Примечание
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
ОБЛАСТЬ ПРИМЕНЕНИЯ: ![]() NoSQL
NoSQL
Внимание
Советы по производительности в этой статье предназначены только для пакета SDK для Python для Azure Cosmos DB. Дополнительные сведения см. в Readme, заметках о выпуске пакета SDK для Python для Azure Cosmos DB, пакета (PyPI), пакета (Conda) и руководстве по устранению неполадок.
Azure Cosmos DB — быстрая и гибкая распределенная база данных, которая легко масштабируется с гарантированной задержкой и пропускной способностью. Для масштабирования базы данных с помощью Azure Cosmos DB не нужно вносить в архитектуру существенные изменения или писать сложный код. Для увеличения или уменьшения масштаба достаточно вызвать один метод интерфейса API или пакета SDK. Тем не менее, так как доступ к Azure Cosmos DB осуществляется через сетевые вызовы, существуют клиентские оптимизации, которые можно сделать для достижения пиковой производительности при использовании пакета SDK Python для Azure Cosmos DB.
Поэтому, если вы хотите повысить производительность базы данных, рассмотрите следующие варианты:
Сеть
- Повышение производительности за счет размещения клиентов в одном регионе Azure
Если это возможно, размещайте приложения, выполняющие вызовы к Azure Cosmos DB, в том же регионе, в котором находится база данных Azure Cosmos DB. Для приблизительного сравнения: вызовы к Azure Cosmos DB в пределах региона выполняются в течение 1–2 мс, но задержка между Восточным и Западным побережьем США превышает 50 мс. Значение задержки может отличаться в зависимости от выбранного маршрута при передаче запроса от клиента к границе центра обработки данных Azure. Минимальная возможная задержка достигается при размещении клиентского приложения в том же регионе Azure, в котором предоставляется конечная точка Azure Cosmos DB. Список доступных регионов см. на странице Регионы Azure.
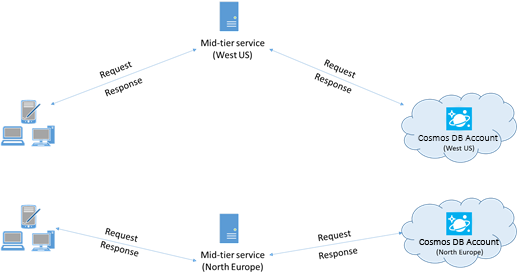
Приложение, взаимодействующее с учетной записью Azure Cosmos DB с несколькими регионами, должно настроить предпочтительные расположения, чтобы запросы направлялись в соответствующий регион.
Включите ускоренную сеть для уменьшения задержки и переменности задержки ЦП
Рекомендуется следовать инструкциям, чтобы включить ускоренную сеть в Windows (выберите инструкции) или Linux (выберите инструкции) виртуальной машины Azure, чтобы повысить производительность (уменьшить задержку и jitter ЦП).
Без ускорения сети операции ввода-вывода, передаваемые между виртуальной машиной Azure и другими ресурсами Azure, могут быть ненужно перенаправлены через узел и виртуальный коммутатор, расположенный между виртуальной машиной и ее сетевой картой. Наличие узла и виртуального коммутатора внутри пути данных не только увеличивает задержку и дрожание в коммуникационном канале, но также приводит к краже циклов ЦП у виртуальной машины. Благодаря ускоренной сети виртуальная машина взаимодействует напрямую с сетевой картой, без посредников; все сведения о политике сети, которые ранее обрабатывались узлом и виртуальным коммутатором, теперь обрабатываются оборудованием на сетевой карте, а узел и виртуальный коммутатор обходятся. При включении ускоренной сети, как правило, можно ожидать снижение задержки и увеличение пропускной способности, а также улучшение согласованности задержки и снижение загрузки ЦП.
Ограничения: ускоренная сеть должна поддерживаться в ОС виртуальной машины и может быть включена только при остановке и освобождении виртуальной машины. Виртуальную машину невозможно развернуть с помощью Azure Resource Manager. Служба приложений не включает ускоренную сеть.
Дополнительные сведения см. в инструкциях для Windows и Linux.
Высокая доступность
Общие рекомендации по настройке высокой доступности в Azure Cosmos DB см. в статье "Высокий уровень доступности" в Azure Cosmos DB.
Помимо хорошей базовой настройки платформы баз данных, аварийный выключатель уровня раздела может быть реализован в Python SDK, что может помочь в случае сбоя. Эта функция предлагает расширенные механизмы решения проблем доступности, превосходящие возможности повторных попыток между регионами, встроенные в пакет SDK по умолчанию. Это может значительно повысить устойчивость и производительность приложения, особенно в условиях высокой нагрузки или снижения уровня нагрузки.
Автоматический выключатель на уровне раздела
Сечение уровней разделов (PPCB) в пакете SDK для Python повышает доступность и устойчивость путем отслеживания работоспособности отдельных физических секций и перенаправления запросов от проблемных. Эта функция особенно полезна для обработки временных и конечных проблем, таких как проблемы сети, обновления секций или миграции.
PPCB применяется в следующих сценариях:
- Любой уровень согласованности
- Операции с ключом раздела (точечные чтения/записи)
- Учетные записи одного региона записи с несколькими регионами чтения
- Несколько учетных записей для записи в регионах
Принцип работы
Секции переходят через четыре состояния — работоспособная, неработоспособная предварительная, неработоспособная и работоспособная предварительная — на основе успешного выполнения или сбоя запросов.
- Отслеживание сбоев: Пакет SDK отслеживает частоту ошибок (например, 5xx, 408) на секцию в течение одной минуты. Последовательные сбои по каждой перегородке отслеживаются бессрочно программным комплектом разработки (SDK).
- Пометка как недоступной: Если секция превышает настроенные пороговые значения, она помечается как временно неработоспособная и исключается из маршрутизации на 1 минуту.
- Переход в состояние 'Неработоспособный' или 'Восстановление': Если попытка восстановления завершается ошибкой, раздел переходит в состояние неработоспособный. После интервала задержки выполняется зондирование здорового предварительного состояния с ограниченным временем запроса для определения восстановления.
- Восстановление: Если предварительное тестирование успешно выполнено, секция возвращается в Исправно. В противном случае она остается нездоровой до следующей проверки.
Этот механизм переключения управляется внутренне пакетом SDK и гарантирует, что запросы избегают известных проблемных секций, пока их работоспособность не будет подтверждена снова.
Настройка с помощью переменных среды
Вы можете управлять поведением PPCB с помощью следующих переменных среды:
| Переменная | Описание | По умолчанию |
|---|---|---|
AZURE_COSMOS_ENABLE_CIRCUIT_BREAKER |
Включение и отключение PPCB | false |
AZURE_COSMOS_CONSECUTIVE_ERROR_COUNT_TOLERATED_FOR_READ |
Максимальное число последовательных сбоев чтения перед тем, как раздел будет отмечен как недоступный | 10 |
AZURE_COSMOS_CONSECUTIVE_ERROR_COUNT_TOLERATED_FOR_WRITE |
Максимальное количество последовательных сбоев записи перед пометкой раздела как недоступного | 5 |
AZURE_COSMOS_FAILURE_PERCENTAGE_TOLERATED |
Пороговое значение процента сбоев перед изменением статуса раздела на недоступный | 90 |
Подсказка
Дополнительные параметры конфигурации могут быть предоставлены в будущих выпусках для точной настройки длительности ожидания и поведения отката восстановления.
Использование пакета SDK
- Установка последней версии пакета SDK
Пакеты SDK для Azure Cosmos DB постоянно улучшаются, чтобы обеспечивать самую высокую производительность. Ознакомьтесь с заметками о выпуске пакета SDK для Azure Cosmos DB, чтобы определить самый последний пакет SDK и просмотреть улучшения.
- Использование одного и того же клиента Azure Cosmos DB в течение всего жизненного цикла приложения
Каждый экземпляр клиента Azure Cosmos DB является потокобезопасным, а также эффективно управляет подключениями и кэширует адреса. Чтобы обеспечить эффективное управление подключениями и повысить производительность клиента Azure Cosmos DB, рекомендуется использовать один экземпляр клиента Azure Cosmos DB в течение всего времени существования приложения.
- Настройка конфигураций времени ожидания и повторных попыток
Конфигурации времени ожидания и политики повторных попыток можно настроить в зависимости от потребностей приложения. Ознакомьтесь с документом по настройкам времени ожидания и повторных попыток, чтобы получить полный список конфигураций, которые можно настроить.
- Использование минимально необходимого уровня согласованности для приложения
При создании CosmosClient используется согласованность на уровне учетной записи, если она не указана при создании клиента. Дополнительные сведения о уровнях согласованности см. в документе о уровнях согласованности.
- Горизонтальное увеличение масштаба рабочей нагрузки клиента
Если вы тестируете на высоких уровнях пропускной способности, клиентское приложение может стать узким местом из-за исчерпания ресурсов компьютера на ЦП или использовании сети. Если вы достигли этой точки, то можете повысить производительность Azure Cosmos DB, развернув клиентские приложения на нескольких серверах.
Общее правило заключается в том, чтобы не превышать загрузку ЦП >50% на любом конкретном сервере для снижения задержки.
- Лимит на ресурсы открытых файлов ОС
Некоторые дистрибутивы Linux (например, RedHat) ограничивают максимальное число открытых файлов и общее число подключений. Чтобы узнать текущие ограничения, выполните следующую команду:
ulimit -a
Количество открытых файлов (nofile) должно быть достаточно большим, чтобы иметь достаточно места для настроенного размера пула подключений и других открытых файлов ОС. Можно изменить параметры, чтобы увеличить размер пула соединений.
Откройте файл limits.conf:
vim /etc/security/limits.conf
Добавьте или измените следующие строки:
* - nofile 100000
Операции запросов
Операции с запросами см. в разделе Рекомендации по повышению производительности запросов.
Политика индексирования
- Исключите неиспользуемые пути из индексирования, чтобы ускорить выполнение операций записи
Политика индексирования Azure Cosmos DB позволяет вам указывать, какие пути к документам включать или исключать из индексирования, используя пути индексирования (setIncludedPaths и setExcludedPaths). Возможность управления путями индексирования позволяет оптимизировать производительность записи и снизить затраты на хранение индекса для сценариев с заранее определенными шаблонами запросов. Это связано с тем, что затраты на индексирование непосредственно зависят от количества уникальных путей индексирования. Например, в следующем коде показано, как с помощью подстановочного знака "*" включать в индексацию и исключать из нее целые разделы документов (также называемые поддеревьями).
container_id = "excluded_path_container"
indexing_policy = {
"includedPaths" : [ {'path' : "/*"} ],
"excludedPaths" : [ {'path' : "/non_indexed_content/*"} ]
}
db.create_container(
id=container_id,
indexing_policy=indexing_policy,
partition_key=PartitionKey(path="/pk"))
Дополнительные сведения см. в статье Политики индексации Azure Cosmos DB.
Пропускная способность
- Измерение и настройка для снижения использования единиц запроса в секунду
Azure Cosmos DB предоставляет обширный набор операций с документами в коллекции базы данных, в том числе реляционные и иерархические запросы с использованием UDF, хранимых процедур и триггеров. Затраты, связанные с каждой из этих операций, зависят от типа процессора, операций ввода-вывода и памяти, необходимой для завершения операции. Вместо того чтобы думать о закупке и управлении аппаратными ресурсами, вы можете думать о единице запроса (RU) как единой меры для ресурсов, необходимых для выполнения различных операций с базами данных и обслуживания запросов приложений.
Пропускная способность выделяется на основе количества единиц запроса, заданного для каждого контейнера. Удельный расход единиц запросов оценивается в расчете на одну секунду. Частота запросов для приложений, у которых она превышает подготовленные единицы запросов для контейнера, будет ограничена, пока она не упадет ниже зарезервированного для контейнера уровня. Если приложению требуется более высокий уровень пропускной способности, можно увеличить ее путем выделения дополнительных единиц запросов.
Сложность запроса влияет на количество единиц запроса, потребляемых операцией. Количество и характер предикатов, количество UDF, размер набора исходных данных — все это влияет на затраты на операции запроса.
Чтобы оценить расходы на любую операцию (создание, обновление или удаление), проверьте значение заголовка x-ms-request-charge. Это значение содержит число единиц запроса, потребляемых соответствующей операцией.
document_definition = {
'id': 'document',
'key': 'value',
'pk': 'pk'
}
document = container.create_item(
body=document_definition,
)
print("Request charge is : ", container.client_connection.last_response_headers['x-ms-request-charge'])
Стоимость запроса, указанная в этом заголовке, представляет собой долю вашей подготовленной пропускной способности. Например, если вы предоставили 2000 единиц запроса в секунду, а приведенный выше запрос возвращает 1000 документов размером по 1 КБ каждый, затраты на операцию составят 1000 единиц. Таким образом, перед ограничением частоты выполнения последующих запросов сервер за одну секунду выполняет только два таких запроса. Чтобы узнать больше, ознакомьтесь с единицами запроса и калькулятором единиц запроса.
- Обработка ограничения скорости / слишком высокая частота запросов
Выполнение запроса, который превышает лимит зарезервированной пропускной способности для учетной записи, не приводит к снижению производительности сервера, так как пользователь не сможет превысить это зарезервированное значение. Сервер заранее завершит запрос с ошибкой RequestRateTooLarge (код состояния HTTP: 429) и вернет заголовок x-ms-retry-after-ms, индиицирующий время (в миллисекундах), которое пользователь должен подождать, прежде чем повторно попытаться выполнить этот запрос.
HTTP Status 429,
Status Line: RequestRateTooLarge
x-ms-retry-after-ms :100
SDK автоматически перехватывают этот ответ, обрабатывают заголовок retry-after, указанный сервером, и отправляют запрос повторно. Если к вашей учетной записи параллельно имеет доступ только один клиент, следующая попытка будет успешной.
Если у вас есть несколько клиентов, которые совокупно работают с превышением скорости запросов, количество повторных попыток по умолчанию, установленное в настоящее время клиентом на уровне 9, может оказаться недостаточным. В этом случае клиент выдает объект CosmosHttpResponseError с кодом состояния 429 для приложения. Число повторных попыток по умолчанию можно изменить, передав retry_total конфигурацию клиенту. По умолчанию CosmosHttpResponseError с кодом статуса 429 возвращается после совокупного времени ожидания в течение 30 секунд, если запрос продолжает превышать лимит скорости запросов. Это происходит, даже если текущее значение количества повторных попыток (по умолчанию (9) или определенное пользователем) меньше максимального значения.
Хотя автоматическое повторное выполнение запроса помогает улучшить устойчивость и удобство использования большинства приложений, оно может встать в противоречие при проведении тестов производительности, особенно при измерении задержек. Если эксперимент достигает ограничения сервера и заставляет клиентский SDK повторять попытки в тихом режиме, на стороне клиента могут возникать пиковые задержки. Чтобы избежать пиков задержек во время экспериментов с производительностью, измерьте возвращаемый заряд каждой операции и убедитесь, что частота запросов не превышает зарезервированное значение. Дополнительные сведения см. в статье Единицы запросов.
- Использование меньших документов для более высокой пропускной способности
Стоимость запроса (плата за обработку запроса) для каждой операции напрямую зависит от размера документа. Операции с большими документами стоят больше, чем операции с маленькими документами. Оптимальнее всего проектировать приложение и рабочие процессы с размером элемента около 1 КБ либо с размером схожего порядка или величины. Для приложений, чувствительных к задержке, следует избегать крупных элементов — документы размером в несколько мегабайт замедлят работу приложения.
Следующие шаги
Дополнительные сведения о создании приложения с высокой масштабируемостью и производительностью см. в статье Partitioning and scaling in Azure Cosmos DB (Секционирование и масштабирование в Azure Cosmos DB).
Если вы планируете ресурсы для миграции в Azure Cosmos DB, Для планирования ресурсов можно использовать сведения об имеющемся кластере базы данных.
- Если вам известно только количество виртуальных ядер и серверов в существующем кластере баз данных, см. сведения об оценке единиц запросов на основе виртуальных ядер и серверов.
- Если вам известна стандартная частота запросов для текущей рабочей нагрузки базы данных, ознакомьтесь со статьей о расчете единиц запросов с помощью планировщика ресурсов Azure Cosmos DB