Примечание.
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
Применяется только к:![]() Портал Foundry (классический). Эта статья недоступна для нового портала Foundry.
Дополнительные сведения о новом портале.
Портал Foundry (классический). Эта статья недоступна для нового портала Foundry.
Дополнительные сведения о новом портале.
Примечание
Содержание в новой документации Microsoft Foundry может открываться по ссылкам в этой статье вместо документации Foundry (классической версии), которую вы просматриваете сейчас.
Важно
Элементы, помеченные (предварительная версия) в этой статье, в настоящее время находятся в общедоступной предварительной версии. Эта предварительная версия предоставляется без соглашения об уровне обслуживания, и мы не рекомендуем ее для рабочих нагрузок. Некоторые функции могут не поддерживаться или могут иметь ограниченные возможности. Дополнительные сведения см. в разделе Supplemental Terms of Use for Microsoft Azure Previews.
Мониторинг приложений, развернутых в рабочей среде, является важной частью жизненного цикла создания приложений ИИ. Изменения в поведении данных и потребителей могут повлиять на ваше приложение с течением времени. Эти изменения могут привести к устаревшим системам, которые негативно влияют на бизнес-результаты. Такие системы предоставляют организациям риски соответствия, экономической и репутации.
Примечание
Для улучшенного способа непрерывного мониторинга развернутых приложений, отличного от системы обработки запросов, рассмотрите возможность использования онлайн-оценок Azure AI.
С помощью мониторинга Azure AI для генеративных ИИ приложений вы можете отслеживать ваши приложения в рабочей среде в продакшене для использования токенов, качества генерации и операционных метрик.
Интеграции для мониторинга развертывания потока команд позволяют выполнять следующие действия.
- Соберите данные вывода рабочей среды из развернутого приложения потока запроса.
- Применяйте метрики оценки ответственного искусственного интеллекта, такие как обоснованность, согласованность, беглость и релевантность, которые совместимы с метриками оценки потока подсказок.
- Отслеживайте запросы, выполнение и общее использование токенов в каждом развертывании модели в процессе обработки запросов.
- Отслеживайте операционные метрики, такие как количество запросов, задержка и частота ошибок.
- Используйте предварительно настроенные оповещения и значения по умолчанию для выполнения мониторинга на регулярной основе.
- Использование визуализаций данных и настройка расширенного поведения на портале Microsoft Foundry.
Необходимые условия
Важно
Эта статья предоставляет устаревшую поддержку для проектов на основе концентраторов. Он не будет работать для проектов Foundry. Узнайте , какой у меня тип проекта?
примечание о совместимости SDK. Для примеров кода требуется определенная версия пакета SDK для Foundry Microsoft. При возникновении проблем совместимости рассмотрите возможность миграции из концентратора в проект Foundry.
- Учетная запись Azure с активной подпиской. Если у вас нет, создайте учетную запись free Azure, которая включает бесплатную пробную подписку.
- Если у вас нет одного, создайте проект на основе концентратора.
- Готовый к развертыванию поток. Если у вас его нет, см. статью "Разработка потока запроса".
- Управление доступом на основе ролей в Azure для предоставления доступа к операциям на портале Foundry. Для выполнения указаний в этой статье ваша учетная запись пользователя должна иметь назначенную роль разработчика ИИ Azure в группе ресурсов. Дополнительные сведения см. в разделе "Управление доступом на основе ролей" для Foundry.
Требования к метрикам мониторинга
Генеративные предварительно обученные языковые модели трансформеров (GPT) генерируют метрики мониторинга при настройке с конкретными инструкциями по оценке или шаблонами запросов. Эти модели служат моделями оценивания для задач последовательности-в-последовательность.
Использование этого метода для создания метрик мониторинга показывает сильные эмпирические результаты и высокую корреляцию с человеческим решением по сравнению со стандартными метриками оценки искусственного интеллекта. Дополнительные сведения об оценке потока запросов см. в статьях «Отправка пакетного тестирования» и оценка потока и наблюдаемость в генеративном ИИ.
Следующие модели GPT создают метрики мониторинга. Эти модели GPT поддерживаются с мониторингом и настроены в качестве ресурса OpenAI Azure:
- GPT-3.5 Turbo
- GPT-4
- GPT-4-32k
Поддерживаемые метрики для мониторинга
Для мониторинга поддерживаются следующие метрики.
| Метрика | Описание |
|---|---|
| Заземленность | Измеряет, насколько хорошо созданные модели ответы соответствуют данным из исходных данных (определяемый пользователем контекст). |
| Актуальность | Измеряет степень, в которой созданные моделью ответы относятся к заданным вопросам и непосредственно связаны с заданными вопросами. |
| Согласованность | Измеряет степень, в которой созданные моделями ответы логически согласованы и связаны. |
| Плавность | Измеряет грамматическую корректность ответа, предсказанного генеративным ИИ. |
Сопоставление имен столбцов
При создании потока убедитесь, что вы сопоставляете имена столбцов. Следующие имена входных столбцов данных используются для измерения безопасности и качества создания данных.
| Имя входного столбца | Определение | Обязательный или необязательный |
|---|---|---|
| Вопрос | Исходный запрос, который также называется входными данными или вопросом. | Обязательно |
| Ответ | Окончательное завершение вызова API, который возвращается, также называется выходными данными или ответами. | Обязательно |
| Контекст | Все данные контекста, отправляемые вызову API, вместе с исходным запросом. Например, если вы хотите получить результаты поиска только из определенных сертифицированных источников информации или веб-сайтов, можно определить этот контекст в шагах оценки. | Необязательный |
Параметры, необходимые для метрик
Параметры, настроенные в ресурсе данных, определяют, какие метрики можно создать в соответствии с этой таблицей.
| Метрика | Вопрос | Ответ | Контекст |
|---|---|---|---|
| Согласованность | Обязательно | Обязательно | - |
| Плавность | Обязательно | Обязательно | - |
| Заземленность | Обязательно | Обязательно | Обязательно |
| Актуальность | Обязательно | Обязательно | Обязательно |
Настройка мониторинга для потока подсказок
Чтобы настроить мониторинг для вашего приложения потоковой обработки запросов, разверните приложение потоковой обработки запросов с включением сбора данных инференса. Затем настройте мониторинг развернутого приложения.
Развертывание приложения потока подсказок с последующим сбором данных инференса
В этом разделе вы узнаете, как развернуть поток обработки с использованием сбора данных для вывода. Дополнительные сведения см. в статье "Развертывание потока для вывода в режиме реального времени".
Совет
Так как вы можете настроить левую панель на портале Microsoft Foundry, вы можете увидеть элементы, которые могут отличаться от тех, что показаны в этих шагах. Если вы не видите, что вы ищете, выберите ... Подробнее в нижней части левой панели.
-
Войдите в Microsoft Foundry. Убедитесь, что переключатель New Foundry отключен. Эти шаги относятся к Foundry (classic).

Если вы еще не находитесь в проекте, выберите его.
Важно
Эта статья предоставляет устаревшую поддержку для проектов на основе концентраторов. Он не будет работать для проектов Foundry. Узнайте , какой у меня тип проекта?
примечание о совместимости SDK. Для примеров кода требуется определенная версия пакета SDK для Foundry Microsoft. При возникновении проблем совместимости рассмотрите возможность миграции из концентратора в проект Foundry.
На левой панели выберите поток запроса.
Выберите созданный ранее поток запроса.
В этой статье предполагается, что вы создали поток данных, готовый к развертыванию. Если у вас его нет, см. статью "Разработка потока запроса".
Убедитесь, что поток выполняется успешно, и что необходимые входные и выходные данные настроены для метрик, которые необходимо оценить.
Минимальные необходимые параметры - вопрос, входные данные, ответы и выходные данные. Предоставление минимальных параметров обеспечивает только две метрики: согласованность и беглость. Настройте поток, как описано в разделе "Требования к метрикам мониторинга". В этом примере в качестве входных данных потока используется
question(вопрос) иchat_history(контекст) иanswer(Ответ) в качестве выходных данных потока.Выберите "Развернуть", чтобы начать развертывание потока.
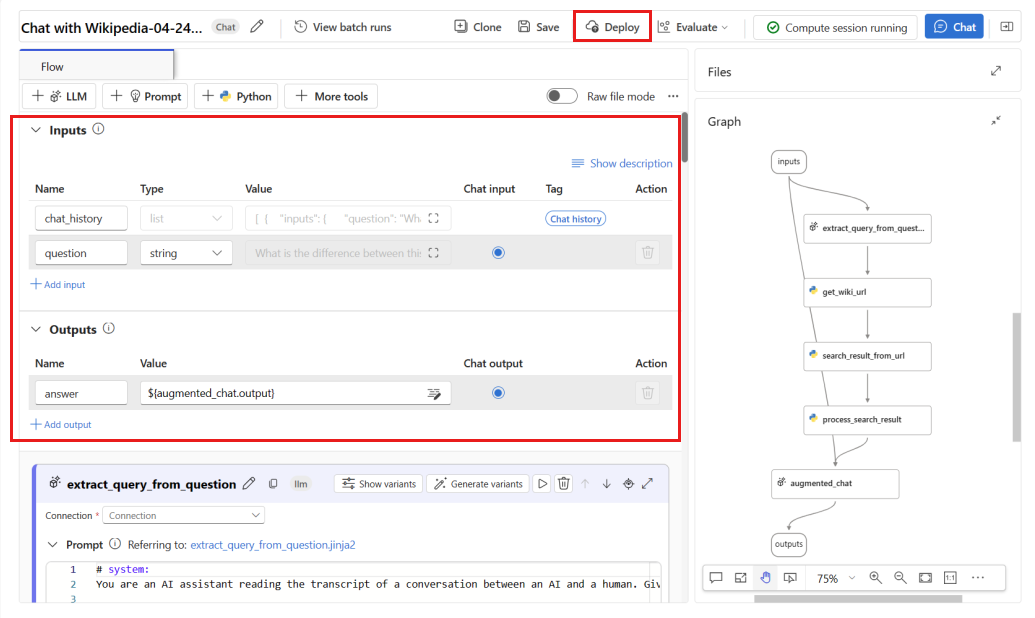
В окне развертывания убедитесь, что сбор данных выводов включен. Используйте этот параметр, чтобы бесшовно интегрировать данные инференции вашего приложения в Хранилище BLOB-объектов Azure. Эта коллекция данных требуется для мониторинга.
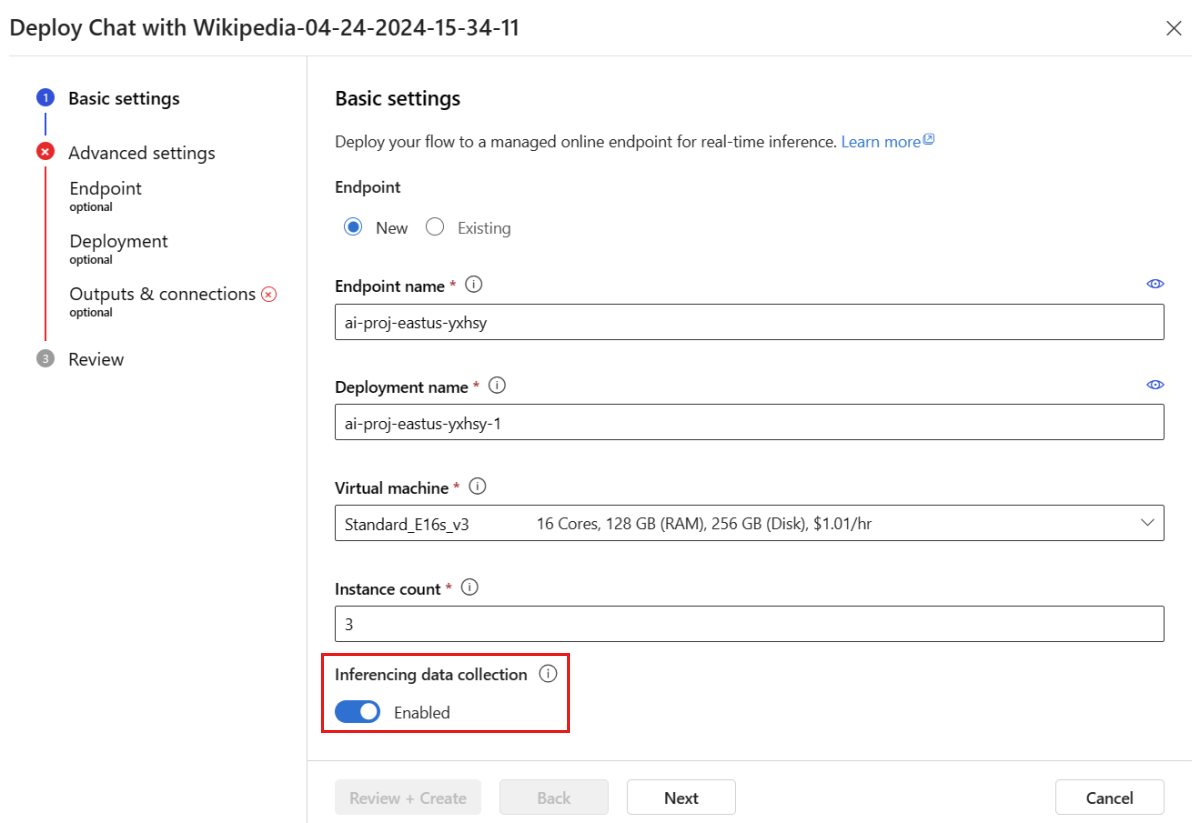
Следуйте шагам в окне среды развертывания, чтобы завершить настройку расширенных параметров.
На странице Обзор просмотрите конфигурацию развертывания и выберите Создать, чтобы развернуть поток.
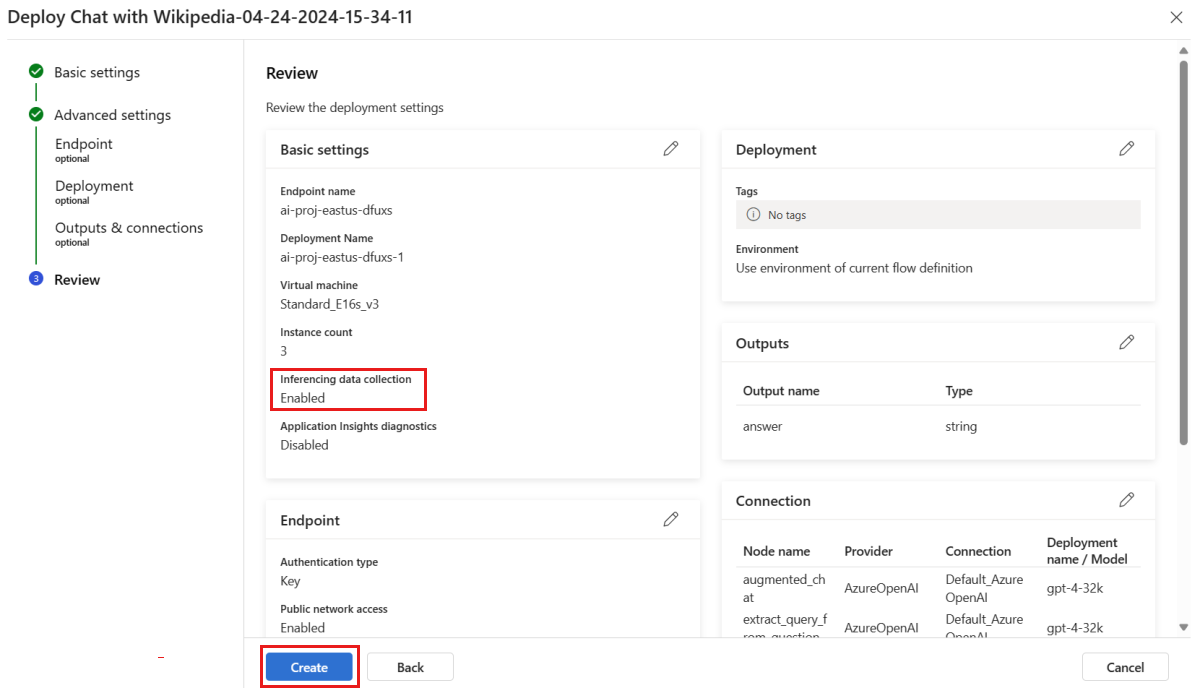
По умолчанию все входные и выходные данные вашего приложения потока запроса, которое развернуто, собираются в ваше BLOB-хранилище. При запуске развертывания данные собираются для использования вашим монитором.
Перейдите на вкладку "Тест" на странице развертывания. Затем протестируйте развертывание, чтобы убедиться, что оно работает правильно.
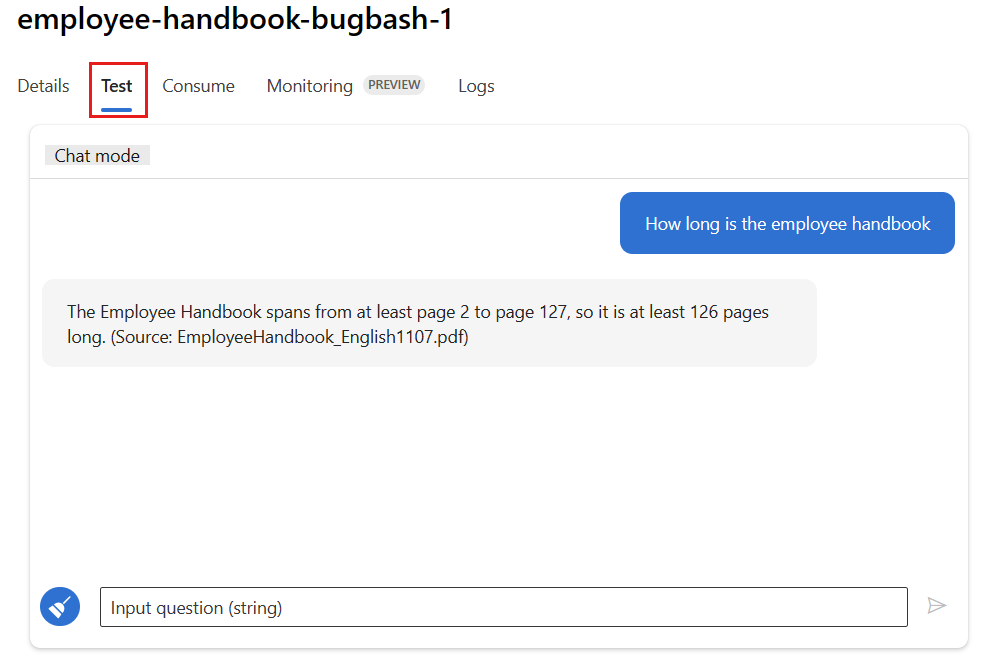
Для мониторинга требуется, чтобы по крайней мере одна точка данных была получена из источника, отличного от вкладки "Тест " в развертывании. Используйте REST API, доступный на вкладке Использование, чтобы отправить образцы запросов к развертыванию. Дополнительные сведения о том, как отправить примерные запросы на ваше развертывание, см. статью "Создание онлайн-развертывания".




Настройка мониторинга
В этом разделе вы узнаете, как настроить мониторинг для вашего развернутого приложения потокового ввода данных.
На левой панели перейдите в раздел "Мои активы>" Модели и конечные точки".
Выберите развертывание потока prompt flow, которое вы создали.
В поле "Включить мониторинг качества создания" нажмите кнопку "Включить".
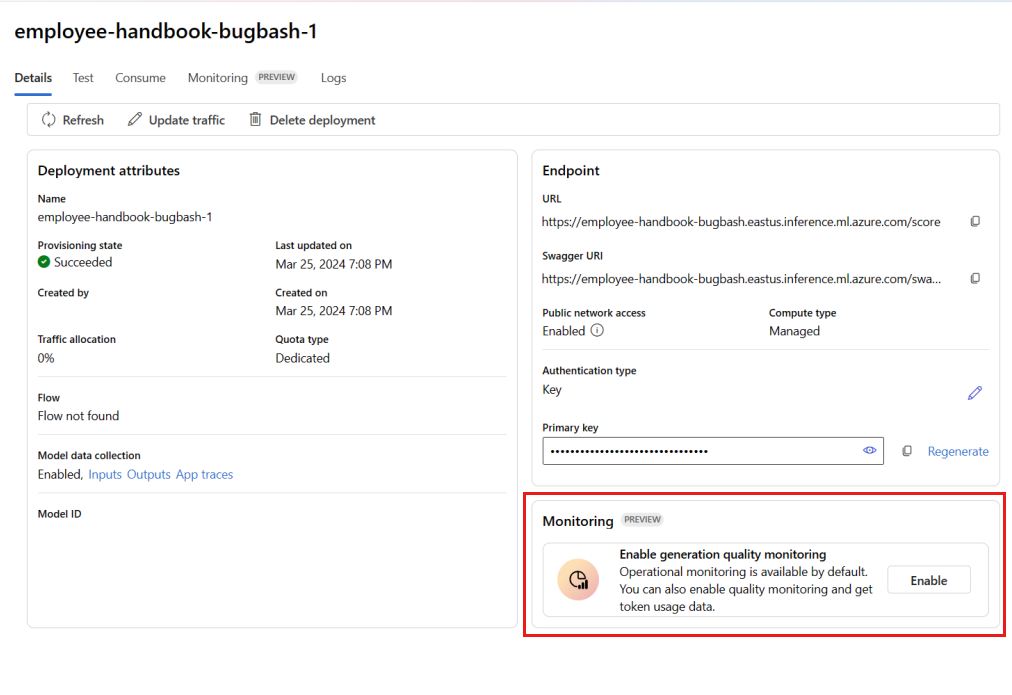
Начните настраивать мониторинг, выбрав нужные метрики.
Убедитесь, что имена столбцов сопоставлены с вашим потоком в соответствии с сопоставлением имен столбцов.
Выберите значения для Подключение Azure OpenAI и Развертывание, которые вы хотите использовать для выполнения мониторинга вашего приложения потока запроса.
Выберите дополнительные параметры , чтобы просмотреть дополнительные параметры для настройки.
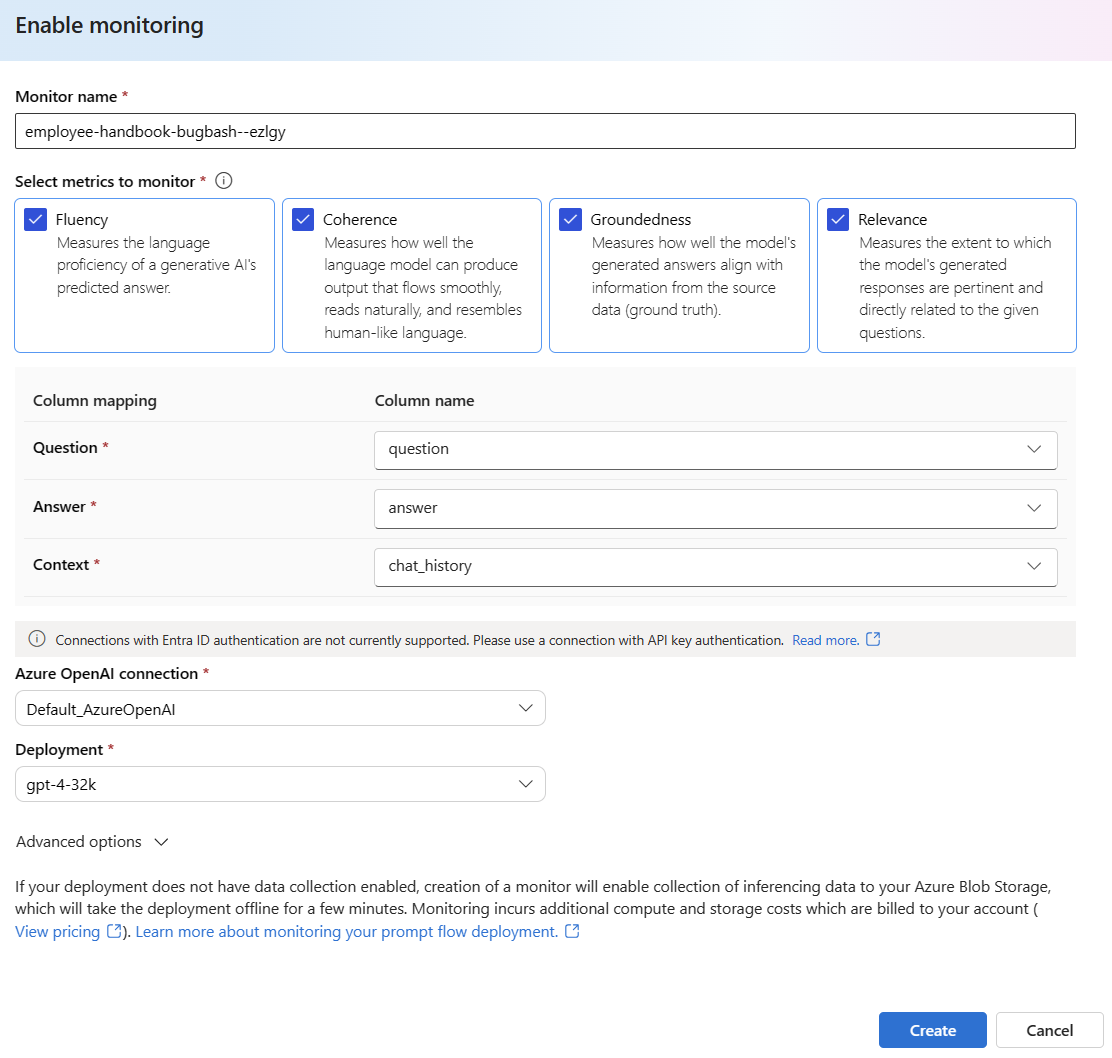
Настройте частоту выборки и пороговые значения для настроенных метрик. Укажите адреса электронной почты, которые должны получать оповещения, когда средняя оценка для заданной метрики ниже порогового значения.
Если сбор данных не включен для вашего развертывания, создание монитора позволяет собирать данные вывода в хранилище Blob. Эта задача переводит развертывание в автономный режим на несколько минут.
Нажмите кнопку "Создать", чтобы создать монитор.



Использование результатов мониторинга
После создания монитора он ежедневно выполняет вычисление показателей использования токенов и качества генерации.
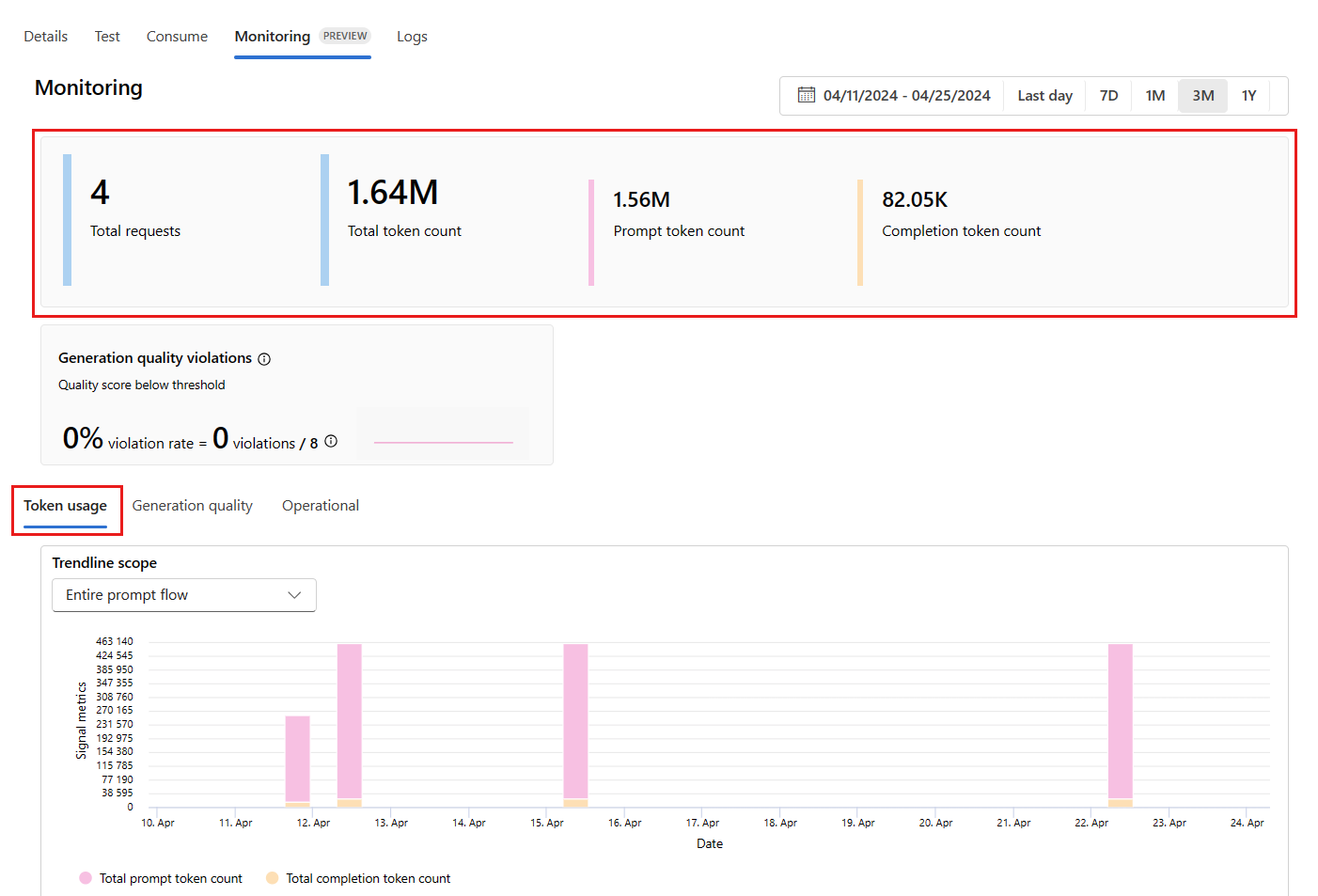
В развертывании перейдите на вкладку "Мониторинг (предварительная версия"), чтобы просмотреть результаты мониторинга. В выбранном окне времени отображается обзор результатов мониторинга. Используйте средство выбора дат, чтобы изменить период времени мониторинга данных. В этом обзоре доступны следующие метрики:
- Общее количество запросов: общее количество запросов, отправленных в развертывание в течение выбранного периода времени.
- Общее количество маркеров: общее количество маркеров, используемых развертыванием в течение выбранного периода времени.
- Количество маркеров запроса: количество маркеров запроса, используемых развертыванием в течение выбранного периода времени.
- Количество маркеров завершения: количество маркеров завершения, используемых развертыванием в течение выбранного периода времени.
Просмотрите метрики на вкладке "Использование маркеров ". Эта вкладка выбрана по умолчанию. Вы можете просматривать использование токенов вашего приложения во времени. Вы также можете увидеть, как распределяются маркеры запроса и завершения с течением времени. Измените значение области Trendline, чтобы отслеживать использование токенов во всем приложении или для конкретного развертывания, например GPT-4, используемого в вашем приложении.
Перейдите на вкладку "Качество создания" , чтобы отслеживать качество приложения с течением времени. На диаграмме времени отображаются следующие метрики:
- Число нарушений: количество нарушений для заданной метрики, например беглости, является суммой нарушений в течение выбранного периода времени. Нарушение метрики возникает при вычислении метрик, если вычисляемое значение для метрики ниже заданного порогового значения. По умолчанию метрики вычисляются ежедневно.
- Средняя оценка: средняя оценка для заданной метрики, например беглость, — это сумма показателей для всех экземпляров или запросов, разделенная на количество экземпляров или запросов в течение выбранного периода времени.
Нарушения качества создания показывают частоту нарушений в течение выбранного периода времени. Частота нарушений — это количество нарушений, разделенных на общее количество возможных нарушений. Пороговые значения метрик можно настроить в параметрах. По умолчанию метрики вычисляются ежедневно. Вы также можете настроить эту частоту в параметрах.
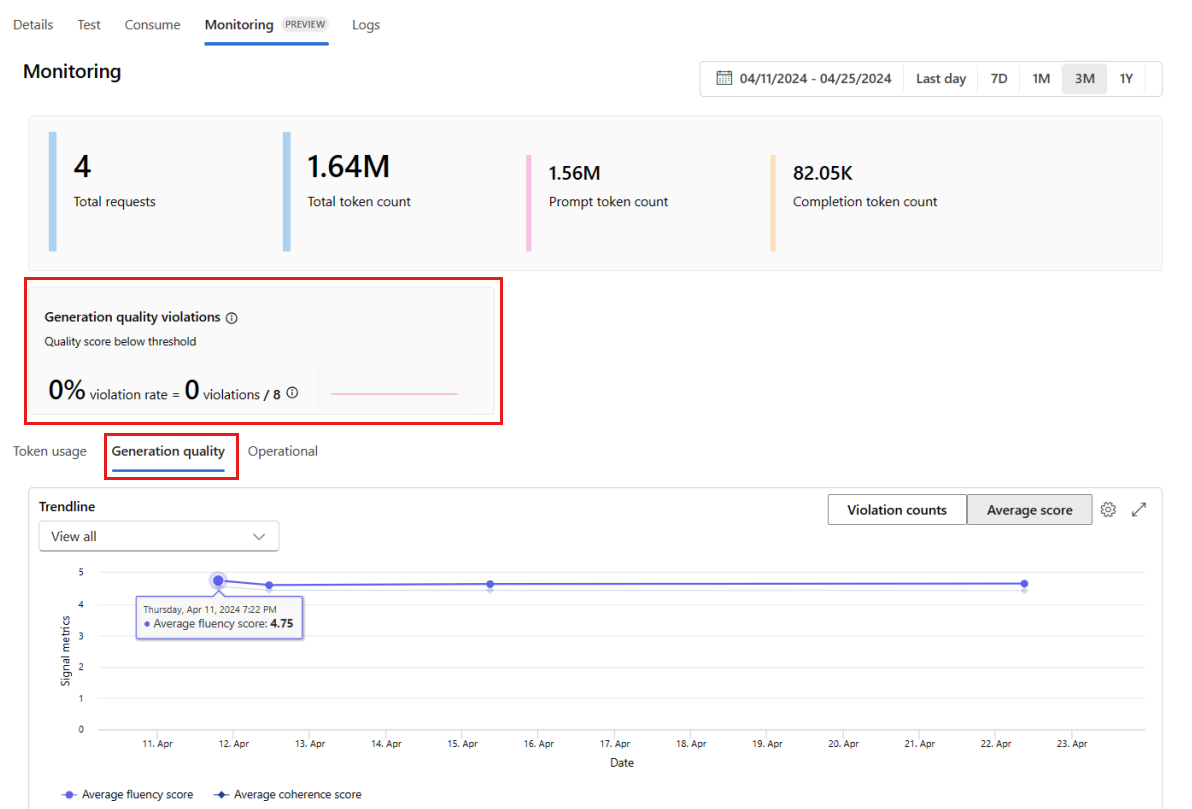
На вкладке "Мониторинг ( предварительная версия) можно просмотреть полную таблицу всех примеров запросов, отправленных в развертывание в течение выбранного периода времени.
Мониторинг задает частоту выборки по умолчанию в 10%. Например, если 100 запросов отправляются в развертывание, из них выбираются 10, которые используются для вычисления метрик качества результата. Вы можете настроить частоту выборки в параметрах.
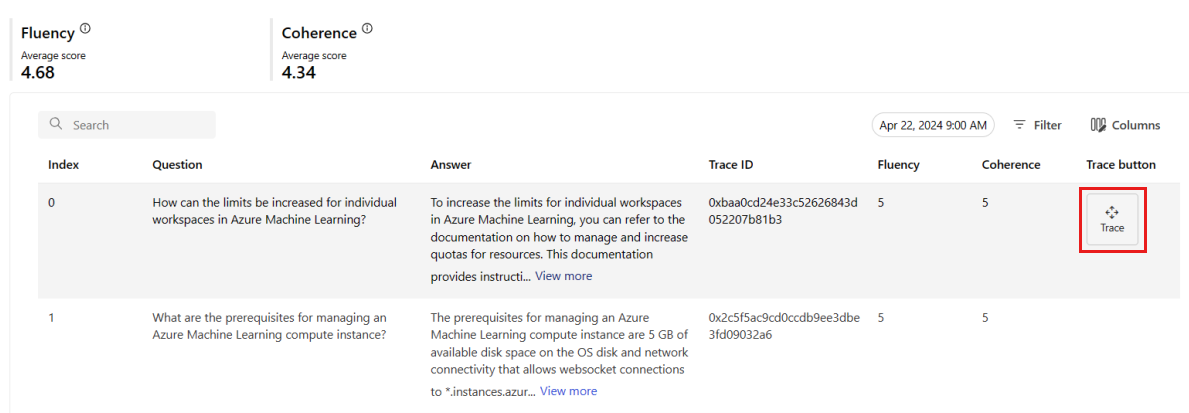
Чтобы просмотреть сведения о трассировке запроса, в правой части строки выберите "Трассировка". Это представление предоставляет подробные сведения о трассировке запроса к вашему приложению.
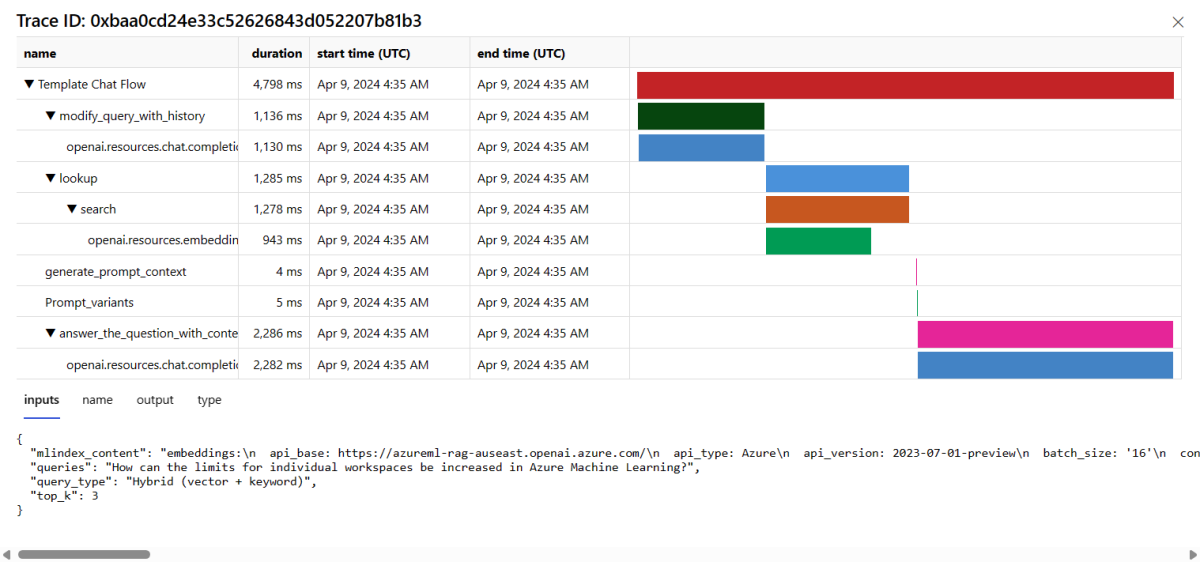
Закройте представление трассировки.
Чтобы просмотреть операционные метрики для развертывания в режиме реального времени, перейдите на вкладку "Операционная". Это представление поддерживает следующие операционные метрики:
- Количество запросов
- Задержки
- Частота ошибок
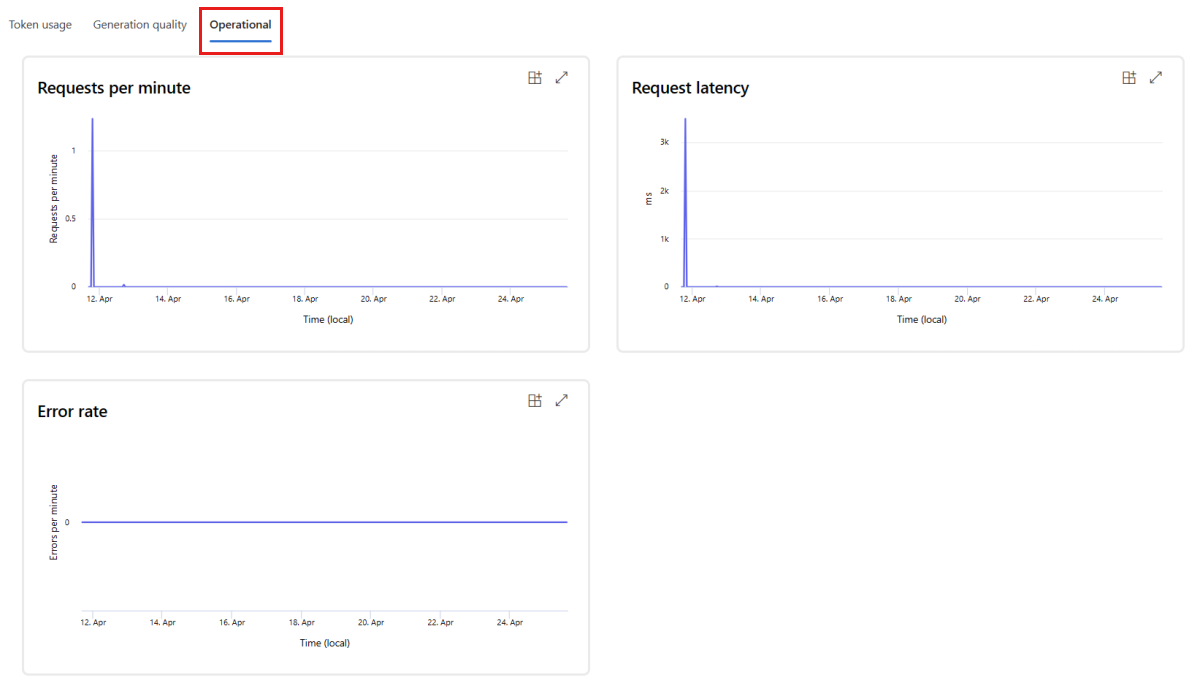





Результаты на вкладке Monitoring (предварительная версия) развертывания предоставляют аналитические сведения, помогающие заранее повысить производительность программного приложения для управления потоками команд.
Расширенная конфигурация мониторинга с помощью пакета SDK версии 2
Мониторинг поддерживает расширенные параметры конфигурации с помощью пакета SDK версии 2. Поддерживаются следующие сценарии.
Включение мониторинга использования токенов
Чтобы включить только мониторинг использования токенов для вашего развернутого приложения prompt flow, адаптируйте следующий сценарий к вашим требованиям.
from azure.ai.ml import MLClient
from azure.ai.ml.entities import (
MonitorSchedule,
CronTrigger,
MonitorDefinition,
ServerlessSparkCompute,
MonitoringTarget,
AlertNotification,
GenerationTokenStatisticsSignal,
)
from azure.ai.ml.entities._inputs_outputs import Input
from azure.ai.ml.constants import MonitorTargetTasks, MonitorDatasetContext
# Authentication package
from azure.identity import DefaultAzureCredential
credential = DefaultAzureCredential()
# Update your Azure resources details
subscription_id = "INSERT YOUR SUBSCRIPTION ID"
resource_group = "INSERT YOUR RESOURCE GROUP NAME"
project_name = "INSERT YOUR PROJECT NAME" # This is the same as your Foundry project name
endpoint_name = "INSERT YOUR ENDPOINT NAME" # This is your deployment name without the suffix (e.g., deployment is "contoso-chatbot-1", endpoint is "contoso-chatbot")
deployment_name = "INSERT YOUR DEPLOYMENT NAME"
# These variables can be renamed but it is not necessary
monitor_name ="gen_ai_monitor_tokens"
defaulttokenstatisticssignalname ="token-usage-signal"
# Determine the frequency to run the monitor, and the emails to receive email alerts
trigger_schedule = CronTrigger(expression="15 10 * * *")
notification_emails_list = ["test@example.com", "def@example.com"]
ml_client = MLClient(
credential=credential,
subscription_id=subscription_id,
resource_group_name=resource_group,
workspace_name=project_name,
)
spark_compute = ServerlessSparkCompute(instance_type="standard_e4s_v3", runtime_version="3.3")
monitoring_target = MonitoringTarget(
ml_task=MonitorTargetTasks.QUESTION_ANSWERING,
endpoint_deployment_id=f"azureml:{endpoint_name}:{deployment_name}",
)
# Create an instance of a token statistic signal
token_statistic_signal = GenerationTokenStatisticsSignal()
monitoring_signals = {
defaulttokenstatisticssignalname: token_statistic_signal,
}
monitor_settings = MonitorDefinition(
compute=spark_compute,
monitoring_target=monitoring_target,
monitoring_signals = monitoring_signals,
alert_notification=AlertNotification(emails=notification_emails_list),
)
model_monitor = MonitorSchedule(
name = monitor_name,
trigger=trigger_schedule,
create_monitor=monitor_settings
)
ml_client.schedules.begin_create_or_update(model_monitor)
Включение мониторинга качества генерации
Чтобы включить мониторинг качества генерации только для развернутого приложения потока запросов, адаптируйте приведенный ниже скрипт под вашу ситуацию.
from azure.ai.ml import MLClient
from azure.ai.ml.entities import (
MonitorSchedule,
CronTrigger,
MonitorDefinition,
ServerlessSparkCompute,
MonitoringTarget,
AlertNotification,
GenerationSafetyQualityMonitoringMetricThreshold,
GenerationSafetyQualitySignal,
BaselineDataRange,
LlmData,
)
from azure.ai.ml.entities._inputs_outputs import Input
from azure.ai.ml.constants import MonitorTargetTasks, MonitorDatasetContext
# Authentication package
from azure.identity import DefaultAzureCredential
credential = DefaultAzureCredential()
# Update your Azure resources details
subscription_id = "INSERT YOUR SUBSCRIPTION ID"
resource_group = "INSERT YOUR RESOURCE GROUP NAME"
project_name = "INSERT YOUR PROJECT NAME" # This is the same as your Foundry project name
endpoint_name = "INSERT YOUR ENDPOINT NAME" # This is your deployment name without the suffix (e.g., deployment is "contoso-chatbot-1", endpoint is "contoso-chatbot")
deployment_name = "INSERT YOUR DEPLOYMENT NAME"
aoai_deployment_name ="INSERT YOUR AOAI DEPLOYMENT NAME"
aoai_connection_name = "INSERT YOUR AOAI CONNECTION NAME"
# These variables can be renamed but it is not necessary
app_trace_name = "app_traces"
app_trace_Version = "1"
monitor_name ="gen_ai_monitor_generation_quality"
defaultgsqsignalname ="gsq-signal"
# Determine the frequency to run the monitor and the emails to receive email alerts
trigger_schedule = CronTrigger(expression="15 10 * * *")
notification_emails_list = ["test@example.com", "def@example.com"]
ml_client = MLClient(
credential=credential,
subscription_id=subscription_id,
resource_group_name=resource_group,
workspace_name=project_name,
)
spark_compute = ServerlessSparkCompute(instance_type="standard_e4s_v3", runtime_version="3.3")
monitoring_target = MonitoringTarget(
ml_task=MonitorTargetTasks.QUESTION_ANSWERING,
endpoint_deployment_id=f"azureml:{endpoint_name}:{deployment_name}",
)
# Set thresholds for the passing rate (0.7 = 70%)
aggregated_groundedness_pass_rate = 0.7
aggregated_relevance_pass_rate = 0.7
aggregated_coherence_pass_rate = 0.7
aggregated_fluency_pass_rate = 0.7
# Create an instance of a gsq signal
generation_quality_thresholds = GenerationSafetyQualityMonitoringMetricThreshold(
groundedness = {"aggregated_groundedness_pass_rate": aggregated_groundedness_pass_rate},
relevance={"aggregated_relevance_pass_rate": aggregated_relevance_pass_rate},
coherence={"aggregated_coherence_pass_rate": aggregated_coherence_pass_rate},
fluency={"aggregated_fluency_pass_rate": aggregated_fluency_pass_rate},
)
input_data = Input(
type="uri_folder",
path=f"{endpoint_name}-{deployment_name}-{app_trace_name}:{app_trace_Version}",
)
data_window = BaselineDataRange(lookback_window_size="P7D", lookback_window_offset="P0D")
production_data = LlmData(
data_column_names={"prompt_column": "question", "completion_column": "answer", "context_column": "context"},
input_data=input_data,
data_window=data_window,
)
gsq_signal = GenerationSafetyQualitySignal(
connection_id=f"/subscriptions/{subscription_id}/resourceGroups/{resource_group}/providers/Microsoft.MachineLearningServices/workspaces/{project_name}/connections/{aoai_connection_name}",
metric_thresholds=generation_quality_thresholds,
production_data=[production_data],
sampling_rate=1.0,
properties={
"aoai_deployment_name": aoai_deployment_name,
"enable_action_analyzer": "false",
"azureml.modelmonitor.gsq_thresholds": '[{"metricName":"average_fluency","threshold":{"value":4}},{"metricName":"average_coherence","threshold":{"value":4}}]',
},
)
monitoring_signals = {
defaultgsqsignalname: gsq_signal,
}
monitor_settings = MonitorDefinition(
compute=spark_compute,
monitoring_target=monitoring_target,
monitoring_signals = monitoring_signals,
alert_notification=AlertNotification(emails=notification_emails_list),
)
model_monitor = MonitorSchedule(
name = monitor_name,
trigger=trigger_schedule,
create_monitor=monitor_settings
)
ml_client.schedules.begin_create_or_update(model_monitor)
После создания монитора из пакета SDK можно использовать результаты мониторинга на портале Foundry.
Связанное содержимое
- Узнайте больше о том, что можно сделать в Foundry.
- Получите ответы на часто задаваемые вопросы в Foundry FAQ.