Примечание.
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
Применимо к:![]() База данных SQL Azure
База данных SQL Azure
В этой статье рассматривается модель приобретения vCore для База данных SQL Azure.
Обзор
Виртуальная ядро (vCore) представляет логический ЦП и предлагает вам возможность выбрать физические характеристики оборудования (например, количество ядер, память и размер хранилища). Модель приобретения на основе виртуальных ядер обеспечивает гибкость, контроль, прозрачность использования отдельных ресурсов и простой способ преобразования требований к локальной рабочей нагрузке в облако. Эта модель оптимизирует цену и позволяет выбирать ресурсы вычислений, памяти и хранилища в зависимости от потребностей рабочей нагрузки.
В модели приобретения на основе vCore ваши затраты зависят от выбора и использования:
- Уровень служб
- Конфигурация оборудования
- Вычислительные ресурсы (количество виртуальных ядер и объем памяти)
- Зарезервированное хранилище базы данных
- Фактическое хранилище резервных копий
Это важно
Вычислительные ресурсы, операции ввода-вывода, а также данные и журналы взимаются за каждую базу данных или эластичный пул. Оплата за хранилище резервных копий взимается за каждую базу данных. Сведения о ценах см. на странице цен База данных SQL Azure.
Сравните модели покупки vCore и DTU
Модель приобретения виртуальных ядер, используемая База данных SQL Azure, предоставляет несколько преимуществ по сравнению с моделью приобретения на основе DTU:
- Более высокие пределы вычислительных ресурсов, памяти, операций ввода-вывода и хранилища.
- Выбор конфигурации оборудования для лучшего соответствия требованиям к вычислительным ресурсам и памяти рабочей нагрузки.
- Скидки на цены с помощью Преимущество гибридного использования Azure (AHB).
- Большая прозрачность в деталях аппаратного обеспечения, питающего вычислительные ресурсы, облегчает планирование миграции с локальных развертываний.
- Цены на резервированные экземпляры доступны только для модели покупки vCore.
- Более высокая степень детализации масштабирования с несколькими доступными размерами вычислительных ресурсов.
Чтобы получить помощь в выборе между моделями приобретения виртуальных ядер и DTU, см. раздел различия между моделями приобретения на основе виртуальных ядер и DTU.
Вычисление
Модель приобретения на основе виртуальных ядер имеет предоставленный уровень вычислительных ресурсов и уровень бессерверных вычислений. В подготовленном уровне вычислений затраты на вычисления отражают общую емкость вычислений, постоянно подготовленную для приложения независимо от действия рабочей нагрузки. Выберите выделение ресурсов, которое лучше всего подходит для вашего бизнеса в зависимости от требований к виртуальным ядрам и памяти, а затем масштабируйте ресурсы вверх и вниз по мере необходимости в рабочей нагрузке. В бессерверном уровне вычислений для База данных SQL Azure вычислительные ресурсы автоматически масштабируются на основе емкости рабочей нагрузки и выставляются счета за объем используемых вычислений в секунду.
Бессерверные технологии поддерживаются только на оборудовании Standard-series (Gen5).
Чтобы свести итоги, выполните приведенные ниже действия.
- Хотя уровень вычислений в подготовленном режиме предоставляет определенный объем вычислительных ресурсов, которые постоянно подготавливаются независимо от активности рабочей нагрузки, уровень вычислений в бессерверном режиме автоматически масштабирует вычислительные ресурсы в зависимости от активности рабочей нагрузки.
- Хотя уровень выделенных вычислений тарифицируется по объему выделенных ресурсов и по фиксированной цене за час, бессерверный вычислительный уровень тарифицируется по объему использованных вычислений, в секунду.
Независимо от уровня вычислений, три дополнительных вторичных реплики высокой доступности автоматически выделяются на уровне сервиса "Критически важный для бизнеса", чтобы обеспечить устойчивость к сбоям и быструю отработку отказа. Эти дополнительные реплики делают стоимость примерно в 2,7 раза выше, чем на уровне обслуживания общего назначения. Аналогичным образом, более высокая стоимость хранения на ГБ в уровне служб "Критически важный для бизнеса" отражает более высокие ограничения операций ввода-вывода и низкую задержку локального хранилища SSD.
В Гипермасштабировании клиенты управляют количеством дополнительных реплик высокой доступности от 0 до 4, чтобы получить уровень устойчивости, необходимый для своих приложений при управлении затратами.
Дополнительные сведения о вычислениях в База данных SQL Azure см. в разделе Compute resources (ЦП и память).
Ограничения ресурсов
Для ограничений ресурсов виртуальных ядер сначала изучите доступные конфигурации оборудования, а затем ознакомьтесь с ограничениями ресурсов для следующих элементов:
Хранилище данных и журналов
Следующие факторы влияют на объем хранилища, используемого для файлов данных и журналов, и применяются к уровням "Общего назначения" и "Критически важный для бизнеса".
- Каждый размер вычислительных ресурсов поддерживает настраиваемый максимальный размер данных с размером по умолчанию 32 ГБ.
- При настройке максимального размера данных для файла журнала автоматически добавляется дополнительное 30 процентов оплачиваемого хранилища.
- На уровне служб общего назначения
tempdbиспользует локальное хранилище SSD, и эта стоимость хранения включается в цену виртуальных ядер. - На уровне обслуживания "Критически важный для бизнеса"
tempdbиспользуется совместно с локальным хранилищем SSD для файлов данных и журналов, а стоимость хранилищаtempdbвходит в цену виртуальных ядер. - В категориях "Общего назначения" и "Критически важный для бизнеса" взимается плата за максимальный размер хранилища, настроенный для базы данных или эластичного пула.
- Для базы данных SQL можно выбрать любой максимальный размер данных в диапазоне от 1 ГБ до максимального размера поддерживаемого хранилища в 1 ГБ.
Следующие соображения по хранению применяются к Hyperscale.
- Максимальный размер хранилища данных имеет значение 128 ТБ и не настраивается.
- Плата взимается только за выделенное хранилище данных, а не для максимального хранилища данных.
- Плата за хранение журналов не взимается.
-
tempdbиспользует локальное хранилище SSD, а стоимость хранилища включается в цену виртуальных ядер. Чтобы отслеживать текущий размер выделенного и используемого хранилища данных в базе данных SQL, используйте метрики allocated_data_storage и storage в Azure Monitor соответственно.
Чтобы отслеживать текущий выделенный и используемый размер хранилища отдельных данных и файлов журналов в базе данных с помощью T-SQL, используйте представление sys.database_files и функцию FILEPROPERTY(... , SpaceUsed).
Подсказка
В некоторых случаях может потребоваться уменьшить базу данных, чтобы освободить неиспользуемое пространство. Для получения дополнительной информации см. Управление файловым пространством в базе данных Azure SQL.
Хранилище резервных копий
Хранилище для резервных копий базы данных выделяется для поддержки возможностей восстановления в определенный момент времени (PITR) и долгосрочного хранения (LTR) в базе данных SQL. Это хранилище отличается от хранилища данных и файлов журнала и оплачивается отдельно.
- PITR. В уровнях "Общего назначения" и "Критически важный для бизнеса" резервные копии отдельных баз данных копируются в хранилище Azure. Размер хранилища увеличивается динамически по мере создания новых резервных копий. Хранилище используется для полного, разностного и резервного копирования журналов транзакций. Потребление хранилища зависит от скорости изменения базы данных и периода хранения, настроенного для резервного копирования. Можно настроить отдельный период хранения для каждой базы данных в диапазоне от 1 до 35 дней для базы данных SQL. Объем хранилища резервных копий, равный заданному максимальному размеру данных, предоставляется без дополнительной платы.
- LTR. Вы также можете настроить долгосрочное хранение полных резервных копий до 10 лет. Если вы настроили политику LTR, эти резервные копии хранятся в хранилище BLOB-объектов Azure автоматически, но вы можете контролировать частоту копирования резервных копий. Для удовлетворения различных требований соответствия можно выбрать различные периоды хранения для еженедельных, ежемесячных и /или ежегодных резервных копий. Выбранная конфигурация определяет, сколько хранилища используется для резервных копий LTR. Дополнительные сведения см. в разделе долгосрочное хранение резервных копий.
Сведения о хранилище резервных копий в Hyperscale см. в автоматизированных резервных копий для баз данных Hyperscale.
Уровни служб
Параметры уровня служб в модели приобретения виртуальных ядер включают общее назначение, критически важный для бизнеса и гипермасштабирование. Уровень служб обычно определяет тип хранилища и производительность, высокий уровень доступности и аварийного восстановления, а также доступность некоторых функций, таких как In-Memory OLTP.
| сценарий использования | Категория общего назначения | критически важные для бизнеса | гипермасштаб |
|---|---|---|---|
| лучше всего подходит для | Большинство рабочих нагрузок в бизнесе Предоставляет бюджетные, сбалансированные и масштабируемые параметры вычислений и хранилища. | Предлагает бизнес-приложениям максимальную устойчивость к сбоям с помощью нескольких вторичных реплик высокого уровня доступности и обеспечивает максимальную производительность ввода-вывода. | Самый широкий спектр рабочих нагрузок, включая те с высоко масштабируемым хранилищем и требованиями к масштабированию чтения. Обеспечивает более высокую устойчивость к сбоям, разрешая настройку нескольких вторичных реплик высокого уровня доступности. |
| размер вычислительных ресурсов | 2–128 виртуальных процессорных ядер | 2–128 виртуальных процессорных ядер | 2–192 виртуальных ядер |
| тип хранилища | Удаленное хранилище класса Premium (для каждого экземпляра) | Супер-быстрое локальное SSD-хранилище (для каждого экземпляра) | Отсоединяемое хранилище с локальным кэшем SSD (на реплику вычислений) |
| размер хранилища | 1 ГБ – 4 ТБ | 1 ГБ – 4 ТБ | 10 ГБ – 128 ТБ |
| Макс. IOPS | 320 операций ввода-вывода в секунду на виртуальное ядро с максимальной скоростью 16 000 операций ввода-вывода в секунду | 4000 операций ввода-вывода в секунду на виртуальное ядро с максимальным числом 327 680 операций ввода-вывода в секунду | 5500 операций ввода-вывода в секунду на одно виртуальное ядро при максимальной скорости 544 000 операций ввода-вывода в секунду на локальные SSD. Гипермасштабная архитектура — это многоуровневое строение с кэшированием на нескольких ступенях. Эффективные IOPS зависят от объема рабочей нагрузки. |
| Память/виртуальное ядро | 5,1 ГБ | 5,1 ГБ | 5,1 ГБ или 10,2 ГБ |
| Резервные копии | Выбор геоизбыточного, избыточного в зоне или локально избыточного хранилища резервных копий, 1–35 дней времени хранения (по умолчанию 7 дней) Долгосрочное хранение доступно до 10 лет |
Выбор геоизбыточного, избыточного в зоне или локально избыточного хранилища резервных копий, 1–35 дней времени хранения (по умолчанию 7 дней) Долгосрочное хранение доступно до 10 лет |
Выбор локально избыточного хранилища (LRS), зонально избыточного хранилища (ZRS) или геоизбыточного хранилища (GRS) Срок хранения 1–35 дней (по умолчанию — 7 дней) с сроком хранения до 10 лет. |
| Доступность | Одна реплика, ни одна реплика, не масштабируемая реплика, Высокая доступность с избыточностью по зонам (ВД) |
Три реплики, одна реплика для масштабируемого чтения . Высокая доступность с избыточностью по зонам (ВД) |
Высокая доступность с избыточностью по зонам (ВД) |
| цены и выставление счетов | Плата взимается за vCore, зарезервированное хранилище и хранилище резервных копий. Плата за IOPS не взимается. |
Плата взимается за vCore, зарезервированное хранилище и хранилище резервных копий. Плата за IOPS не взимается. |
плата за vCore для каждой реплики и за используемое хранилище. Плата за IOPS не взимается. |
| модели скидок |
Azure резервирования Преимущество гибридного использования Azure (недоступно для подписок разработки и тестирования) Корпоративные и подписки на предложение для разработки и тестирования с оплатой по мере использования |
Azure резервирования Преимущество гибридного использования Azure (недоступно для подписок разработки и тестирования) Корпоративные и подписки на предложение для разработки и тестирования с оплатой по мере использования |
Преимущество гибридного использования Azure (недоступно в подписках dev/test) 1 Корпоративные и подписки на предложение для разработки и тестирования с оплатой по мере использования |
| таблицы OLTP в памяти | Нет | Да | Нет |
1 Скоро упрощенное ценообразование для гипермасштабируемых баз данных SQL. Ознакомьтесь с блогом о ценах на гипермасштабируемые решения для получения более подробной информации.
Дополнительную информацию можно найти в разделе об ограничениях ресурсов для логического сервера , отдельных баз данных и баз данных в пуле .
Заметка
Дополнительные сведения о соглашении об уровне обслуживания (SLA) см. в разделе SLA для База данных SQL Azure
Общее назначение
Архитектурная модель для уровня служб общего назначения основана на разделении вычислительных ресурсов и хранилища. Эта архитектурная модель зависит от высокой доступности и надежности хранилища BLOB-объектов Azure, которая прозрачно реплицирует файлы базы данных и гарантирует отсутствие потери данных в случае сбоя базовой инфраструктуры.
На следующем рисунке показаны четыре узла в стандартной архитектурной модели с разделенными уровнями вычислений и хранилища.
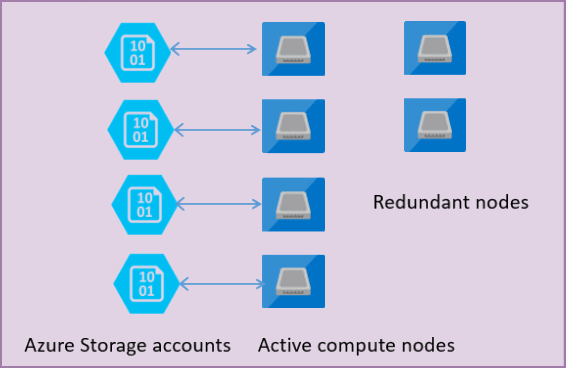
В архитектурной модели для уровня служб общего назначения существует два уровня:
- Бездеятельностный вычислительный уровень, выполняющий процесс
sqlservr.exeи содержащий только временные и кэшированные данные (например, кэш планов, буферный пул и столбцовый пул). Этот безстатусный узел управляется Azure Service Fabric, который инициализирует процесс, контролирует работоспособность узла и выполняет перевод на другой узел при необходимости. - Уровень данных с отслеживанием состояния с файлами базы данных (.mdf/.ldf), которые хранятся в Azure Blob Storage. Azure Blob Storage гарантирует, что данные не будут утеряны для любой записи в файле базы данных. служба хранилища Azure имеет встроенную доступность и избыточность данных, которая гарантирует сохранение каждой записи в файле журнала или странице в файле данных, даже если процесс завершается сбоем.
При обновлении ядра СУБД или операционной системы некоторые части базовой инфраструктуры завершаются сбоем, или если в процессе sqlservr.exe обнаружена какая-либо критическая проблема, Azure Service Fabric перемещает процесс с бессостоянием в другой вычислительный узел с бессостоянием. Существует набор запасных узлов, которые готовы запускать новую вычислительную службу в случае сбоя первичного узла, чтобы свести к минимуму время простоя. Данные в Azure уровне хранения не затрагиваются, а файлы данных и журналов присоединяются к вновь инициализированному процессу. Этот процесс обеспечивает доступность уровня обслуживания корпоративного класса по умолчанию, что увеличивается при реализации избыточности зоны. В результате перехода может негативно сказаться на производительности рабочих нагрузок в процессе выполнения, из-за времени перехода и того факта, что новый узел запускается с холодным кэшем.
Когда выбрать уровень служб общего назначения
Уровень служб общего назначения — это уровень служб по умолчанию в База данных SQL Azure предназначен для большинства универсальных рабочих нагрузок. Если вам нужна полностью управляемая база данных с соглашением об уровне обслуживания по умолчанию и задержкой хранилища в диапазоне от 5 мс до 10 мс, уровень General Purpose — это ваш вариант.
Критически важный для бизнеса
Модель уровня служб "Критически важный для бизнеса" основана на кластере процессов ядра СУБД. Эта архитектурная модель использует кворум узлов ядра СУБД, чтобы свести к минимуму влияние производительности на рабочую нагрузку даже во время обслуживания. Обновления и исправления базовой операционной системы, драйверов и ядра СУБД выполняются прозрачно с минимальным временем простоя для конечных пользователей.
В бизнес-критической модели вычислительные ресурсы и хранилище интегрируются на каждом узле. Репликация данных между процессами ядра СУБД на каждом узле кластера с четырьмя узлами обеспечивает высокую доступность, при этом каждый узел использует локально подключенный SSD в качестве хранилища данных. На следующей схеме показано, как уровень служб "Критически важный для бизнеса" упорядочивает кластер узлов ядра СУБД в репликах группы доступности.

Процесс ядра СУБД и базовые файлы .mdf/.ldf размещаются на одном узле с локально подключенным хранилищем SSD, обеспечивая низкую задержку в рабочей нагрузке. Высокая доступность реализуется с помощью технологии, аналогичной группам доступности SQL Server Always On. Каждая база данных — это кластер узлов базы данных с одной первичной репликой, доступной для клиентских рабочих нагрузок, и тремя вторичными репликами, содержащими копии данных. Первичная реплика постоянно отправляет изменения во вторичные реплики, чтобы обеспечить доступность данных на вторичных репликах, если первичная реплика выходит из строя по какой-либо причине. Отказоустойчивость обеспечивается платформой Service Fabric и движком базы данных – одна вторичная реплика становится основной, и создается новая вторичная реплика, чтобы убедиться, что в кластере достаточно узлов. Рабочая нагрузка автоматически перенаправляется на новую первичную реплику.
Кроме того, в критически важном бизнес-кластере есть встроенная функция масштабирования чтения, которая предоставляет бесплатную реплику только для чтения. Эта реплика используется для выполнения запросов только для чтения (например, отчетов), не влияющих на производительность рабочей нагрузки на вашей основной реплике.
Когда выбирать уровень услуг "Критически важный для бизнеса"
Уровень обслуживания "Критически важный для бизнеса" предназначен для приложений, которые требуют низкой задержки ответов от базового хранилища SSD (в среднем 1–2 мс), быстрого восстановления в случае сбоя базовой инфраструктуры, или при необходимости разгрузки отчётов, аналитики и запросов только для чтения в бесплатную доступную для чтения вторичную реплику основной базы данных.
Основные причины, по которым следует выбрать уровень служб "Критически важный для бизнеса" вместо уровня "Общего назначения":
- требования к низкой задержке ввода-вывода — рабочие нагрузки, которые нуждаются в постоянно быстром ответе слоя хранения (в среднем 1–2 миллисекунды), должны использовать уровень "Критически важный для бизнеса".
- рабочая нагрузка с запросами отчетов и аналитики, где достаточно одной вторичной реплики с доступом только для чтения.
- Более высокая устойчивость и более быстрое восстановление после сбоев. В случае сбоя системы база данных на первичном экземпляре отключена, а одна из вторичных реплик сразу же становится новой базой данных-источником для чтения и записи, готовой к обработке запросов.
- Расширенная защита от повреждения данных. Поскольку уровень "Критически важный для бизнеса" использует реплики баз данных в фоновом режиме, служба применяет автоматическое восстановление страниц, доступное благодаря технологии зеркального отображения и группам доступности, для устранения повреждения данных. Если реплика не может считывать страницу из-за проблемы целостности данных, новая копия страницы извлекается из другой реплики, заменив нечитаемую страницу без потери данных или простоя клиента. Эта функция доступна на уровне общего назначения, если у базы данных есть гео-вторичная реплика.
- Более высокая доступность — уровень "Критически важный для бизнеса" в конфигурации многозонной доступности обеспечивает устойчивость к зональным сбоям и более высокий уровень доступности.
- Быстрое геовосстановление - Если настроена активная георепликация, уровень "Критически важный для бизнеса" имеет гарантированную целевую точку восстановления (RPO) в 5 секунд и целевой момент времени восстановления (RTO) в течение 30 секунд в течение 100% развернутых часов.
Гипермасштаб
Уровень служб "Гипермасштабирование" подходит для всех типов рабочих нагрузок. Ее облачная архитектура обеспечивает независимо масштабируемые вычислительные ресурсы и хранилище для поддержки самых разнообразных традиционных и современных приложений. Ресурсы вычисления и хранения в гипермасштабе значительно превышают ресурсы, доступные на уровнях "Общего назначения" и "Критически важный для бизнеса".
Для получения дополнительной информации ознакомьтесь с уровнем обслуживания Hyperscale для базы данных Azure SQL.
Когда следует выбирать уровень обслуживания HyperScale
Уровень службы Hyperscale снимает многие практические ограничения, традиционно существующие в облачных базах данных. Где большинство других баз данных ограничены ресурсами, доступными в одном узле, базы данных на уровне служб гипермасштабирования не имеют таких ограничений. Благодаря гибкой архитектуре хранилища база данных Hyperscale растет по мере необходимости, и вы оплачиваете только за используемую емкость хранилища.
Помимо расширенных возможностей масштабирования, Hyperscale — отличный вариант для любых рабочих нагрузок, а не только для больших баз данных. С гипермасштабированием можно:
- Добейтесь высокой устойчивости и быстрого восстановления сбоев, при этом управляя затратами, выбрав количество реплик высокой доступности от 0 до 4.
- Улучшите высокую доступность, включив зональную избыточность для вычислений и хранилища.
- Достигайте низкой задержки ввода-вывода (в среднем 1–2 миллисекунды) для часто используемой части вашей базы данных. Для небольших баз данных это может применяться ко всей базе данных.
- Реализуйте широкий выбор сценариев масштабирования чтения с именованными репликами.
- Воспользуйтесь преимуществами быстрого масштабирования, не ожидая копирования данных в локальное хранилище на новых узлах.
- Наслаждайтесь непрерывным резервным копированием базы данных с нулевым воздействием и быстрым восстановлением .
- Поддерживайте требования непрерывности бизнес-процессов с помощью групп отказоустойчивости и георепликации.
Конфигурация оборудования
Распространенные конфигурации оборудования в модели виртуальных ядер включают стандартную серию (5-го поколения), премиум-серию, премиум-серию с оптимизацией для памяти и серию DC. Гипермасштабирование также предоставляет возможность для оборудования серии «Премиум» и оборудования серии «Премиум», оптимизированного для работы с памятью. Конфигурация оборудования определяет ограничения вычислительных ресурсов и памяти и другие характеристики, влияющие на производительность рабочей нагрузки.
Некоторые конфигурации оборудования, такие как стандартная серия (5-го поколения), могут использовать несколько типов процессоров (ЦП), как описано в вычислительных ресурсов (ЦП и памяти). Хотя определенная база данных или эластичные пулы обычно остаются на оборудовании с одинаковым типом ЦП в течение длительного времени (обычно в течение нескольких месяцев), существуют определенные события, которые могут привести к перемещению базы данных или пула в оборудование, использующее другой тип ЦП.
Базу данных или пул можно переместить для различных сценариев, включая, но не ограничивается тем, когда:
- Цель службы изменена
- Текущая инфраструктура в центре обработки данных приближается к ограничениям емкости
- В настоящее время используемое оборудование удаляется из-за окончания срока жизни
- Конфигурация с избыточностью между зонами включена, перенос на другое оборудование из-за наличия доступной емкости.
Для некоторых рабочих нагрузок переход на другой тип ЦП может изменить производительность. База данных SQL настраивает оборудование с целью обеспечить прогнозируемую производительность рабочей нагрузки, даже если тип ЦП изменяется, сохраняя изменения производительности в узком диапазоне. Однако в широком спектре рабочих нагрузок клиентов в базе данных SQL и по мере того, как новые типы ЦП становятся доступными, иногда можно увидеть более заметные изменения производительности, если база данных или пул перемещается на другой тип ЦП.
Независимо от используемого типа ЦП, ограничения ресурсов для базы данных или эластичного пула (например, количество ядер, объем памяти, максимальное число операций ввода-вывода в секунду, максимальная скорость записи журнала и максимальное число одновременных рабочих процессов) остаются неизменными, если база данных остается в той же цели обслуживания.
Вычислительные ресурсы (ЦП и память)
В следующей таблице сравниваются вычислительные ресурсы в различных конфигурациях оборудования и уровнях вычислений для База данных SQL Azure. Для получения информации о Hyperscale см. уровень службы Hyperscale.
| Конфигурация оборудования | ЦПУ | Память |
|---|---|---|
| Стандартная серия (Gen5) |
Выделенные вычислительные ресурсы - Процессоры Intel® E5-2673 v4 (Broadwell) 2,3 ГГц, Intel® SP-8160 (Skylake)*, Intel® 8272CL (Cascade Lake) 2,5 ГГц*, Intel® Xeon® Platinum 8370C (Ice Lake)*, AMD EPYC™ 7763v (Milan)*, AMD EPYC 9004 (Genoa)*, Intel® Xeon® Platinum 8573C (Emerald Rapids)* — Предоставление до 128 виртуальных ядер (с поддержкой технологии Hyper-Threading) бессерверные вычисления - Процессоры Intel® E5-2673 v4 (Broadwell) 2,3 ГГц, Intel® SP-8160 (Skylake)*, Intel® 8272CL (Cascade Lake) 2,5 ГГц*, Intel® Xeon® Platinum 8370C (Ice Lake)*, AMD EPYC™ 7763v (Milan)*, AMD EPYC 9004 (Genoa)*, Intel® Xeon® Platinum 8573C (Emerald Rapids)* — автомасштабирование до 80 виртуальных ядер (с поддержкой гиперпоточности) — Соотношение памяти и виртуальных ядер динамически адаптируется на основе использования памяти и процессора в соответствии с рабочей нагрузкой и может достигать 24 ГБ на vCore. Например, в определенный момент времени рабочей нагрузке может потребоваться 240 ГБ памяти, за которую выставляется счет, в то время как используется только 10 виртуальных ядер. |
Выделенные вычислительные ресурсы — 5,1 ГБ на виртуальное ядро — предоставление до 625 ГБ бессерверные вычисления — автоматическое масштабирование до 24 ГБ на виртуальный процессор — автомасштабирование до 240 ГБ макс. |
| Серия DC | — процессоры Intel® Xeon® E-2288G — с расширением Intel Software Guard (Intel SGX) — предоставление до 8 физических виртуальных ядер |
4,5 ГБ на виртуальное ядро |
| Серия Fsv2** | — Процессоры Intel® 8168 (Skylake) - С поддерживаемой турбочастотой всех ядер 3,4 ГГц и максимальной турбочастотой одного ядра 3,7 ГГц. — предоставление до 72 виртуальных процессоров (гиперпоток) |
— 1,9 ГБ на виртуальное ядро — предоставление до 136 ГБ |
* Для заданного размера вычислительных ресурсов и аппаратной конфигурации ограничения ресурсов одинаковы независимо от типа ЦП (Intel® Broadwell, Skylake, Ice Lake, Cascade Lake, Emerald Rapids или AMD Milan, Genoa). В динамическом представлении управления sys.dm_user_db_resource_governance создание оборудования для баз данных с помощью:
- Процессоры Intel® SP-8160 (Skylake) отображаются в качестве 6-го поколения
- Intel® 8272CL (Cascade Lake) отображается как Gen7
- Intel® Xeon® Platinum 8370C (Ice Lake) или AMD EPYC™ 7763v (Милан) появляются как Gen8
- AMD EPYC™ 9004 (Genoa) появляются как 9-го поколения или Intel® Xeon® Platinum 8573C (Изумрудные рапидс) появляются как 10-го поколения
** Оборудование серии Fsv2 больше недоступно для создания и будет прекращено 1 октября 2026 г.
Дополнительную информацию см. в разделе про ограничения ресурсов для отдельных баз данных
Стандартная серия (Gen5)
Оборудование серии "Стандартный" (5-го поколения) обеспечивает сбалансированные вычислительные ресурсы и ресурсы памяти и подходит для большинства рабочих нагрузок базы данных.
Оборудование серии Standard (Gen5) доступно во всех общедоступных регионах по всему миру.
Премиум-серия с гипермасштабированием
Варианты оборудования серии "Премиум" используют новейшие технологии ЦП и памяти intel и AMD. Серия "Премиум" обеспечивает повышение производительности вычислений относительно оборудования стандартной серии.
- Вариант серии "Премиум" обеспечивает более высокую производительность ЦП по сравнению с серией "Стандартный" и более высоким числом виртуальных ядер.
- Оптимизированный для памяти категории "Премиум" вариант обеспечивает двойной объем памяти относительно категории "Стандартный".
Оптимизированные по памяти серии "Стандартный", "Премиум" и "Премиум-оптимизированный" доступны для гипермасштабируемых эластичных пулов .
Дополнительные сведения см. в объявлении блогао серии "Hyperscale премиум"
Доступные регионы см. в разделе доступности серии "Премиум" Hyperscale .
Серия DC
- Оборудование серии DC использует процессоры Intel с технологией Software Guard Extensions (Intel SGX).
- Для всегда зашифрованных рабочих нагрузок с безопасными анклавами, которые требуют более строгой защиты аппаратных анклавов по сравнению с анклавами безопасности на основе виртуализации (VBS).
- Серия DC предназначена для рабочих нагрузок, обрабатывающих конфиденциальные данные и требующих возможности безопасной обработки запросов, которые обеспечиваются функцией Always Encrypted с безопасными анклавами.
- Оборудование серии DC предоставляет сбалансированные вычислительные ресурсы и ресурсы памяти.
Серия DC поддерживается только для выделенных вычислительных ресурсов (бессерверные не поддерживаются) и не поддерживает зональную отказоустойчивость. Для регионов, в которых доступна серия DC, см. для информации о доступности серии DC.
Типы предложений Azure, поддерживаемые серией DC
Чтобы создать базы данных или эластичные пулы на оборудовании серии DC, подписка должна быть платным типом предложения, включая "Оплата по мере использования" (You-Go) или Корпоративное соглашение (EA). Полный список типов предложений Azure, поддерживаемых серией DC, см. в разделе текущие предложения без лимитов на траты.
Выбор конфигурации оборудования
Вы можете выбрать конфигурацию оборудования для базы данных или эластичного пула в базе данных SQL во время создания. Вы также можете изменить конфигурацию оборудования существующей базы данных или эластичного пула.
Выбор конфигурации оборудования при создании базы данных SQL или пула
Подробные сведения см. в статье Созданиебазы данных SQL.
На вкладке Основные выберите ссылку "Настройка базы данных" в разделе Вычисление и хранилище, а затем щелкните ссылку Изменить конфигурацию:

Выберите нужную конфигурацию оборудования:

Изменение конфигурации оборудования существующей базы данных SQL или пула
Для базы данных на странице "Обзор" выберите ссылку ценовая категория.

Для пула на странице Обзор выберите Настроить.
Выполните действия, чтобы изменить конфигурацию и выбрать конфигурацию оборудования, как описано в предыдущих шагах.
Доступность оборудования
Сведения о доступности оборудования текущего поколения см. в разделе Feature Availability by Region for База данных SQL Azure.
Оборудование предыдущего поколения
Серия Fsv2
Оборудование серии Fsv2 больше не доступно для создания и будет прекращено 1 октября 2026 г.
Чтобы свести к минимуму сбои в работе службы и сохранить соотношение цена-производительность, переходите на оборудование серии Hyperscale премиум или Standard (Gen5). Дополнительные сведения см. в разделе Уведомление об окончании поддержки: предложение База данных SQL Azure серии FSV2. Для большинства баз данных и рабочих нагрузок оборудование Hyperscale серии "Премиум" или "Стандартная" (Gen5) обеспечивает аналогичную или лучшую ценовую производительность по сравнению с Fsv2. Чтобы убедиться, проверьте это с помощью конкретной базы данных и рабочих нагрузок.
- Fsv2 обеспечивает меньше памяти и
tempdbна каждый виртуальный процессор по сравнению с другим оборудованием, поэтому рабочие нагрузки, чувствительные к этим ограничениям, могут работать лучше на стандартной серии (Gen5). - Серия Fsv2 поддерживается только на уровне общего назначения.
4-го поколения
Аппаратное обеспечение 4-го поколения было выведено из эксплуатации и недоступно для использования, масштабирования. Перенос базы данных в поддерживаемое поколение оборудования для более широкого диапазона масштабируемости виртуальных ядер и хранилища, ускорения сети, оптимальной производительности операций ввода-вывода и минимальной задержки. Просмотрите варианты оборудования для отдельных баз данных и варианты оборудования для эластичных пулов. Дополнительные сведения см. в разделе Support завершено для оборудования 4-го поколения на База данных SQL Azure.