Примечание.
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
Это важно
Azure Data Lake Analytics вышел из эксплуатации 29 февраля 2024 года. Дополнительные сведения см. в этом объявлении.
Для аналитики данных ваша организация может использовать Azure Synapse Analytics или Microsoft Fabric.
Служба Azure Data Lake Analytics архивирует задания, отправленные в хранилище запросов. В этой статье вы узнаете, как использовать браузер заданий и представление заданий в средствах Azure Data Lake для Visual Studio для поиска сведений об исторических заданиях.
По умолчанию служба Data Lake Analytics архивирует задания в течение 30 дней. Срок действия можно настроить на портале Azure, настроив настраиваемую политику окончания срока действия. Вы не сможете получить доступ к сведениям о задании после истечения срока действия.
Предпосылки
Дополнительные сведения см. в разделе "Инструменты Data Lake" для Visual Studio.
Открытие браузера заданий
Доступ к Обозревателю заданий через > > > > > в Visual Studio. С помощью браузера заданий вы можете получить доступ к хранилищу запросов учетной записи Data Lake Analytics. В браузере заданий слева отображается хранилище запросов, в котором отображаются основные сведения о задании, а в представлении заданий справа отображаются подробные сведения о задании.
Просмотр вакансии
В представлении заданий отображаются подробные сведения о задании. Чтобы открыть задание, можно дважды щелкнуть задание в браузере заданий или открыть его в меню Data Lake, щелкнув представление задания. Должно появиться диалоговое окно, заполненное URL-адресом задания.

Представление задания содержит следующее:
Сводка задания
Обновите представление задания, чтобы просмотреть более последние сведения о выполнении заданий.
Состояние задания (граф):
Состояние задания описывает этапы задания:

Подготовка. Отправка скрипта в облако, компиляция и оптимизация скрипта с помощью службы компиляции.
В очереди: задания помещаются в очередь, когда они ожидают достаточного количества ресурсов или когда превышают лимит на количество одновременных заданий на одну учетную запись. Параметр приоритета определяет последовательность очередных заданий — чем меньше число, тем выше приоритет.
Выполнение: задание фактически выполняется в учетной записи Data Lake Analytics.
Завершение: задание завершается (например, завершение файла).
Задание может завершиться сбоем на каждом этапе. Например, ошибки компиляции на этапе подготовки, ошибки времени ожидания в очереди и ошибки выполнения на этапе выполнения и т. д.
Основные сведения
Основные сведения о задании отображаются в нижней части панели "Сводка заданий".

- Результат задания: выполнено успешно или завершилось сбоем. Задание может завершиться сбоем на каждом этапе.
- Общая длительность: время (длительность) между отправкой времени и конечным временем.
- Общее время вычислений: сумма каждого времени выполнения вершины можно рассматривать как время выполнения задания только в одной вершине. Дополнительную информацию о вершинах см. в разделе "Общие сведения о вершинах".
- Время отправки и окончания: время, когда служба Data Lake Analytics получает отправку задания или начинает выполнение задания или завершает задание успешно или нет.
- Компиляция/Очередь/Выполнение: Реальное время, затраченное в фазах Подготовка/Очередь/Выполнение.
- Учетная запись: учетная запись Data Lake Analytics, используемая для выполнения задания.
- Автор: пользователь, отправивший задание, может быть учетной записью реального человека или системной учетной записью.
- Приоритет: приоритет задания. Чем ниже число, тем выше приоритет. Это влияет только на последовательность заданий в очереди. Установка более высокого приоритета не прерывает выполнение текущих заданий.
- Параллелизм: запрошенное максимальное количество параллельных единиц Azure Data Lake Analytics (ADLAUs), также известное как вершины. В настоящее время одна вершина равна одной виртуальной машине с двумя виртуальными ядрами и шестью ГБ ОЗУ, хотя это может быть обновлено в будущих обновлениях Data Lake Analytics.
- Оставшиеся байты: байты, которые требуется обработать до завершения задания.
- Байты чтения и записи: байты, которые были прочитаны или записаны с момента запуска задания.
- Всего вершин: задание разбито на множество частей работы, каждая часть работы называется вершиной. Значение показывает, сколько частей включает задание. Вершины можно рассматривать как базовую единицу процесса, также называемую единицей анализа озера данных Azure (ADLAU), и вершины можно запускать параллельно.
- Завершено или выполнено или завершилось сбоем: количество завершенных или неудачных вершин. Вершины могут выйти из строя из-за ошибок пользовательского кода и системных сбоев, но система автоматически повторяет ошибочные вершины несколько раз. Если вершина по-прежнему завершается ошибкой после повторных попыток, всё задание завершится ошибкой.
Граф заданий
Скрипт U-SQL представляет логику преобразования входных данных в выходные данные. Скрипт компилируется и оптимизирован для плана физического выполнения на этапе подготовки. Граф заданий — показать план физического выполнения. На схеме ниже показан соответствующий процесс:

Работа разбита на множество заданий. Каждая часть работы называется вершиной. Вершины группируются в супервершину (также называемую этапом) и визуализированы как Граф Заданий. Зеленые плакаты на диаграмме заданий показывают этапы.
Каждая вершина на этапе выполняет одинаковую работу с различными частями одинаковых данных. Например, если у вас есть файл с данными с одним ТБ, и есть сотни вершин считывания из него, каждый из них считывает блок. Эти вершины группируются на одном этапе и выполняют одну и ту же работу над разными частями одного входного файла.
-
На определенном этапе некоторые числа отображаются на плакате.

Извлечение SV1: имя этапа, именованное числом и методом операции.
84 вершины: общее количество вершин на этом этапе. На рисунке показано, сколько частей работы разделено на этом этапе.
12.90 с/вершину: среднее время обработки вершины для этой стадии. Этот показатель вычисляется по формуле: сумма времени выполнения каждой вершины делится на общее количество вершин. Это означает, что если можно будет выполнить все вершины параллельно, весь этап завершится за 12,90 с. Это также означает, что если все работы на этом этапе выполняются последовательно, стоимость будет #vertices * AVG времени.
850 895 строк, написанных: общее число строк, записанных на этом этапе.
R/W: объем данных считывания и записи на этом этапе в байтах.
Цвета: цвета используются на сцене, чтобы указать различное состояние вершины.
- Зеленый цвет указывает, что вершина достигнута.
- Оранжевый указывает, что вершина извлекается. Полученная вершина завершилась сбоем, но выполняется автоматически и успешно выполняется системой, а общий этап успешно завершен. Если вершина повторно запущена, но все равно завершилась ошибкой, цвет становится красным, и всё задание завершилось ошибкой.
- Красный указывает на сбой, что означает, что определенная вершина была несколько раз попытана системой, но все равно не удалось достичь успеха. Этот сценарий приводит к сбою всего задания.
- Синий означает, что выполняется определенная вершина.
- Белый цвет указывает на то, что вершина ожидает. Вершина может ждать запланированного после того, как ADLAU станет доступной или может ожидать входных данных, так как входные данные могут не быть готовы.
Дополнительные сведения о этапе можно найти, наведите указатель мыши на одно состояние:
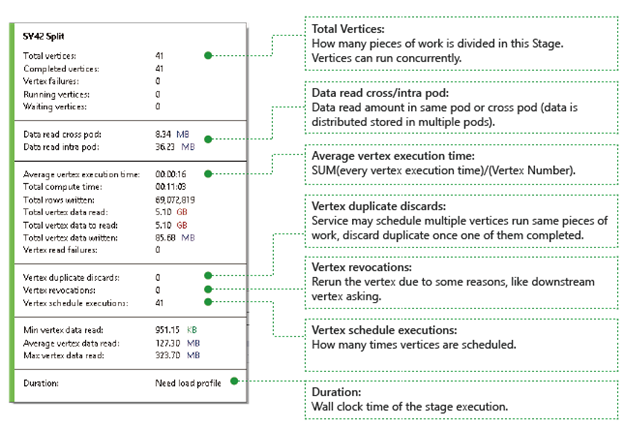
Вершины: описывает сведения о вершинах, например, сколько вершин в общей сложности, сколько вершин завершено, они завершаются сбоем или по-прежнему выполняются или ждут и т. д.
Данные считываются между модулями pod или внутри модуля pod. Файлы и данные хранятся в нескольких модулях pod в распределенной файловой системе. Значение здесь описывает, сколько данных было считано в одном модуле pod или перекрестном модуле pod.
Общее время вычислений: сумма каждого времени выполнения вершин в стадии, вы можете рассмотреть его как время, необходимое, если все работы на этапе выполняются только в одной вершине.
Данные и строки, записанные или прочитанные. Указывает, сколько данных или строк было прочитано или нужно считывать.
Сбои чтения вершин: описывает, сколько вершин не удалось прочитать при чтении данных.
Отбрасывание дубликатов вершин: если вершина выполняется слишком медленно, система может запланировать выполнение одной части работы несколькими вершинами. Избыточные вершины будут удалены после успешного завершения одной из вершин. Записанные дубляжи вершин фиксируют количество вершин, которые удаляются как дубликаты на этапе.
Отзыв вершин: вершина была успешно выполнена, но получите повторное выполнение позже из-за некоторых причин. Например, если нижестоящая вершина теряет промежуточные входные данные, она попросит вышестоящую вершину повторно запустить.
Выполнение расписания вершин: общее время выполнения запланированных вершин.
Минимальное/среднее/максимальное чтение данных вершины: минимальные/средние/максимальные значения каждого из прочитанных данных вершин.
Длительность: время настенных часов, которое занимает этап, необходимо загрузить профиль, чтобы увидеть это значение.
Воспроизведение заданий
Data Lake Analytics выполняет задания и архивирует информацию о вершинах, выполняющих задания, такую как время запуска, остановки, сбоя и повторных попытках выполнения и т. д. Все сведения автоматически заносятся в хранилище запросов и хранятся в его профиле задания. Профиль задания можно скачать через "Профиль загрузки" в представлении задания и просмотреть воспроизведение задания после скачивания профиля задания.
Воспроизведение заданий — это визуализация того, что произошло в кластере. Это помогает отслеживать ход выполнения задания и визуально обнаруживать аномалии производительности и узкие места в очень короткое время (менее 30 секунд обычно).
Отображение тепловой карты работы
Тепловая карта задания можно выбрать в раскрывающемся списке "Отображение" в графе заданий.

В нем показана тепловая карта, отображающая ввод-вывод, время и пропускную способность задания, с помощью которой можно определить, где задание тратит большую часть времени, является ли задание с ограничением по вводу-выводу и так далее.

- Ход выполнения задания: сведения о ходе выполнения задания см. в сведениях о стадии.
- Чтение и запись данных: тепловая карта общего объема данных, считанных и записанных на каждом этапе.
- Время вычислений: тепловая карта суммы (время выполнения каждой вершины). Можно считать это временем, которое потребуется, если вся работа на стадии выполняется только одной вершиной.
- Среднее время выполнения на узел: тепловая карта СУММА (время выполнения каждой вершины) / (число вершин). Это означает, что если вы можете назначить все вершины, исполняемые параллельно, весь процесс будет завершён за этот промежуток времени.
- Пропускная способность ввода и вывода: тепловая карта входной и выходной пропускной способности каждого этапа, с помощью которой вы можете подтвердить, является ли ваше задание ограниченной вводом-выводом задачей.
-
Операции метаданных
Некоторые операции метаданных можно выполнять в скрипте U-SQL, например создать базу данных, удалить таблицу и т. д. Эти операции отображаются в операции метаданных после компиляции. Вы можете найти утверждения, создать сущности, удалить сущности здесь.

Журнал состояний
Журнал состояний также визуализирован в сводке заданий, но вы можете получить дополнительные сведения здесь. Вы можете найти подробную информацию, такую как время подготовки задания, постановки в очередь, начала выполнения и завершения работы. Кроме того, можно узнать, сколько раз было скомпилировано задание (CcsAttempts: 1), когда задание отправляется в кластер фактически (детализация: отправка задания в кластер) и т. д.

Диагностика
Средство автоматически диагностирует выполнение задания. Вы получите оповещения при возникновении некоторых ошибок или проблем с производительностью в заданиях. Обратите внимание, что вам нужно скачать профиль, чтобы получить полную информацию здесь.

- Предупреждения: оповещение отображается здесь с предупреждением компилятора. Вы можете выбрать ссылку "Проблемы x", чтобы получить дополнительные сведения после появления оповещения.
- Вершина выполняется слишком долго: если какая-либо вершина истекает (скажем, 5 часов), проблемы будут найдены здесь.
- Использование ресурсов: если выделено больше или недостаточно параллелизма, чем требуется, то здесь будут найдены проблемы. Кроме того, вы можете выбрать использование ресурсов, чтобы просмотреть дополнительные сведения и выполнить сценарии, чтобы найти лучшее выделение ресурсов (дополнительные сведения см. в этом руководстве).
- Проверка памяти. Если любая вершина использует более 5 ГБ памяти, то здесь будут найдены проблемы. Выполнение задания может быть убито системой, если она использует больше памяти, чем ограничение системы.
Job Detail ("Сведения о задании").
Подробные сведения о задании включают информацию о скрипте, ресурсах и представлении выполнения вершин.

Сценарий
Скрипт U-SQL задания хранится в хранилище запросов. При необходимости можно просмотреть исходный скрипт U-SQL и повторно отправить его.
Ресурсы
Выходные данные компиляции заданий, хранящиеся в хранилище запросов, можно найти с помощью ресурсов. Например, можно найти "algebra.xml", который используется для отображения графа заданий, зарегистрированных сборок и т. д. здесь.
Представление выполнения вершин
В нем показаны сведения о выполнении вершин. Профиль задания архивирует каждый журнал выполнения вершин, например общий объем данных, прочитанных и записанных, время работы, состояние и т. д. Этот обзор позволяет получить более подробную информацию о том, как выполнялось задание. Дополнительные сведения см. в разделе "Использование представления выполнения вершин в средствах Data Lake для Visual Studio".
Дальнейшие шаги
- Сведения о диагностике см. в разделе "Доступ к журналам диагностики" для Azure Data Lake Analytics
- Более сложный запрос можно посмотреть в разделе Анализ журналов веб-сайта с помощью аналитики озера данных Azure.
- Сведения об использовании представления выполнения вершин см. в разделе "Использование представления выполнения вершин в средствах Data Lake для Visual Studio"