Примечание.
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
Рабочий процесс оркестрации, предлагаемый Azure Language в средствах Foundry, позволяет интегрировать несколько языковых моделей, таких как понимание разговорного языка (CLU) и настройка ответов на вопросы (CQA), в один проект. Эта функция интеллектуально направляет запросы пользователей в наиболее подходящую модель через единую конечную точку, обеспечивая простой и сложный диалоговый интерфейс в различных задачах языковых служб.
В этом кратком руководстве описаны основные принципы работы с проектами рабочих процессов оркестрации. Выполнение каждого шага способствует созданию надежного фундамента для понимания ключевых концепций. Завершение этого руководства по быстрому началу дает вам практический опыт, подготавливая вас к уверенной работе над проектами рабочих процессов оркестрации в вашей среде.
Предварительные условия
Примечание.
- Если у вас уже есть язык Azure в средствах Foundry или ресурс с несколькими службами, вы можете продолжать использовать эти существующие языковые ресурсы на портале Microsoft Foundry через проект Foundry Hub.
- Дополнительные сведения см. в статье "Использование средств Foundry" на портале Foundry
- Настоятельно рекомендуется использовать ресурс Foundry в Foundry. Однако, эти инструкции также можно выполнить, используя ресурс Language.
- Подписка Azure. Если у вас нет учетной записи, вы можете создать ее бесплатно.
- Необходимые разрешения. Убедитесь, что пользователь, устанавливающий учетную запись и проект, назначен в качестве роли владельца учетной записи ИИ Azure на уровне подписки. Кроме того, роль Участника или Участника Cognitive Services в области подписки также соответствует этому требованию. Дополнительные сведения см. в разделе"Управление доступом на основе ролей" (RBAC).
- Ресурс Foundry (рекомендуется). Дополнительные сведения см. в разделе"Настройка ресурса Foundry". Кроме того, можно использовать ресурс языка.
- Проект Foundry, созданный в Foundry. Дополнительные сведения см. в разделе"Создание проекта Foundry".
- Проект "Понимание разговорного языка" (CQA) или проект настраиваемого ответа на вопросы (CQA), созданный в Фаундри.
Перенос существующего рабочего процесса оркестрации из Language Studio
Если у вас есть существующий рабочий процесс оркестрации в Language Studio, который вы хотите использовать в Foundry, у вас есть два варианта миграции:
Вариант 1. Подключение ресурса языка к Центру Foundry (рекомендуется)
Подключите существующий ресурс языка к проекту Foundry Hub. Этот подход автоматически сохраняет все связи задач между рабочим процессом оркестрации и связанными задачами CLU и CQA.
Вариант 2. Импорт проектов в новый ресурс Foundry
Если вы хотите использовать новый ресурс Foundry, импортируйте проекты по отдельности. Чтобы сохранить компоновки задач, импортируйте в следующем порядке:
- Сначала импортируйте задачи CLU и CQA.
- Импортируйте рабочий процесс оркестрации только после того, как зависимые задачи доступны в ресурсе Foundry.
Это важно
Порядок импорта имеет значение. Если вы импортируете рабочий процесс оркестрации перед зависимыми задачами CLU и CQA, связи задач не сохраняются. Затем необходимо вручную повторно связать задачи в разделе "Настройка оркестрации ".
Подробные инструкции по миграции см. в статье "Миграция из Language Studio в Microsoft Foundry".
Начало работы
После создания ресурса Foundry можно инициировать проект рабочего процесса оркестрации в Microsoft Foundry. Этот проект служит выделенной рабочей областью для разработки пользовательских моделей машинного обучения с помощью данных. Доступ к проекту ограничен вами и другими пользователями, имеющими разрешения на связанный ресурс Foundry.
Для этого краткого руководства вы можете выполнить краткое руководство по пониманию разговорного языка или настраиваемый вопросно-ответный модуль (CQA), чтобы создать проект для использования в последующих шагах быстрого запуска рабочего процесса оркестрации.
Начнем:
Перейдите к Литейному цеху.
Если вы еще не вошли, на портале появится запрос на использование учетных данных Azure.
После входа вы можете создать или получить доступ к существующим проектам в Foundry.
Если вы еще не находитесь в вашем
CLUилиCQAпроекте, выберите его сейчас.
Создание проекта для рабочего процесса оркестрации
Выберите "Точная настройка" в левой панели навигации.
В появившемся окне выберите вкладку тонкой настройки сервиса ИИ, затем нажмите кнопку + Тонкая настройка.

В появившемся окне выберите рабочий процесс оркестрации бесед в качестве типа задачи, а затем нажмите кнопку "Далее".
Если у вас нет задачи CLU или CQA подстройки в этом ресурсе Foundry, появится предупреждение, указывающее, что никакие задачи не доступны для подключения.

Сначала создайте задачу "Понимание разговорного языка" или "Пользовательское вопросно-ответное решение", а затем вернитесь к созданию процесса оркестрации.
В окне "Создание сервиса настройки" можно создать новую задачу или импортировать существующую. Заполните все обязательные поля и нажмите кнопку "Создать".
- Имя. Укажите уникальное имя для проекта рабочего процесса оркестрации.
- Язык: выберите язык для проекта.
- Описание. При необходимости укажите описание проекта.
После создания проекта рабочего процесса оркестрации вы будете перенаправлены на страницу обзора проекта. Здесь вы можете управлять параметрами проекта, отслеживать ход обучения и получать доступ к различным средствам для улучшения модели.
Настройка оркестрации
Подключите существующие задачи понимания разговорного языка (CLU) и настраиваемого ответа на вопросы (CQA), чтобы создать единый слой оркестрации, который направляет ввод пользователя в соответствующую модель. Вы можете определить больше намерений маршрутизации, если входные данные пользователей неоднозначны и требуют дополнительной логики для определения правильной задачи.
Примечание.
Если страница настройки оркестрации пуста, в этом ресурсе Foundry нет задач по настройке CLU или CQA. Сначала создайте задачу Понимание языка в контексте беседы или Настраиваемый вопрос-ответ, а затем вернитесь на эту страницу и свяжите ее.
Чтобы добавить существующие
CLUилиCQAмодели в рабочий процесс оркестрации, перейдите к проекту тонкой настройки и выберите раздел "Настройка оркестрации " в меню "Начало работы ". Там можно связать задачи тонкой настройки и добавить интенты из существующих моделей в процесс оркестрации.
Свяжите задачи, выбрав радиокнопку рядом с задачей, которую вы хотите связать, а затем выберите задачу тонкой настройки на верхней панели навигации. Поле "Имя намерения оркестрации " автоматически заполняется таким же именем, что и поле "Имя задачи точной настройки ".
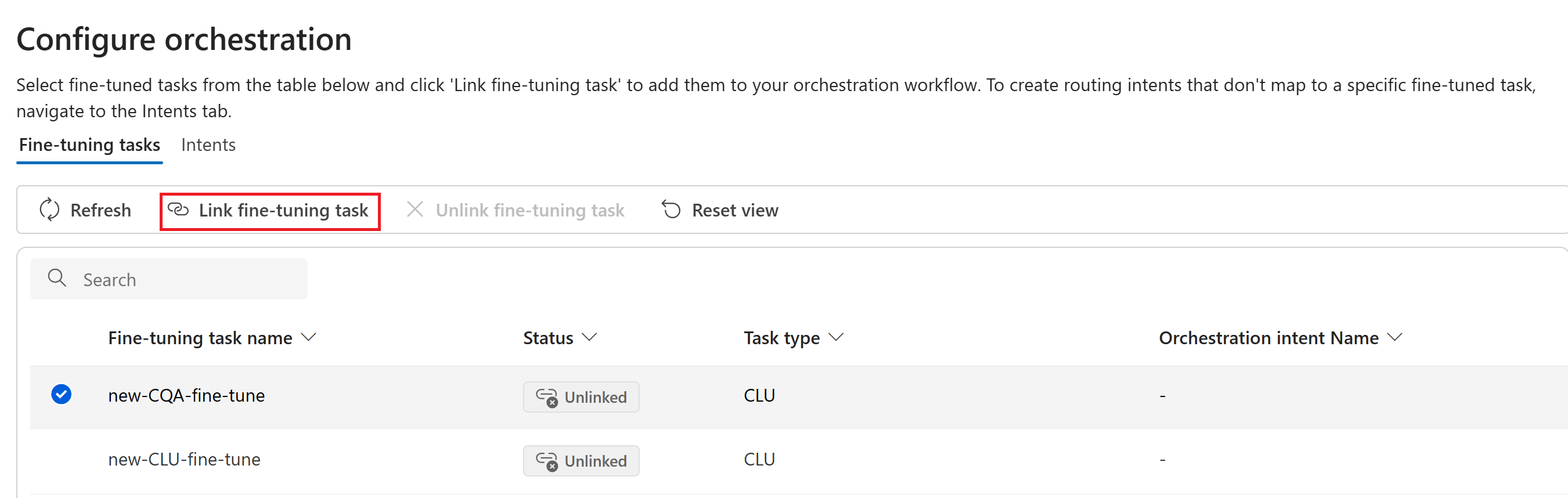
После завершения этого шага состояние ваших задач изменится с Не связаны на Связаны в разделе Настройка оркестрации.
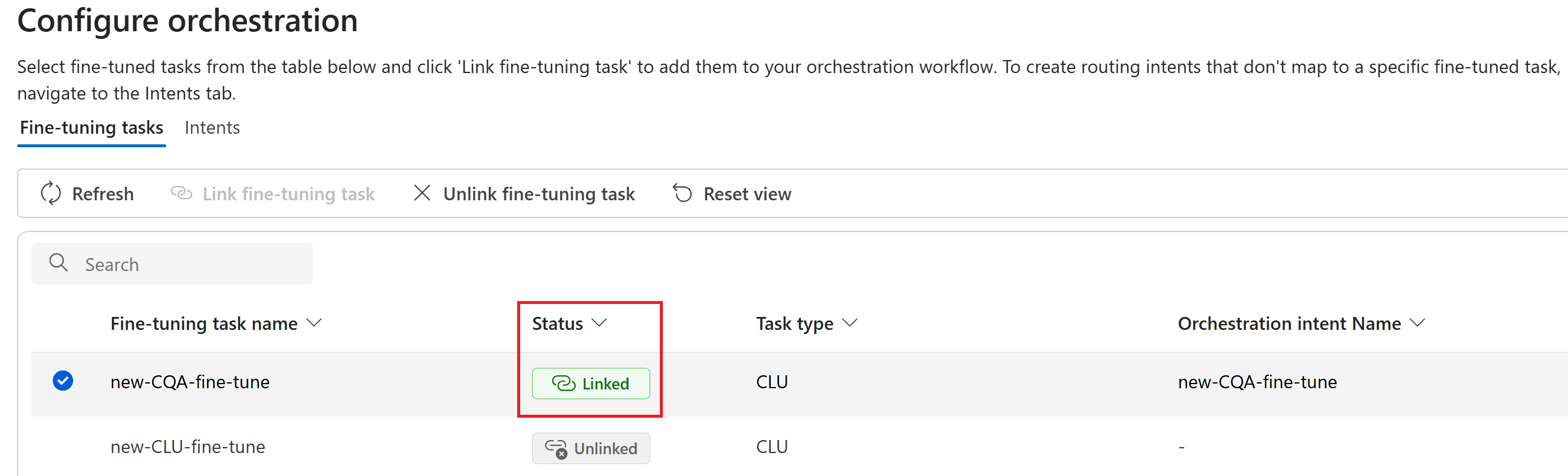
Чтобы связать несколько задач точной настройки одновременно, выберите одну или несколько несвязанных задач, а затем выберите команду "Связать задачу точной настройки " на верхней панели навигации.
Чтобы разъединить задачи, выберите одну или несколько связанных задач, затем выберите Отменить связь задачи тонкой настройки на верхней панели инструментов.
Чтобы добавить намерения маршрутизации, выберите вкладку "Намерения" на верхней панели навигации. В появившемся окне нажмите кнопку +Добавить намерение, укажите уникальное имя намерения в поле "Имя намерения", а затем нажмите кнопку "Добавить ", чтобы продолжить.





Добавление обучающих данных
Перейдите на вкладку "Управление данными". Для этого проекта используйте один из существующих проектов CLU. Если существующий проект не содержит помеченные речевые фрагменты, можно скачать наш пример файла высказываний, который поставляется предварительно настроенным с помеченными речевыми фрагментами.
Нажмите кнопку "Отправить речевые фрагменты" , чтобы отправить файл речевых фрагментов в формате JSON.
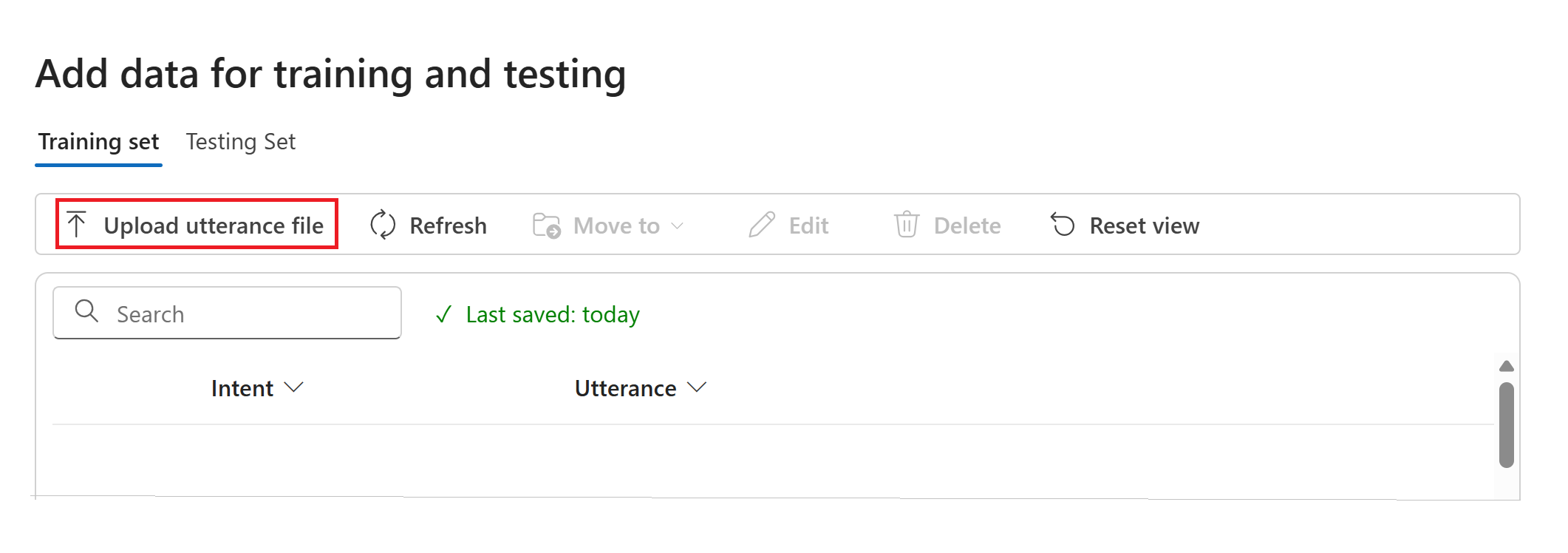
После загрузки вашего файла высказываний выберите несвязанные намерения на панели "Insights". Это действие позволяет сопоставить эти намерения с соответствующими связанными задачами в рабочем процессе оркестрации.

Обучение модели
Перейдите в раздел "Обучение модели" и нажмите кнопку "Обучение модели", чтобы начать обучение процесса оркестрации со связанными задачами и загруженными репликами. Этот процесс может занять некоторое время в зависимости от размера набора данных и сложности модели.

В окне обучения новой модели укажите имя модели, сохраните стандартный режим обучения по умолчанию и нажмите кнопку "Далее ".

В окне разделения данных можно использовать разделение данных по умолчанию или настроить его в соответствии с вашими потребностями. После выбора нажмите кнопку "Далее ", чтобы продолжить.
Просмотрите выбранные элементы в окне сводки, а если все выглядит правильно, выберите "Создать ", чтобы инициировать учебный процесс для модели рабочего процесса оркестрации.

После запуска процесса обучения можно отслеживать ход выполнения и просматривать подробные метрики на панели мониторинга обучения. После завершения обучения модель рабочего процесса оркестрации готова к развертыванию и тестированию.
Разверните вашу модель
Разверните обученную модель, перейдя в раздел "Развернуть модель " и нажав кнопку "Развернуть ". Следуйте инструкциям, чтобы завершить процесс развертывания.

Тестирование модели
После успешного развертывания модели его можно протестировать непосредственно в интерфейсе Foundry. Перейдите к разделу Test in playground, введите различные высказывания и наблюдайте, как оркестрационный процесс маршрутизирует запросы к соответствующим и связанным задачам.
Готово, поздравляем!
Очистка ресурсов
Если проект больше не нужен, его можно удалить из Foundry.
Перейдите на домашнюю страницу Foundry . Начните процесс аутентификации, выполнив вход, если вы еще не завершили этот шаг и ваш сеанс не активен.
Выберите проект, который нужно удалить из раздела Keep building with Foundry
Выберите центр управления.
Выберите "Удалить проект".
Предварительные условия
- Подписка Azure — создайте бесплатную учетную запись.
Создание языкового ресурса на портале Azure
Создание ресурса на портале Azure
Перейдите на портал Azure , чтобы создать новый ресурс Azure Language in Foundry Tools.
Нажмите кнопку "Продолжить", чтобы создать ресурс
Создайте языковой ресурс со следующими деталями.
Сведения об экземпляре Обязательное значение Область/регион Один из поддерживаемых регионов. Имя. Имя языкового ресурса. Ценовая категория Одна из поддерживаемых ценовых категорий.
Получите свои ключи и конечную точку ресурса
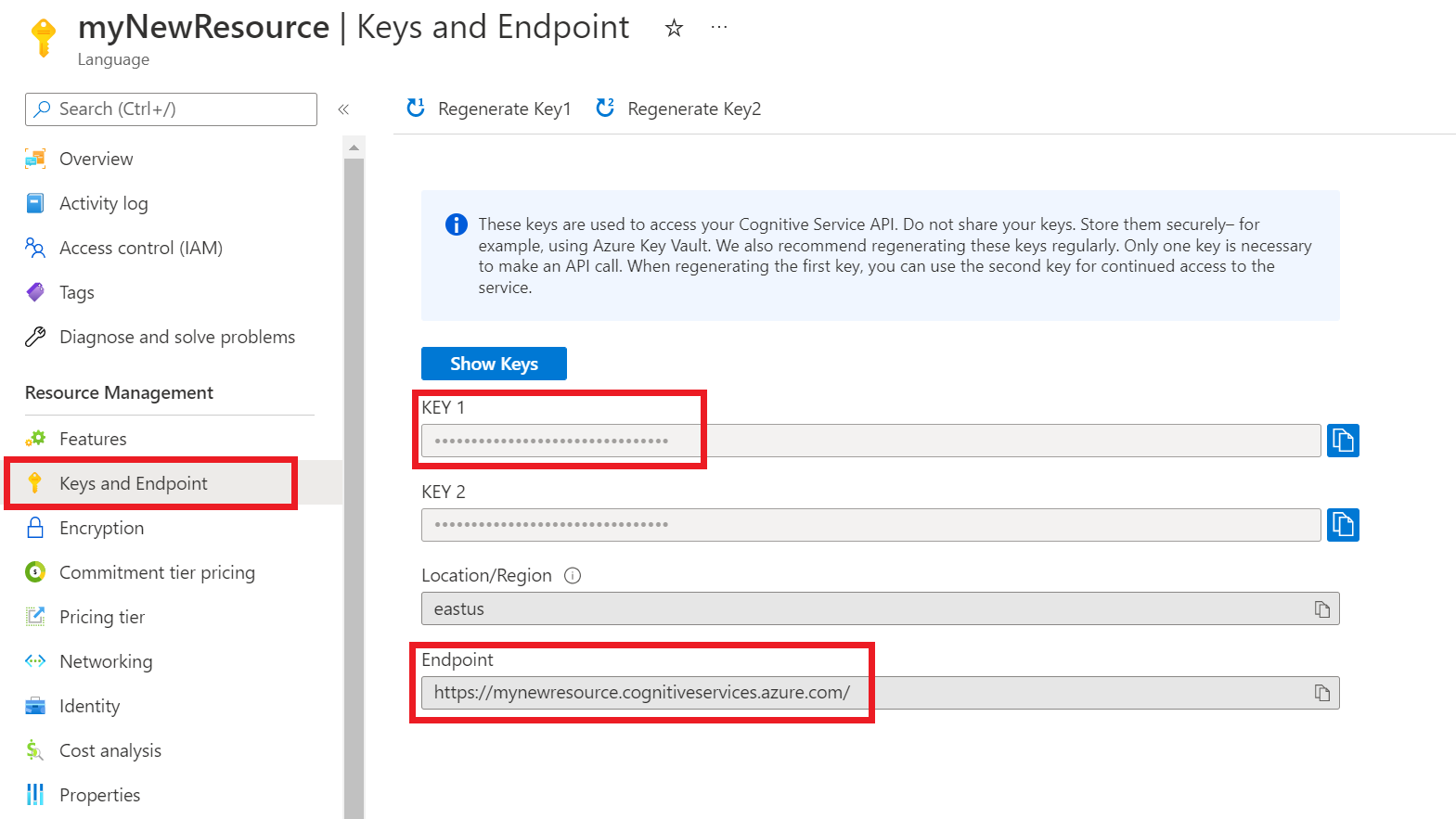
Перейдите на страницу обзора ресурса на портале Azure.
В меню слева выберите Ключи и конечная точка. Конечная точка и ключ используются для запросов API.

Создание проекта для рабочего процесса оркестрации
Создав языковой ресурс, создайте проект рабочего процесса оркестрации. Проект — это рабочая область для создания настраиваемых моделей машинного обучения на основе данных. Доступ к проекту осуществляется только вами и другими пользователями, имеющими доступ к используемому ресурсу языка Azure.
Для этого краткого руководства выполните краткое руководство по CLU, чтобы создать проект CLU для использования в рабочем процессе оркестрации.
Отправьте запрос PATCH, используя следующий URL-адрес, заголовки и текст JSON, чтобы создать проект.
Запросить URL-адрес
При создании запроса API используйте следующий URL-адрес. Замените значения заполнителей собственными значениями.
{ENDPOINT}/language/authoring/analyze-conversations/projects/{PROJECT-NAME}?api-version={API-VERSION}
Заголовки
Используйте следующий заголовок для проверки подлинности запроса.
| Ключ | значение |
|---|---|
Ocp-Apim-Subscription-Key |
Ключ к ресурсу. Используется для проверки подлинности запросов API. |
Тело
Используйте следующий пример JSON в качестве тела.
{
"projectName": "{PROJECT-NAME}",
"language": "{LANGUAGE-CODE}",
"projectKind": "Orchestration",
"description": "Project description"
}
| Ключ | Заполнитель | значение | Пример |
|---|---|---|---|
projectName |
{PROJECT-NAME} |
Имя проекта. Это значение чувствительно к регистру. | EmailApp |
language |
{LANGUAGE-CODE} |
Строка, указывающая код языка для речевых фрагментов, используемых в проекте. Если проект является многоязычным проектом, выберите языковой код для большинства речевых фрагментов. | en-us |
Создание схемы
Следующим шагом после завершения работы с быстрым стартом по CLU и создания проекта оркестрации является добавление намерений.
Отправьте запрос POST, используя указанный ниже URL-адрес, заголовки и текст JSON, чтобы импортировать проект.
Запросить URL-адрес
При создании запроса API используйте следующий URL-адрес. Замените значения заполнителей собственными значениями.
{ENDPOINT}/language/authoring/analyze-conversations/projects/{PROJECT-NAME}/:import?api-version={API-VERSION}
Заголовки
Используйте следующий заголовок для проверки подлинности запроса.
| Ключ | значение |
|---|---|
Ocp-Apim-Subscription-Key |
Ключ к ресурсу. Используется для проверки подлинности запросов API. |
Тело
Примечание.
Каждое намерение должно быть только одного типа (CLU, LUIS и qna)
Используйте следующий пример JSON в качестве тела.
{
"projectFileVersion": "{API-VERSION}",
"stringIndexType": "Utf16CodeUnit",
"metadata": {
"projectKind": "Orchestration",
"settings": {
"confidenceThreshold": 0
},
"projectName": "{PROJECT-NAME}",
"description": "Project description",
"language": "{LANGUAGE-CODE}"
},
"assets": {
"projectKind": "Orchestration",
"intents": [
{
"category": "string",
"orchestration": {
"kind": "luis",
"luisOrchestration": {
"appId": "00001111-aaaa-2222-bbbb-3333cccc4444",
"appVersion": "string",
"slotName": "string"
},
"cluOrchestration": {
"projectName": "string",
"deploymentName": "string"
},
"qnaOrchestration": {
"projectName": "string"
}
}
}
],
"utterances": [
{
"text": "Trying orchestration",
"language": "{LANGUAGE-CODE}",
"intent": "string"
}
]
}
}
| Ключ | Заполнитель | значение | Пример |
|---|---|---|---|
api-version |
{API-VERSION} |
Версия вызываемого API. Используемая здесь версия должна совпадать с версией API в URL-адресе. | 2022-03-01-preview |
projectName |
{PROJECT-NAME} |
Имя проекта. Это значение чувствительно к регистру. | EmailApp |
language |
{LANGUAGE-CODE} |
Строка, указывающая код языка для речевых фрагментов, используемых в проекте. Если проект является многоязычным проектом, выберите языковой код для большинства речевых фрагментов. | en-us |
Обучение модели
Чтобы обучить модель, необходимо запустить задание обучения. Выходные данные успешного задания обучения — это обученная модель.
Создайте запрос POST, используя указанный ниже URL-адрес, заголовки и текст JSON, чтобы запустить задание обучения.
Запросить URL-адрес
При создании запроса API используйте следующий URL-адрес. Замените значения заполнителей собственными значениями.
{ENDPOINT}/language/authoring/analyze-conversations/projects/{PROJECT-NAME}/:train?api-version={API-VERSION}
Заголовки
Используйте следующий заголовок для проверки подлинности запроса.
| Ключ | значение |
|---|---|
Ocp-Apim-Subscription-Key |
Ключ к ресурсу. Используется для проверки подлинности запросов API. |
Текст запроса
Используйте в запросе следующий объект. Когда обучение завершится, модели будет присвоено имя MyModel.
{
"modelLabel": "{MODEL-NAME}",
"trainingMode": "standard",
"trainingConfigVersion": "{CONFIG-VERSION}",
"evaluationOptions": {
"kind": "percentage",
"testingSplitPercentage": 20,
"trainingSplitPercentage": 80
}
}
| Ключ | Заполнитель | значение | Пример |
|---|---|---|---|
modelLabel |
{MODEL-NAME} |
Название вашей модели. | Model1 |
trainingMode |
standard |
Режим обучения. В оркестрации доступен только один режим обучения, это standard. |
standard |
trainingConfigVersion |
{CONFIG-VERSION} |
Версия модели конфигурации обучения. По умолчанию используется последняя версия модели. | 2022-05-01 |
kind |
percentage |
Методы разделения. Возможные значения: percentage или manual. Дополнительные сведения см. в статье об обучении модели. |
percentage |
trainingSplitPercentage |
80 |
Процент помеченных тегами данных, которые будут включены в набор для обучения. Рекомендуемое значение — 80. |
80 |
testingSplitPercentage |
20 |
Процент помеченных тегами данных, которые будут включены в набор для тестирования. Рекомендуемое значение — 20. |
20 |
Примечание.
trainingSplitPercentage и testingSplitPercentage требуются только в том случае, если для Kind задано значение percentage, а сумма процентных значений должна быть равна 100.
После отправки запроса API вы получите ответ, указывающий 202 на успех. В заголовках ответа извлеките значение operation-location, отформатированное следующим образом:
{ENDPOINT}/language/authoring/analyze-conversations/projects/{PROJECT-NAME}/train/jobs/{JOB-ID}?api-version={API-VERSION}
Этот URL-адрес позволяет получить текущее состояние задания обучения.
Получить статус обучения
Обучение может занять от 10 до 30 минут. Следующий запрос можно использовать для регулярного опроса состояния задания обучения, пока оно не будет успешно завершено.
Используйте следующий запрос GET, чтобы получить состояние хода обучения модели. Замените значения заполнителей собственными значениями.
Запросить URL-адрес
{ENDPOINT}/language/authoring/analyze-conversations/projects/{PROJECT-NAME}/train/jobs/{JOB-ID}?api-version={API-VERSION}
Заголовки
Используйте следующий заголовок для проверки подлинности запроса.
| Ключ | значение |
|---|---|
Ocp-Apim-Subscription-Key |
Ключ к ресурсу. Используется для проверки подлинности запросов API. |
Текст ответа
После отправки запроса вы получите следующий ответ. Продолжайте опрос этой конечной точки до тех пор, пока значение параметра Состояние не изменится на "Выполнено".
{
"result": {
"modelLabel": "{MODEL-LABEL}",
"trainingConfigVersion": "{TRAINING-CONFIG-VERSION}",
"estimatedEndDateTime": "2022-04-18T15:47:58.8190649Z",
"trainingStatus": {
"percentComplete": 3,
"startDateTime": "2022-04-18T15:45:06.8190649Z",
"status": "running"
},
"evaluationStatus": {
"percentComplete": 0,
"status": "notStarted"
}
},
"jobId": "xxxxxx-xxxxx-xxxxxx-xxxxxx",
"createdDateTime": "2022-04-18T15:44:44Z",
"lastUpdatedDateTime": "2022-04-18T15:45:48Z",
"expirationDateTime": "2022-04-25T15:44:44Z",
"status": "running"
}
| Ключ | значение | Пример |
|---|---|---|
modelLabel |
имя модели; | Model1 |
trainingConfigVersion |
Версия конфигурации тренировочной программы. По умолчанию используется последняя версия. | 2022-05-01 |
startDateTime |
Время начала обучения | 2022-04-14T10:23:04.2598544Z |
status |
Состояние учебной задачи. | running |
estimatedEndDateTime |
Предполагаемое время завершения задания обучения. | 2022-04-14T10:29:38.2598544Z |
jobId |
Идентификатор задания обучения. | xxxxx-xxxx-xxxx-xxxx-xxxxxxxxx |
createdDateTime |
Дата и время создания задачи обучения. | 2022-04-14T10:22:42Z |
lastUpdatedDateTime |
Дата и время последнего обновления задания обучения | 2022-04-14T10:23:45Z |
expirationDateTime |
Дата и время истечения задания обучения | 2022-04-14T10:22:42Z |
Разверните вашу модель
Обычно после обучения модели, вы детально изучаете сведения о её оценке. В этом кратком руководстве вы просто развернете модель и вызовете API прогнозирования для запроса результатов.
Отправка задания развертывания
Создайте запрос PUT, используя указанный ниже URL-адрес, заголовки и текст JSON, чтобы приступить к развертыванию модели оркестрации рабочих процессов.
Запросить URL-адрес
{ENDPOINT}/language/authoring/analyze-conversations/projects/{PROJECT-NAME}/deployments/{DEPLOYMENT-NAME}?api-version={API-VERSION}
Заголовки
Используйте следующий заголовок для проверки подлинности запроса.
| Ключ | значение |
|---|---|
Ocp-Apim-Subscription-Key |
Ключ к ресурсу. Используется для проверки подлинности запросов API. |
Тело запроса
{
"trainedModelLabel": "{MODEL-NAME}",
}
| Ключ | Заполнитель | значение | Пример |
|---|---|---|---|
| метка обученной модели | {MODEL-NAME} |
Имя модели, назначенное вашему развертыванию. Назначать можно только успешно обученные модели. Это значение чувствительно к регистру. | myModel |
После отправки запроса API вы получите ответ, указывающий 202 на успех. В заголовках ответа извлеките значение operation-location, отформатированное следующим образом:
{ENDPOINT}/language/authoring/analyze-conversations/projects/{PROJECT-NAME}/deployments/{DEPLOYMENT-NAME}/jobs/{JOB-ID}?api-version={API-VERSION}
Этот URL-адрес можно использовать для получения состояния задания развертывания.
Узнать статус задания развертывания
Используйте указанный ниже запрос GET для запроса состояния задания развертывания. Замените значения заполнителей собственными значениями.
Запросить URL-адрес
{ENDPOINT}/language/authoring/analyze-conversations/projects/{PROJECT-NAME}/deployments/{DEPLOYMENT-NAME}/jobs/{JOB-ID}?api-version={API-VERSION}
Заголовки
Используйте следующий заголовок для проверки подлинности запроса.
| Ключ | значение |
|---|---|
Ocp-Apim-Subscription-Key |
Ключ к ресурсу. Используется для проверки подлинности запросов API. |
Текст ответа
После отправки запроса вы получите следующий ответ. Продолжайте опрос этой конечной точки до тех пор, пока значение параметра Состояние не изменится на "Выполнено".
{
"jobId":"{JOB-ID}",
"createdDateTime":"{CREATED-TIME}",
"lastUpdatedDateTime":"{UPDATED-TIME}",
"expirationDateTime":"{EXPIRATION-TIME}",
"status":"running"
}
Модель запроса
Развернутую модель можно начать использовать для прогнозирования с помощью API прогнозирования.
После успешного развертывания модели вы можете начать отправлять запросы для получения предсказаний.
Создайте запрос POST, используя следующий URL-адрес, заголовки и текст JSON, чтобы приступить к тестированию модели рабочего процесса оркестрации.
Запросить URL-адрес
{ENDPOINT}/language/:analyze-conversations?api-version={API-VERSION}
Заголовки
Используйте следующий заголовок для проверки подлинности запроса.
| Ключ | значение |
|---|---|
Ocp-Apim-Subscription-Key |
Ключ к ресурсу. Используется для проверки подлинности запросов API. |
Тело запроса
{
"kind": "Conversation",
"analysisInput": {
"conversationItem": {
"text": "Text1",
"participantId": "1",
"id": "1"
}
},
"parameters": {
"projectName": "{PROJECT-NAME}",
"deploymentName": "{DEPLOYMENT-NAME}",
"directTarget": "qnaProject",
"targetProjectParameters": {
"qnaProject": {
"targetProjectKind": "QuestionAnswering",
"callingOptions": {
"context": {
"previousUserQuery": "Meet Surface Pro 4",
"previousQnaId": 4
},
"top": 1,
"question": "App Service overview"
}
}
}
}
}
Текст ответа
После отправки запроса вы получите следующий ответ для прогноза!
{
"kind": "ConversationResult",
"result": {
"query": "App Service overview",
"prediction": {
"projectKind": "Orchestration",
"topIntent": "qnaTargetApp",
"intents": {
"qnaTargetApp": {
"targetProjectKind": "QuestionAnswering",
"confidenceScore": 1,
"result": {
"answers": [
{
"questions": [
"App Service overview"
],
"answer": "The compute resources you use are determined by the *App Service plan* that you run your apps on.",
"confidenceScore": 0.7384000000000001,
"id": 1,
"source": "https://learn.microsoft.com/azure/app-service/overview",
"metadata": {},
"dialog": {
"isContextOnly": false,
"prompts": []
}
}
]
}
}
}
}
}
}
Очистка ресурсов
Если проект вам больше не нужен, вы можете удалить его с помощью интерфейсов API.
Создайте запрос DELETE, используя следующий URL-адрес, заголовки и текст JSON, чтобы удалить проект по распознаванию устной речи.
Запросить URL-адрес
{ENDPOINT}/language/authoring/analyze-conversations/projects/{PROJECT-NAME}?api-version={API-VERSION}
Заголовки
Используйте следующий заголовок для проверки подлинности запроса.
| Ключ | значение |
|---|---|
Ocp-Apim-Subscription-Key |
Ключ к ресурсу. Используется для проверки подлинности запросов API. |
После отправки запроса API вы получите ответ, указывающий 202 на успешность, что означает удаление проекта.