Примечание.
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
Узнайте, как использовать Apache Spark в HDInsight для анализа данных телеметрии Application Insight.
Visual Studio Application Insights — это служба аналитики, которая отслеживает ваши веб-приложения. Данные телеметрии, созданные службой Application Insights, можно экспортировать в службу хранилища Azure. Когда данные находятся в хранилище Azure, вы можете использовать HDInsight для их анализа.
Предварительные условия
Приложение, настроенное для использования службы Application Insights.
Умение создавать кластеры HDInsight под управлением Linux. Дополнительные сведения см. в статье о создании кластера Apache Spark в HDInsight.
Веб-браузер.
При разработке и тестировании этого документа использовались следующие ресурсы:
Данные телеметрии Application Insights были созданы с помощью веб-приложения Node.js, настроенного для использования Application Insights.
Для анализа данных использована платформа Spark под управлением Linux в кластере HDInsight версии 3.5.
Архитектура и планирование
На следующей схеме показана архитектура служб данного примера:
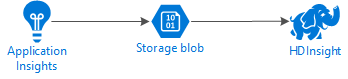
Хранилище Azure
В службе Application Insights можно настроить непрерывный экспорт данных телеметрии в большие двоичные объекты. Затем HDInsight сможет считывать данные, хранимые в блобах. Однако существует ряд требований, которые необходимо выполнить. Они описаны ниже.
Расположение. Если учетная запись хранения и HDInsight находятся в разных местах, это может увеличить задержку. Это также увеличивает затраты, так как передача данных между регионами оплачивается как исходящий трафик.
Предупреждение
Использование учетной записи хранения, расположение которой отличается от расположения кластера HDInsight, не поддерживается.
Тип BLOB-объекта: HDInsight поддерживает только блочные BLOB-объекты. Служба Application Insights по умолчанию использует блок-блобы, что обеспечивает совместимость с HDInsight.
Сведения о добавлении хранилища в имеющийся кластер см. в статье Добавление дополнительных учетных записей хранения.
Схема данных
Application Insights предоставляет сведения о модели данных экспорта для формата данных телеметрии, экспортируемых в блобы. В этом документе для работы с данными используется Spark SQL. Spark SQL может автоматически создавать схему для структуры данных JSON, регистрируемой службой Application Insights.
Экспорт данных телеметрии
Чтобы настроить непрерывный экспорт данных телеметрии из Application Insights в хранилище BLOB-объектов Azure, выполните действия, описанные в статье Экспорт данных телеметрии из Application Insights.
Настройка доступа к данным из HDInsight
Если вы создаете кластер HDInsight, в процессе добавьте учетную запись хранения.
Чтобы добавить учетную запись хранения Azure в имеющийся кластер, ознакомьтесь со сведениями, приведенными в статье Добавление дополнительных учетных записей хранения.
Анализ данных. PySpark
В веб-браузере перейдите на страницу
https://CLUSTERNAME.azurehdinsight.net/jupyter, заменив CLUSTERNAME именем своего кластера.В правом верхнем углу страницы Jupyter щелкните Создать, а затем выберите PySpark. При этом откроется новая вкладка браузера, содержащая записную книжку Jupyter на основе Python.
На этой странице в первом поле (которое называется ячейка) введите следующий текст:
sc._jsc.hadoopConfiguration().set('mapreduce.input.fileinputformat.input.dir.recursive', 'true')Этот код настраивает Spark рекурсивно обращаться к структуре каталогов для получения входных данных. Телеметрия Application Insights записывается в структуру каталогов, аналогичную этой:
/{telemetry type}/YYYY-MM-DD/{##}/.Для выполнения кода используйте сочетание клавиш SHIFT+ВВОД. Слева от ячейки в скобках отобразится звездочка (*), показывая тем самым, что код в этой ячейке выполняется. После завершения выполнения звездочку (*) заменит число, а под ячейкой отобразятся данные, аналогичные следующим:
Creating SparkContext as 'sc' ID YARN Application ID Kind State Spark UI Driver log Current session? 3 application_1468969497124_0001 pyspark idle Link Link ✔ Creating HiveContext as 'sqlContext' SparkContext and HiveContext created. Executing user code ...Под первой ячейкой будет создана новая ячейка. Введите в новую ячейку следующие данные. Замените
CONTAINERиSTORAGEACCOUNTименем учетной записи хранения Azure и именем контейнера BLOB, который содержит данные службы Application Insights.%%bash hdfs dfs -ls wasbs://CONTAINER@STORAGEACCOUNT.blob.core.windows.net/Для выполнения этой ячейки используйте сочетание клавиш SHIFT+ВВОД. Отобразится результат, аналогичный следующему:
Found 1 items drwxrwxrwx - 0 1970-01-01 00:00 wasbs://appinsights@contosostore.blob.core.windows.net/contosoappinsights_2bededa61bc741fbdee6b556571a4831Полученный путь WASBS является расположением данных телеметрии Application Insights. Замените строку
hdfs dfs -lsв ячейке на возвращенный путь wasbs, а затем используйте сочетание клавиш SHIFT+ВВОД для повторного выполнения ячейки. На этот раз в результате выполнения должны отобразиться каталоги, содержащие данные телеметрии.Примечание.
Для остальных действий, описанных в этом разделе, использовался каталог
wasbs://appinsights@contosostore.blob.core.windows.net/contosoappinsights_{ID}/Requests. Структура каталога может отличаться.В следующей ячейке введите код ниже: замените
WASB_PATHна путь, который вы использовали на предыдущем шаге.jsonFiles = sc.textFile('WASB_PATH') jsonData = sqlContext.read.json(jsonFiles)Этот код создает кадр данных на основе файлов JSON, экспортируемых в процессе непрерывного экспорта. Для выполнения ячейки используйте сочетание клавиш SHIFT+ВВОД.
В следующей ячейке введите и выполните такую команду, чтобы просмотреть схему, созданную Spark для JSON-файлов:
jsonData.printSchema()Схемы для разных типов телеметрии будут отличаться. Ниже приведен пример схемы, созданной для веб-запросов (для данных, хранящихся в подкаталоге
Requests):root |-- context: struct (nullable = true) | |-- application: struct (nullable = true) | | |-- version: string (nullable = true) | |-- custom: struct (nullable = true) | | |-- dimensions: array (nullable = true) | | | |-- element: string (containsNull = true) | | |-- metrics: array (nullable = true) | | | |-- element: string (containsNull = true) | |-- data: struct (nullable = true) | | |-- eventTime: string (nullable = true) | | |-- isSynthetic: boolean (nullable = true) | | |-- samplingRate: double (nullable = true) | | |-- syntheticSource: string (nullable = true) | |-- device: struct (nullable = true) | | |-- browser: string (nullable = true) | | |-- browserVersion: string (nullable = true) | | |-- deviceModel: string (nullable = true) | | |-- deviceName: string (nullable = true) | | |-- id: string (nullable = true) | | |-- osVersion: string (nullable = true) | | |-- type: string (nullable = true) | |-- location: struct (nullable = true) | | |-- city: string (nullable = true) | | |-- clientip: string (nullable = true) | | |-- continent: string (nullable = true) | | |-- country: string (nullable = true) | | |-- province: string (nullable = true) | |-- operation: struct (nullable = true) | | |-- name: string (nullable = true) | |-- session: struct (nullable = true) | | |-- id: string (nullable = true) | | |-- isFirst: boolean (nullable = true) | |-- user: struct (nullable = true) | | |-- anonId: string (nullable = true) | | |-- isAuthenticated: boolean (nullable = true) |-- internal: struct (nullable = true) | |-- data: struct (nullable = true) | | |-- documentVersion: string (nullable = true) | | |-- id: string (nullable = true) |-- request: array (nullable = true) | |-- element: struct (containsNull = true) | | |-- count: long (nullable = true) | | |-- durationMetric: struct (nullable = true) | | | |-- count: double (nullable = true) | | | |-- max: double (nullable = true) | | | |-- min: double (nullable = true) | | | |-- sampledValue: double (nullable = true) | | | |-- stdDev: double (nullable = true) | | | |-- value: double (nullable = true) | | |-- id: string (nullable = true) | | |-- name: string (nullable = true) | | |-- responseCode: long (nullable = true) | | |-- success: boolean (nullable = true) | | |-- url: string (nullable = true) | | |-- urlData: struct (nullable = true) | | | |-- base: string (nullable = true) | | | |-- hashTag: string (nullable = true) | | | |-- host: string (nullable = true) | | | |-- protocol: string (nullable = true)Чтобы зарегистрировать таблицу данных в качестве временной таблицы и выполнить запрос на основе этих данных, используйте следующую команду:
jsonData.registerTempTable("requests") df = sqlContext.sql("select context.location.city from requests where context.location.city is not null") df.show()Этот запрос вернет сведения о городе для первых 20 записей, где параметр context.location.city не имеет значение NULL.
Примечание.
Структура контекста присутствует во всех данных телеметрии, записываемых Application Insights. Элемент city может не заполняться в ваших журналах. Используйте эту схему для определения других элементов, которые можно запросить и которые могут содержать данные для журналов.
Этот запрос возвращает следующие сведения:
+---------+ | city| +---------+ | Bellevue| | Redmond| | Seattle| |Charlotte| ... +---------+
Проанализируй данные: Scala
В веб-браузере перейдите на страницу
https://CLUSTERNAME.azurehdinsight.net/jupyter, заменив CLUSTERNAME именем своего кластера.В правом верхнем углу страницы Jupyter щелкните Создать, а затем выберите Scala. При этом откроется новая вкладка браузера, содержащая записную книжку Jupyter на основе Scala.
На этой странице в первом поле (которое называется ячейка) введите следующий текст:
sc.hadoopConfiguration.set("mapreduce.input.fileinputformat.input.dir.recursive", "true")Этот код настраивает Spark рекурсивно обращаться к структуре каталогов для получения входных данных. Телеметрия Application Insights записывается в структуру каталогов, аналогичную этой:
/{telemetry type}/YYYY-MM-DD/{##}/.Для выполнения кода используйте сочетание клавиш SHIFT+ВВОД. Слева от ячейки в скобках отобразится звездочка (*), показывая тем самым, что код в этой ячейке выполняется. После завершения выполнения звездочку (*) заменит число, а под ячейкой отобразятся данные, аналогичные следующим:
Creating SparkContext as 'sc' ID YARN Application ID Kind State Spark UI Driver log Current session? 3 application_1468969497124_0001 spark idle Link Link ✔ Creating HiveContext as 'sqlContext' SparkContext and HiveContext created. Executing user code ...Под первой ячейкой будет создана новая ячейка. Введите в новую ячейку следующие данные. Замените
CONTAINERиSTORAGEACCOUNTименем учетной записи хранения Azure и именем контейнера BLOB, который содержит журналы Application Insights.%%bash hdfs dfs -ls wasbs://CONTAINER@STORAGEACCOUNT.blob.core.windows.net/Для выполнения этой ячейки используйте сочетание клавиш SHIFT+ВВОД. Отобразится результат, аналогичный следующему:
Found 1 items drwxrwxrwx - 0 1970-01-01 00:00 wasbs://appinsights@contosostore.blob.core.windows.net/contosoappinsights_2bededa61bc741fbdee6b556571a4831Полученный путь WASBS указывает на расположение данных телеметрии Application Insights. Замените строку
hdfs dfs -lsв ячейке на полученный путь wasbs, а затем нажмите SHIFT+ВВОД для повторного выполнения ячейки. На этот раз в результате выполнения должны отобразиться каталоги, содержащие данные телеметрии.Примечание.
Для остальных действий, описанных в этом разделе, использовался каталог
wasbs://appinsights@contosostore.blob.core.windows.net/contosoappinsights_{ID}/Requests. Этот каталог может отсутствовать, если ваши данные телеметрии не предназначены для веб-приложения.В следующей ячейке введите код ниже: замените
WASB\_PATHна путь, который вы использовали на предыдущем шаге.var jsonFiles = sc.textFile('WASB_PATH') val sqlContext = new org.apache.spark.sql.SQLContext(sc) var jsonData = sqlContext.read.json(jsonFiles)Этот код создает кадр данных на основе файлов JSON, экспортируемых в процессе непрерывного экспорта. Для выполнения ячейки используйте сочетание клавиш SHIFT+ВВОД.
В следующей ячейке введите и выполните такую команду, чтобы просмотреть схему, созданную Spark для JSON-файлов:
jsonData.printSchemaСхемы для разных типов телеметрии будут отличаться. Ниже приведен пример схемы, созданной для веб-запросов (для данных, хранящихся в подкаталоге
Requests):root |-- context: struct (nullable = true) | |-- application: struct (nullable = true) | | |-- version: string (nullable = true) | |-- custom: struct (nullable = true) | | |-- dimensions: array (nullable = true) | | | |-- element: string (containsNull = true) | | |-- metrics: array (nullable = true) | | | |-- element: string (containsNull = true) | |-- data: struct (nullable = true) | | |-- eventTime: string (nullable = true) | | |-- isSynthetic: boolean (nullable = true) | | |-- samplingRate: double (nullable = true) | | |-- syntheticSource: string (nullable = true) | |-- device: struct (nullable = true) | | |-- browser: string (nullable = true) | | |-- browserVersion: string (nullable = true) | | |-- deviceModel: string (nullable = true) | | |-- deviceName: string (nullable = true) | | |-- id: string (nullable = true) | | |-- osVersion: string (nullable = true) | | |-- type: string (nullable = true) | |-- location: struct (nullable = true) | | |-- city: string (nullable = true) | | |-- clientip: string (nullable = true) | | |-- continent: string (nullable = true) | | |-- country: string (nullable = true) | | |-- province: string (nullable = true) | |-- operation: struct (nullable = true) | | |-- name: string (nullable = true) | |-- session: struct (nullable = true) | | |-- id: string (nullable = true) | | |-- isFirst: boolean (nullable = true) | |-- user: struct (nullable = true) | | |-- anonId: string (nullable = true) | | |-- isAuthenticated: boolean (nullable = true) |-- internal: struct (nullable = true) | |-- data: struct (nullable = true) | | |-- documentVersion: string (nullable = true) | | |-- id: string (nullable = true) |-- request: array (nullable = true) | |-- element: struct (containsNull = true) | | |-- count: long (nullable = true) | | |-- durationMetric: struct (nullable = true) | | | |-- count: double (nullable = true) | | | |-- max: double (nullable = true) | | | |-- min: double (nullable = true) | | | |-- sampledValue: double (nullable = true) | | | |-- stdDev: double (nullable = true) | | | |-- value: double (nullable = true) | | |-- id: string (nullable = true) | | |-- name: string (nullable = true) | | |-- responseCode: long (nullable = true) | | |-- success: boolean (nullable = true) | | |-- url: string (nullable = true) | | |-- urlData: struct (nullable = true) | | | |-- base: string (nullable = true) | | | |-- hashTag: string (nullable = true) | | | |-- host: string (nullable = true) | | | |-- protocol: string (nullable = true)Чтобы зарегистрировать таблицу данных в качестве временной таблицы и выполнить запрос на основе этих данных, используйте следующую команду:
jsonData.registerTempTable("requests") var city = sqlContext.sql("select context.location.city from requests where context.location.city isn't null limit 10").show()Этот запрос вернет сведения о городе для первых 20 записей, где параметр context.location.city не имеет значение NULL.
Примечание.
Структура контекста присутствует во всех данных телеметрии, записываемых Application Insights. Элемент "город" может не заполняться в ваших журналах. Используйте эту схему для определения других элементов, которые можно запросить и которые могут содержать данные для журналов.
Этот запрос возвращает следующие сведения:
+---------+ | city| +---------+ | Bellevue| | Redmond| | Seattle| |Charlotte| ... +---------+
Следующие шаги
Дополнительные примеры применения Apache Spark при работе с данными и службами в Azure см. в следующих документах:
- Использование Apache Spark со средствами бизнес-аналитики. Выполнение интерактивного анализа данных с использованием Spark в HDInsight с помощью средств бизнес-аналитики
- Apache Spark с Машинным обучением: использование Spark в HDInsight для анализа температуры зданий с помощью данных системы HVAC
- Apache Spark и машинное обучение: использование Spark в HDInsight для прогнозирования результатов проверки пищевых продуктов
- Анализ журналов веб-сайтов с помощью Apache Spark в HDInsight
Дополнительные сведения о создании и запуске приложений Spark см. в следующих документах: