Примечание.
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
Репликация вашего рабочей области Log Analytics в разных регионах повышает устойчивость, позволяя переключиться на реплицированную область и продолжать работу в случае сбоя в определенном регионе. В этой статье объясняется, как работает репликация рабочей области Log Analytics, как реплицировать рабочую область, как переключиться и вернуться, а также как решить, когда переключаться между реплицированными рабочими областями.
Репликация рабочей области — это платная настраиваемая функция, которая защищает от инцидентов на уровне региона, которые дополняют зоны доступности, прозрачной защиты в регионе от сбоев центра обработки данных. См. полный обзор всех вариантов устойчивости в разделе Надежность в журналах Azure Monitor.
Ниже приведено видео, в которое приведены краткие сведения о том, как работает репликация рабочей области Log Analytics:
Это важно
Хотя мы иногда используем термин "failover", например, в вызове API, "failover" также часто используется для описания автоматического процесса. Поэтому в этой статье используется термин "переключение", чтобы подчеркнуть, что переход к реплицированному рабочему пространству — это действие, которое вы выполняете вручную.
Как работает репликация рабочей области Log Analytics
Исходная рабочая область и регион называются основной. Реплицированная рабочая область и альтернативный регион называются вторичными.
Процесс репликации рабочей области создает копию вашей рабочей области в дополнительном регионе. Процесс создает вторичную рабочую область с той же конфигурацией, что и основная рабочая область, и Azure Monitor автоматически обновляет вторичную рабочую область с любыми будущими изменениями, внесенными в конфигурацию основной рабочей области.
Вторичная рабочая область представляет собой «теневую» рабочую область, предназначенную исключительно для обеспечения устойчивости. Вы не видите вторичную рабочую область на портале Azure и не можете напрямую управлять и обращаться к ней.
Когда вы включаете репликацию рабочего пространства, Azure Monitor отправляет новые журналы, поступающие в ваше основное рабочее пространство, также в ваш вторичный регион. Журналы, которые вы отправляете в рабочую область, прежде чем включить репликацию рабочей области, не копируются.
Примечание
Репликация рабочей области полностью реплицирует все схемы таблиц, но отправляет только новые журналы, полученные с момента активации репликации. Журналы, загруженные в рабочую область до того, как вы включили репликацию рабочей области, не копируются.
Если сбой затрагивает ваш основной регион, вы можете переключиться и перенаправить все запросы на ввод и запросы на ваш вторичный регион. После того как Azure устранит сбой и ваш основной рабочий кабинет снова станет доступным, вы можете вернуться к вашему основному региону.
Когда вы переключаетесь, вторичное рабочее пространство становится активным, а основное — неактивным. Затем Azure Monitor производит прием новых данных через конвейер загрузки в вашем вторичном регионе, а не в основном. При переключении на вторичный регион, Azure Monitor реплицирует все данные, которые вы получаете из вторичного региона, в первичный регион. Процесс является асинхронным и не влияет на задержку обработки данных.
Примечание
После переключения на вторичный регион, если первичный регион не может обработать входящие данные журналов, Azure Monitor буферизует данные во вторичном регионе в течение до 11 дней. В течение первых четырех дней Azure Monitor автоматически повторяет попытки периодически реплицировать данные.

Защита от потери данных при передаче в случае регионального сбоя
Azure Monitor имеет несколько механизмов, чтобы гарантировать, что данные во время передачи не будут потеряны при сбое в основном регионе.
Служба Azure Monitor защищает данные, которые достигают конечной точки приема в основном регионе, когда конвейер основного региона недоступен для обработки данных. Когда конвейер становится доступным, он продолжает обрабатывать данные в пути, а Azure Monitor поглощает и реплицирует данные во вторичный регион.
Если конечная точка сбора данных в основной регионе недоступна, агент мониторинга Azure регулярно пытается повторно отправить данные журнала на эту конечную точку. Конечная точка передачи данных во вторичном регионе начинает получать данные от агентов через несколько минут после того, как вы инициируете переключение.
Если вы создаете собственный клиент для отправки данных журналов в вашу рабочую область Log Analytics, убедитесь, что клиент обрабатывает запросы на получение, которые завершились неудачно.
Рассмотрение развертывания
Примечание
Репликация рабочей области в настоящее время не поддерживает репликацию вспомогательных таблиц и не должна быть включена в рабочих областях, включающих вспомогательные таблицы. Вспомогательные таблицы не реплицируются и поэтому не защищены от потери данных в случае регионального сбоя и недоступны при переключении на вторичную рабочую область.
Операции по управлению рабочим пространством нельзя инициировать во время переключения, включая:
- Изменение срока хранения рабочей среды, ценовой категории, дневного лимита и т. д.
- Изменение параметров сети
- Изменение схемы с помощью новых пользовательских журналов или подключения журналов платформы от новых поставщиков ресурсов, таких как отправка журналов диагностики из нового типа ресурса
Процесс резервирования обновляет записи системы доменных имен (DNS), чтобы перенаправить все запросы на ввод данных в резервный регион для дальнейшей обработки. Некоторые HTTP-клиенты имеют "постоянные подключения" и могут занимать больше времени на получение обновлений DNS. Во время переключения эти клиенты могут попытаться загрузить журналы через основную область в течение некоторого времени. Вы можете отправлять журналы в ваше основное рабочее пространство, используя различных клиентов, включая устаревший агент Log Analytics, агент Azure Monitor, код (с использованием API для отправки журналов или устаревшего API для сбора данных через HTTP), а также другие сервисы, такие как Microsoft Sentinel.
Это важно
Правила генерации оповещений поиска журналов продолжают работать при переключении между регионами, за исключением случаев, когда служба оповещений в активном регионе не работает должным образом или правила оповещений недоступны. Это может произойти, например, если регион, в котором были созданы правила генерации оповещений, полностью отключен. Репликация правил генерации оповещений в разных регионах не выполняется автоматически в рамках репликации рабочей области, но может выполняться пользователем (например, экспортируя из основного региона и импортируя в дополнительный).
Операция очистки, которая удаляет записи из рабочей области, удаляет соответствующие записи из основной и вторичной рабочих областей. Если один из экземпляров рабочего пространства недоступен, операция очистки завершается неудачей.
Реплицированная рабочая область не может быть удалена. Чтобы правильно удалить рабочую область, сначала отключите репликацию.
Microsoft Sentinel обновляет журналы в таблицах "Контрольный список" и "Аналитика угроз" каждые 12 дней. Таким образом, поскольку в дублируемую рабочую область будут поступать только новые журналы регистрации, может потребоваться до 12 дней, чтобы полностью реплицировать данные по списку наблюдения и аналитике угроз на вторичную площадку.
Возможность адресации решения наследственного агента Log Analytics не поддерживается в период переключения. Во время переключения данные решения поступают от всех агентов.
В настоящее время эти функции не поддерживаются или поддерживаются только частично.
Особенность Поддержка Вспомогательные планы столов Не поддерживается. Azure Monitor не реплицирует данные в таблицах с вспомогательным планом журналирования в ваше вторичное рабочее пространство. Поэтому эти данные не защищены от потери данных в случае отказа в регионе и недоступны при переключении на ваше вторичное рабочее пространство. Поиск вакансий, Восстановить Частично поддерживается - операции поиска и восстановления создают таблицы и заполняют их результатами поиска или восстановленными данными. После того как вы включите репликацию рабочих пространств, новые таблицы, создаваемые для этих операций, будут реплицированы в ваше вторичное рабочее пространство. Таблицы, заполненные перед включением репликации, не реплицируются. Если эти операции выполняются в момент переключения, результат может оказаться неожиданным. Это может успешно завершиться, но не воспроизводиться, или может закончиться неудачно, в зависимости от состояния вашего рабочего пространства и точного времени. Приложение Insights поверх рабочих областей анализа журналов Не поддерживается Аналитика виртуальных машин Не поддерживается Аналитика контейнеров Не поддерживается Приватные ссылки Не поддерживается при переключении на резервную систему
Поддерживаемые регионы
В настоящее время репликация рабочих областей поддерживается для рабочих областей в ограниченном наборе регионов, организованных по группам регионов (группы географически соседних регионов). При включении репликации выберите вторичное местоположение из списка поддерживаемых регионов в той же группе регионов, что и основное местоположение рабочего пространства. Например, рабочее пространство в Западной Европе можно реплицировать в Северной Европе, но не в Западных США 2, так как эти регионы находятся в разных группах регионов.
Поддерживаются следующие группы регионов и регионы:
| Группа региона | Основные регионы | Вторичные регионы (места репликации) |
|---|---|---|
| Северная Америка | Центральная Канада Восточная Канада Центральные штаты США Восток США* Восток США 2* Северная часть США Юго-Центральные США* Западная часть США Западная часть США Запад США 2 Западная часть США 3 |
Центральная Канада Центральные штаты США Восток США* Восток США 2* Западная часть США Запад США 2 Западная часть США 3 |
| Южная Америка | Южная Бразилия Юго-Восточная Бразилия |
Южная Бразилия Юго-Восточная Бразилия |
| Европа | Центральная Франция Юг Франции Север Германии Западно-Центральная Германия Север Италии Северная Европа Восточная Норвегия Норвегия Запад Центральная Польша Южная часть Великобритании Центральная Испания Центральная Швеция Южная Швеция Швейцария Север Запад Швейцарии Западная Европа Запад Великобритании |
Центральная Франция Западно-Центральная Германия Северная Европа Южная часть Великобритании Западная Европа Запад Великобритании |
| Средний Восток | Центральный Катар Центральная часть ОАЭ Северная часть ОАЭ; |
Центральный Катар Центральная часть ОАЭ Северная часть ОАЭ; |
| Индия | Центральная Индия Jio India Central Джио Индия Западная Южная Индия |
Центральная Индия Jio India Central Джио Индия Западная Южная Индия |
| Азиатско-Тихоокеанский регион | Восточная Азия Восточная Япония Япония Запад Корея Центр Южная Корея Юго-Восточная Азия |
Восточная Азия Восточная Япония Япония Запад Корея Центр Юго-Восточная Азия |
| Океания | Центральная Австралия Центральная Австралия 2 Восток Австралии Юго-Восточная часть Австралии |
Центральная Австралия Восток Австралии Юго-Восточная часть Австралии |
| Африка | Север Южной Африки Западная часть ЮАР |
Север Южной Африки Западная часть ЮАР |
Примечание
Рабочие пространства, расположенные в East US, East US 2 и South Central US, могут реплицироваться только в вторичные регионы, находящиеся вне этого набора из трех. Пожалуйста, выберите другое дополнительное местоположение из группы регионов Северной Америки.
Требования к местонахождению данных
У разных клиентов различные требования к местоположению данных, поэтому важно контролировать, где хранятся ваши данные. Azure Monitor обрабатывает и сохраняет журналы в основных и вторичных регионах, которые вы выбираете. Дополнительные сведения см. в разделе "Поддерживаемые регионы".
Поддержка Microsoft Sentinel и других служб
Различные сервисы и функции, использующие рабочие области Log Analytics, совместимы с репликацией и переключением рабочей области. Эти услуги и функции продолжают работать, когда вы переключаетесь на вторичное рабочее пространство.
Например, региональные проблемы с сетью, вызывающие задержку при сборе журналов, могут повлиять на клиентов Microsoft Sentinel. Клиенты, которые используют реплицированные рабочие пространства, могут переключиться на свою вторичную область, чтобы продолжить работу с рабочим пространством Log Analytics и Sentinel. Однако, если проблема с сетью влияет на работоспособность службы Sentinel, переключение на другой регион не решает эту проблему.
Некоторые функции Azure Monitor, включая Application Insights и VM Insights, в настоящее время лишь частично совместимы с репликацией рабочего пространства и переключением. Полный список см. в разделе "Рекомендации по развертыванию".
Модель ценообразования
При включении репликации рабочей области взимается плата за репликацию всех данных, которые вы загружаете в рабочую область, за исключением данных, где _IsBillable = false.
Это важно
Если вы отправляете данные в рабочую область с помощью агента Azure Monitor, API приема журналов, Центров событий Azure или других источников данных, использующих правила сбора данных, обязательно свяжите правила сбора данных с конечной точкой сбора данных рабочей области. Эта ассоциация гарантирует, что данные, которые вы загружаете, будут реплицированы в ваше вторичное рабочее пространство. Если вы не связываете свои правила сбора данных с конечной точкой сбора данных рабочей области, с вас все равно взимается плата за все данные, которые вы загружаете в свою рабочую область, даже если данные не реплицируются.
Требуются разрешения
| Действие | Требуются разрешения |
|---|---|
| Включить репликацию рабочего пространства |
Microsoft.OperationalInsights/workspaces/write и Microsoft.Insights/dataCollectionEndpoints/write разрешения, предоставляемые встроенной ролью участника мониторинга, например |
| Переключение и возврат (инициировать отказоустойчивость и возврат) |
Microsoft.OperationalInsights/locations/workspaces/failover, Microsoft.OperationalInsights/workspaces/failback, Microsoft.Insights/dataCollectionEndpoints/triggerFailover/action и Microsoft.Insights/dataCollectionEndpoints/triggerFailback/action разрешения, предоставляемые встроенной ролью участника мониторинга, например |
| Проверить состояние рабочей области |
Microsoft.OperationalInsights/workspaces/read разрешения на рабочую область Log Analytics, предоставляемые встроенной ролью Monitoring Contributor, например |
Включение и отключение репликации рабочего пространства
Вы включаете и отключаете репликацию рабочей области с помощью команды REST. Команда запускает длительную операцию, что означает, что для применения новых настроек может потребоваться несколько минут. После того как вы включите репликацию, может потребоваться до одного часа, чтобы все таблицы (типы данных) начали реплицироваться, и некоторые типы данных могут начать реплицироваться раньше других. Изменения, которые вы вносите в схемы таблиц после включения репликации рабочего пространства, например, новые таблицы пользовательских журналов или созданные вами пользовательские поля, или диагностические журналы, настроенные для новых типов ресурсов, могут начать реплицироваться в течение одного часа.
Используете выделенный кластер?
Если ваше рабочее пространство связано с выделенным кластером, сначала необходимо включить репликацию на кластере, а затем на рабочем пространстве. Эта операция создает второй кластер во вторичном регионе (без дополнительной оплаты сверх затрат на репликацию), чтобы позволить рабочей области использовать выделенный кластер даже при переключении на резерв. Это также означает, что такие функции, как управляемые кластером ключи (CMK), продолжают работать (с тем же ключом) во время переключения. После включения репликации между регионами перейдите к включению репликации для одного или нескольких рабочих пространств, связанных с этим кластером.
Это важно
После того как репликация кластера включена, изменение целевой точки репликации требует отключения репликации и её повторного включения для другого местоположения.
Чтобы включить репликацию в выделенном кластере, используйте следующую команду. Включение репликации в кластере — это длительная операция, которая может занять некоторое время, и вы можете отслеживать его точное состояние, как описано в разделе "Проверка состояния подготовки кластера".
Чтобы включить репликацию кластера, используйте команду az rest Azure CLI для вызова REST API Azure Resource Manager:
az rest --method put \
--uri "/subscriptions/<subscription_id>/resourcegroups/<resourcegroup_name>/providers/microsoft.operationalinsights/clusters/<cluster_name>?api-version=2025-02-01" \
--body '{
"properties": {
"replication": {
"enabled": true,
"location": "<secondary_region>"
}
},
"location": "<primary_region>"
}'
Где
-
<subscription_id>: идентификатор подписки, связанный с кластером -
<resourcegroup_name>: группа ресурсов, содержащая ресурс кластера Log Analytics -
<cluster_name>: имя выделенного кластера -
<primary_region>: основной регион для выделенного кластера Log Analytics -
<secondary_region>: регион, в котором Azure Monitor создает дополнительный выделенный кластер
Проверить состояние подготовки кластера
Чтобы проверить состояние развертывания вашего кластера, используйте команду Azure CLI az monitor log-analytics cluster show.
az monitor log-analytics cluster show \
--resource-group <resourcegroup_name> \
--cluster-name <cluster_name> \
--query "replication.provisioningState"
Где
-
<subscription_id>: идентификатор подписки, связанный с кластером -
<resourcegroup_name>: группа ресурсов, содержащая ресурс кластера Log Analytics -
<cluster_name>: имя кластера Log Analytics
Используйте команду, чтобы убедиться, что состояние подготовки кластера изменяется с Updating на Succeeded, и что дополнительный регион задан так, как ожидалось.
Примечание
Когда вы включаете репликацию кластера, новый кластер создается на вторичной площадке. Этот процесс может занять 1-2 часа.
Включить репликацию рабочего пространства
Чтобы включить репликацию в рабочей области Log Analytics, используйте команду az rest Azure CLI для вызова REST API Azure Resource Manager:
az rest --method put \
--uri "/subscriptions/<subscription_id>/resourcegroups/<resourcegroup_name>/providers/microsoft.operationalinsights/workspaces/<workspace_name>?api-version=2025-02-01" \
--body '{
"properties": {
"replication": {
"enabled": true,
"location": "<secondary_region>"
}
},
"location": "<primary_region>"
}'
Где
-
<subscription_id>: идентификатор подписки, связанный с вашей рабочей областью -
<resourcegroup_name>: группа ресурсов, содержащая ресурс рабочей области Log Analytics -
<workspace_name>: имя рабочей области -
<primary_region>: основной регион для рабочей области Log Analytics -
<secondary_region>: регион, в котором Azure Monitor создает вторичную рабочую область
Поддерживаемые значения регионов см. в разделе "Поддерживаемые регионы".
Команда включения репликации рабочей области — это длительная операция, которая может занять некоторое время. Состояние подготовки запроса можно отслеживать, как описано в разделе "Проверка состояния подготовки рабочей области".
Это важно
Если ваше рабочее пространство связано с выделенным кластером, сначала включите репликацию на кластере. Также обратите внимание, что вторичное местоположение вашего рабочего пространства должно быть идентичным вторичному местоположению его выделенного кластера.
Проверьте состояние обеспечения рабочего пространства
Чтобы проверить состояние предоставления рабочей области, используйте команду Azure CLI az monitor log-analytics workspace show.
az monitor log-analytics workspace show \
--resource-group <resourcegroup_name> \
--workspace-name <workspace_name> \
--query "replication.provisioningState"
Где
-
<subscription_id>: Идентификатор подписки, связанный с вашим рабочим пространством. -
<resourcegroup_name>: Группа ресурсов, содержащая ресурс рабочего пространства Log Analytics. -
<workspace_name>: Название вашего рабочей области Log Analytics.
Используйте команду, чтобы убедиться, что состояние подготовки рабочей области изменяется из Updating в Succeeded, и вторичный регион задан должным образом.
Примечание
Когда вы включаете репликацию для рабочих пространств, взаимодействующих с Sentinel, полная репликация данных списка наблюдения и данных об угрозах на вторичное рабочее пространство может занять до 12 дней.
Проверьте, включена ли репликация в рабочей области
Чтобы проверить, включена ли репликация рабочей области и где она включена, просмотрите эти параметры.
На портале Azure > области.
Если репликация включена, в разделе Essentials отображается дополнительное расположение, указывающее регион реплицированной рабочей области.

В том же разделе Essentials есть представление JSON , отображающее сведения о репликации в виде объекта JSON, который также доступен через REST/CLI.

Свяжите правила сбора данных с конечной точкой сбора данных рабочего пространства
Агент Azure Monitor, API приема журналов и Центры событий Azure собирают данные и отправляют их в указанное место на основе настройки правил сбора данных (DCR).
Если у вас есть правила сбора данных, которые отправляют данные в ваше первичное рабочее пространство, вам нужно связать эти правила с системной конечной точкой сбора данных (DCE), которую Azure Monitor создает при включении репликации рабочего пространства. Название конечной точки сбора данных рабочего пространства совпадает с вашим идентификатором рабочего пространства. Только правила сбора данных, сопоставленные с сетевой точкой сбора данных рабочей области, обеспечивают продолжение приема данных во время переключения на резерв. Это поведение позволяет вам указать набор потоков журналов, которые нужно реплицировать, что помогает контролировать ваши затраты на репликацию.
Чтобы реплицировать данные, которые вы собираете с помощью правил сбора данных, свяжите ваши правила сбора данных с конечной точкой сбора данных рабочего пространства.
На портале Azure выберите правила сбора данных.
На экране правил сбора данных выберите правило сбора данных, которое отправляет данные в основную рабочую область Log Analytics.
На странице обзора правила сбора данных выберите "Настроить DCE " и выберите конечную точку сбора данных рабочей области из доступного списка:
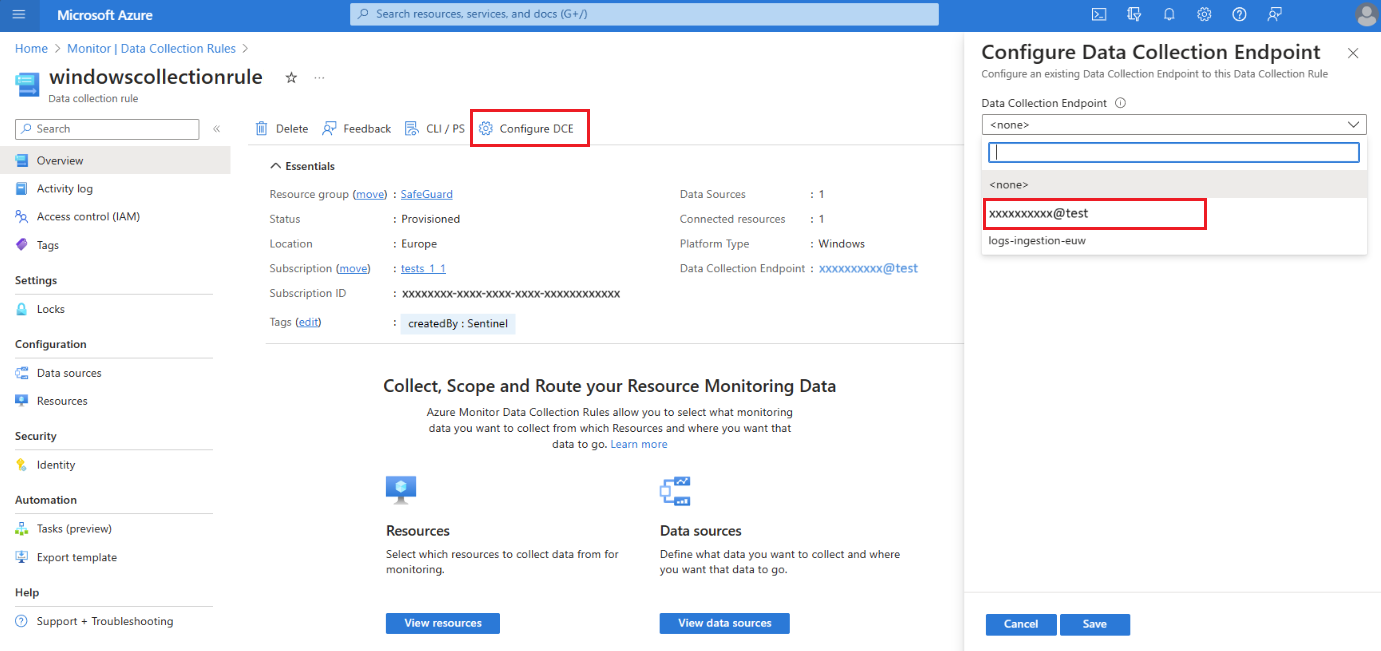
Дополнительные сведения о системе DCE см. в свойствах объекта рабочей области.

Это важно
Правила сбора данных, связанные с конечной точкой сбора данных рабочего пространства, могут быть нацелены только на это конкретное рабочее пространство. Правила сбора данных не должны нацелены на другие назначения, такие как другие рабочие области или учетные записи хранения Azure.
Что проверить, если репликация рабочей области не выполняется
- Рабочая область связана с выделенным кластером?
- Репликация должна быть включена на кластере, прежде чем ее можно будет включить на рабочем пространстве.
- Репликация как кластера, так и рабочего пространства должна быть настроена на одинаковое вторичное местоположение. Например, если кластер реплицируется в Северную Европу, то рабочие пространства, связанные с ним, также могут быть реплицированы только в Северную Европу.
- Вы использовали REST API для включения репликации?
- Убедитесь, что вы используете версию API 2025-02-01 или более позднюю.
- Основное рабочее пространство расположено в East US, East US 2 или South Central US?
- East US, East US 2 и South Central US не могут реплицироваться друг с другом.
- Где находится основное рабочее место и где вторичное? Оба местоположения должны находиться в одной группе регионов. Например, рабочие области, расположенные в регионах США, не могут иметь репликацию (дополнительный регион) в Европе и наоборот. Список групп регионов см. в разделе "Поддерживаемые регионы".
- У вас есть необходимые разрешения?
- Вы выделили достаточно времени для завершения операции репликации? Репликация — это длительная операция. Отслеживайте состояние операции, как описано в разделе "Проверка состояния подготовки рабочей области".
- Вы пытались повторно включить репликацию, чтобы изменить вторичное расположение рабочей области? Чтобы изменить расположение вторичной рабочей области, необходимо сначала отключить репликацию рабочей области, разрешить выполнение операции, а затем включить репликацию в другое дополнительное расположение.
Что проверить, если репликация рабочей области настроена, но журналы не реплицируются?
- Репликация может занять до часа, чтобы начать применяться, и некоторые типы данных могут стать реплицируемыми раньше других.
- Журналы, передаваемые в рабочую область до включения репликации, не копируются в вторичную рабочую область. Реплицируются только те журналы, которые были загружены после включения репликации.
- Если некоторые журналы реплицируются, а другие – нет, проверьте все правила сбора данных (DCR), которые передают журналы в рабочую область, чтобы они были настроены правильно. Чтобы просмотреть правила сбора данных, нацеленные на рабочую область, перейдите на вкладку 'Сбор данных' Log Analytics Workspace Insights на портале Azure.
Отключить репликацию рабочей области
Чтобы отключить репликацию для рабочей области, используйте команду az monitor log-analytics workspace update Azure CLI:
az monitor log-analytics workspace update \
--resource-group <resourcegroup_name> \
--workspace-name <workspace_name> \
--replication-enabled false
Где
-
<subscription_id>: Идентификатор подписки, связанный с вашим рабочим пространством. -
<resourcegroup_name>: Группа ресурсов, содержащая ресурс вашего рабочего пространства. -
<workspace_name>: Имя вашего рабочего пространства. -
<primary_region>: Основной регион для вашего рабочего пространства.
Команда отключения репликации — это длительная операция, которая может занять некоторое время. Состояние подготовки запроса можно отслеживать, как описано в разделе "Проверка состояния подготовки рабочей области".
Это важно
Если вы используете выделенный кластер, вам следует отключить репликацию кластера после отключения репликации для каждого рабочего пространства, связанного с этим кластером.
Отключить репликацию кластера
Отключение репликации кластера возможно только после отключения репликации для всех рабочих областей, связанных с этим кластером (если она была включена ранее).
Чтобы отключить репликацию для кластера, используйте команду az monitor log-analytics cluster update Azure CLI:
az monitor log-analytics cluster update \
--resource-group <resourcegroup_name> \
--cluster-name <cluster_name> \
--replication-enabled false
Где
-
<subscription_id>: Идентификатор подписки, связанный с вашим кластером. -
<resourcegroup_name>: Группа ресурсов, содержащая ресурсы вашего кластера. -
<workspace_name>: Название вашего кластера. -
<primary_region>: Основной регион для вашего кластера.
Эта команда является длительным процессом, который может занять некоторое время. Состояние подготовки запроса можно отслеживать, как описано в разделе "Проверка состояния подготовки рабочей области".
Примечание
После отключения репликации и очистки реплицированного кластера реплицированные журналы удаляются и не удается получить доступ снова. Их первоначальная копия в вашем основном местоположении не изменяется в этом процессе.
Это важно
Процесс удаления репликации кластера занимает 14 дней. Если вам потребуется выполнить этот процесс быстрее, создайте запрос в службу поддержки Azure.
Отслеживать состояние рабочего пространства и услуг
Задержка загрузки данных или сбои при выполнении запросов — это примеры проблем, которые часто можно решить, переключившись на резервный регион. Такие проблемы можно обнаружить с помощью уведомлений о состоянии службы и запросов журналов.
Уведомления о состоянии службы полезны для вопросов, связанных с обслуживанием. Чтобы выявить проблемы, влияющие на ваше конкретное рабочее пространство (а возможно, и не на весь сервис), вы можете использовать другие методы.
Создание оповещений на основе работоспособности ресурсов рабочей области
Настройка собственных пороговых значений для метрик работоспособности рабочей области
Создайте собственные запросы мониторинга для использования в качестве пользовательских индикаторов работоспособности рабочей области, как описано в разделе "Мониторинг производительности рабочей области с помощью запросов", чтобы:
- Измерение задержки загрузки для каждой таблицы
- Определите, является ли источником задержки агенты сбора или конвейер приема данных.
- Отслеживайте аномалии объема загрузки данных для каждой таблицы и ресурса.
- Отслеживайте успешность запросов по таблицам, пользователям или ресурсам
- Создавайте оповещения на основе ваших запросов
Примечание
Вы также можете использовать запросы логов для мониторинга вашего вторичного рабочего пространства, но имейте в виду, что репликация логов выполняется пакетными операциями. Измеренная задержка может колебаться и не указывает на какие-либо проблемы со здоровьем вашего вторичного рабочего пространства. Дополнительные сведения см. в разделе "Аудит неактивной рабочей области".
Переключитесь на свое вторичное рабочее пространство
Во время переключения большинство операций работает так же, как и при использовании основного рабочего пространства и региона. Однако некоторые операции имеют слегка отличное поведение или заблокированы. Дополнительные сведения см. в разделе "Рекомендации по развертыванию".
Когда мне нужно переключиться?
Вы решаете, когда переключиться на вторичное рабочее пространство и вернуться к основному рабочему пространству, основываясь на текущем мониторинге производительности и состояния системы, а также ваших системных стандартах и требованиях.
В вашем плане переключения следует учитывать несколько моментов, как описано в следующих разделах.
Тип и масштаб проблемы
Процесс переключения маршрутизирует запросы на загрузку и запросы к вашей вторичной области, что обычно позволяет обойти любой неисправный компонент, вызывающий задержку или сбой в вашей первичной области. В результате переключение вряд ли поможет, если:
- Существует проблема пересечений регионов с базовым ресурсом. Например, если одни и те же типы ресурсов выходят из строя как в вашем основном, так и в дополнительном регионе.
- Вы сталкиваетесь с проблемой, связанной с управлением рабочим пространством, такой как изменение сроков хранения рабочей области. Операции по управлению рабочими пространствами всегда осуществляются в вашем основном регионе. Во время переключения операции управления рабочим пространством блокируются.
Длительность проблемы
Переключение не происходит мгновенно. Процесс перенаправления запросов зависит от обновлений DNS, которые некоторые клиенты получают в течение нескольких минут, в то время как другим может потребоваться больше времени. Поэтому важно понять, можно ли решить проблему за несколько минут. Если наблюдаемая проблема стабильна или непрерывна, не ждите и переключитесь. Вот несколько примеров:
Поглощение: Проблемы с потоком данных в основном регионе могут повлиять на репликацию данных во вторичной рабочей области. Во время переключения логи вместо этого отправляются в конвейер сбора в резервном регионе.
Запрос. Если запросы в основной рабочей области завершаются сбоем или истечением времени ожидания, могут быть затронуты оповещения поиска по журналам. В этом сценарии переключитесь на ваше вторичное рабочее пространство, чтобы убедиться, что все ваши оповещения срабатывают корректно.
данные вторичной рабочей области
Логи, полученные в вашу основную рабочую область до того, как вы включите репликацию, не будут скопированы во вторичную рабочую область. Если вы включили репликацию рабочего пространства три часа назад и теперь переключаетесь на вторичное рабочее пространство, ваши запросы могут возвращать данные только за последние три часа.
Прежде чем переключать регионы во время переключения, ваша вторичная рабочая область должна содержать достаточный объем логов. Мы рекомендуем подождать как минимум одну неделю после того, как вы включите репликацию, прежде чем инициировать переключение. Семь дней позволяют получить достаточно данных в вашем вторичном регионе.
Переключение по триггеру
Перед переключением убедитесь, что операция репликации рабочей области успешно завершена. Переключение выполняется успешно только тогда, когда вторичное рабочее пространство настроено правильно.
Чтобы переключиться на вторичную рабочую область, используйте команду az monitor log-analytics workspace failover Azure CLI:
az monitor log-analytics workspace failover \
--resource-group <resourcegroup_name> \
--workspace-name <workspace_name> \
--location <secondary_region>
Где
-
<subscription_id>: Идентификатор подписки, связанный с вашим рабочим пространством. -
<resourcegroup_name>: Группа ресурсов, содержащая ресурс вашего рабочего пространства. -
<secondary_region>: Регион, на который нужно переключиться во время переключения. -
<workspace_name>: Название рабочего пространства, на которое нужно переключиться во время переключения.
Эта команда является длительным процессом, который может занять некоторое время. Состояние подготовки запроса можно отслеживать, как описано в разделе "Проверка состояния подготовки рабочей области".
Что проверить, если переключение (отказоустойчивость) не удалось
- Вы использовали REST API для инициирования переключения (фейловера)?
- Убедитесь, что вы используете версию API 2025-02-01 или более позднюю.
- Убедитесь, что резервное расположение, указанное в команде переключения на резервный источник, является резервным расположением, установленным для этой рабочей области. Эта информация доступна в представлении портала Azure рабочей области и через API.
- Для переключения регионов требуется роль участника Log Analytics в группе ресурсов рабочей области, а не только в самой рабочей области.
Переключитесь обратно на основное рабочее пространство
Процесс возврата отменяет перенаправление запросов и запросов на получение журналов на вторичное рабочее пространство. Когда вы возвращаетесь назад, Azure Monitor снова начинает маршрутизацию запросов и запросов на регистрацию журналов в ваше основное рабочее пространство.
Когда вы переключаетесь на свой вторичный регион, Azure Monitor реплицирует журналы из вашего вторичного рабочего пространства в основное рабочее пространство. Если сбой влияет на процесс поглощения журналов в основной области, Azure Monitor может потребоваться некоторое время для завершения поглощения реплицированных журналов в ваше основное рабочее пространство.
Когда мне вернуться обратно?
В вашем плане для зигзагообразного маршрута есть несколько моментов, которые нужно учесть, как описано в следующих подразделах.
Состояние репликации журнала
Прежде чем переключиться обратно, убедитесь, что Azure Monitor завершил репликацию всех журналов, загруженных в период переключения в основную регион. Если вы переключитесь обратно, прежде чем все логи будут реплицированы в основное рабочее пространство, ваши запросы могут вернуть частичные результаты, пока не завершится обработка логов.
Вы можете запросить основную рабочую область на портале Azure для неактивного региона, как описано в разделе "Аудит неактивной рабочей области".
Основное состояние рабочего пространства
Существует две важных аспекта здоровья, которые следует проверить в рамках подготовки к возвращению в ваше основное рабочее пространство.
- Подтвердите отсутствие каких-либо непогашенных уведомлений о состоянии службы для основной рабочей области и региона.
- Убедитесь, что ваше основное рабочее пространство принимает логи и обрабатывает запросы, как ожидалось.
Примеры того, как запрашивать основную рабочую область, когда вторичная рабочая область активна и обходить перенаправление запросов в вторичную рабочую область, см. в разделе "Аудит неактивной рабочей области".
Активировать переключение назад
Прежде чем вернуться, подтвердите работоспособность основной рабочей области и завершите репликацию журналов.
Процесс возврата обновляет ваши DNS-записи. После обновления записей DNS может потребоваться время, чтобы все клиенты получили обновленные настройки DNS и возобновили маршрутизацию в основной рабочий стол.
Чтобы вернуться к основной рабочей области, используйте команду az monitor log-analytics workspace failback Azure CLI:
az monitor log-analytics workspace failback \
--resource-group <resourcegroup_name> \
--workspace-name <workspace_name>
Где
-
<subscription_id>: Идентификатор подписки, связанный с вашим рабочим пространством. -
<resourcegroup_name>: Группа ресурсов, содержащая ресурс вашего рабочего пространства. -
<workspace_name>: Название рабочего пространства, к которому нужно переключиться при возврате.
Эта команда является длительным процессом, который может занять некоторое время. Состояние подготовки запроса можно отслеживать, как описано в разделе "Проверка состояния подготовки рабочей области".
Провести аудит неактивного рабочего пространства.
По умолчанию активная область рабочей области — это регион, в котором создается рабочая область, а неактивный регион — это дополнительный регион, в котором Azure Monitor создает реплицированную рабочую область.
Когда вы инициируете отказоустойчивое переключение, происходит смена — активируется вторичный регион, а первичный регион становится неактивным. Мы говорим, что оно неактивно, потому что оно не является прямой целью для поглощения логов и выполнения запросов.
Полезно делать запрос в неактивный регион перед переключением между регионами, чтобы убедиться, что рабочая область в неактивном регионе содержит нужные журналы.
Для взаимодействия с неактивным регионом необходимо использовать API Log Analytics журналов Azure Monitor. Дополнительные сведения, включая аутентификацию, см. в статье "Доступ к API Log Analytics Azure Monitor".
Запрос неактивного региона
Чтобы запросить данные журнала в неактивном регионе, используйте эту команду GET:
GET
api.loganalytics.azure.com/v1/workspaces/<workspace id>/query?query=<query>×pan=<timespan-in-ISO8601-format>&overrideWorkspaceRegion=<primary|secondary>
Например, чтобы выполнить такой короткий запрос, как Perf | count за прошедший день в вашем дополнительном регионе, используйте следующее:
GET
api.loganalytics.azure.com/v1/workspaces/<workspace id>/query?query=Perf%20|%20count×pan=P1D&overrideWorkspaceRegion=secondary
Вы можете убедиться, что Azure Monitor запускает запрос в предполагаемом регионе LAQueryLogs , проверив эти поля в таблице, которая создается при включении аудита запросов в рабочей области Log Analytics:
-
isWorkspaceInFailover: Указывает, находилось ли рабочее пространство в режиме переключения во время запроса. Тип данных — Булевский (Истина, Ложь). -
workspaceRegion: Область рабочей области, на которую направлен запрос. Тип данных — строка.
Мониторинг производительности рабочей области с помощью запросов
Мы рекомендуем использовать запросы в этом разделе для создания правил оповещений, которые будут уведомлять вас о возможных проблемах со здоровьем или производительностью рабочего пространства. Однако решение о переходе требует тщательного рассмотрения и не должно приниматься автоматически.
В правиле запроса вы можете определить условие для перехода на вторичное рабочее пространство после определенного числа нарушений. Дополнительные сведения см. в статье "Создание или изменение правила генерации оповещений поиска по журналам".
Два основных измерения производительности рабочей среды включают латентность приема и объем приема. В следующих разделах рассматриваются эти варианты мониторинга.
Мониторинг задержки приема данных от начала до конца.
Задержка при загрузке измеряет время, необходимое для загрузки журналов в рабочую область. Измерение времени начинается, когда происходит первоначальное зарегистрированное событие, и заканчивается, когда журнал сохраняется в вашем рабочем пространстве. Общая задержка при загрузке данных состоит из двух частей.
- Задержка агента: время, необходимое агенту для отчета о событии.
- Задержка конвейера обработки данных (серверная часть): время, необходимое для того, чтобы конвейер обработки данных обработал журналы и записал их в вашу рабочую область.
Разные типы данных имеют различную задержку приёма. Вы можете измерить обработку для каждого типа данных отдельно, создать универсальный запрос для всех типов, а также более подробный запрос для наиболее важных для вас типов. Мы рекомендуем измерять 90-й процентиль задержки приема данных, который чувствительнее к изменениям, чем среднее значение или 50-й процентиль (медиана).
Следующие разделы показывают, как использовать запросы для проверки задержки загрузки данных в ваше рабочее пространство.
Оцените базовую задержку поглощения данных для конкретных таблиц.
Начните с определения базового времени задержки для конкретных таблиц за несколько дней.
Этот пример запроса создает диаграмму 90-го процентиля задержки поступления данных в таблице Perf.
// Assess the ingestion latency baseline for a specific data type
Perf
| where TimeGenerated > ago(3d)
| project TimeGenerated,
IngestionDurationSeconds = (ingestion_time()-TimeGenerated)/1s
| summarize LatencyIngestion90Percentile=percentile(IngestionDurationSeconds, 90) by bin(TimeGenerated, 1h)
| render timechart
После выполнения запроса просмотрите результаты и построенный график, чтобы определить ожидаемую задержку для этой таблицы.
Отслеживайте и предупреждайте о текущей задержке приёмки
После установления базовой задержки приема для определенной таблицы создайте правило генерации оповещений поиска по журналам для таблицы на основе изменений задержки за короткий период времени.
Этот запрос вычисляет задержку загрузки за последние 20 минут:
// Track the recent ingestion latency (in seconds) of a specific table
Perf
| where TimeGenerated > ago(20m)
| extend IngestionDurationSeconds = (ingestion_time()-TimeGenerated)/1s
| summarize Ingestion90Percent_seconds=percentile(IngestionDurationSeconds, 90)
Поскольку можно ожидать некоторых колебаний, создайте условие правила уведомления, чтобы проверить, возвращает ли запрос значение, значительно превышающее базовый уровень.
Определите источник задержки загрузки данных
Когда вы замечаете, что общая задержка при поступлении данных увеличивается, вы можете использовать запросы, чтобы определить, является ли источником задержки агенты или канал поступления данных.
Этот запрос строит график задержки на 90-м процентиле как агентов, так и конвейера отдельно.
// Assess agent and pipeline (backend) latency
Perf
| where TimeGenerated > ago(1h)
| extend AgentLatencySeconds = (_TimeReceived-TimeGenerated)/1s,
PipelineLatencySeconds=(ingestion_time()-_TimeReceived)/1s
| summarize percentile(AgentLatencySeconds,90), percentile(PipelineLatencySeconds,90) by bin(TimeGenerated,5m)
| render columnchart
Примечание
Хотя на диаграмме 90-й процентиль данных представлен в виде диаграммы с накоплением, сумма данных в двух диаграммах не равняется общему 90-му процентилю по обработке данных.
Мониторинг объема приема
Измерения объема потребления могут помочь выявить неожиданные изменения в общем объеме потребления или объеме потребления для конкретной таблицы в вашем рабочем пространстве. Измерения объёма запросов могут помочь вам выявить проблемы с производительностью при передаче журналов. К некоторым полезным измерениям объема относятся:
- Объем данных, загружаемых в каждую таблицу
- Постоянный объем потребления (остановка)
- Аномалии загрузки — резкие изменения и падения объёма загрузки
Следующие разделы показывают, как использовать запросы для проверки объема потребления данных в вашем рабочем пространстве.
Мониторинг общего объема загрузки для каждой таблицы.
Вы можете определить запрос для мониторинга объема данных по каждой таблице в рабочем пространстве. Запрос может включать оповещение, которое проверяет неожиданные изменения общих или специфичных для таблицы объемов.
Этот запрос вычисляет общий объем поглощения данных за последний час для каждой таблицы в мегабайтах в секунду (МБ/с).
// Calculate total ingestion volume over the past hour per table
Usage
| where TimeGenerated > ago(1h)
| summarize BillableDataMB = sum(_BilledSize)/1.E6 by bin(TimeGenerated,1h), DataType
Проверьте на остановку процесса поглощения
При приеме журналов через агенты можно использовать пульс агента для обнаружения подключения. Остановка сердцебиения может свидетельствовать о прекращении приема логов в ваш рабочий процесс. Когда данные запроса показывают остановку процесса приема, вы можете определить условие для вызова необходимой реакции.
Следующий запрос проверяет наличие сигнала агента для обнаружения проблем с подключением.
// Count agent heartbeats in the last ten minutes
Heartbeat
| where TimeGenerated>ago(10m)
| count
Отслеживание аномалий при поглощении
Вы можете определить пики и падения данных об объеме поступлений в рабочем пространстве различными способами. Используйте функцию series_decompose_anomalies(), чтобы извлечь аномалии из объемов данных, которые вы отслеживаете в своей рабочей области, или создайте собственный анализатор аномалий, соответствующий уникальным сценариям вашей рабочей области.
Определите аномалии, используя series_decompose_anomalies
Функция series_decompose_anomalies() выявляет аномалии в ряду значений данных. Запрос вычисляет ежечасный объем данных для каждой таблицы в вашем рабочем пространстве Log Analytics и использует series_decompose_anomalies() для идентификации аномалий.
// Calculate hourly ingestion volume per table and identify anomalies
Usage
| where TimeGenerated > ago(24h)
| project TimeGenerated, DataType, Quantity
| summarize IngestionVolumeMB=sum(Quantity) by bin(TimeGenerated, 1h), DataType
| summarize
Timestamp=make_list(TimeGenerated),
IngestionVolumeMB=make_list(IngestionVolumeMB)
by DataType
| extend series_decompose_anomalies(IngestionVolumeMB)
| mv-expand
Timestamp,
IngestionVolumeMB,
series_decompose_anomalies_IngestionVolumeMB_ad_flag,
series_decompose_anomalies_IngestionVolumeMB_ad_score,
series_decompose_anomalies_IngestionVolumeMB_baseline
| where series_decompose_anomalies_IngestionVolumeMB_ad_flag != 0
Дополнительные сведения об обнаружении series_decompose_anomalies() аномалий в данных журнала см. в статье "Обнаружение и анализ аномалий" с помощью возможностей машинного обучения KQL в Azure Monitor.
Создайте свой собственный детектор аномалий
Вы можете создать индивидуальный детектор аномалий для поддержки требований сценария конфигурации вашего рабочего пространства. Этот раздел содержит пример, чтобы продемонстрировать процесс.
Следующий запрос вычисляет:
- Ожидаемый объем приема: в час по таблицам (на основе медианы медианов, но можно настроить логику)
- Фактический объем приема: в час, по таблице
Чтобы устранить незначительные различия между ожидаемым и фактическим объёмом ввода данных, запрос применяет два фильтра:
- Скорость изменения: более 150% или менее 66% ожидаемого объема в соответствии с таблицей
- Объем изменений: указывает, является ли увеличение или уменьшение объема более чем 0,1% ежемесячного объема этой таблицы.
// Calculate expected vs actual hourly ingestion per table
let TimeRange=24h;
let MonthlyIngestionByType=
Usage
| where TimeGenerated > ago(30d)
| summarize MonthlyIngestionMB=sum(Quantity) by DataType;
// Calculate the expected ingestion volume by median of hourly medians
let ExpectedIngestionVolumeByType=
Usage
| where TimeGenerated > ago(TimeRange)
| project TimeGenerated, DataType, Quantity
| summarize IngestionMedian=percentile(Quantity, 50) by bin(TimeGenerated, 1h), DataType
| summarize ExpectedIngestionVolumeMB=percentile(IngestionMedian, 50) by DataType;
Usage
| where TimeGenerated > ago(TimeRange)
| project TimeGenerated, DataType, Quantity
| summarize IngestionVolumeMB=sum(Quantity) by bin(TimeGenerated, 1h), DataType
| join kind=inner (ExpectedIngestionVolumeByType) on DataType
| extend GapVolumeMB = round(IngestionVolumeMB-ExpectedIngestionVolumeMB,2)
| where GapVolumeMB != 0
| extend Trend=iff(GapVolumeMB > 0, "Up", "Down")
| extend IngestedVsExpectedAsPercent = round(IngestionVolumeMB * 100 / ExpectedIngestionVolumeMB, 2)
| join kind=inner (MonthlyIngestionByType) on DataType
| extend GapAsPercentOfMonthlyIngestion = round(abs(GapVolumeMB) * 100 / MonthlyIngestionMB, 2)
| project-away DataType1, DataType2
// Determine whether the spike/deep is substantial: over 150% or under 66% of the expected volume for this data type
| where IngestedVsExpectedAsPercent > 150 or IngestedVsExpectedAsPercent < 66
// Determine whether the gap volume is significant: over 0.1% of the total monthly ingestion volume to this workspace
| where GapAsPercentOfMonthlyIngestion > 0.1
| project
Timestamp=format_datetime(todatetime(TimeGenerated), 'yyyy-MM-dd HH:mm:ss'),
Trend,
IngestionVolumeMB,
ExpectedIngestionVolumeMB,
IngestedVsExpectedAsPercent,
GapAsPercentOfMonthlyIngestion
Следить за успешностью и неудачами запросов
Каждый запрос возвращает код ответа, который указывает на успех или неудачу. Когда запрос не удаётся, в ответ также включаются типы ошибок. Высокий скачок ошибок может указывать на проблемы с доступностью рабочего пространства или производительностью службы.
Этот запрос подсчитывает количество запросов, которые вернули код ошибки сервера.
// Count query errors
LAQueryLogs
| where ResponseCode>=500 and ResponseCode<600
| count