Примечание
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
Применимо к: База данных SQL Azure
Бессерверный — это уровень вычислений для отдельных баз данных в базе данных Azure SQL, который автоматически масштабирует вычислительные мощности на основе спроса на рабочую нагрузку и выставляет счета за объем вычислительных ресурсов, используемых в секунду. Уровень бессерверных вычислений также автоматически приостанавливает базы данных в периоды отсутствия активности, когда оплачивается только хранилище, и автоматически возобновляет работу баз данных, когда активность восстанавливается. Уровень бессерверных вычислений доступен на уровне услуг общего назначения и на уровне услуг гипермасштабируемости.
Примечание.
Автоматическая приостановка и автоматическое возобновление в настоящее время поддерживаются только на уровне служб общего назначения.
Обзор
Диапазон автомасштабирования вычислений и задержка автоматической приостановки являются важными параметрами для бессерверного уровня вычислений. Конфигурация этих параметров определяет производительность базы данных и стоимость вычислений.
Настройка производительности
- минимальное число виртуальных ядер и максимальное число виртуальных ядер — это настраиваемые параметры, которые определяют диапазон доступных вычислений для базы данных. Ограничения памяти и операций ввода-вывода пропорциональны указанному диапазону виртуальных ядер.
- Задержка автоматической приостановки — это настраиваемый параметр, определяющий период времени, в течение которого база данных должна быть неактивной, прежде чем она будет автоматически приостановлена. База данных автоматически возобновляется при следующем входе или другом действии. Кроме того, автоматическую приостановку можно отключить.
Себестоимость
Стоимость пользования бессерверной базой данных включает плату за вычисления и хранение. Стоимость ресурсов хранения определяется так же, как и на уровне подготовленных вычислительных ресурсов.
- При использовании вычислений между минимальными и максимальными ограничениями затраты на вычисления основаны на виртуальных ядрах и используемой памяти.
- Если использование вычислений ниже минимальных ограничений, затраты на вычисления основаны на минимальных виртуальных ядрах и минимальной памяти.
- При приостановке базы данных стоимость вычислений будет равна нулю, вы оплачиваете только затраты на хранение.
Для получения более подробной информации о затратах см. раздел Выставление счетов.
Сценарии
Бессерверные решения, оптимизированные по критерию цена-производительность, предназначены для отдельных баз данных с прерывистым и непредсказуемым использованием, где допустима некоторая задержка перед запуском вычислительных мощностей после периодов простоя. В отличие от этого, предоставленный уровень вычислительных ресурсов оптимизирован для соотношения цены и производительности в случае с отдельными базами данных или несколькими базами данных в эластичных пулах с более высоким средним использованием, где недопустима задержка начала работы вычислительных ресурсов.
Оптимальные сценарии для бессерверных вычислений
- Отдельные базы данных с нестабильным и непредсказуемым использованием с периодами бездействия и более низким средним использованием вычислительных ресурсов.
- Single databases in the provisioned compute tier that are frequently rescaled and customers who prefer to delegate compute rescaling to the service.
- Новые отдельные базы данных без истории использования, в которых сложно или невозможно заранее оценить размеры вычислений перед развертыванием в Azure SQL Database.
Scenarios well suited for provisioned compute
- Отдельные базы данных с более равномерным, прогнозируемым использованием ресурсов и увеличенным средним объемом использования вычислительных ресурсов в долгосрочной перспективе.
- Базы данных, для которых недопустимо снижение производительности из-за частого ограничения ресурсов памяти или задержек автоматического возобновления работы из приостановленного состояния.
- Несколько баз данных с непостоянным и непрогнозируемым использованием, которые можно объединить в эластичные пулы для оптимизации соотношения затрат и производительности.
Compare compute tiers
В следующей таблице перечислены различия между уровнями бессерверных вычислений и подготовленных вычислений:
| Бессерверные вычисления | Provisioned compute | |
|---|---|---|
| Сценарий использования баз данных | Нерегулярное и плохо прогнозируемое использование с более низким средним уровнем загрузки вычислительных ресурсов в долгосрочной перспективе. | Более равномерное использование ресурсов, более высокий средний объем использования ресурсов в долгосрочной перспективе или множество баз данных, использующих эластичные пулы. |
| Затраты на управление производительностью | Lower | Higher |
| Масштабирование вычислительных ресурсов | Автоматически | Руководство |
| Отзывчивость вычислений | Низкая после периодов бездействия | Немедленно |
| Billing granularity | Per second | Per hour |
Модель приобретения и уровень обслуживания
В следующей таблице описана бессерверная поддержка на основе модели приобретения, уровней служб и оборудования:
| Категория | Поддерживается | Не поддерживаются |
|---|---|---|
| Модель приобретения | vCore | DTU |
| Уровень служб |
General Purpose Hyperscale |
Критически важный для бизнеса |
| Оборудование | Серия Standard (5-е поколение) | Все другое оборудование |
Автомасштабирование
Scaling responsiveness
Бессерверные базы данных выполняются на компьютере с достаточной емкостью для удовлетворения спроса на ресурсы без прерывания для любого объема вычислительных ресурсов, в пределах ограничений, установленных максимальным значением виртуальных ядер. В некоторых случаях автоматически выполняется балансировка нагрузки, если компьютер не может удовлетворить потребность в ресурсах в течение нескольких минут. For example, if the resource demand is 4 vCores, but only 2 vCores are available, then it can take up to a few minutes to load balance before 4 vCores are provided. База данных остается доступной по сети во время балансировки нагрузки, кроме непродолжительного периода в конце операции, когда подключение прерывается.
Управление памятью
В уровнях служб общего назначения и гипермасштабирования память для бессерверных баз данных часто освобождается, чем для подготовленных вычислительных баз данных. Это важно для контроля над затратами при бессерверных вычислениях и может влиять на производительность.
Cache reclamation
В отличие от подготовленных вычислительных баз данных память из кэша SQL освобождается при использовании бессерверной базы данных при низком уровне использования ЦП и активного кэша.
- Использование активного кэша считается низким, если общий размер последних использованных записей кэша ниже порогового значения в течение определенного периода времени.
- При активации освобождения кэша целевой размер кэша постепенно уменьшается до доли от прошлого размера. Освобождение продолжается только в том случае, если уровень использования остается низким.
- В случае освобождения кэша политика выбора записей в кэше для удаления остается такой же, как и политика выбора для подготовленных вычислительных баз данных с интенсивным использованием ресурсов памяти.
- Размер кэша никогда не уменьшается ниже минимального ограничения памяти, как определено минимальными виртуальными ядрами.
В бессерверных и подготовленных вычислительных базах данных записи кэша можно вытеснить, если используется все доступные памяти.
При низком уровне использования ЦП уровень использования активного кэша может оставаться высоким в зависимости от шаблона использования и функции предотвращения освобождения памяти. Кроме того, после прекращения действий пользователя и до освобождения памяти могут возникать другие задержки из-за периодических фоновых процессов, реагирующих на предыдущие действия пользователя. Например, при выполнении операций удаления и заданий по очистке хранилища запросов создаются фантомные записи, которые помечаются для удаления, но физически не удаляются до тех пор, пока не будет запущен процесс очистки фантомных записей, Очистка призрака может включать чтение страниц данных в кэш.
Cache hydration
Кэш памяти SQL растет по мере получения данных с диска таким же образом и с той же скоростью, что и для подготовленных баз данных. Если база данных занята, кэш может увеличиваться без ограничений, пока есть доступная память.
Управление кэшем дисков
На уровне служб гипермасштабирования для бессерверных и выделенных видов вычислений каждая реплика вычислений использует кэш устойчивого буферного пула (RBPEX), в котором хранятся страницы данных на локальном SSD для повышения производительности операций ввода-вывода. Однако в бессерверном уровне вычислений для гипермасштабирования кэш RBPEX для каждой реплики вычислений автоматически увеличивается и уменьшается в ответ на увеличение и снижение спроса на рабочую нагрузку. Максимальный размер кэша RBPEX может увеличиваться в три раза больше памяти, настроенной для базы данных. Дополнительные сведения о максимальном объёме памяти и ограничениях автоматического масштабирования RBPEX в бессерверной архитектуре см. в разделе ограничения ресурсов гипермасштаба в бессерверной архитектуре.
Автоматическая пауза и возобновление
В настоящее время бессерверная автоматическая приостановка и автоматическое возобновление поддерживаются только на уровне общего назначения.
Автоматическая приостановка
Auto-pausing is triggered if all of the following conditions are true during the auto-pause delay:
- Число сеансов — 0
- Ресурсы ЦП — 0 (для пользовательской рабочей нагрузки, выполняемой в пуле ресурсов пользователя).
При необходимости автоматическую приостановку можно отключить.
Следующие функции не поддерживают автоматическую приостановку, но поддерживают автоматическое масштабирование. Если используются какие-либо из следующих функций, автоматическое приостановка должна быть отключена, а база данных остается в сети независимо от длительности бездействия базы данных:
- Георепликация (активная георепликация и группы отказоустойчивости).
- Долгосрочное хранение резервных копий (LTR).
- База данных синхронизации, используемая в SQL Data Sync. В отличие от баз данных синхронизации, узловые и линейные базы данных поддерживают автоматическую приостановку.
- Псевдоним DNS, созданный для логического сервера, содержащего бессерверную базу данных.
- Elastic Jobs, Auto-pause enabled serverless database is not supported as a Job Database. Бессерверные базы данных, предназначенные для эластичных заданий, поддерживают автоматическую приостановку. Job connections resume a database.
Автоматическая приостановка временно предотвращается во время развертывания определённых обновлений службы, для которых требуется включённая база данных. В таких случаях после завершения обновления службы автоматическая приостановка снова становится доступной.
Автоматическая приостановка устранения неполадок
Если включена автоматическая приостановка и функции, которые блокируют автоматическое приостановку, не используются, но база данных не приостанавливается после периода задержки, то сеансы приложений или пользователей могут препятствовать автоматическому приостановке.
Чтобы узнать, подключены ли сейчас к базе данных какие-либо приложения или сеансы пользователей, подключитесь к базе данных с помощью любого клиентского средства и выполните следующий запрос.
SELECT session_id,
host_name,
program_name,
client_interface_name,
login_name,
status,
login_time,
last_request_start_time,
last_request_end_time
FROM sys.dm_exec_sessions AS s
INNER JOIN sys.dm_resource_governor_workload_groups AS wg
ON s.group_id = wg.group_id
WHERE s.session_id <> @@SPID
AND
(
(
wg.name like 'UserPrimaryGroup.DB%'
AND
TRY_CAST(RIGHT(wg.name, LEN(wg.name) - LEN('UserPrimaryGroup.DB') - 2) AS int) = DB_ID()
)
OR
wg.name = 'DACGroup'
);
Tip
После выполнения запроса обязательно разорвите соединение с базой данных. Otherwise, the open session used by the query prevents auto-pausing.
- Если результирующий набор не является пустым, это указывает на то, что в настоящее время существуют сеансы, которые препятствуют автоматической паузе.
- If the result set is empty, it is still possible that sessions were open, possibly for a short time, at some point earlier during the auto-pause delay period. To check for activity during the delay period, you can use Auditing for Azure SQL Database and Azure Synapse Analytics and examine audit data for the relevant period.
Внимание
Наличие открытых сеансов как при одновременном использовании ЦП в пуле ресурсов пользователя, так и без такового является самой распространенной причиной, по которой автоматическая приостановка бессерверной базы данных не выполняется надлежащим образом.
Автоматическое возобновление
Автоматическое возобновление выполняется, если в любой момент времени соблюдается какое-либо из следующих условий:
| Функция | Auto-resume trigger |
|---|---|
| Аутентификация и авторизация | Вход |
| Обнаружение угроз | Включение и отключение параметров обнаружения угроз на уровне базы данных или сервера. Изменение параметров обнаружения угроз на уровне базы данных или сервера. |
| Обнаружение и классификация данных | Добавление, изменение, удаление или просмотр меток конфиденциальности. |
| Аудит | Просмотр записей аудита. Обновление или просмотр политик аудита. |
| Маскирование данных | Добавление, изменение, удаление или просмотр правил маскирования данных. |
| Прозрачное шифрование данных | Просмотр состояния или статуса прозрачного шифрования данных |
| Оценка уязвимостей | Сканирование, инициированное вручную, и периодические сканирования при включении |
| Query (performance) data store | Изменение или просмотр параметров хранилища запросов |
| Рекомендации по повышению производительности | Просмотр или применение рекомендаций по производительности |
| Автоматическая настройка | Применение и проверка рекомендаций по автоматической настройке, включая автоматическое индексирование |
| Копирование базы данных | Create database as copy. Export to a BACPAC file. |
| Синхронизация данных SQL | Синхронизация между центральной и рядовыми базами данных, которая запускается по настраиваемому расписанию или вручную. |
| Изменение некоторых метаданных базы данных | Добавление новых тегов базы данных. Changing maximum vCores, minimum vCores, or auto-pause delay. |
| SQL Server Management Studio (SSMS) | При использовании версий SSMS до версии 18.1 и открытии нового окна запроса для любой базы данных на сервере возобновляется автоматически приостановленная база данных на том же сервере. При использовании SSMS версии 18.1 или выше такое поведение не происходит. |
Мониторинг, управление или другие решения, выполняющие любую из этих операций, активируют автоматическое возобновление. Автоматическое возобновление запускается также при развертывании некоторых обновлений служб, которым требуется, чтобы база данных была подключенной.
Подключение
Если бессерверная база данных приостановлена, первая попытка подключения возобновляет базу данных и возвращает ошибку, указывающую, что база данных недоступна с кодом ошибки 40613. После возобновления работы базы данных повторите вход, чтобы установить подключение. Клиенты базы данных, следующие рекомендациям по логике повторных попыток подключения, не должны быть изменены. Параметры и рекомендации по логике повторных попыток подключения см. в следующей статье:
- Логика повторных попыток подключения в SqlClient
- Логика повторных попыток подключения в базе данных SQL с использованием Entity Framework Core.
- Connection retry logic in SQL Database using Entity Framework 6
- Connection retry logic in SQL Database using ADO.NET
Задержка
Задержка для автоматического возобновления и приостановки бессерверной базы данных обычно составляет примерно 1 минуту для возобновления и 1–10 минут для приостановки после окончания периода задержки.
Прозрачное шифрование данных, управляемое клиентом (BYOK)
Удаление ключей или отзыв
Если используется управляемое клиентом прозрачное шифрование данных (BYOK), и бессерверная база данных автоматически переходит в состояние приостановки при удалении или отзыве ключа, то база данных остается в режиме автоматической приостановки. В этом случае после возобновления работы базы данных она становится недоступной в течение примерно 10 минут. Как только база данных становится недоступной, процедуру восстановления можно выполнить так же, как для подготовленных вычислительных баз данных. Если бессерверная база данных находится в режиме онлайн во время удаления или отзыва ключа, то она также становится недоступной в течение примерно 10 минут, так же, как в случае с выделенными вычислительными базами данных.
Ротация ключей
Если используется прозрачное шифрование данных, управляемое клиентом, (BYOK), а бессерверная автоматическая приостановка включена, база данных автоматически возобновляется при смене ключей. Затем база данных будет автоматически приостановлена при выполнении условий автоматической приостановки.
Создание бессерверной базы данных
Создание новой базы данных или перемещение существующей базы данных на уровень бессерверных вычислений выполняется аналогично созданию новой базы данных на уровне подготовленных вычислений. Этот процесс включает два этапа:
Определение цели службы. Цель службы определяет уровень служб, конфигурацию оборудования и максимальные виртуальные ядра. Для вариантов цели обслуживания см. ограничения бессерверных ресурсов
Optionally, specify the minimum vCores and auto-pause delay to change their default values. В таблице ниже показаны доступные значения для этих параметров.
Параметр Варианты значений Значение по умолчанию Minimum vCores Depends on maximum vCores configured - see resource limits. 0,5 виртуальных процессоров Auto-pause delay Минимум: 15 минут
Максимум: 10 080 минут (семь дней)
Increments: 1 minute
Отключение автоматической приостановки: -160 минут
В следующих примерах создается новая база данных на уровне бессерверных вычислений.
Использование портала Azure
См. Краткое руководство: Создание базы данных в Azure SQL Database с помощью портала Azure.
С помощью PowerShell
Создайте новую бессерверную базу данных общего назначения с помощью следующего примера PowerShell:
New-AzSqlDatabase -ResourceGroupName $resourceGroupName -ServerName $serverName -DatabaseName $databaseName `
-Edition GeneralPurpose -ComputeModel Serverless -ComputeGeneration Gen5 `
-MinVcore 0.5 -MaxVcore 2 -AutoPauseDelayInMinutes 720
Использование Azure CLI
Создайте новую бессерверную базу данных общего назначения с помощью следующего примера Azure CLI:
az sql db create -g $resourceGroupName -s $serverName -n $databaseName `
-e GeneralPurpose --compute-model Serverless -f Gen5 `
--min-capacity 0.5 -c 2 --auto-pause-delay 720
Использование Transact-SQL (T-SQL)
When using T-SQL to create a new serverless database, default values are applied for the minimum vCores and auto-pause delay. Их значения можно изменить на портале Azure или через API, включая PowerShell, Azure CLI и REST.
Дополнительные сведения см. в СОЗДАНИЕ БАЗЫ ДАННЫХ.
Создайте новую бессерверную базу данных общего назначения с помощью следующего примера T-SQL:
CREATE DATABASE testdb
( EDITION = 'GeneralPurpose', SERVICE_OBJECTIVE = 'GP_S_Gen5_1' ) ;
Перемещение базы данных между уровнями вычислений или уровнями служб
Базу данных можно переместить между подготовленным уровнем вычислений и бессерверным уровнем вычислений.
Бессерверную базу данных также можно переместить с уровня служб общего назначения на уровень служб "Гипермасштабирование". Дополнительные сведения см. в статье Преобразование существующей базы данных в гипермасштабирование.
При перемещении базы данных между уровнями вычислительных ресурсов укажите параметр compute model либо как Serverless, либо как Provisioned при использовании PowerShell или Azure CLI, либо параметр SERVICE_OBJECTIVE при использовании T-SQL. Просмотрите ограничения ресурсов, чтобы определить соответствующий целевой показатель обслуживания.
В следующих примерах существующая база данных перемещается из выделенных ресурсов в бессерверные вычисления.
С помощью PowerShell
Переместите подготовленную базу данных общего назначения вычислений на бессерверный уровень вычислений с помощью следующего примера PowerShell:
Set-AzSqlDatabase -ResourceGroupName $resourceGroupName -ServerName $serverName -DatabaseName $databaseName `
-Edition GeneralPurpose -ComputeModel Serverless -ComputeGeneration Gen5 `
-MinVcore 1 -MaxVcore 4 -AutoPauseDelayInMinutes 1440
Использование Azure CLI
Переместите подготовленную базу данных общего назначения вычислений на бессерверный уровень вычислений с помощью следующего примера Azure CLI:
az sql db update -g $resourceGroupName -s $serverName -n $databaseName `
--edition GeneralPurpose --compute-model Serverless --family Gen5 `
--min-capacity 1 --capacity 4 --auto-pause-delay 1440
Использование Transact-SQL (T-SQL)
When using T-SQL to move a database between compute tiers, default values are applied for the minimum vCores and auto-pause delay. Их значения можно изменить из портала Azure или с помощью API, включая PowerShell, Azure CLI и REST. Для получения дополнительной информации см. ALTER DATABASE.
Переместите подготовленную базу данных общего назначения вычислений на бессерверный уровень вычислений с помощью следующего примера T-SQL:
ALTER DATABASE testdb
MODIFY ( SERVICE_OBJECTIVE = 'GP_S_Gen5_1') ;
Изменение бессерверной конфигурации
С помощью PowerShell
Use Set-AzSqlDatabase to modify the maximum or minimum vCores, and auto-pause delay. Используйте аргументы MaxVcore, MinVcore и AutoPauseDelayInMinutes. Бессерверная автоматическая приостановка в настоящее время не поддерживается на уровне гипермасштабирования, поэтому аргумент задержки автоматической приостановки применим только к уровню общего назначения.
Использование Azure CLI
Use az sql db update to modify the maximum or minimum vCores, and auto-pause delay. Используйте аргументы capacity, min-capacity и auto-pause-delay. Бессерверная автоматическая приостановка в настоящее время не поддерживается на уровне гипермасштабирования, поэтому аргумент задержки автоматической приостановки применим только к уровню общего назначения.
Монитор
Используемые и тарифицируемые ресурсы
Ресурсы бессерверной базы данных включают сущности пула ресурсов приложений, экземпляра SQL и пула ресурсов пользователей.
Пакет приложения
Пакет приложения представляет внешнюю границу управления для большинства ресурсов базы данных, независимо от того, на каком уровне находится база данных (бессерверные или подготовленные вычисления). Пакет приложения содержит экземпляр SQL и внешние службы (например, полнотекстовый поиск), которые вместе определяют область применения всех пользовательских и системных ресурсов, используемых базой данных в Базе данных SQL. The SQL instance generally dominates the overall resource utilization across the app package.
Пул пользовательских ресурсов
Пул пользовательских ресурсов представляет внутреннюю границу управления для ресурсов базы данных независимо от того, на каком уровне находится база данных (бессерверные или подготовленные вычисления). The user resource pool scopes CPU and IO for user workload generated by DDL (CREATE and ALTER) and DML (INSERT, UPDATE, DELETE, and MERGE, and SELECT) queries. Эти запросы обычно представляют самые распространенные операции, потребляющие ресурсы в пакете приложения.
Метрики
В следующей таблице содержатся показатели для мониторинга использования ресурсов пакета приложений и пула пользовательских ресурсов бессерверной базы данных, включая любые геореплики:
| Объект | Metric | Описание | единицы |
|---|---|---|---|
| Пакет приложения | app_cpu_percent | Процент виртуальных ядер, используемых приложением относительно максимального количества виртуальных ядер, разрешенных для приложения. Для бессерверного гипермасштабирования эта метрика предоставляется для всех основных реплик, именованных реплик и геореплик. | Процентное отношение |
| Пакет приложения | app_cpu_billed | Объем вычислительных ресурсов, тарифицируемых для приложения в отчетный период. Сумма выплаты за этот период является произведением этого показателя и цены за виртуальное ядро. Значения этой метрики определяются агрегированием максимального количества используемых ЦП и памяти, используемых каждую секунду. Если используемый объём меньше минимального объема, зарезервированного по минимальным виртуальным процессорным ядрам и минимальной памяти, взимается плата за минимальный объём. Для сравнения использования ЦП и памяти при расчете платежей объем памяти нормализуется в единицы виртуальных ядер путем пересчета объема памяти в ГБ по курсу 3 ГБ на одно виртуальное ядро. Для бессерверного гипермасштабирования эта метрика предоставляется для основной реплики и всех именованных реплик. |
vCore seconds |
| Пакет приложения | app_cpu_billed_HA_replicas | Применимо только к бессерверной гипермасштабируемости. Sum of the compute billed across all apps for HA replicas during the reporting period. This sum is scoped either to the HA replicas belonging to the primary replica or the HA replicas belonging to a given named replica. Before calculating this sum across HA replicas, the amount of compute billed for an individual HA replica is determined in the same way as for the primary replica or a named replica. Для бессерверного гипермасштабирования эта метрика предоставляется для всех основных реплик, именованных реплик и геореплик. Сумма, выплаченная в течение отчетного периода, рассчитывается как произведение этой метрики и цены единицы виртуальных ядер (vCore). | vCore seconds |
| Пакет приложения | процент памяти приложения | Процент памяти, используемой приложением относительно максимально допустимой памяти для приложения. Для бессерверного гипермасштабирования эта метрика предоставляется для всех основных реплик, именованных реплик и геореплик. | Процентное отношение |
| Пул пользовательских ресурсов | процент использования CPU | Процент виртуальных ядер, используемых рабочей нагрузкой пользователя относительно максимального количества виртуальных ядер, разрешенных для рабочей нагрузки пользователя. | Процентное отношение |
| Пул пользовательских ресурсов | data_IO_percent | Percentage of data IOPS used by user workload relative to maximum data IOPS allowed for user workload. | Процентное отношение |
| Пул пользовательских ресурсов | log_IO_percent | Percentage of log MB/s used by user workload relative to maximum log MB/s allowed for user workload. | Процентное отношение |
| Пул пользовательских ресурсов | workers_percent | Процент числа работников, используемых в рабочей нагрузке пользователя относительно максимально допустимого числа работников, разрешенных для рабочей нагрузки пользователя. | Процентное отношение |
| Пул пользовательских ресурсов | sessions_percent | Процент сеансов, используемых рабочей нагрузкой пользователя относительно максимального числа сеансов, разрешенных для рабочей нагрузки пользователя. | Процентное отношение |
Состояние приостановки и возобновления работы
В случае бессерверной базы данных с включенной автоматической приостановкой сообщаемое состояние включает следующие значения:
| Состояние | Описание |
|---|---|
| Online | База данных находится в сети. |
| Приостановка | База данных переходит из сети в режим приостановки. |
| Приостановлен | База данных приостановлена. |
| Resuming | База данных переходит из приостановленной в режим "в сети". |
Использование портала Azure
В портале Azure состояние базы данных отображается на странице обзора базы данных и на странице обзора сервера. Кроме того, в портале Azure историю событий приостановки и возобновления бессерверной базы данных можно просмотреть в Журнале действий.
С помощью PowerShell
Просмотрите текущее состояние базы данных с помощью следующего примера PowerShell:
Get-AzSqlDatabase -ResourceGroupName $resourcegroupname -ServerName $servername -DatabaseName $databasename `
| Select -ExpandProperty "Status"
Использование Azure CLI
Просмотрите текущее состояние базы данных с помощью следующего примера Azure CLI:
az sql db show --name $databasename --resource-group $resourcegroupname --server $servername --query 'status' -o json
Ограничения ресурсов
Для ограничения ресурсов см. уровень бессерверных вычислений.
Выставление счетов
Объем вычислительных ресурсов, выставленных для бессерверной базы данных, — это максимальное количество используемых ЦП и памяти, используемых каждую секунду. Если объем используемой ЦП и памяти меньше минимальной суммы, подготовленной для каждого ресурса, плата взимается. Чтобы сравнить ЦП с памятью для выставления счетов, память нормализуется до количества виртуальных ядер, перерасчитывая объем в ГБ по коэффициенту 3 ГБ на одно виртуальное ядро.
- Оплачиваемые ресурсы: ЦП и память
- Amount billed: vCore unit price * maximum (minimum vCores, vCores used, minimum memory GB * 1/3, memory GB used * 1/3)
- Периодичность выставления счета: раз в секунду
The vCore unit price is the cost per vCore per second.
Refer to the Azure SQL Database pricing page for specific unit prices in a given region.
The amount of compute billed in serverless for a General Purpose database, or a Hyperscale primary or named replica is exposed by the following metric:
- Metric: app_cpu_billed (vCore seconds)
- Definition: maximum (minimum vCores, vCores used, minimum memory GB * 1/3, memory GB used * 1/3)
- Частота отчетности: в минуту на основе измерений в секунду, агрегированных в течение 1 минуты.
The amount of compute billed in serverless for Hyperscale HA replicas belonging to the primary replica or any named replica is exposed by the following metric:
- Metric: app_cpu_billed_HA_replicas (vCore seconds)
- Definition: Sum of maximum (minimum vCores, vCores used, minimum memory GB * 1/3, memory GB used * 1/3) for any HA replicas belonging to their parent resource.
- Parent resource and metric endpoint: The primary replica and any named replica each separately expose this metric, which measures the compute billed for any associated HA replicas.
- Частота отчетности: в минуту на основе измерений в секунду, агрегированных в течение 1 минуты.
Minimum compute bill
Если бессерверная база данных приостановлена, то счет за вычислительные ресурсы равен нулю. If a serverless database is not paused, then the minimum compute bill is no less than the amount of vCores based on maximum (minimum vCores, minimum memory GB * 1/3).
Примеры:
- Предположим, что бессерверная база данных на уровне общего назначения не приостановлена и настроена с 8 максимальными виртуальными ядрами и 1 минимальным виртуальным ядром, соответствующим минимальному 3,0 ГБ памяти. Затем минимальная плата за вычисления основана на максимальном значении (1 виртуальное ядро, 3,0 ГБ * 1 виртуальное ядро / 3 ГБ) = 1 виртуальное ядро.
- Предположим, что бессерверная база данных на уровне общего назначения не приостановлена и настроена с 4 максимальными виртуальными ядрами и 0,5 минимальными виртуальными ядрами, соответствующими 2,1 ГБ минимальной памяти. Then the minimum compute bill is based on maximum (0.5 vCores, 2.1 GB * 1 vCore / 3 GB) = 0.7 vCores.
- Предположим, что бессерверная база данных на уровне гипермасштабирования имеет первичную реплику с одной репликой высокой доступности и одну именованную реплику, у которой нет реплик высокой доступности. Предположим, что каждая реплика настроена с 8 максимальными виртуальными ядрами и 1 минимальным виртуальным ядром, соответствующим минимальному 3 ГБ памяти. Then the minimum compute bill for the primary replica, HA replica, and named replica are each based on maximum (1 vCore, 3 GB * 1 vCore / 3 GB) = 1 vCore.
The Azure SQL Database pricing calculator for serverless can be used to determine the minimum memory configurable based on the number of maximum and minimum vCores configured. Как правило, если минимальные виртуальные ядра больше 0,5, минимальная стоимость вычислений не зависит от объема настроенной минимальной памяти. Она определяется только числом минимальных виртуальных ядер.
Примеры сценариев.
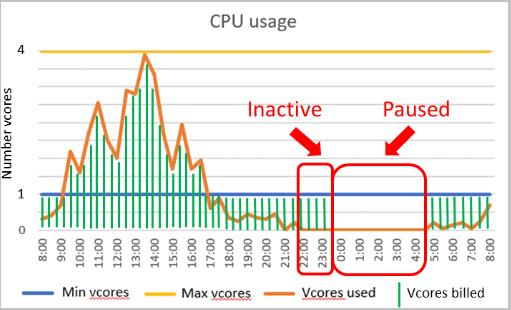
Рассмотрим бессерверную базу данных на уровне общего назначения, настроенную с 1 минимальным виртуальным ядром и 4 максимальными виртуальными ядрами. Эта конфигурация соответствует примерно 3 ГБ минимальной памяти и 12 ГБ максимальной памяти. Предположим, что задержка автоматической приостановки равна 6 часам, а рабочая нагрузка базы данных активна в течение первых 2 часов в 24-часовом периоде, а затем неактивна.
В этом случае оплачиваются вычислительные ресурсы и ресурсы хранения базы данных за первые 8 часов. Несмотря на неактивность базы данных после второго часа, счет за вычислительные ресурсы в последующие 6 часов все равно выставляется (за минимальные подготовленные вычислительные ресурсы, пока база данных в сети). В течение оставшейся части 24-часового периода, пока база данных приостановлена, оплачиваются только ресурсы хранения.
Точнее, счет за вычислительные ресурсы в этом примере выставляется следующим образом.
| Интервал времени | vCores used each second | GB used each second | Compute dimension billed | vCore seconds billed over time interval |
|---|---|---|---|---|
| 0:00–1:00. | 4 | 9 | vCores used | 4 vCores * 3,600 seconds = 14,400 vCore seconds |
| 1:00–2:00 | 1 | 12 | Используемая память | 12 GB * 1/3 * 3,600 seconds = 14,400 vCore seconds |
| 2:00–8:00. | 0 | 0 | Минимальная выделенная память | 3 ГБ * 1/3 * 21600 секунд = 21600 vCore секунд |
| 8:00–24:00. | 0 | 0 | No compute billed while paused | 0 vCore seconds |
| Общее количество секунд vCore, выставленных в течение 24 часов | 50,400 vCore seconds |
Предположим, что цена за единицу вычислений составляет 0,000145 долл. США/виртуальное ядро/секунда. Затем вычислительные расходы за этот 24-часовой период составляют произведение цены за единицу вычислений и количества секунд виртуальных ядер: $0,000145/вКоре/секунда * 50 400 секунд виртуальных ядер ~ $7,31.
Преимущество гибридного использования Azure и резервирование
Скидки на гибридные преимущества Azure (AHB) и резервирования Azure не применяются к бессерверному уровню вычислений.
Доступные регионы
Сведения о региональной доступности см. в разделе доступность бессерверных серверов по регионам для базы данных SQL Azure.
Связанный контент
- To get started, see Quickstart: Create a single database - Azure SQL Database.
- Варианты уровня бессерверных служб см. в разделах Общего назначения и Гипермасштабирование.