Быстрый старт: Создание детектора объектов с помощью веб-сайта Custom Vision
Статья
11.04.2025
В этом кратком руководстве объясняется, как использовать веб-сайт Custom Vision для создания модели детектора объектов. Созданную модель можно протестировать с использованием новых изображений и интегрировать в собственное приложение для распознавания изображений.
Набор изображений для обучения модели детектора. Можно использовать набор примеров изображений в GitHub. Кроме того, вы можете выбрать собственные изображения, используя следующие советы.
Чтобы использовать службу Custom Vision, необходимо создать обучающие ресурсы и ресурсы прогнозирования Custom Vision в Azure. В портале Azure используйте страницу «Создать пользовательское визуальное распознавание» для создания ресурса обучения и ресурса прогнозирования.
Создание нового проекта
В веб-браузере перейдите на веб-сайт Custom Vision. Войдите с той же учетной записью, которую вы использовали для входа в портал Azure.
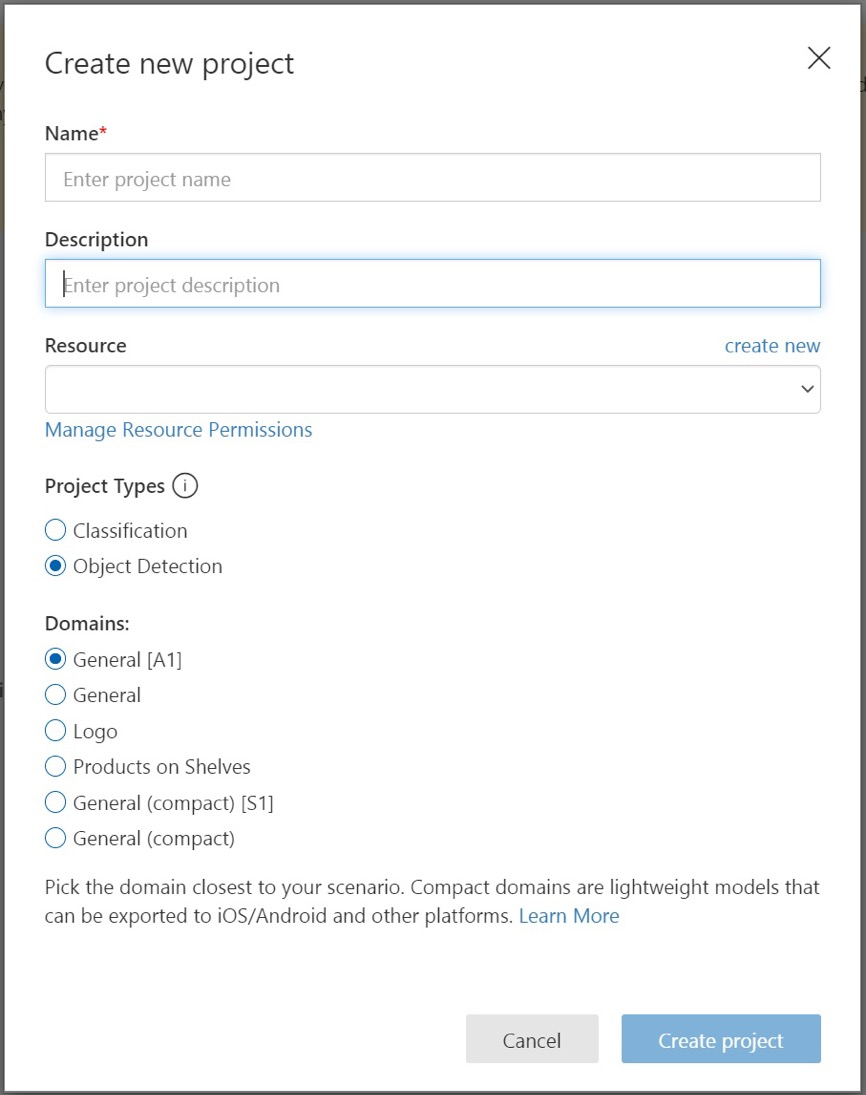
Для создания первого проекта щелкните Новый проект. Откроется диалоговое окно "Создание проекта ".
Введите имя и описание проекта. Затем выберите свой пользовательский визуальный обучающий ресурс. Если учетная запись входа связана с учетной записью Azure, раскрывающийся список ресурсов отображает все совместимые ресурсы Azure.
Примечание
Если ресурс недоступен, убедитесь, что вы вошли в customvision.ai с той же учетной записью, что и для входа в портал Azure. Кроме того, убедитесь, что вы выбрали тот же каталог на веб-сайте Custom Vision, что и каталог в портале Azure, где находятся ваши ресурсы Custom Vision. На обоих сайтах можно выбрать каталог в раскрывающемся меню учетной записи в правом верхнем углу экрана.
В разделе "Типы проектов" выберите "Обнаружение объектов".
Выберите один из доступных доменов. Каждый домен оптимизирует средство обнаружения для определенных типов изображений, как описано в следующей таблице. Вы можете изменить домен позже, если вы хотите.
Домен
Цель
Общие сведения
Рассчитан на самые разные задачи обнаружения объектов. Если не подходит ни один из других доменов или вы не уверены, какой домен выбрать, выбирайте General.
Логотип
Оптимизировано для поиска марочных логотипов в изображениях.
Продукты на полках
Оптимизировано для обнаружения и классификации продуктов на полках.
Компактные домены
Оптимизированы для ограничений обнаружения объектов в режиме реального времени на мобильных устройствах. Модели, созданные доменами Compact, можно экспортировать для локального запуска.
И наконец, щелкните Create project (Создать проект).
Выбор обучающих изображений
Как минимум, следует использовать не менее 30 изображений на тег в начальном наборе обучения. Вы также должны собрать несколько дополнительных изображений, чтобы протестировать модель после того, как она будет обучена.
Чтобы обучение модели было эффективным, используйте разнообразные изображения. Выберите изображения, которые различаются по:
угол обзора камеры;
освещение;
фон
стиль изображения;
отдельные субъекты и сгруппированные субъекты
размер
тип
Также убедитесь, что все обучающие изображения соответствуют следующим критериям:
должен быть в формате .jpg, .png, .bmp или .gif
размер не превышает 6 МБ (4 МБ для изображений прогнозирования)
не менее 256 пикселей на самой короткой стороне; все изображения, короче 256 пикселей, автоматически масштабируются службой Custom Vision.
Отправка и снабжение тегами изображений
В этом разделе вы отправляете и вручную помечаете изображения для обучения детектора.
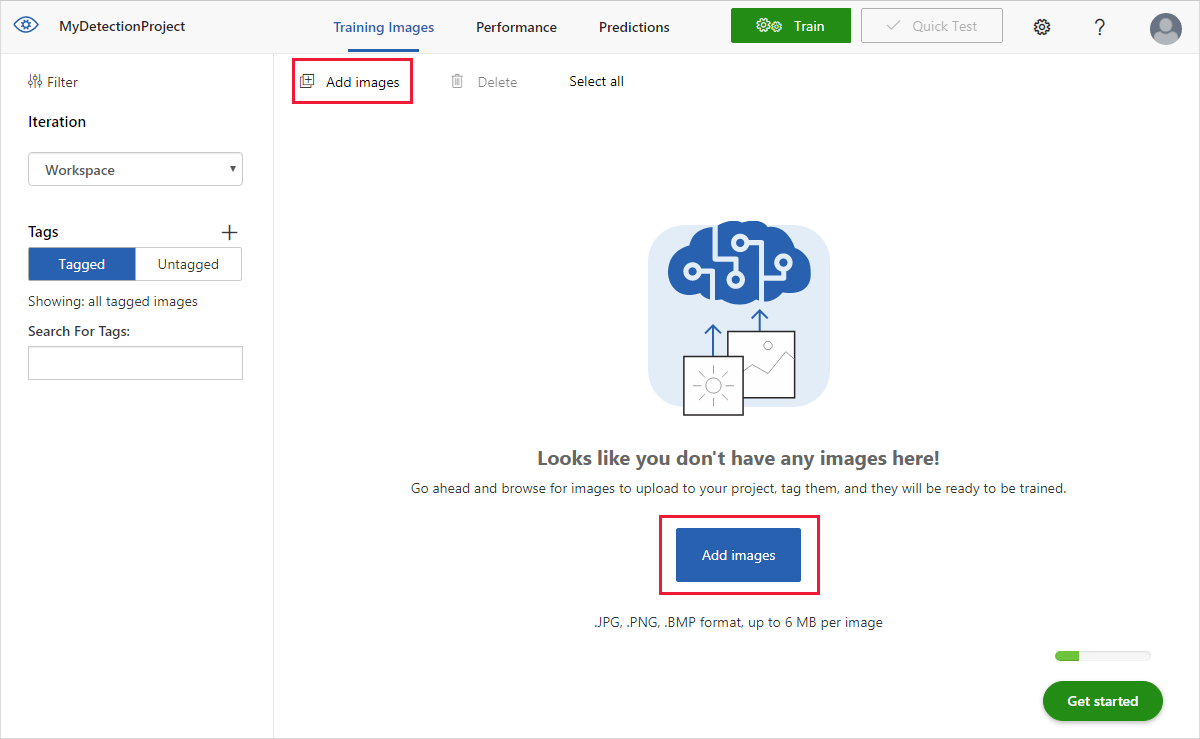
Чтобы добавить изображения, последовательно выберите элементы Add images (Добавить изображения) и Browse local files (Обзор локальных файлов). Выберите Открыть, чтобы загрузить изображение.
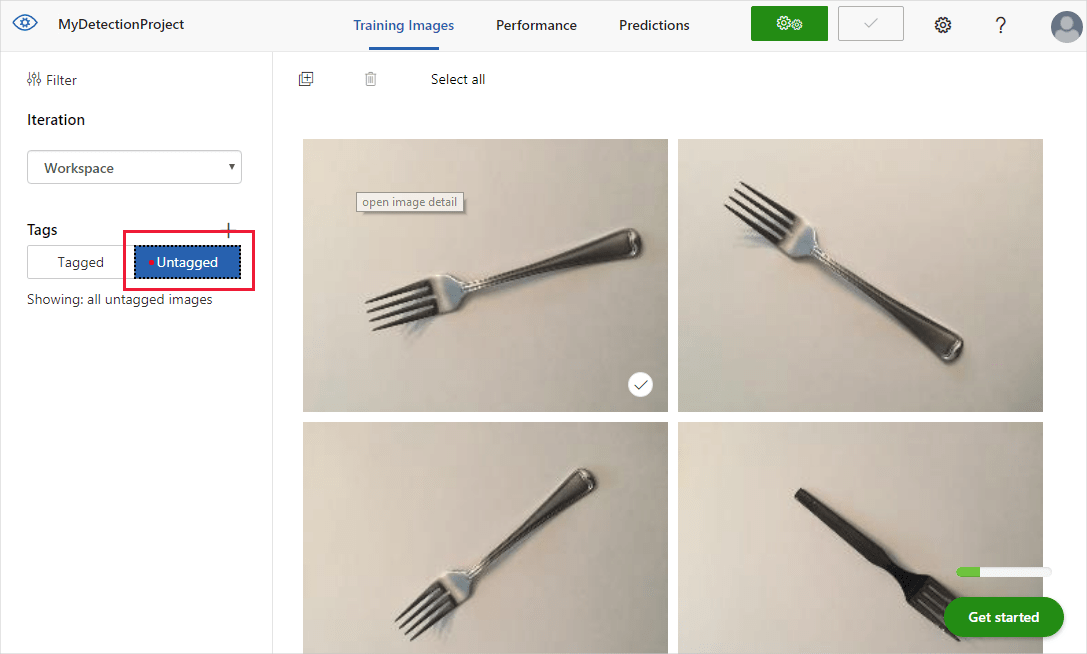
Вы увидите свои загруженные изображения в разделе Без тегов. Следующий этап — вручную отметить объекты, которые вы хотите, чтобы средство обнаружения научилось распознавать. Выберите первое изображение, чтобы открыть диалоговое окно присвоения тегов.
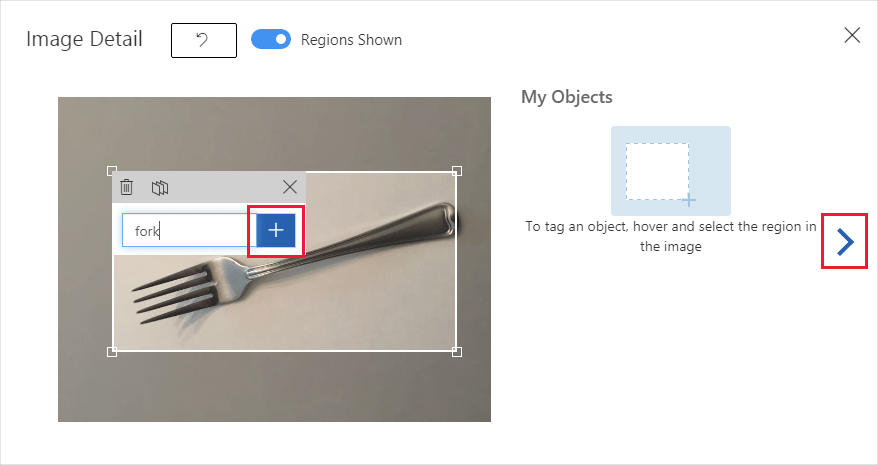
Выделите и перетащите прямоугольник вокруг объекта в изображении. Затем введите новое имя тега с помощью кнопки + или выберите существующий тег из раскрывающегося списка. Важно отметить все экземпляры объектов, которые вы хотите обнаружить, так как детектор использует непомеченную фоновую область в качестве отрицательного примера при обучении. После добавления тегов щелкните стрелку справа, чтобы сохранить теги и перейти к следующему изображению.
Чтобы отправить новый набор изображений, прокрутите страницу наверх и повторите все шаги.
Обучение средства обнаружения
Для обучения модели средства обнаружения нажмите кнопку Train (Обучение). Средство обнаружения использует все текущие изображения и их теги для создания модели, которая идентифицирует каждый помеченный объект. Этот процесс может занять несколько минут.
Процесс обучения обычно занимает пару минут. В течение этого времени информация о процессе обучения отображается на вкладке Performance (Производительность).
анализ средств обнаружения;
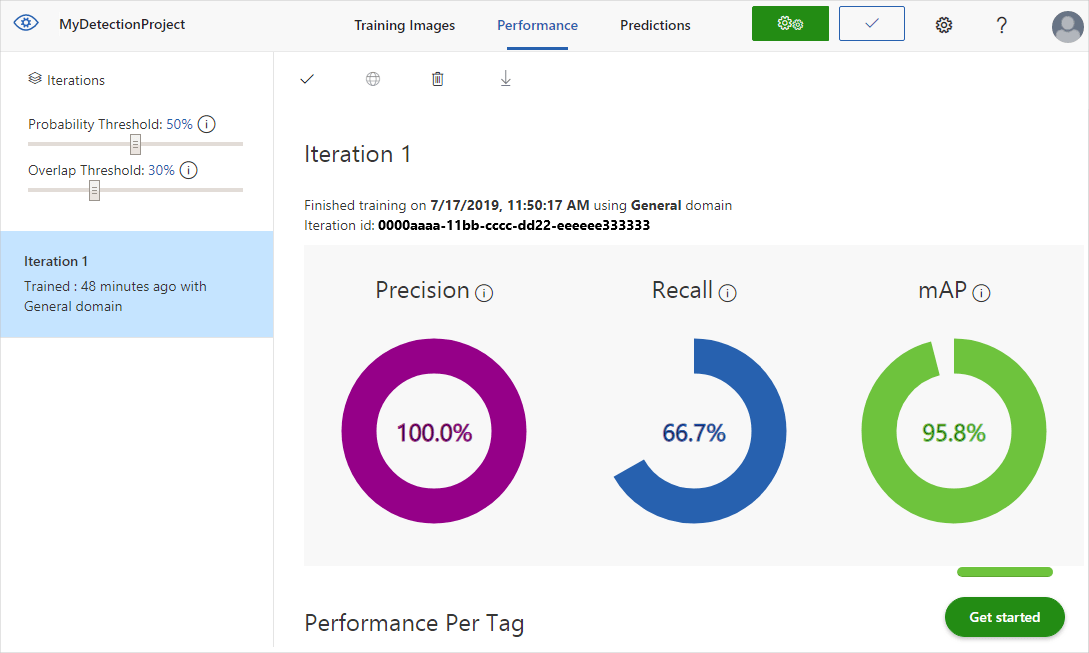
После завершения обучения производительность модели вычисляется и отображается. Служба Custom Vision использует изображения, которые вы отправили для обучения, чтобы вычислить точность, полноту и среднее значение точности. Точность и полнота — это разные характеристики эффективности средства обнаружения.
Точность обозначает долю правильно определенных классов. Например, если модель определила наличие собак на 100 изображениях, из которых на 99 действительно есть собаки, точность этой модели составляет 99 %.
Полнота обозначает долю фактических классификаций, которые были правильно идентифицированы. Например, если на самом деле имеется 100 изображений яблок, из которых модель правильно определила 80, полнота этой модели составляет 80 %.
Усредненная точность — среднее значение средней точности (AP). AP — это область под кривой точности и полноты (точность, построенная в зависимости от полноты для каждого прогноза).
Порог вероятности
Обратите внимание на ползунок порога вероятности на левой панели вкладки «Производительность». Это уровень уверенности, который должен иметь прогноз, чтобы считаться правильным (в целях вычисления точности и достоверности).
Когда вы интерпретируете вызовы прогнозирования с высоким порогом вероятности, они, как правило, возвращают результаты с высокой точностью в ущерб полноте: обнаруженные классификации верны, но многие остаются не обнаруженными. При низком пороге вероятности ситуация противоположная: обнаруживается большинство фактических классификаций, но в этом наборе больше ложных положительных срабатываний. Учитывайте это при настройке порога вероятности в соответствии с потребностями для конкретного проекта. Позже, когда вы получите результаты прогнозирования на стороне клиента, вам нужно будет задать используемое здесь значение порога вероятности.
Порог перекрытия
Ползунок порога перекрытия определяет, насколько точно должно быть спрогнозировано положение объекта, чтобы в обучении это считалось правильным. Он устанавливает минимальное допустимое перекрытие между рамкой прогнозируемого объекта и фактической рамкой, введенной пользователем. Если ограничивающие поля не перекрываются до такой степени, прогноз не считается правильным.
Управление итерациями обучения
При каждом обучении средства обнаружения создается новая итерация с обновленными метриками производительности. Все итерации можно просмотреть на левой панели вкладки "Производительность ". В левой области вы также найдете кнопку "Удалить ", которую можно использовать для удаления итерации, если она устарела. При удалении итерации удаляются только связанные с ней изображения.
Сведения о программном доступе к обученным моделям см. в статье "Использование модели с API прогнозирования".
Следующий шаг
В этом кратком руководстве вы узнали, как создать и обучить модель обнаружения объектов с помощью веб-сайта Custom Vision. Далее получите больше информации об итеративном процессе улучшения вашей модели.
Управляйте загрузкой и подготовкой данных, обучением и развертыванием моделей, а также мониторингом решений машинного обучения с использованием Python, Azure Machine Learning и MLflow.