Примечание.
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
Применяется только к:![]() Портал Foundry (классический). Эта статья недоступна для нового портала Foundry.
Дополнительные сведения о новом портале.
Портал Foundry (классический). Эта статья недоступна для нового портала Foundry.
Дополнительные сведения о новом портале.
Примечание
Содержание в новой документации Microsoft Foundry может открываться по ссылкам в этой статье вместо документации Foundry (классической версии), которую вы просматриваете сейчас.
Предупреждение
Разработка функций потока запросов закончилась 20 апреля 2026 г. Функция будет полностью прекращена 20 апреля 2027 г. В дату выхода на пенсию, Prompt Flow переходит в режим только для чтения. Существующие потоки будут продолжать работать до этой даты.
Рекомендуемое действие: Перенесите рабочие нагрузки Prompt Flow на Microsoft Agent Framework до 20 апреля 2027 г.
Инструмент Prompt Flow — это средство разработки, предназначенное для упрощения всего цикла разработки приложений искусственного интеллекта на основе больших языковых моделей (БЯМ). Поток запросов предоставляет комплексное решение, упрощающее процесс создания прототипов, экспериментирования, итерации и развертывания приложений ИИ.
С помощью потока подсказок вы можете:
- Оркестрация исполняемых потоков с помощью LLM-моделей, подсказок и инструментов Python с помощью визуализированного графа.
- Тестируйте, отлаживайте и итерационно развивайте свои потоки легко.
- Создайте варианты запроса и сравните их производительность.
В этой статье вы узнаете, как создать и разработать первый поток запроса на портале Microsoft Foundry.
Необходимые условия
Важно
Эта статья предоставляет устаревшую поддержку для проектов на основе концентраторов. Он не будет работать для проектов Foundry. Узнайте , какой у меня тип проекта?
примечание о совместимости SDK. Для примеров кода требуется определенная версия пакета SDK для Foundry Microsoft. При возникновении проблем совместимости рассмотрите возможность миграции из концентратора в проект Foundry.
- Учетная запись Azure с активной подпиской. Если у вас нет, создайте учетную запись free Azure, которая включает бесплатную пробную подписку.
- Если у вас нет одного, создайте проект на основе концентратора.
- Поток запросов требует сеанса вычислений. Если у вас нет среды выполнения, ее можно создать на портале Foundry.
- Вам нужна развернутая модель.
- В проекте настройте управление доступом для учетной записи хранилища блобов. Назначьте роль участник данных хранилища BLOB-объектов учетной записи пользователя.
- В нижней левой части портала Foundry выберите центр управления.
- В Соединяемые ресурсы для центра выберите ссылку, соответствующую типу Хранилище BLOB-объектов Azure.
- Выберите Просмотреть в портале Azure
- На портале Azure выберите Управление доступом (IAM).
- Выберите Добавить>Добавить назначение роли.
- Найдите Storage Blob Data Contributor, а затем выберите его.
- Используйте страницу добавления назначения ролей , чтобы добавить себя в качестве члена.
- Выберите "Рецензирование и назначение", чтобы ознакомиться с назначением.
- Нажмите кнопку "Проверить и назначить" для назначения роли.
Разработка и создание потока Prompt
Вы можете создать поток, клонируя примеры, доступные в коллекции, или создав поток с нуля. Если у вас уже есть файлы потока в локальной или общей папке, можно также импортировать файлы для создания потока.
Чтобы создать поток подсказки из галереи на портале Foundry, выполните следующие действия.
Совет
Так как вы можете настроить левую панель на портале Microsoft Foundry, вы можете увидеть элементы, которые могут отличаться от тех, что показаны в этих шагах. Если вы не видите, что вы ищете, выберите ... Подробнее в нижней части левой панели.
Войдите в Microsoft Foundry. Убедитесь, что переключатель New Foundry отключен. Эти шаги относятся к Foundry (classic).

Выберите проект.
Если вы находитесь в центре управления, выберите "Перейти к проекту ", чтобы вернуться к проекту.
В левой раскрывающейся панели выберите Prompt flow.
Нажмите кнопку +Создать.
На плитке Стандартный поток выберите Создать.
На странице "Создание нового потока " введите имя папки и нажмите кнопку "Создать".
Откроется страница разработки потока запроса. Выберите "Пуск вычислительного сеанса ", чтобы запустить вычислительный сеанс для потока.
Теперь вы можете начать создание вашего потока. По умолчанию отображается пример потока. В этом примере потока есть узлы для средств LLM и Python.
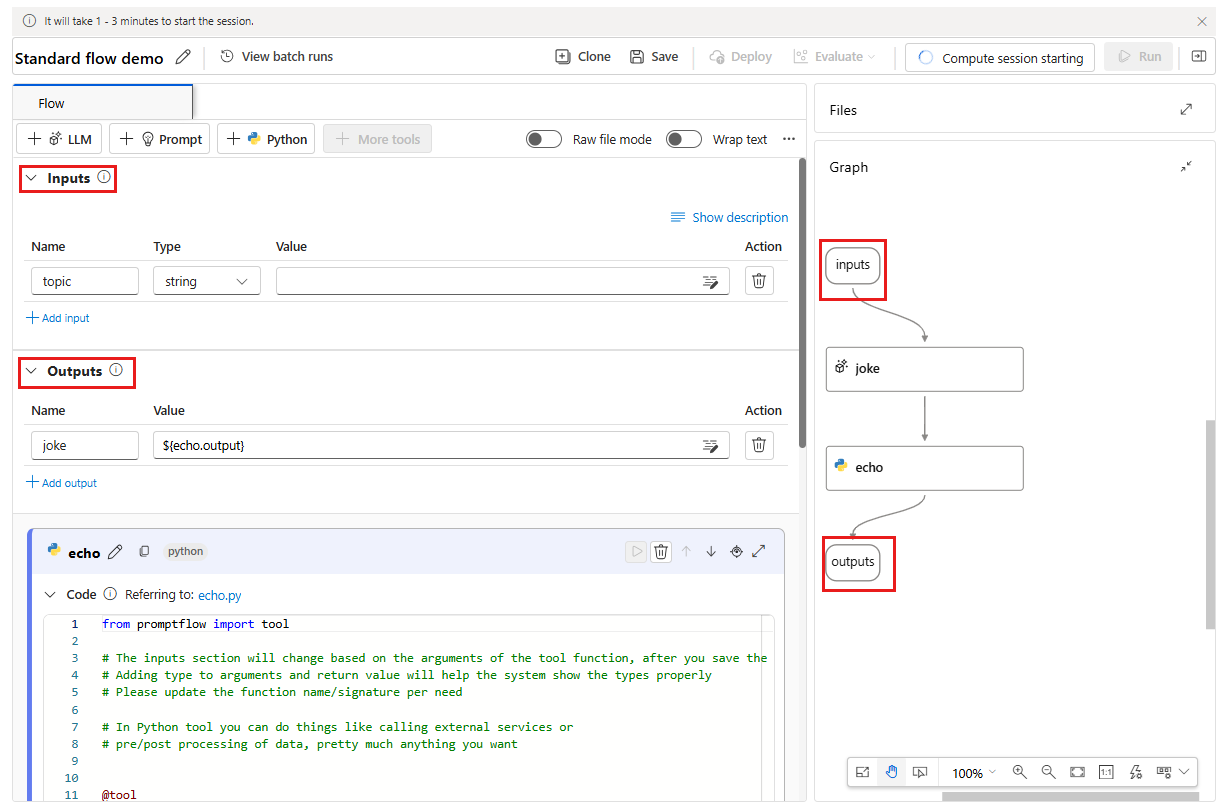
Примечание
Представление графа только для визуализации. В нем показана структура потока, которую вы разрабатываете. Вы не можете напрямую редактировать представление графа, но вы можете увеличить масштаб, уменьшить и прокрутить. Вы можете выбрать узел в представлении графа, чтобы выделить и перейти к узлу в режиме редактирования средства.
При желании в поток можно добавить дополнительные инструменты. Видимые параметры инструментов: LLM, Prompt и Python. Чтобы просмотреть дополнительные инструменты, нажмите кнопку +Другие инструменты.

Выберите подключение и развертывание в редакторе инструментов LLM.
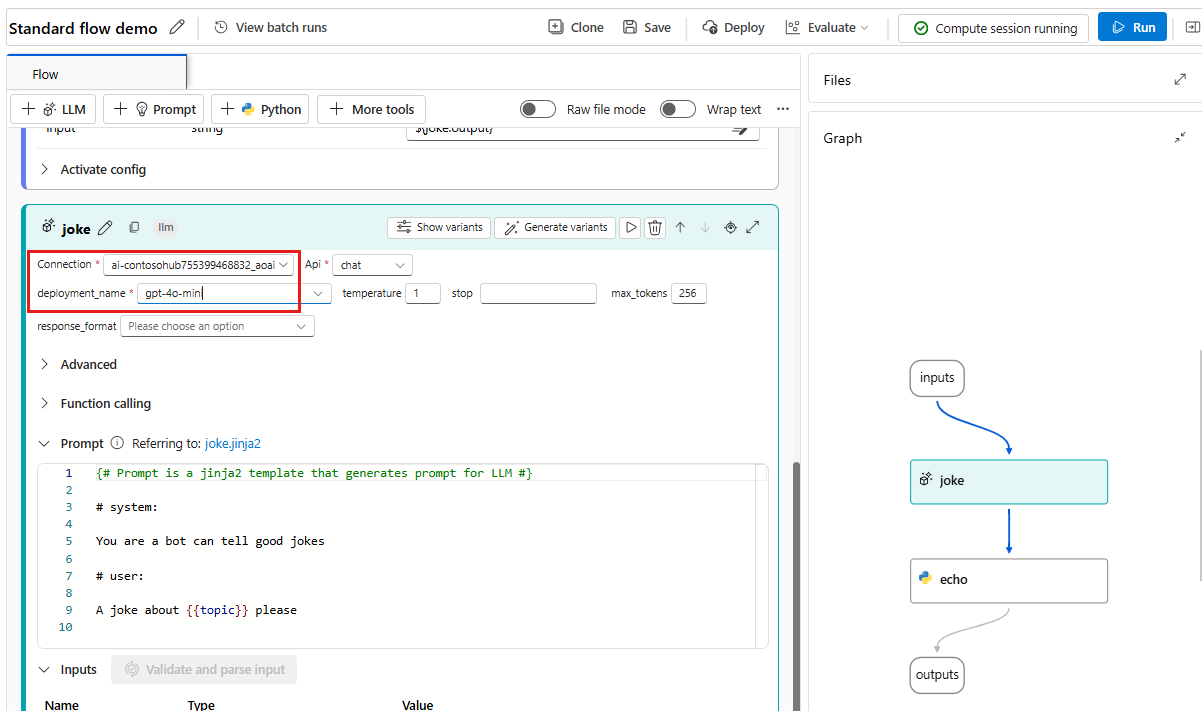
В разделе "Входные данные" добавьте значение для темы. Например, "атомы".
Выберите "Выполнить" , чтобы запустить поток.

Состояние выполнения потока показано как Запуск.
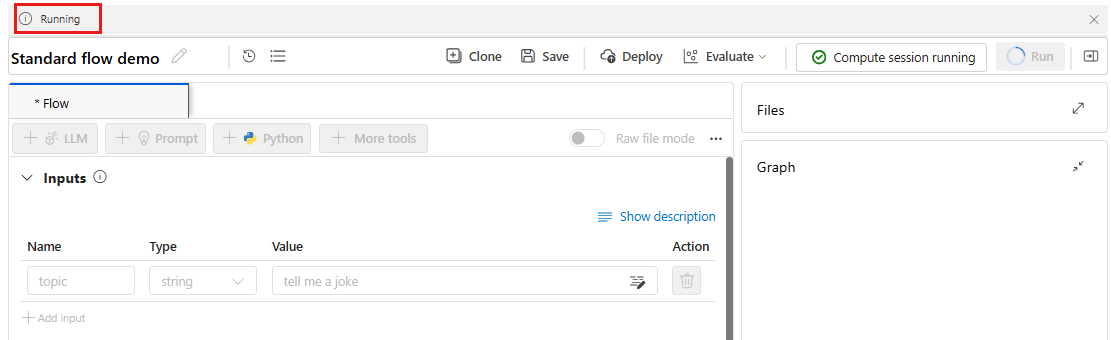
После завершения выполнения потока выберите "Просмотреть выходные данные ", чтобы просмотреть результаты потока.

Состояние выполнения потока и выходные данные можно просмотреть в разделе "Выходные данные ".
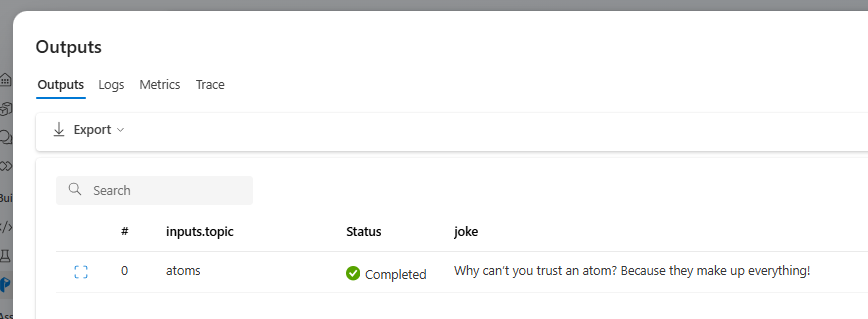








Создание потока
Каждый поток представлен папкой, содержащей файл flow.dag.yaml', файлы исходного кода и системные папки. Вы можете добавлять новые файлы, изменять существующие файлы и удалять файлы. Вы также можете экспортировать файлы в локальное хранилище или импортировать файлы из него.
Помимо встроенного редактирования узла в представлении по умолчанию, вы также можете включить переключатель режима необработанного файла и выбрать имя файла, чтобы изменить файл на вкладке открытия файла.
Входные и выходные данные потока
Входные данные потока — это данные, передаваемые в поток в целом. Определите входную схему, указав имя и тип. Установите значение каждого входного параметра для проверки процесса. Вы можете ссылаться на входные данные потока позже в узлах потока с помощью ${inputs.[input name]} синтаксиса.
Выходные данные потока — это данные, созданные потоком в целом, которые суммируют результаты выполнения потока. Вы можете просматривать и экспортировать выходную таблицу после завершения выполнения потока или пакетного выполнения. Определите выходное значение потока, ссылаясь на выходные данные одного узла потока с помощью синтаксиса ${[node name].output} или ${[node name].output.[field name]}.
Связывайте узлы
Ссылаясь на выходные данные узла, можно связать узлы вместе. Например, можно ссылаться на выходные данные узла LLM в входных данных Python узла, поэтому узел Python может использовать выходные данные узла LLM, а в представлении графа можно увидеть, что два узла связаны друг с другом.
Включение условного управления потоком
Поток запросов предлагает не только упрощенный способ выполнения потока, но и обеспечивает мощный компонент для разработчиков — условный контроль, который позволяет пользователям задавать условия для выполнения любого узла в потоке.
В основе условного управления лежит возможность связывания каждого узла в потоке с активацией конфигурации
В частности, можно задать конфигурацию активации для узла, нажав кнопку "Активировать конфигурацию " на карточке узла. Вы можете добавить оператор "when" и задать условие.
Вы можете задать условия, ссылаясь на входные данные потока или выходные данные узла. Например, можно задать условие ${inputs.[input name]} в качестве определенного значения или ${[node name].output} в качестве конкретного значения.
Если условие не выполнено, узел пропускается. Состояние узла отображается как "Обход".
Тестирование потока
Вы можете протестировать поток двумя способами:
Запустите один узел:
- Чтобы запустить один узел, выберите значок запуска на узле в представлении по умолчанию. После завершения выполнения можно быстро проверить результат в разделе выходных данных узла.
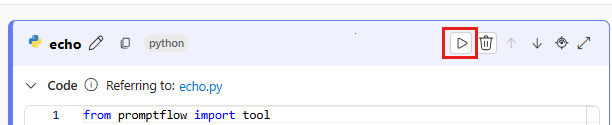
- Чтобы запустить один узел, выберите значок запуска на узле в представлении по умолчанию. После завершения выполнения можно быстро проверить результат в разделе выходных данных узла.
Запустите весь поток:
- Чтобы запустить весь поток, нажмите кнопку "Выполнить " в правом верхнем углу.
Просмотр результатов теста и трассировки (предварительная версия)
Трассировка отключена по умолчанию. Чтобы включить трассировку, вам нужно задать переменную среды PF_DISABLE_TRACING значением false. Одним из способов этого является добавление следующего элемента в узел Python:
import os
os.environ["PF_DISABLE_TRACING"] = "false"
В течение всего процесса выполнения потока, после его запуска, можно увидеть статус выполнения в баннере запуска. Чтобы просмотреть трассировку для проверки результата и наблюдения за выполнением потока, можно выбрать "Просмотреть выходные данные " и выбрать вкладку трассировки . Вы можете просмотреть входные и выходные данные всего потока и каждого узла, а также более подробные сведения об отладке. Функционал доступен во время выполнения и после его завершения.
Понимание представления трассировки
Выберите вкладку «Трассировка» на экране «Выходные данные», чтобы увидеть график, предоставляющий информацию о длительности и связанных затратах на токены потока. Выберите поток под именем узла, чтобы просмотреть подробные сведения о потоке в правой области.

Примечание
В SDK Prompt Flow мы определили несколько типов спанов, включая LLM, Function, Embedding, Retrieval и Flow. Система автоматически создает диапазоны с информацией о выполнении в указанных атрибутах и событиях.
Дополнительные сведения о типах диапазонов см. в разделе "Диапазон трассировки".
Разработка потока чата
Поток чата предназначен для разработки беседных приложений, опираясь на возможности стандартного потока и обеспечивая расширенную поддержку входных и выходных данных чата и управления журналом чата. С помощью потока чата можно легко создать чат-бот, который обрабатывает входные и выходные данные чата.
На странице разработки потока чата поток чата помечен меткой "чат", чтобы отличить его от стандартного потока и потока оценки. Чтобы проверить поток чата, нажмите кнопку "Чат", чтобы активировать поле чата для беседы.
История ввода и вывода сообщений чата
Наиболее важными элементами, которые отличают поток чата от стандартного потока, являются входные данные чата, журнал чата и выходные данные чата.
- Входные данные чата: входные данные чата ссылаются на сообщения или запросы, отправленные пользователями в чат-бот. Эффективная обработка входных данных чата имеет решающее значение для успешной беседы, так как она включает понимание намерений пользователей, извлечение соответствующей информации и активацию соответствующих ответов.
- Журнал чата: журнал чата — это запись всех взаимодействий между пользователем и чат-ботом, включая входные данные пользователя и созданные ИИ выходные данные. Ведение журнала чата является важным для отслеживания контекста беседы и обеспечения ИИ может создавать контекстно релевантные ответы.
- Выходные данные чата: выходные данные чата ссылаются на созданные ИИ сообщения, отправляемые пользователю в ответ на их входные данные. Создание контекстно подходящих и привлекательных выходных данных чата жизненно важно для положительного взаимодействия с пользователем.
Поток чата может содержать несколько входных данных, при этом журнал чата и входные данные чата необходимы в потоке чата.
В разделе входных параметров входные данные потока чата можно пометить как входные данные чата. Затем вы можете заполнить входное значение чата, введя в поле чата.
Поток запросов может помочь пользователю управлять журналом чата. В разделе
chat_history"Входные данные" предназначен для отображения журнала чата. Все взаимодействия в поле чата, включая входные данные чата пользователя, созданные выходные данные чата, а также другие входные и выходные данные потока, автоматически хранятся в журнале чата. Пользователь не может вручную задать значениеchat_historyв разделе "Входные данные". Он структурирован как список входных и выходных данных:[ { "inputs": { "<flow input 1>": "xxxxxxxxxxxxxxx", "<flow input 2>": "xxxxxxxxxxxxxxx", "<flow input N>""xxxxxxxxxxxxxxx" }, "outputs": { "<flow output 1>": "xxxxxxxxxxxx", "<flow output 2>": "xxxxxxxxxxxxx", "<flow output M>": "xxxxxxxxxxxxx" } }, { "inputs": { "<flow input 1>": "xxxxxxxxxxxxxxx", "<flow input 2>": "xxxxxxxxxxxxxxx", "<flow input N>""xxxxxxxxxxxxxxx" }, "outputs": { "<flow output 1>": "xxxxxxxxxxxx", "<flow output 2>": "xxxxxxxxxxxxx", "<flow output M>": "xxxxxxxxxxxxx" } } ]
Примечание
Возможность автоматического сохранения или управления журналом чата — это функция на странице разработки при проведении тестов в поле чата. Для пакетных запусков пользователям необходимо включить журнал чата в набор данных пакетного запуска. Если журнал чата недоступен для тестирования, задайте для chat_history пустой список [] в наборе данных пакетного запуска.
Подсказка автору с историей чата
Включение журнала чата в запросы является важным для создания контекстно-зависимого и привлекательного ответа чат-бота. В своих запросах вы можете ссылаться на chat_history, чтобы получить прошлые взаимодействия. Это позволяет ссылаться на предыдущие входные и выходные данные для создания контекстно релевантных ответов.
Используйте грамматику for-цикла языка Jinja для отображения списка входных и выходных данных из chat_history.
{% for item in chat_history %}
user:
{{item.inputs.question}}
assistant:
{{item.outputs.answer}}
{% endfor %}
Тестирование с помощью поля чата
Поле чата предоставляет интерактивный способ тестирования потока чата путем имитации беседы с чат-ботом. Чтобы протестировать поток чата с помощью поля чата, выполните следующие действия.
- Нажмите кнопку "Чат", чтобы открыть поле чата.
- Введите входные данные теста в поле чата и нажмите клавишу ВВОД, чтобы отправить их в чат-бот.
- Просмотрите ответы чат-бота, чтобы убедиться, что они контекстно подходят и точны.
- Просмотрите трассировку на месте для быстрого наблюдения и отладки.