Примечание.
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
В этом руководстве приведены пошаговые инструкции по использованию распознавания именованных сущностей (NER) с Microsoft Foundry или REST API. NER позволяет обнаруживать и классифицировать сущности в неструктурированном тексте, например людей, мест, организаций и чисел. Пользовательский NER позволяет обучать модели для идентификации сущностей, специфичных для бизнеса, и дает возможность постоянно адаптировать их в соответствии с изменяющимися требованиями.
Чтобы приступить к началу, пример соглашения о кредите предоставляется в виде набора данных для создания пользовательской модели NER и извлечения этих ключевых сущностей:
- дата соглашения;
- Имя, адрес, город и штат заемщика
- Имя, адрес, город и штат кредитора
- сумма кредита и процентов.
Примечание.
- Если у вас уже есть язык Azure в средствах Foundry или ресурс с несколькими службами ( независимо от того, используется ли он самостоятельно или через Language Studio), вы можете продолжать использовать эти существующие языковые ресурсы на портале Microsoft Foundry. Дополнительные сведения см. в разделе "Использование средств Foundry" на портале Foundry.
Предварительные условия
Подписка Azure. Если у вас нет учетной записи, вы можете создать ее бесплатно.
Необходимые разрешения. Убедитесь, что пользователь, устанавливающий учетную запись и проект, назначен в качестве роли владельца учетной записи ИИ Azure на уровне подписки. Кроме того, роль Участника или Участника Cognitive Services в области подписки также соответствует этому требованию. Дополнительные сведения см. в разделе"Управление доступом на основе ролей" (RBAC).
Ресурс языка с учетной записью хранения. На странице выбора дополнительных функций выберите классификацию пользовательского текста, настраиваемое распознавание именованных сущностей, пользовательский анализ тональности и настраиваемую аналитику текста для здравоохранения, чтобы связать требуемую учетную запись хранения с этим ресурсом.

Примечание.
- Для создания языкового ресурса необходимо назначить роль владельца в группе ресурсов.
- Если вы подключаетесь к уже созданной учетной записи хранения, вам должна быть назначена роль владельца.
- Не перемещайте учетную запись хранения в другую группу ресурсов или подписку, связанную с ресурсом языка Azure.
Проект Foundry, созданный в Foundry. Дополнительные сведения см. в разделе"Создание проекта Foundry".
Пользовательский набор данных NER, загруженный в контейнер хранилища. Настраиваемый набор данных распознавания именованных сущностей (NER) — это коллекция помеченных текстовых документов, используемых для обучения пользовательской модели NER. Вы можете загрузить наш пример набора данных для этого быстрого начала. Исходный язык — английский.
Шаг 1. Настройка необходимых ролей, разрешений и параметров
Начнем с настройки ресурсов.
Включите функцию распознавания именованных сущностей
Убедитесь, что функция "Пользовательское распознавание текста" или "Распознавание именованных сущностей " включена на портале Azure.
- Перейдите к ресурсу языка на портале Azure.
- В меню слева в разделе "Управление ресурсами " выберите "Компоненты".
- Убедитесь, что включена функция "Пользовательское распознавание текста" или "Распознавание именованных сущностей ".
- Если учетная запись хранения не назначена, выберите и подключите учетную запись хранения.
- Нажмите кнопку "Применить".
Добавьте необходимые роли для языкового ресурса
- На странице языковых ресурсов на портале Azure выберите элемент "Управление доступом" (IAM) в левой области.
- Выберите "Добавить " для добавления назначений ролей и добавьте назначение роли "Владелец языка Cognitive Services " или " Участник Cognitive Services " для ресурса языка.
- В области "Назначение доступа" выберите "Пользователь", "Группа" или "Субъект-служба".
- Выберите участников.
- Выберите имя пользователя. Вы можете искать имена пользователей в поле "Выбор ". Повторите этот шаг для всех ролей.
- Повторите эти действия для всех учетных записей пользователей, которым требуется доступ к этому ресурсу.
Добавление требуемых ролей для учетной записи хранения
- Перейдите на страницу учетной записи хранения на портале Azure.
- Выберите элемент управления доступом (IAM) в левой области.
- Выберите Добавить, чтобы добавить назначение ролей, и выберите роль участника данных хранилища BLOB-объектов в учетной записи хранения.
- В области "Назначить доступ" выберите Управляемое удостоверение.
- Выберите участников.
- Выберите подписку и Language в качестве управляемого удостоверения. Вы можете искать языковой ресурс в поле "Выбор ".
Добавление обязательных ролей пользователей
Внимание
Если пропустить этот шаг, при попытке подключиться к пользовательскому проекту возникает ошибка 403. Важно, чтобы текущий пользователь имел эту роль для доступа к данным BLOB в учетной записи хранения, даже если вы являетесь владельцем этой учетной записи.
- Перейдите на страницу учетной записи хранения на портале Azure.
- Выберите элемент управления доступом (IAM) в левой области.
- Выберите Добавить, чтобы добавить назначение ролей, и выберите роль участника данных хранилища BLOB-объектов в учетной записи хранения.
- В области "Назначение доступа" выберите "Пользователь", "Группа" или "Субъект-служба".
- Выберите участников.
- Выберите пользователя. Вы можете искать имена пользователей в поле "Выбор ".
Внимание
Если у вас есть брандмауэр или виртуальная сеть или частная конечная точка, обязательно выберите разрешить службам Azure в списке доверенных служб доступ к этой учетной записи хранения на вкладке "Сеть " на портале Azure.

Шаг 2. Отправка набора данных в контейнер хранилища
Затем добавим контейнер и отправим файлы набора данных непосредственно в корневой каталог контейнера хранилища. Эти документы используются для обучения модели.
Добавьте контейнер в учетную запись хранения, связанную с ресурсом языка. Дополнительные сведения см. в статьео создании контейнера.
Скачайте пример набора данных с GitHub. Предоставленный пример набора данных содержит 20 соглашений о кредитах:
- В каждом соглашении указаны две стороны: кредитор и заемщик.
- Вы извлекаете соответствующую информацию: обе стороны, дата соглашения, сумма кредита и процентная ставка.
Откройте файл ZIP и извлеките папку с документами.
Перейдите к Литейному цеху.
Если вы еще не вошли, на портале появится запрос на использование учетных данных Azure.
После входа перейдите к вашему существующему проекту Foundry для быстрого старта.
Выберите центр управления в меню навигации слева.
Выберите подключенные ресурсы из раздела "Центр управления" в меню "Центр управления ".
Затем выберите хранилище BLOB-объектов рабочей области, настроенное для вас в качестве подключенного ресурса.
В хранилище BLOB-объектов рабочей области выберите «Просмотр» на портале Azure.
На странице AzurePortal для хранилища BLOB-объектов выберите " Отправить " в верхнем меню. Затем выберите файлы
.txtи.json, которые вы скачали ранее. Наконец, нажмите кнопку "Отправить ", чтобы добавить файл в контейнер.
Теперь, когда необходимые ресурсы Azure подготовлены и настроены на портале Azure, давайте будем использовать эти ресурсы в Foundry для создания настраиваемой пользовательской модели распознавания именованных сущностей (NER).
Шаг 3. Подключение языкового ресурса
Затем мы создадим подключение к ресурсу языка, чтобы Foundry могли безопасно получить доступ к нему. Это подключение обеспечивает безопасное управление удостоверениями и проверку подлинности, а также контролируемый и изолированный доступ к данным.
Вернитесь в Литейный цех.
Получите доступ к существующему проекту Foundry, чтобы использовать это краткое руководство.
Выберите центр управления в меню навигации слева.
Выберите подключенные ресурсы из раздела "Центр управления" в меню "Центр управления ".
В главном окне нажмите кнопку +Создать подключение .
Выберите язык из окна "Добавить подключение к внешним ресурсам ".
Выберите "Добавить подключение", а затем нажмите кнопку "Закрыть".

Шаг 4. Настройка пользовательской модели NER
Теперь мы готовы создать пользовательскую модель точной настройки NER.
В разделе "Проект " в меню "Центр управления" выберите "Перейти к проекту".
В меню "Обзор" выберите "Точное настройка".
В главном окне выберите вкладку тонкой настройки службы ИИ , а затем нажмите кнопку +Точно настроить .
В окне "Создание и настройка службы" выберите вкладку "Распознавание пользовательских именованных сущностей" и нажмите кнопку "Далее".

В окне задачи "Создание службы тонкой настройки" заполните поля следующим образом:
Подключенная служба. Имя вашего языкового ресурса должно отображаться в этом поле по умолчанию. Если нет, добавьте его из раскрывающегося меню.
Имя. Присвойте проекту задачи тонкой настройки имя.
Язык. Английский установлен как язык по умолчанию и уже отображается в этом поле.
Описание. При необходимости можно указать описание или оставить это поле пустым.
Контейнер хранилища Blob. Выберите контейнер хранилища BLOB-объектов рабочей области на шаге 2 и нажмите кнопку "Подключить ".
Наконец, нажмите кнопку "Создать ". Выполнение операции создания может занять несколько минут.

Шаг 5. Обучение модели

- В меню "Начало работы" выберите "Управление данными". В окне "Добавление данных для обучения и тестирования" отображаются примеры данных , которые вы ранее отправили в контейнер хранилища BLOB-объектов Azure.
- Затем в меню "Начало работы" выберите "Обучение модели".
- Нажмите кнопку +Тренировать модель. Когда появится окно обучить новую модель, введите имя новой модели и сохраните значения по умолчанию. Нажмите кнопку Далее.
- В окне Обучение новой модели оставьте включенной опцию Автоматически разделить тестовый набор от обучающих данных по умолчанию с рекомендуемыми значениями процентов: 80% для обучающих данных и 20% для тестовых данных.
- Просмотрите конфигурацию модели и нажмите кнопку "Создать ".
- После обучения модели можно выбрать "Оценка модели " в меню "Начало работы ". Вы можете выбрать модель в окне "Оценка модели " и при необходимости внести улучшения.
Шаг 6. Развертывание модели
Как правило, после обучения модели просмотрите его сведения об оценке. В этом кратком руководстве вы можете просто развернуть модель и сделать ее доступной для тестирования на языковой площадке Azure или путем вызова API прогнозирования. Однако, если вы хотите, вы можете воспользоваться моментом, чтобы выбрать "Оценить модель " в меню слева и просмотреть подробные данные телеметрии для модели. Выполните следующие действия, чтобы развернуть модель в Foundry.
Выберите "Развернуть модель " в меню слева.
Затем выберите ➕"Развернуть обученную модель" в окне "Развертывание модели ".
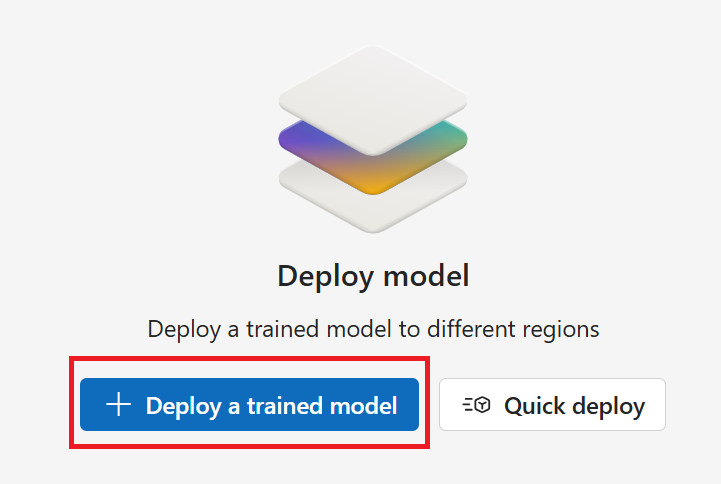
Убедитесь, что выбрана кнопка "Создать новое развертывание ".
Выполните развертывание полей окна обученной модели :
- Имя развертывания. Присвойте модели имя.
- Назначьте модель. Выберите обученную модель в раскрывающемся меню.
- Регион. Выберите регион в раскрывающемся меню.
Наконец, нажмите кнопку "Создать ". Развертывание модели может занять несколько минут.
После успешного развертывания можно просмотреть состояние развертывания модели на странице развертывания модели . Дата окончания срока действия, которая появляется помечает дату, когда развернутая модель становится недоступной для задач прогнозирования. Эта дата обычно составляет 18 месяцев после развертывания конфигурации обучения.

Шаг 7. Пробная площадка для языка Azure
Языковая площадка предоставляет песочницу для тестирования и настройки настраиваемой модели перед развертыванием в рабочей среде без написания кода.
- В верхней строке меню выберите "Попробовать на площадке".
- В окне "Языковая площадка Azure" выберите плитку распознавания пользовательских именованных сущностей .
- В разделе "Конфигурация" выберите имя проекта и имя развертывания в раскрывающихся меню.
- Введите сущность и нажмите кнопку "Выполнить".
- Результаты можно оценить в окне сведений .
Готово, поздравляем!
В этом кратком руководстве вы создали настраиваемую модель NER, развернули ее в Foundry и протестировали модель в песочнице Azure Language.
Очистка ресурсов
Если проект больше не нужен, его можно удалить из Foundry.
- Перейдите на домашнюю страницу Foundry . Начните процесс аутентификации, выполнив вход, если вы еще не завершили этот шаг и ваш сеанс не активен.
- Выберите проект, который хотите удалить из Keep building with Foundry.
- Выберите центр управления.
- Выберите "Удалить проект".
Чтобы удалить концентратор вместе со всеми его проектами:
Перейдите на вкладку Обзор в секции Концентратор.
Справа нажмите кнопку "Удалить узел".
Ссылка открывает портал Azure, чтобы вы могли удалить концентратор.
Предварительные условия
- Подписка Azure — создайте бесплатную учетную запись.
Создание нового языка Azure в ресурсе Foundry Tools и учетной записи хранения Azure
Прежде чем использовать настраиваемое распознавание именованных сущностей (NER), необходимо создать языковой ресурс, который предоставляет учетные данные, нужные для создания проекта и начала обучения модели. Вам также нужна учетная запись хранения Azure, где можно передать набор данных, используемый при создании модели.
Внимание
Чтобы быстро приступить к работе, рекомендуется создать новый ресурс языка. Выполните действия, описанные в этой статье, чтобы создать ресурс Azure Language и одновременно создать и/или подключить учетную запись хранения. Создание обоих одновременно проще, чем делать это позже.
Если у вас есть уже существующий ресурс, который вы хотите использовать, необходимо подключить его к учетной записи хранения. Дополнительные сведения см. в разделе Создание проекта.
Создание ресурса на портале Azure
Войдите на портал Azure , чтобы создать новый ресурс Azure Language in Foundry Tools.
В появившемся окне выберите настраиваемую классификацию текста и распознавание именованных сущностей из пользовательских функций. Нажмите кнопку "Продолжить", чтобы создать ресурс в нижней части экрана.

Создайте языковой ресурс с приведенными ниже сведениями.
Имя Описание Подписка Ваша подписка Azure. Группа ресурсов Группа ресурсов, содержащая ваш ресурс. Можно использовать существующий или создать новый. Область/регион Регион для языкового ресурса. Например, "Западная часть США 2". Имя Имя ресурса. Ценовая категория Тарифный план вашего языкового ресурса. Вы можете использовать уровень "Бесплатный" (F0), чтобы поработать со службой. Примечание.
Если вы получите сообщение о том, что ваша учетная запись входа не является владельцем выбранной группы ресурсов учетной записи хранения, в вашей учетной записи должна быть назначена роль владельца в данной группе ресурсов, прежде чем вы сможете создать ресурс для языка. Обратитесь за помощью к владельцу подписки Azure.
В разделе "Настраиваемая классификация текста" и "Распознавание именованных сущностей" выберите существующую учетную запись хранения или выберите новую учетную запись хранения. Эти значения помогут вам приступить к работе и не обязательно являются значениями учетной записи хранения, которые вы будете использовать в производственной среде. Чтобы избежать задержки во время создания проекта, подключитесь к учетным записям хранения в том же регионе, что и ресурс языка.
Значение учетной записи хранилища Рекомендуемое значение Имя учетной записи хранилища Любое имя Тип учетной записи хранилища Стандартное локально избыточное хранилище (LRS) Убедитесь, что флажок Уведомление об ответственном применении ИИ установлен. В нижней части страницы щелкните Просмотр и создание, а затем нажмите Создать.

Загрузка примера данных в контейнер blob-объекта.
Создав учетную запись хранения Azure и подключив ее к ресурсу языка, необходимо передать документы из примера набора данных в корневой каталог контейнера. Эти документы используются для обучения модели.
Скачайте пример набора данных с GitHub.
Откройте файл ZIP и извлеките папку с документами.
На портале Azure перейдите к созданной учетной записи хранения и выберите ее.
В учетной записи хранения в меню слева выберите Контейнеры под пунктом Хранилище данных. На появившемся экране нажмите + Контейнер. Присвойте контейнеру имя example-data и оставьте Уровень общего доступа, установленный по умолчанию.

После создания контейнера выберите его. Затем нажмите кнопку "Отправить", чтобы выбрать
.txtскачанные ранее файлы..json


Предоставленный пример набора данных содержит 20 соглашений о кредитах. В каждом соглашении указаны две стороны: кредитор и заемщик. Вы можете использовать предоставленный пример файла, чтобы извлечь нужную информацию об участниках соглашения, его дате, сумме кредита и процентной ставке.
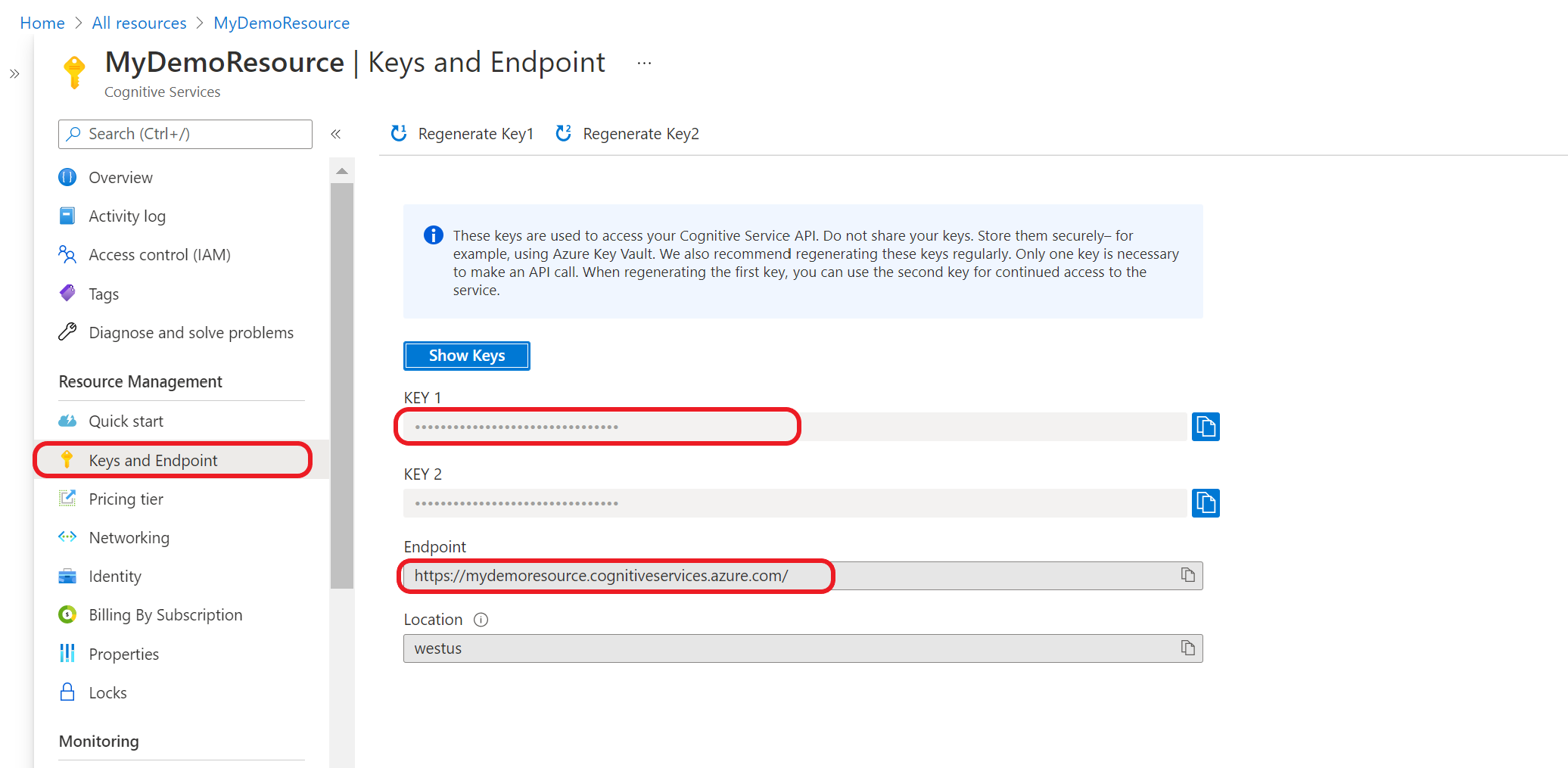
Получите ключи и конечную точку вашего ресурса
Перейдите на страницу обзора ресурса на портале Azure
В меню слева выберите Ключи и конечная точка. Конечная точка и ключ используются для запросов API.

Создание пользовательского проекта NER
Завершив настройку ресурса и учетной записи хранения создайте новый пользовательский проект NER. Проект — это рабочая область для создания настраиваемых моделей машинного обучения на основе данных. Ваш проект доступен вам и другим пользователям, имеющим доступ к используемому ресурсу языка Azure.
Используйте файл тегов, загруженный из примера данных на предыдущем шаге, и добавьте его в текст следующего запроса.
Активация задания импорта проектов
Отправьте запрос POST, используя следующий URL-адрес, заголовки и текст JSON, чтобы импортировать файл меток. Убедитесь, что файл меток соответствует допустимому формату.
Если проект с таким именем уже существует, данные этого проекта заменяются.
{Endpoint}/language/authoring/analyze-text/projects/{projectName}/:import?api-version={API-VERSION}
| Заполнитель | Значение | Пример |
|---|---|---|
{ENDPOINT} |
Конечная точка для проверки подлинности запроса API. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
Имя проекта. Это значение чувствительно к регистру. | myProject |
{API-VERSION} |
Версия вызываемого API. Здесь указано значение для последней выпущенной версии. Дополнительные сведения см. в разделе"Жизненный цикл модели". | 2022-05-01 |
Заголовки
Используйте следующий заголовок для проверки подлинности запроса.
| Ключ | Значение |
|---|---|
Ocp-Apim-Subscription-Key |
Ключ к вашему ресурсу. Используется для проверки подлинности запросов API. |
Тело
Используйте следующий код JSON в запросе. Замените значения заполнителей собственными значениями.
{
"projectFileVersion": "{API-VERSION}",
"stringIndexType": "Utf16CodeUnit",
"metadata": {
"projectName": "{PROJECT-NAME}",
"projectKind": "CustomEntityRecognition",
"description": "Trying out custom NER",
"language": "{LANGUAGE-CODE}",
"multilingual": true,
"storageInputContainerName": "{CONTAINER-NAME}",
"settings": {}
},
"assets": {
"projectKind": "CustomEntityRecognition",
"entities": [
{
"category": "Entity1"
},
{
"category": "Entity2"
}
],
"documents": [
{
"location": "{DOCUMENT-NAME}",
"language": "{LANGUAGE-CODE}",
"dataset": "{DATASET}",
"entities": [
{
"regionOffset": 0,
"regionLength": 500,
"labels": [
{
"category": "Entity1",
"offset": 25,
"length": 10
},
{
"category": "Entity2",
"offset": 120,
"length": 8
}
]
}
]
},
{
"location": "{DOCUMENT-NAME}",
"language": "{LANGUAGE-CODE}",
"dataset": "{DATASET}",
"entities": [
{
"regionOffset": 0,
"regionLength": 100,
"labels": [
{
"category": "Entity2",
"offset": 20,
"length": 5
}
]
}
]
}
]
}
}
| Ключ | Заполнитель | Значение | Пример |
|---|---|---|---|
api-version |
{API-VERSION} |
Версия вызываемого API. Используемая здесь версия должна совпадать с версией API в URL-адресе. Узнайте больше о других доступных версиях API. | 2022-03-01-preview |
projectName |
{PROJECT-NAME} |
Имя проекта. Это значение чувствительно к регистру. | myProject |
projectKind |
CustomEntityRecognition |
Тип проекта. | CustomEntityRecognition |
language |
{LANGUAGE-CODE} |
Строка, указывающая код языка для документов, используемых в проекте. Если проект является многоязычным проектом, выберите языковой код большинства документов. | en-us |
multilingual |
true |
Логическое значение, которое позволяет иметь документы на нескольких языках в наборе данных. После развертывания модели вы можете отправить к ней запрос на любом поддерживаемом языке (не обязательно включенном в обучающие документы). Сведения о многоязычной поддержке см. в разделе Поддержка языков. | true |
storageInputContainerName |
{CONTAINER-NAME} | Имя контейнера хранилища Azure, содержащего отправленные документы. | myContainer |
entities |
Массив, содержащий все типы сущностей, которые есть в проекте и извлеченные из документов. | ||
documents |
Массив, содержащий все документы в проекте и список сущностей, помеченных в каждом документе. | [] | |
location |
{DOCUMENT-NAME} |
Расположение документов в контейнере хранилища. | doc1.txt |
dataset |
{DATASET} |
Тестовый набор, в который помещается этот файл при разделении данных перед обучением. Дополнительные сведения см. в разделе"Обучение модели". Возможные значения для этого поля: Train и Test. |
Train |
После отправки запроса API вы получите ответ, указывающий 202 на правильность отправки задания. Извлеките значение operation-location из заголовков ответа. Ниже приведен пример формата:
{ENDPOINT}/language/authoring/analyze-text/projects/{PROJECT-NAME}/import/jobs/{JOB-ID}?api-version={API-VERSION}
{JOB-ID} используется для идентификации запроса, так как эта операция является асинхронной. Этот URL-адрес используется для получения состояния задания импорта.
Возможные сценарии ошибок для этого запроса:
- выбранный ресурс не имеет необходимых разрешений для учетной записи хранения;
- Указанный
storageInputContainerNameне существует. - используется недопустимый код языка или тип кода языка не является строковым;
- Значение
multilingualявляется строкой, а не логическим значением.
Получение сведений о состоянии задания на импорт
Используйте следующий запрос GET, чтобы получить состояние импорта проекта. Замените значения заполнителей собственными значениями.
Запросить URL-адрес
{ENDPOINT}/language/authoring/analyze-text/projects/{PROJECT-NAME}/import/jobs/{JOB-ID}?api-version={API-VERSION}
| Заполнитель | Значение | Пример |
|---|---|---|
{ENDPOINT} |
Конечная точка для проверки подлинности запроса API. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
Имя проекта. Это значение чувствительно к регистру. | myProject |
{JOB-ID} |
Идентификатор для определения состояния обучения модели. Значение содержится в значении заголовка location, полученного на предыдущем шаге. |
xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxxx |
{API-VERSION} |
Версия вызываемого API. Значение, на которое ссылается, предназначено для последней версии, выпущенной. Дополнительные сведения см. в разделе"Жизненный цикл модели". | 2022-05-01 |
Заголовки
Используйте следующий заголовок для проверки подлинности запроса.
| Ключ | Значение |
|---|---|
Ocp-Apim-Subscription-Key |
Ключ к вашему ресурсу. Используется для проверки подлинности запросов API. |
Обучение модели
Как правило, после создания проекта вы присваиваете теги документам в подключенном к проекту контейнере. В этом кратком руководстве вы импортировали пример помеченного набора данных и инициализировали проект с помощью примера файла тегов JSON.
Запуск задачи обучения
После импорта проекта можно начать обучение модели.
Отправьте запрос POST, используя следующий URL-адрес, заголовки и текст JSON, чтобы отправить задание обучения. Замените значения заполнителей собственными значениями.
{ENDPOINT}/language/authoring/analyze-text/projects/{PROJECT-NAME}/:train?api-version={API-VERSION}
| Заполнитель | Значение | Пример |
|---|---|---|
{ENDPOINT} |
Конечная точка для проверки подлинности запроса API. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
Имя проекта. Это значение чувствительно к регистру. | myProject |
{API-VERSION} |
Версия вызываемого API. Значение, на которое ссылается, предназначено для последней версии, выпущенной. Дополнительные сведения см. в разделе"Жизненный цикл модели". | 2022-05-01 |
Заголовки
Используйте следующий заголовок для проверки подлинности запроса.
| Ключ | Значение |
|---|---|
Ocp-Apim-Subscription-Key |
Ключ к вашему ресурсу. Используется для проверки подлинности запросов API. |
Текст запроса
Используйте следующий код JSON в тексте запроса. Модель предоставляется после завершения обучения {MODEL-NAME}. Только успешные тренировочные задания создают модели.
{
"modelLabel": "{MODEL-NAME}",
"trainingConfigVersion": "{CONFIG-VERSION}",
"evaluationOptions": {
"kind": "percentage",
"trainingSplitPercentage": 80,
"testingSplitPercentage": 20
}
}
| Ключ | Заполнитель | Значение | Пример |
|---|---|---|---|
| modelLabel | {MODEL-NAME} |
Название модели, присвоенное вашей модели после успешного обучения. | myModel |
| trainingConfigVersion | {CONFIG-VERSION} |
Это версия модели , используемая для обучения модели. | 2022-05-01 |
| параметры оценки | Возможность разделять данные по наборам для обучения и тестирования. | {} |
|
| добрый | percentage |
Методы разделения. Возможные значения: percentage или manual. Дополнительные сведения см. в разделе"Обучение модели". |
percentage |
| процент разделения на обучение | 80 |
Процент помеченных тегами данных, которые будут включены в набор для обучения. Рекомендуемое значение — 80. |
80 |
| testingSplitPercentage | 20 |
Процент помеченных тегами данных, которые будут включены в набор для тестирования. Рекомендуемое значение — 20. |
20 |
Примечание.
trainingSplitPercentage и testingSplitPercentage требуются только в том случае, если для Kind задано значение percentage, а сумма процентных значений должна быть равна 100.
После отправки запроса API вы получите ответ, указывающий 202 на правильность отправки задания. В заголовках ответа извлеките location значение, отформатированный следующим образом:
{ENDPOINT}/language/authoring/analyze-text/projects/{PROJECT-NAME}/train/jobs/{JOB-ID}?api-version={API-VERSION}
{JOB-ID} используется для идентификации запроса, так как эта операция является асинхронной. Этот URL-адрес позволяет получить текущее состояние обучения.
Получение статуса задания обучения
Обучение может занять от 10 до 30 минут для этого примера набора данных. Следующий запрос можно использовать для проверки состояния задания обучения до успешного завершения.
Используйте следующий запрос GET, чтобы получить состояние хода обучения модели. Замените значения заполнителей собственными значениями.
Запросить URL-адрес
{ENDPOINT}/language/authoring/analyze-text/projects/{PROJECT-NAME}/train/jobs/{JOB-ID}?api-version={API-VERSION}
| Заполнитель | Значение | Пример |
|---|---|---|
{ENDPOINT} |
Конечная точка для проверки подлинности запроса API. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
Имя проекта. Это значение чувствительно к регистру. | myProject |
{JOB-ID} |
Идентификатор для определения состояния обучения модели. Значение содержится в значении заголовка location, полученного на предыдущем шаге. |
xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxxx |
{API-VERSION} |
Версия вызываемого API. Значение, на которое ссылается, предназначено для последней версии, выпущенной. Дополнительные сведения см. в разделе"Жизненный цикл модели". | 2022-05-01 |
Заголовки
Используйте следующий заголовок для проверки подлинности запроса.
| Ключ | Значение |
|---|---|
Ocp-Apim-Subscription-Key |
Ключ к вашему ресурсу. Используется для проверки подлинности запросов API. |
Текст ответа
После отправки запроса вы получите следующий ответ.
{
"result": {
"modelLabel": "{MODEL-NAME}",
"trainingConfigVersion": "{CONFIG-VERSION}",
"estimatedEndDateTime": "2022-04-18T15:47:58.8190649Z",
"trainingStatus": {
"percentComplete": 3,
"startDateTime": "2022-04-18T15:45:06.8190649Z",
"status": "running"
},
"evaluationStatus": {
"percentComplete": 0,
"status": "notStarted"
}
},
"jobId": "{JOB-ID}",
"createdDateTime": "2022-04-18T15:44:44Z",
"lastUpdatedDateTime": "2022-04-18T15:45:48Z",
"expirationDateTime": "2022-04-25T15:44:44Z",
"status": "running"
}
Разверните свою модель
Обычно после обучения модели изучаются сведения об оценке и вносятся необходимые улучшения. В этом кратком руководстве вы просто развернете модель и сделаете ее доступной для вас, чтобы попробовать в Language Studio или вызвать API прогнозирования.
Запуск задания развертывания
Отправьте запрос PUT, используя следующий URL-адрес, заголовки и текст JSON, чтобы отправить задание развертывания. Замените значения заполнителей собственными значениями.
{Endpoint}/language/authoring/analyze-text/projects/{projectName}/deployments/{deploymentName}?api-version={API-VERSION}
| Заполнитель | Значение | Пример |
|---|---|---|
{ENDPOINT} |
Конечная точка для проверки подлинности запроса API. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
Имя проекта. Это значение чувствительно к регистру. | myProject |
{DEPLOYMENT-NAME} |
Имя вашего развертывания. Это значение чувствительно к регистру. | staging |
{API-VERSION} |
Версия вызываемого API. Значение, на которое ссылается, предназначено для последней версии, выпущенной. Дополнительные сведения см. в разделе"Жизненный цикл модели". | 2022-05-01 |
Заголовки
Используйте следующий заголовок для проверки подлинности запроса.
| Ключ | Значение |
|---|---|
Ocp-Apim-Subscription-Key |
Ключ к вашему ресурсу. Используется для проверки подлинности запросов API. |
Текст запроса
Используйте следующий код JSON в тексте запроса. Используйте имя модели, которое вы назначаете развертыванию.
{
"trainedModelLabel": "{MODEL-NAME}"
}
| Ключ | Заполнитель | Значение | Пример |
|---|---|---|---|
| ярлык обученной модели | {MODEL-NAME} |
Имя модели, назначенное вашему развертыванию. Назначать можно только успешно обученные модели. Это значение чувствительно к регистру. | myModel |
После отправки запроса API вы получите ответ, указывающий 202 на правильность отправки задания. В заголовках ответа извлеките operation-location значение, отформатированный следующим образом:
{ENDPOINT}/language/authoring/analyze-text/projects/{PROJECT-NAME}/deployments/{DEPLOYMENT-NAME}/jobs/{JOB-ID}?api-version={API-VERSION}
{JOB-ID} используется для идентификации запроса, так как эта операция является асинхронной. Этот URL-адрес можно использовать для получения состояния развертывания.
Получение состояния задания развертывания
Используйте следующий запрос GET для запроса состояния задания развертывания. Вы можете использовать URL-адрес, полученный на предыдущем шаге, или заменить значения заполнителей собственными значениями.
{ENDPOINT}/language/authoring/analyze-text/projects/{PROJECT-NAME}/deployments/{DEPLOYMENT-NAME}/jobs/{JOB-ID}?api-version={API-VERSION}
| Заполнитель | Значение | Пример |
|---|---|---|
{ENDPOINT} |
Конечная точка для проверки подлинности запроса API. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
Имя проекта. Это значение чувствительно к регистру. | myProject |
{DEPLOYMENT-NAME} |
Имя вашего развертывания. Это значение чувствительно к регистру. | staging |
{JOB-ID} |
Идентификатор для определения состояния обучения модели. Он находится в значении заголовка location , полученном на предыдущем шаге. |
xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxxx |
{API-VERSION} |
Версия вызываемого API. Значение, на которое ссылается, предназначено для последней версии, выпущенной. Дополнительные сведения см. в разделе"Жизненный цикл модели". | 2022-05-01 |
Заголовки
Используйте следующий заголовок для проверки подлинности запроса.
| Ключ | Значение |
|---|---|
Ocp-Apim-Subscription-Key |
Ключ к вашему ресурсу. Используется для проверки подлинности запросов API. |
Текст ответа
После отправки запроса вы получите следующий ответ. Продолжайте опрос этой конечной точки до тех пор, пока значение параметра Состояние не изменится на "Выполнено". Необходимо получить код 200, указывающий на успешное выполнение запроса.
{
"jobId":"{JOB-ID}",
"createdDateTime":"{CREATED-TIME}",
"lastUpdatedDateTime":"{UPDATED-TIME}",
"expirationDateTime":"{EXPIRATION-TIME}",
"status":"running"
}
Извлечение пользовательских сущностей
Развернутую модель можно использовать для извлечения сущностей из текста через API прогнозирования. В примере набора данных, скачанном ранее, можно найти тестовые документы, которые можно использовать на этом шаге.
Отправьте задачу пользовательского NER
Используйте этот запрос POST для запуска задачи классификации текста.
{ENDPOINT}/language/analyze-text/jobs?api-version={API-VERSION}
| Заполнитель | Значение | Пример |
|---|---|---|
{ENDPOINT} |
Конечная точка для проверки подлинности запроса API. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{API-VERSION} |
Версия вызываемого API. Значение, на которое ссылается, предназначено для последней версии, выпущенной. Дополнительные сведения см. в разделе"Жизненный цикл модели". | 2022-05-01 |
Заголовки
| Ключ | Значение |
|---|---|
| Ocp-Apim-Subscription-Key | Ключ, который предоставляет доступ к этому API. |
Тело
{
"displayName": "Extracting entities",
"analysisInput": {
"documents": [
{
"id": "1",
"language": "{LANGUAGE-CODE}",
"text": "Text1"
},
{
"id": "2",
"language": "{LANGUAGE-CODE}",
"text": "Text2"
}
]
},
"tasks": [
{
"kind": "CustomEntityRecognition",
"taskName": "Entity Recognition",
"parameters": {
"projectName": "{PROJECT-NAME}",
"deploymentName": "{DEPLOYMENT-NAME}"
}
}
]
}
| Ключ | Заполнитель | Значение | Пример |
|---|---|---|---|
displayName |
{JOB-NAME} |
Имя вашего задания. | MyJobName |
documents |
[{},{}] | Список документов для запуска задач. | [{},{}] |
id |
{DOC-ID} |
Имя или идентификатор документа. | doc1 |
language |
{LANGUAGE-CODE} |
Строка, указывающая код языка для документа. Если этот ключ не указан, служба предполагает язык по умолчанию проекта, выбранного во время создания проекта. Список всех поддерживаемых языков см. в статье Поддержка языков. | en-us |
text |
{DOC-TEXT} |
Задача документа, для которого будут выполняться задачи. | Lorem ipsum dolor sit amet |
tasks |
Список задач, которые мы хотим выполнить. | [] |
|
taskName |
CustomEntityRecognition |
Имя задачи | Распознавание пользовательских сущностей |
parameters |
Список параметров, которые нужно передать задаче. | ||
project-name |
{PROJECT-NAME} |
Имя проекта. Это значение чувствительно к регистру. | myProject |
deployment-name |
{DEPLOYMENT-NAME} |
Имя вашего развертывания. Это значение чувствительно к регистру. | prod |
Ответ
Вы получите ответ 202, указывающий, что ваша задача успешно отправлена. В заголовках ответа извлеките operation-location.
operation-location имеет следующий формат:
{ENDPOINT}/language/analyze-text/jobs/{JOB-ID}?api-version={API-VERSION}
Этот URL-адрес можно использовать для запроса состояния завершения задачи и получения результатов после ее завершения.
Получение результатов выполнения задачи
Используйте следующий запрос GET для запроса состояния или результатов пользовательской задачи распознавания сущностей.
{ENDPOINT}/language/analyze-text/jobs/{JOB-ID}?api-version={API-VERSION}
| Заполнитель | Значение | Пример |
|---|---|---|
{ENDPOINT} |
Конечная точка для проверки подлинности запроса API. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{API-VERSION} |
Версия вызываемого API. Значение, на которое ссылается, предназначено для последней версии, выпущенной. Дополнительные сведения см. в разделе"Жизненный цикл модели". | 2022-05-01 |
Заголовки
| Ключ | Значение |
|---|---|
| Ocp-Apim-Subscription-Key | Ключ, который предоставляет доступ к этому API. |
Текст ответа
Ответ будет документом JSON со следующими параметрами
{
"createdDateTime": "2021-05-19T14:32:25.578Z",
"displayName": "MyJobName",
"expirationDateTime": "2021-05-19T14:32:25.578Z",
"jobId": "xxxx-xxxx-xxxxx-xxxxx",
"lastUpdateDateTime": "2021-05-19T14:32:25.578Z",
"status": "succeeded",
"tasks": {
"completed": 1,
"failed": 0,
"inProgress": 0,
"total": 1,
"items": [
{
"kind": "EntityRecognitionLROResults",
"taskName": "Recognize Entities",
"lastUpdateDateTime": "2020-10-01T15:01:03Z",
"status": "succeeded",
"results": {
"documents": [
{
"entities": [
{
"category": "Event",
"confidenceScore": 0.61,
"length": 4,
"offset": 18,
"text": "trip"
},
{
"category": "Location",
"confidenceScore": 0.82,
"length": 7,
"offset": 26,
"subcategory": "GPE",
"text": "Seattle"
},
{
"category": "DateTime",
"confidenceScore": 0.8,
"length": 9,
"offset": 34,
"subcategory": "DateRange",
"text": "last week"
}
],
"id": "1",
"warnings": []
}
],
"errors": [],
"modelVersion": "2020-04-01"
}
}
]
}
}
Очистка ресурсов
Если проект больше не нужен, его можно удалить с помощью следующего запроса DELETE. Замените значения заполнителей собственными значениями.
{Endpoint}/language/authoring/analyze-text/projects/{projectName}?api-version={API-VERSION}
| Заполнитель | Значение | Пример |
|---|---|---|
{ENDPOINT} |
Конечная точка для проверки подлинности запроса API. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
Имя проекта. Это значение чувствительно к регистру. | myProject |
{API-VERSION} |
Версия вызываемого API. Значение, на которое ссылается, предназначено для последней версии, выпущенной. Дополнительные сведения см. в разделе"Жизненный цикл модели". | 2022-05-01 |
Заголовки
Используйте следующий заголовок для проверки подлинности запроса.
| Ключ | Значение |
|---|---|
| Ocp-Apim-Subscription-Key | Ключ к вашему ресурсу. Используется для проверки подлинности запросов API. |
После отправки запроса API вы получите ответ, указывающий 202 на успешность, что означает удаление проекта. Успешный вызов приведет к заголовку Operation-Location, который используется для проверки состояния задания.
Связанный контент
После создания модели извлечения сущностей можно использовать API среды выполнения для извлечения сущностей.
При создании собственных пользовательских проектов NER используйте наши статьи, чтобы узнать больше о тегах, обучении и использовании модели более подробно: