Примечание.
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
Мониторинг и наблюдаемость играют ключевую роль в поддержании высокой производительности и низкой стоимости развертываний рабочих нагрузок ИИ в службе Azure Kubernetes (AKS). Видимость системных и показателей производительности может указывать ограничения базовой инфраструктуры и мотивировать корректировки и оптимизации в режиме реального времени для снижения прерываний рабочей нагрузки. Мониторинг также предоставляет ценные сведения об использовании ресурсов для эффективного управления вычислительными ресурсами и точной подготовкой.
Оператор цепочки инструментов ИИ Kubernetes (KAITO) — это управляемая надстройка для AKS, которая упрощает развертывание и операции для моделей ИИ в кластере AKS.
В KAITO версии 0.4.4 и более поздних версиях среда выполнения вывода vLLM включена по умолчанию в управляемой надстройке AKS. vLLM — это библиотека для вывода и обслуживания языковой модели. Она обеспечивает видимость ключевых показателей производительности системы, использования ресурсов и обработки запросов для метрик Prometheus, которые можно использовать для оценки развертываний инференса KAITO.
В этой статье вы узнаете, как отслеживать и визуализировать метрики вывода vLLM с помощью надстройки оператора цепочки инструментов ИИ с помощью управляемого Prometheus Azure и Управляемого Grafana в кластере AKS.
Перед тем как начать
- В этой статье предполагается, что у вас есть кластер AKS. Если у вас нет кластера, создайте его с помощью Azure CLI, Azure PowerShell или портала Azure.
- Установите и настройте Azure CLI версии 2.47.0 или более поздней. Чтобы узнать, какая версия используется, выполните команду
az --version. Сведения об установке или обновлении см. в статье "Установка Azure CLI".
Предпосылки
- Установите и настройте kubectl, клиент командной строки Kubernetes. Дополнительные сведения см. в разделе "Установка kubectl".
- Включите дополнение оператора инструментальной среды ИИ в вашем кластере AKS.
- Если у вас уже есть надстройка оператора цепочки инструментов ИИ, обновите кластер AKS до последней версии, чтобы запустить KAITO версии 0.4.4 или более поздней версии.
- Включите управляемую службу Prometheus и управляемую Azure Grafana в кластере AKS.
- У вас есть разрешения на создание или обновление экземпляров Azure Managed Grafana в подписке Azure.
Развертывание службы вывода KAITO
В этом примере вы собираете метрики для языковой модели Qwen-2.5-coder-7B-instruct.
Начните с применения к кластеру следующего настраиваемого ресурса рабочей области KAITO:
kubectl apply -f https://raw.githubusercontent.com/Azure/kaito/main/examples/inference/kaito_workspace_qwen_2.5_coder_7b-instruct.yamlОтслеживайте изменения динамических ресурсов в рабочей области KAITO:
kubectl get workspace workspace-qwen-2-5-coder-7b-instruct -wПримечание.
Готовность компьютера может занять до 10 минут, а готовность рабочей области может занять до 20 минут в зависимости от размера языковой модели.
Убедитесь, что служба вывода заключений запущена и узнайте IP-адрес службы.
export SERVICE_IP=$(kubectl get svc workspace-qwen-2-5-coder-7b-instruct -o jsonpath='{.spec.clusterIP}') echo $SERVICE_IP
Метрики вывода Surface KAITO в управляемую службу для Prometheus
Метрики Prometheus собираются по умолчанию в конечной точке KAITO/metrics.
Добавьте следующую метку в инференс-сервис KAITO, чтобы развертывание Kubernetes
ServiceMonitorмогло его обнаружить.kubectl label svc workspace-qwen-2-5-coder-7b-instruct App=qwen-2-5-coderServiceMonitorСоздайте ресурс для определения конечных точек службы вывода и необходимых конфигураций для удаления метрик VLLM Prometheus. Экспортируйте эти метрики в управляемую службу Prometheus, развернув следующийServiceMonitorманифест YAML вkube-systemпространстве имен.cat <<EOF | kubectl apply -n kube-system -f - apiVersion: azmonitoring.coreos.com/v1 kind: ServiceMonitor metadata: name: prometheus-kaito-monitor spec: selector: matchLabels: App: qwen-2-5-coder endpoints: - port: http interval: 30s path: /metrics scheme: http EOFПроверьте наличие следующих выходных данных, чтобы убедиться, что
ServiceMonitorсоздано:servicemonitor.azmonitoring.coreos.com/prometheus-kaito-monitor createdУбедитесь, что развертывание
ServiceMonitorуспешно запущено:kubectl get servicemonitor prometheus-kaito-monitor -n kube-systemНа портале Azure убедитесь, что метрики vLLM успешно собираются в управляемой службе для Prometheus.
В рабочей области Azure Monitor перейдите в Управляемый Prometheus>обозреватель Prometheus.
Выберите вкладку "Сетка" и убедитесь, что элемент метрик связан с именем
workspace-qwen-2-5-coder-7b-instructзадания.Примечание.
Значение
upэтого элемента должно быть1. Значение1указывает, что метрики Prometheus успешно удаляются из конечной точки службы вывода ИИ.
Визуализация метрик вывода KAITO в Azure Managed Grafana
Проект vLLM предоставляет конфигурацию панели мониторинга Grafana с именемgrafana.json для мониторинга рабочей нагрузки вывода. Перейдите к нижней части этой страницы и скопируйте все содержимое
grafana.jsonфайла.Перейдите в нижней части страницы примеров и скопируйте все содержимое
grafana.jsonфайла:
Выполните действия, чтобы импортировать конфигурации Grafana в новую панель мониторинга в Управляемой Grafana Azure.
Перейдите к конечной точке управляемой Grafana, просмотрите доступные панели и выберите панель vLLM.
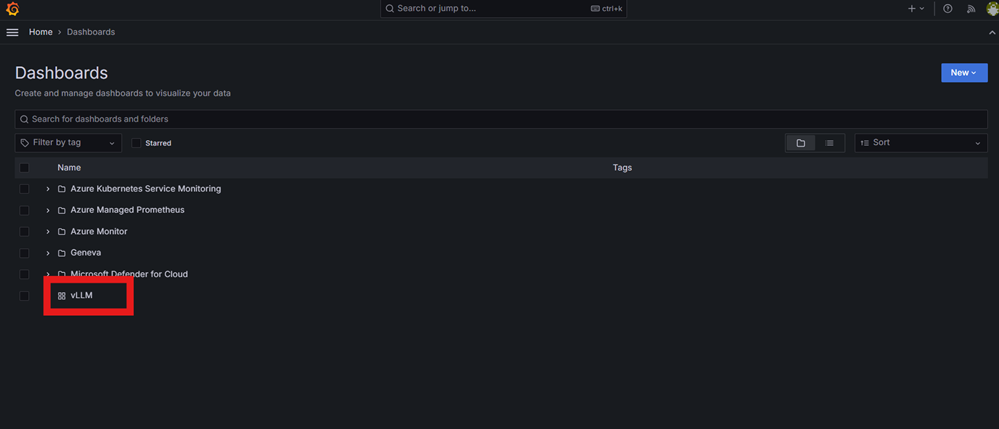
Чтобы начать сбор данных для выбранного развертывания модели, убедитесь, что значение источника данных, отображаемое в левом верхнем углу дашборда Grafana, является экземпляром управляемой службы Prometheus, созданной для этого примера.
Скопируйте имя предустановки для вывода данных, определенное в рабочей области KAITO, в поле model_name на панели Grafana. В этом примере имя модели — qwen2.5-coder-7b-instruct.
Через несколько секунд убедитесь, что метрики для службы вывода KAITO отображаются на панели мониторинга VLLM Grafana.

Примечание.
Значение этих метрик вывода остается 0 до отправки запросов на сервер вывода модели.



Связанный контент
- Мониторьте и визуализируйте свои развертывания AKS в большом масштабе.
- Тестирование и мониторинг вызова инструментов с инференцией KAITO в вашем кластере.
- Точно настройте модель ИИ с помощью дополнительного модуля оператора AI Toolchain в AKS.
- Сведения о вариантах развертывания рабочей нагрузки GPU AKS на узлах Linux и Windows .