Примечание.
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
ПРИМЕНИМО К: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Совет
Data Factory в Microsoft Fabric — это следующее поколение Azure Data Factory с более простой архитектурой, встроенным ИИ и новыми функциями. Если вы не знакомы с интеграцией данных, начните с Fabric Data Factory. Существующие рабочие нагрузки ADF могут обновляться до Fabric для доступа к новым возможностям в области обработки и анализа данных, аналитики в режиме реального времени и отчетов.
В этой статье описывается, как использовать действие копирования для копирования данных из Amazon Simple Storage Service (Amazon S3) и использования Data Flow для преобразования данных в Amazon S3. Дополнительные сведения см. в вводных статьях по Azure Data Factory и Synapse Analytics.
Совет
Дополнительные сведения о сценарии миграции данных из Amazon S3 в Azure Storage см. в статье Migrate data from Amazon S3 to Azure Storage.
Поддерживаемые возможности
Этот соединитель Amazon S3 предназначен для поддержки следующих возможностей:
| Поддерживаемые возможности | IR |
|---|---|
| Copy activity (источник/-) | (1) (2) |
| Сопоставление потока данных (источник/приемник) | (1) |
| Операция поиска | (1) (2) |
| Действие GetMetadata | (1) (2) |
| Удалить активность | (1) (2) |
(1) Azure среды выполнения интеграции (2) локальная среда выполнения интеграции
В частности, этот соединитель Amazon S3 поддерживает копирование файлов "как есть" или анализ файлов с использованием поддерживаемых форматов файлов и кодеков сжатия. Можно также сохранить метаданные файла во время копирования. Для проверки подлинности запросов в S3 соединитель использует подпись AWS версии 4.
Совет
Сведения о том, как скопировать данные из любого поставщика хранилища, совместимого с S3, см. в статье Хранилище, совместимое с Amazon S3.
Необходимые разрешения
Для копирования данных из Amazon S3 убедитесь в том, что вам предоставлены следующие разрешения для операций с объектами Amazon S3: s3:GetObject и s3:GetObjectVersion.
Если вы используете интерфейс Data Factory для создания, для выполнения таких операций, как тестирование подключения к связанной службе и просмотр из корня, требуются дополнительные разрешения s3:ListAllMyBuckets и s3:ListBucket/s3:GetBucketLocation. Если вы не хотите предоставлять эти разрешения, можно выбрать в пользовательском интерфейсе параметры "Тестирование подключения к пути к файлу" или "Просмотр по указанному пути".
Полный список разрешений Amazon S3 см. в статье, посвященной назначению разрешений в политике на сайте AWS.
Начало работы
Для выполнения действия копирования с конвейером можно использовать один из следующих средств или пакетов SDK:
- Средство копирования данных
- портал Azure
- SDK .NET
- пакет SDK Python
- Azure PowerShell
- REST API
- шаблон Azure Resource Manager
Создание связанной службы Amazon Simple Storage Service (S3) с помощью пользовательского интерфейса
Выполните следующие действия, чтобы создать связанную службу Amazon S3 в пользовательском интерфейсе портала Azure.
Перейдите на вкладку "Управление" в рабочей области Azure Data Factory или Synapse и выберите "Связанные службы", а затем нажмите кнопку "Создать".
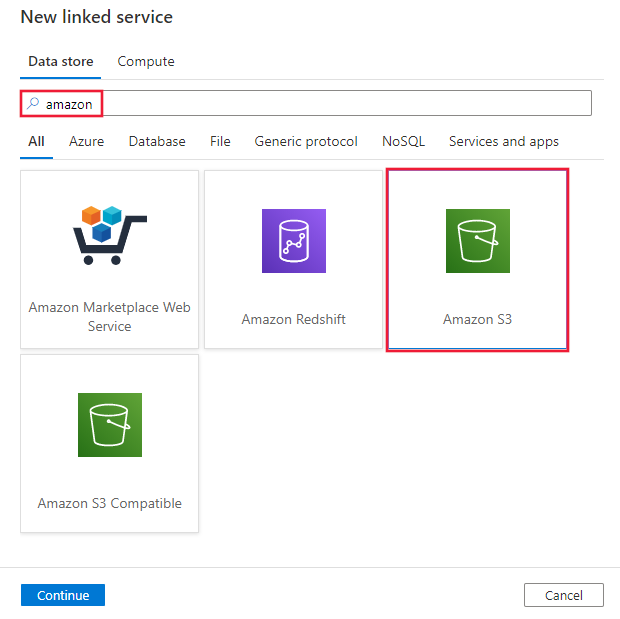
Выполните поиск Amazon и выберите соединитель Amazon S3.
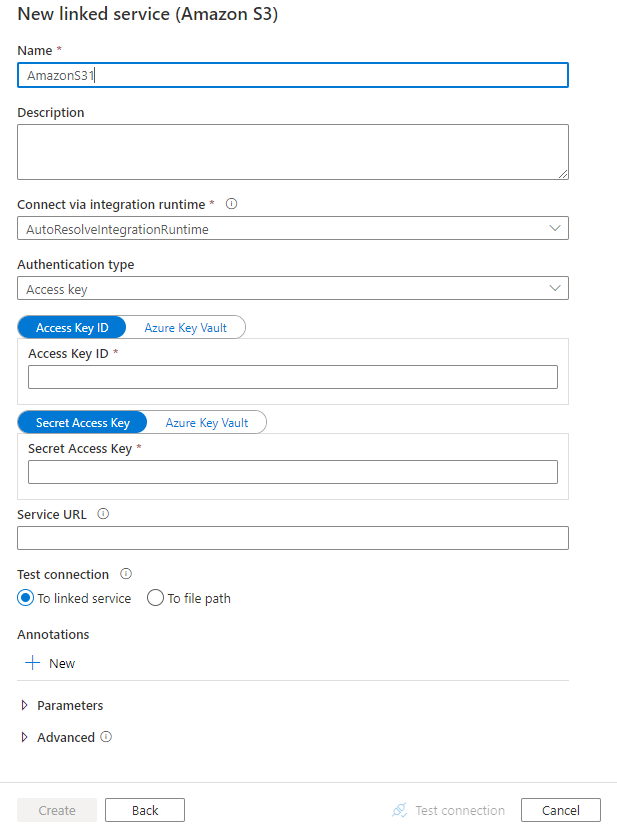
Настройте сведения о службе, проверьте подключение и создайте связанную службу.


Сведения о конфигурации соединителя
Следующие разделы содержат сведения о свойствах, которые используются для определения сущностей фабрики данных, характерных для Amazon S3.
Свойства связанной службы
Для связанной службы Amazon S3 поддерживаются следующие свойства.
| Свойство | Описание: | Обязательное поле |
|---|---|---|
| тип | Для свойства type необходимо задать значение AmazonS3. | Да |
| тип аутентификации | Укажите тип проверки подлинности, используемый для подключения к Amazon S3. Вы можете использовать ключи доступа для учетной записи Системы управления идентификацией и доступом AWS или временные учетные данные безопасности. Допустимые значения: AccessKey (по умолчанию) и TemporarySecurityCredentials. |
Нет |
| идентификаторКлючаДоступа | Идентификатор секретного ключа доступа. | Да |
| секретныйКлючДоступа | Сам секретный ключ доступа. Пометьте это поле как SecureString для безопасного хранения или сошлитесь на секрет, хранящийся в Azure Key Vault. | Да |
| токен сессии | Применяется при использовании аутентификации с временными учетными данными безопасности. Узнайте, как запросить временные учетные данные безопасности в AWS. Обратите внимание, что срок действия временных учетных данных AWS истекает в течение 15 минут — 36 часов в зависимости от параметров. Убедитесь, что ваши учетные данные допустимы при выполнении активности, особенно в случае рабочей нагрузки, например, можно периодически обновлять и хранить их в Azure Key Vault. Пометьте это поле как SecureString для безопасного хранения или сошлитесь на секрет, хранящийся в Azure Key Vault. |
Нет |
| serviceUrl | Укажите настраиваемую конечную точку S3 https://<service url>.Измените ее только в том случае, если вы хотите попробовать другую конечную точку службы или переключиться между https и http. |
Нет |
| connectVia | Среда выполнения интеграции, используемая для подключения к хранилищу данных. Можно использовать среду выполнения интеграции Azure или локальную среду выполнения интеграции (если хранилище данных находится в частной сети). Если это свойство не указано, служба использует среду выполнения интеграции по умолчанию Azure. | Нет |
Пример. Использование проверки подлинности ключа доступа
{
"name": "AmazonS3LinkedService",
"properties": {
"type": "AmazonS3",
"typeProperties": {
"accessKeyId": "<access key id>",
"secretAccessKey": {
"type": "SecureString",
"value": "<secret access key>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Пример: использование аутентификации с временными учетными данными безопасности
{
"name": "AmazonS3LinkedService",
"properties": {
"type": "AmazonS3",
"typeProperties": {
"authenticationType": "TemporarySecurityCredentials",
"accessKeyId": "<access key id>",
"secretAccessKey": {
"type": "SecureString",
"value": "<secret access key>"
},
"sessionToken": {
"type": "SecureString",
"value": "<session token>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Свойства набора данных
Полный список разделов и свойств, доступных для определения наборов данных, см. в статье о наборах данных.
Azure Data Factory поддерживает следующие форматы файлов. Дополнительные сведения о параметрах с учетом форматирования см. в соответствующих статьях.
- Формат Avro
- Двоичный формат
- Формат текста с разделителями
- формат Excel
- Формат JSON
- Формат ORC
- Формат Parquet
- ФОРМАТ XML
Поддерживаются следующие свойства для Amazon S3 в настройках location в наборе данных, основанном на формате.
| Свойство | Описание: | Обязательное поле |
|---|---|---|
| тип | Свойство type в location для набора данных должно быть AmazonS3Location. |
Да |
| bucketName | Имя контейнера S3. | Да |
| folderPath | Путь к папке в заданном контейнере. Если вы хотите использовать подстановочный знак для фильтрации папок, пропустите этот параметр и укажите его в параметрах источника действия. | Нет |
| Имя файла | Имя файла в заданном контейнере и путь к папке. Если вы хотите использовать подстановочный знак для фильтрации файлов, пропустите этот параметр и укажите его в параметрах источника действия. | Нет |
| версия | Версия объекта S3, если включено управление версиями S3. Если значение не указано, будет выбрана последняя версия. | Нет |
Пример:
{
"name": "DelimitedTextDataset",
"properties": {
"type": "DelimitedText",
"linkedServiceName": {
"referenceName": "<Amazon S3 linked service name>",
"type": "LinkedServiceReference"
},
"schema": [ < physical schema, optional, auto retrieved during authoring > ],
"typeProperties": {
"location": {
"type": "AmazonS3Location",
"bucketName": "bucketname",
"folderPath": "folder/subfolder"
},
"columnDelimiter": ",",
"quoteChar": "\"",
"firstRowAsHeader": true,
"compressionCodec": "gzip"
}
}
}
Свойства Copy activity
Полный список разделов и свойств, используемых для определения действий, см. в статье Конвейеры. Этот раздел содержит список свойств, поддерживаемых источником Amazon S3.
Amazon S3 как тип источника
Azure Data Factory поддерживает следующие форматы файлов. Дополнительные сведения о параметрах с учетом форматирования см. в соответствующих статьях.
- Формат Avro
- Двоичный формат
- Формат текста с разделителями
- формат Excel
- Формат JSON
- Формат ORC
- Формат Parquet
- ФОРМАТ XML
Ниже перечислены свойства, которые поддерживаются для Amazon S3 в настройках storeSettings, относящихся к исходному источнику копирования, основанному на формате.
| Свойство | Описание: | Обязательное поле |
|---|---|---|
| тип | Для свойства type в разделе storeSettings необходимо задать значение AmazonS3ReadSettings. |
Да |
| Найдите файлы для копирования: | ||
| ВАРИАНТ 1. Статический путь |
Копирование из заданного контейнера или папки/пути к файлу, которые указаны в наборе данных. Если вы хотите скопировать все файлы из контейнера или папки, дополнительно укажите wildcardFileName как *. |
|
| ВАРИАНТ 2. Префикс S3 - префикс |
Префикс для имени ключа S3 в заданном контейнере, настроенном в наборе данных для фильтрации исходных файлов S3. Выбираются ключи S3, имена которых начинаются с bucket_in_dataset/this_prefix. Он использует фильтр на стороне сервиса S3, который более эффективен, чем фильтр с подстановочными символами.При использовании префикса и копировании в файловый приемник с сохранением иерархии, обратите внимание, что под-путь после последнего символа "/" в префиксе будет сохранен. Например, если у вас есть источник bucket/folder/subfolder/file.txt, и вы настроили префикс как folder/sub, то сохраненный путь к файлу будет subfolder/file.txt. |
Нет |
| Вариант 3: Подстановочный знак — подстановочный знакFolderPath |
Путь к папке с подстановочными знаками в заданном контейнере, настроенном в наборе данных для фильтрации исходных папок. Допустимые знаки подстановки: * (соответствует нулю или нескольким символам) и ? (соответствует нулю или одному символу). Используйте ^ для экранирования символов, если имя папки содержит подстановочный знак или эту управляющую последовательность. Дополнительные примеры приведены в разделе Примеры фильтров папок и файлов. |
Нет |
| Вариант 3: Подстановочный знак — wildcardFileName |
Имя файла с использованием подстановочных символов в заданном контейнере и путь к папке (или путь к папке с подстановочными символами) для фильтрации исходных файлов. Допустимые знаки подстановки: * (соответствует нулю или нескольким символам) и ? (соответствует нулю или одному символу). Используйте ^ для экранирования, если имя файла содержит подстановочный знак или escape-последовательность. Дополнительные примеры приведены в разделе Примеры фильтров папок и файлов. |
Да |
| ВАРИАНТ 4. Список файлов - fileListPath |
Указывает, что нужно скопировать заданный набор файлов. Укажите текстовый файл со списком файлов, которые необходимо скопировать, по одному файлу в строке (каждая строка должна содержать относительный путь к заданному в наборе данных пути). При использовании этого варианта не указывайте имя файла в наборе данных. Ознакомьтесь с дополнительными примерами в разделе Примеры списков файлов. |
Нет |
| Дополнительные параметры: | ||
| рекурсивный | Указывает, считываются ли данные рекурсивно из подпапок или только из указанной папки. Обратите внимание, что если для свойства recursive задано значение true, а приемником является файловое хранилище, пустые папки и вложенные папки не создаются в приемнике. Допустимые значения: true (по умолчанию) и false. Это свойство не применяется при настройке fileListPath. |
Нет |
| удалитьФайлыПослеЗавершения | Указывает, удаляются ли двоичные файлы из исходного хранилища после успешного перемещения в конечное хранилище. Файлы удаляются поочередно, поэтому в случае сбоя действия копирования вы увидите, что некоторые файлы уже скопированы в место назначения и удалены из источника, в то время как остальные находятся в исходном хранилище. Это свойство допустимо только в сценарии копирования двоичных файлов. По умолчанию имеет значение false. |
Нет |
| modifiedDatetimeStart | Фильтр файлов на основе атрибута времени последнего изменения. Будут выбраны все файлы, у которых время последнего изменения больше или равно modifiedDatetimeStart и меньше modifiedDatetimeEnd. Время представлено часовым поясом UTC в формате "2018-12-01T05:00:00Z". Эти свойства могут иметь значение NULL. Это означает, что фильтры атрибута файла не будут применяться к этому набору данных. Если для параметра modifiedDatetimeStart задано значение даты и времени, но параметр modifiedDatetimeEnd имеет значение NULL, то выбираются файлы, чей атрибут времени последнего изменения больше указанного значения даты и времени или равен ему. Если для параметра modifiedDatetimeEnd задано значение даты и времени, но параметр modifiedDatetimeStart имеет значение NULL, то выбираются файлы, чей атрибут времени последнего изменения меньше указанного значения даты и времени.Это свойство не применяется при настройке fileListPath. |
Нет |
| modifiedDatetimeEnd | То же, что выше. | Нет |
| ВключитьОбнаружениеРазделов | Для секционированных файлов укажите, следует ли анализировать секции из пути к файлу и добавлять их как дополнительные исходные столбцы. Допустимые значения: false (по умолчанию) и true. |
Нет |
| partitionRootPath | Если обнаружение секций включено, укажите абсолютный корневой путь, чтобы считывать секционированные папки как столбцы данных. Если параметр не задан (по умолчанию), происходит следующее. — При использовании пути к файлу в наборе данных или списке файлов в источнике корневым путем секции считается путь, настроенный в наборе данных. — При использовании фильтра по папке с подстановочными знаками корневой путь раздела определяется как часть пути до первого подстановочного знака. — При использовании префикса корневой путь секции — это вложенный путь перед последним символом "/". Предположим, что вы настроили путь в наборе данных следующим образом: "root/folder/year=2020/month=08/day=27". — Если указать корневой путь секции "root/folder/year=2020", действие копирования в дополнение к указанным в файлах столбцам создаст еще два столбца, month и day, со значениями "08" и "27" соответственно.— Если корневой путь секции не указан, дополнительные столбцы создаваться не будут. |
Нет |
| максимальное количество одновременных подключений | Верхний предел одновременных подключений, установленных в хранилище данных во время выполнения активности. Указывайте значение только при необходимости ограничить количество одновременных подключений. | Нет |
Пример:
"activities":[
{
"name": "CopyFromAmazonS3",
"type": "Copy",
"inputs": [
{
"referenceName": "<Delimited text input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "DelimitedTextSource",
"formatSettings":{
"type": "DelimitedTextReadSettings",
"skipLineCount": 10
},
"storeSettings":{
"type": "AmazonS3ReadSettings",
"recursive": true,
"wildcardFolderPath": "myfolder*A",
"wildcardFileName": "*.csv"
}
},
"sink": {
"type": "<sink type>"
}
}
}
]
Примеры фильтров папок и файлов
В этом разделе описывается поведение пути папки и имени файла при использовании фильтров с подстановочными знаками.
| контейнер | ключ | рекурсивный | Структура исходной папки и результат фильтрации (извлекаются файлы, выделенные полужирным шрифтом) |
|---|---|---|---|
| контейнер | Folder*/* |
ложь | контейнер ПапкаA Файл1.csv File2.json Вложенная папка1 File3.csv File4.json File5.csv Другая папка B Файл6.csv |
| контейнер | Folder*/* |
true | контейнер ПапкаA Файл1.csv File2.json Вложенная папка1 File3.csv File4.json File5.csv Другая папка B Файл6.csv |
| контейнер | Folder*/*.csv |
ложь | контейнер ПапкаA Файл1.csv File2.json Вложенная папка1 File3.csv File4.json File5.csv Другая папка B Файл6.csv |
| контейнер | Folder*/*.csv |
true | контейнер ПапкаA Файл1.csv File2.json Вложенная папка1 File3.csv File4.json File5.csv Другая папка B Файл6.csv |
Примеры списков файлов
В этом разделе описывается поведение при использовании пути списка файлов в источнике операции копирования.
Предположим, что у вас есть следующая исходная структура папок и вы хотите скопировать файлы, выделенные полужирным шрифтом:
| Пример исходной структуры | Содержимое в файле FileListToCopy.txt | Настройка |
|---|---|---|
| контейнер ПапкаA Файл1.csv File2.json Вложенная папка1 File3.csv File4.json File5.csv Метаданные FileListToCopy.txt |
Файл1.csv Вложенная папка1/Файл3.csv Subfolder1/Файл5.csv |
В наборе данных: – Контейнер: bucket– Путь к папке: FolderAВ источнике действия "Копирование": – Путь к списку файлов: bucket/Metadata/FileListToCopy.txt Путь к списку файлов указывает на текстовый файл в том же хранилище данных. Этот текстовый файл содержит список файлов, которые вы хотите скопировать. Каждый файл указан на новой строке с относительным путём, который соотносится с путём, заданным в наборе данных. |
Сохранение метаданных файла во время копирования
При копировании файлов из Amazon S3 в Azure Data Lake Storage Gen2 или Azure Blob-хранилище вы можете выбрать сохранение метаданных файла наряду с данными. Подробнее см. в разделе Сохранение метаданных.
Сопоставление свойств потока данных
При преобразовании данных в потоках данных для сопоставления можно считывать файлы из Amazon S3 в следующих форматах:
Конкретные параметры приведены в документации для соответствующего формата. Для получения дополнительной информации, смотрите статью Трансформация источника в потоке сопоставления данных.
Преобразование источника
В преобразовании источника можно выполнять чтение из контейнера, папки или отдельного файла в Amazon S3. Используйте вкладку Параметры источника для управления чтением файлов.

Пути с подстановочными знаками: Использование шаблона с подстановочными знаками указывает службе перебрать каждую соответствующую папку и файл в ходе одного преобразования источника. Это эффективный способ обработки нескольких файлов в одном потоке. Добавьте несколько шаблонов сопоставления с подстановочными знаками с помощью значка "плюс", который появляется при наведении указателя мыши на существующий шаблон с подстановочными знаками.
В исходном контейнере выберите файлы, соответствующие шаблону. В наборе данных можно указать только контейнер. Ваш путь с подстановочными знаками должен также включать путь к папке, начиная с корневой папки.
Примеры подстановочных знаков:
*— представляет любой набор символов.**— представляет рекурсивную вложенность каталога.?— заменяет один символ.[]— соответствует одному или нескольким символам в квадратных скобках./data/sales/**/*.csv— возвращает все файлы .csv в папке /data/sales./data/sales/20??/**/— возвращает все файлы, созданные в 20 веке./data/sales/*/*/*.csv— возвращает файлы .csv, расположенные двумя уровнями ниже папки /data/sales./data/sales/2004/*/12/[XY]1?.csv— возвращает все файлы .csv, созданные в декабре 2004 года, которые начинаются с X или Y с двузначным числом в качестве префикса.
Корневой путь раздела. Если в источнике файлов имеются секционированные папки формата key=value (например, year=2019), то верхний уровень этого дерева секционированной папки можно назначить имени столбца в потоке данных.
Во-первых, задайте подстановочный знак, чтобы включить все пути, которые содержатся в секционированных папках, и конечные файлы, которые вы хотите прочитать.

Для определения верхнего уровня структуры папок используйте параметр Корневой путь раздела. При просмотре содержимого данных с помощью предварительного просмотра данных вы увидите, что служба добавляет разрешенные разделы, найденные на каждом уровне папок.

Список файлов: это набор файлов. Создайте текстовый файл, который включает список относительных путей файлов для обработки. Укажите на этот текстовый файл.
Столбец для хранения имени файла: сохраните имя исходного файла в столбце в данных. Укажите здесь новое имя столбца для хранения строки имени файла.
После завершения: выберите ничего делать с исходным файлом после запуска потока данных, удалите исходный файл или переместите исходный файл. Пути для перемещения являются относительными.
Чтобы переместить исходные файлы в другое расположение после обработки, сначала выберите "Переместить" для операции с файлом. Затем задайте исходный каталог. Если вы не используете подстановочные знаки для пути, в настройке "from" будет использоваться та же папка, что и ваш исходный каталог.
Если имеется исходный путь с подстановочным знаком, синтаксис будет выглядеть следующим образом.
/data/sales/20??/**/*.csv
Можно указать «from» как:
/data/sales
А в качестве целевой точки можно указать:
/backup/priorSales
В этом случае все файлы, источником которых является папка /data/sales, перемещаются в папку /backup/priorSales.
Примечание.
Операции с файлами выполняются только при запуске потока данных из конвейера данных (отладка или выполнение конвейера), который использует действие выполнения потока данных в конвейере. Операции с файлами не выполняются в режиме отладки Data Flow.
Фильтр по последнему изменению: вы можете фильтровать файлы, обрабатываемые путем указания диапазона дат последнего изменения. Все значения даты и времени указаны в формате UTC.
Свойства действия поиска
Подробные сведения об этих свойствах см. в разделе Действие поиска.
Свойства операции GetMetadata
Подробные сведения об этих свойствах см. в статье Действие GetMetadata.
Свойства удаления активности
Чтобы узнать подробности о свойствах, ознакомьтесь со статьей Удаление активности.
Устаревшие модели
Примечание.
Следующие модели по-прежнему поддерживаются на условиях "как есть" для обеспечения обратной совместимости. Рекомендуется использовать новую модель, упомянутую ранее. Интерфейс создания контента переключился на генерацию новой модели.
Устаревшая модель набора данных
| Свойство | Описание: | Обязательное поле |
|---|---|---|
| тип | Свойство типа для набора данных должно быть AmazonS3Object. | Да |
| bucketName | Имя контейнера S3. Фильтр подстановочных знаков не поддерживается. | Yes для действия Copy/Lookup, No для действия GetMetadata |
| ключ | Имя или фильтр подстановочных знаков ключа объекта S3 в указанном контейнере. Применяется, только если свойство prefix не указано. Фильтр с подстановочными знаками поддерживается как для части пути к папке, так и для части имени файла. Допустимые знаки подстановки: * (соответствует нулю или нескольким символам) и ? (соответствует нулю или одному символу).Пример 1. "key": "rootfolder/subfolder/*.csv"Пример 2. "key": "rootfolder/subfolder/???20180427.txt"Дополнительные примеры приведены в разделе Примеры фильтров папок и файлов. Используйте ^ для экранирования, если фактическое имя папки или файла содержит подстановочный знак или является этим escape-символом. |
Нет |
| prefix | Префикс для ключа объекта S3. Выбираются объекты, ключи которых начинаются с этого префикса. Применяется, только если свойство key не указано. | Нет |
| версия | Версия объекта S3, если включено управление версиями S3. Если версия не указана, будет выбрана последняя версия. | Нет |
| modifiedDatetimeStart | Фильтр файлов на основе атрибута времени последнего изменения. Будут выбраны все файлы, у которых время последнего изменения больше или равно modifiedDatetimeStart и меньше modifiedDatetimeEnd. Время представлено часовым поясом UTC в формате "2018-12-01T05:00:00Z". Помните, что включение этого параметра в случае, если требуется использовать фильтр файлов с огромными объемами файлов, влияет на общую производительность перемещения данных. Эти свойства могут иметь значение NULL. Это означает, что фильтры атрибута файла не будут применяться к этому набору данных. Если для параметра modifiedDatetimeStart задано значение даты и времени, но параметр modifiedDatetimeEnd имеет значение NULL, то выбираются файлы, чей атрибут времени последнего изменения больше указанного значения даты и времени или равен ему. Если для параметра modifiedDatetimeEnd задано значение даты и времени, но параметр modifiedDatetimeStart имеет значение NULL, то выбираются файлы, чей атрибут времени последнего изменения меньше указанного значения даты и времени. |
Нет |
| modifiedDatetimeEnd | Фильтр файлов на основе атрибута времени последнего изменения. Будут выбраны все файлы, у которых время последнего изменения больше или равно modifiedDatetimeStart и меньше modifiedDatetimeEnd. Время представлено часовым поясом UTC в формате "2018-12-01T05:00:00Z". Помните, что включение этого параметра в случае, если требуется использовать фильтр файлов с огромными объемами файлов, влияет на общую производительность перемещения данных. Эти свойства могут иметь значение NULL. Это означает, что фильтры атрибута файла не будут применяться к этому набору данных. Если для параметра modifiedDatetimeStart задано значение даты и времени, но параметр modifiedDatetimeEnd имеет значение NULL, то выбираются файлы, чей атрибут времени последнего изменения больше указанного значения даты и времени или равен ему. Если для параметра modifiedDatetimeEnd задано значение даты и времени, но параметр modifiedDatetimeStart имеет значение NULL, то выбираются файлы, чей атрибут времени последнего изменения меньше указанного значения даты и времени. |
Нет |
| формат | Если требуется скопировать файлы между файловыми хранилищами "как есть" (двоичное копирование), можно пропустить раздел форматирования в определениях входного и выходного наборов данных. Если нужно проанализировать или создать файлы определенного формата, поддерживаются следующие типы форматов файлов: TextFormat, JsonFormat, AvroFormat, OrcFormat, ParquetFormat. Свойству type в разделе format необходимо присвоить одно из этих значений. Дополнительные сведения см. в разделах о текстовом формате, формате JSON, формате Avro, формате Orc и формате Parquet. |
Нет (только для сценария двоичного копирования) |
| сжатие | Укажите тип и уровень сжатия данных. Дополнительные сведения см. в разделе Поддержка сжатия. Поддерживаемые типы: GZip, Deflate, BZip2 и ZipDeflate. Поддерживаемые уровни: Optimal и Fastest. |
Нет |
Совет
Чтобы скопировать все файлы в папке, укажите bucketName для контейнеров и prefix для части папки.
Чтобы скопировать один файл с заданным именем, укажите bucketName для контейнеров и key для части папки вместе с именем файла.
Чтобы скопировать подмножество файлов в папке, укажите bucketName для контейнеров и key для части папки и фильтра подстановочных знаков.
Пример. Использование префикса
{
"name": "AmazonS3Dataset",
"properties": {
"type": "AmazonS3Object",
"linkedServiceName": {
"referenceName": "<Amazon S3 linked service name>",
"type": "LinkedServiceReference"
},
"typeProperties": {
"bucketName": "testbucket",
"prefix": "testFolder/test",
"modifiedDatetimeStart": "2018-12-01T05:00:00Z",
"modifiedDatetimeEnd": "2018-12-01T06:00:00Z",
"format": {
"type": "TextFormat",
"columnDelimiter": ",",
"rowDelimiter": "\n"
},
"compression": {
"type": "GZip",
"level": "Optimal"
}
}
}
}
Пример. Использование ключа и версии (необязательно)
{
"name": "AmazonS3Dataset",
"properties": {
"type": "AmazonS3",
"linkedServiceName": {
"referenceName": "<Amazon S3 linked service name>",
"type": "LinkedServiceReference"
},
"typeProperties": {
"bucketName": "testbucket",
"key": "testFolder/testfile.csv.gz",
"version": "XXXXXXXXXczm0CJajYkHf0_k6LhBmkcL",
"format": {
"type": "TextFormat",
"columnDelimiter": ",",
"rowDelimiter": "\n"
},
"compression": {
"type": "GZip",
"level": "Optimal"
}
}
}
}
Устаревшая исходная модель для Copy activity
| Свойство | Описание: | Обязательное поле |
|---|---|---|
| тип | Свойство type источника Copy activity должно иметь значение FileSystemSource. | Да |
| рекурсивный | Указывает, считываются ли данные рекурсивно из подпапок или только из указанной папки. Обратите внимание, что, если для свойства recursive задано значение true, а приемником является файловое хранилище, пустые папки и вложенные папки не копируются и не создаются в приемнике. Допустимые значения: true (по умолчанию) и false. |
Нет |
| максимальное количество одновременных подключений | Верхний предел одновременных подключений, установленных в хранилище данных во время выполнения активности. Указывайте значение только при необходимости ограничить количество одновременных подключений. | Нет |
Пример:
"activities":[
{
"name": "CopyFromAmazonS3",
"type": "Copy",
"inputs": [
{
"referenceName": "<Amazon S3 input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "FileSystemSource",
"recursive": true
},
"sink": {
"type": "<sink type>"
}
}
}
]
Связанный контент
Список хранилищ данных, поддерживаемых Copy activity в качестве источников и приемников, см. в разделе Сопортированные хранилища данных.