Примечание
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
Одна из самых больших проблем с текущими методами отладки моделей — использование статистических метрик для оценки моделей в наборе данных теста. Точность модели может не быть единообразной в подгруппах данных, и могут быть входные когорты, для которых модель часто завершается сбоем. Прямые последствия этих сбоев являются отсутствием надежности и безопасности, появлением проблем справедливости и потерей доверия в машинном обучении в целом.

Анализ ошибок переходит от метрик статистической точности. Он предоставляет прозрачное распределение ошибок разработчикам и позволяет им эффективно выявлять и диагностировать ошибки.
Компонент анализа ошибок панели мониторинга ответственного искусственного интеллекта предоставляет специалистам по машинному обучению более глубокое понимание распределения ошибок модели и помогает им быстро выявлять ошибочные когорты данных. Этот компонент определяет когорты данных с более высокой скоростью ошибок и общей частотой ошибок теста. Он вносит свой вклад в этап идентификации рабочего процесса жизненного цикла модели с помощью следующих действий:
- Дерево принятия решений, показывающее когорты с высоким уровнем ошибок.
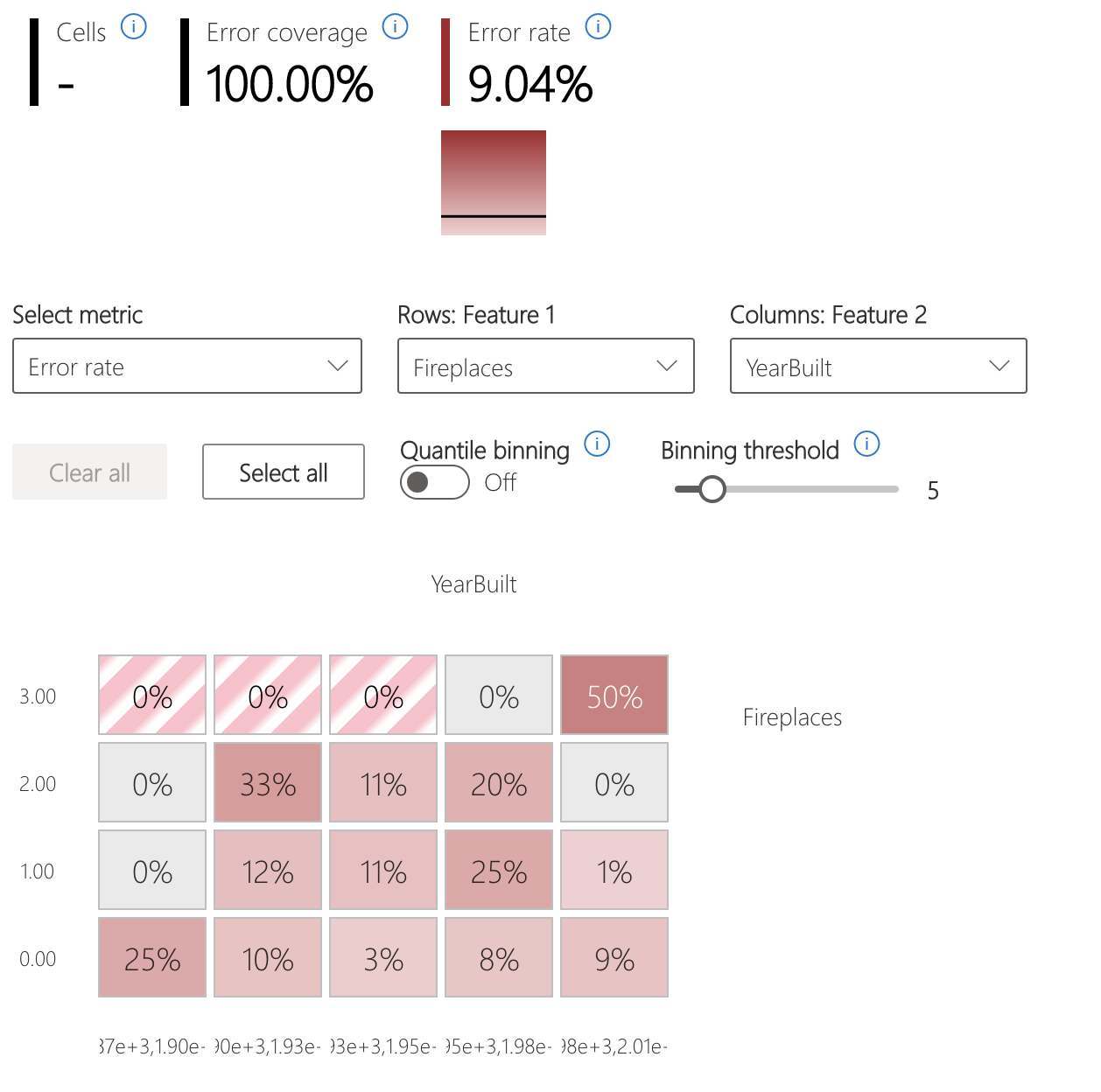
- Тепловая карта, визуализируемая тем, как входные функции влияют на частоту ошибок в когортах.
Несоответствия в ошибках могут возникать, когда система недоимки для определенных демографических групп или редко наблюдаемых входных данных в данных обучения.
Возможности этого компонента получены из пакета анализа ошибок, который создает профили ошибок модели.
Используйте анализ ошибок при необходимости:
- Получите глубокое представление о том, как ошибки модели распределяются по набору данных и нескольким измерениям входных данных и функций.
- Разбиите статистические метрики производительности, чтобы автоматически обнаруживать ошибочные когорты, чтобы сообщить о целевых шагах по устранению рисков.
Дерево ошибок
Часто шаблоны ошибок являются сложными и включают несколько или двух функций. Разработчики могут столкнуться с трудностями при изучении всех возможных сочетаний функций для обнаружения скрытых карманов данных с критическими сбоями.
Чтобы облегчить нагрузку, визуализация двоичного дерева автоматически секционирует данные теста на интерпретируемые подгруппы с неожиданно высоким или низким уровнем ошибок. Другими словами, дерево использует признаки из входных данных, чтобы максимально разделить ошибки и успешные прогнозы модели. Для каждого узла, определяющего подгруппу данных, пользователи могут исследовать следующие сведения:
- Частота ошибок: часть экземпляров в узле, для которого модель является неправильной. Он показан с помощью интенсивности красного цвета.
- Покрытие ошибок: часть всех ошибок, которые попадают в узел. Он отображается с помощью скорости заполнения узла.
- Представление данных: количество экземпляров в каждом узле дерева ошибок. Он отображается по толщине входящего края узла, а также общее количество экземпляров в узле.

Тепловая карта ошибок
Представление срезает данные на основе одномерной или двухмерной сетки входных функций. Пользователи могут выбрать для анализа наиболее интересующие признаки из входных данных.
Тепловая карта визуализирует ячейки с высокой ошибкой, используя темный красный цвет, чтобы привлечь внимание пользователя к этим регионам. Эта функция особенно полезна, если темы ошибок отличаются между секциями, что часто происходит на практике. В этом представлении идентификации ошибок анализ очень руководствуется пользователями и их знаниями или гипотезами о том, какие функции могут быть наиболее важными для понимания сбоев.
Следующие шаги
- Узнайте, как создать панель мониторинга ответственного ИИ с помощью CLI и пакета SDK или пользовательского интерфейса Студии Машинного обучения Azure.
- Изучите поддерживаемые визуализации анализа ошибок.
- Узнайте, как создать систему показателей ответственного применения ИИ на основе аналитических сведений, наблюдаемых на панели мониторинга ответственного применения ИИ.