Примечание.
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
В этой статье приведены рекомендации по оптимизации производительности, сокращению затрат и защите учетной записи хранения Azure с поддержкой Data Lake Storage.
Общие рекомендации по структурированию озера данных см. в следующих статьях:
- Обзор Azure Data Lake Storage для сценария управления данными и аналитики
- Создайте три учетные записи Azure Data Lake Storage для каждой зоны посадки данных
Поиск документации
Azure Data Lake Storage не является выделенной службой или типом учетной записи. Это набор возможностей, поддерживающих высокопроизводительные аналитические рабочие нагрузки. Документация по Data Lake Storage предоставляет лучшие практики и рекомендации по использованию этих возможностей. Для всех остальных аспектов управления учетными записями, таких как настройка сетевой безопасности, проектирование для обеспечения высокой доступности и восстановление после аварий, см. содержание документации по Blob-хранилищу.
Оценка поддержки функций и известных проблем
Используйте следующий шаблон при настройке учетной записи для использования функций Blob-хранилища.
Ознакомьтесь со статьей о поддержке возможностей хранилища BLOB-объектов в учетных записях хранения Azure, чтобы определить, полностью ли поддерживается эта функция в ваших учетных записях. Некоторые функции пока не поддерживаются или частично поддерживаются в учетных записях с поддержкой Data Lake Storage. Поддержка функций постоянно расширяется, поэтому периодически просматривайте эту статью.
Просмотрите известные проблемы с Azure Data Lake Storage , чтобы узнать, существуют ли ограничения или специальные рекомендации по использованию функции.
Сканируйте статьи с описанием функциональности в поисках любых рекомендаций, относящихся к учетным записям с поддержкой Data Lake Storage.
Общие сведения о терминах, используемых в документации
При перемещении между наборами содержимого вы заметите некоторые незначительные различия в терминологии. Например, содержимое, используемое в документации по хранилищу BLOB-объектов, будет использовать термин BLOB-объект вместо файла. Технически файлы, которые вы загружаете в учетную запись хранения, становятся объектами BLOB в вашей учетной записи. Поэтому термин правильный. Тем не менее, термин blob может вызвать путаницу, если вы привыкли к термину файл. Вы также увидите контейнер терминов, используемый для ссылки на файловую систему. Рассмотрим эти термины как синонимы.
Рассмотрите премиум.
Если для рабочих нагрузок требуется низкая согласованность задержки и (или) требуется большое количество входных выходных операций в секунду (IOP), рассмотрите возможность использования учетной записи хранения BLOB-объектов класса Premium. Этот тип учетной записи предоставляет данные с помощью высокопроизводительного оборудования. Данные хранятся на твердотельных накопителях (SSD), оптимизированных для низкой задержки. SSD обеспечивают более высокую пропускную способность по сравнению с традиционными жесткими дисками. Затраты на хранение производительности уровня "Премиум" выше, но затраты на транзакции ниже. Таким образом, если ваши рабочие нагрузки выполняют большое количество транзакций, учетная запись блобов с премиум-производительностью может быть экономичным вариантом.
Если ваша учетная запись хранения будет использоваться для аналитики, мы настоятельно рекомендуем использовать Azure Data Lake Storage вместе с учетной записью хранения BLOB-объектов класса Premium. Эта комбинация использования учетных записей хранения BLOB-объектов класса premium вместе с учетной записью Data Lake Storage с поддержкой Data Lake Storage называется ценовой категории "Премиум" для Azure Data Lake Storage.
Оптимизация загрузки данных
При приеме данных из исходной системы исходное оборудование, исходное сетевое оборудование или сетевое подключение к учетной записи хранения может быть узким местом.
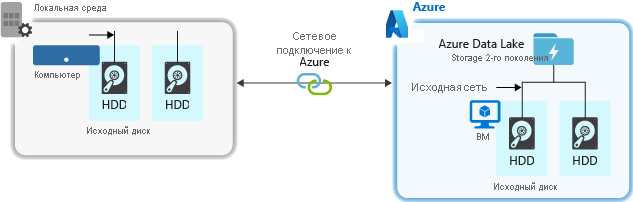
исходное оборудование
Независимо от того, используете ли вы локальные машины или виртуальные машины в Azure, тщательно выберите соответствующее оборудование. Для аппаратного обеспечения диска рекомендуется использовать твердотельные накопители (SSD) и выбирать аппаратное обеспечение с быстродействующими шпинделями. Для сетевого оборудования используйте максимально быстрые сетевые контроллеры (сетевые адаптеры). В Azure рекомендуется использовать виртуальные машины Azure D14 с соответствующими мощными дисками и сетевым оборудованием.
Сетевое подключение к учетной записи хранения
Сетевое подключение между исходными данными и учетной записью хранения иногда может быть узким местом. При локальной работе с исходными данными рекомендуется использовать выделенную ссылку с Azure ExpressRoute. Если ваши исходные данные находятся в Azure, наилучшей производительности можно достичь, если данные будут в том же регионе Azure, что и учетная запись Data Lake Storage.
Настройка средств приема данных для максимальной параллелизации
Чтобы обеспечить оптимальную производительность, используйте всю доступную пропускную способность, выполняя как можно больше операций чтения и записи.
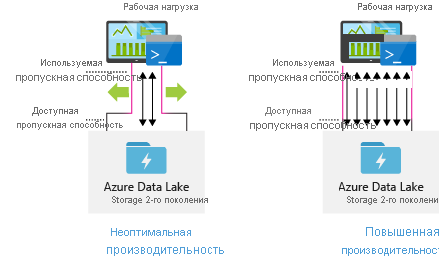
В следующей таблице приведены основные параметры для нескольких популярных средств приема.
| Инструмент | Настройки |
|---|---|
| DistCp | -m (маппер) |
| Фабрика данных Azure | параллельные копии |
| Sqoop | fs.azure.block.size, -m (маппер) |
| AzCopy | AZCOPY_CONCURRENCY_VALUE |
Замечание
Общая производительность операций приема зависит от других факторов, относящихся к инструменту, используемому для приема данных. Для получения лучших рекомендаций по up-to-date, обратитесь к документации каждого инструмента, который вы планируете использовать.
Учетная запись может масштабироваться, чтобы обеспечить необходимую пропускную способность для всех сценариев аналитики. По умолчанию включенная учетная запись Data Lake Storage обеспечивает достаточную пропускную способность в конфигурации по умолчанию для удовлетворения потребностей широкой категории вариантов использования. При выполнении ограничения по умолчанию учетная запись может быть настроена для обеспечения большей пропускной способности, обратившись в службу поддержки Azure.
Структурированные наборы данных
Рассмотрите возможность предварительного планирования структуры данных. Формат файлов, размер файла и структура каталогов могут повлиять на производительность и стоимость.
Форматы файлов
Данные можно получать в различных форматах. Данные могут отображаться в удобочитаемых форматах, таких как JSON, CSV или XML, или в виде сжатых двоичных форматов, таких как .tar.gz. Данные также могут поступать в различных размерах. Данные могут состоять из больших файлов (несколько терабайтов), таких как данные из экспорта таблицы SQL из локальных систем. Данные также могут поступать в виде большого количества крошечных файлов (несколько килобайтов), таких как данные из событий в режиме реального времени из решения Интернета вещей . Вы можете оптимизировать эффективность и затраты, выбрав соответствующий формат файла и размер файла.
Hadoop поддерживает набор форматов файлов, оптимизированных для хранения и обработки структурированных данных. Некоторые распространенные форматы: Avro, Parquet и оптимизированный формат Row Columnar (ORC). Все эти форматы — это форматы двоичных файлов, доступные для машинного чтения. Они сжимаются для управления размером файла. Они имеют схему, внедренную в каждый файл, что делает их самоописательными. Разница между этими форматами заключается в том, как хранятся данные. Avro хранит данные в формате на основе строк, а форматы Parquet и ORC хранят данные в столбцовом формате.
Рекомендуется использовать формат файла Avro в случаях, когда шаблоны ввода-вывода являются более тяжелыми для записи, или шаблоны запросов предпочитают получать несколько строк записей в целом. Например, формат Avro хорошо работает с шиной сообщений, например Центрами событий или Kafka, которая записывает несколько событий или сообщений в последовательности.
Рассмотрим форматы файлов Parquet и ORC, если шаблоны ввода-вывода более читаются или когда шаблоны запросов сосредоточены на подмножестве столбцов в записях. Транзакции чтения можно оптимизировать для получения определенных столбцов вместо чтения всей записи.
Apache Parquet — это формат файла с открытым исходным кодом, оптимизированный для интенсивного чтения в аналитических конвейерах. Структура хранилища столбцов Parquet позволяет пропустить не соответствующие данные. Ваши запросы гораздо эффективнее, так как они могут сузить область обработки данных, отправляемых из хранилища в подсистему аналитики. Кроме того, так как аналогичные типы данных (для столбца) хранятся вместе, Parquet поддерживает эффективные схемы сжатия и кодирования данных, которые могут снизить затраты на хранение данных. Такие службы, как Azure Synapse Analytics, Azure Databricks и Фабрика данных Azure , имеют собственные функции, которые используют преимущества форматов файлов Parquet.
Размер файла
Более крупные файлы приводят к повышению производительности и снижению затрат.
Как правило, подсистемы аналитики, такие как HDInsight, имеют нагрузку на файл, которая включает такие задачи, как перечисление, проверка доступа и выполнение различных операций метаданных. Если вы храните данные в виде множества небольших файлов, это может негативно сказаться на производительности. В общем, организуйте ваши данные в файлы большего размера для повышения производительности (от 256 МБ до 100 ГБ). Некоторые подсистемы и приложения могут иметь проблемы с эффективной обработкой файлов, размер которых превышает 100 ГБ.
Увеличение размера файла также может снизить затраты на транзакции. Операции чтения и записи оплачиваются за каждые 4 мегабайта, поэтому плата взимается за чтение или запись независимо от того, содержит файл 4 мегабайта или меньше. Сведения о ценах см. в разделе о ценах на Azure Data Lake Storage.
В некоторых случаях конвейеры данных имеют ограниченный контроль над необработанными данными, которые содержат множество небольших файлов. Как правило, рекомендуется, чтобы в системе был какой-то процесс агрегирования небольших файлов в более крупные файлы для использования подчиненными приложениями. Если вы обрабатываете данные в режиме реального времени, вы можете использовать подсистему потоковой передачи в реальном времени (например , Azure Stream Analytics или Spark Streaming) вместе с брокером сообщений (например, Центрами событий или Apache Kafka) для хранения данных в виде больших файлов. При агрегации небольших файлов в большие, рекомендуется сохранить их в оптимизированном для чтения формате, например Apache Parquet для последующей обработки.
Структура каталогов
Каждая рабочая нагрузка имеет разные требования к способу использования данных, но это некоторые распространенные макеты, которые следует учитывать при работе с Интернетом вещей (IoT), пакетными сценариями или при оптимизации данных временных рядов.
Структура Интернета вещей
В рабочих нагрузках Интернета вещей может быть много данных, которые охватывают множество продуктов, устройств, организаций и клиентов. Важно предварительно спланировать макет каталога для организации, безопасности и эффективной обработки данных для потребителей нижнего потока. Ниже приведен общий шаблон, который стоит рассмотреть.
- {Region}/{SubjectMatter(s)}/{y}/{mm}/{dd}/{hh}/
Например, структура посадочной телеметрии двигателя самолета в Соединенном Королевстве может выглядеть следующим образом:
- Uk/Planes/BA1293/Engine1/2017/08/11/12/
В этом примере поместив дату в конец структуры каталогов, вы можете использовать списки управления доступом для более простой защиты регионов и темы для конкретных пользователей и групп. Если вы положили структуру дат в начале, было бы гораздо сложнее защитить эти регионы и темы. Например, если вы хотите предоставить доступ только к британским данным или определённым самолётам, вам потребуется дать отдельное разрешение для многочисленных каталогов в каждом каталоге по часам. Эта структура также будет экспоненциально увеличивать количество каталогов по мере того, как время продолжалось.
Структура пакетных заданий
Часто используемый подход в пакетной обработке заключается в том, чтобы поместить данные в каталог in. Затем после обработки данных поместите новые данные в каталог "out" для использования последующими процессами. Эта структура каталогов иногда используется для заданий, требующих обработки отдельных файлов, и может не требовать массовой параллельной обработки над большими наборами данных. Как и рекомендуемая выше структура Интернета вещей, хорошая структура каталогов имеет каталоги родительского уровня для таких вещей, как регион и темы (например, организация, продукт или производитель). Рассмотрим дату и время в структуре, чтобы обеспечить лучшую организацию, отфильтрованные поиски, безопасность и автоматизацию в обработке. Уровень детализации структуры даты определяется интервалом, с которым данные загружаются или обрабатываются, например ежечасно, ежедневно или даже ежемесячно.
Иногда обработка файлов завершается сбоем из-за повреждения данных или непредвиденных форматов. В таких случаях структура каталогов может воспользоваться папкой /bad , чтобы переместить файлы на более подробную проверку. Пакетное задание может также управлять процессом составления отчетов или уведомлений об этих недопустимых файлах для устранения проблем вручную. Рассмотрите следующую структуру:
- {Region}/{SubjectMatter(s)}/In/{y}/{mm}/{dd}/{hh}/
- {Region}/{SubjectMatter(s)}/Out/{gggg}/{mm}/{dd}/{hh}/
- {Region}/{SubjectMatter(s)}/Bad/{y}/{mm}/{dd}/{hh}/
Например, маркетинговая фирма ежедневно получает выгрузки данных об обновлениях клиентов из Северной Америки. Она может выглядеть, как приведенный ниже фрагмент кода, перед обработкой и после нее:
- NA/Extracts/ACMEPaperCo/In/2017/08/14/updates_08142017.csv
- NA/Extracts/ACMEPaperCo/Out/2017/08/14/processed_updates_08142017.csv
В обычном случае обработки пакетных данных непосредственно в базы данных, такие как Hive или традиционные базы данных SQL, не требуется каталог /in или /out , так как выходные данные уже попадают в отдельную папку для таблицы Hive или внешней базы данных. Например, ежедневные выгрузки от клиентов будут попадать в соответствующие папки. Затем служба, например Фабрика данных Azure, Apache Oozie или Apache Airflow , активирует ежедневное задание Hive или Spark для обработки и записи данных в таблицу Hive.
Структура данных временных рядов
Для задач Hive, подрезка секций временных рядов данных может помочь некоторым запросам читать только подмножество данных, что повышает производительность.
Те конвейеры, которые импортируют данные временных рядов, часто используют структурированное именование для файлов и папок. Ниже приведен распространенный пример данных, структурированных по дате:
/DataSet/ГГГГ/ММ/ДД/datafile_YYYY_MM_DD.tsv
Обратите внимание, что информация о дате и времени появляется как в виде папок, так и в имени файла.
Для даты и времени ниже приведен общий шаблон.
/DataSet/YYYY/MM/DD/HH/mm/datafile_YYYY_MM_DD_HH_mm.tsv
Снова, выбор, который вы делаете в отношении организации папок и файлов, должен оптимизировать большее количество файлов и увеличить их разумное количество в каждой папке.
Настройка безопасности
Начните с изучения статьи Рекомендации по безопасности для хранилища BLOB-объектов. Вы найдете рекомендации по защите данных от случайного или вредоносного удаления, защиты данных за брандмауэром и использования идентификатора Microsoft Entra в качестве основы управления удостоверениями.
Затем ознакомьтесь с моделью управления доступом в статье Azure Data Lake Storage , чтобы получить рекомендации, относящиеся к учетным записям с поддержкой Data Lake Storage. В этой статье показано, как использовать роли управления доступом на основе ролей Azure (Azure RBAC) вместе со списками управления доступом (ACL) для принудительного применения разрешений безопасности для каталогов и файлов в иерархической файловой системе.
Прием, обработка и анализ
Существует множество различных источников данных и различных способов приема данных в учетную запись Data Lake Storage.
Например, можно получать большие наборы данных из кластеров HDInsight и Hadoop или небольших наборов нерегламентированных данных для прототипов приложений. Вы можете получать потоковые данные, создаваемые различными источниками, такими как приложения, устройства и датчики. Для данного типа данных можно использовать инструменты для захвата и обработки данных пособытийно в режиме реального времени, а затем записывать события пакетами в свою учетную запись. Вы также можете получать журналы веб-сервера, содержащие такие сведения, как журнал запросов страниц. Для данных журнала рассмотрите возможность написания пользовательских скриптов или приложений для их отправки, чтобы обеспечить гибкость включения компонента отправки данных в рамках более крупного приложения больших данных.
После того как данные будут доступны в учетной записи, вы можете выполнить анализ этих данных, создать визуализации и даже скачать данные на локальный компьютер или в другие репозитории, такие как база данных SQL Azure или экземпляр SQL Server.
В следующей таблице рекомендуется использовать средства для приема, анализа, визуализации и скачивания данных. Используйте ссылки в этой таблице, чтобы найти рекомендации по настройке и использованию каждого средства.
| Цель | Руководство по инструментам и их использованию |
|---|---|
| Прием разовых данных | Портал Azure, Azure PowerShell, Azure CLI, REST, Обозреватель службы хранилища Azure, Apache DistCp, AzCopy |
| Прием реляционных данных | Фабрика данных Azure |
| Прием журналов веб-сервера | Azure PowerShell, Azure CLI, REST, Пакеты SDK Azure (.NET, Java, Python и Node.js), Фабрика данных Azure |
| Загрузка данных из кластеров HDInsight | Фабрика данных Azure, Apache DistCp, AzCopy |
| Прием данных из кластеров Hadoop | Фабрика данных Azure, Apache DistCp, миграция WANdisco LiveData для Azure, Azure Data Box |
| Обработка больших наборов данных (несколько терабайтов) | Azure ExpressRoute |
| Обработка и анализ данных | Azure Synapse Analytics, Azure HDInsight, Databricks |
| Визуализация данных | Ускорение запросов Power BI, Azure Data Lake Storage |
| Скачивание данных | Портал Azure, PowerShell, Azure CLI, REST, Пакеты SDK Azure (.NET, Java, Python и Node.js), Обозреватель службы хранилища Azure, AzCopy, Фабрика данных Azure, Apache DistCp |
Замечание
Эта таблица не отражает полный список служб Azure, поддерживающих Data Lake Storage. Чтобы просмотреть список поддерживаемых служб Azure, их уровень поддержки, см . в службах Azure, поддерживающих Azure Data Lake Storage.
Мониторинг телеметрии
Мониторинг использования и производительности является важной частью эксплуатации службы. Примеры включают частые операции, операции с высокой задержкой или операции, которые вызывают ограничение на стороне службы.
Все данные телеметрии для учетной записи хранения доступны через журналы службы хранилища Azure в Azure Monitor. Эта функция интегрирует учетную запись хранения с Log Analytics и Центрами событий, а также позволяет архивировать журналы в другую учетную запись хранения. Полный список метрик и журналов ресурсов и их связанной схемы см. в справочнике по данным мониторинга службы хранилища Azure.
Место хранения журналов зависит от того, как вы планируете получить к ним доступ. Например, если вы хотите получить доступ к журналам практически в реальном времени и иметь возможность сопоставлять события в журналах с другими метриками из Azure Monitor, вы можете хранить журналы в рабочей области Log Analytics. Затем запросите журналы с помощью KQL и авторских запросов, перечисляющих таблицу StorageBlobLogs в рабочей области.
Если вы хотите хранить журналы как для запроса в режиме реального времени, так и для долгосрочного хранения, можно настроить параметры диагностики для отправки журналов как в рабочую область Log Analytics, так и в учетную запись хранения.
Если вы хотите получить доступ к журналам через другой обработчик запросов, например Splunk, можно настроить параметры диагностики для отправки журналов в концентратор событий и приема журналов из концентратора событий в выбранное место назначения.
Журналы службы хранилища Azure в Azure Monitor можно включить с помощью портала Azure, PowerShell, Azure CLI и шаблонов Azure Resource Manager. Для масштабируемых развертываний политика Azure может использоваться с полной поддержкой задач исправления. Дополнительные сведения см. в разделе ciphertxt/AzureStoragePolicy.