Примечание.
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
Azure Data Explorer — это быстрая полностью управляемая служба аналитики данных. Он предлагает анализ в режиме реального времени на больших объемах данных, которые передаются из многих источников, таких как приложения, веб-сайты и устройства Интернета вещей.
Чтобы скопировать данные из базы данных в Oracle Server, Netezza, Teradata или SQL Server в Azure Data Explorer, необходимо загрузить огромные объемы данных из нескольких таблиц. Обычно данные должны быть секционированы в каждой таблице, чтобы можно было загружать строки с несколькими потоками параллельно из одной таблицы. В этой статье описывается шаблон, используемый в этих сценариях.
Шаблоны фабрики данных Azure являются стандартными конвейерами фабрики данных. Эти шаблоны помогут быстро приступить к работе с фабрикой данных и сократить время разработки в проектах интеграции с данными.
Вы создаете шаблон массового копирования из базы данных в Azure Data Explorer с помощью преобразований Lookup и ForEach. Для ускорения копирования данных можно использовать шаблон для создания множества конвейеров для каждой базы данных или таблицы.
Это важно
Не забудьте использовать средство, соответствующее количеству данных, которые требуется скопировать.
- Используйте шаблон массового копирования из базы данных в Azure Data Explorer, чтобы копировать большие объемы данных из таких баз данных, как SQL Server и Google BigQuery, в Azure Data Explorer.
- Используйте инструмент копирования данных в Data Factory, чтобы скопировать несколько таблиц с небольшими или средними объемами данных в Azure Data Explorer.
Предпосылки
- Подписка Azure. Создайте бесплатную учетную запись Azure.
- Кластер и база данных Azure Data Explorer. Создайте кластер и базу данных.
- Фабрика данных. Создайте фабрику данных.
- Источник данных.
Создать ControlTableDataset
ControlTableDataset указывает, какие данные будут скопированы из источника в место назначения в конвейере. Число строк указывает общее количество конвейеров, необходимых для копирования данных. Необходимо определить ControlTableDataset как часть исходной базы данных.
Пример формата исходной таблицы SQL Server показан в следующем коде:
CREATE TABLE control_table (
PartitionId int,
SourceQuery varchar(255),
ADXTableName varchar(255)
);
Элементы кода описаны в следующей таблице:
| Недвижимость | Описание | Пример |
|---|---|---|
| Идентификатор раздела | Порядок копирования | 1 |
| SourceQuery | Запрос, указывающий, какие данные будут скопированы в процессе выполнения конвейера | select * from table where lastmodifiedtime LastModifytime >= ''2015-01-01 00:00:00''>
|
| ADXTableName | Имя целевой таблицы | MyAdxTable |
Если ваш набор данных ControlTableDataset находится в другом формате, создайте подходящий набор данных ControlTableDataset для вашего формата.
Используйте шаблон массового копирования из базы данных в Azure Data Explorer
В области "Начало работы" выберите "Создать конвейер из шаблона", чтобы открыть панель галереи шаблонов.
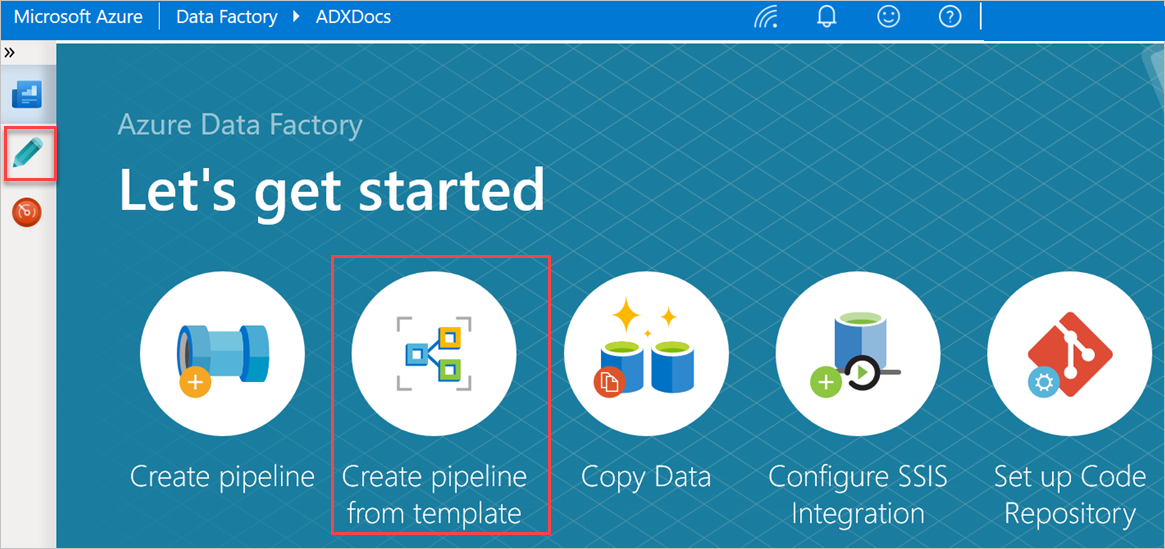
Выберите шаблон массового копирования из базы данных в Azure Data Explorer.

В области массового копирования из базы данных в Azure Data Explorer под Входные данные пользователей укажите наборы данных, выполнив следующие действия:
a. В раскрывающемся списке ControlTableDataset выберите связанную службу к таблице управления, которая указывает, какие данные копируются из источника в место назначения и в какое место назначения он будет помещен.
б. В раскрывающемся списке SourceDataset выберите связанную службу с исходной базой данных.
с. В раскрывающемся списке AzureDataExplorerTable выберите таблицу Azure Data Explorer. Если набор данных не существует, создайте связанную службу Azure Data Explorer для добавления набора данных.
д. Выберите Использовать этот шаблон.

Выберите область на холсте, вне области действий, чтобы получить доступ к шаблонной схеме. Перейдите на вкладку "Параметры ", чтобы ввести параметры таблицы, включая имя (имя таблицы управления) и значение по умолчанию (имена столбцов).
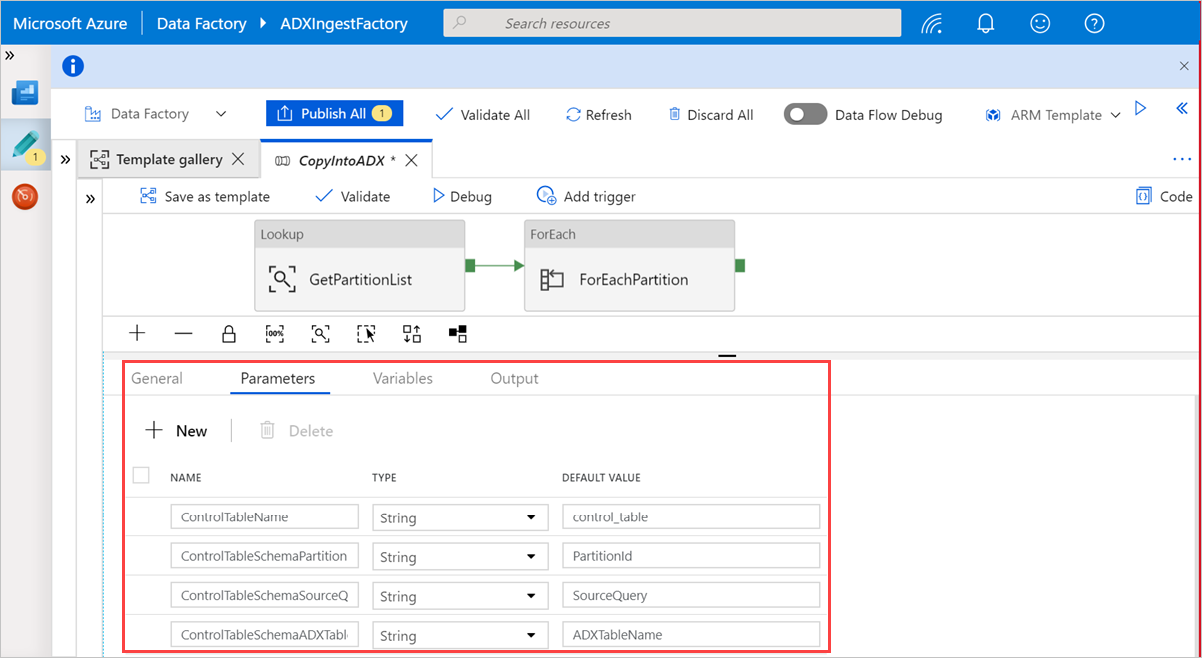
В разделе "Поиск" выберите GetPartitionList , чтобы просмотреть параметры по умолчанию. Запрос создается автоматически.
Выберите действие "Команда", ForEachPartition, перейдите на вкладку "Параметры " и выполните следующие действия:
a. В поле "Число пакетов " введите число от 1 до 50. Этот выбор определяет количество конвейеров, выполняемых параллельно, пока не будет достигнуто число строк ControlTableDataset .
б. Чтобы убедиться, что пакеты конвейера выполняются параллельно, не установите флажок "Последовательный".

Подсказка
Рекомендуется параллельно запускать множество конвейеров, чтобы можно было быстрее копировать данные. Чтобы повысить эффективность, разделите данные в исходной таблице и выделите одну секцию на конвейер в соответствии с датой и таблицей.
Выберите "Проверить все ", чтобы проверить конвейер Фабрики данных Azure, а затем просмотрите результат на панели "Вывод проверки конвейера ".
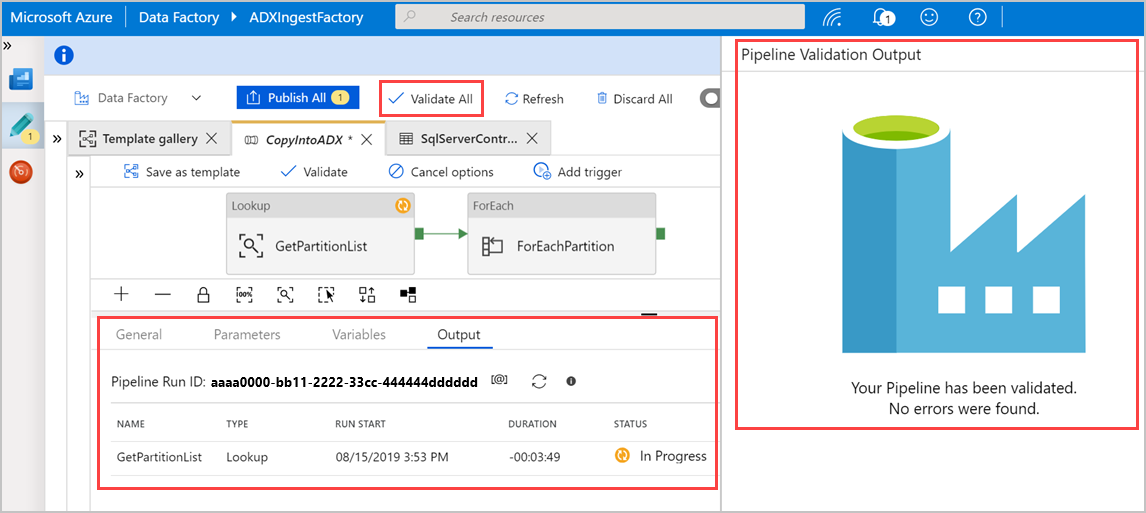
При необходимости выберите "Отладка" и нажмите кнопку "Добавить триггер " для запуска конвейера.

Теперь шаблон можно использовать для эффективного копирования больших объемов данных из баз данных и таблиц.
Связанный контент
- Сведения о соединителе Azure Data Explorer для Фабрики данных Azure.
- Изменение связанных служб, наборов данных и конвейеров в пользовательском интерфейсе фабрики данных.
- Запрос данных в веб-интерфейсе Azure Data Explorer.