Примечание
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
Из этого руководства вы узнаете:
- Создание и настройка ресурсов Azure для использования модели DeepSeek-R1 в выводе модели ИИ Azure.
- Настройка развертывания модели.
- Как использовать DeepSeek-R1 с помощью Azure AI Inference SDK или REST API.
- Как использовать DeepSeek-R1 с помощью других пакетов SDK.
Предпосылки
Для работы с этой статьей необходимо иметь следующее.
- Подписка Azure. Если вы используете GitHub Models, вы можете улучшить свой опыт и одновременно создать подписку на Azure. Ознакомьтесь с материалом «Переход от моделей GitHub к моделям предсказания AI Azure», если вам это необходимо.
Модели причин
Модели причин могут достичь более высокого уровня производительности в таких доменах, как математика, программирование, наука, стратегия и логистика. Таким образом, эти модели создают выходные данные путем явного использования цепочки мысли для изучения всех возможных путей перед созданием ответа. Они проверяют свои ответы по мере их создания, что помогает им приходить к более точным и обоснованным выводам. Это означает, что моделям рассуждений может требоваться меньше контекста в подсказках для получения эффективных результатов.
Такой способ масштабирования производительности модели называется время вычислений вывода, поскольку он обменивает улучшение производительности на более высокую задержку и стоимость. Он отличается от других подходов, которые масштабируются за счёт времени вычислений, затраченного на обучение.
Затем модели причин создают два типа выходных данных:
- Результаты рассуждений
- Завершение выходных данных
Обе эти генерации считаются частью содержимого, генерируемого моделью, и, следовательно, учитываются при оценке лимитов токенов и затрат, связанных с моделью. Некоторые модели могут выводить содержание рассуждений, например, DeepSeek-R1. Некоторые другие, например o1, выводят только выходной фрагмент завершения.
Создание ресурсов
Вывод модели искусственного интеллекта Azure — это возможность в ресурсах Служб искусственного интеллекта Azure в Azure. Вы можете создать развертывания моделей под ресурсом для использования их прогнозов. Вы также можете подключить ресурс к Центрам ИИ Azure и проектам в Azure AI Foundry, чтобы создать интеллектуальные приложения при необходимости. На следующем рисунке показана архитектура высокого уровня.
Диаграмма, демонстрирующая высокоуровневую архитектуру ресурсов, созданных в обучающем материале.
Чтобы создать проект ИИ Azure, поддерживающий вывод модели для DeepSeek-R1, выполните следующие действия. Вы также можете создать ресурсы с помощью Azure CLI или инфраструктуры в качестве кода с помощью Bicep.
Перейдите на портал Azure AI Foundry и войдите в систему с помощью учетной записи.
На целевой странице выберите "Создать проект".
Подсказка
Вы используете службу Azure OpenAI? При подключении к порталу Azure AI Foundry с помощью ресурса службы Azure OpenAI в каталоге отображаются только модели Azure OpenAI. Чтобы просмотреть полный список моделей, включая DeepSeek-R1, используйте верхний раздел "Объявления" и найдите карточку с параметром "Изучить больше моделей".
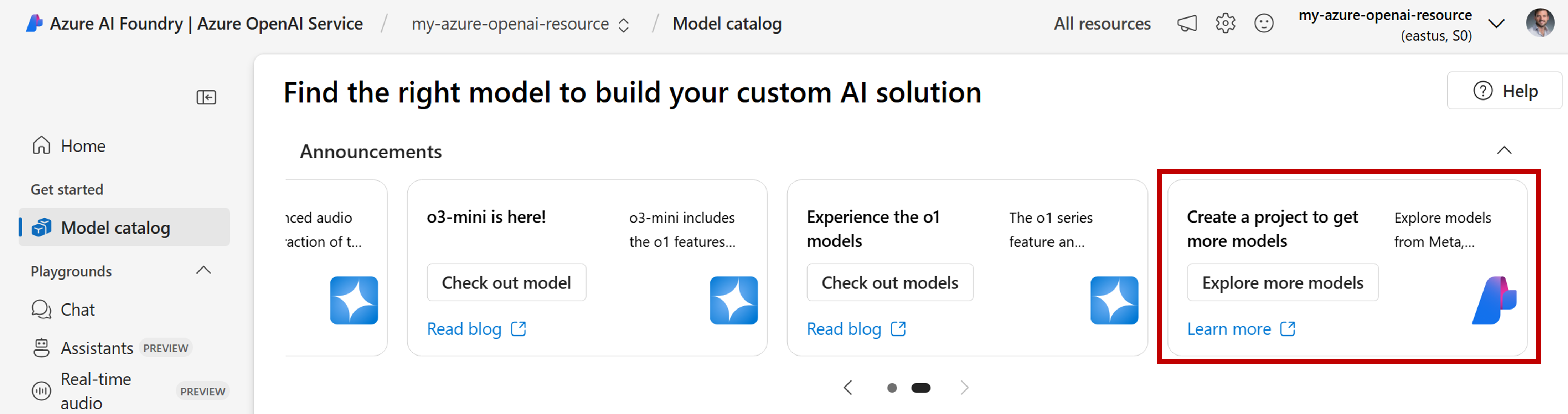
Новое окно отображается с полным списком моделей. Выберите DeepSeek-R1 из списка и выберите "Развернуть". Мастер просит создать новый проект.
Присвойте проекту имя, например my-project.
В этом руководстве мы создадим новый проект в новом хабе искусственного интеллекта, поэтому выберите Создать концентратор. Центры — это контейнеры для нескольких проектов и позволяют совместно использовать ресурсы во всех проектах.
Присвойте концентратору имя, например "my-hub" и нажмите кнопку "Далее".
Мастер обновляет сведения о созданных ресурсах. Выберите ресурсы Azure, которые нужно создать , чтобы просмотреть сведения.
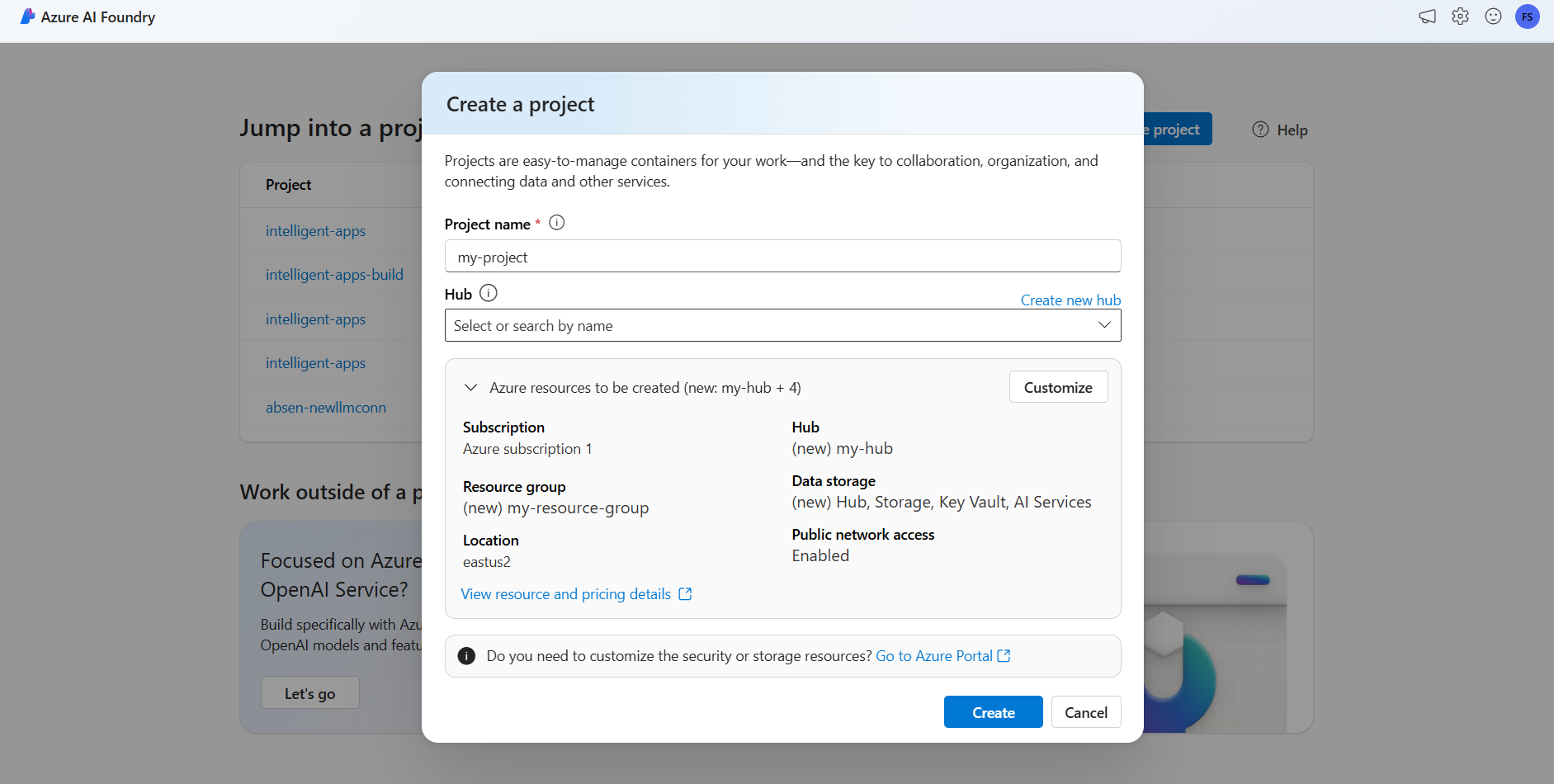
Вы увидите, что создаются следующие ресурсы:
Недвижимость Описание Группа ресурсов Основной контейнер для всех ресурсов в Azure. Это помогает организовать ресурсы для совместной работы. Также помогает получить оценку затрат, связанных со всем проектом. Местоположение Регион, в котором вы создаете ресурсы. Хаб Основной контейнер для проектов ИИ в Azure AI Foundry. Центры способствуют совместной работе и позволяют хранить сведения для проектов. Службы искусственного интеллекта Ресурс, обеспечивающий доступ к флагманским моделям в каталоге моделей ИИ Azure. В этом руководстве создается новая учетная запись, но ресурсы служб ИИ Azure можно совместно использовать в нескольких центрах и проектах. Центры используют подключение к ресурсу, чтобы иметь доступ к развертываниям моделей, которые там доступны. Чтобы узнать, как создать подключения между проектами и службами ИИ Azure для использования инференса модели ИИ Azure, можно прочитать Подключите ваш проект ИИ. Выберите Создать. Начинается процесс создания ресурсов.
После завершения проект будет готов к настройке.
Вывод модели искусственного интеллекта Azure — это функция предварительной версии, которая должна быть включена в Azure AI Foundry. В верхней панели навигации в правом углу выберите значок функций предварительного просмотра. Контекстная панель отображается справа от экрана.
Включите функцию Развертывание моделей в службе вывода моделей Azure AI.
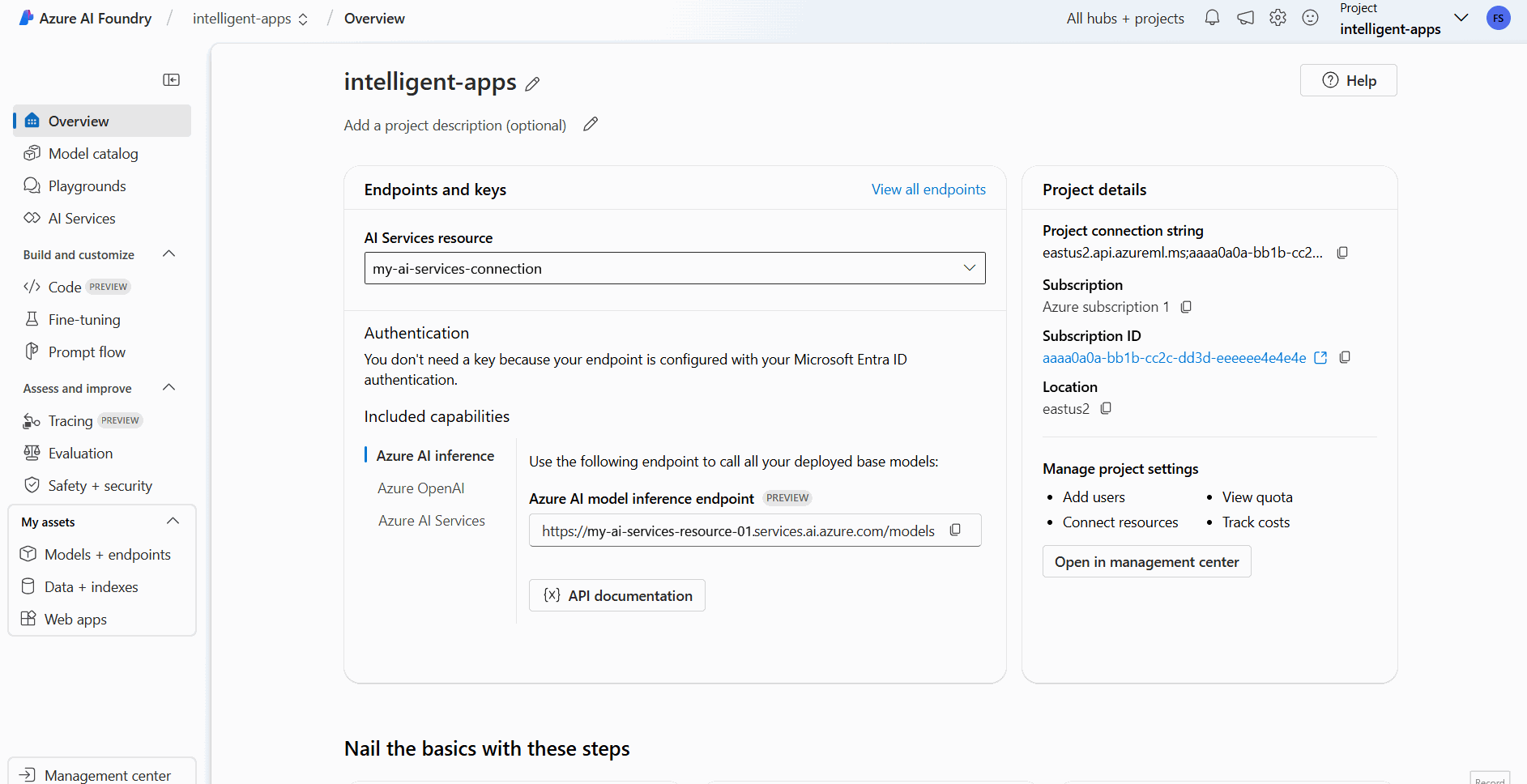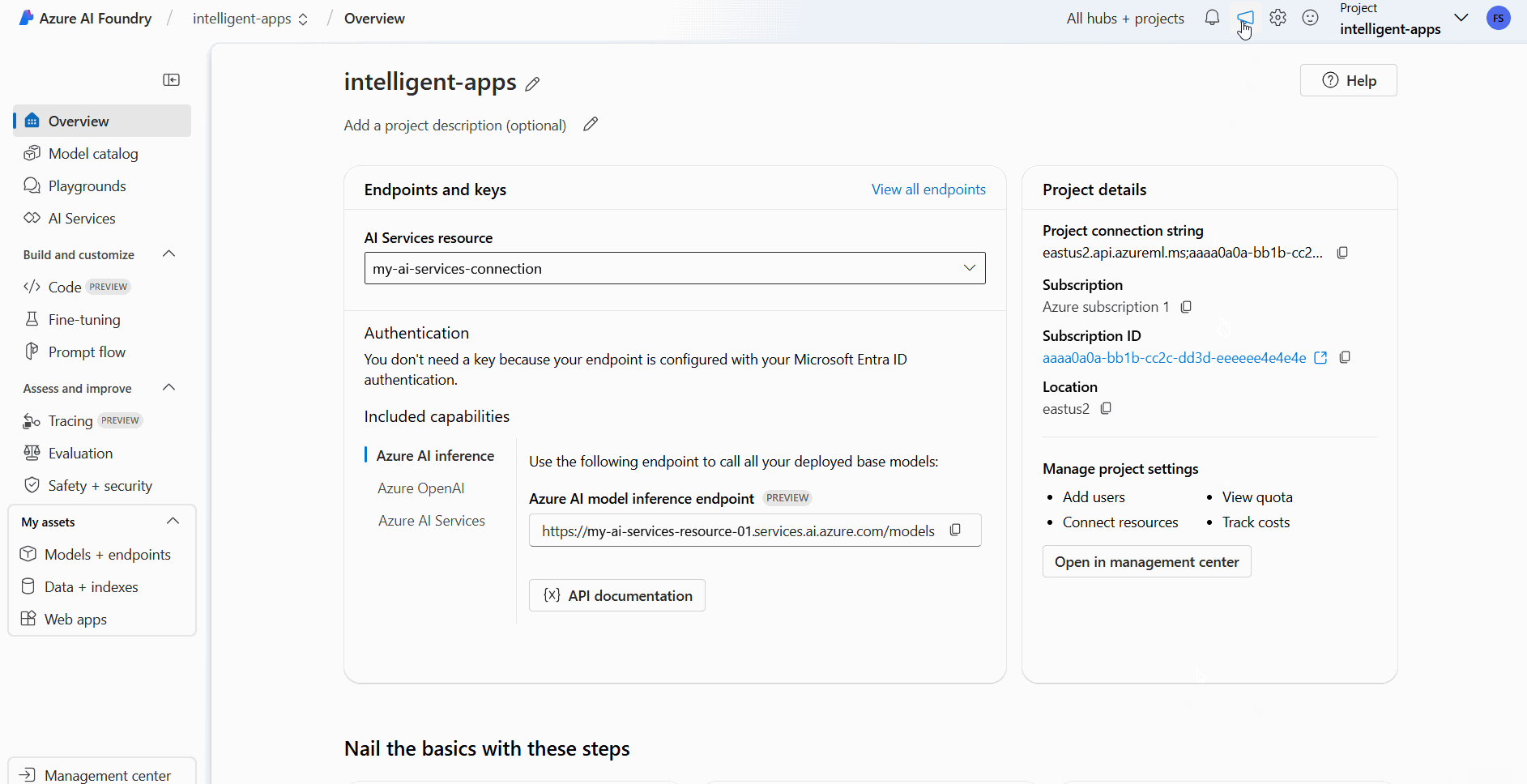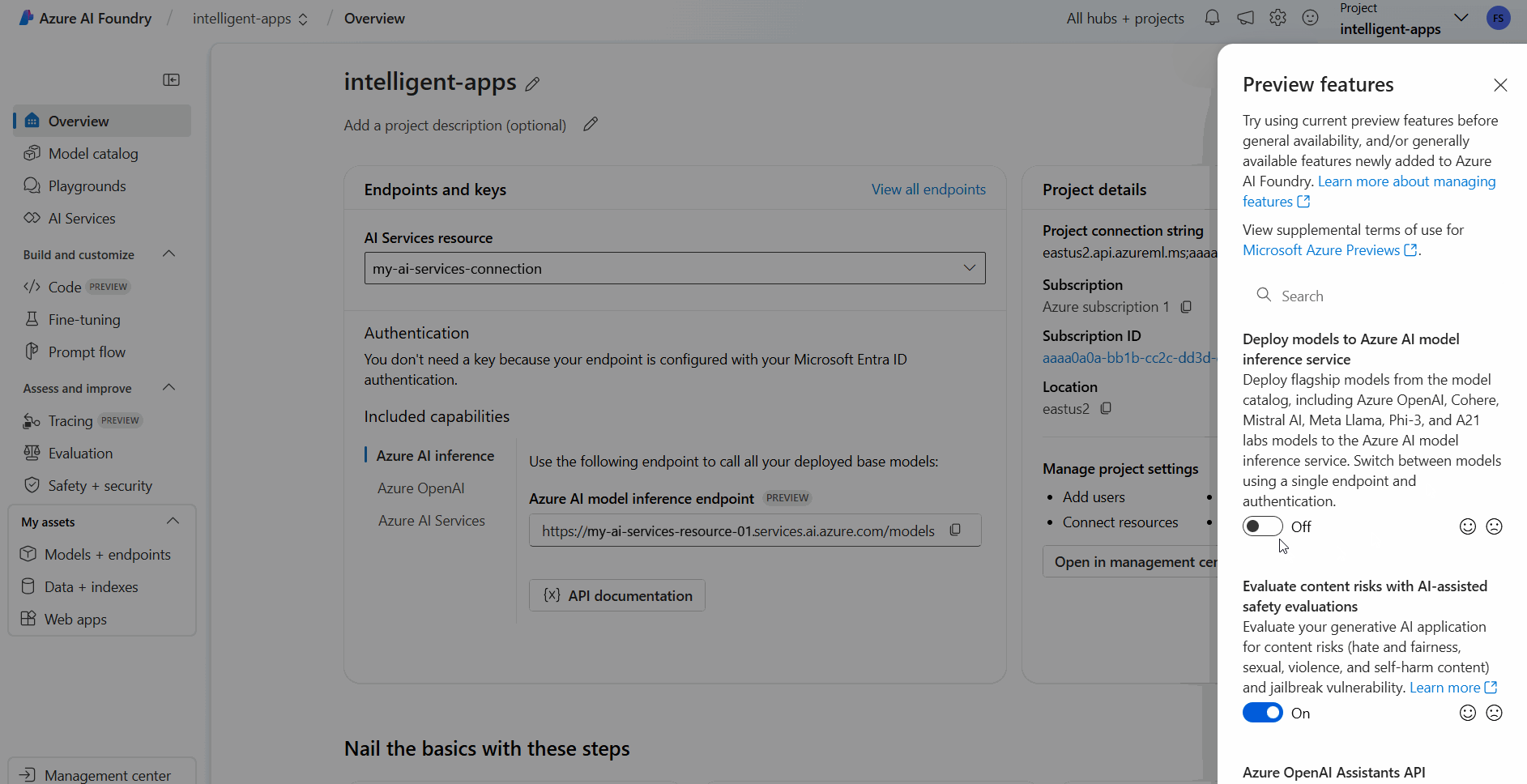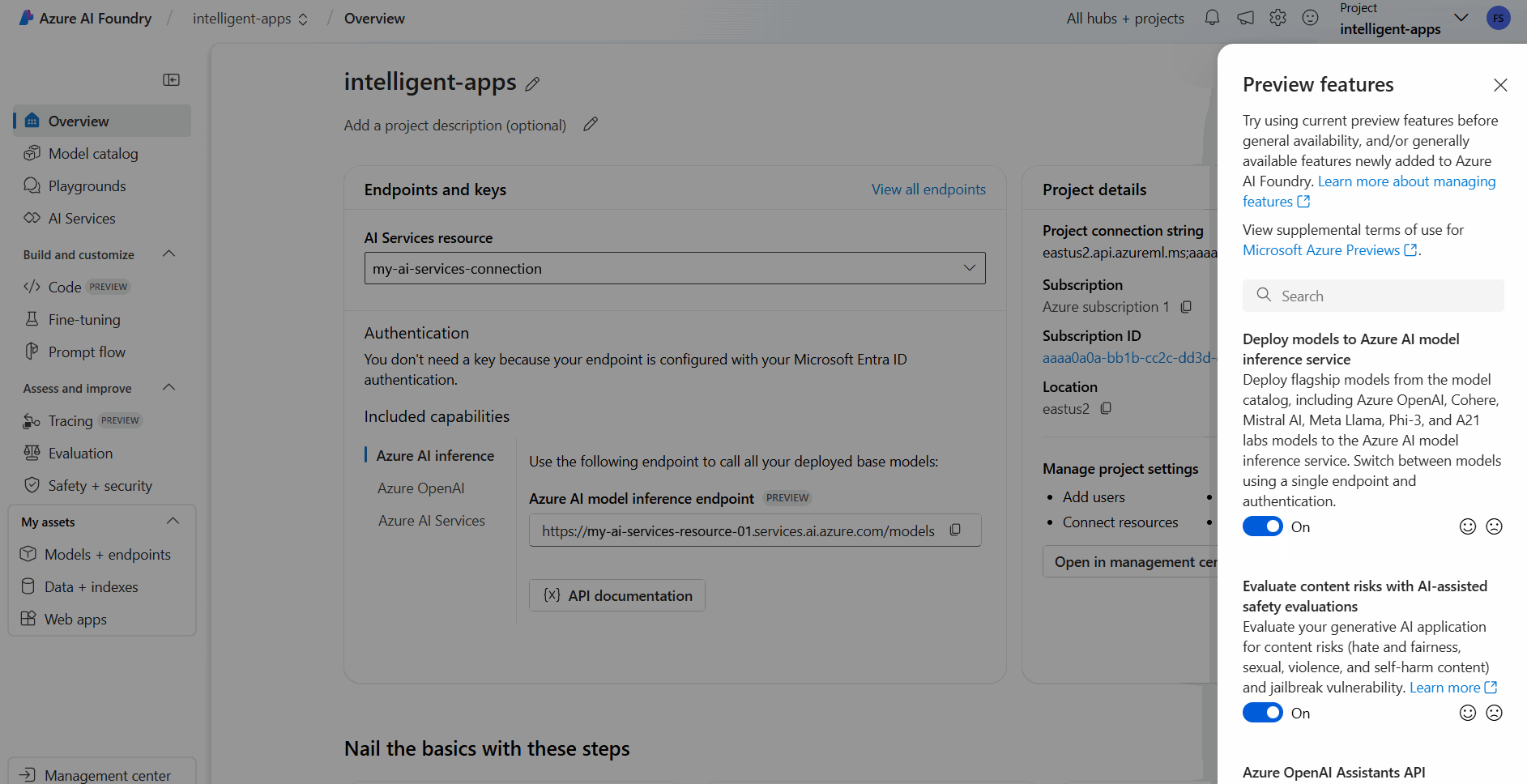
Закройте панель.



Добавьте развертывание модели DeepSeek-R1
Теперь создадим новое развертывание модели для DeepSeek-R1:
Перейдите в раздел каталога моделей на портале Azure AI Foundry и найдите модель DeepSeek-R1 .
Вы можете просмотреть сведения о модели в карточке модели.
Выберите Развернуть.
Мастер отображает условия и положения модели для DeepSeek-R1, которая предлагается как собственная услуга Microsoft. Вы можете просмотреть наши обязательства по обеспечению конфиденциальности и безопасности в соответствии с данными, конфиденциальностью и безопасностью.
Подсказка
Просмотрите сведения о ценах для модели, выбрав цены и условия.
Примите условия в этих случаях, выбрав Подписаться и развернуть.
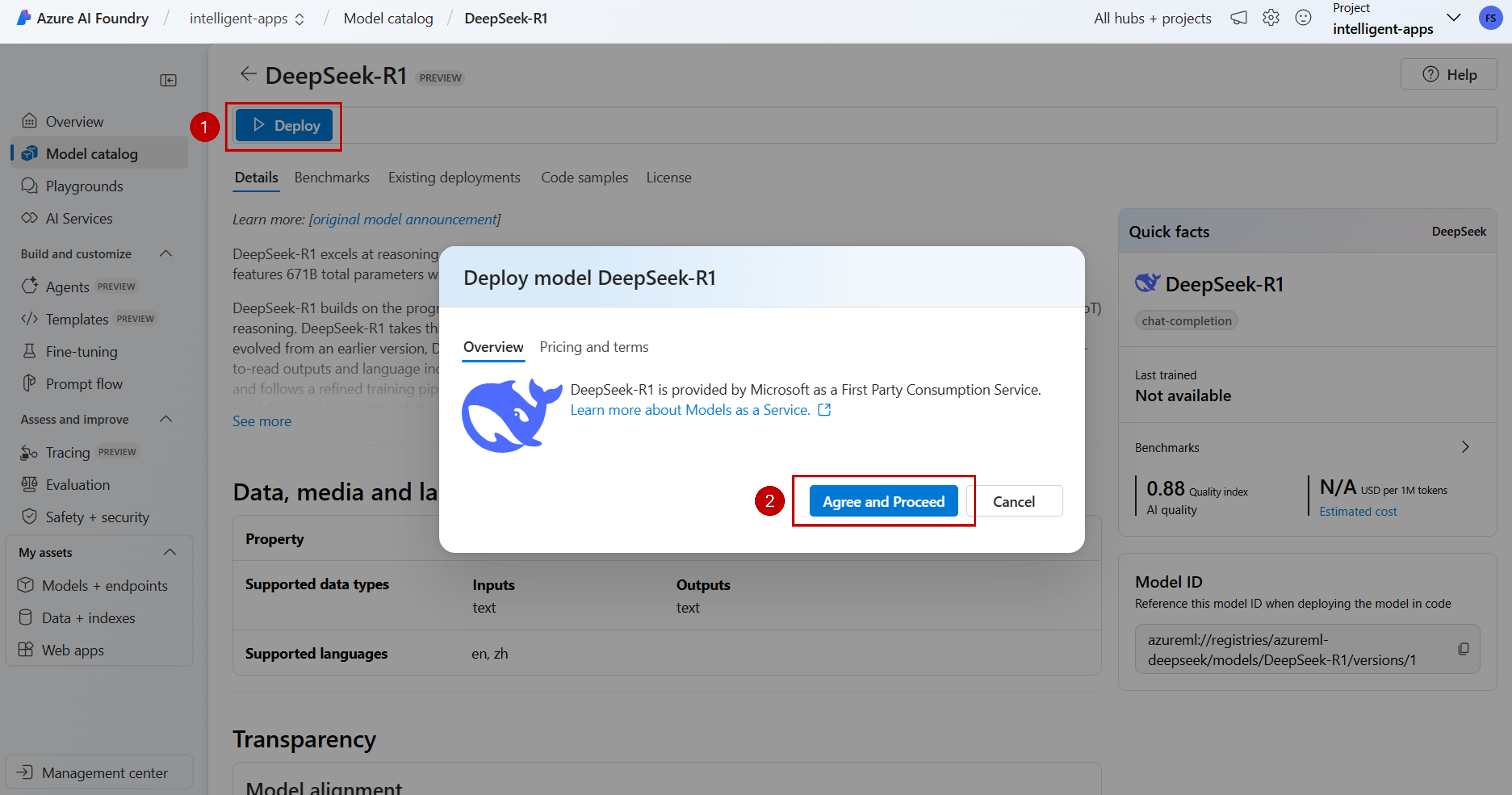
Вы можете настроить параметры развертывания в настоящее время. По умолчанию развертывание получает имя модели, которую вы развертываете. Имя развертывания используется в параметре
model, чтобы маршрутизировать запрос к данному развертыванию модели. Это позволяет также настроить определенные имена для моделей при присоединении определенных конфигураций.В зависимости от вашего проекта мы автоматически выбираем подключение к Службам искусственного интеллекта Azure. Используйте параметр "Настройка", чтобы изменить подключение в зависимости от ваших потребностей. в настоящее время DeepSeek-R1 предлагается в типе развертывания Global Standard , который обеспечивает более высокую пропускную способность и производительность.
Выберите Развернуть.
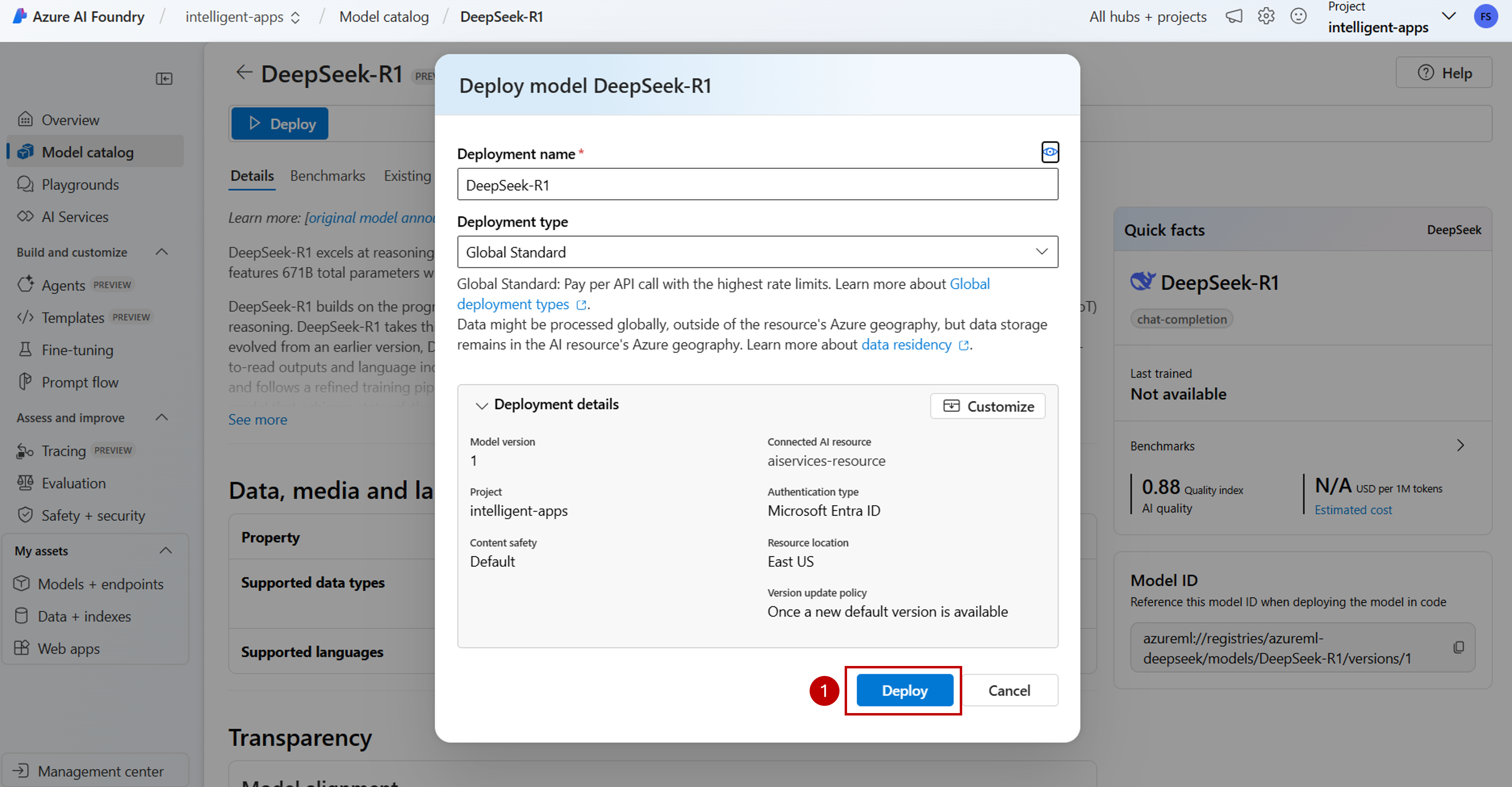
После завершения развертывания новая модель будет указана на странице и будет готова к использованию.


Использование модели на детской площадке
Вы можете приступить к работе с моделью на детской площадке, чтобы иметь представление о возможностях модели.
На странице сведений о развертывании выберите "Открыть в игровой площадке " в верхней строке.
В раскрывающемся списке развертывание автоматически выбрано созданное вами развертывание.
Настройте параметр запроса системы по мере необходимости. Модели рассуждения, как правило, не используют системные сообщения таким же образом, как это делают другие типы моделей.
Введите запрос и просмотрите выходные данные.
Кроме того, можно использовать просмотр кода, чтобы узнать, как получить доступ к развертыванию модели программным способом.

При создании запросов на создание моделей причин следует учитывать следующее:
- Используйте простые инструкции и избегайте использования методов цепочки мышления.
- Встроенные возможности рассуждений делают простые запросы нулевого снимка эффективными, чем более сложные методы.
- При предоставлении дополнительного контекста или документов, например в сценариях RAG, включая только наиболее релевантную информацию, может помочь предотвратить чрезмерное усложнение ответа модели.
- Модели причин могут поддерживать использование системных сообщений. Тем не менее, они не могут следовать им строго, как и другие неразумные модели.
- При создании многоэтапных приложений рассмотрите возможность добавления только окончательного ответа из модели, без содержания рассуждений, как описано в разделе "Содержание рассуждений".
Обратите внимание, что модели причин могут занять больше времени для создания ответов. Они используют длинные цепочки рассуждений, которые позволяют более глубоко и структурировано решать проблемы. Они также выполняют самопроверку, чтобы сверить свои собственные ответы и исправить свои собственные ошибки, показывая возникающие саморефлексивные поведение.
Использование модели в коде
Используйте конечную точку вывода модели ИИ Azure и учетные данные для подключения к модели:

Можно использовать пакет Azure AI Inference для выполнения модели в коде:
Установите пакет azure-ai-inference с помощью диспетчера пакетов, например pip:
pip install azure-ai-inference
Затем можно использовать пакет для работы с моделью. В следующем примере показано, как создать клиент для вызова завершений чата.
import os
from azure.ai.inference import ChatCompletionsClient
from azure.core.credentials import AzureKeyCredential
client = ChatCompletionsClient(
endpoint="https://<resource>.services.ai.azure.com/models",
credential=AzureKeyCredential(os.environ["AZURE_INFERENCE_CREDENTIAL"]),
)
Ознакомьтесь с нашими примерами и ознакомьтесь со справочной документацией по API, чтобы приступить к работе.
from azure.ai.inference.models import SystemMessage, UserMessage
response = client.complete(
messages=[
UserMessage(content="How many languages are in the world?"),
],
model="DeepSeek-R1"
)
print(response.choices[0].message.content)
Рассуждение может создавать более длинные ответы и использовать большее количество токенов. Вы увидите ограничения скорости , применяемые к моделям DeepSeek-R1. Рассмотрите возможность применения стратегии повторных попыток для обработки ограничений скорости. Вы также можете запросить увеличение ограничений по умолчанию.
Содержимое рассуждений
Некоторые модели рассуждения, такие как DeepSeek-R1, формируют завершения и включают в себя обоснование. Причины, связанные с завершением, включаются в содержимое ответа в тегах <think> и </think>. Модель может выбрать, в каких сценариях создается содержимое рассуждений. В следующем примере показано, как это сделать в Python:
import re
match = re.match(r"<think>(.*?)</think>(.*)", response.choices[0].message.content, re.DOTALL)
print("Response:", )
if match:
print("\tThinking:", match.group(1))
print("\tAnswer:", match.group(2))
else:
print("\tAnswer:", response.choices[0].message.content)
print("Model:", response.model)
print("Usage:")
print("\tPrompt tokens:", response.usage.prompt_tokens)
print("\tTotal tokens:", response.usage.total_tokens)
print("\tCompletion tokens:", response.usage.completion_tokens)
Thinking: Okay, the user is asking how many languages exist in the world. I need to provide a clear and accurate answer. Let's start by recalling the general consensus from linguistic sources. I remember that the number often cited is around 7,000, but maybe I should check some reputable organizations.\n\nEthnologue is a well-known resource for language data, and I think they list about 7,000 languages. But wait, do they update their numbers? It might be around 7,100 or so. Also, the exact count can vary because some sources might categorize dialects differently or have more recent data. \n\nAnother thing to consider is language endangerment. Many languages are endangered, with some having only a few speakers left. Organizations like UNESCO track endangered languages, so mentioning that adds context. Also, the distribution isn't even. Some countries have hundreds of languages, like Papua New Guinea with over 800, while others have just a few. \n\nA user might also wonder why the exact number is hard to pin down. It's because the distinction between a language and a dialect can be political or cultural. For example, Mandarin and Cantonese are considered dialects of Chinese by some, but they're mutually unintelligible, so others classify them as separate languages. Also, some regions are under-researched, making it hard to document all languages. \n\nI should also touch on language families. The 7,000 languages are grouped into families like Indo-European, Sino-Tibetan, Niger-Congo, etc. Maybe mention a few of the largest families. But wait, the question is just about the count, not the families. Still, it's good to provide a bit more context. \n\nI need to make sure the information is up-to-date. Let me think – recent estimates still hover around 7,000. However, languages are dying out rapidly, so the number decreases over time. Including that note about endangerment and language extinction rates could be helpful. For instance, it's often stated that a language dies every few weeks. \n\nAnother point is sign languages. Does the count include them? Ethnologue includes some, but not all sources might. If the user is including sign languages, that adds more to the count, but I think the 7,000 figure typically refers to spoken languages. For thoroughness, maybe mention that there are also over 300 sign languages. \n\nSummarizing, the answer should state around 7,000, mention Ethnologue's figure, explain why the exact number varies, touch on endangerment, and possibly note sign languages as a separate category. Also, a brief mention of Papua New Guinea as the most linguistically diverse country. \n\nWait, let me verify Ethnologue's current number. As of their latest edition (25th, 2022), they list 7,168 living languages. But I should check if that's the case. Some sources might round to 7,000. Also, SIL International publishes Ethnologue, so citing them as reference makes sense. \n\nOther sources, like Glottolog, might have a different count because they use different criteria. Glottolog might list around 7,000 as well, but exact numbers vary. It's important to highlight that the count isn't exact because of differing definitions and ongoing research. \n\nIn conclusion, the approximate number is 7,000, with Ethnologue being a key source, considerations of endangerment, and the challenges in counting due to dialect vs. language distinctions. I should make sure the answer is clear, acknowledges the variability, and provides key points succinctly.
Answer: The exact number of languages in the world is challenging to determine due to differences in definitions (e.g., distinguishing languages from dialects) and ongoing documentation efforts. However, widely cited estimates suggest there are approximately **7,000 languages** globally.
Model: DeepSeek-R1
Usage:
Prompt tokens: 11
Total tokens: 897
Completion tokens: 886
Параметры
Как правило, модели причин не поддерживают следующие параметры, которые можно найти в моделях завершения чата:
- Температура
- Штраф за присутствие
- Штраф за повторение
- Параметр
top_p