Примечание.
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
В настоящее время просмотр:![]() Версия портала Foundry (классическая версия) - Переключиться на версию для нового портала Foundry
Версия портала Foundry (классическая версия) - Переключиться на версию для нового портала Foundry
Из этой статьи вы узнаете:
- Находите и открывайте запуски оценивания.
- Просмотр агрегированных и выборочных метрик.
- Сравните результаты между запусками.
- Интерпретация категорий и вычислений метрик.
- Диагностика и устранение отсутствующих или частичных метрик.
Необходимые условия
Проведение оценки.
- Чтобы узнать, как проводить оценки на портале, см. Оценка моделей и приложений генеративного ИИ.
- Чтобы узнать, как выполнять оценки из пакета SDK, выполните оценки в облаке или локально.
Просмотр результатов оценки
После отправки оценки найдите запуск на странице оценки . Для сосредоточения на интересующих вас запусках используйте фильтрацию или настройку столбцов. Просмотрите основные метрики быстро перед тем, как углубиться в детали.
Совет
Вы можете просмотреть оценочный запуск с любой версией promptflow-evals SDK или azure-ai-evaluation версии 1.0.0b1, 1.0.0b2, 1.0.0b3. Включите переключатель "Показать все запуски", чтобы найти запуск.
Выберите Подробнее о метриках для определений и формул.

Выберите запуск, чтобы открыть подробности (набор данных, тип задачи, запрос, параметры) и метрики для каждой выборки. Панель мониторинга метрик визуализирует скорость передачи или статистическую оценку для каждой метрики.
Осторожно
Пользователи, которые ранее управляли развертываниями моделей и выполняли оценки с помощью oai.azure.com, а затем подключены к платформе разработчика Microsoft Foundry, имеют следующие ограничения при использовании ai.azure.com:
- Эти пользователи не могут просматривать свои оценки, созданные с помощью AZURE API OpenAI. Чтобы просмотреть эти оценки, они должны вернуться в
oai.azure.com. - Эти пользователи не могут использовать AZURE API OpenAI для выполнения вычислений в Foundry. Вместо этого они должны продолжать использовать
oai.azure.comдля этой задачи. Однако они могут использовать оценщики Azure OpenAI, доступные непосредственно в Foundry (ai.azure.com) в параметре создания оценки набора данных. Параметр оценки модели с тонкой настройкой не поддерживается, если развертывание представляет собой миграцию из Azure OpenAI в Foundry.
Для сценария отправки набора данных и использования собственного хранилища существует несколько требований к конфигурации:
- Проверка подлинности учетной записи должна осуществляться через Microsoft Entra ID.
- Хранилище должно быть добавлено в учетную запись. Добавление его в проект приводит к ошибкам службы.
- Пользователи должны добавить свой проект в свою учетную запись хранения с помощью управления доступом на портале Azure.
Дополнительные сведения о создании оценок с помощью оценочных градеров OpenAI в Azure OpenAI хабе см. в статье Как использовать Azure OpenAI для оценки моделей в Foundry.
Панель мониторинга метрик
В разделе панель метрик агрегированные отображения разбиваются по метрикам, которые включают качество ИИ (с поддержкой ИИ),риск и безопасность (версия для предварительного просмотра),качество ИИ (NLP) и настраиваемые (если применимо). Результаты измеряются в процентах сдачи/провала на основе критериев, выбранных при создании проверки. Дополнительные сведения о определениях метрик и их вычислении см. в статье "Встроенные оценщики".
- Для метрик качества ИИ (с помощью ИИ) результаты усредняются по всем показателям для каждой метрики. Если вы используете Groundedness Pro, выходные данные являются двоичными, а агрегированная оценка — показатель успешности:
(#trues / #instances) × 100.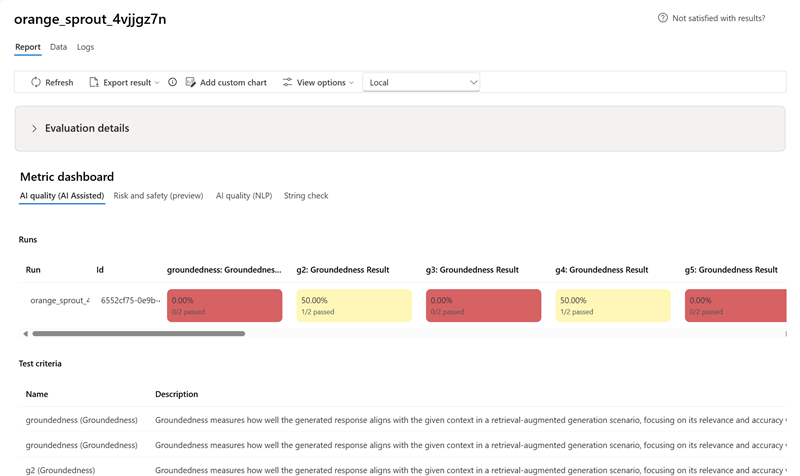
- Для метрик риска и безопасности (предварительная версия) результаты агрегируются по частоте дефектов.
- Вред содержимого: процент экземпляров, превышающих пороговое значение серьезности (по умолчанию
Medium). - Для защищенного материала и косвенной атаки уровень дефекта вычисляется как процент экземпляров, в которых выходные данные составляют
true, используя формулу(Defect Rate = (#trues / #instances) × 100).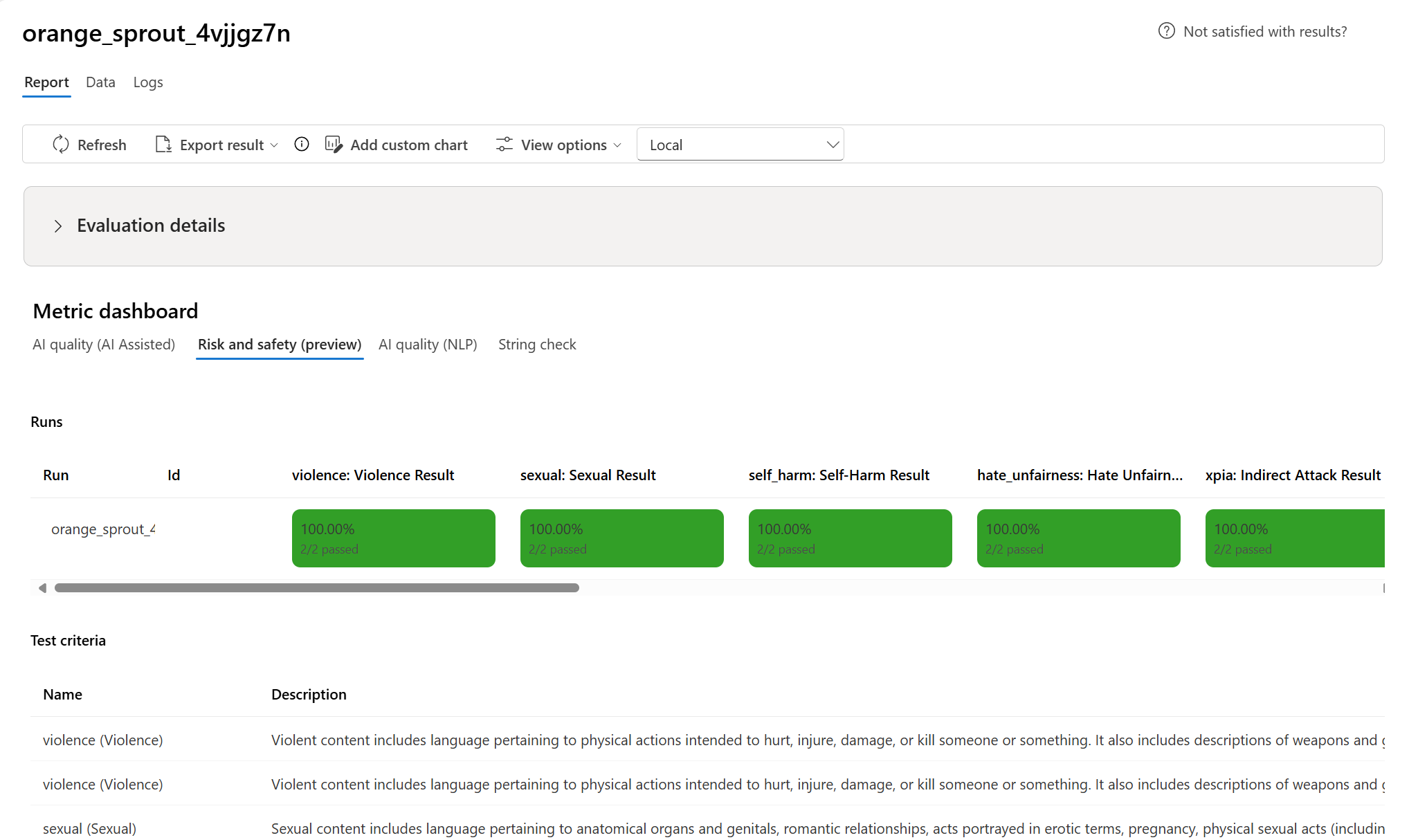
- Вред содержимого: процент экземпляров, превышающих пороговое значение серьезности (по умолчанию
- Для метрик качества ИИ (NLP) результаты агрегируются по среднему показателю на метрики.
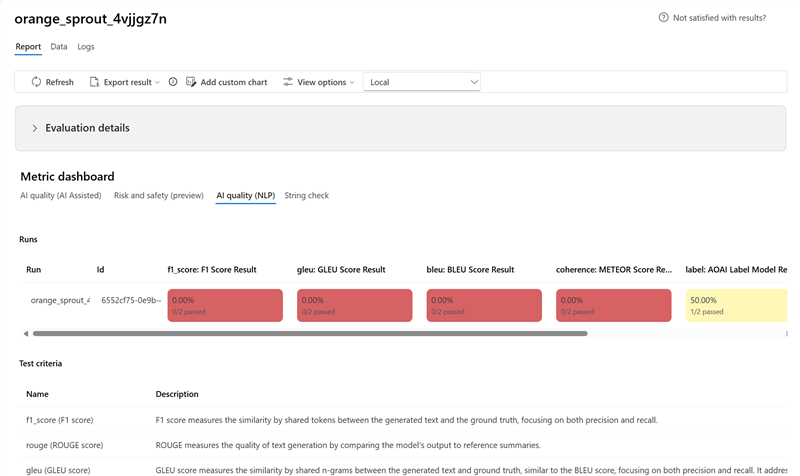



Подробная таблица результатов метрик
Используйте таблицу под панелью мониторинга для проверки каждого примера данных. Сортируйте по метрикам, чтобы получить наиболее высокопроизводительные образцы и выявить систематические пробелы (неправильные результаты, сбои безопасности, задержка). Используйте поиск для группировки связанных тем сбоев. Примените настройку столбца, чтобы сосредоточиться на ключевых метриках.
Типичные действия:
- Фильтрация по низким оценкам для обнаружения повторяющихся шаблонов.
- При появлении системных пробелов измените подсказки или выполните их тонкую настройку.
- Экспорт для автономного анализа.
Ниже приведены некоторые примеры результатов метрик для сценария ответа на вопросы:

Некоторые оценки имеют подоценки, которые позволяют просматривать JSON результатов этих подоценок. Чтобы просмотреть результаты, выберите "Вид" в ФОРМАТЕ JSON.

Просмотрите JSON в предварительном просмотре JSON:

Ниже приведены некоторые примеры результатов метрик для сценария беседы. Чтобы просмотреть результаты в многоэтапной беседе, выберите Просмотреть результаты оценки по каждому этапу в столбце Беседа.

При выборе просмотреть результаты оценки по каждому этапу вы увидите следующий экран:

Для оценки безопасности в много модальном сценарии (текст и изображения) можно лучше понять результат оценки, просмотрив изображения из входных и выходных данных в подробной таблице результатов метрик. Так как мультимодальная оценка в настоящее время поддерживается только для сценариев беседы, вы можете выбрать Просмотр результатов оценки каждого шага чтобы проверить входные и выходные данные для каждого шага.

Выберите изображение, чтобы развернуть его и просмотреть. По умолчанию все изображения размыты, чтобы защитить вас от потенциально вредного содержимого. Чтобы четко просмотреть изображение, включите переключатель " Проверить размытие изображения ".

Результаты оценки могут иметь разные значения для разных аудиторий. Например, оценки безопасности могут создать метку для низкой серьезности насильственного содержимого, которое может не соответствовать определению рецензента человека о том, насколько сильно это конкретное насильственное содержимое. Проходной балл, установленный во время создания оценки, определяет, является ли результат прохождением или неудачей. Существует столбец отзывов пользователей, в котором можно выбрать значок 'палец вверх' или 'палец вниз' во время просмотра результатов оценки. Этот столбец можно использовать для записи, какие случаи были утверждены или помечены как неверные человеческим рецензентом.

Чтобы понять каждую метрику риска содержимого, просмотрите определения метрик в разделе "Отчет " или просмотрите тест в разделе панели мониторинга метрик .
Если что-то пошло не так при запуске, вы также можете использовать журналы регистрации для отладки вашего запуска оценки. Ниже приведены некоторые примеры журналов, которые можно использовать для отладки выполнения оценки:

Если вы оцениваете поток запроса, можно выбрать кнопку «Просмотреть в потоке», чтобы перейти на оцененную страницу потока и обновить поток. Например, можно добавить дополнительные инструкции мета-запроса или изменить некоторые параметры и повторно оценить.
Сравнение результатов оценки
Чтобы сравнить два или более запусков, выберите нужные запуски и запустите процесс. Нажмите кнопку "Сравнить " или кнопку "Переключиться на панель мониторинга" для подробного представления панели мониторинга. Анализируйте и сопоставляйте производительность и результаты нескольких запусков, чтобы принимать обоснованные решения и вносить целенаправленные улучшения.

В представлении панели мониторинга у вас есть доступ к двум ценным компонентам: диаграмме сравнения метрик и таблице сравнения. Эти инструменты можно использовать для сравнительного анализа выбранных этапов оценки. Вы можете сравнить различные аспекты каждого примера данных с легкостью и точностью.
Примечание
По умолчанию в более ранних запусках оценки строки между столбцами совпадают. Тем не менее, новые выполненные оценки необходимо намеренно настроить так, чтобы столбцы совпадали во время создания оценки. Убедитесь, что одно и то же имя используется в качестве значения имени критерия во всех оценках, которые необходимо сравнить.
На следующем сниме экрана показаны результаты, когда поля совпадают:

Если пользователь не использует то же имя критерия при создании оценки, поля не совпадают, что приводит к тому, что платформа не сможет напрямую сравнить результаты:

В таблице сравнения наведите указатель мыши на запуск, который вы хотите использовать в качестве точки отсчета, и установите его в качестве базовой линии. Активируйте переключатель "Показать дельту" для визуализации различий между базовыми и другими запусками для числовых значений. Выберите переключатель "Показать только разницу", чтобы отобразить только строки, отличающиеся среди выбранных запусков, помогая определить изменения.
Используя эти функции сравнения, вы можете принять обоснованное решение, чтобы выбрать лучшую версию:
- Сравнение базовых показателей. Задав базовый запуск, можно определить эталонную точку, с которой можно сравнить другие запуски. Вы можете увидеть, как каждый запуск отклоняется от выбранного стандарта.
- Оценка числовых значений: Включение параметра "Показать делту" помогает понять степень различий между базовой и другими запусками. Эти сведения помогут оценить, как различные запуски выполняются с точки зрения конкретных метрик оценки.
- Изоляция различий. Функция "Показать только разницу" упрощает анализ, выделяя только области, в которых существуют несоответствия между запусками. Эта информация может быть важной в том, чтобы определить, где необходимы улучшения или корректировки.
Используйте средства сравнения, чтобы выбрать конфигурацию с наилучшими характеристиками и избежать регрессий в безопасности или базисности.

Оценка уязвимости джейлбрейка
** Оценка уязвимости джейлбрейка — это сравнительная оценка, а не метрика при помощи ИИ. Запустите оценки на двух разных наборах данных, проходящих красную команду: базовый набор данных с атакующим тестом и тот же набор данных с тестом реализованным внедрением методов обхода защиты на первом этапе. Вы можете использовать симулятор данных, генерирующий противостоящие примеры, для создания набора данных с внедрением вредоносного кода или без него. Убедитесь, что значение имени критерия совпадает с каждой метрикой оценки при настройке выполнения.
Чтобы проверить, уязвимо ли ваше приложение к jailbreak, укажите базовый уровень и включите переключатель уровня дефектов при джейлбрейке в таблице сравнения. Частота дефектов джейлбрейка — это процент случаев в тестовом наборе данных, где внедрение джейлбрейка повышает оценку степени тяжести для любой метрики риска безопасности по сравнению с базовым показателем во всем наборе данных. Выберите несколько оценок на панели мониторинга сравнения, чтобы просмотреть разницу в частоте дефектов.

Совет
Частота дефектов в джейлбрейке вычисляется только для наборов данных одного размера и когда все запуски включают метрики риска контента и безопасности.
Общие сведения о встроенных метриках оценки
Понимание встроенных метрик важно для оценки производительности и эффективности приложения ИИ. Изучая эти ключевые средства измерения, вы можете интерпретировать результаты, принимать обоснованные решения и настраивать приложение для достижения оптимальных результатов.
Дополнительные сведения см. в разделе "Встроенные оценщики".
Устранение неполадок
| Симптом | Возможная причина | Действие |
|---|---|---|
| Выполнение остается в ожидании | Высокая загрузка или поставленные в очередь задания | Обновите, проверьте квоту и повторно отправьте в случае задержки. |
| Отсутствующие метрики | Не выбран при создании | Повторное выполнение и выбор необходимых метрик |
| Все метрики безопасности ноль | Категория отключена или неподдерживаемая модель | Подтверждение матрицы поддержки моделей и метрик |
| Неожиданно низкое заземление | Получение/контекст неполное | Проверка задержки создания или извлечения контекста |
Связанное содержимое
- Улучшайте низкие метрики с помощью итерации запросов или тонкой настройки.
- Запустите оценки в облаке с помощью пакета SDK Microsoft Foundry.
Узнайте, как оценить созданные приложения ИИ: