Примечание.
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
В этой статье описывается, как настроить базовый кластер Pacemaker на Red Hat Enterprise Server (RHEL). Инструкции охватывают RHEL 7, RHEL 8 и RHEL 9.
Предварительные требования
Сначала ознакомьтесь со следующими заметками и статьями SAP:
Документация по высокой доступности RHEL
- Настройка кластеров высокой доступности и управление ими.
- Политики поддержки для кластеров RHEL с высоким уровнем доступности — sbd и fence_sbd.
- Политики поддержки кластеров высокого уровня доступности RHEL — fence_azure_arm.
- Известные ограничения программного эмулятора сторожевого таймера.
- Изучение компонентов RHEL высокого уровня доступности — sbd и fence_sbd.
- Руководство по проектированию кластеров высокой доступности RHEL — рекомендации по SBD.
- Рекомендации по внедрению RHEL 8 — высокий уровень доступности и кластеров
документация по RHEL Azure
- Политики поддержки кластеров высокой доступности RHEL — виртуальные машины в Microsoft Azure в качестве участников кластера.
- Руководство по проектированию кластеров высокой доступности RHEL — Виртуальные машины Microsoft Azure как члены кластера.
Документация по RHEL для предложений SAP
- Политики поддержки кластеров высокого уровня доступности RHEL — управление SAP S/4HANA в кластере.
- Настройка SAP S/4HANA ASCS/ERS с автономным сервером Enqueue Server 2 (ENSA2) в Pacemaker.
- Настройка системной репликации SAP HANA в кластере Pacemaker.
- решение Red Hat Enterprise Linux HA для SAP HANA Scale-Out и репликации системы.
Обзор
Внимание
Кластеры Pacemaker, охватывающие несколько виртуальных сетей(виртуальных сетей)/подсетей, не охватываются стандартными политиками поддержки.
Существуют два варианта, доступные в Azure для настройки ограждения в кластере Pacemaker для RHEL: агент ограждения Azure, который перезапускает неисправный узел через API Azure, или можно использовать устройство SBD.
Внимание
В Azure кластер высокого уровня доступности RHEL с ограждением на основе хранилища (fence_sbd) использует программную эмулированную сторожевую группу. Важно ознакомиться с известными ограничениями, связанными с программно-эмулируемым контрольным таймером и политиками поддержки для кластеров высокой доступности RHEL — sbd и fence_sbd при выборе SBD в качестве механизма ограждения.
Используйте устройство SBD
Примечание.
Механизм ограждения с SBD поддерживается в RHEL 8.8 и выше, а также в RHEL 9.0 и выше.
Настроить устройство SBD можно одним из двух способов:
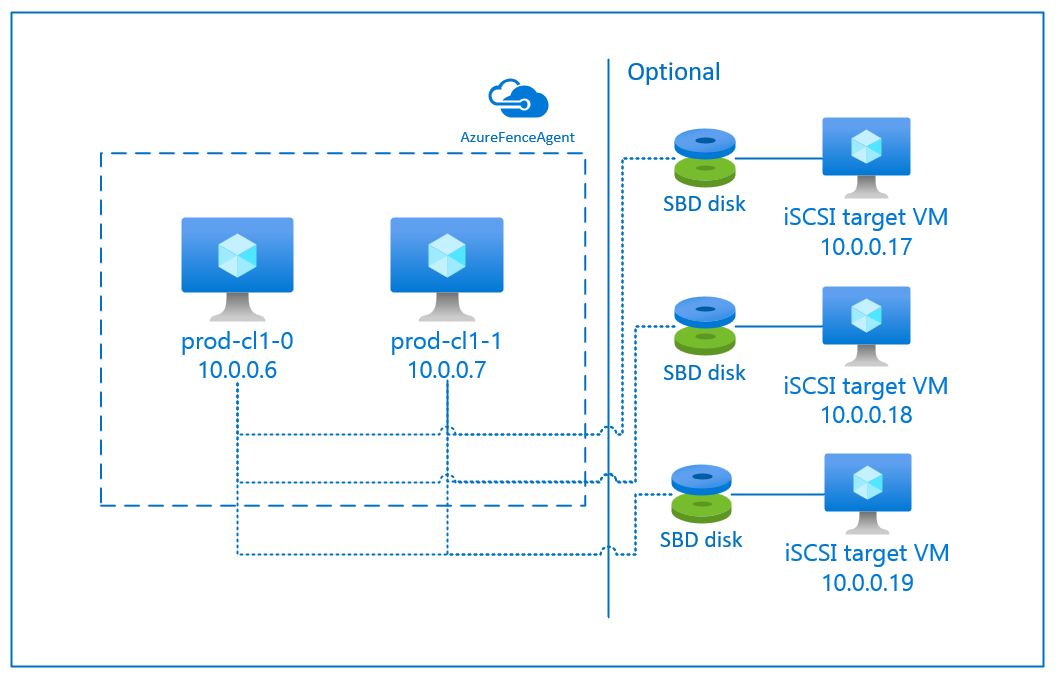
SBD с целевым сервером iSCSI
Для устройства SBD требуется по крайней мере одна дополнительная виртуальная машина, которая выступает в качестве целевого сервера iSCSI и предоставляет устройство SBD. Однако эти целевые серверы iSCSI могут совместно использоваться другими кластерами Pacemaker. Преимущество использования устройства SBD заключается в том, что если вы уже используете устройства SBD на месте, они не требуют никаких изменений в том, как вы управляете кластером pacemaker.
Вы можете использовать до трех устройств SBD для кластера pacemaker, чтобы иметь возможность отключить устройство SBD (например, во время обновления ОС целевого сервера iSCSI). Если вы хотите использовать несколько устройств SBD на pacemaker, обязательно разверните несколько целевых серверов iSCSI и подключите один SBD с каждого целевого сервера iSCSI. Рекомендуется использовать одно или три устройства SBD. Pacemaker не может автоматически обесточить узел кластера, если настроено только два устройства SBD и одно из них недоступно. Если вы хотите иметь возможность ограждать, когда один iSCSI-сервер недоступен, вам необходимо использовать три устройства SBD и, следовательно, три iSCSI-сервера. Это самая устойчивая конфигурация при использовании устройств SBD.
Внимание
При планировании развертывания и настройки узлов кластера Linux pacemaker и устройств SBD не разрешайте маршрутизацию между виртуальными машинами и виртуальными машинами, на которых размещаются устройства SBD, передаваться через любые другие устройства, такие как сетевое виртуальное устройство (NVA).
События обслуживания и другие проблемы с NVA могут негативно повлиять на стабильность и надежность общей конфигурации кластера. Для получения дополнительной информации см. правила маршрутизации, определенные пользователем.
SBD с общим диском Azure
Чтобы настроить устройство SBD, необходимо подключить по крайней мере один общий диск Azure ко всем виртуальным машинам, входящим в кластер Pacemaker. Преимущество использования устройства SBD с общим диском Azure заключается в том, что вам не нужно развертывать и настраивать дополнительные виртуальные машины.

Вот несколько важных соображений об устройствах SBD при настройке Azure Shared Disk:
- Общий диск Azure с SSD уровня "Премиум" поддерживается как устройство SBD.
- Устройства SBD, использующие общий диск Azure, поддерживаются в RHEL 8.8 и более поздних версиях.
- Устройства SBD, использующие Azure диск общего ресурса класса Premium, поддерживаются в локально избыточном хранилище (LRS) и зонально избыточном хранилище (ZRS).
- В зависимости от типа развертывания, выберите соответствующее резервное хранилище для совместно используемого диска Azure в качестве устройства SBD.
- Устройство SBD с помощью LRS для общего диска Azure класса "премиум" (skuName - Premium_LRS) поддерживается только для регионального развертывания, такого как набор доступности.
- Устройство SBD с помощью ZRS для общего диска Azure класса Premium (skuName - Premium_ZRS) рекомендуется использовать зональное развертывание, например зону доступности или масштабируемый набор с FD=1.
- В настоящее время ZRS для управляемых дисков доступен в регионах, перечисленных в документе о региональной доступности.
- Общий диск Azure, который вы используете для устройств SBD, не обязательно должен быть большим. Значение maxShares определяет, сколько узлов кластера может использовать общий диск. Например, можно использовать размеры дисков P1 или P2 для устройства SBD в двухузловом кластере, например SAP ASCS/ERS или SAP HANA масштабирование.
- Для масштабирования HANA с помощью репликации системы HANA (HSR) и Pacemaker можно использовать общий диск Azure для устройств SBD в кластерах, содержащих до пяти узлов на каждом сайте репликации из-за текущего ограничения maxShares.
- Не рекомендуется подключать общий диск SBD Azure в кластерах pacemaker.
- Если вы используете несколько Azure устройств SBD общего диска, проверьте ограничение на максимальное количество дисков данных, которые можно подключить к виртуальной машине.
- Дополнительные сведения об ограничениях для общих дисков Azure можно найти в разделе "Ограничения" документации по общим дискам Azure.
Использование агента ограничения доступа Azure
Вы можете настроить ограждение с помощью Azure-агента ограждения. Azure агент ограждения требует управляемых удостоверений для виртуальных машин кластера или удостоверения субъекта-службы или управляемого системного удостоверения (MSI), который управляет перезапуском неисправных узлов с помощью API-интерфейсов Azure. Azure агент ограждения не требует развертывания дополнительных виртуальных машин.
SBD с целевым сервером iSCSI
Чтобы использовать устройство SBD, применяющее сервер цели iSCSI для изоляции, следуйте инструкциям в следующих разделах.
Настройка сервера цели iSCSI
Сначала необходимо создать целевые виртуальные машины iSCSI. Вы можете совместно использовать целевые серверы iSCSI с несколькими кластерами pacemaker.
Разверните виртуальные машины, которые выполняются в поддерживаемой версии ОС RHEL, и подключитесь к ним через SSH. Виртуальные машины не должны иметь большого размера. Доступны такие размеры виртуальных машин, как Standard_E2s_v3 или Standard_D2s_v3. Убедитесь в том, что для диска ОС используется хранилище класса "Премиум".
Не обязательно использовать RHEL для SAP с сервисами высокой доступности и обновлений или образ ОС для SAP Apps для целевого сервера iSCSI. Вместо этого можно использовать стандартный образ ОС RHEL. Однако жизненный цикл поддержки зависит от разных выпусков продуктов ОС.
Выполните следующие команды на всех целевых виртуальных машинах iSCSI.
Обновление RHEL.
sudo yum -y updateПримечание.
После модернизации или обновления ОС может понадобиться перезагрузить узел.
Установите целевой пакет iSCSI.
sudo yum install targetcliЗапуск и настройка целевого объекта для запуска во время загрузки.
sudo systemctl start target sudo systemctl enable targetОткрытие порта
3260в брандмауэреsudo firewall-cmd --add-port=3260/tcp --permanent sudo firewall-cmd --add-port=3260/tcp
Создание устройства iSCSI на сервере цели iSCSI
Чтобы создать диски iSCSI для кластеров системы SAP, выполните следующие команды на каждой целевой виртуальной машине iSCSI. В примере показано создание SBD-устройств для нескольких кластеров, демонстрирующее использование одного целевого сервера iSCSI для нескольких кластеров. Устройство SBD настроено на диске ОС, поэтому убедитесь, что достаточно места.
- ascsnw1: представляет кластер ASCS/ERS NW1.
- dbhn1: представляет кластер базы данных HN1.
- sap-cl1 и sap-cl2: имена узлов кластера NW1 ASCS/ERS.
- hn1-db-0 и hn1-db-1: имена узлов кластера базы данных.
В следующих инструкциях измените команду с определенными именами узлов и идентификаторами SID по мере необходимости.
Создайте корневую папку для всех устройств SBD.
sudo mkdir /sbdСоздайте устройство SBD для серверов ASCS/ERS системы NW1.
sudo targetcli backstores/fileio create sbdascsnw1 /sbd/sbdascsnw1 50M write_back=false sudo targetcli iscsi/ create iqn.2006-04.ascsnw1.local:ascsnw1 sudo targetcli iscsi/iqn.2006-04.ascsnw1.local:ascsnw1/tpg1/luns/ create /backstores/fileio/sbdascsnw1 sudo targetcli iscsi/iqn.2006-04.ascsnw1.local:ascsnw1/tpg1/acls/ create iqn.2006-04.sap-cl1.local:sap-cl1 sudo targetcli iscsi/iqn.2006-04.ascsnw1.local:ascsnw1/tpg1/acls/ create iqn.2006-04.sap-cl2.local:sap-cl2Создайте устройство SBD для кластера базы данных системы HN1.
sudo targetcli backstores/fileio create sbddbhn1 /sbd/sbddbhn1 50M write_back=false sudo targetcli iscsi/ create iqn.2006-04.dbhn1.local:dbhn1 sudo targetcli iscsi/iqn.2006-04.dbhn1.local:dbhn1/tpg1/luns/ create /backstores/fileio/sbddbhn1 sudo targetcli iscsi/iqn.2006-04.dbhn1.local:dbhn1/tpg1/acls/ create iqn.2006-04.hn1-db-0.local:hn1-db-0 sudo targetcli iscsi/iqn.2006-04.dbhn1.local:dbhn1/tpg1/acls/ create iqn.2006-04.hn1-db-1.local:hn1-db-1Сохраните конфигурацию targetcli.
sudo targetcli saveconfigУбедитесь, что все настроено правильно
sudo targetcli ls o- / ......................................................................................................................... [...] o- backstores .............................................................................................................. [...] | o- block .................................................................................................. [Storage Objects: 0] | o- fileio ................................................................................................. [Storage Objects: 2] | | o- sbdascsnw1 ............................................................... [/sbd/sbdascsnw1 (50.0MiB) write-thru activated] | | | o- alua ................................................................................................... [ALUA Groups: 1] | | | o- default_tg_pt_gp ....................................................................... [ALUA state: Active/optimized] | | o- sbddbhn1 ................................................................... [/sbd/sbddbhn1 (50.0MiB) write-thru activated] | | o- alua ................................................................................................... [ALUA Groups: 1] | | o- default_tg_pt_gp ....................................................................... [ALUA state: Active/optimized] | o- pscsi .................................................................................................. [Storage Objects: 0] | o- ramdisk ................................................................................................ [Storage Objects: 0] o- iscsi ............................................................................................................ [Targets: 2] | o- iqn.2006-04.dbhn1.local:dbhn1 ..................................................................................... [TPGs: 1] | | o- tpg1 ............................................................................................... [no-gen-acls, no-auth] | | o- acls .......................................................................................................... [ACLs: 2] | | | o- iqn.2006-04.hn1-db-0.local:hn1-db-0 .................................................................. [Mapped LUNs: 1] | | | | o- mapped_lun0 ............................................................................... [lun0 fileio/sbdhdb (rw)] | | | o- iqn.2006-04.hn1-db-1.local:hn1-db-1 .................................................................. [Mapped LUNs: 1] | | | o- mapped_lun0 ............................................................................... [lun0 fileio/sbdhdb (rw)] | | o- luns .......................................................................................................... [LUNs: 1] | | | o- lun0 ............................................................. [fileio/sbddbhn1 (/sbd/sbddbhn1) (default_tg_pt_gp)] | | o- portals .................................................................................................... [Portals: 1] | | o- 0.0.0.0:3260 ..................................................................................................... [OK] | o- iqn.2006-04.ascsnw1.local:ascsnw1 ................................................................................. [TPGs: 1] | o- tpg1 ............................................................................................... [no-gen-acls, no-auth] | o- acls .......................................................................................................... [ACLs: 2] | | o- iqn.2006-04.sap-cl1.local:sap-cl1 .................................................................... [Mapped LUNs: 1] | | | o- mapped_lun0 ........................................................................... [lun0 fileio/sbdascsers (rw)] | | o- iqn.2006-04.sap-cl2.local:sap-cl2 .................................................................... [Mapped LUNs: 1] | | o- mapped_lun0 ........................................................................... [lun0 fileio/sbdascsers (rw)] | o- luns .......................................................................................................... [LUNs: 1] | | o- lun0 ......................................................... [fileio/sbdascsnw1 (/sbd/sbdascsnw1) (default_tg_pt_gp)] | o- portals .................................................................................................... [Portals: 1] | o- 0.0.0.0:3260 ..................................................................................................... [OK] o- loopback ......................................................................................................... [Targets: 0]
Настройка устройства SBD для iSCSI сервера назначения
[A]: применяется ко всем узлам. [1]: применяется только к узлу 1. [2]: применяется только к узлу 2.
На узлах кластера подключите и найдите устройство iSCSI, созданное в предыдущем разделе. Выполните следующие команды для узлов нового кластера, которые нужно создать.
[A] На всех узлах кластера установите или обновите утилиты инициатора iSCSI.
sudo yum install -y iscsi-initiator-utils[A] Установите пакеты кластера и SBD на всех узлах кластера.
sudo yum install -y pcs pacemaker sbd fence-agents-sbd[A] Включите службу iSCSI.
sudo systemctl enable iscsid iscsi[1] Измените имя инициатора на первом узле кластера.
sudo vi /etc/iscsi/initiatorname.iscsi # Change the content of the file to match the access control ists (ACLs) you used when you created the iSCSI device on the iSCSI target server (for example, for the ASCS/ERS servers) InitiatorName=iqn.2006-04.sap-cl1.local:sap-cl1[2] Измените имя инициатора на втором узле кластера.
sudo vi /etc/iscsi/initiatorname.iscsi # Change the content of the file to match the access control ists (ACLs) you used when you created the iSCSI device on the iSCSI target server (for example, for the ASCS/ERS servers) InitiatorName=iqn.2006-04.sap-cl2.local:sap-cl2[A] Перезапустите службу iSCSI, чтобы применить изменения.
sudo systemctl restart iscsid sudo systemctl restart iscsi[A] Подключитесь к устройствам iSCSI. В следующем примере 10.0.0.17 является IP-адресом сервера цели iSCSI, а 3260 — это порт по умолчанию. Имя целевого объекта
iqn.2006-04.ascsnw1.local:ascsnw1отображается при выполнении первой командыiscsiadm -m discovery.sudo iscsiadm -m discovery --type=st --portal=10.0.0.17:3260 sudo iscsiadm -m node -T iqn.2006-04.ascsnw1.local:ascsnw1 --login --portal=10.0.0.17:3260 sudo iscsiadm -m node -p 10.0.0.17:3260 -T iqn.2006-04.ascsnw1.local:ascsnw1 --op=update --name=node.startup --value=automatic[A] При использовании нескольких устройств SBD также подключитесь ко второму целевому серверу iSCSI.
sudo iscsiadm -m discovery --type=st --portal=10.0.0.18:3260 sudo iscsiadm -m node -T iqn.2006-04.ascsnw1.local:ascsnw1 --login --portal=10.0.0.18:3260 sudo iscsiadm -m node -p 10.0.0.18:3260 -T iqn.2006-04.ascsnw1.local:ascsnw1 --op=update --name=node.startup --value=automatic[A] При использовании нескольких устройств SBD также подключитесь к третьему целевому серверу iSCSI.
sudo iscsiadm -m discovery --type=st --portal=10.0.0.19:3260 sudo iscsiadm -m node -T iqn.2006-04.ascsnw1.local:ascsnw1 --login --portal=10.0.0.19:3260 sudo iscsiadm -m node -p 10.0.0.19:3260 -T iqn.2006-04.ascsnw1.local:ascsnw1 --op=update --name=node.startup --value=automatic[A] Убедитесь, что устройства iSCSI доступны и запишите имя устройства. В следующем примере обнаруживаются три устройства iSCSI, подключая узел к трем целевым серверам iSCSI.
lsscsi [0:0:0:0] disk Msft Virtual Disk 1.0 /dev/sde [1:0:0:0] disk Msft Virtual Disk 1.0 /dev/sda [1:0:0:1] disk Msft Virtual Disk 1.0 /dev/sdb [1:0:0:2] disk Msft Virtual Disk 1.0 /dev/sdc [1:0:0:3] disk Msft Virtual Disk 1.0 /dev/sdd [2:0:0:0] disk LIO-ORG sbdascsnw1 4.0 /dev/sdf [3:0:0:0] disk LIO-ORG sbdascsnw1 4.0 /dev/sdh [4:0:0:0] disk LIO-ORG sbdascsnw1 4.0 /dev/sdg[A] Получите идентификаторы устройств iSCSI.
ls -l /dev/disk/by-id/scsi-* | grep -i sdf # lrwxrwxrwx 1 root root 9 Jul 15 20:21 /dev/disk/by-id/scsi-1LIO-ORG_sbdhdb:85d254ed-78e2-4ec4-8b0d-ecac2843e086 -> ../../sdf # lrwxrwxrwx 1 root root 9 Jul 15 20:21 /dev/disk/by-id/scsi-3600140585d254ed78e24ec48b0decac2 -> ../../sdf # lrwxrwxrwx 1 root root 9 Jul 15 20:21 /dev/disk/by-id/scsi-SLIO-ORG_sbdhdb_85d254ed-78e2-4ec4-8b0d-ecac2843e086 -> ../../sdf ls -l /dev/disk/by-id/scsi-* | grep -i sdh # lrwxrwxrwx 1 root root 9 Jul 15 20:21 /dev/disk/by-id/scsi-1LIO-ORG_sbdhdb:87122bfc-8a0b-4006-b538-d0a6d6821f04 -> ../../sdh # lrwxrwxrwx 1 root root 9 Jul 15 20:21 /dev/disk/by-id/scsi-3600140587122bfc8a0b4006b538d0a6d -> ../../sdh # lrwxrwxrwx 1 root root 9 Jul 15 20:21 /dev/disk/by-id/scsi-SLIO-ORG_sbdhdb_87122bfc-8a0b-4006-b538-d0a6d6821f04 -> ../../sdh ls -l /dev/disk/by-id/scsi-* | grep -i sdg # lrwxrwxrwx 1 root root 9 Jul 15 20:21 /dev/disk/by-id/scsi-1LIO-ORG_sbdhdb:d2ddc548-060c-49e7-bb79-2bb653f0f34a -> ../../sdg # lrwxrwxrwx 1 root root 9 Jul 15 20:21 /dev/disk/by-id/scsi-36001405d2ddc548060c49e7bb792bb65 -> ../../sdg # lrwxrwxrwx 1 root root 9 Jul 15 20:21 /dev/disk/by-id/scsi-SLIO-ORG_sbdhdb_d2ddc548-060c-49e7-bb79-2bb653f0f34a -> ../../sdgКоманда перечисляет три идентификатора устройства для каждого устройства SBD. Мы рекомендуем использовать идентификатор, начинающийся со scsi-3. В приведенном примере идентификаторы следующие:
- /dev/disk/by-id/scsi-3600140585d254ed78e24ec48b0decac2
- /dev/disk/by-id/scsi-360014058712bfc8a0b4006b538d0a6d
- /dev/disk/by-id/scsi-36001405d2ddc548060c49e7bb792bb65
[1] Создайте устройство SBD.
Используйте идентификаторы устройств iSCSI, чтобы создать устройства SBD на первом узле кластера.
sudo sbd -d /dev/disk/by-id/scsi-3600140585d254ed78e24ec48b0decac2 -1 60 -4 120 createЕсли вы хотите использовать несколько устройств, создайте второе и третье устройства SBD.
sudo sbd -d /dev/disk/by-id/scsi-3600140587122bfc8a0b4006b538d0a6d -1 60 -4 120 create sudo sbd -d /dev/disk/by-id/scsi-36001405d2ddc548060c49e7bb792bb65 -1 60 -4 120 create
[A] Адаптация конфигурации SBD
Откройте файл конфигурации SBD.
sudo vi /etc/sysconfig/sbdИзмените свойство устройства SBD, включите интеграцию с Pacemaker и измените режим запуска SBD.
[...] SBD_DEVICE="/dev/disk/by-id/scsi-3600140585d254ed78e24ec48b0decac2;/dev/disk/by-id/scsi-3600140587122bfc8a0b4006b538d0a6d;/dev/disk/by-id/scsi-36001405d2ddc548060c49e7bb792bb65" [...] SBD_PACEMAKER=yes [...] SBD_STARTMODE=always [...] # # In some cases, a longer delay than the default "msgwait" seconds is needed. So, set a specific delay value, in seconds. See, `man sbd` for more information. SBD_DELAY_START=186 [...]
[A] Выполните следующую команду, чтобы загрузить
softdogмодуль.modprobe softdog[A] Выполните следующую команду, чтобы убедиться, что
softdogавтоматически загружается после перезагрузки узла.echo softdog > /etc/modules-load.d/watchdog.conf systemctl restart systemd-modules-load[A] Если
SBD_DELAY_STARTзадано значение, оно задерживает запуск службы SBD при загрузке. ЕслиTimeoutSecслужбы SBD в systemd остается по умолчанию (90 секунд), служба может превысить время ожидания до начала, поэтомуTimeoutSecнеобходимо увеличить до значения большеSBD_DELAY_START.sudo mkdir /etc/systemd/system/sbd.service.d echo -e "[Service]\nTimeoutSec=223" | sudo tee /etc/systemd/system/sbd.service.d/sbd_delay_start.conf sudo systemctl daemon-reload systemctl show sbd | grep -i timeout # TimeoutStartUSec=3min 43s # TimeoutStopUSec=3min 43s # TimeoutAbortUSec=3min 43s
SBD с общим диском Azure
Этот раздел применяется только в том случае, если вы хотите использовать устройство SBD с общим диском Azure.
Настройка общего диска Azure с помощью PowerShell
Чтобы создать и подключить Azure общий диск с PowerShell, выполните следующую инструкцию. Если вы хотите развернуть ресурсы с помощью Azure CLI или портала Azure, вы также можете обратиться к развертыванию диска ZRS.
$ResourceGroup = "MyResourceGroup"
$Location = "MyAzureRegion"
$DiskSizeInGB = 4
$DiskName = "SBD-disk1"
$ShareNodes = 2
$LRSSkuName = "Premium_LRS"
$ZRSSkuName = "Premium_ZRS"
$vmNames = @("prod-cl1-0", "prod-cl1-1") # VMs to attach the disk
# ZRS Azure shared disk: Configure an Azure shared disk with ZRS for a premium shared disk
$zrsDiskConfig = New-AzDiskConfig -Location $Location -SkuName $ZRSSkuName -CreateOption Empty -DiskSizeGB $DiskSizeInGB -MaxSharesCount $ShareNodes
$zrsDataDisk = New-AzDisk -ResourceGroupName $ResourceGroup -DiskName $DiskName -Disk $zrsDiskConfig
# Attach ZRS disk to cluster VMs
foreach ($vmName in $vmNames) {
$vm = Get-AzVM -ResourceGroupName $resourceGroup -Name $vmName
Add-AzVMDataDisk -VM $vm -Name $diskName -CreateOption Attach -ManagedDiskId $zrsDataDisk.Id -Lun 0
Update-AzVM -VM $vm -ResourceGroupName $resourceGroup -Verbose
}
# LRS Azure shared disk: Configure an Azure shared disk with LRS for a premium shared disk
$lrsDiskConfig = New-AzDiskConfig -Location $Location -SkuName $LRSSkuName -CreateOption Empty -DiskSizeGB $DiskSizeInGB -MaxSharesCount $ShareNodes
$lrsDataDisk = New-AzDisk -ResourceGroupName $ResourceGroup -DiskName $DiskName -Disk $lrsDiskConfig
# Attach LRS disk to cluster VMs
foreach ($vmName in $vmNames) {
$vm = Get-AzVM -ResourceGroupName $resourceGroup -Name $vmName
Add-AzVMDataDisk -VM $vm -Name $diskName -CreateOption Attach -ManagedDiskId $lrsDataDisk.Id -Lun 0
Update-AzVM -VM $vm -ResourceGroupName $resourceGroup -Verbose
}
Настройка устройства SBD с общим диском Azure
[A] Установите пакеты кластера и SBD на всех узлах кластера.
sudo yum install -y pcs pacemaker sbd fence-agents-sbd[A] Убедитесь, что подключенный диск доступен.
lsblk # NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT # sda 8:0 0 4G 0 disk # sdb 8:16 0 64G 0 disk # ├─sdb1 8:17 0 500M 0 part /boot # ├─sdb2 8:18 0 63G 0 part # │ ├─rootvg-tmplv 253:0 0 2G 0 lvm /tmp # │ ├─rootvg-usrlv 253:1 0 10G 0 lvm /usr # │ ├─rootvg-homelv 253:2 0 1G 0 lvm /home # │ ├─rootvg-varlv 253:3 0 8G 0 lvm /var # │ └─rootvg-rootlv 253:4 0 2G 0 lvm / # ├─sdb14 8:30 0 4M 0 part # └─sdb15 8:31 0 495M 0 part /boot/efi # sr0 11:0 1 1024M 0 rom lsscsi # [0:0:0:0] disk Msft Virtual Disk 1.0 /dev/sdb # [0:0:0:2] cd/dvd Msft Virtual DVD-ROM 1.0 /dev/sr0 # [1:0:0:0] disk Msft Virtual Disk 1.0 /dev/sda # [1:0:0:1] disk Msft Virtual Disk 1.0 /dev/sdc[A] Получите идентификатор устройства подключенного общего диска.
ls -l /dev/disk/by-id/scsi-* | grep -i sda # lrwxrwxrwx 1 root root 9 Jul 15 22:24 /dev/disk/by-id/scsi-14d534654202020200792c2f5cc7ef14b8a7355cb3cef0107 -> ../../sda # lrwxrwxrwx 1 root root 9 Jul 15 22:24 /dev/disk/by-id/scsi-3600224800792c2f5cc7e55cb3cef0107 -> ../../sdaИдентификатор устройства для списка команд для подключенного общего диска. Мы рекомендуем использовать идентификатор, начинающийся со scsi-3. В этом примере идентификатор : /dev/disk/by-id/scsi-3600224800792c2f5cc7e55cb3cef0107.
[1] Создайте устройство SBD.
# Use the device ID from step 3 to create the new SBD device on the first cluster node sudo sbd -d /dev/disk/by-id/scsi-3600224800792c2f5cc7e55cb3cef0107 -1 60 -4 120 create[A] Адаптация конфигурации SBD
Откройте файл конфигурации SBD.
sudo vi /etc/sysconfig/sbdИзмените свойство устройства SBD, включите интеграцию Pacemaker, измените режим запуска SBD и измените значение SBD_DELAY_START.
[...] SBD_DEVICE="/dev/disk/by-id/scsi-3600224800792c2f5cc7e55cb3cef0107" [...] SBD_PACEMAKER=yes [...] SBD_STARTMODE=always [...] # In some cases, a longer delay than the default "msgwait" seconds is needed. So, set a specific delay value, in seconds. See, `man sbd` for more information. SBD_DELAY_START=186 [...]
[A] Выполните следующую команду, чтобы загрузить
softdogмодуль.modprobe softdog[A] Выполните следующую команду, чтобы убедиться, что
softdogавтоматически загружается после перезагрузки узла.echo softdog > /etc/modules-load.d/watchdog.conf systemctl restart systemd-modules-load[A] Если
SBD_DELAY_STARTзадано значение, оно задерживает запуск службы SBD при загрузке. ЕслиTimeoutSecслужбы SBD в systemd остается по умолчанию (90 секунд), служба может превысить время ожидания до начала, поэтомуTimeoutSecнеобходимо увеличить до значения большеSBD_DELAY_START.sudo mkdir /etc/systemd/system/sbd.service.d echo -e "[Service]\nTimeoutSec=223" | sudo tee /etc/systemd/system/sbd.service.d/sbd_delay_start.conf sudo systemctl daemon-reload systemctl show sbd | grep -i timeout # TimeoutStartUSec=3min 43s # TimeoutStopUSec=3min 43s # TimeoutAbortUSec=3min 43s
Конфигурация агента защиты Azure
Устройство ограждения использует управляемую идентичность Azure или служебный принципал для авторизации в Azure. В зависимости от метода управления удостоверениями следуйте соответствующим процедурам.
Настройка управления удостоверениями
Используйте управляемое удостоверение или служебный принципал.
Чтобы создать управляемое удостоверение (MSI), создайте назначаемое системой управляемое удостоверение для каждой виртуальной машины в кластере. Если управляемое удостоверение, назначаемое системой, уже существует, оно будет использоваться. Не используйте назначаемые пользователем управляемые удостоверения с Pacemaker в настоящее время. На RHEL 7.9, а также RHEL 8.x, RHEL 9.x и RHEL 10.x поддерживается устройство ограждения на основе управляемого удостоверения.
Создать пользовательскую роль для агента ограждения
Управляемое удостоверение и служебный принципал изначально не имеют разрешений на доступ к вашим ресурсам Azure. Необходимо предоставить управляемому удостоверению или служебному принципалу разрешения на запуск и остановку (выключение) всех виртуальных машин кластера. Если вы еще не создали пользовательскую роль, ее можно создать с помощью PowerShell или Azure CLI.
Используйте следующее содержимое для входного файла. Необходимо адаптировать содержимое к подпискам, т. е. заменить
xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxxиyyyyyyyy-yyyy-yyyy-yyyy-yyyyyyyyyyyyна идентификаторы ваших подписок. Если у вас есть только одна подписка, удалите вторую записьAssignableScopes.{ "Name": "Linux Fence Agent Role", "description": "Allows to power-off and start virtual machines", "assignableScopes": [ "/subscriptions/xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx", "/subscriptions/yyyyyyyy-yyyy-yyyy-yyyy-yyyyyyyyyyyy" ], "actions": [ "Microsoft.Compute/*/read", "Microsoft.Compute/virtualMachines/powerOff/action", "Microsoft.Compute/virtualMachines/start/action" ], "notActions": [], "dataActions": [], "notDataActions": [] }Назначение настраиваемой роли
Используйте управляемое удостоверение или служебный принципал.
Назначьте каждому управляемому удостоверению виртуальных машин кластера пользовательскую роль
Linux Fence Agent Role, созданную в последнем разделе. Каждое управляемое удостоверение виртуальной машины, назначаемое системой, требует назначения роли для каждого ресурса кластера виртуальных машин. Дополнительные сведения см. в статье Предоставление управляемой идентичности доступа к ресурсу с помощью портала Azure. Убедитесь, что назначение роли управляемого удостоверения каждой виртуальной машины включает все виртуальные машины кластера.Внимание
Помните, что назначение и удаление авторизации с управляемыми удостоверениями может быть отложено до тех пор, пока не будет эффективным.
Установка кластера
Различия в командах или конфигурации между RHEL 7 и RHEL 8/RHEL 9 отмечены в документе.
[A] Установите надстройку RHEL HA.
sudo yum install -y pcs pacemaker nmap-ncat[A] В RHEL 9.x установите агенты ресурсов для облачного развертывания.
sudo yum install -y resource-agents-cloud[A] Установите пакет fence-agents, если вы используете устройство ограждения на основе Azure fence agent.
sudo yum install -y fence-agents-azure-armВнимание
Мы рекомендуем использовать следующие версии агента ограждения Azure (или более поздние версии) для клиентов, которые хотят использовать управляемые удостоверения для ресурсов Azure вместо имен субъектов-представителей службы для агента ограждения.
- RHEL 8.4: fence-agents-4.2.1-54.el8.
- RHEL 8.2: fence-agents-4.2.1-41.el8_2.4
- RHEL 8.1: fence-agents-4.2.1-30.el8_1.4
- RHEL 7.9: fence-agents-4.2.1-41.el7_9.4.
Внимание
В RHEL 9 мы рекомендуем использовать следующие версии пакетов или более поздние, чтобы избежать проблем с агентом ограждения Azure.
- забор-агенты-4.10.0-20.el9_0.7
- fence-agent-common-4.10.0-20.el9_0.6
- ha-cloud-support-4.10.0-20.el9_0.6.x86_64.rpm
Проверьте версию агента ограждения Azure. При необходимости обновите его до минимальной требуемой версии или более поздней.
# Check the version of the Azure Fence Agent sudo yum info fence-agents-azure-armВнимание
Если необходимо обновить агент ограждения Azure, и вы используете настраиваемую роль, обязательно обновите её, чтобы включить действие powerOff. Для получения дополнительной информации см. Создание настраиваемой роли для агента ограждения.
[A] Настройте разрешение имен узлов.
Вы можете использовать DNS-сервер или изменить
/etc/hostsфайл на всех узлах. В этом примере показано, как использовать файл/etc/hosts. Замените IP-адрес и имя узла в следующих командах.Внимание
Если вы используете имена узлов в конфигурации кластера, важно иметь надежное разрешение имен узлов. Связь кластера дает сбой, если имена недоступны, что может привести к задержкам переключения кластера.
Преимущество использования
/etc/hostsзаключается в том, что кластер становится независимым от DNS, который также может быть одной точкой сбоев.sudo vi /etc/hostsВставьте следующие строки в
/etc/hosts. Измените IP-адрес и имя узла в соответствии с параметрами среды.# IP address of the first cluster node 10.0.0.6 prod-cl1-0 # IP address of the second cluster node 10.0.0.7 prod-cl1-1[A] Измените
haclusterпароль на тот же пароль.sudo passwd hacluster[A] Добавьте правила брандмауэра для Pacemaker.
Добавьте приведенные ниже правила брандмауэра для всех взаимодействий между узлами кластера.
sudo firewall-cmd --add-service=high-availability --permanent sudo firewall-cmd --add-service=high-availability[A] Включите базовые службы кластеров.
Чтобы включить службу Pacemaker и запустить ее, выполните приведенные ниже команды.
sudo systemctl start pcsd.service sudo systemctl enable pcsd.service[1] Создание кластера Pacemaker.
Чтобы выполнить проверку подлинности узлов и создать кластер, выполните приведенные ниже команды. Установите значение токена на 30000, чтобы позволить поддерживать память. Дополнительные сведения см. в этой статье для Linux.
Если вы создаете кластер на RHEL 7.x, используйте следующие команды:
sudo pcs cluster auth prod-cl1-0 prod-cl1-1 -u hacluster sudo pcs cluster setup --name nw1-azr prod-cl1-0 prod-cl1-1 --token 30000 sudo pcs cluster start --allЕсли вы создаете кластер на RHEL 8.x/RHEL 9.x/RHEL 10.x, используйте следующие команды:
sudo pcs host auth prod-cl1-0 prod-cl1-1 -u hacluster sudo pcs cluster setup nw1-azr prod-cl1-0 prod-cl1-1 totem token=30000 sudo pcs cluster start --allПроверьте состояние кластера, выполнив следующую команду:
# Run the following command until the status of both nodes is online sudo pcs status # Cluster name: nw1-azr # WARNING: no stonith devices and stonith-enabled is not false # Stack: corosync # Current DC: prod-cl1-1 (version 1.1.18-11.el7_5.3-2b07d5c5a9) - partition with quorum # Last updated: Fri Aug 17 09:18:24 2018 # Last change: Fri Aug 17 09:17:46 2018 by hacluster via crmd on prod-cl1-1 # # 2 nodes configured # 0 resources configured # # Online: [ prod-cl1-0 prod-cl1-1 ] # # No resources # # Daemon Status: # corosync: active/disabled # pacemaker: active/disabled # pcsd: active/enabled[A] Задайте ожидаемые голоса.
# Check the quorum votes pcs quorum status # If the quorum votes are not set to 2, execute the next command sudo pcs quorum expected-votes 2Совет
Если вы создаете кластер с несколькими узлами, то есть кластер с более чем двумя узлами, не устанавливайте для голосов значение 2.
[1] Разрешить одновременное выполнение барьерных действий.
sudo pcs property set concurrent-fencing=true
Создайте устройство ограждения в кластере Pacemaker
Совет
- Чтобы избежать гонок на защиту в кластере pacemaker с двумя узлами, можно настроить
priority-fencing-delayсвойство кластера. Это свойство вводит дополнительную задержку в изоляции узла, обладающего более высоким общим приоритетом ресурса при возникновении сценария расщеплённого мозга. Дополнительные сведения см. в статье "Может ли Pacemaker отключить узел кластера с наименьшим количеством активных ресурсов?" - Это свойство
priority-fencing-delayприменимо к Pacemaker версии 2.0.4-6.el8 или более поздней версии и в кластере с двумя узлами. Если вы настраиваетеpriority-fencing-delayсвойство кластера, вам не нужно задаватьpcmk_delay_max. Но если версия Pacemaker меньше 2.0.4-6.el8, необходимо задатьpcmk_delay_maxсвойство. - Инструкции по настройке свойства кластера
priority-fencing-delayсм. в соответствующих документах SAP ASCS/ERS и SAP HANA высокого уровня доступности.
На основе выбранного механизма ограждения следуйте инструкциям только из одного из следующих разделов: SBD как механизм ограждения или Azure как агент ограждения.
SBD в качестве устройства ограждения
[A] Включение службы SBD
sudo systemctl enable sbd[1] Для устройства SBD, настроенного на целевые узлы iSCSI или общий диск Azure, выполните следующие команды.
sudo pcs property set stonith-timeout=210 sudo pcs property set stonith-enabled=true # Replace the device IDs with your device ID. pcs stonith create sbd fence_sbd \ devices=/dev/disk/by-id/scsi-3600140585d254ed78e24ec48b0decac2,/dev/disk/by-id/scsi-3600140587122bfc8a0b4006b538d0a6d,/dev/disk/by-id/scsi-36001405d2ddc548060c49e7bb792bb65 \ op monitor interval=600 timeout=15[1] Перезапустите кластер
sudo pcs cluster stop --all # It would take time to start the cluster as "SBD_DELAY_START" is set to "yes" sudo pcs cluster start --allПримечание.
Если при запуске кластера Pacemaker возникает ошибка, указанная ниже, вы можете игнорировать это сообщение. Кроме того, можно запустить кластер с помощью команды
pcs cluster start --all --request-timeout 140.Ошибка: не удается запустить все узлы node1/node2: не удается подключиться к node1/node2, проверьте, работает ли pcsd там или попробуйте установить более высокое время ожидания с
--request-timeoutпараметром (время ожидания операции истекло после 60000 миллисекунда с 0 байтами, полученными)
Azure агент ограждения в качестве устройства защиты
[1] После назначения ролей обоим узлам кластера можно настроить устройства ограждения в кластере.
sudo pcs property set stonith-timeout=900 sudo pcs property set stonith-enabled=true[1] выполните соответствующую команду в зависимости от того, используете ли вы управляемую идентификацию или учетную запись службы для агента ограничения Azure.
Примечание.
При использовании Azure облака для государственных организаций необходимо указать параметр
cloud=при настройке агента ограждения. Например,cloud=usgovдля облака Azure правительства США. Дополнительные сведения о поддержке RedHat в облаке Azure государственных организаций см. в разделе Support Policies for RHEL High Availability Clusters — Microsoft Azure Virtual Machines as Cluster Members.Совет
Параметр
pcmk_host_mapтолько требуется в команде, если имена узлов RHEL и имена виртуальных машин Azure не совпадают. Задайте сопоставление в формате имя_узла:имя_виртуальной_машины. Для получения дополнительной информации см. какой формат следует использовать для указания сопоставлений узлов с устройствами ограждения в pcmk_host_map?Для RHEL 7.x используйте следующую команду, чтобы настроить устройство ограждения:
sudo pcs stonith create rsc_st_azure fence_azure_arm msi=true resourceGroup="resource group" \ subscriptionId="subscription id" pcmk_host_map="prod-cl1-0:prod-cl1-0-vm-name;prod-cl1-1:prod-cl1-1-vm-name" \ power_timeout=240 pcmk_reboot_timeout=900 pcmk_monitor_timeout=120 pcmk_monitor_retries=4 pcmk_action_limit=3 pcmk_delay_max=15 \ meta failure-timeout=120s \ op monitor interval=3600Для RHEL 8.x/9.x/10.x используйте следующую команду, чтобы настроить устройство забора:
# Run following command if you are setting up fence agent on (two-node cluster and pacemaker version greater than 2.0.4-6.el8) OR (HANA scale out) sudo pcs stonith create rsc_st_azure fence_azure_arm msi=true resourceGroup="resource group" \ subscriptionId="subscription id" pcmk_host_map="prod-cl1-0:prod-cl1-0-vm-name;prod-cl1-1:prod-cl1-1-vm-name" \ power_timeout=240 pcmk_reboot_timeout=900 pcmk_monitor_timeout=120 pcmk_monitor_retries=4 pcmk_action_limit=3 \ meta failure-timeout=120s \ op monitor interval=3600 # Run following command if you are setting up fence agent on (two-node cluster and pacemaker version less than 2.0.4-6.el8) sudo pcs stonith create rsc_st_azure fence_azure_arm msi=true resourceGroup="resource group" \ subscriptionId="subscription id" pcmk_host_map="prod-cl1-0:prod-cl1-0-vm-name;prod-cl1-1:prod-cl1-1-vm-name" \ power_timeout=240 pcmk_reboot_timeout=900 pcmk_monitor_timeout=120 pcmk_monitor_retries=4 pcmk_action_limit=3 pcmk_delay_max=15 \ meta failure-timeout=120s \ op monitor interval=3600
Если вы используете устройство ограждения на основе конфигурации субъекта-службы, прочитайте Change из субъекта-службы в MSI для кластеров Pacemaker с помощью Azure для ограждения и узнайте, как преобразовать в конфигурацию управляемого удостоверения.
Операции мониторинга и ограждения десериализованы. В результате, если существует более длительное выполнение операции мониторинга и одновременное событие изоляции, задержка в отработке отказа кластера отсутствует, так как операция мониторинга уже запущена.
Совет
Агент Azure Fence требует наличия исходящего подключения к общедоступным конечным точкам. Дополнительные сведения и возможные решения см. в разделе "Подключение к общедоступной конечной точке" для виртуальных машин с использованием стандартной подсистемы балансировки нагрузки.
Настройка Pacemaker для запланированных событий Azure
Azure предлагает запланированные события. Запланированные события предоставляются через службу метаданных и позволяют приложению подготовиться к таким событиям.
Агент ресурсов azure-events-az следит за запланированными событиями Azure. Если обнаружены события и агент ресурсов определяет, что доступен другой узел кластера, он устанавливает атрибут #health-azure-1000000 работоспособности узла.
Если этот специальный атрибут работоспособности кластера задан для узла, узел считается неработоспособным кластером, а все ресурсы переносятся с затронутого узла. Ограничение расположения гарантирует, что ресурсы с именем, начинающимся с "health-", исключены, так как агент должен выполняться в этом нездоровом состоянии. После того как узел кластера освобожден от работающих кластерных ресурсов, запланированное событие может выполнить своё действие, например перезапуск, без риска для работающих ресурсов.
Атрибут #heath-azure возвращается к 0 при запуске pacemaker после обработки всех событий, снова помечая узел как здоровый.
[A] Убедитесь, что пакет для
azure-events-azагента уже установлен и обновлен.RHEL 8.x: sudo dnf info resource-agents RHEL 9.x: sudo dnf info resource-agents-cloudМинимальные требования к версии:
- RHEL 8.4:
resource-agents-4.1.1-90.13 - RHEL 8.6:
resource-agents-4.9.0-16.9 - RHEL 8.8:
resource-agents-4.9.0-40.1 - RHEL 9.0:
resource-agents-cloud-4.10.0-9.6 - RHEL 9.2 и более поздней версии:
resource-agents-cloud-4.10.0-34.1
- RHEL 8.4:
[1] Настройте ресурсы в Pacemaker.
#Place the cluster in maintenance mode sudo pcs property set maintenance-mode=true[1] Установите стратегию и ограничение для кластера Pacemaker health-node.
sudo pcs property set node-health-strategy=custom # For RHEL 8.x/9.x sudo pcs constraint location 'regexp%!health-.*' \ rule score-attribute='#health-azure' \ defined '#uname' # For RHEL 10.x sudo pcs constraint location 'regexp%!health-.*' \ rule score-attribute='#health-azure' \ "defined #uname"Внимание
Не определяйте в кластере другие ресурсы, начинающиеся с
health-, кроме ресурсов, описанных в следующих шагах.[1] Задайте начальное значение атрибутов кластера. Запустите для каждого узла кластера и для сред с возможностью горизонтального масштабирования, включая управляющую виртуальную машину большинства.
sudo crm_attribute --node prod-cl1-0 --name '#health-azure' --update 0 sudo crm_attribute --node prod-cl1-1 --name '#health-azure' --update 0[1] Настройте ресурсы в Pacemaker. Убедитесь, что ресурсы начинаются с
health-azure.sudo pcs resource create health-azure-events \ ocf:heartbeat:azure-events-az \ meta failure-timeout=120s \ op monitor interval=10s timeout=240s \ op start timeout=10s start-delay=90s # For RHEL 8.x/9.x sudo pcs resource clone health-azure-events allow-unhealthy-nodes=true # For RHEL 10.x sudo pcs resource clone health-azure-events meta allow-unhealthy-nodes=trueВыведите кластер Pacemaker из режима обслуживания.
sudo pcs property set maintenance-mode=falseСнимите все ошибки во время включения и убедитесь, что
health-azure-eventsресурсы успешно запущены на всех узлах кластера.sudo pcs resource cleanupВыполнение первого запроса для запланированных событий может занять до двух минут. Тестирование Pacemaker с запланированными событиями может использовать действия перезагрузки или повторного развертывания для виртуальных машин кластера. Дополнительные сведения см. в разделе Запланированные события.
Необязательная конфигурация ограждения
Совет
Этот раздел применим только в том случае, если вы хотите настроить специальное устройство fence_kdump для ограждения.
Если вам нужно собрать диагностическую информацию на виртуальной машине, может быть полезно настроить другое средство ограждения на основе агентa fence_kdump. Агент fence_kdump может обнаружить, что узел перешёл в состояние аварийного восстановления с помощью kdump и может позволить службе завершить процесс до вызова других методов фенсинга. Обратите внимание, что fence_kdump не является заменой традиционных механизмов ограждения, таких как SBD или агент ограждения Azure, при использовании виртуальных машин Azure.
Внимание
Помните, что при настройке fence_kdump в качестве устройства ограждения первого уровня возникают задержки в операциях ограждения, а также задержки в переключении ресурсов приложения.
Если аварийный дамп успешно обнаружен, ограждение задерживается до завершения работы сервиса восстановления после аварии. Если неисправный узел недоступен или не отвечает, блокировка откладывается на время, зависящее от настроенного числа итераций и fence_kdump времени ожидания. Дополнительные сведения см. в разделе о настройке fence_kdump в кластере Red Hat Pacemaker.
Предлагаемое fence_kdump время ожидания может потребоваться адаптировать к конкретной среде.
Рекомендуем настраивать fence_kdump ограждение только в случае необходимости сбора диагностических данных в виртуальной машине и всегда в сочетании с традиционными методами ограждения, такими как SBD или агент ограждения Azure.
В следующих статьях Базы знаний Red Hat содержатся важные сведения о настройке fence_kdump ограждения:
- Узнайте , как настроить fence_kdump в кластере Red Hat Pacemaker?
- Узнайте , как настроить уровни ограждения и управлять ими в кластере RHEL с помощью Pacemaker.
- См. fence_kdump не удается из-за "превышения времени ожидания после X секунд" в кластере RHEL 6 или 7 HA с kexec-tools старее 2.0.14.
- Сведения об изменении времени ожидания по умолчанию см. в статье "Как настроить kdump для использования с надстройкой RHEL 6, 7, 8 HA?
- Сведения о снижении задержки отработки отказа при использовании
fence_kdump, см. в статье «Можно ли уменьшить ожидаемую задержку отработки отказа при добавлении конфигурации fence_kdump?».
Выполните следующие необязательные шаги, чтобы добавить fence_kdump в качестве конфигурации первого уровня fencing в дополнение к конфигурации агента Azure fencing.
[A] Убедитесь, что
kdumpон активен и настроен.systemctl is-active kdump # Expected result # active[A] Установите агент ограждения
fence_kdump.yum install fence-agents-kdump[1] Создайте
fence_kdumpустройство ограждения в кластере.pcs stonith create rsc_st_kdump fence_kdump pcmk_reboot_action="off" pcmk_host_list="prod-cl1-0 prod-cl1-1" timeout=30[1] Настройте уровни ограждения так, чтобы
fence_kdumpмеханизм ограждения активировался первым.pcs stonith create rsc_st_kdump fence_kdump pcmk_reboot_action="off" pcmk_host_list="prod-cl1-0 prod-cl1-1" pcs stonith level add 1 prod-cl1-0 rsc_st_kdump pcs stonith level add 1 prod-cl1-1 rsc_st_kdump # Replace <stonith-resource-name> to the resource name of the STONITH resource configured in your pacemaker cluster (example based on above configuration - sbd or rsc_st_azure) pcs stonith level add 2 prod-cl1-0 <stonith-resource-name> pcs stonith level add 2 prod-cl1-1 <stonith-resource-name> # Check the fencing level configuration pcs stonith level # Example output # Target: prod-cl1-0 # Level 1 - rsc_st_kdump # Level 2 - <stonith-resource-name> # Target: prod-cl1-1 # Level 1 - rsc_st_kdump # Level 2 - <stonith-resource-name>[A] Разрешить необходимые порты для
fence_kdump, проходящие через брандмауэр.firewall-cmd --add-port=7410/udp firewall-cmd --add-port=7410/udp --permanent[A] Выполните настройку в
fence_kdump_nodes/etc/kdump.conf, чтобы избежать сбоя с истечением времени ожидания у некоторых версийfence_kdumpkexec-tools. Дополнительные сведения см. в разделе fence_kdump завершается сбоем по истечении времени ожидания, если fence_kdump_nodes не указаны с помощью kexec-tools версии 2.0.15 или более поздней и fence_kdump завершается сбоем с "время ожидания после X секунд" в кластере высокой доступности RHEL 6 или 7 с версиями kexec-tools старше 2.0.14. Здесь представлена пример конфигурации для двухузлового кластера. После внесения изменений в/etc/kdump.conf, образ kdump должен быть создан повторно. Чтобы восстановить, перезапуститеkdump.vi /etc/kdump.conf # On node prod-cl1-0 make sure the following line is added fence_kdump_nodes prod-cl1-1 # On node prod-cl1-1 make sure the following line is added fence_kdump_nodes prod-cl1-0 # Restart the service on each node systemctl restart kdump[A] Убедитесь, что файл
initramfsизображения содержит файлыfence_kdumpиhosts. Дополнительные сведения см. в разделе о настройке fence_kdump в кластере Red Hat Pacemaker.lsinitrd /boot/initramfs-$(uname -r)kdump.img | egrep "fence|hosts" # Example output # -rw-r--r-- 1 root root 208 Jun 7 21:42 etc/hosts # -rwxr-xr-x 1 root root 15560 Jun 17 14:59 usr/libexec/fence_kdump_sendПроверьте конфигурацию, инициируя сбой узла. Дополнительные сведения см. в разделе о настройке fence_kdump в кластере Red Hat Pacemaker.
Внимание
Если кластер уже работает продуктивно, запланируйте тест соответствующим образом, так как сбой узла оказывает влияние на приложение.
echo c > /proc/sysrq-trigger
Следующие шаги
- См. Планирование и реализацию виртуальных машин Azure для SAP.
- См. сведения о развертывании Azure Virtual Machines для SAP.
- См. развертывание СУБД на виртуальных машинах Azure для SAP.
- Сведения о создании высокого уровня доступности и планировании аварийного восстановления SAP HANA на виртуальных машинах Azure см. в статье Доступность SAP HANA на Azure Virtual Machines.