Примечание.
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
В этой статье описывается, как мониторить компьютеры, реплицированные с помощью Azure Site Recovery, используя журналы Azure Monitor и Log Analytics.
Журналы Azure Monitor предоставляют платформу данных журнала, которая собирает журналы действий и журналов ресурсов, а также другие данные мониторинга. В журналах Azure Monitor вы используете Log Analytics для записи и тестирования запросов журналов и интерактивного анализа данных журнала. Вы можете визуализировать и запрашивать результаты журнала запросов и настраивать оповещения для выполнения действий на основе данных мониторинга.
Для Site Recovery используйте журналы Azure Monitor для выполнения следующих действий:
- Наблюдение за работоспособностью и состоянием Site Recovery. Например, можно отслеживать работоспособность репликации, состояние тестовой отработки отказа, события Site Recovery, целевые точки восстановления (RPO) для защищенных компьютеров и частоту изменения дисков и данных.
- Настройка оповещений для Site Recovery. Например, можно настроить оповещения о состоянии устройства, статусе тестового резервного переключения или о состоянии задания Site Recovery.
Поддержка журналов Azure Monitor в работе с Site Recovery для репликации между Azure и для репликации между виртуальной машиной VMware или физическим сервером и Azure.
Примечание.
Для получения журналов о скорости изменения данных и журналов о скорости отправки данных для VMware и физических компьютеров необходимо установить Microsoft Monitoring Agent на сервере обработки. Этот агент отправляет журналы реплицируемых компьютеров в рабочую область. Эта функция доступна только для версии агента мобильности 9.30 и выше.
Предварительные условия
Вам потребуется следующее.
- По крайней мере один компьютер, защищенный в хранилище служб восстановления.
- Рабочая область Log Analytics для хранения журналов Site Recovery. Узнайте о настройке рабочей области.
- Базовые сведения о том, как писать, выполнять и анализировать запросы журналов в Log Analytics. Подробнее.
Ознакомьтесь с общими вопросами мониторинга перед началом работы.
Журналы событий, доступные для Azure Site Recovery
Azure Site Recovery предоставляет следующие специфичные для ресурсов и устаревшие таблицы. Каждое событие предоставляет подробные данные по определенному набору артефактов, связанных с восстановлением сайта.
Таблицы, относящиеся к ресурсам:
Устаревшие таблицы:
- События Azure Site Recovery
- Реплицированные элементы Azure Site Recovery
- Статистика репликации Azure Site Recovery
- Точки восстановления Azure Site Recovery
- Скорость загрузки данных репликации Azure Site Recovery
- Интенсивность изменения данных защищенного диска в Azure Site Recovery
- Детали реплицированного элемента в Azure Site Recovery
Настройка Site Recovery для отправки журналов
В хранилище щелкните Параметры диагностики>Добавить настройку диагностики.

В параметрах диагностики введите имя и установите флажок "Отправить в Log Analytics".
Выберите подписку Azure Monitor Logs и рабочую область Log Analytics.
Выберите Диагностика Azure в переключателе.
В списке журналов выберите все журналы с префиксом AzureSiteRecovery. Затем выберите OK.

Журналы Site Recovery начнут поступать в таблицу (AzureDiagnostics) в выбранной рабочей области.
Настройка Microsoft Monitoring Agent на сервере обработки процессов для отправки журналов о частоте изменения и скорости загрузки данных.
Вы можете записать сведения о скорости обработки данных и скорость передачи исходных данных для виртуальных машин VMware и физических компьютеров в локальной среде. Чтобы включить эту функцию, установите агент мониторинга Майкрософт на сервере обработки.
Перейдите в рабочую область Log Analytics и выберите Дополнительные параметры.
Выберите подключенные источники и выберите серверы Windows.
Скачайте агент Windows (64-разрядную версию) на сервере обработки.
Завершите установку агента, указав полученный идентификатор и ключ рабочей области.
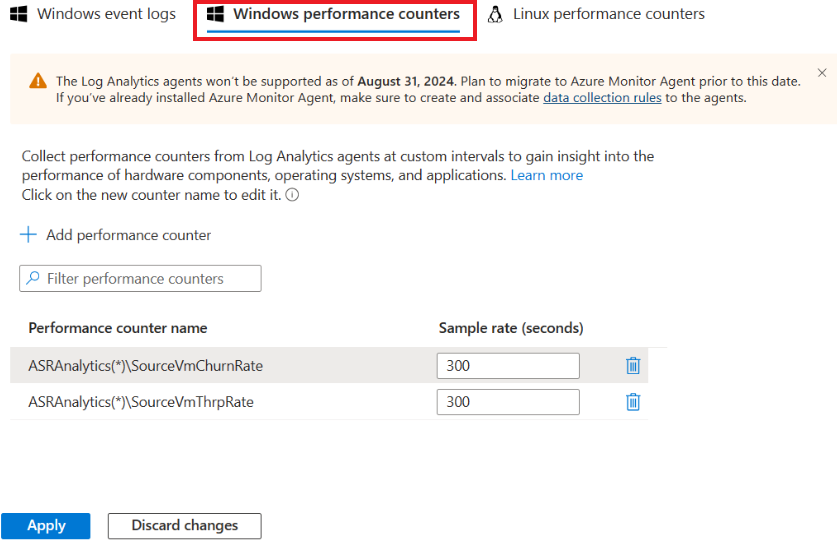
После завершения установки перейдите в рабочую область Log Analytics и выберите управление устаревшими агентами. Перейдите на страницу Данные и выберите Счетчики производительности Windows.
Выберите "+", чтобы добавить следующие два счетчика с интервалом в 300 секунд:
- ASRAnalytics(*)\SourceVmChurnRate
- ASRAnalytics(*)\SourceVmThrpRate
Данные о показателе оттока и скорости загрузки начинают поступать в рабочую область.
В настоящее время следующие счетчики Site Recovery недоступны для поиска.
- ASRAnalytics(*)\SourceVmChurnRate
- ASRAnalytics(*)\SourceVmThrpRate
Однако их можно добавить, вставив имена в полном объеме.
Примечание.
В настоящее время вы не можете искать эти счетчики. Однако их можно добавить, скопировав и вставив их полные имена.
- SourceVmThrpRate показывает скорость пропускной способности сети в источнике.
- SourceVmChurnRate показывает частоту изменения данных на диске на исходной виртуальной машине.
Выполнение запросов журналов — примеры
Данные из журналов извлекаются с помощью запросов журналов, написанных на языке запросов Kusto. В этом разделе приводится несколько примеров распространенных запросов, которые можно использовать для мониторинга Site Recovery.
Примечание.
В некоторых примерах используется replicationProviderName_s со значением A2A. Это значение извлекает виртуальные машины Azure, которые реплицируются в дополнительный регион Azure с помощью Site Recovery. В этих примерах можно заменить A2Aна InMageRcm , если вы хотите получить локальные виртуальные машины VMware или физические серверы, которые реплицируются в Azure с помощью Site Recovery.
Выполнение запроса о работоспособности репликации
Этот запрос создает круговую диаграмму для текущей работоспособности репликации всех защищенных виртуальных машин Azure. Диаграмма разбивает состояние на три категории: "Нормальное", "Предупреждение" или "Критическое".
AzureDiagnostics
| where replicationProviderName_s == "A2A"
| where isnotempty(name_s) and isnotnull(name_s)
| summarize hint.strategy=partitioned arg_max(TimeGenerated, *) by name_s
| project name_s , replicationHealth_s
| summarize count() by replicationHealth_s
| render piechart
Выполнение запроса о версии службы "Мобильность"
Этот запрос создает круговую диаграмму для виртуальных машин Azure, реплицируемых с помощью Site Recovery. Разбивка на диаграмме показывает виртуальные машины по версиям агента Mobility, который установлен на них.
AzureDiagnostics
| where replicationProviderName_s == "A2A"
| where isnotempty(name_s) and isnotnull(name_s)
| summarize hint.strategy=partitioned arg_max(TimeGenerated, *) by name_s
| project name_s , agentVersion_s
| summarize count() by agentVersion_s
| render piechart
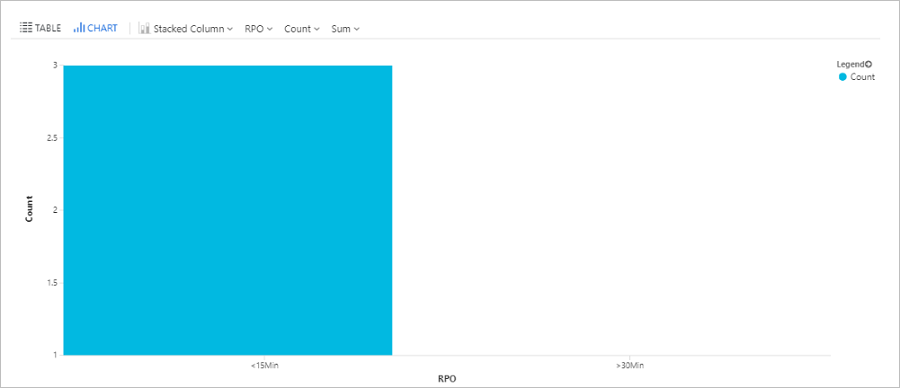
Выполнение запроса о времени RPO
Этот запрос создает линейчатую диаграмму виртуальных машин Azure, реплицированных с помощью Site Recovery. Диаграмма разбивает виртуальные машины по целевой точке восстановления (RPO): менее 15 минут, от 15 до 30 минут, более 30 минут.
AzureDiagnostics
| where replicationProviderName_s == "A2A"
| where isnotempty(name_s) and isnotnull(name_s)
| extend RPO = case(rpoInSeconds_d <= 900, "<15Min",
rpoInSeconds_d <= 1800, "15-30Min", ">30Min")
| summarize hint.strategy=partitioned arg_max(TimeGenerated, *) by name_s
| project name_s , RPO
| summarize Count = count() by RPO
| render barchart
Запрос заданий Site Recovery
Этот запрос извлекает все задания Site Recovery (для всех сценариев аварийного восстановления), которые активируются за последние 72 часа и их состояние завершения.
AzureDiagnostics
| where Category == "AzureSiteRecoveryJobs"
| where TimeGenerated >= ago(72h)
| project JobName = OperationName , VaultName = Resource , TargetName = affectedResourceName_s, State = ResultType
Запрос событий Site Recovery
Этот запрос извлекает все события Site Recovery для всех сценариев аварийного восстановления, которые система вызвала за последние 72 часа, а также их серьезность.
AzureDiagnostics
| where Category == "AzureSiteRecoveryEvents"
| where TimeGenerated >= ago(72h)
| project AffectedObject=affectedResourceName_s , VaultName = Resource, Description_s = healthErrors_s , Severity = Level
Выполнение запроса о состоянии тестовой отработки отказа (в виде круговой диаграммы)
Этот запрос отображает круговую диаграмму для тестового состояния отработки отказа виртуальных машин Azure, реплицированных с помощью Site Recovery.
AzureDiagnostics
| where replicationProviderName_s == "A2A"
| where isnotempty(name_s) and isnotnull(name_s)
| where isnotempty(failoverHealth_s) and isnotnull(failoverHealth_s)
| summarize hint.strategy=partitioned arg_max(TimeGenerated, *) by name_s
| project name_s , Resource, failoverHealth_s
| summarize count() by failoverHealth_s
| render piechart
Выполнение запроса о состоянии тестовой отработки отказа (с созданием таблицы)
Этот запрос отображает таблицу для тестового состояния отработки отказа виртуальных машин Azure, реплицированных с помощью Site Recovery.
AzureDiagnostics
| where replicationProviderName_s == "A2A"
| where isnotempty(name_s) and isnotnull(name_s)
| where isnotempty(failoverHealth_s) and isnotnull(failoverHealth_s)
| summarize hint.strategy=partitioned arg_max(TimeGenerated, *) by name_s
| project VirtualMachine = name_s , VaultName = Resource , TestFailoverStatus = failoverHealth_s
Выполнение запроса целевой точки восстановления (RPO) виртуальной машины
Этот запрос отображает график тренда, отслеживающий RPO конкретной виртуальной машины Azure (ContosoVM123) за последние 72 часа.
AzureDiagnostics
| where replicationProviderName_s == "A2A"
| where TimeGenerated > ago(72h)
| where isnotempty(name_s) and isnotnull(name_s)
| where name_s == "ContosoVM123"
| project TimeGenerated, name_s , RPO_in_seconds = rpoInSeconds_d
| render timechart

Запросить скорость изменения данных (изменчивость) и скорость загрузки для виртуальной машины Azure
Этот запрос отображает график тренда для определенной виртуальной машины Azure (ContosoVM123), которая представляет частоту изменения данных (запись байтов в секунду) и скорость отправки данных.
AzureDiagnostics
| where Category in ("AzureSiteRecoveryProtectedDiskDataChurn", "AzureSiteRecoveryReplicationDataUploadRate")
| extend CategoryS = case(Category contains "Churn", "DataChurn",
Category contains "Upload", "UploadRate", "none")
| extend InstanceWithType=strcat(CategoryS, "_", InstanceName_s)
| where TimeGenerated > ago(24h)
| where InstanceName_s startswith "ContosoVM123"
| project TimeGenerated , InstanceWithType , Churn_MBps = todouble(Value_s)/1048576
| render timechart

Выполнение запроса скорости изменения данных и скорости отправки данных для конкретной виртуальной машины VMware или физического компьютера
Примечание.
Убедитесь, что на сервере обработки настроен агент мониторинга для извлечения этих журналов. См. описание действий по настройке агента мониторинга.
Этот запрос формирует график тенденций для конкретного диска disk0 реплицированного элемента Win-9r7sfh9qlru, который представляет скорость изменения данных (байт записи в секунду) и скорость отправки данных. Имя диска можно найти в колонке "Диски " реплицированного элемента в хранилище служб восстановления. Имя экземпляра, используемое в запросе, — это DNS-имя компьютера, за которым следует _ и имя диска, как в этом примере.
Perf
| where ObjectName == "ASRAnalytics"
| where InstanceName contains "win-9r7sfh9qlru_disk0"
| where TimeGenerated >= ago(4h)
| project TimeGenerated ,CounterName, Churn_MBps = todouble(CounterValue)/5242880
| render timechart
Сервер обработки отправляет эти данные каждые пять минут в рабочую область Log Analytics. Эти точки данных представляют среднее значение, вычисляемое за 5 минут.
Запрос сводной информации об аварийном восстановлении (из Azure в Azure)
Этот запрос содержит сводную таблицу для виртуальных машин Azure, реплицированных в дополнительный регион Azure. В нем отображаются имя виртуальной машины, состояние репликации и защиты, RPO, состояние тестового отказа, версия агента мобильности, активные ошибки репликации и исходное местоположение.
AzureDiagnostics
| where replicationProviderName_s == "A2A"
| where isnotempty(name_s) and isnotnull(name_s)
| summarize hint.strategy=partitioned arg_max(TimeGenerated, *) by name_s
| project VirtualMachine = name_s , Vault = Resource , ReplicationHealth = replicationHealth_s, Status = protectionState_s, RPO_in_seconds = rpoInSeconds_d, TestFailoverStatus = failoverHealth_s, AgentVersion = agentVersion_s, ReplicationError = replicationHealthErrors_s, SourceLocation = primaryFabricName_s
Запрос сводной информации о восстановлении после сбоев (виртуальные машины VMware/физические серверы)
Этот запрос отображает сводную таблицу для виртуальных машин VMware и физических серверов, реплицированных в Azure. В нем показаны имя компьютера, состояние репликации и защиты, RPO, состояние функции тестирования отказа, версия агента мобильности, все активные ошибки репликации и соответствующий процессорный сервер.
AzureDiagnostics
| where replicationProviderName_s == "InMageRcm"
| where isnotempty(name_s) and isnotnull(name_s)
| summarize hint.strategy=partitioned arg_max(TimeGenerated, *) by name_s
| project VirtualMachine = name_s , Vault = Resource , ReplicationHealth = replicationHealth_s, Status = protectionState_s, RPO_in_seconds = rpoInSeconds_d, TestFailoverStatus = failoverHealth_s, AgentVersion = agentVersion_s, ReplicationError = replicationHealthErrors_s, ProcessServer = processServerName_g
Настройка оповещений — примеры
Вы можете настроить оповещения Site Recovery на основе данных Azure Monitor. Узнайте больше о настройке оповещений здесь.
Примечание.
В некоторых примерах используется replicationProviderName_s со значением A2A. Это значение задает оповещения для виртуальных машин Azure, которые реплицируются в дополнительный регион Azure. В этих примерах можно заменить A2A на InMageRcm , если вы хотите настроить оповещения для локальных виртуальных машин VMware или физических серверов, реплицированных в Azure.
Несколько машин в критическом состоянии
Настройте оповещение, если более 20 реплицированных виртуальных машин Azure попадают в критическое состояние.
AzureDiagnostics
| where replicationProviderName_s == "A2A"
| where replicationHealth_s == "Critical"
| where isnotempty(name_s) and isnotnull(name_s)
| summarize hint.strategy=partitioned arg_max(TimeGenerated, *) by name_s
| summarize count()
Для оповещения установите Пороговое значение на 20.
Одна машина в критическом состоянии
Настройте оповещение, если определенная реплицированная виртуальная машина Azure переходит в критическое состояние.
AzureDiagnostics
| where replicationProviderName_s == "A2A"
| where replicationHealth_s == "Critical"
| where name_s == "ContosoVM123"
| where isnotempty(name_s) and isnotnull(name_s)
| summarize hint.strategy=partitioned arg_max(TimeGenerated, *) by name_s
| summarize count()
Для оповещения установите Пороговое значение на 1.
Несколько машин превышают RPO
Настройте оповещение, если RPO для более чем 20 виртуальных машин Azure превышает 30 минут.
AzureDiagnostics
| where replicationProviderName_s == "A2A"
| where isnotempty(name_s) and isnotnull(name_s)
| where rpoInSeconds_d > 1800
| summarize hint.strategy=partitioned arg_max(TimeGenerated, *) by name_s
| project name_s , rpoInSeconds_d
| summarize count()
Для оповещения установите Пороговое значение на 20.
Превышение RPO для одной машины
Настройте оповещение, если RPO для одной виртуальной машины Azure превышает 30 минут.
AzureDiagnostics
| where replicationProviderName_s == "A2A"
| where isnotempty(name_s) and isnotnull(name_s)
| where name_s == "ContosoVM123"
| where rpoInSeconds_d > 1800
| summarize hint.strategy=partitioned arg_max(TimeGenerated, *) by name_s
| project name_s , rpoInSeconds_d
| summarize count()
Для оповещения задайте "Пороговое значение"1.
Тестирование отказоустойчивости для нескольких компьютеров превышает 90 дней
Настройте оповещение, если последняя успешная отработка отказа на более чем 20 виртуальных машинах была более 90 дней назад.
AzureDiagnostics
| where replicationProviderName_s == "A2A"
| where Category == "AzureSiteRecoveryReplicatedItems"
| where isnotempty(name_s) and isnotnull(name_s)
| where lastSuccessfulTestFailoverTime_t <= ago(90d)
| summarize hint.strategy=partitioned arg_max(TimeGenerated, *) by name_s
| summarize count()
Для оповещения задайте Пороговое значение на 20.
Тестовое переключение на резервную систему для одной машины продолжается более 90 дней.
Настройте оповещение, если успешное тестирование переключения на резервный канал для конкретной виртуальной машины не проводилось более 90 дней.
AzureDiagnostics
| where replicationProviderName_s == "A2A"
| where Category == "AzureSiteRecoveryReplicatedItems"
| where isnotempty(name_s) and isnotnull(name_s)
| where lastSuccessfulTestFailoverTime_t <= ago(90d)
| where name_s == "ContosoVM123"
| summarize hint.strategy=partitioned arg_max(TimeGenerated, *) by name_s
| summarize count()
Для оповещения установите значение "Пороговое значение" на 1.
Сбой задания восстановления Site Recovery
Настройте оповещение, если задание Site Recovery (в данном случае задание повторной защиты) завершается сбоем для любого сценария Site Recovery в течение последнего дня.
AzureDiagnostics
| where Category == "AzureSiteRecoveryJobs"
| where OperationName == "Reprotect"
| where ResultType == "Failed"
| summarize count()
Для оповещения задайте для параметра "Пороговое значение " значение 1 и "Период " значение 1440 минут, чтобы проверить сбои в последний день.
Следующие шаги
Узнайте о встроенном мониторинге Site Recovery.