательских скриптов тестирования. Дополнительные сведения см. в статье о требованиях к скрипту тестирования.
Введите имя модели голосовой связи. Тщательно выберите имя. Имя модели используется в качестве голосового имени в запросе синтеза речи с помощью SDK и входных данных SSML. Допускаются только буквы, цифры и несколько знаков препинания. Используйте разные имена для различных моделей нейронных голосовых данных.
При необходимости введите описание , чтобы определить модель. Обычное использование описания заключается в записи имен данных, используемых для создания модели.
Установите флажок, чтобы принять условия использования, а затем нажмите кнопку "Далее".
Просмотрите параметры и выберите поле для принятия условий использования.
Выберите "Обучение ", чтобы начать обучение модели.

Двуязычное обучение
Если выбрать тип обучения нейронный, вы можете обучить голос говорить на нескольких языках.
zh-CN, zh-HK, и zh-TW поддерживают двуязычное обучение системы, чтобы распознавать речь как на китайском, так и на английском языках. В зависимости от ваших обучающих данных синтезированный голос может говорить на английском языке с английским собственным акцентом или английским с тем же акцентом, что и данные обучения.
Примечание
Чтобы включить голос в zh-CN языковом стандарте для разговора на английском языке с тем же акцентом, что и в образце данных, следует загрузить данные на английском языке в контекстный набор обучения или выбрать Chinese (Mandarin, Simplified), English bilingual при создании проекта, либо указать zh-CN (English bilingual) языковой стандарт для данных набора обучения через REST API.
Включите в контекстный набор обучения по крайней мере 100 предложений или 10 минут английского контента, и не превышайте объема китайского контента.
В следующей таблице показаны различия локалей системы:
| Локализация для Speech Studio | Локаль REST API | Двуязычная поддержка |
|---|---|---|
Chinese (Mandarin, Simplified) |
zh-CN |
Если образец данных содержит английский, синтезированный голос говорит по-английски с родным английским акцентом, вместо акцента образца данных, независимо от объема данных на английском языке. |
Chinese (Mandarin, Simplified), English bilingual |
zh-CN (English bilingual) |
Если вы хотите, чтобы синтезированный голос говорил на английском языке с тем же акцентом, что и примеры данных, рекомендуется включить более 10% английских данных в наборе обучения. В противном случае акцент на английском языке может быть не идеальным. |
Chinese (Cantonese, Simplified) |
zh-HK |
Если вы хотите обучить синтезированный голос, способный говорить на английском языке с тем же акцентом, что и образец данных, обязательно предоставьте более 10% английских данных в учебном наборе. В противном случае, по умолчанию переключается на английский родной акцент. Пороговое значение 10% вычисляется на основе данных, принятых после успешной отправки, а не данных перед отправкой. Если некоторые загруженные данные на английском языке отклоняются из-за дефектов и не соответствуют порогу в 10%, синтезированный голос по умолчанию переключается на акцент носителя английского. |
Chinese (Taiwanese Mandarin, Traditional) |
zh-TW |
Если вы хотите обучить синтезированный голос, способный говорить на английском языке с тем же акцентом, что и образец данных, обязательно предоставьте более 10% английских данных в учебном наборе. В противном случае, по умолчанию переключается на английский родной акцент. Пороговое значение 10% вычисляется на основе данных, принятых после успешной отправки, а не данных перед отправкой. Если некоторые загруженные данные на английском языке отклоняются из-за дефектов и не соответствуют порогу в 10%, синтезированный голос по умолчанию переключается на акцент носителя английского. |




Мониторинг процесса обучения
В таблице Обучение модели отображается новая запись, соответствующая созданной модели. Состояние отражает процесс преобразования данных в голосовую модель, как описано в этой таблице:
| Государства | Смысл |
|---|---|
| Обработка | Ваша голосовая модель создается. |
| Удалось | Ваша голосовая модель создана и может быть развернута. |
| Ошибка | Ваша голосовая модель претерпела неудачу в обучении. Причиной сбоя может быть, например, невидимые проблемы с данными или сетевые проблемы. |
| Отменен | Обучение вашей голосовой модели было отменено. |
Пока состояние модели — обработка, можно выбрать модель, а затем выбрать команду "Отмена обучения ", чтобы отменить обучение. Плата за это отмененное обучение не взимается.

После успешного обучения модели можно просмотреть сведения о модели и протестировать голосовую модель.
Переименование модели
Чтобы переименовать модель, необходимо клонировать ее. Невозможно переименовать модель напрямую.
- Выберите модель.
- Выберите модель клонирования , чтобы создать клон модели с новым именем в текущем проекте.
- Введите новое имя в окне Клонировать голосовую модель.
- Нажмите кнопку "Отправить". Текст нейронный автоматически добавляется как суффикс к названию новой модели.
Тестирование голосовой модели
После успешной сборки модели голосовой связи можно использовать созданные примеры звуковых файлов для его тестирования перед развертыванием.
Примечание
Нейронная — многоязычная и нейронная — голосовая связь HD не поддерживает этот тип тестирования.
Качество голоса зависит от многих факторов, таких как:
- Размер обучающих данных.
- Качество записи.
- Точность файла расшифровки.
- Насколько хорошо записанный голос в обучающих данных соответствует личности разработанного голоса для вашего предполагаемого варианта использования.
Выберите DefaultTests в разделе "Тестирование ", чтобы прослушивать образец звуковых файлов. Примеры тестов по умолчанию включают 100 примеров звуковых файлов, созданных автоматически во время обучения, чтобы помочь вам протестировать модель. Помимо этих 100 звуковых файлов, предоставляемых по умолчанию, собственные речевые фрагменты скрипта тестирования также добавляются в набор DefaultTests . Это дополнение составляет не более 100 высказываний. Плата за тестирование с помощью DefaultTests не взимается.
Если вы хотите отправить собственные тестовые скрипты для дальнейшего тестирования модели, выберите "Добавить тестовые скрипты " для отправки собственного тестового скрипта.
Перед отправкой тестового скрипта проверьте требования к скрипту тестирования. Плата за дополнительное тестирование с помощью пакетного синтеза взимается на основе количества оплачиваемых символов. См. Azure Speech в инструментах Foundry для получения информации о ценах.
В разделе "Добавить тестовые скрипты" выберите "Обзор файла ", чтобы выбрать собственный скрипт, а затем нажмите кнопку "Добавить ", чтобы отправить его.
Требования к тестовом скрипту
Тестовый скрипт должен быть файлом.txt размером менее 1 МБ. Поддерживаемые форматы кодирования включают ANSI/ASCII, UTF-8, UTF-8-BOM, UTF-16-LE или UTF-16-BE.
В отличие от файлов обучающего транскрибирования, скрипт теста должен исключить идентификатор высказываний, который является именем файла каждого высказывания. Иначе эти идентификаторы озвучиваются.
Ниже приведен пример набора речевых фрагментов в одном .txt файле:
This is the waistline, and it's falling.
We have trouble scoring.
It was Janet Maslin.
Каждый абзац речевого высказывания приводит к отдельному аудиофайлу. Если вы хотите объединить все предложения в один звук, сделайте их одним абзацем.
Примечание
Созданные звуковые файлы — это сочетание скриптов автоматического тестирования и пользовательских скриптов тестирования.
Обновите версию движка для вашей голосовой модели
Azure системы преобразования текста в речь обновляются время от времени, чтобы включить последнюю языковую модель, которая определяет произношение языка. После того как вы обучите голос, вы можете его применить к новой языковой модели, обновившись до последней версии модуля.
- Когда доступен новый модуль, вам будет предложено обновить нейронную голосовую модель.
- Перейдите на страницу сведений о модели и следуйте инструкциям на экране, чтобы установить последнюю версию подсистемы.
- В качестве альтернативы выберите Установить последнюю версию движка, чтобы обновить модель до последней версии ядра. За обновление движка плата не взимается. Предыдущие версии по-прежнему хранятся.
- Вы можете проверить все версии подсистемы для модели из списка версий подсистемы или удалить ее, если она больше не нужна.
Обновленная версия автоматически устанавливается в качестве значения по умолчанию. Но вы можете изменить версию по умолчанию, выбрав версию из раскрывающегося списка и выбрав "Задать в качестве значения по умолчанию".
Если вы хотите протестировать каждую версию подсистемы голосовой модели, можно выбрать версию из списка, а затем выберите DefaultTests в разделе "Тестирование ", чтобы прослушивать образец звуковых файлов. Если вы хотите отправить собственные тестовые скрипты для дальнейшего тестирования текущей версии подсистемы, сначала убедитесь, что версия задана по умолчанию, а затем выполните действия, описанные в разделе "Тестирование голосовой модели".
Обновление подсистемы создает новую версию модели без дополнительных затрат. После обновления версии движка для вашей голосовой модели необходимо развернуть новую версию, чтобы создать новую конечную точку. Вы можете развернуть только версию по умолчанию.
После создания новой конечной точки необходимо передать трафик в новую конечную точку в продукте.
Дополнительные сведения о возможностях и ограничениях этой функции и рекомендациях по улучшению качества модели см. в разделе "Характеристики и ограничения" для использования пользовательского голоса.
Копирование голосовой модели в другой проект
Примечание
В этом контексте "проект" относится к задаче тонкой настройки, а не к проекту Microsoft Foundry.
После обучения вы можете скопировать голосовую модель в другой проект для одного региона или другого региона.
Например, можно скопировать профессиональную голосовую модель, которая была обучена в одном регионе, в проект для другого региона. Профессиональная настройка голосовой связи в настоящее время доступна только в некоторых регионах.
Чтобы скопировать пользовательскую голосовую модель в другой проект:
- На вкладке «Обучение модели» выберите голосовую модель, которую требуется скопировать, а затем выберите «Копировать в проект».
- Выберите подписку, целевой регион, ресурс подключенной службы ИИ (ресурс Foundry) и целевую задачу тонкой настройки, в которой требуется скопировать модель.
- Выберите Копировать в, чтобы скопировать модель.
- Выберите модель представления в сообщении уведомления об успешном копировании.
Перейдите к проекту, в котором вы скопировали модель для развертывания копии модели.
Дальнейшие действия
Из этой статьи вы узнаете, как настроить профессиональный голос на портале Speech Studio.
Важно
Профессиональная настройка голосовой связи в настоящее время доступна только в некоторых регионах. После обучения голосовой модели в поддерживаемом регионе его можно скопировать в ресурс Foundry для распознавания речи в другом регионе по мере необходимости. Дополнительные сведения см. в сносках в таблице службы "Речь".
Длительность обучения зависит от того, сколько данных вы используете. Это занимает около 10 часов вычислений в среднем, чтобы точно настроить профессиональный голос. Пользователи стандартной подписки (S0) могут одновременно обучать четыре голоса. Если вы достигнете предела, подождите, пока не менее одна из ваших голосовых моделей завершит обучение, а затем повторите попытку.
Примечание
Хотя общее количество часов, необходимых для каждого метода обучения, может различаться, одинаковая цена за единицу применяется ко всем. Дополнительные сведения см. в разделе о ценах на настраиваемую нейронную подготовку.
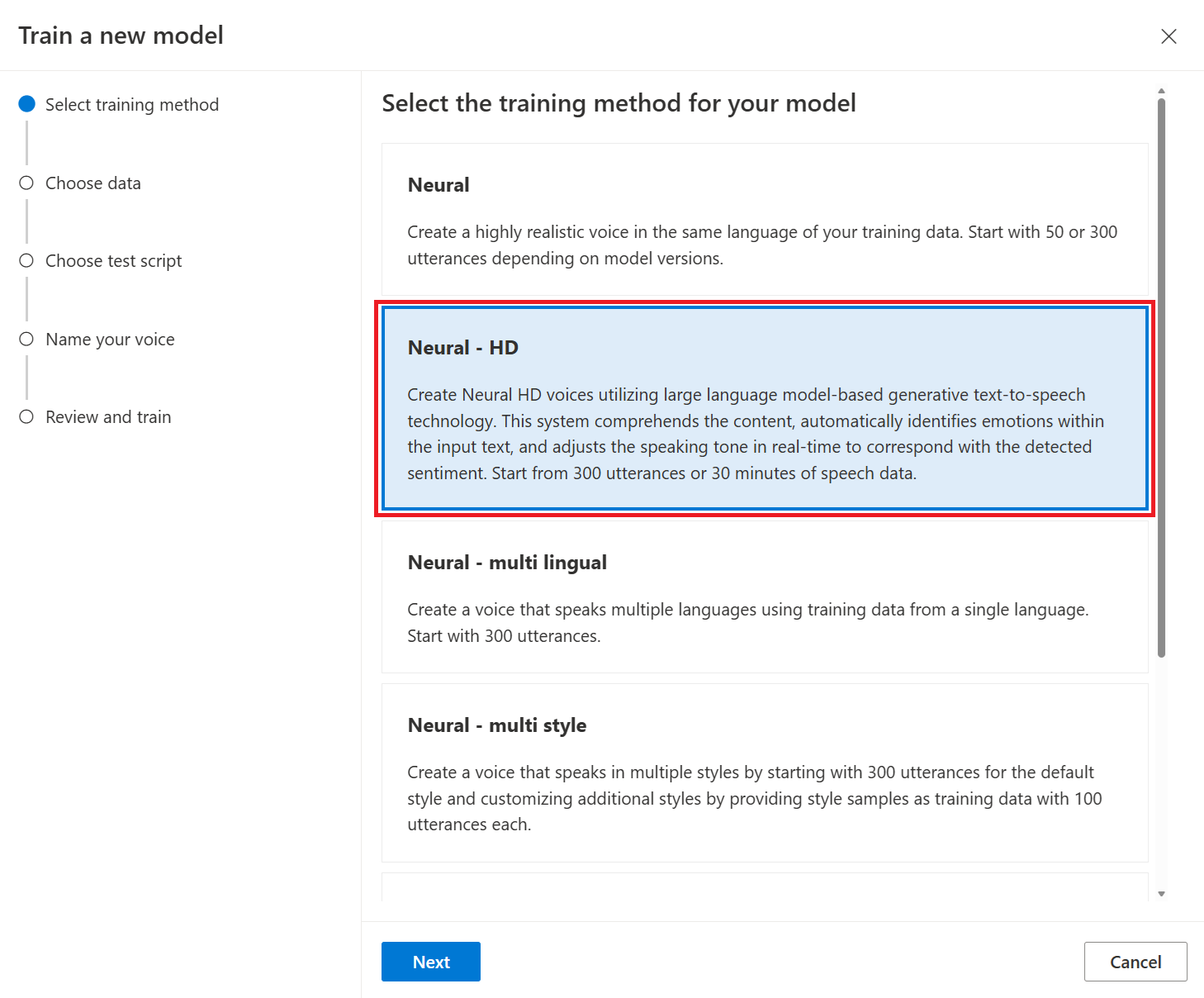
Выбор метода обучения
После проверки файлов данных используйте их для создания пользовательской голосовой модели. При создании пользовательского голоса вы можете обучить его одним из следующих методов:
Нейронный: создайте голос на том же языке, что и язык данных обучения.
Нейронный — HD голос: создайте HD голос на том же языке, что и ваши обучающие данные. Голоса Azure Neural HD на базе LLM оптимизированы для динамических диалогов. Дополнительные сведения об нейронных голосах HD см. здесь.
Нейронная — многоязычная: создайте голос, который может говорить на нескольких языках, используя данные обучения для одного языка. Например, с
en-USосновными учебными данными можно создать голос, который говоритen-US,de-DEzh-CNи т. д. вторичные языки.Основной язык обучающих данных и вторичных языков должен находиться на языках, которые поддерживаются для обучения многоязычной голосовой связи. Вам не нужно подготавливать обучающие данные на дополнительных языках.
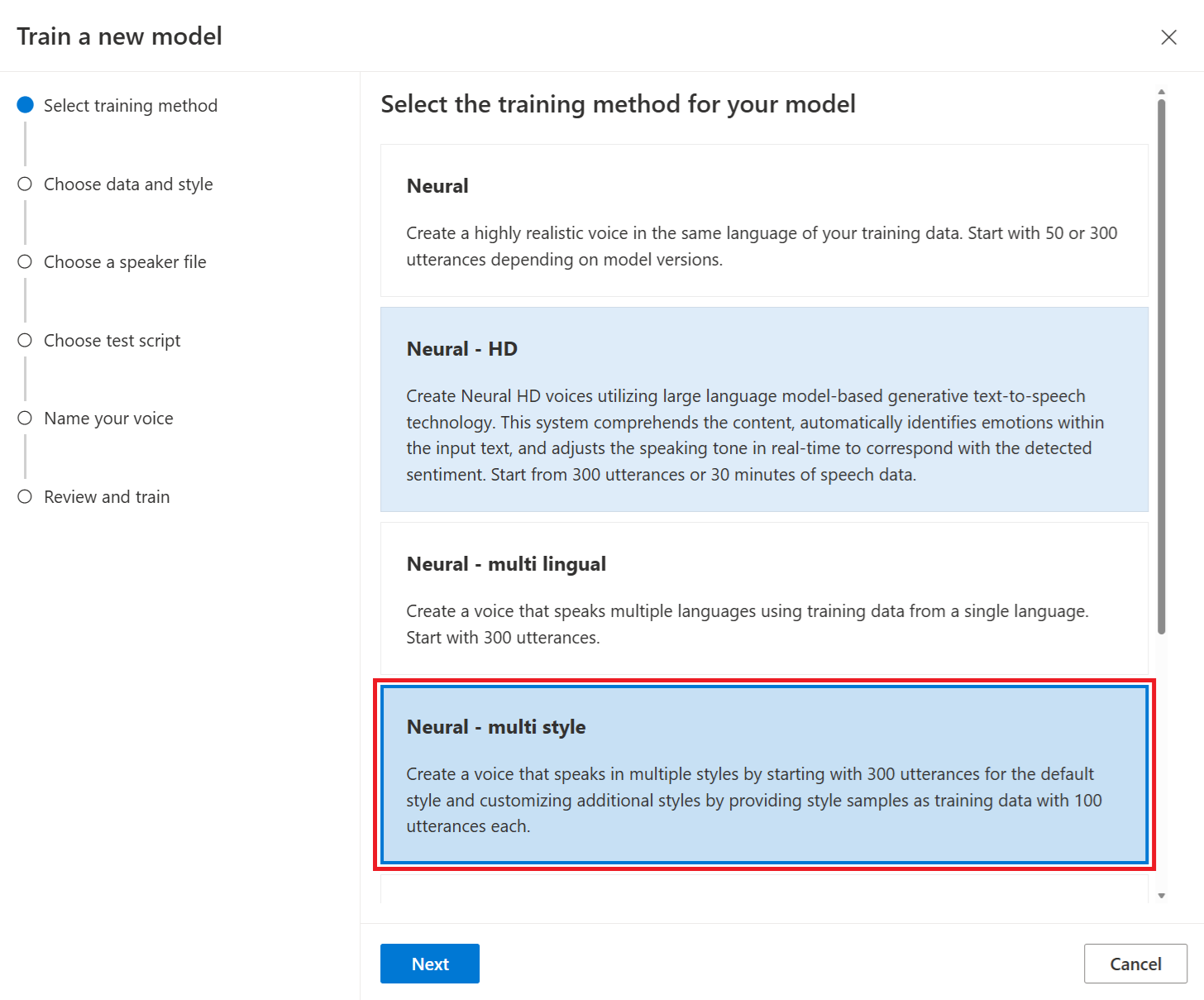
Нейронная — много стилей: создайте пользовательский голос, который выступает в нескольких стилях и эмоциях, не добавляя новые обучающие данные. Несколько стилей голоса полезны для игровых персонажей, беседных чат-ботов, аудиокниг, средств чтения содержимого и многое другое.
Чтобы создать несколько стилей голоса, необходимо подготовить набор общих обучающих данных, по крайней мере 300 речевых фрагментов. Выберите один или несколько предустановленных стилей речи целевого объекта. Вы также можете создать несколько пользовательских стилей, предоставив примеры стилей, по крайней мере 100 речевых фрагментов на стиль, в качестве дополнительных обучающих данных для одного голоса. Поддерживаемые стили предустановок зависят от разных языков. Просмотрите доступные стили предустановок на разных языках.
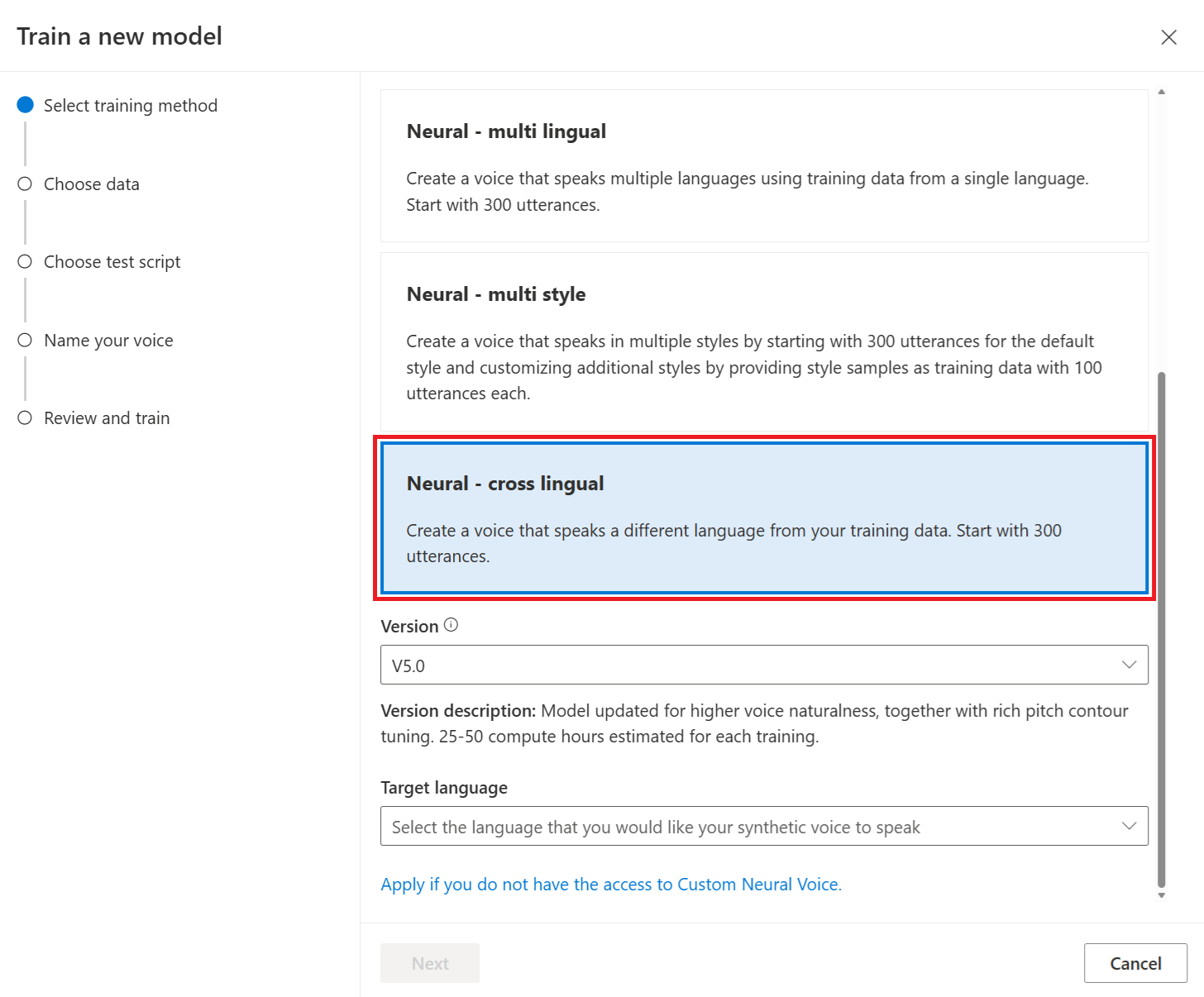
Нейронный — кросслингвальный: создайте голос, который говорит на другом языке, отличном от обучающих данных. Например, используя
zh-CNобучающие данные, можно создать голос, который произноситen-US.Язык обучающих данных и целевого языка должен быть одним из языков, которые поддерживаются для перекрестного обучения голосовой связи. Вам не нужно подготавливать обучающие данные на целевом языке, но тестовый скрипт должен находиться на целевом языке.
Язык обучающих данных должен быть одним из языков, поддерживаемых для пользовательского голосового, кросслингвального или нескольких стилей обучения.
Обучение пользовательской голосовой модели
Чтобы создать пользовательский голос в Speech Studio, выполните следующие действия для одного из следующих методов:
- Нейронный
- Нейронная — голосовая связь HD
- Нейронная — многоязычная
- Нейронная — многостильная
- Нейронная — межъязыковая
Войдите в Speech Studio.
Выберите Настраиваемый голос><Имя вашего проекта>>Обучите модель>Обучите новую модель.
Выберите "Нейрон" в качестве метода обучения для модели и нажмите кнопку "Далее". Сведения об использовании другого метода обучения см. в разделе Нейронная - межъязыковая или Нейронная - мультимодальная или Нейронная - многоязыковая или Нейронная - HD голос.

Выберите версию рецепта обучения для модели. По умолчанию выбрана последняя версия. Поддерживаемые функции и время обучения могут отличаться по версии. Как правило, мы рекомендуем последнюю версию. В некоторых случаях можно выбрать более раннюю версию, чтобы сократить время обучения. Дополнительные сведения о двуязычной подготовке и различиях между языковыми стандартами см. в Bilingual training.
Примечание
Версии модели
V3.0,V7.0иV8.0были сняты с производства 25 июля 2025 года. Модели голосовой связи, уже созданные в этих устаревших версиях, не затрагиваются.Выберите данные, которые вы хотите использовать для обучения. Дублирующиеся звуковые имена удаляются из обучения. Убедитесь, что данные, которые вы выбрали, не содержат одинаковые имена звука в нескольких .zip файлах.
Вы можете выбрать только успешно обработанные наборы данных для обучения. Если в списке не отображается набор обучения, проверьте состояние обработки данных.
Выберите файл диктора с заявлением о голосовом таланте, соответствующий диктору в ваших тренировочных данных.
Нажмите кнопку "Далее".
Каждое обучение создает 100 примеров звуковых файлов автоматически, чтобы протестировать модель с помощью скрипта по умолчанию.
При необходимости можно также выбрать " Добавить собственный скрипт теста " и предоставить собственный скрипт теста до 100 речевых фрагментов, чтобы протестировать модель без дополнительных затрат. Созданные звуковые файлы — это сочетание скриптов автоматического тестирования и пользовательских скриптов тестирования. Дополнительные сведения см. в статье о требованиях к скрипту тестирования.
Введите имя , чтобы определить модель. Тщательно выберите имя. Имя модели используется в качестве голосового имени в запросе синтеза речи с помощью SDK и входных данных SSML. Допускаются только буквы, цифры и несколько знаков препинания. Используйте разные имена для различных моделей нейронных голосовых данных.
При необходимости введите описание , чтобы определить модель. Обычное использование описания заключается в записи имен данных, используемых для создания модели.
Нажмите кнопку "Далее".
Просмотрите параметры и выберите поле для принятия условий использования.
Нажмите кнопку "Отправить ", чтобы начать обучение модели.
Двуязычное обучение
Если выбрать тип обучения нейронный, вы можете обучить голос говорить на нескольких языках.
zh-CN, zh-HK, и zh-TW поддерживают двуязычное обучение системы, чтобы распознавать речь как на китайском, так и на английском языках. В зависимости от ваших обучающих данных синтезированный голос может говорить на английском языке с английским собственным акцентом или английским с тем же акцентом, что и данные обучения.
Примечание
Чтобы включить голос в zh-CN языковом стандарте для разговора на английском языке с тем же акцентом, что и в образце данных, следует загрузить данные на английском языке в контекстный набор обучения или выбрать Chinese (Mandarin, Simplified), English bilingual при создании проекта, либо указать zh-CN (English bilingual) языковой стандарт для данных набора обучения через REST API.
Включите в контекстный набор обучения по крайней мере 100 предложений или 10 минут английского контента, и не превышайте объема китайского контента.
В следующей таблице показаны различия локалей системы:
| Локализация для Speech Studio | Локаль REST API | Двуязычная поддержка |
|---|---|---|
Chinese (Mandarin, Simplified) |
zh-CN |
Если образец данных содержит английский, синтезированный голос говорит по-английски с родным английским акцентом, вместо акцента образца данных, независимо от объема данных на английском языке. |
Chinese (Mandarin, Simplified), English bilingual |
zh-CN (English bilingual) |
Если вы хотите, чтобы синтезированный голос говорил на английском языке с тем же акцентом, что и примеры данных, рекомендуется включить более 10% английских данных в наборе обучения. В противном случае акцент на английском языке может быть не идеальным. |
Chinese (Cantonese, Simplified) |
zh-HK |
Если вы хотите обучить синтезированный голос, способный говорить на английском языке с тем же акцентом, что и образец данных, обязательно предоставьте более 10% английских данных в учебном наборе. В противном случае, по умолчанию переключается на английский родной акцент. Пороговое значение 10% вычисляется на основе данных, принятых после успешной отправки, а не данных перед отправкой. Если некоторые загруженные данные на английском языке отклоняются из-за дефектов и не соответствуют порогу в 10%, синтезированный голос по умолчанию переключается на акцент носителя английского. |
Chinese (Taiwanese Mandarin, Traditional) |
zh-TW |
Если вы хотите обучить синтезированный голос, способный говорить на английском языке с тем же акцентом, что и образец данных, обязательно предоставьте более 10% английских данных в учебном наборе. В противном случае, по умолчанию переключается на английский родной акцент. Пороговое значение 10% вычисляется на основе данных, принятых после успешной отправки, а не данных перед отправкой. Если некоторые загруженные данные на английском языке отклоняются из-за дефектов и не соответствуют порогу в 10%, синтезированный голос по умолчанию переключается на акцент носителя английского. |

Мониторинг процесса обучения
В таблице Обучение модели отображается новая запись, соответствующая созданной модели. Состояние отражает процесс преобразования данных в голосовую модель, как описано в этой таблице:
| Государства | Смысл |
|---|---|
| Обработка | Ваша голосовая модель создается. |
| Удалось | Ваша голосовая модель создана и может быть развернута. |
| Ошибка | Ваша голосовая модель претерпела неудачу в обучении. Причиной сбоя может быть, например, невидимые проблемы с данными или сетевые проблемы. |
| Отменен | Обучение вашей голосовой модели было отменено. |
Пока состояние модели — Обрабатывается, можно выбрать Отмена обучения, чтобы отменить вашу голосовую модель. Плата за это отмененное обучение не взимается.

После успешного обучения модели можно просмотреть сведения о модели и протестировать голосовую модель.
Вы можете использовать средство создания аудиоконтентов в Speech Studio для создания звука и точной настройки развернутого голоса. Если применимо для голоса, можно выбрать один из нескольких стилей.
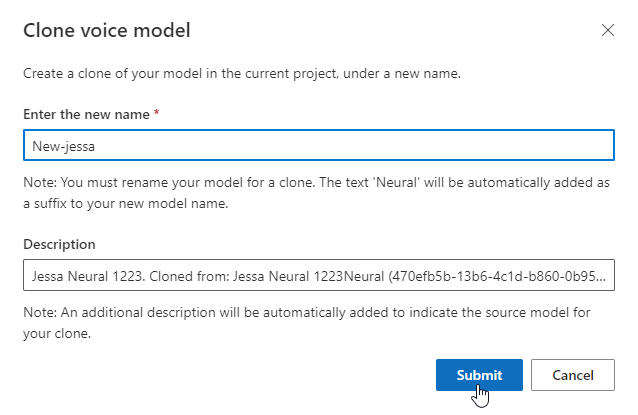
Переименование модели
Если вы хотите переименовать созданную модель, выберите " Клонировать модель", чтобы создать клон модели с новым именем в текущем проекте.

Введите новое имя в окне «Клонировать голосовую модель», затем выберите «Отправить». Текст нейронный автоматически добавляется как суффикс к названию новой модели.
Тестирование голосовой модели
После успешной сборки модели голосовой связи можно использовать созданные примеры звуковых файлов для его тестирования перед развертыванием.
Примечание
Нейронная — многоязычная и нейронная — голосовая связь HD не поддерживает этот тип тестирования.
Качество голоса зависит от многих факторов, таких как:
- Размер обучающих данных.
- Качество записи.
- Точность файла расшифровки.
- Насколько хорошо записанный голос в обучающих данных соответствует личности разработанного голоса для вашего предполагаемого варианта использования.
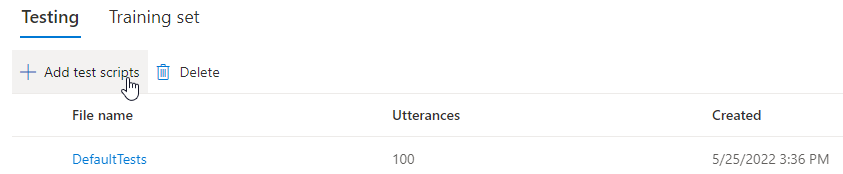
Выберите DefaultTests в разделе "Тестирование ", чтобы прослушивать образец звуковых файлов. Примеры тестов по умолчанию включают 100 примеров звуковых файлов, созданных автоматически во время обучения, чтобы помочь вам протестировать модель. Помимо этих 100 звуковых файлов, предоставляемых по умолчанию, собственные речевые фрагменты скрипта тестирования также добавляются в набор DefaultTests . Это дополнение составляет не более 100 высказываний. Плата за тестирование с помощью DefaultTests не взимается.

Если вы хотите отправить собственные тестовые скрипты для дальнейшего тестирования модели, выберите "Добавить тестовые скрипты " для отправки собственного тестового скрипта.
Перед отправкой тестового скрипта проверьте требования к скрипту тестирования. Плата за дополнительное тестирование с помощью пакетного синтеза взимается на основе количества оплачиваемых символов. См. Azure Speech в инструментах Foundry для получения информации о ценах.
В разделе "Добавить тестовые скрипты" выберите "Обзор файла ", чтобы выбрать собственный скрипт, а затем нажмите кнопку "Добавить ", чтобы отправить его.

Требования к тестовом скрипту
Тестовый скрипт должен быть файлом.txt размером менее 1 МБ. Поддерживаемые форматы кодирования включают ANSI/ASCII, UTF-8, UTF-8-BOM, UTF-16-LE или UTF-16-BE.
В отличие от файлов обучающего транскрибирования, скрипт теста должен исключить идентификатор высказываний, который является именем файла каждого высказывания. Иначе эти идентификаторы озвучиваются.
Ниже приведен пример набора речевых фрагментов в одном .txt файле:
This is the waistline, and it's falling.
We have trouble scoring.
It was Janet Maslin.
Каждый абзац речевого высказывания приводит к отдельному аудиофайлу. Если вы хотите объединить все предложения в один звук, сделайте их одним абзацем.
Примечание
Созданные звуковые файлы — это сочетание скриптов автоматического тестирования и пользовательских скриптов тестирования.
Обновите версию движка для вашей голосовой модели
Azure системы преобразования текста в речь обновляются время от времени, чтобы включить последнюю языковую модель, которая определяет произношение языка. После того как вы обучите голос, вы можете его применить к новой языковой модели, обновившись до последней версии модуля.
Когда доступен новый модуль, вам будет предложено обновить нейронную голосовую модель.

Перейдите на страницу сведений о модели и следуйте инструкциям на экране, чтобы установить последнюю версию подсистемы.

В качестве альтернативы выберите Установить последнюю версию движка, чтобы обновить модель до последней версии ядра.

За обновление движка плата не взимается. Предыдущие версии по-прежнему хранятся.
Вы можете проверить все версии подсистемы для модели из списка версий подсистемы или удалить ее, если она больше не нужна.

Обновленная версия автоматически устанавливается в качестве значения по умолчанию. Но вы можете изменить версию по умолчанию, выбрав версию из раскрывающегося списка и выбрав "Задать в качестве значения по умолчанию".


Если вы хотите протестировать каждую версию подсистемы голосовой модели, можно выбрать версию из списка, а затем выберите DefaultTests в разделе "Тестирование ", чтобы прослушивать образец звуковых файлов. Если вы хотите отправить собственные тестовые скрипты для дальнейшего тестирования текущей версии подсистемы, сначала убедитесь, что версия задана по умолчанию, а затем выполните действия, описанные в разделе "Тестирование голосовой модели".
Обновление подсистемы создает новую версию модели без дополнительных затрат. После обновления версии движка для вашей голосовой модели необходимо развернуть новую версию, чтобы создать новую конечную точку. Вы можете развернуть только версию по умолчанию.

После создания новой конечной точки необходимо передать трафик в новую конечную точку в продукте.
Дополнительные сведения о возможностях и ограничениях этой функции и рекомендациях по улучшению качества модели см. в разделе "Характеристики и ограничения" для использования пользовательского голоса.
Копирование голосовой модели в другой проект
Вы можете скопировать голосовую модель в другой проект для того же региона или другого региона. Например, можно скопировать нейронную голосовую модель, обученную в одном регионе, в проект для другого региона.
Примечание
Профессиональная настройка голосовой связи в настоящее время доступна только в некоторых регионах. Вы можете скопировать нейронную голосовую модель из этих регионов в другие регионы. Дополнительные сведения см. в регионах для пользовательского голоса.
Чтобы скопировать пользовательскую голосовую модель в другой проект:
На вкладке «Обучение модели» выберите голосовую модель, которую требуется скопировать, а затем выберите «Копировать в проект».

Выберите Subscription, Region, Speech resource и Project где нужно скопировать модель. У вас должен быть ресурс речи и проект в целевом регионе, в противном случае необходимо сначала создать их.

Нажмите кнопку "Отправить ", чтобы скопировать модель.
Выберите модель представления в сообщении уведомления об успешном копировании.
Перейдите к проекту, в котором вы скопировали модель для развертывания копии модели.
Дальнейшие действия
В этой статье вы узнаете, как настроить профессиональный голос с помощью пользовательского API голосовой связи.
Важно
Профессиональная настройка голосовой связи в настоящее время доступна только в некоторых регионах. После обучения голосовой модели в поддерживаемом регионе его можно скопировать в ресурс Foundry в другом регионе по мере необходимости. Дополнительные сведения см. в сносках в таблице службы "Речь".
Длительность обучения зависит от того, сколько данных вы используете. Это занимает около 10 часов вычислений в среднем, чтобы точно настроить профессиональный голос. Пользователи стандартной подписки (S0) могут одновременно обучать четыре голоса. Если вы достигнете предела, подождите, пока не менее одна из ваших голосовых моделей завершит обучение, а затем повторите попытку.
Примечание
Хотя общее количество часов, необходимых для каждого метода обучения, может различаться, одинаковая цена за единицу применяется ко всем. Дополнительные сведения см. в разделе о ценах на настраиваемую нейронную подготовку.
Выбор метода обучения
После проверки файлов данных используйте их для создания пользовательской голосовой модели. При создании пользовательского голоса вы можете обучить его одним из следующих методов:
Нейронный: создайте голос на том же языке, что и язык данных обучения.
Нейронный — HD голос: создайте HD голос на том же языке, что и ваши обучающие данные. Голоса Azure Neural HD на базе LLM оптимизированы для динамических диалогов. Дополнительные сведения об нейронных голосах HD см. здесь.
Нейронная — много стилей: создайте пользовательский голос, который выступает в нескольких стилях и эмоциях, не добавляя новые обучающие данные. Несколько стилей голоса полезны для игровых персонажей, беседных чат-ботов, аудиокниг, средств чтения содержимого и многое другое.
Чтобы создать несколько стилей голоса, необходимо подготовить набор общих обучающих данных, по крайней мере 300 речевых фрагментов. Выберите один или несколько предустановленных стилей речи целевого объекта. Вы также можете создать несколько пользовательских стилей, предоставив примеры стилей, по крайней мере 100 речевых фрагментов на стиль, в качестве дополнительных обучающих данных для одного голоса. Поддерживаемые стили предустановок зависят от разных языков. Просмотрите доступные стили предустановок на разных языках.
Нейронный — кросслингвальный: создайте голос, который говорит на другом языке, отличном от обучающих данных. Например, используя
fr-FRобучающие данные, можно создать голос, который произноситen-US.Язык обучающих данных и целевого языка должен быть одним из языков, которые поддерживаются для перекрестного обучения голосовой связи. Вам не нужно подготавливать обучающие данные на целевом языке, но тестовый скрипт должен находиться на целевом языке.
Язык обучающих данных должен быть одним из языков, которые поддерживаются для пользовательской голосовой обработки, межъязыкового, нескольких стилей или HD голосовой связи.
Создание голосовой модели
- Нейронный
- Нейронная — голосовая связь HD
- Нейронная — многостильная
- Нейронная — межъязыковая
- Нейронная — многоязычная
Чтобы создать нейронный голос, используйте операцию Models_Create пользовательского API голосовой связи. Создайте текст запроса в соответствии со следующими инструкциями:
- Задайте необходимое
projectIdсвойство. Смотрите создание проекта. - Задайте необходимое
consentIdсвойство. См. добавление согласия для работы с голосовыми талантами. - Задайте необходимое
trainingSetIdсвойство. См. статью о создании обучаемого набора. - Установите требуемое свойство
kindвDefaultдля тренировки нейронного голоса. Тип рецепта указывает метод обучения и не может быть изменен позже. Чтобы использовать другой метод обучения, см. Нейронная — кросс-языковая или Нейронная — многостилевая или Нейронная — HD голос. Дополнительные сведения о двуязычной подготовке и различиях между языковыми стандартами см. в Bilingual training. - Задайте необходимое
voiceNameсвойство. Тщательно выберите имя. Имя голоса используется в запросе синтеза речи SDK и входных данных SSML. Допускаются только буквы, цифры и несколько знаков препинания. Используйте разные имена для различных моделей нейронных голосовых данных. - При необходимости задайте
descriptionсвойство для описания голоса. Описание голоса можно изменить позже.
Выполните HTTP-запрос PUT с помощью URI, как показано в следующем Models_Create примере.
- Замените
YourResourceKeyключом ресурса распознавания речи. - Замените
YourResourceRegionрегион ресурсов службы "Речь". - Замените
JessicaModelIdидентификатором модели по своему усмотрению. Регистрозависимый идентификатор будет использоваться в URI модели и не может быть изменен позже.
curl -v -X PUT -H "Ocp-Apim-Subscription-Key: YourResourceKey" -H "Content-Type: application/json" -d '{
"voiceName": "JessicaNeural",
"description": "Jessica voice",
"recipe": {
"kind": "Default"
},
"projectId": "ProjectId",
"consentId": "JessicaConsentId",
"trainingSetId": "JessicaTrainingSetId"
} ' "https://YourResourceRegion.api.cognitive.microsoft.com/customvoice/models/JessicaModelId?api-version=2026-01-01"
Текст ответа должен быть получен в следующем формате:
{
"id": "JessicaModelId",
"voiceName": "JessicaNeural",
"description": "Jessica voice",
"recipe": {
"kind": "Default",
"version": "V10.0"
},
"projectId": "ProjectId",
"consentId": "JessicaConsentId",
"trainingSetId": "JessicaTrainingSetId",
"locale": "en-US",
"engineVersion": "2023.07.04.0",
"status": "NotStarted",
"createdDateTime": "2023-04-01T05:30:00.000Z",
"lastActionDateTime": "2023-04-02T10:15:30.000Z"
}
Двуязычное обучение
Если выбрать тип обучения нейронный, вы можете обучить голос говорить на нескольких языках.
zh-CN, zh-HK, и zh-TW поддерживают двуязычное обучение системы, чтобы распознавать речь как на китайском, так и на английском языках. В зависимости от ваших обучающих данных синтезированный голос может говорить на английском языке с английским собственным акцентом или английским с тем же акцентом, что и данные обучения.
Примечание
Чтобы включить голос в zh-CN языковом стандарте для разговора на английском языке с тем же акцентом, что и в образце данных, следует загрузить данные на английском языке в контекстный набор обучения или выбрать Chinese (Mandarin, Simplified), English bilingual при создании проекта, либо указать zh-CN (English bilingual) языковой стандарт для данных набора обучения через REST API.
Включите в контекстный набор обучения по крайней мере 100 предложений или 10 минут английского контента, и не превышайте объема китайского контента.
В следующей таблице показаны различия локалей системы:
| Локализация для Speech Studio | Локаль REST API | Двуязычная поддержка |
|---|---|---|
Chinese (Mandarin, Simplified) |
zh-CN |
Если образец данных содержит английский, синтезированный голос говорит по-английски с родным английским акцентом, вместо акцента образца данных, независимо от объема данных на английском языке. |
Chinese (Mandarin, Simplified), English bilingual |
zh-CN (English bilingual) |
Если вы хотите, чтобы синтезированный голос говорил на английском языке с тем же акцентом, что и примеры данных, рекомендуется включить более 10% английских данных в наборе обучения. В противном случае акцент на английском языке может быть не идеальным. |
Chinese (Cantonese, Simplified) |
zh-HK |
Если вы хотите обучить синтезированный голос, способный говорить на английском языке с тем же акцентом, что и образец данных, обязательно предоставьте более 10% английских данных в учебном наборе. В противном случае, по умолчанию переключается на английский родной акцент. Пороговое значение 10% вычисляется на основе данных, принятых после успешной отправки, а не данных перед отправкой. Если некоторые загруженные данные на английском языке отклоняются из-за дефектов и не соответствуют порогу в 10%, синтезированный голос по умолчанию переключается на акцент носителя английского. |
Chinese (Taiwanese Mandarin, Traditional) |
zh-TW |
Если вы хотите обучить синтезированный голос, способный говорить на английском языке с тем же акцентом, что и образец данных, обязательно предоставьте более 10% английских данных в учебном наборе. В противном случае, по умолчанию переключается на английский родной акцент. Пороговое значение 10% вычисляется на основе данных, принятых после успешной отправки, а не данных перед отправкой. Если некоторые загруженные данные на английском языке отклоняются из-за дефектов и не соответствуют порогу в 10%, синтезированный голос по умолчанию переключается на акцент носителя английского. |
Доступные стили предустановок на разных языках
В следующей таблице перечислены различные предустановленные стили в соответствии с различными языками.
| Стиль речи | Язык (локаль) |
|---|---|
| Злой | Английский (Соединенные Штаты) (en-US)Японский (Япония) ( ja-JP1)Китайский (Мандарин, упрощённый китайский) ( zh-CN) 1 |
| Спокойствие | Китайский (Мандарин, упрощённый китайский) (zh-CN) 1 |
| Чат | Китайский (Мандарин, упрощённый китайский) (zh-CN) 1 |
| Веселый | Английский (Соединенные Штаты) (en-US)Японский (Япония) ( ja-JP1)Китайский (Мандарин, упрощённый китайский) ( zh-CN) 1 |
| Недовольных | Китайский (Мандарин, упрощённый китайский) (zh-CN) 1 |
| Взволнован | Английский (Соединенные Штаты) (en-US) |
| Испуганный | Китайский (Мандарин, упрощённый китайский) (zh-CN) 1 |
| Дружелюбный | Английский (Соединенные Штаты) (en-US) |
| обнадеживающий | Английский (Соединенные Штаты) (en-US) |
| Грустно | Английский (Соединенные Штаты) (en-US)Японский (Япония) ( ja-JP1)Китайский (Мандарин, упрощённый китайский) ( zh-CN) 1 |
| Кричать | Английский (Соединенные Штаты) (en-US) |
| Серьезный | Китайский (Мандарин, упрощённый китайский) (zh-CN) 1 |
| Ужасе | Английский (Соединенные Штаты) (en-US) |
| Недружелюбный | Английский (Соединенные Штаты) (en-US) |
| Шепот | Английский (Соединенные Штаты) (en-US) |
1 Стиль нейронного голоса доступен в общедоступной предварительной версии. Текущий список регионов, поддерживающих стили в общедоступной предварительной версии, см. в таблице регионов службы "Речь".
Получить статус обучения
Чтобы получить состояние обучения модели голосовой связи, используйте Models_Get операцию пользовательского API голосовой связи. Создайте URI запроса в соответствии со следующими инструкциями:
Выполните HTTP-запрос GET с помощью URI, как показано в следующем Models_Get примере.
- Замените
YourResourceKeyключом ресурса распознавания речи. - Замените
YourResourceRegionрегион ресурсов службы "Речь". - Замените
JessicaModelId, если вы указали другой идентификатор модели на предыдущем шаге.
curl -v -X GET "https://YourResourceRegion.api.cognitive.microsoft.com/customvoice/models/JessicaModelId?api-version=2026-01-01" -H "Ocp-Apim-Subscription-Key: YourResourceKey"
Текст ответа должен быть получен в следующем формате.
Примечание
Рецепт kind и другие свойства зависят от того, как вы обучили голос. В этом примере Default обозначает тип рецепта для обучения нейронного голоса.
{
"id": "JessicaModelId",
"voiceName": "JessicaNeural",
"description": "Jessica voice",
"recipe": {
"kind": "Default",
"version": "V7.2023.03"
},
"projectId": "ProjectId",
"consentId": "JessicaConsentId",
"trainingSetId": "JessicaTrainingSetId",
"locale": "en-US",
"engineVersion": "2023.07.04.0",
"status": "Succeeded",
"createdDateTime": "2023-04-01T05:30:00.000Z",
"lastActionDateTime": "2023-04-02T10:15:30.000Z"
}
Может потребоваться ждать несколько минут до завершения обучения. В конечном итоге состояние изменится на одно из значений: либо Succeeded, либо Failed.