Примечание.
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
Узнайте, как выполнять запросы Hive с использованием представления Hive Apache Ambari. Представление Hive позволяет создавать, оптимизировать и выполнять запросы Hive из веб-браузера.
Предварительные требования
Кластер Hadoop в HDInsight. Ознакомьтесь с Начало работы с HDInsight на Linux.
Выполнение запроса Hive
На портале Azure выберите свой кластер. Инструкции см. в разделе Отображение кластеров. Кластер откроется на новой странице портала.
На Панелях мониторинга кластеров выберите Представления Ambari. Если запрашивается проверка подлинности, используйте имя пользователя и пароль учетной записи входа в кластер (по умолчанию —
admin), указанные при создании кластера. Можно также перейти по адресуhttps://CLUSTERNAME.azurehdinsight.net/#/main/viewsв браузере, гдеCLUSTERNAME— это имя кластера.В списке представлений выберите Hive View.

Страница представления Hive выглядит следующим образом:
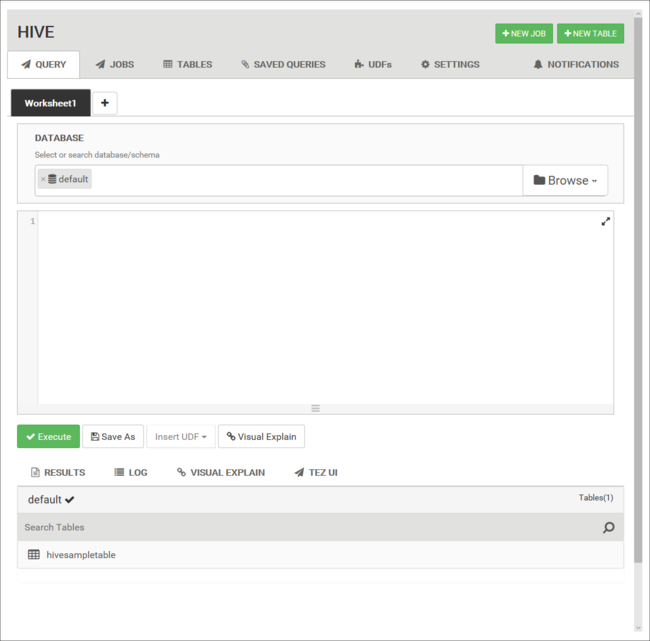
На вкладке Запрос вставьте в лист следующие инструкции HiveQL:
DROP TABLE log4jLogs; CREATE EXTERNAL TABLE log4jLogs( t1 string, t2 string, t3 string, t4 string, t5 string, t6 string, t7 string) ROW FORMAT DELIMITED FIELDS TERMINATED BY ' ' STORED AS TEXTFILE LOCATION '/example/data/'; SELECT t4 AS loglevel, COUNT(*) AS count FROM log4jLogs WHERE t4 = '[ERROR]' GROUP BY t4;Эти инструкции выполняют описанные ниже действия.
Заявление Описание УДАЛИТЬ ТАБЛИЦУ удаляет таблицу и файл данных, если таблица уже существует. СОЗДАТЬ ВНЕШНЮЮ ТАБЛИЦУ Создает "внешнюю" таблицу в Hive. Внешние таблицы хранят только определение таблицы в Hive. Данные остаются в исходном расположении. Формат строки показывает настройку форматирования данных. В данном случае поля всех журналов разделены пробелом. СОХРАНЕНО В ВИДЕ ФАЙЛА ТЕКСТОВОЕ РАСПОЛОЖЕНИЕ показывает место хранения данных и их формат (текст). ВЫБРАТЬ выбирает подсчет количества строк, в которых столбец t4 содержит значение [ERROR]. Внимание
Оставьте для параметра База данных значение по умолчанию. В примерах в этом документе используется база данных по умолчанию, входящая в состав HDInsight.
Чтобы выполнить запрос, нажмите кнопку Выполнить под листом. Кнопка станет оранжевой, а текст изменится на Остановить.
Когда запрос будет выполнен, на вкладке Результаты появятся результаты этой операции. Вот пример результата запроса:
loglevel count [ERROR] 3Вы можете использовать вкладку ЖУРНАЛ для просмотра сведений журналирования, созданных в процессе выполнения задания.
Совет
Скачайте или сохраните результаты из раскрывающегося диалогового окна Действия на вкладке Результаты.
Визуальные объяснения
Чтобы отобразить визуализацию плана запроса, перейдите на вкладку "Визуальные объяснения " под листом.
Представление визуального пояснения запроса может быть полезно для понимания потока сложных запросов.
Пользовательский интерфейс Tez
Чтобы отобразить пользовательский интерфейс Tez для запроса, выберите под листом вкладку Пользовательский интерфейс Tez.
Внимание
Tez используется не для всех запросов. Многие запросы можно разрешить и без применения Tez.
Просмотреть журнал заданий
На вкладке Задания отображается журнал запросов Hive.
История вкладки заданий в интерфейсе просмотра Apache Hive.
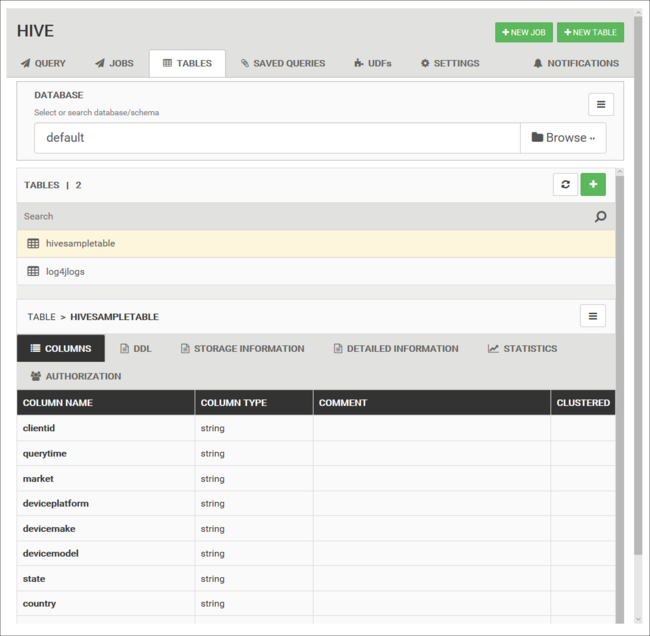
Таблицы базы данных
Вкладку Таблицы можно использовать для работы с таблицами в базе данных Hive.
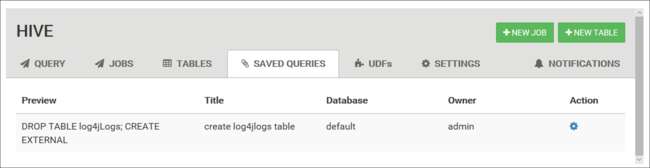
Сохраненные запросы
На вкладке Запрос можно при желании сохранять запросы. После сохранения запроса можно повторно использовать его из вкладки Saved Queries (Сохраненные запросы).
Совет
Запросы сохраняются в системе хранения данных кластера по умолчанию. Сохраненные запросы можно найти в следующем расположении: /user/<username>/hive/scripts. Они хранятся в виде обычных текстовых файлов .hql.
Если удалить кластер, но сохранить хранилище, можно использовать утилиты, такие как Обозреватель хранилища Azure или Data Lake Storage Explorer (с портала Azure), чтобы получить запросы.
Пользовательские функции
Hive можно расширить с помощью пользовательских функций (UDF). Используйте UDF (пользовательскую функцию), чтобы реализовать функции или логику, которые сложно моделировать в HiveQL.
Объявлять и сохранять наборы определяемых пользователем функций можно с помощью вкладки UDF вверху представления Hive. Эти пользовательские функции (UDFs) могут использоваться в редакторе запросов.
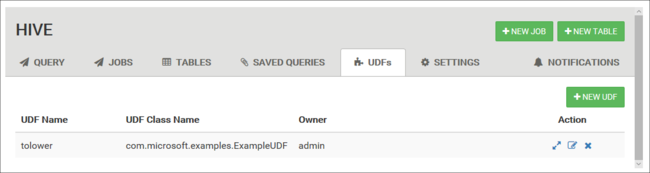
Кнопка Вставить UDF появляется в нижней части Редактора запросов. Эта запись отображает раскрывающийся список пользовательских функций, определённых в представлении Hive. Добавление определяемой пользователем функции добавляет инструкции HiveQL в ваш запрос для активации этой функции.
Например, если вы определили пользовательскую функцию (UDF) со следующими свойствами:
имя ресурса — myudfs;
путь к ресурсу — /myudfs.jar;
имя определяемой пользователем функции — myawesomeudf;
имя класса определяемой пользователем функции — com.myudfs.Awesome.
Нажав кнопку Insert udfs (Вставить определяемые пользователем функции), вы увидите запись с именем myudfs, содержащую раскрывающийся список для каждой функции, определяемой для этого ресурса. В нашем примере это функция myawesomeudf. Если вы выберете эту запись, в начало запроса будет добавлен следующий код:
add jar /myudfs.jar;
create temporary function myawesomeudf as 'com.myudfs.Awesome';
Затем вы можете использовать UDF в своем запросе. Например, SELECT myawesomeudf(name) FROM people;.
Вы можете ознакомиться с дополнительной информацией об использовании определяемых пользователем функций в Hive на HDInsight в следующих статьях:
- Использование Python с Apache Hive и Apache Pig в HDInsight
- Использование Java UDF с Apache Hive в среде HDInsight
Параметры Hive
Вы можете изменять различные настройки Hive, например, сменить механизм выполнения Hive с Tez (используется по умолчанию) на MapReduce.
Следующие шаги
Общая информация о Hive в HDInsight:
- Использование Apache Hive с Apache Hadoop в HDInsight
- Use the Apache Beeline client with Apache Hive (Использование клиента Apache Beeline с Apache Hive)