Примечание.
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
Предупреждение
Разработка функций потока запросов закончилась 20 апреля 2026 г. Функция будет полностью прекращена 20 апреля 2027 г. В дату выхода на пенсию, Prompt Flow переходит в режим только для чтения. Существующие потоки будут продолжать работать до этой даты.
Рекомендуемое действие: Перенесите рабочие нагрузки Prompt Flow на Microsoft Agent Framework до 20 апреля 2027 г.
Потоки оценки — это особый тип потоков взаимодействия, который вычисляет метрики для оценки того, насколько хорошо выходные данные выполнения соответствуют определенным критериям и целям. Вы можете создавать или настраивать потоки оценки и метрики, адаптированные к задачам и целям, и использовать их для оценки других потоков запросов. В этой статье объясняется, что такое потоки оценки, как их разрабатывать и настраивать, а также как использовать их в пакетных запусках запросов для оценки эффективности потоков.
Общие сведения о потоках оценки
Поток запроса — это последовательность узлов, которые обрабатывают входные данные и создают выходные данные. Потоки оценки также используют входные данные и создают соответствующие выходные данные, которые обычно представляют собой оценки или метрики. Потоки оценки отличаются от стандартных потоков в их опыте разработки и использовании.
Потоки оценки обычно запускаются после тестируемого выполнения, получая его результаты и используя их для вычисления оценок и метрик. Метрики журналов потоков оценки фиксируются с помощью функции log_metric() пакета SDK для потока подсказок.
Выходные данные потока оценки — это результаты, которые измеряют производительность проверяемого потока. Потоки оценки могут иметь узел агрегирования, который вычисляет общую производительность потока, проверяемого в тестовом наборе данных.
В следующих разделах описывается определение входных и выходных данных в потоках оценки.
Входы
Потоки оценки вычисляют метрики или оценки для пакетных запусков, принимая выходные данные запуска, который они тестируют. Например, если тестируемый поток является потоком QnA, который создает ответ на основе вопроса, вы можете назвать входные данные оценки как answer. Если тестируемый поток является потоком классификации, классифицирующим текст в категорию, можно назвать пример ввода для оценки как category.
Возможно, вам потребуются другие данные в качестве эталонных. Например, если вы хотите вычислить точность потока классификации, необходимо указать category столбец набора данных в качестве эталонной правды. Если вы хотите вычислить точность потока QnA, необходимо указать столбец answer набора данных в качестве эталонного значения. Для вычисления метрик может потребоваться несколько других входных данных, таких как question и context в сценариях QnA или дополненной генерации (RAG).
Вы определяете входные данные потока оценки так же, как вы определяете входные данные стандартного потока. По умолчанию оценка использует тот же набор данных, что и тестируемый запуск. Если соответствующие метки или целевые эталонные значения находятся в другом наборе данных, вы можете легко переключиться на этот набор данных.
Описания входных данных
Чтобы описать входные данные, необходимые для вычисления метрик, можно добавить описания. Описания появляются при сопоставлении источников входных данных в пакетных отправках.
Чтобы добавить описания для каждого входного ввода, выберите "Показать описание " в разделе входных данных при разработке метода оценки, а затем введите описания.

Чтобы скрыть описания из входной формы, выберите "Скрыть описание".

Выходные данные и метрики
Выходные данные оценки — это результаты, которые показывают производительность проверяемого потока. Выходные данные обычно содержат метрики, такие как оценки, а также могут содержать текст по соображениям и предложениям.
Выходные оценки
Поток запроса обрабатывает одну строку данных одновременно и создает выходную запись. Потоки оценки также могут вычислять баллы для каждой строки данных, чтобы вы могли проверить, как поток работает на каждом отдельном элементе данных.
Оценки для каждого экземпляра данных можно записать в виде выходных данных потока оценки, указав их в выходном разделе потока оценки. Интерфейс разработки совпадает с определением стандартного вывода потока.

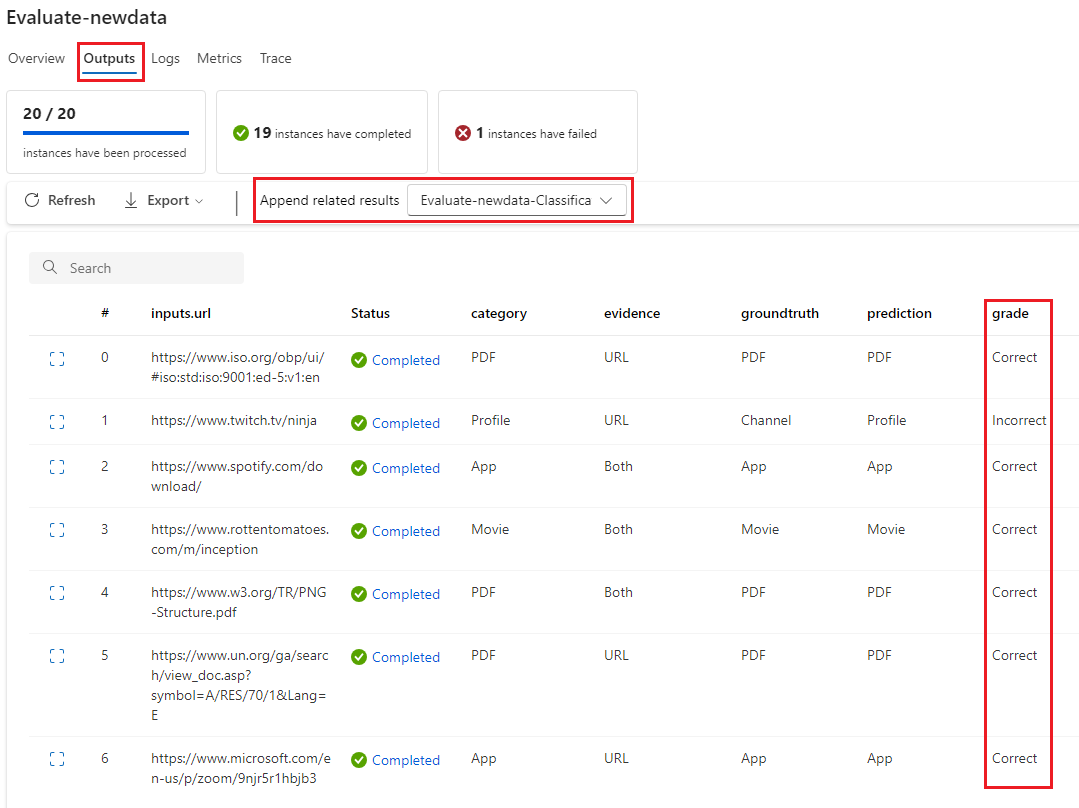
При выборе Просмотр выходных данных вы можете просмотреть индивидуальные результаты на вкладке Выходные данные, подобно тому, как вы проверяете данные стандартного выполнения пакета потока. Эти оценки уровня экземпляра можно добавить в выходные данные протестированного потока.
Ведение журнала агрегирования и метрик
Поток оценки также предоставляет общую оценку для выполнения. Чтобы отличить общие результаты от отдельных показателей выходных данных, эти общие значения производительности запуска называются метриками.
Чтобы вычислить общее значение оценки на основе отдельных показателей, выберите Aggregation на узле Python в потоке оценки, чтобы превратить его в узел reduce. Затем узел принимает входные данные в виде списка и обрабатывает их как пакет.

С помощью агрегирования можно вычислить и обработать все оценки каждого вывода потока и вычислить общий результат с помощью каждой оценки. Например, чтобы вычислить точность потока классификации, можно вычислить точность каждого результата оценки, а затем вычислить среднюю точность всех выходных данных оценки. Затем можно записать среднюю точность в виде метрики с помощью promptflow_sdk.log_metric(). Метрики должны быть числовыми, например float или int. Ведение журнала метрик типа строк не поддерживается.
Следующий фрагмент кода является примером вычисления общей точности путем усреднения оценки grades точности всех точек данных. Общая точность регистрируется как метрика с помощью promptflow_sdk.log_metric().
from typing import List
from promptflow import tool, log_metric
@tool
def calculate_accuracy(grades: List[str]): # Receive a list of grades from a previous node
# calculate accuracy
accuracy = round((grades.count("Correct") / len(grades)), 2)
log_metric("accuracy", accuracy)
return accuracy
Так как вы вызываете эту функцию в узле Python, ее не нужно назначать в другом месте, и вы можете просмотреть метрики позже. После использования этого метода оценки в пакетном запуске можно просмотреть метрику, показывающую общую производительность, выбрав метрики при просмотре выходных данных.

Разработка потока оценки
Чтобы разработать собственный поток оценки, на странице Студия машинного обучения Azure Prompt выберите Create. На странице "Создание потока " можно выполнить следующие действия:
Выберите "Создать " на карте потока оценки в разделе "Создать по типу". Этот выбор предоставляет шаблон для разработки нового метода оценки.
Выберите поток оценки в галерее "Исследование" и выберите один из доступных встроенных потоков. Выберите "Просмотр сведений" , чтобы получить сводку по каждому потоку. Выберите "Клонировать", чтобы открыть и настроить поток. Конструктор потоков помогает настроить поток для вашего сценария.

Вычисление показателей для каждой точки данных
Потоки оценки вычисляют оценки и метрики для потоков, выполняемых в наборах данных. Первым шагом в потоках оценки является вычисление показателей для каждого отдельного вывода данных.
Например, в встроенной процедуре оценки точности классификации grade, которая измеряет точность каждого выходного результата потока в его соответствующей истинной величине, вычисляется в узле grade Python.
Если вы используете шаблон потока оценки, вы вычисляете эту оценку в узле line_process Python. Вы также можете заменить узел python line_process большим узлом языковой модели (LLM), чтобы использовать LLM для вычисления оценки или использовать несколько узлов для выполнения вычисления.

Выходные данные этого узла указываются в качестве выходных данных потока оценки, которые указывают на то, что выходные данные — это оценки, вычисляемые для каждого примера данных. Вы также можете выводить причины для получения дополнительных сведений. Это тот же опыт, что и при определении выходных данных в стандартном потоке.
Вычислить и записать метрики
Следующим шагом в оценке является вычисление общих метрик для оценки выполнения. Вы вычисляете метрики в узле Python с выбранным параметром Aggregation. Этот узел принимает оценки из предыдущего узла вычислений и упорядочивает их в список, а затем вычисляет общие значения.
Если вы используете шаблон оценки, эта оценка вычисляется в агрегатном узле. В следующем фрагменте кода показан шаблон для узла агрегирования.
from typing import List
from promptflow import tool
@tool
def aggregate(processed_results: List[str]):
"""
This tool aggregates the processed result of all lines and log metric.
:param processed_results: List of the output of line_process node.
"""
# Add your aggregation logic here
aggregated_results = {}
# Log metric
# from promptflow import log_metric
# log_metric(key="<my-metric-name>", value=aggregated_results["<my-metric-name>"])
return aggregated_results
Вы можете использовать собственную логику агрегирования, например вычисление среднего показателя, медиана или стандартное отклонение.
Записывайте метрики с помощью функции promptflow.log_metric(). Вы можете записать несколько метрик в одном потоке оценки. Метрики должны быть числовыми (float или int).
Использование потоков оценки
После создания собственного потока оценки и метрик можно использовать поток для оценки производительности стандартного потока. Например, можно оценить поток QnA, чтобы проверить, как он выполняется в большом наборе данных.
В Студия машинного обучения Azure откройте поток, который требуется оценить. В верхней строке меню выберите "Оценить".

В мастере пакетное выполнение и оценка заполните основные настройки и настройки пакетного выполнения, чтобы загрузить набор данных для тестирования и настроить сопоставление входных данных. Дополнительные сведения см. в разделе "Отправка пакетного запуска" для оценки потока.
На шаге "Выбор оценки " можно выбрать одну или несколько настраиваемых вычислений или встроенных вычислений для выполнения. Кастомизированная оценка содержит потоки оценки, которые вы создали, клонировали или настроили. Потоки оценки, созданные другими пользователями, работающими над тем же проектом, не отображаются в этом разделе.

На экране настройки оценки укажите источники входных данных, необходимых для метода оценки. Например, столбец с эталонными данными может быть взят из набора данных. Если метод оценки не требует данных из набора данных, вам не нужно выбирать набор данных или ссылаться на столбцы набора данных в разделе сопоставления входных данных.
В разделе сопоставления входных данных оценки можно указать источники необходимых входных данных для оценки. Если источник данных находится из выходных данных запуска, задайте источник как
${run.outputs.[OutputName]}. Если данные из вашего тестового набора данных, установите источник как${data.[ColumnName]}. Здесь также отображаются все описания, заданные для входных данных. Дополнительные сведения см. в разделе "Отправка пакетного запуска" для оценки потока.
Важно
Если в потоке оценки есть узел LLM или требуется подключение для использования учетных данных или других ключей, необходимо ввести данные подключения в разделе "Подключение " этого экрана, чтобы использовать поток оценки.
Выберите "Просмотр и отправка" , а затем нажмите кнопку "Отправить ", чтобы запустить поток оценки.
После завершения процесса оценки можно просмотреть оценки уровня экземпляра, выбрав Просмотр пакетных запусков>Просмотр последних выходных данных пакетного выполнения в верхней части потока оценки. Выберите запуск оценки из списка добавления связанных результатов, чтобы увидеть оценку для каждой строки данных.