Примечание.
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
Когда вы готовы создать пользовательский синтез речи для вашего приложения, начните с собирания аудиозаписей и связанных сценариев для обучения модели голоса. Дополнительные сведения о записи образцов голоса см. в этом руководстве. Служба речи использует эти данные для создания уникального голоса, настроенного для сопоставления голоса в записях. После обучения голоса вы можете начать синтез речи в приложениях.
Все отправляемые данные должны соответствовать требованиям к выбранному типу данных. Важно правильно отформатировать данные перед отправкой, что гарантирует, что данные точно обрабатываются службой "Речь". Чтобы убедиться, что данные правильно отформатированы, см. статью "Типы данных обучения".
Примечание.
- Пользователи со стандартной подпиской (S0) могут одновременно отправлять пять файлов данных. Если достигнуто предельное количество отправляемых файлов, подождите, пока завершится импорт хотя бы одного из них. Затем повторите попытку.
- Максимальное количество файлов данных, которые пользователи стандартной подписки (S0) могут импортировать для каждой подписки, составляет 500 .zip файлов. Дополнительные сведения см. в разделе "Квоты и ограничения службы "Речь".
Отправка данных
Подсказка
Пример инструкции согласия и обучающих данных см. в репозитории GitHub.
Когда вы будете готовы отправить данные, откройте вкладку Prepare training data (Подготовка обучающих данных), чтобы добавить первый обучающий набор и передать данные. Обучающий набор — это набор речевых фрагментов и их сценариев сопоставления, используемых для обучения голосовой модели. Обучающий набор можно использовать для организации обучающих данных. Сервис проверяет готовность данных для каждого обучаемого набора. Вы можете импортировать несколько файлов данных в набор обучения.
Чтобы отправить обучающие данные, выполните следующие действия.
Войдите на портал Microsoft Foundry (классический).
Выберите Тонкая настройка в левой области и выберите Тонкая настройка службы ИИ.
Выберите задачу профессиональной настройки голосовой связи (по имени модели), которую вы начали, как описано в статье о создании профессиональной голосовой связи.
Выберите Подготовить обучающие данные>Загрузить данные.
В мастере отправки данных выберите тип данных. Если вы используете примеры данных, выберите отдельные речевые фрагменты и соответствующие расшифровки.

Выберите Далее.
На странице "Указание целевого набора обучения" нажмите кнопку "Создать".
Введите имя набора обучения и нажмите кнопку "Создать".
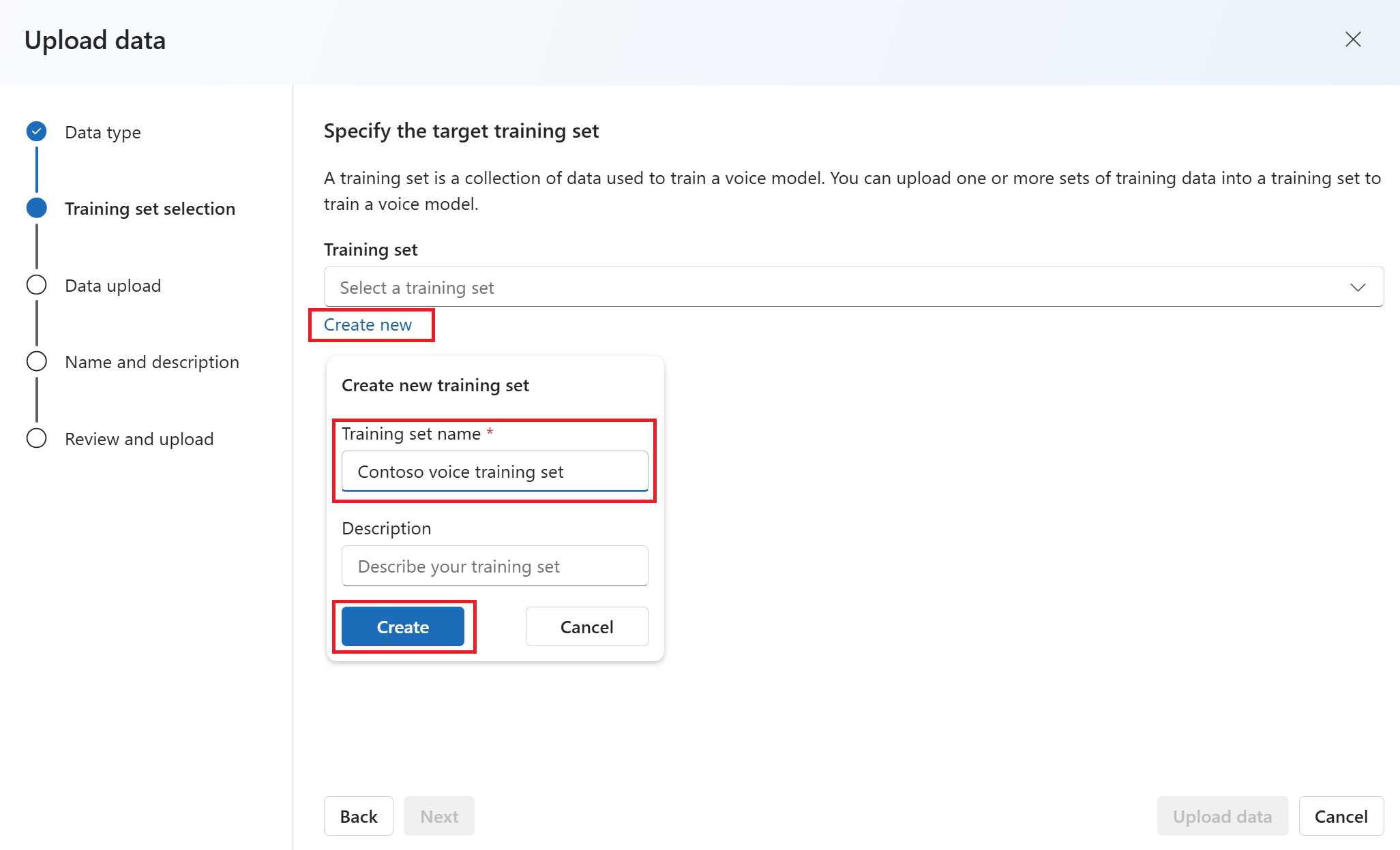
Выберите Далее.
На странице отправки данных выберите файл записи и файл скрипта в соответствующих плитках. Вы можете выбрать локальные файлы на компьютере или ввести URL-адрес хранилища BLOB-объектов Azure для отправки данных.
Выберите Далее.
Введите имя и описание данных, а затем нажмите кнопку "Далее".
Просмотрите сведения о отправке и выберите " Отправить данные".


Примечание.
Дублирующиеся идентификаторы не принимаются. Речевые фрагменты с тем же идентификатором удаляются.
Дубликаты названий аудио удаляются из обучения. Убедитесь, что в выбранных вами данных нет звуковых фрагментов с одинаковыми названиями в одном или нескольких ZIP-файлах. Если идентификаторы речевых фрагментов (в аудиофайлах или файлах сценариев) дублируются, они будут отклонены.
Файлы данных автоматически проверяются при выборе кнопки "Отправить данные". Проверка данных включает ряд проверок аудиофайлов, чтобы проверить их формат, размер и частоту выборки. Если возникнут ошибки, исправьте их и повторите отправку.
После того как вы загрузите данные, вы можете проверить сведения в подробном представлении обучающего набора. На странице деталей можно проверить вопросы произношения и уровень шума для каждого из ваших данных. Оценка произношения на уровне предложения составляет от 0 до 100. Оценка ниже 70 обычно означает ошибку в речи или несоответствие в сценарии. Речевые фрагменты с общей оценкой ниже 70 отклоняются. Заметный акцент уменьшает оценку произношения и влияет на созданный цифровой голос.
Устранение проблем с данными в Сети
После отправки данных можно проверить сведения о данных для обучаемого набора. Прежде чем продолжить обучение голосовой модели, попробуйте устранить все проблемы с данными.
Типичные проблемы с данными
В следующих таблицах описываются распространенные проблемы с данными.
Автоматически отклонено
Процесс обучения исключает данные с этими проблемами. Процесс импорта игнорирует данные с этими проблемами, поэтому их не нужно удалять. Вы можете устранить эти проблемы с данными в Интернете или отправить исправленные данные для обучения.
| Категория | Имя | Описание |
|---|---|---|
| Скрипт | Недопустимый разделитель | Идентификатор высказывания и содержимое сценария следует разделять символом табуляции. |
| Скрипт | Недопустимый идентификатор сценария. | Идентификатор строки сценария должен быть числом. |
| Скрипт | Дублирующийся скрипт | Каждая строка содержимого скрипта должна быть уникальной. Для дублирования строк используются символы {}. |
| Скрипт | Слишком длинный скрипт | Длина скрипта должна быть менее 1000 символов. |
| Скрипт | Нет соответствующего звукового фрагмента | Идентификатор каждого речевого фрагмента (каждой строки в файле скрипта) должен соответствовать идентификатору звукового фрагмента. |
| Скрипт | Нет допустимого сценария | В этом наборе данных не найден допустимый сценарий. Исправьте строки скрипта, отображаемые в подробном списке проблем. |
| Аудио | Нет соответствующего скрипта | Нет звуковых файлов, соответствующих идентификатору скрипта. Имена WAV-файлов должны соответствовать идентификаторам в файле сценария. |
| Аудио | Недопустимый формат звука | Недопустимый звуковой формат WAV-файлов. Проверьте формат WAV-файлов средством для работы со звуковыми данными, например SoX. |
| Аудио | Низкая частота дискретизации | Частота дискретизации WAV-файлов должна быть не ниже 16 кГц. |
| Аудио | Слишком длинный звуковой фрагмент | Длительность звука превышает 30 секунд. Разделите длинный звуковой фрагмент на несколько файлов. Хорошей идеей будет делать речевые фрагменты короче 15 секунд. |
| Аудио | Нет допустимого звука | В этом наборе данных нет допустимых звуковых фрагментов. Проверьте звуковые данные и отправьте их еще раз. |
| Несоответствие | Речевой фрагмент с низкой оценкой | Оценка произношения на уровне предложений ниже 70. Проверьте скрипт и содержимое звуковых файлов и убедитесь, что они соответствуют друг другу. |
Автоматическое исправление
Система автоматически исправляет следующие проблемы, но необходимо проверить и подтвердить правильность исправлений.
| Категория | Имя | Описание |
|---|---|---|
| Несоответствие | Автоматически исправлена тишина | Начальная тишина обнаруживается короче 100 мс и расширяется до 100 мс автоматически. Скачайте нормализованный набор данных и проверьте его. |
| Несоответствие | Автоматически исправлена тишина | Конечная пауза обнаружена короче 100 мс и автоматически увеличивается до 100 мс. Скачайте нормализованный набор данных и проверьте его. |
| Скрипт | Текст автоматически нормализован | Текст автоматически нормализуется для цифр, символов и аббревиаций. Просмотрите скрипт и звук, чтобы убедиться, что они соответствуют. |
Требуется проверка вручную
Неразрешенные проблемы, перечисленные в следующей таблице, влияют на качество обучения, но процесс обучения не исключает данные с этими проблемами. Для повышения качества обучения исправьте эти проблемы вручную.
| Категория | Имя | Описание |
|---|---|---|
| Скрипт | Ненормализованный текст | В этом сценарии имеются символы. Нормализуйте эти символы, чтобы они соответствовали аудиозаписи. Например, нормализуйте / в slash. |
| Скрипт | Недостаточное количество вопросительных речевых фрагментов | Не менее 10 % всех речевых фрагментов должны представлять собой вопросительные предложения. С их помощью голосовая модель учится правильно произносить вопросительные интонации. |
| Скрипт | Недостаточно восклицаний | Не менее 10 % всех речевых фрагментов должны представлять собой восклицательные предложения. Это помогает голосовой модели грамотно выражать возбуждённый тон. |
| Скрипт | Недопустимая конечная пунктуация | Добавьте одно из следующих элементов в конце строки: полная остановка (половина ширины "." или "。" "), восклицательный знак (половина ширины "!" или полной ширины "!") или вопросительный знак (половина ширины "?" или полной ширины "?"). |
| Аудио | Низкая частота дискретизации нейронного голоса | Рекомендуется, чтобы скорость выборки файлов .wav была 24 КГц или выше для создания нейронных голосов. Если это меньше, система автоматически поднимает ее до 24 КГц. |
| Громкость | Общая громкость слишком низкая | Уровень громкости не должен быть ниже 18 дБ (10 % от максимального уровня громкости). Во время записи образцов или подготовки данных следите за тем, чтобы средний уровень находился в пределах допустимого диапазона. |
| Громкость | Превышение допустимого уровня громкости | Обнаружено превышение допустимого уровня громкости в позиции {} с. Настройте записывающее оборудование, чтобы избежать превышения громкости на её пиковом значении. |
| Громкость | Запустить процесс устранения проблемы молчания | Первые 100 мс тишины не являются чистыми. Уменьшите пороговый уровень шума при записи. Начальный фрагмент длительностью 100 мс должен быть без звуков. |
| Громкость | Проблема прекращения молчания | Последние 100 мс тишины не чисты. Уменьшите пороговый уровень шума при записи. Конечный фрагмент длительностью 100 мс должен быть без звуков. |
| Несоответствие | Слова с низкой оценкой | Проверьте сценарий и содержимое звуковых файлов. Убедитесь, что они соответствуют друг другу, и снизьте пороговый уровень шума. Уменьшите продолжительность длинного участка без звуков. Если звуковой файл слишком длинный, разделите его на несколько речевых фрагментов. |
| Несоответствие | Запустить процесс устранения проблемы молчания | Перед первым словом был слышен посторонний звук. Проверьте скрипт и содержимое звуковых файлов; убедитесь, что они соответствуют друг другу, уменьшите пороговый уровень шума и создайте в начале записи фрагмент продолжительностью 100 мс без звуков. |
| Несоответствие | Проблема прекращения молчания | После последнего слова был слышен лишний звук. Проверьте скрипт и содержимое звуковых файлов; убедитесь, что они соответствуют друг другу, уменьшите пороговый уровень шума и создайте в конце записи фрагмент продолжительностью 100 мс без звуков. |
| Несоответствие | Плохое отношение "сигнал/шум" | Отношение "сигнал/шум" меньше 20 дБ. Рекомендуется значение не менее 35 дБ. |
| Несоответствие | Оценка недоступна | Не удалось распознать речевое содержимое в этом звуковом фрагменте. Проверьте содержимое звукового фрагмента и скрипта; убедитесь, что звуковой фрагмент допустимый и соответствует скрипту. |
Следующий шаг
Когда вы будете готовы создать пользовательский голос для преобразования текста в речь для приложения, первым шагом будет собрать аудиозаписи и соответствующие сценарии для начала обучения модели голоса. Дополнительные сведения о записи образцов голоса см. в этом руководстве. Служба речи использует эти данные для создания уникального голоса, настроенного для сопоставления голоса в записях. После обучения голосовой модели вы можете использовать ее для синтезирования речи в приложениях.
Все отправляемые данные должны соответствовать требованиям к выбранному типу данных. Перед отправкой важно правильно отформатировать данные, чтобы обеспечить их точную обработку в службе "Речь". Чтобы убедиться, что данные правильно отформатированы, см. статью "Типы данных обучения".
Примечание.
- Пользователи со стандартной подпиской (S0) могут одновременно отправлять пять файлов данных. Если достигнуто предельное количество отправляемых файлов, подождите, пока завершится импорт хотя бы одного из них. Затем повторите попытку.
- В рамках одной стандартной подписки (S0) можно импортировать не более 500 ZIP-файлов с данными. Дополнительную информацию см. в статье Квоты и ограничения службы речи.
Отправка данных
Когда вы будете готовы отправить данные, откройте вкладку Prepare training data (Подготовка обучающих данных), чтобы добавить первый обучающий набор и передать данные. Обучающий набор — это набор речевых фрагментов и их сценариев сопоставления, используемых для обучения голосовой модели. Обучающий набор можно использовать для организации обучающих данных. Служба проверяет готовность данных каждого обучающего набора. В обучающий набор можно импортировать несколько наборов данных.
Чтобы отправить обучающие данные, выполните следующие действия.
- Войдите в службу Speech Studio.
- Выберите Пользовательский голос> наименование вашего проекта >Подготовить данные для обучения>Загрузить данные.
- В мастере отправки данных выберите тип данных и нажмите кнопку "Далее".
- Выберите локальные файлы на компьютере или введите URL-адрес хранилища BLOB-объектов Azure для отправки данных.
- Если в контекстных проектах поддержки вы выбрали типы данных Длинные аудио + транскрибирование или Только аудио, вы увидите вариант выбора режима обработки:
- Обработано как контекстное: обрабатывает звук при сохранении контекстной информации для расширенных возможностей общения и более естественных шаблонов речи.
- Сегментировано: обрабатывает звук и транскрибирование в отдельные речевые фрагменты с помощью стандартной сегментации.
- В разделе "Укажите целевой набор обучения", выберите существующий набор обучения или создайте новый. Если вы создали новый набор обучения, убедитесь, что он выбран в раскрывающемся списке перед продолжением.
- Выберите Далее.
- Введите имя и описание данных, а затем нажмите кнопку "Далее".
- Просмотрите сведения о отправке и нажмите кнопку "Отправить".
Примечание.
Повторяющиеся идентификаторы не принимаются. Речевые фрагменты с тем же идентификатором будут удалены.
Дубликаты названий аудио удаляются из обучения. Убедитесь, что в выбранных вами данных нет звуковых фрагментов с одинаковыми названиями в одном или нескольких ZIP-файлах. Если идентификаторы речевых фрагментов (в аудиофайлах или файлах сценариев) дублируются, они будут отклонены.
Обучающий набор может содержать только данные, обработанные в том же режиме. Например, если вы загружаете данные в набор данных для обучения в режиме "обработано как контекстное", все последующие загрузки в тот же набор данных для обучения также должны использовать режим "обработано как контекстное".
Файлы данных проверяются автоматически при нажатии кнопки Submit (Отправить). Проверка данных включает ряд проверок звуковых файлов, включая проверку формата, размера и частоты выборки. Если возникнут ошибки, исправьте их и повторите отправку.
После того как вы загрузите данные, вы можете проверить сведения в подробном представлении обучающего набора. На странице сведений можно дополнительно проверить проблему произношения и уровень шума для каждого из данных. Оценка произношения на уровне предложения составляет от 0 до 100. Оценка ниже 70 обычно означает ошибку в речи или несоответствие в сценарии. Речевые фрагменты с общей оценкой ниже 70 будут отклонены. Заметный акцент уменьшает оценку произношения и влияет на созданный цифровой голос.
Устранение проблем с данными в Сети
После отправки можно проверить сведения о данных обучающего набора. Прежде чем продолжить обучение голосовой модели, необходимо попытаться устранить любые проблемы с данными.
Вы можете определить и устранить проблемы с данными в речевых фрагментах в Speech Studio.
Обработано как сегментированные данные
На странице сведений перейдите на страницу "Принятые данные" или "Отклоненные данные". Выберите отдельные речевые фрагменты, которые вы хотите изменить, а затем нажмите кнопку "Изменить".
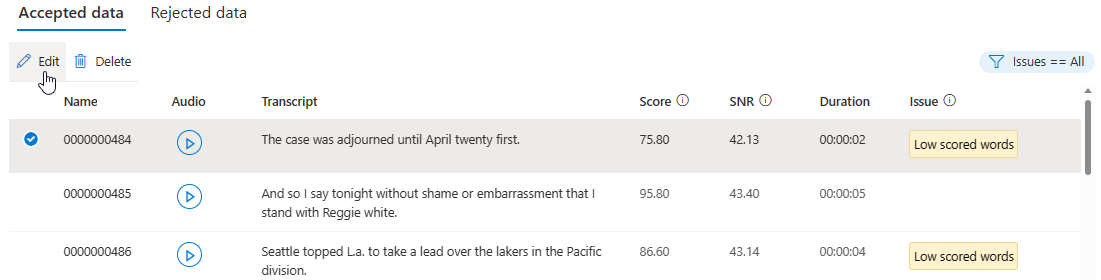
Вы можете выбрать, какие проблемы с данными должны отображаться в зависимости от условий.

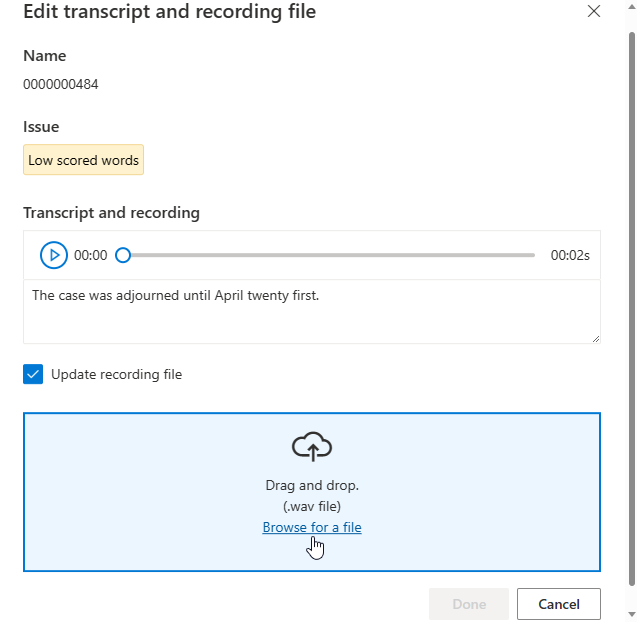
Откроется окно правки.

Обновите файл расшифровки или записи в соответствии с описанием проблемы в окне редактирования.
Вы можете изменить расшифровку в текстовом поле, а затем нажмите кнопку "Готово"

Если нужно обновить файл записи, выберите элемент Обновление файла записи, а затем отправьте исправленный файл записи (WAV).
После внесения изменений в данные необходимо проверить качество данных, нажав кнопку "Анализ данных", прежде чем использовать этот набор данных для обучения.
Нельзя выбирать этот обучающий набор для модели обучения до завершения анализа.
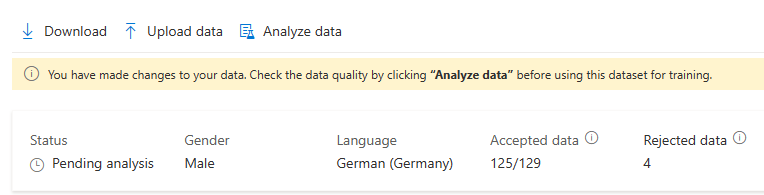
Кроме того, вы можете удалять речевые фрагменты с проблемами. Для этого выберите их и нажмите кнопку Удалить.
Обработано как контекстное
В отличие от обработанного как сегментированного, обработанный как Контекстуальный сохраняет исходные звуковые файлы и создает соответствующую контекстную информацию.
На странице сведений щелкните отдельные речевые фрагменты с параметром "Количество проблем".

Контекстная информация представлена в виде сегментов. Выберите сегмент, который нужно изменить, а затем нажмите кнопку "Изменить ".
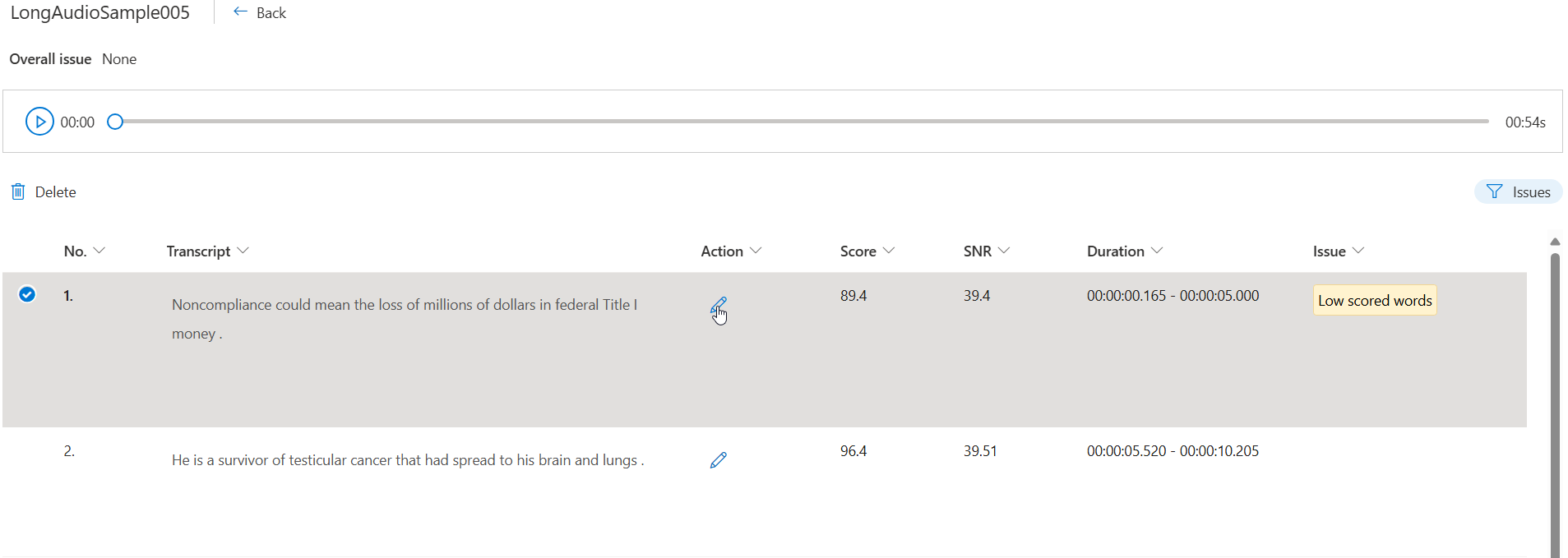
Вы можете выбрать, какие проблемы с данными должны отображаться в зависимости от условий.
Измените расшифровку в текстовом поле в соответствии с описанием проблемы, а затем нажмите кнопку "Готово".

После внесения изменений в данные необходимо проверить качество данных, нажав кнопку "Анализ данных", прежде чем использовать этот набор данных для обучения.
Нельзя выбирать этот обучающий набор для модели обучения до завершения анализа.
Примечание.
Удаление сегмента контекстной информации не исключает это содержимое из обучения. Удаление сегментов только в том случае, если их информация уже включена или будет включена в смежные сегменты.
Отклоненные сегменты не будут использоваться для обучения.
Типичные проблемы с данными
Проблемы делятся на три типа. Чтобы определить тип ошибки, обратитесь к приведенным ниже таблицам.
Автоматически отклонено
Данные с такими ошибками не будут использоваться для обучения. Импортированные данные с ошибками будут игнорироваться, поэтому удалять их не нужно. Эти ошибки данных можно исправить в Интернете или снова отправить исправленные данные для обучения.
| Категория | Имя | Описание |
|---|---|---|
| Скрипт | Недопустимый разделитель | Идентификатор высказывания и содержимое сценария следует разделять символом табуляции. |
| Скрипт | Недопустимый идентификатор сценария. | Идентификатор строки сценария должен быть числом. |
| Скрипт | Дублирующийся скрипт | Каждая строка содержимого скрипта должна быть уникальной. Для дублирования строк используются символы {}. |
| Скрипт | Слишком длинный скрипт | Длина скрипта должна быть менее 1000 символов. |
| Скрипт | Нет соответствующего звукового фрагмента | Идентификатор каждого речевого фрагмента (каждой строки в файле скрипта) должен соответствовать идентификатору звукового фрагмента. |
| Скрипт | Нет допустимого сценария | В этом наборе данных не найден допустимый сценарий. Исправьте строки скрипта, указанные в списке проблем. |
| Аудио | Нет соответствующего скрипта | Нет звуковых файлов, соответствующих идентификатору скрипта. Имена WAV-файлов должны соответствовать идентификаторам в файле сценария. |
| Аудио | Недопустимый формат звука | Недопустимый звуковой формат WAV-файлов. Проверьте формат WAV-файлов средством для работы со звуковыми данными, например SoX. |
| Аудио | Низкая частота дискретизации | Частота дискретизации WAV-файлов должна быть не ниже 16 кГц. |
| Аудио | Слишком длинный звуковой фрагмент | Длительность звука превышает 30 секунд. Разделите длинный звуковой фрагмент на несколько файлов. Хорошей идеей будет делать речевые фрагменты короче 15 секунд. |
| Аудио | Нет допустимого звука | В этом наборе данных нет допустимых звуковых фрагментов. Проверьте звуковые данные и отправьте их еще раз. |
| Несоответствие | Речевой фрагмент с низкой оценкой | Оценка произношения на уровне предложений ниже 70. Проверьте скрипт и содержимое звуковых файлов и убедитесь, что они соответствуют друг другу. |
Автоматическое исправление
Следующие ошибки исправляются автоматически, но вам следует проверять эти исправления и убеждаться, что они выполнены верно.
| Категория | Имя | Описание |
|---|---|---|
| Несоответствие | Автоматически исправлена тишина | Обнаружено, что в начале записи имеется фрагмент без звука продолжительностью менее 100 мс. Система автоматически увеличила его длительность до 100 мс. Скачайте нормализованный набор данных и проверьте его. |
| Несоответствие | Автоматически исправлена тишина | Обнаружено, что в конце записи имеется фрагмент без звука продолжительностью менее 100 мс. Система автоматически увеличила его длительность до 100 мс. Скачайте нормализованный набор данных и проверьте его. |
| Скрипт | Текст автоматически нормализован | Текст автоматически нормализуется для цифр, символов и аббревиаций. Просмотрите скрипт и звук, чтобы убедиться, что они соответствуют. |
Требуется проверка вручную
Неисправленные ошибки, указанные в следующей таблице, влияют на качество обучения, но данные с этими ошибками не будут исключены во время обучения. Для более высокого качества обучения эти ошибки рекомендуется исправлять вручную.
| Категория | Имя | Описание |
|---|---|---|
| Скрипт | Ненормализованный текст | В этом сценарии имеются символы. Нормализуйте эти символы, чтобы они соответствовали аудиозаписи. Например, нормализуйте / в slash. |
| Скрипт | Недостаточное количество вопросительных речевых фрагментов | Не менее 10 % всех речевых фрагментов должны представлять собой вопросительные предложения. С их помощью голосовая модель учится правильно произносить вопросительные интонации. |
| Скрипт | Недостаточно восклицаний | Не менее 10 % всех речевых фрагментов должны представлять собой восклицательные предложения. Это помогает голосовой модели грамотно выражать возбуждённый тон. |
| Скрипт | Недопустимая конечная пунктуация | Добавьте один из следующих символов в конце строки: точка (полуширина '.' или полная ширина '。'), восклицательный знак (полуширина '!' или полная ширина '!') или знак вопроса (полуширина '?' или полная ширина '?'). |
| Аудио | Низкая частота дискретизации нейронного голоса | При создании нейронных голосов рекомендуется использовать WAV-файлы с частотой дискретизации 24 кГц или больше. Если она ниже, то будет автоматически повышена до 24 кГц. |
| Громкость | Общая громкость слишком низкая | Уровень громкости не должен быть ниже 18 дБ (10 % от максимального уровня громкости). Во время записи образцов или подготовки данных следите за тем, чтобы средний уровень находился в пределах допустимого диапазона. |
| Громкость | Превышение допустимого уровня громкости | Обнаружено превышение допустимого уровня громкости в позиции {} с. Настройте записывающее оборудование, чтобы избежать превышения громкости на её пиковом значении. |
| Громкость | Проблема с фрагментом без звука в начале записи | Первые 100 мс тишины не являются чистыми. Уменьшите пороговый уровень шума при записи. Начальный фрагмент длительностью 100 мс должен быть без звуков. |
| Громкость | Устранение проблемы тишины | Последние 100 мс тишины не чисты. Уменьшите пороговый уровень шума при записи. Конечный фрагмент длительностью 100 мс должен быть без звуков. |
| Несоответствие | Слова с низкой оценкой | Проверьте сценарий и содержимое звуковых файлов. Убедитесь, что они соответствуют друг другу, и снизьте пороговый уровень шума. Уменьшите продолжительность длинного участка без звуков. Если звуковой файл слишком длинный, разделите его на несколько речевых фрагментов. |
| Несоответствие | Проблема с фрагментом без звука в начале записи | Перед первым словом был слышен посторонний звук. Проверьте скрипт и содержимое звуковых файлов; убедитесь, что они соответствуют друг другу, уменьшите пороговый уровень шума и создайте в начале записи фрагмент продолжительностью 100 мс без звуков. |
| Несоответствие | Устранение проблемы тишины | После последнего слова был слышен лишний звук. Проверьте скрипт и содержимое звуковых файлов; убедитесь, что они соответствуют друг другу, уменьшите пороговый уровень шума и создайте в конце записи фрагмент продолжительностью 100 мс без звуков. |
| Несоответствие | Плохое отношение "сигнал/шум" | Отношение "сигнал/шум" меньше 20 дБ. Рекомендуется значение не менее 35 дБ. |
| Несоответствие | Оценка недоступна | Не удалось распознать речевое содержимое в этом звуковом фрагменте. Проверьте содержимое звукового фрагмента и скрипта; убедитесь, что звуковой фрагмент допустимый и соответствует скрипту. |
Следующие шаги
Вам нужен обучающий набор данных для создания профессионального голоса. Набор данных для обучения включает звуковые файлы и скрипты. Аудиофайлы являются записями голосовых дикторов, читающих сценарные файлы. Файлы скриптов — это текст звуковых файлов.
В этой статье вы создадите обучающий набор и получите его идентификатор ресурса. Затем с помощью идентификатора ресурса можно отправить набор звуковых и скриптовых файлов.
Создание обучаемого набора
Чтобы создать набор обучения, используйте операцию TrainingSets_Create пользовательского голосового API. Создайте текст запроса в соответствии со следующими инструкциями:
- Задайте обязательное свойство
projectId. См. статью о создании проекта. - Установите требуемое свойство
voiceKindв значениеMaleилиFemale. Тип нельзя изменить позже. - Задайте обязательное свойство
locale. Это должна быть локаль данных обучающего набора. Языковой стандарт обучающего набора должен совпадать с языковым стандартом заявления о согласии. Изменить региональные настройки позже будет невозможно. Список локалей для преобразования текста в речь можно найти здесь. - При необходимости задайте
descriptionсвойство для описания набора обучения. Описание набора обучения можно изменить позже.
Выполните HTTP-запрос PUT с помощью URI, как показано в следующем TrainingSets_Create примере.
- Замените
YourResourceKeyключом ресурса службы речи. - Замените
YourResourceRegionна регион ресурса «Речь». - Замените
JessicaTrainingSetIdидентификатором тренировочного набора данных по вашему выбору. Идентификатор, чувствительный к регистру, будет использоваться в URI тренировочного набора и не может быть изменен позже.
curl -v -X PUT -H "Ocp-Apim-Subscription-Key: YourResourceKey" -H "Content-Type: application/json" -d '{
"description": "300 sentences Jessica data in general style.",
"projectId": "ProjectId",
"locale": "en-US",
"voiceKind": "Female"
} ' "https://YourResourceRegion.api.cognitive.microsoft.com/customvoice/trainingsets/JessicaTrainingSetId?api-version=2026-01-01"
Вы должны получить ответ в следующем формате:
{
"id": "JessicaTrainingSetId",
"description": "300 sentences Jessica data in general style.",
"projectId": "ProjectId",
"locale": "en-US",
"voiceKind": "Female",
"status": "Succeeded",
"createdDateTime": "2023-04-01T05:30:00.000Z",
"lastActionDateTime": "2023-04-02T10:15:30.000Z"
}
Загрузка данных обучающего набора
Чтобы отправить обучающий набор аудио и скриптов, используйте операцию TrainingSets_UploadData пользовательского голосового API.
Перед вызовом этого API сохраните файлы записей и скриптов в BLOB-объекте Azure. В следующем примере файлы записи обозначены как https://contoso.blob.core.windows.net/voicecontainer/jessica300/*.wav, а файлы скриптов — как https://contoso.blob.core.windows.net/voicecontainer/jessica300/*.txt.
Создайте текст запроса в соответствии со следующими инструкциями:
- Задайте требуемому свойству значение
kind,AudioAndScript,LongAudioилиAudioOnly. Вид определяет тип обучающего набора. - При необходимости задайте
processAsсвойство, чтобы указать метод обработки. Поддерживаемые значения:Segmented(по умолчанию) иContextual.Contextual— расширенный режим, который сохраняет звук в целом, чтобы сохранить контекстную информацию для более естественных интонации. РежимContextualдоступен только в том случае, еслиkindустановлено вLongAudioилиAudioOnly. Если это не указано, используется режим по умолчаниюSegmented. Дополнительные сведения см. в разделе "Учебные типы данных". - Задайте обязательное свойство
audios. В свойствеaudiosзадайте следующие свойства:- Задайте для требуемого
containerUrlсвойства URL-адрес контейнера Хранилище BLOB-объектов Azure, который содержит звуковые файлы. Используйте подписи общего доступа (SAS) для контейнера с разрешениями на чтение и список. - Задайте требуемое
extensionsсвойство расширениям звуковых файлов. - По желанию установите свойство
prefix, чтобы задать префикс для имени BLOB.
- Задайте для требуемого
- Задайте обязательное свойство
scripts. В свойствеscriptsзадайте следующие свойства:- Задайте для требуемого
containerUrlсвойства URL-адрес контейнера хранилища блоб-объектов Azure, в котором содержатся файлы скриптов. Используйте подписи общего доступа (SAS) для контейнера с разрешениями на чтение и список. - Задайте требуемое
extensionsсвойство расширениям файлов скриптов. - По желанию установите свойство
prefix, чтобы задать префикс для имени BLOB.
- Задайте для требуемого
Выполните HTTP-запрос POST с помощью URI, как показано в следующем TrainingSets_UploadData примере.
- Замените
YourResourceKeyключом ресурса службы речи. - Замените
YourResourceRegionна регион ресурса «Речь». - Замените
JessicaTrainingSetId, если вы указали другой идентификатор набора обучения на предыдущем шаге.
curl -v -X POST -H "Ocp-Apim-Subscription-Key: YourResourceKey" -H "Content-Type: application/json" -d '{
"kind": "AudioAndScript",
"audios": {
"containerUrl": "https://contoso.blob.core.windows.net/voicecontainer?mySasToken",
"prefix": "jessica300/",
"extensions": [
".wav"
]
},
"scripts": {
"containerUrl": "https://contoso.blob.core.windows.net/voicecontainer?mySasToken",
"prefix": "jessica300/",
"extensions": [
".txt"
]
}
} ' "https://YourResourceRegion.api.cognitive.microsoft.com/customvoice/trainingsets/JessicaTrainingSetId:upload?api-version=2026-01-01"
В следующем примере передаются длинные звуковые данные с контекстной обработкой:
curl -v -X POST -H "Ocp-Apim-Subscription-Key: YourResourceKey" -H "Content-Type: application/json" -d '{
"kind": "LongAudio",
"processAs": "Contextual",
"audios": {
"containerUrl": "https://contoso.blob.core.windows.net/voicecontainer?mySasToken",
"prefix": "jessica-long/",
"extensions": [
".wav"
]
},
"scripts": {
"containerUrl": "https://contoso.blob.core.windows.net/voicecontainer?mySasToken",
"prefix": "jessica-long/",
"extensions": [
".txt"
]
}
} ' "https://YourResourceRegion.api.cognitive.microsoft.com/customvoice/trainingsets/JessicaTrainingSetId:upload?api-version=2026-01-01"
Заголовок ответа содержит Operation-Location свойство. Используйте этот URI для получения сведений об операции TrainingSets_UploadData . Ниже приведен пример заголовка ответа:
Operation-Location: https://eastus.api.cognitive.microsoft.com/customvoice/operations/aaaabbbb-0000-cccc-1111-dddd2222eeee?api-version=2026-01-01
Operation-Id: aaaabbbb-0000-cccc-1111-dddd2222eeee