Примечание
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
Внимание
Элементы, обозначенные в этой статье как (предварительная версия), сейчас предлагаются в общедоступной предварительной версии. Эта предварительная версия предоставляется без соглашения об уровне обслуживания, и мы не рекомендуем ее для рабочих нагрузок. Некоторые функции могут не поддерживаться или их возможности могут быть ограничены. Дополнительные сведения см. в статье Дополнительные условия использования Предварительных версий Microsoft Azure.
В этой статье объясняется, как использовать возможности создания аргументов для моделей завершения чата, развернутых в модели искусственного интеллекта Azure в службах ИИ Azure.
Модели причин
Модели причин могут достичь более высокого уровня производительности в таких доменах, как математика, программирование, наука, стратегия и логистика. Таким образом, эти модели создают выходные данные путем явного использования цепочки мысли для изучения всех возможных путей перед созданием ответа. Они проверяют свои ответы по мере их составления, что помогает им прийти к более точным и правильным выводам. Это означает, что модели рассуждений могут требовать меньше контекста в подсказках для получения эффективных результатов.
Такой способ масштабирования производительности модели называется временем вычисления при выводе, так как он обменивает производительность на более высокую задержку и затраты. Он отличается от других подходов, которые масштабируются за счет времени вычислений для тренировки.
Затем модели причин создают два типа выходных данных:
- Обоснование выводов
- Завершение выходных данных
Оба этих завершения учитываются в отношении содержимого, созданного моделью, и, следовательно, к лимитам токенов и затратам, связанным с моделью. Некоторые модели могут выводить содержание рассуждений, например DeepSeek-R1. Некоторые другие, например o1, выводят только выходной фрагмент завершения.
Предварительные требования
Для работы с этим учебником необходимы указанные ниже компоненты.
Подписка Azure. Если вы используете GitHub Models, вы можете улучшить свой опыт и создать подписку Azure в процессе. Прочитайте обновление от моделей GitHub к использованию вывода ИИ Azure, если это ваш случай.
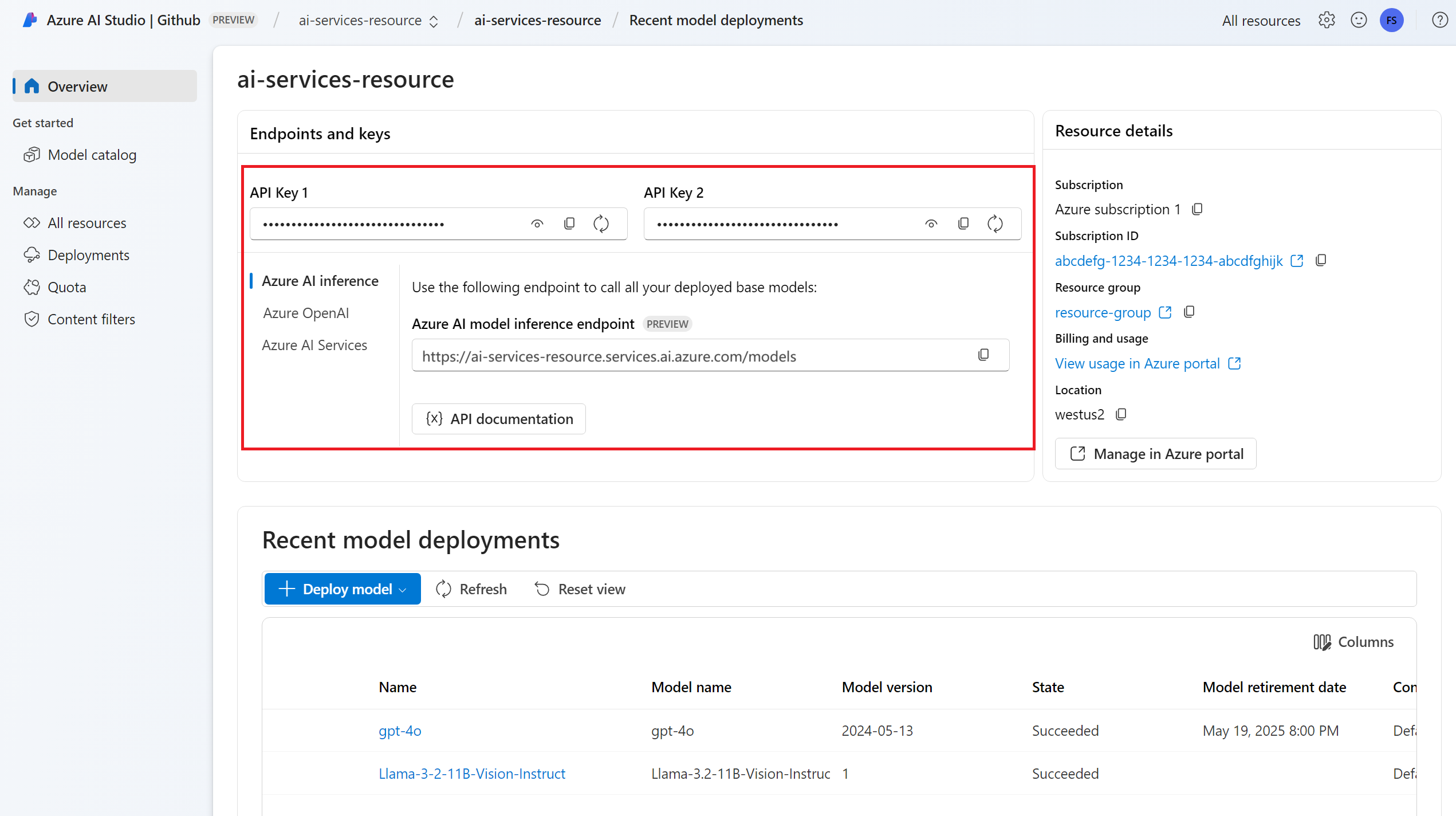
Ресурс служб ИИ Azure. Дополнительные сведения см. в статье "Создание ресурса Служб искусственного интеллекта Azure".
URL-адрес конечной точки и ключ.

Установите пакет вывода искусственного интеллекта Azure для Python с помощью следующей команды:
pip install -U azure-ai-inference
Модель с возможностями рассуждения для развертывания. Если у вас его нет, прочитайте "Добавление и настройка моделей в службах AI Azure", чтобы добавить модель рассуждений.
- В этом примере используется
DeepSeek-R1.
- В этом примере используется
Использование возможностей логического мышления в чате
Сначала создайте клиент для использования модели. В следующем коде используется URL-адрес конечной точки и ключ, хранящиеся в переменных среды.
import os
from azure.ai.inference import ChatCompletionsClient
from azure.core.credentials import AzureKeyCredential
client = ChatCompletionsClient(
endpoint="https://<resource>.services.ai.azure.com/models",
credential=AzureKeyCredential(os.environ["AZURE_INFERENCE_CREDENTIAL"]),
model="deepseek-r1"
)
Совет
Убедитесь, что вы развернули модель в ресурсе Служб искусственного интеллекта Azure с помощью API вывода модели Azure.
Deepseek-R1 также доступен в качестве конечных точек БЕССерверного API. Однако эти конечные точки не принимают параметр model , как описано в этом руководстве. Вы можете убедиться в этом, перейдя на портал Azure AI Foundry> в раздел "Модели + конечные точки" и убедиться, что модель указана в разделе Службы Azure AI.
Если вы настроили ресурс для поддержки Microsoft Entra ID, можно использовать следующий фрагмент кода для создания клиента.
import os
from azure.ai.inference import ChatCompletionsClient
from azure.identity import DefaultAzureCredential
client = ChatCompletionsClient(
endpoint="https://<resource>.services.ai.azure.com/models",
credential=DefaultAzureCredential(),
credential_scopes=["https://cognitiveservices.azure.com/.default"],
model="deepseek-r1"
)
Создание запроса на завершение чата
В следующем примере показано, как создать базовый запрос чата для модели.
from azure.ai.inference.models import SystemMessage, UserMessage
response = client.complete(
messages=[
UserMessage(content="How many languages are in the world?"),
],
)
При создании запросов на создание моделей причин следует учитывать следующее:
- Используйте простые инструкции и избегайте использования методов цепочки мышления.
- Встроенные возможности рассуждения делают простые запросы нулевого снимка столь же эффективными, как и более сложные методы.
- При предоставлении дополнительного контекста или документов, например в сценариях RAG, включая только наиболее релевантную информацию, может помочь предотвратить чрезмерное усложнение ответа модели.
- Модели причин могут поддерживать использование системных сообщений. Тем не менее, они не могут следовать им строго, как и другие неразумные модели.
- При создании многоэтапных приложений рассмотрите возможность добавления только окончательного ответа из модели, без содержимого рассуждений, как объясняется в разделе „Содержимое рассуждений“.
Обратите внимание, что модели причин могут занять больше времени для создания ответов. Они используют длинные цепочки рассуждений, которые позволяют более глубоко и структурировано решать проблемы. Они также выполняют самопроверку, чтобы сверить свои собственные ответы и исправить свои собственные ошибки, показывая возникающие саморефлексивные поведение.
Ответ выглядит следующим образом, где можно просмотреть статистику использования модели:
print("Response:", response.choices[0].message.content)
print("Model:", response.model)
print("Usage:")
print("\tPrompt tokens:", response.usage.prompt_tokens)
print("\tTotal tokens:", response.usage.total_tokens)
print("\tCompletion tokens:", response.usage.completion_tokens)
Response: <think>Okay, the user is asking how many languages exist in the world. I need to provide a clear and accurate answer...</think>As of now, it's estimated that there are about 7,000 languages spoken around the world. However, this number can vary as some languages become extinct and new ones develop. It's also important to note that the number of speakers can greatly vary between languages, with some having millions of speakers and others only a few hundred.
Model: deepseek-r1
Usage:
Prompt tokens: 11
Total tokens: 897
Completion tokens: 886
Содержание рассуждений
Некоторые модели рассуждений, такие как DeepSeek-R1, создают завершения и включают в себя рассуждения, лежащие в основе. Причины, связанные с завершением, включаются в содержимое ответа в тегах <think> и </think>. Модель может выбрать, в каких сценариях генерировать рациональное содержимое. Вы можете извлечь содержимое причин из ответа, чтобы понять процесс мысли модели следующим образом:
import re
match = re.match(r"<think>(.*?)</think>(.*)", response.choices[0].message.content, re.DOTALL)
print("Response:", )
if match:
print("\tThinking:", match.group(1))
print("\tAnswer:", match.group(2))
else:
print("\tAnswer:", response.choices[0].message.content)
print("Model:", response.model)
print("Usage:")
print("\tPrompt tokens:", response.usage.prompt_tokens)
print("\tTotal tokens:", response.usage.total_tokens)
print("\tCompletion tokens:", response.usage.completion_tokens)
Thinking: Okay, the user is asking how many languages exist in the world. I need to provide a clear and accurate answer. Let's start by recalling the general consensus from linguistic sources. I remember that the number often cited is around 7,000, but maybe I should check some reputable organizations.\n\nEthnologue is a well-known resource for language data, and I think they list about 7,000 languages. But wait, do they update their numbers? It might be around 7,100 or so. Also, the exact count can vary because some sources might categorize dialects differently or have more recent data. \n\nAnother thing to consider is language endangerment. Many languages are endangered, with some having only a few speakers left. Organizations like UNESCO track endangered languages, so mentioning that adds context. Also, the distribution isn't even. Some countries have hundreds of languages, like Papua New Guinea with over 800, while others have just a few. \n\nA user might also wonder why the exact number is hard to pin down. It's because the distinction between a language and a dialect can be political or cultural. For example, Mandarin and Cantonese are considered dialects of Chinese by some, but they're mutually unintelligible, so others classify them as separate languages. Also, some regions are under-researched, making it hard to document all languages. \n\nI should also touch on language families. The 7,000 languages are grouped into families like Indo-European, Sino-Tibetan, Niger-Congo, etc. Maybe mention a few of the largest families. But wait, the question is just about the count, not the families. Still, it's good to provide a bit more context. \n\nI need to make sure the information is up-to-date. Let me think – recent estimates still hover around 7,000. However, languages are dying out rapidly, so the number decreases over time. Including that note about endangerment and language extinction rates could be helpful. For instance, it's often stated that a language dies every few weeks. \n\nAnother point is sign languages. Does the count include them? Ethnologue includes some, but not all sources might. If the user is including sign languages, that adds more to the count, but I think the 7,000 figure typically refers to spoken languages. For thoroughness, maybe mention that there are also over 300 sign languages. \n\nSummarizing, the answer should state around 7,000, mention Ethnologue's figure, explain why the exact number varies, touch on endangerment, and possibly note sign languages as a separate category. Also, a brief mention of Papua New Guinea as the most linguistically diverse country. \n\nWait, let me verify Ethnologue's current number. As of their latest edition (25th, 2022), they list 7,168 living languages. But I should check if that's the case. Some sources might round to 7,000. Also, SIL International publishes Ethnologue, so citing them as reference makes sense. \n\nOther sources, like Glottolog, might have a different count because they use different criteria. Glottolog might list around 7,000 as well, but exact numbers vary. It's important to highlight that the count isn't exact because of differing definitions and ongoing research. \n\nIn conclusion, the approximate number is 7,000, with Ethnologue being a key source, considerations of endangerment, and the challenges in counting due to dialect vs. language distinctions. I should make sure the answer is clear, acknowledges the variability, and provides key points succinctly.
Answer: The exact number of languages in the world is challenging to determine due to differences in definitions (e.g., distinguishing languages from dialects) and ongoing documentation efforts. However, widely cited estimates suggest there are approximately **7,000 languages** globally.
Model: DeepSeek-R1
Usage:
Prompt tokens: 11
Total tokens: 897
Completion tokens: 886
При ведении многоэтапных бесед полезно избегать отправки содержимого размышлений в истории чата, поскольку размышления обычно включают длинные объяснения.
Стриминг контента
По умолчанию API завершения возвращает все созданное содержимое в одном ответе. Если вы создаёте длинные завершения, ожидание ответа может занять много времени.
Вы можете транслировать содержимое, чтобы получать его в режиме реального времени. Потоковая передача содержимого позволяет начать обработку завершения по мере того, как содержимое становится доступным. Этот режим возвращает объект, который передает ответ в виде серверных событий, отправляемых только с данными. Извлекайте фрагменты из дельта-поля, а не из поля сообщения.
Чтобы выполнить потоковую передачу завершения, задайте stream=True при вызове модели.
result = client.complete(
model="deepseek-r1",
messages=[
UserMessage(content="How many languages are in the world?"),
],
max_tokens=2048,
stream=True,
)
Чтобы визуализировать выходные данные, определите вспомогательную функцию для печати потока. В следующем примере реализуется маршрутизация, которая передает только ответ без содержимого причин:
def print_stream(result):
"""
Prints the chat completion with streaming.
"""
is_thinking = False
for event in completion:
if event.choices:
content = event.choices[0].delta.content
if content == "<think>":
is_thinking = True
print("🧠 Thinking...", end="", flush=True)
elif content == "</think>":
is_thinking = False
print("🛑\n\n")
elif content:
print(content, end="", flush=True)
Вы можете визуализировать, как потоковая передача создает содержимое:
print_stream(result)
Параметры
Как правило, модели причин не поддерживают следующие параметры, которые можно найти в моделях завершения чата:
- Температура
- Штраф за присутствие
- Штраф за повторение
- Параметр
top_p
Некоторые модели поддерживают использование средств или структурированных выходных данных (включая схемы JSON). Ознакомьтесь со страницей сведений о моделях , чтобы понять поддержку каждой модели.
Применение безопасности содержимого
API вывода модели ИИ Azure поддерживает безопасность содержимого ИИ Azure. При использовании развертываний с включенной безопасностью содержимого искусственного интеллекта Azure входные и выходные данные проходят через ансамбль моделей классификации, направленных на обнаружение и предотвращение вывода вредного содержимого. Система фильтрации содержимого обнаруживает и принимает меры по определенным категориям потенциально вредного содержимого как в запросах ввода, так и в завершении выходных данных.
В следующем примере показано, как обрабатывать события, когда модель обнаруживает вредное содержимое во входном запросе и включена безопасность содержимого.
from azure.ai.inference.models import AssistantMessage, UserMessage
try:
response = client.complete(
model="deepseek-r1",
messages=[
UserMessage(content="Chopping tomatoes and cutting them into cubes or wedges are great ways to practice your knife skills."),
],
)
print(response.choices[0].message.content)
except HttpResponseError as ex:
if ex.status_code == 400:
response = ex.response.json()
if isinstance(response, dict) and "error" in response:
print(f"Your request triggered an {response['error']['code']} error:\n\t {response['error']['message']}")
else:
raise
raise
Совет
Дополнительные сведения о настройке и управлении параметрами безопасности содержимого ИИ Azure см. в документации по безопасности содержимого ИИ Azure.
Внимание
Элементы, обозначенные в этой статье как (предварительная версия), сейчас предлагаются в общедоступной предварительной версии. Эта предварительная версия предоставляется без соглашения об уровне обслуживания, и мы не рекомендуем ее для рабочих нагрузок. Некоторые функции могут не поддерживаться или их возможности могут быть ограничены. Дополнительные сведения см. в статье Дополнительные условия использования Предварительных версий Microsoft Azure.
В этой статье объясняется, как использовать возможности рассуждения моделей завершения чата, развернутых для выполнения выводов моделей в службах ИИ Azure.
Модели причин
Модели причин могут достичь более высокого уровня производительности в таких доменах, как математика, программирование, наука, стратегия и логистика. Таким образом, эти модели создают выходные данные путем явного использования цепочки мысли для изучения всех возможных путей перед созданием ответа. Они проверяют свои ответы в процессе их создания, что помогает им приходить к более точным выводам. Это означает, что модели рассуждений могут требовать меньше контекста при формировании запроса для достижения эффективных результатов.
Такой способ масштабирования производительности модели называется временем вычислений для вывода, так как он обменивает производительность на более высокую задержку и затраты. Он отличается от других подходов, которые масштабируются за счет времени вычислений при обучении.
Затем модели причин создают два типа выходных данных:
- Завершение рассуждений
- Завершение выходных данных
Оба этих завершения учитываются при расчете содержимого, созданного моделью, и, следовательно, токенов и связанных с моделью затрат. Некоторые модели могут выводить содержимое рассуждений, например DeepSeek-R1. Некоторые другие, например o1, выводит только выходной фрагмент завершения.
Предварительные условия
Для работы с этим учебником необходимы указанные ниже компоненты.
Подписка Azure. Если вы используете GitHub Models, вы можете улучшить свой опыт и создать подписку Azure в рамках этого процесса. Прочитайте об обновлении с моделей GitHub на модели ИИ Azure, если это ваш случай.
Ресурс служб ИИ Azure. Дополнительные сведения см. в статье "Создание ресурса Служб искусственного интеллекта Azure".
URL-адрес конечной точки и ключ.
Установите библиотеку вывода Azure для JavaScript с помощью следующей команды:
npm install @azure-rest/ai-inference npm install @azure/core-auth npm install @azure/identityЕсли вы используете Node.js, вы можете настроить зависимости в package.json:
package.json
{ "name": "main_app", "version": "1.0.0", "description": "", "main": "app.js", "type": "module", "dependencies": { "@azure-rest/ai-inference": "1.0.0-beta.6", "@azure/core-auth": "1.9.0", "@azure/core-sse": "2.2.0", "@azure/identity": "4.8.0" } }Импортируйте следующее:
import ModelClient from "@azure-rest/ai-inference"; import { isUnexpected } from "@azure-rest/ai-inference"; import { createSseStream } from "@azure/core-sse"; import { AzureKeyCredential } from "@azure/core-auth"; import { DefaultAzureCredential } from "@azure/identity";
Модель с возможностями рассуждений и развертыванием. Если у вас нет, прочитайте "Добавление и настройка моделей в службах Azure AI", чтобы добавить модель рассуждений.
- В этом примере используется
DeepSeek-R1.
- В этом примере используется
Использование возможностей рассуждения в чате
Сначала создайте клиент для использования модели. В следующем коде используется URL-адрес конечной точки и ключ, хранящиеся в переменных среды.
const client = ModelClient(
"https://<resource>.services.ai.azure.com/models",
new AzureKeyCredential(process.env.AZURE_INFERENCE_CREDENTIAL)
);
Если вы настроили ресурс с поддержкой идентификатора Microsoft Entra, можно использовать следующий фрагмент кода для создания клиента.
const clientOptions = { credentials: { "https://cognitiveservices.azure.com" } };
const client = ModelClient(
"https://<resource>.services.ai.azure.com/models",
new DefaultAzureCredential()
clientOptions,
);
Создание запроса на завершение чата
В следующем примере показано, как создать базовый запрос чата для модели.
var messages = [
{ role: "user", content: "How many languages are in the world?" },
];
var response = await client.path("/chat/completions").post({
body: {
model: "DeepSeek-R1",
messages: messages,
}
});
При создании запросов на создание моделей причин следует учитывать следующее:
- Используйте простые инструкции и избегайте использования методов цепочки мышления.
- Встроенные возможности рассуждений делают простые запросы нулевого снимка эффективными, чем более сложные методы.
- При предоставлении дополнительного контекста или документов, например в сценариях RAG, включая только наиболее релевантную информацию, может помочь предотвратить чрезмерное усложнение ответа модели.
- Модели причин могут поддерживать использование системных сообщений. Тем не менее, они не могут следовать им строго, как и другие неразумные модели.
- При создании многоэтапных приложений рассмотрите возможность добавления только окончательного ответа из модели, без объяснительного содержания, как описано в разделе «Объяснительное содержание».
Обратите внимание, что модели причин могут занять больше времени для создания ответов. Они используют длинные цепочки рассуждений, которые позволяют более глубоко и структурировано решать проблемы. Они также выполняют самопроверку, чтобы сверить свои собственные ответы и исправить свои собственные ошибки, показывая возникающие саморефлексивные поведение.
Ответ выглядит следующим образом, где можно просмотреть статистику использования модели:
if (isUnexpected(response)) {
throw response.body.error;
}
console.log("Response: ", response.body.choices[0].message.content);
console.log("Model: ", response.body.model);
console.log("Usage:");
console.log("\tPrompt tokens:", response.body.usage.prompt_tokens);
console.log("\tTotal tokens:", response.body.usage.total_tokens);
console.log("\tCompletion tokens:", response.body.usage.completion_tokens);
Response: <think>Okay, the user is asking how many languages exist in the world. I need to provide a clear and accurate answer...</think>As of now, it's estimated that there are about 7,000 languages spoken around the world. However, this number can vary as some languages become extinct and new ones develop. It's also important to note that the number of speakers can greatly vary between languages, with some having millions of speakers and others only a few hundred.
Model: deepseek-r1
Usage:
Prompt tokens: 11
Total tokens: 897
Completion tokens: 886
Аргументация
Некоторые модели причин, такие как DeepSeek-R1, создают завершения и включают в себя причины, лежащие в основе. Причины, связанные с завершением, включаются в содержимое ответа в тегах <think> и </think>. Модель может выбрать, для каких сценариев генерировать содержимое рассуждений. Вы можете извлечь содержимое причин из ответа, чтобы понять процесс мысли модели следующим образом:
var content = response.body.choices[0].message.content
var match = content.match(/<think>(.*?)<\/think>(.*)/s);
console.log("Response:");
if (match) {
console.log("\tThinking:", match[1]);
console.log("\Answer:", match[2]);
}
else {
console.log("Response:", content);
}
console.log("Model: ", response.body.model);
console.log("Usage:");
console.log("\tPrompt tokens:", response.body.usage.prompt_tokens);
console.log("\tTotal tokens:", response.body.usage.total_tokens);
console.log("\tCompletion tokens:", response.body.usage.completion_tokens);
Thinking: Okay, the user is asking how many languages exist in the world. I need to provide a clear and accurate answer. Let's start by recalling the general consensus from linguistic sources. I remember that the number often cited is around 7,000, but maybe I should check some reputable organizations.\n\nEthnologue is a well-known resource for language data, and I think they list about 7,000 languages. But wait, do they update their numbers? It might be around 7,100 or so. Also, the exact count can vary because some sources might categorize dialects differently or have more recent data. \n\nAnother thing to consider is language endangerment. Many languages are endangered, with some having only a few speakers left. Organizations like UNESCO track endangered languages, so mentioning that adds context. Also, the distribution isn't even. Some countries have hundreds of languages, like Papua New Guinea with over 800, while others have just a few. \n\nA user might also wonder why the exact number is hard to pin down. It's because the distinction between a language and a dialect can be political or cultural. For example, Mandarin and Cantonese are considered dialects of Chinese by some, but they're mutually unintelligible, so others classify them as separate languages. Also, some regions are under-researched, making it hard to document all languages. \n\nI should also touch on language families. The 7,000 languages are grouped into families like Indo-European, Sino-Tibetan, Niger-Congo, etc. Maybe mention a few of the largest families. But wait, the question is just about the count, not the families. Still, it's good to provide a bit more context. \n\nI need to make sure the information is up-to-date. Let me think – recent estimates still hover around 7,000. However, languages are dying out rapidly, so the number decreases over time. Including that note about endangerment and language extinction rates could be helpful. For instance, it's often stated that a language dies every few weeks. \n\nAnother point is sign languages. Does the count include them? Ethnologue includes some, but not all sources might. If the user is including sign languages, that adds more to the count, but I think the 7,000 figure typically refers to spoken languages. For thoroughness, maybe mention that there are also over 300 sign languages. \n\nSummarizing, the answer should state around 7,000, mention Ethnologue's figure, explain why the exact number varies, touch on endangerment, and possibly note sign languages as a separate category. Also, a brief mention of Papua New Guinea as the most linguistically diverse country. \n\nWait, let me verify Ethnologue's current number. As of their latest edition (25th, 2022), they list 7,168 living languages. But I should check if that's the case. Some sources might round to 7,000. Also, SIL International publishes Ethnologue, so citing them as reference makes sense. \n\nOther sources, like Glottolog, might have a different count because they use different criteria. Glottolog might list around 7,000 as well, but exact numbers vary. It's important to highlight that the count isn't exact because of differing definitions and ongoing research. \n\nIn conclusion, the approximate number is 7,000, with Ethnologue being a key source, considerations of endangerment, and the challenges in counting due to dialect vs. language distinctions. I should make sure the answer is clear, acknowledges the variability, and provides key points succinctly.
Answer: The exact number of languages in the world is challenging to determine due to differences in definitions (e.g., distinguishing languages from dialects) and ongoing documentation efforts. However, widely cited estimates suggest there are approximately **7,000 languages** globally.
Model: DeepSeek-R1
Usage:
Prompt tokens: 11
Total tokens: 897
Completion tokens: 886
При ведении многоэтапных бесед полезно избегать отправки содержимого рассуждений в истории чата, так как рассуждения, как правило, приводят к длинным объяснениям.
Трансляция контента
По умолчанию API завершения возвращает все созданное содержимое в одном ответе. Если вы создаете длительные завершения, ожидание ответа может занять много секунд.
Вы можете транслировать контент и получать его по мере его создания. Потоковая передача содержимого позволяет начать обработку завершения по мере того, как содержимое становится доступным. Этот режим возвращает объект, который передает ответ в виде событий, отправленных сервером исключительно для данных. Извлекайте блоки из поля дельты, а не из поля сообщения.
Чтобы включить потоковую передачу завершений, задайте stream=True при вызове модели.
var messages = [
{ role: "user", content: "How many languages are in the world?" },
];
var response = await client.path("/chat/completions").post({
body: {
model: "DeepSeek-R1",
messages: messages,
}
}).asNodeStream();
Чтобы визуализировать выходные данные, определите вспомогательную функцию для печати потока. В следующем примере реализуется маршрутизация, которая передает только ответ без содержимого причин:
function printStream(sses) {
let isThinking = false;
for await (const event of sses) {
if (event.data === "[DONE]") {
return;
}
for (const choice of (JSON.parse(event.data)).choices) {
const content = choice.delta?.content ?? "";
if (content === "<think>") {
isThinking = true;
process.stdout.write("🧠 Thinking...");
} else if (content === "</think>") {
isThinking = false;
console.log("🛑\n\n");
} else if (content) {
process.stdout.write(content);
}
}
}
}
Вы можете визуализировать, как потоковая передача создает содержимое:
var sses = createSseStream(response.body);
printStream(result)
Параметры
Как правило, модели причин не поддерживают следующие параметры, которые можно найти в моделях завершения чата:
- Температура
- Штраф за наличие
- Штраф за повторение
- Параметр
top_p
Некоторые модели поддерживают использование средств или структурированных выходных данных (включая схемы JSON). Ознакомьтесь со страницей сведений о моделях , чтобы понять поддержку каждой модели.
Применение безопасности содержимого
API вывода модели ИИ Azure поддерживает безопасность содержимого ИИ Azure. При использовании развертываний с включенной безопасностью содержимого искусственного интеллекта Azure входные и выходные данные проходят через ансамбль моделей классификации, направленных на обнаружение и предотвращение вывода вредного содержимого. Система фильтрации содержимого обнаруживает и принимает меры по определенным категориям потенциально вредного содержимого как в запросах ввода, так и в завершении выходных данных.
В следующем примере показано, как обрабатывать события, когда модель обнаруживает вредное содержимое во входном запросе и включена безопасность содержимого.
try {
var messages = [
{ role: "system", content: "You are an AI assistant that helps people find information." },
{ role: "user", content: "Chopping tomatoes and cutting them into cubes or wedges are great ways to practice your knife skills." },
];
var response = await client.path("/chat/completions").post({
model: "DeepSeek-R1",
body: {
messages: messages,
}
});
console.log(response.body.choices[0].message.content);
}
catch (error) {
if (error.status_code == 400) {
var response = JSON.parse(error.response._content);
if (response.error) {
console.log(`Your request triggered an ${response.error.code} error:\n\t ${response.error.message}`);
}
else
{
throw error;
}
}
}
Совет
Дополнительные сведения о настройке и управлении параметрами безопасности содержимого ИИ Azure см. в документации по безопасности содержимого ИИ Azure.
Внимание
Элементы, обозначенные в этой статье как (предварительная версия), сейчас предлагаются в общедоступной предварительной версии. Эта предварительная версия предоставляется без соглашения об уровне обслуживания, и мы не рекомендуем ее для рабочих нагрузок. Некоторые функции могут не поддерживаться или их возможности могут быть ограничены. Дополнительные сведения см. в статье Дополнительные условия использования Предварительных версий Microsoft Azure.
В этой статье объясняется, как использовать возможности создания аргументов для моделей завершения чата, развернутых в модели искусственного интеллекта Azure в службах ИИ Azure.
Модели причин
Модели причин могут достичь более высокого уровня производительности в таких доменах, как математика, программирование, наука, стратегия и логистика. Таким образом, эти модели создают выходные данные путем явного использования цепочки мысли для изучения всех возможных путей перед созданием ответа. Они проверяют свои ответы по мере их создания, что помогает им прийти к более точным выводам. Это означает, что модели рассуждений могут требовать меньше контекста при составлении запроса для получения эффективных результатов.
Такой способ масштабирования производительности модели называется временем инференса, так как он обменивает производительность на более высокую задержку и затраты. Он отличается от других подходов, которые масштабируются за счет времени вычислений во время обучения.
Затем модели причин создают два типа выходных данных:
- Завершения рассуждений
- Завершение выходных данных
Обе эти версии учитываются как содержимое, созданное моделью, и, следовательно, включаются в ограничения по токенам и стоимость, связанную с моделью. Некоторые модели могут выдавать содержимое рассуждений, как, например, DeepSeek-R1. Некоторые другие, например o1, выводит только выходной фрагмент завершения.
Предварительные условия
Для работы с этим учебником необходимы указанные ниже компоненты.
Подписка Azure. Если вы используете модели GitHub, вы можете улучшить ваш опыт и создать подписку Azure при этом. Прочитайте обновление о переходе с моделей GitHub на использование моделей ИИ Azure для вывода, если это ваш случай.
Ресурс служб ИИ Azure. Дополнительные сведения см. в статье "Создание ресурса Служб искусственного интеллекта Azure".
URL-адрес конечной точки и ключ.
Добавьте пакет вывода искусственного интеллекта Azure в проект:
<dependency> <groupId>com.azure</groupId> <artifactId>azure-ai-inference</artifactId> <version>1.0.0-beta.4</version> </dependency>Если вы используете Entra ID, вам также потребуется следующий пакет:
<dependency> <groupId>com.azure</groupId> <artifactId>azure-identity</artifactId> <version>1.15.3</version> </dependency>Импортируйте следующее пространство имен:
package com.azure.ai.inference.usage; import com.azure.ai.inference.EmbeddingsClient; import com.azure.ai.inference.EmbeddingsClientBuilder; import com.azure.ai.inference.ChatCompletionsClient; import com.azure.ai.inference.ChatCompletionsClientBuilder; import com.azure.ai.inference.models.EmbeddingsResult; import com.azure.ai.inference.models.EmbeddingItem; import com.azure.ai.inference.models.ChatCompletions; import com.azure.core.credential.AzureKeyCredential; import com.azure.core.util.Configuration; import java.util.ArrayList; import java.util.List;
Модель с возможностями рассуждения для развертывания. Если у вас нет модели, прочитайте «Добавление и настройка моделей в службах ИИ Azure», чтобы добавить модель логического вывода.
- В этом примере используется
DeepSeek-R1.
- В этом примере используется
Использование возможностей логического анализа в чате
Сначала создайте клиент для использования модели. В следующем коде используется URL-адрес конечной точки и ключ, хранящиеся в переменных среды.
ChatCompletionsClient client = new ChatCompletionsClient(
new URI("https://<resource>.services.ai.azure.com/models"),
new AzureKeyCredential(System.getProperty("AZURE_INFERENCE_CREDENTIAL")),
Совет
Убедитесь, что вы развернули модель в ресурсе Служб искусственного интеллекта Azure с помощью API вывода модели Azure.
Deepseek-R1 также доступен в качестве конечных точек БЕССерверного API. Однако эти конечные точки не принимают параметр model , как описано в этом руководстве. Вы можете убедиться, что перейдите на портал> Azure AI Foundry Portal Models + endpoints и убедитесь, что модель указана в разделе Azure AI Services.
Если вы настроили ресурс в службу поддержки идентификатора Microsoft Entra, можно использовать следующий фрагмент кода для создания клиента.
client = new ChatCompletionsClient(
new URI("https://<resource>.services.ai.azure.com/models"),
new DefaultAzureCredentialBuilder().build()
);
Создание запроса на завершение чата
В следующем примере показано, как создать базовый запрос чата для модели.
ChatCompletionsOptions requestOptions = new ChatCompletionsOptions()
.setModel("DeepSeek-R1")
.setMessages(Arrays.asList(
new ChatRequestUserMessage("How many languages are in the world?")
));
Response<ChatCompletions> response = client.complete(requestOptions);
При создании запросов на создание моделей причин следует учитывать следующее:
- Используйте простые инструкции и избегайте использования методов цепочки мышления.
- Встроенные возможности рассуждений делают простые запросы нулевого снимка эффективными, чем более сложные методы.
- При предоставлении дополнительного контекста или документов, например в сценариях RAG, включая только наиболее релевантную информацию, может помочь предотвратить чрезмерное усложнение ответа модели.
- Модели причин могут поддерживать использование системных сообщений. Тем не менее, они не могут следовать им строго, как и другие неразумные модели.
- При создании многоэтапных приложений рассмотрите возможность добавления только окончательного ответа из модели, без его пояснительного содержания, как описано в разделе 'Пояснительное содержание'.
Обратите внимание, что модели причин могут занять больше времени для создания ответов. Они используют длинные цепочки рассуждений, которые позволяют более глубоко и структурировано решать проблемы. Они также выполняют самопроверку, чтобы сверить свои собственные ответы и исправить свои собственные ошибки, показывая возникающие саморефлексивные поведение.
Ответ выглядит следующим образом, где можно просмотреть статистику использования модели:
System.out.println("Response: " + response.getValue().getChoices().get(0).getMessage().getContent());
System.out.println("Model: " + response.getValue().getModel());
System.out.println("Usage:");
System.out.println("\tPrompt tokens: " + response.getValue().getUsage().getPromptTokens());
System.out.println("\tTotal tokens: " + response.getValue().getUsage().getTotalTokens());
System.out.println("\tCompletion tokens: " + response.getValue().getUsage().getCompletionTokens());
Response: <think>Okay, the user is asking how many languages exist in the world. I need to provide a clear and accurate...</think>The exact number of languages in the world is challenging to determine due to differences in definitions (e.g., distinguishing languages from dialects) and ongoing documentation efforts. However, widely cited estimates suggest there are approximately **7,000 languages** globally.
Model: deepseek-r1
Usage:
Prompt tokens: 11
Total tokens: 897
Completion tokens: 886
Содержимое размышлений
Некоторые модели рассуждений, такие как DeepSeek-R1, создают варианты завершения и включают обоснования. Причины, связанные с завершением, включаются в содержимое ответа в тегах <think> и </think>. Модель может выбирать сценарии, в которых генерируется содержание рассуждений. Вы можете извлечь содержимое причин из ответа, чтобы понять процесс мысли модели следующим образом:
String content = response.getValue().getChoices().get(0).getMessage().getContent()
Pattern pattern = Pattern.compile("<think>(.*?)</think>(.*)", Pattern.DOTALL);
Matcher matcher = pattern.matcher(content);
System.out.println("Response:");
if (matcher.find()) {
System.out.println("\tThinking: " + matcher.group(1));
System.out.println("\tAnswer: " + matcher.group(2));
}
else {
System.out.println("Response: " + content);
}
System.out.println("Model: " + response.getValue().getModel());
System.out.println("Usage:");
System.out.println("\tPrompt tokens: " + response.getValue().getUsage().getPromptTokens());
System.out.println("\tTotal tokens: " + response.getValue().getUsage().getTotalTokens());
System.out.println("\tCompletion tokens: " + response.getValue().getUsage().getCompletionTokens());
Thinking: Okay, the user is asking how many languages exist in the world. I need to provide a clear and accurate answer. Let's start by recalling the general consensus from linguistic sources. I remember that the number often cited is around 7,000, but maybe I should check some reputable organizations.\n\nEthnologue is a well-known resource for language data, and I think they list about 7,000 languages. But wait, do they update their numbers? It might be around 7,100 or so. Also, the exact count can vary because some sources might categorize dialects differently or have more recent data. \n\nAnother thing to consider is language endangerment. Many languages are endangered, with some having only a few speakers left. Organizations like UNESCO track endangered languages, so mentioning that adds context. Also, the distribution isn't even. Some countries have hundreds of languages, like Papua New Guinea with over 800, while others have just a few. \n\nA user might also wonder why the exact number is hard to pin down. It's because the distinction between a language and a dialect can be political or cultural. For example, Mandarin and Cantonese are considered dialects of Chinese by some, but they're mutually unintelligible, so others classify them as separate languages. Also, some regions are under-researched, making it hard to document all languages. \n\nI should also touch on language families. The 7,000 languages are grouped into families like Indo-European, Sino-Tibetan, Niger-Congo, etc. Maybe mention a few of the largest families. But wait, the question is just about the count, not the families. Still, it's good to provide a bit more context. \n\nI need to make sure the information is up-to-date. Let me think – recent estimates still hover around 7,000. However, languages are dying out rapidly, so the number decreases over time. Including that note about endangerment and language extinction rates could be helpful. For instance, it's often stated that a language dies every few weeks. \n\nAnother point is sign languages. Does the count include them? Ethnologue includes some, but not all sources might. If the user is including sign languages, that adds more to the count, but I think the 7,000 figure typically refers to spoken languages. For thoroughness, maybe mention that there are also over 300 sign languages. \n\nSummarizing, the answer should state around 7,000, mention Ethnologue's figure, explain why the exact number varies, touch on endangerment, and possibly note sign languages as a separate category. Also, a brief mention of Papua New Guinea as the most linguistically diverse country. \n\nWait, let me verify Ethnologue's current number. As of their latest edition (25th, 2022), they list 7,168 living languages. But I should check if that's the case. Some sources might round to 7,000. Also, SIL International publishes Ethnologue, so citing them as reference makes sense. \n\nOther sources, like Glottolog, might have a different count because they use different criteria. Glottolog might list around 7,000 as well, but exact numbers vary. It's important to highlight that the count isn't exact because of differing definitions and ongoing research. \n\nIn conclusion, the approximate number is 7,000, with Ethnologue being a key source, considerations of endangerment, and the challenges in counting due to dialect vs. language distinctions. I should make sure the answer is clear, acknowledges the variability, and provides key points succinctly.
Answer: The exact number of languages in the world is challenging to determine due to differences in definitions (e.g., distinguishing languages from dialects) and ongoing documentation efforts. However, widely cited estimates suggest there are approximately **7,000 languages** globally.
Model: DeepSeek-R1
Usage:
Prompt tokens: 11
Total tokens: 897
Completion tokens: 886
При ведении многоэтапных бесед полезно избегать отправки содержимого рассуждений в истории чата, так как рассуждения, как правило, порождают длинные объяснения.
Потоковый контент
По умолчанию API завершения возвращает все созданное содержимое в одном ответе. Если вы создаете длительные завершения, ожидание ответа может занять много секунд.
Вы можете транслировать содержимое, чтобы получать его в процессе создания. Потоковая передача содержимого позволяет начать обработку сразу же, как только содержимое становится доступным. Этот режим возвращает объект, который передает ответ в виде серверных событий, отправляемых только с данными. Извлеките блоки из поля дельта, а не из поля сообщения.
ChatCompletionsOptions requestOptions = new ChatCompletionsOptions()
.setModel("DeepSeek-R1")
.setMessages(Arrays.asList(
new ChatRequestUserMessage("How many languages are in the world? Write an essay about it.")
))
.setMaxTokens(4096);
return client.completeStreamingAsync(requestOptions).thenAcceptAsync(response -> {
try {
printStream(response);
} catch (Exception e) {
throw new RuntimeException(e);
}
});
Чтобы визуализировать выходные данные, определите вспомогательную функцию для печати потока. В следующем примере реализуется маршрутизация, которая передает только ответ без содержимого причин:
public void printStream(StreamingResponse<StreamingChatCompletionsUpdate> response) throws Exception {
boolean isThinking = false;
for (StreamingChatCompletionsUpdate chatUpdate : response) {
if (chatUpdate.getContentUpdate() != null && !chatUpdate.getContentUpdate().isEmpty()) {
String content = chatUpdate.getContentUpdate();
if ("<think>".equals(content)) {
isThinking = true;
System.out.print("🧠 Thinking...");
System.out.flush();
} else if ("</think>".equals(content)) {
isThinking = false;
System.out.println("🛑\n\n");
} else if (content != null && !content.isEmpty()) {
System.out.print(content);
System.out.flush();
}
}
}
}
Вы можете визуализировать, как потоковая передача создает содержимое:
try {
streamMessageAsync(client).get();
} catch (Exception e) {
throw new RuntimeException(e);
}
Параметры
Как правило, модели причин не поддерживают следующие параметры, которые можно найти в моделях завершения чата:
- Температура
- Штраф за присутствие
- Пенальти повторения
- Параметр
top_p
Некоторые модели поддерживают использование средств или структурированных выходных данных (включая схемы JSON). Ознакомьтесь со страницей сведений о моделях , чтобы понять поддержку каждой модели.
Внимание
Элементы, обозначенные в этой статье как (предварительная версия), сейчас предлагаются в общедоступной предварительной версии. Эта предварительная версия предоставляется без соглашения об уровне обслуживания, и мы не рекомендуем ее для рабочих нагрузок. Некоторые функции могут не поддерживаться или их возможности могут быть ограничены. Дополнительные сведения см. в статье Дополнительные условия использования Предварительных версий Microsoft Azure.
В этой статье объясняется, как использовать возможности рассуждения моделей завершения чата, развернутых для интерпретации моделей ИИ в службах искусственного интеллекта Azure.
Модели причин
Модели причин могут достичь более высокого уровня производительности в таких доменах, как математика, программирование, наука, стратегия и логистика. Таким образом, эти модели создают выходные данные путем явного использования цепочки мысли для изучения всех возможных путей перед созданием ответа. Они проверяют свои ответы по мере их составления, что помогает им делать более точные выводы. Это означает, что модели рассуждения могут требовать меньше контекста в подсказках для получения эффективных результатов.
Такой способ масштабирования производительности модели называется временем вычислений при выводе, так как он обменивает производительность на более высокую задержку и затраты. Он отличается от других подходов, которые масштабируются за счет использования времени вычислений для обучения.
Затем модели причин создают два типа выходных данных:
- Завершение рассуждений
- Завершение выходных данных
Оба этих результата засчитываются как часть содержимого, созданного моделью, и, следовательно, к лимитам на количество токенов и затратам, связанным с моделью. Некоторые модели могут выводить содержимое рассуждений, например, DeepSeek-R1. Некоторые другие, например o1, выводит только выходной фрагмент завершения.
Предварительные условия
Для работы с этим учебником необходимы указанные ниже компоненты.
Подписка Azure. Если вы используете GitHub Models, вы можете улучшить свой опыт и создать подписку Azure в процессе. Прочтите о переходе от моделей GitHub к модели вывода ИИ Azure, если это ваш случай.
Ресурс служб ИИ Azure. Дополнительные сведения см. в статье "Создание ресурса Служб искусственного интеллекта Azure".
URL-адрес конечной точки и ключ.
Установите пакет вывода искусственного интеллекта Azure с помощью следующей команды:
dotnet add package Azure.AI.Inference --prereleaseЕсли вы используете Entra ID, вам также потребуется следующий пакет:
dotnet add package Azure.Identity
Модель с возможностями рассуждения и развертыванием модели. Если у вас его нет, прочитайте "Добавление и настройка моделей в службах ИИ Azure, чтобы добавить модель рассуждений.
- В этом примере используется
DeepSeek-R1.
- В этом примере используется
Использование логических возможностей чата
Сначала создайте клиент для использования модели. В следующем коде используется URL-адрес конечной точки и ключ, хранящиеся в переменных среды.
ChatCompletionsClient client = new ChatCompletionsClient(
new Uri("https://<resource>.services.ai.azure.com/models"),
new AzureKeyCredential(Environment.GetEnvironmentVariable("AZURE_INFERENCE_CREDENTIAL"))
);
Совет
Убедитесь, что вы развернули модель в ресурсе Служб искусственного интеллекта Azure с помощью API вывода модели Azure.
Deepseek-R1 также доступны как бессерверные точки API. Однако эти конечные точки не принимают параметр model , как описано в этом руководстве. Вы можете проверить это, перейдя на портал Azure AI Foundry, в разделе «Модели + конечные точки» и убедиться, что модель указана в разделе Azure AI Services.
Если вы настроили ресурс для поддержки Microsoft Entra ID, можно использовать следующий фрагмент кода для создания клиента.
TokenCredential credential = new DefaultAzureCredential(includeInteractiveCredentials: true);
AzureAIInferenceClientOptions clientOptions = new AzureAIInferenceClientOptions();
BearerTokenAuthenticationPolicy tokenPolicy = new BearerTokenAuthenticationPolicy(credential, new string[] { "https://cognitiveservices.azure.com/.default" });
clientOptions.AddPolicy(tokenPolicy, HttpPipelinePosition.PerRetry);
client = new ChatCompletionsClient(
new Uri("https://<resource>.services.ai.azure.com/models"),
credential,
clientOptions,
);
Создание запроса на завершение чата
В следующем примере показано, как создать базовый запрос чата для модели.
ChatCompletionsOptions requestOptions = new ChatCompletionsOptions()
{
Messages = {
new ChatRequestUserMessage("How many languages are in the world?")
},
Model = "deepseek-r1",
};
Response<ChatCompletions> response = client.Complete(requestOptions);
При создании запросов на создание моделей причин следует учитывать следующее:
- Используйте простые инструкции и избегайте использования методов цепочки мышления.
- Встроенные возможности рассуждений делают простые запросы нулевого снимка эффективными, чем более сложные методы.
- При предоставлении дополнительного контекста или документов, например в сценариях RAG, включая только наиболее релевантную информацию, может помочь предотвратить чрезмерное усложнение ответа модели.
- Модели причин могут поддерживать использование системных сообщений. Тем не менее, они не могут следовать им строго, как и другие неразумные модели.
- При создании многоэтапных приложений рассмотрите возможность добавления только окончательного ответа из модели, без его причины содержимого, как описано в разделе "Причины содержимого ".
Обратите внимание, что модели причин могут занять больше времени для создания ответов. Они используют длинные цепочки рассуждений, которые позволяют более глубоко и структурировано решать проблемы. Они также выполняют самопроверку, чтобы сверить свои собственные ответы и исправить свои собственные ошибки, показывая возникающие саморефлексивные поведение.
Ответ выглядит следующим образом, где можно просмотреть статистику использования модели:
Console.WriteLine($"Response: {response.Value.Content}");
Console.WriteLine($"Model: {response.Value.Model}");
Console.WriteLine("Usage:");
Console.WriteLine($"\tPrompt tokens: {response.Value.Usage.PromptTokens}");
Console.WriteLine($"\tTotal tokens: {response.Value.Usage.TotalTokens}");
Console.WriteLine($"\tCompletion tokens: {response.Value.Usage.CompletionTokens}");
Response: <think>Okay, the user is asking how many languages exist in the world. I need to provide a clear and accurate...</think>The exact number of languages in the world is challenging to determine due to differences in definitions (e.g., distinguishing languages from dialects) and ongoing documentation efforts. However, widely cited estimates suggest there are approximately **7,000 languages** globally.
Model: deepseek-r1
Usage:
Prompt tokens: 11
Total tokens: 897
Completion tokens: 886
Содержимое причин
Некоторые модели рассуждений, такие как DeepSeek-R1, создают завершения и включают в себя логику. Причины, связанные с завершением, включаются в содержимое ответа в тегах <think> и </think>. Модель может выбрать сценарии, в которых будет создаваться контент рассуждений. Вы можете извлечь содержимое причин из ответа, чтобы понять процесс мысли модели следующим образом:
Regex regex = new Regex(pattern, RegexOptions.Singleline);
Match match = regex.Match(response.Value.Content);
Console.WriteLine("Response:");
if (match.Success)
{
Console.WriteLine($"\tThinking: {match.Groups[1].Value}");
Console.WriteLine($"\tAnswer: {match.Groups[2].Value}");
else
{
Console.WriteLine($"Response: {response.Value.Content}");
}
Console.WriteLine($"Model: {response.Value.Model}");
Console.WriteLine("Usage:");
Console.WriteLine($"\tPrompt tokens: {response.Value.Usage.PromptTokens}");
Console.WriteLine($"\tTotal tokens: {response.Value.Usage.TotalTokens}");
Console.WriteLine($"\tCompletion tokens: {response.Value.Usage.CompletionTokens}");
Thinking: Okay, the user is asking how many languages exist in the world. I need to provide a clear and accurate answer. Let's start by recalling the general consensus from linguistic sources. I remember that the number often cited is around 7,000, but maybe I should check some reputable organizations.\n\nEthnologue is a well-known resource for language data, and I think they list about 7,000 languages. But wait, do they update their numbers? It might be around 7,100 or so. Also, the exact count can vary because some sources might categorize dialects differently or have more recent data. \n\nAnother thing to consider is language endangerment. Many languages are endangered, with some having only a few speakers left. Organizations like UNESCO track endangered languages, so mentioning that adds context. Also, the distribution isn't even. Some countries have hundreds of languages, like Papua New Guinea with over 800, while others have just a few. \n\nA user might also wonder why the exact number is hard to pin down. It's because the distinction between a language and a dialect can be political or cultural. For example, Mandarin and Cantonese are considered dialects of Chinese by some, but they're mutually unintelligible, so others classify them as separate languages. Also, some regions are under-researched, making it hard to document all languages. \n\nI should also touch on language families. The 7,000 languages are grouped into families like Indo-European, Sino-Tibetan, Niger-Congo, etc. Maybe mention a few of the largest families. But wait, the question is just about the count, not the families. Still, it's good to provide a bit more context. \n\nI need to make sure the information is up-to-date. Let me think – recent estimates still hover around 7,000. However, languages are dying out rapidly, so the number decreases over time. Including that note about endangerment and language extinction rates could be helpful. For instance, it's often stated that a language dies every few weeks. \n\nAnother point is sign languages. Does the count include them? Ethnologue includes some, but not all sources might. If the user is including sign languages, that adds more to the count, but I think the 7,000 figure typically refers to spoken languages. For thoroughness, maybe mention that there are also over 300 sign languages. \n\nSummarizing, the answer should state around 7,000, mention Ethnologue's figure, explain why the exact number varies, touch on endangerment, and possibly note sign languages as a separate category. Also, a brief mention of Papua New Guinea as the most linguistically diverse country. \n\nWait, let me verify Ethnologue's current number. As of their latest edition (25th, 2022), they list 7,168 living languages. But I should check if that's the case. Some sources might round to 7,000. Also, SIL International publishes Ethnologue, so citing them as reference makes sense. \n\nOther sources, like Glottolog, might have a different count because they use different criteria. Glottolog might list around 7,000 as well, but exact numbers vary. It's important to highlight that the count isn't exact because of differing definitions and ongoing research. \n\nIn conclusion, the approximate number is 7,000, with Ethnologue being a key source, considerations of endangerment, and the challenges in counting due to dialect vs. language distinctions. I should make sure the answer is clear, acknowledges the variability, and provides key points succinctly.
Answer: The exact number of languages in the world is challenging to determine due to differences in definitions (e.g., distinguishing languages from dialects) and ongoing documentation efforts. However, widely cited estimates suggest there are approximately **7,000 languages** globally.
Model: DeepSeek-R1
Usage:
Prompt tokens: 11
Total tokens: 897
Completion tokens: 886
При выполнении многоэтапных бесед полезно избежать отправки содержимого причин в журнале чата в качестве причин, как правило, генерировать длинные объяснения.
Потоковая передача содержимого
По умолчанию API завершения возвращает все созданное содержимое в одном ответе. Если вы создаете длительные завершения, ожидание ответа может занять много секунд.
Вы можете передавать содержимое, чтобы получить его по мере создания. Потоковая передача содержимого позволяет начать обработку результатов, когда содержимое становится доступным. Этот режим возвращает объект, который передает ответ в виде событий, отправляемых сервером, содержащих только данные. Извлекайте блоки из поля дельта, а не поля сообщения.
static async Task StreamMessageAsync(ChatCompletionsClient client)
{
ChatCompletionsOptions requestOptions = new ChatCompletionsOptions()
{
Messages = {
new ChatRequestUserMessage("How many languages are in the world?")
},
MaxTokens=4096,
Model = "deepseek-r1",
};
StreamingResponse<StreamingChatCompletionsUpdate> streamResponse = await client.CompleteStreamingAsync(requestOptions);
await PrintStream(streamResponse);
}
Чтобы визуализировать выходные данные, определите вспомогательную функцию для печати потока. В следующем примере реализуется маршрутизация, которая передает только ответ без содержимого причин:
static void PrintStream(StreamingResponse<StreamingChatCompletionsUpdate> response)
{
bool isThinking = false;
await foreach (StreamingChatCompletionsUpdate chatUpdate in response)
{
if (!string.IsNullOrEmpty(chatUpdate.ContentUpdate))
{
string content = chatUpdate.ContentUpdate;
if (content == "<think>")
{
isThinking = true;
Console.Write("🧠 Thinking...");
Console.Out.Flush();
}
else if (content == "</think>")
{
isThinking = false;
Console.WriteLine("🛑\n\n");
}
else if (!string.IsNullOrEmpty(content))
{
Console.Write(content);
Console.Out.Flush();
}
}
}
}
Вы можете визуализировать, как потоковая передача создает содержимое:
StreamMessageAsync(client).GetAwaiter().GetResult();
Параметры
Как правило, модели причин не поддерживают следующие параметры, которые можно найти в моделях завершения чата:
- Температура
- Штраф за повторения
- Штраф за повторение
- Параметр
top_p
Некоторые модели поддерживают использование средств или структурированных выходных данных (включая схемы JSON). Ознакомьтесь со страницей сведений о моделях , чтобы понять поддержку каждой модели.
Применение безопасности содержимого
API вывода модели ИИ Azure поддерживает безопасность содержимого ИИ Azure. При использовании развертываний с включенной безопасностью содержимого искусственного интеллекта Azure входные и выходные данные проходят через ансамбль моделей классификации, направленных на обнаружение и предотвращение вывода вредного содержимого. Система фильтрации содержимого обнаруживает и принимает меры по определенным категориям потенциально вредного содержимого как в запросах ввода, так и в завершении выходных данных.
В следующем примере показано, как обрабатывать события, когда модель обнаруживает вредное содержимое во входном запросе и включена безопасность содержимого.
try
{
requestOptions = new ChatCompletionsOptions()
{
Messages = {
new ChatRequestSystemMessage("You are an AI assistant that helps people find information."),
new ChatRequestUserMessage(
"Chopping tomatoes and cutting them into cubes or wedges are great ways to practice your knife skills."
),
},
Model = "deepseek-r1",
};
response = client.Complete(requestOptions);
Console.WriteLine(response.Value.Content);
}
catch (RequestFailedException ex)
{
if (ex.ErrorCode == "content_filter")
{
Console.WriteLine($"Your query has trigger Azure Content Safety: {ex.Message}");
}
else
{
throw;
}
}
Совет
Дополнительные сведения о настройке и управлении параметрами безопасности содержимого ИИ Azure см. в документации по безопасности содержимого ИИ Azure.
Внимание
Элементы, обозначенные в этой статье как (предварительная версия), сейчас предлагаются в общедоступной предварительной версии. Эта предварительная версия предоставляется без соглашения об уровне обслуживания, и мы не рекомендуем ее для рабочих нагрузок. Некоторые функции могут не поддерживаться или их возможности могут быть ограничены. Дополнительные сведения см. в статье Дополнительные условия использования Предварительных версий Microsoft Azure.
В этой статье объясняется, как использовать возможности создания аргументов для моделей завершения чата, развернутых в модели искусственного интеллекта Azure в службах ИИ Azure.
Модели причин
Модели причин могут достичь более высокого уровня производительности в таких доменах, как математика, программирование, наука, стратегия и логистика. Таким образом, эти модели создают выходные данные путем явного использования цепочки мысли для изучения всех возможных путей перед созданием ответа. Они проверяют свои ответы в ходе их составления, что помогает им прийти к более точным выводам. Это означает, что модели рассуждений могут требовать меньше контекста при формулировании запросов для получения эффективных результатов.
Такой способ масштабирования производительности модели называется временем вычислений для получения результата, так как он обменивает производительность на более высокую задержку и стоимость. Он отличается от других подходов, которые масштабируются с помощью обучения вычислительного времени.
Затем модели причин создают два типа выходных данных:
- Аргументирование завершений
- Завершение вывода данных
Обе эти генерации влияют на содержимое, созданное моделью, и, следовательно, учитываются в лимитах токенов и расходах, связанных с моделью. Некоторые модели могут выводить объяснительное содержимое, например DeepSeek-R1. Некоторые другие, например o1, выводит только выходной фрагмент завершения.
Предварительные условия
Для работы с этим учебником необходимы указанные ниже компоненты.
Подписка Azure. Если вы используете GitHub Models, вы можете улучшить свои возможности и создать подписку Azure в процессе. Прочтите о переходе от моделей GitHub к модели вывода ИИ Azure, если это касается вас.
Ресурс служб ИИ Azure. Дополнительные сведения см. в статье "Создание ресурса Служб искусственного интеллекта Azure".
URL-адрес конечной точки и ключ.
Модель с возможностями логического мышления для развертывания. Если у вас нет необходимой модели, прочитайте "Добавление и настройка моделей в службах Azure AI", чтобы добавить модель рассуждений.
- В этом примере используется
DeepSeek-R1.
- В этом примере используется
Использование умственных возможностей в чате
Сначала создайте клиент для использования модели. В следующем коде используется URL-адрес конечной точки и ключ, хранящиеся в переменных среды.
POST https://<resource>.services.ai.azure.com/models/chat/completions?api-version=2024-05-01-preview
Content-Type: application/json
api-key: <key>
Совет
Убедитесь, что вы развернули модель в ресурсе Служб искусственного интеллекта Azure с помощью API вывода модели Azure.
Deepseek-R1 также доступен в качестве конечных точек бессерверного API. Однако эти конечные точки не принимают параметр model , как описано в этом руководстве. Вы можете убедиться в этом, перейдя на портал Azure AI Foundry>, выбрав Models + endpoints, и проверить, что модель указана в разделе Azure AI Services.
Если вы настроили ресурс с поддержкой Microsoft Entra ID, передайте токен в заголовке Authorization с форматом Bearer <token>. Используйте область https://cognitiveservices.azure.com/.default.
POST https://<resource>.services.ai.azure.com/models/chat/completions?api-version=2024-05-01-preview
Content-Type: application/json
Authorization: Bearer <token>
Использование идентификатора Microsoft Entra может потребовать дополнительной конфигурации в ресурсе для предоставления доступа. Узнайте, как настроить проверку подлинности без ключей с помощью идентификатора Microsoft Entra.
Создание запроса на завершение чата
В следующем примере показано, как создать базовый запрос чата для модели.
{
"model": "deepseek-r1",
"messages": [
{
"role": "user",
"content": "How many languages are in the world?"
}
]
}
При создании запросов на создание моделей причин следует учитывать следующее:
- Используйте простые инструкции и избегайте использования методов цепочки мышления.
- Встроенные возможности рассуждений делают простые запросы нулевого снимка эффективными, чем более сложные методы.
- При предоставлении дополнительного контекста или документов, например в сценариях RAG, включая только наиболее релевантную информацию, может помочь предотвратить чрезмерное усложнение ответа модели.
- Модели причин могут поддерживать использование системных сообщений. Тем не менее, они не могут следовать им строго, как и другие неразумные модели.
- При создании многоэтапных приложений рассмотрите возможность добавления только окончательного ответа из модели, без содержимого рассуждений, как описано в разделе «Содержимое рассуждений».
Обратите внимание, что модели причин могут занять больше времени для создания ответов. Они используют длинные цепочки рассуждений, которые позволяют более глубоко и структурировано решать проблемы. Они также выполняют самопроверку, чтобы сверить свои собственные ответы и исправить свои собственные ошибки, показывая возникающие саморефлексивные поведение.
Ответ выглядит следующим образом, где можно просмотреть статистику использования модели:
{
"id": "0a1234b5de6789f01gh2i345j6789klm",
"object": "chat.completion",
"created": 1718726686,
"model": "DeepSeek-R1",
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"content": "<think>\nOkay, the user is asking how many languages exist in the world. I need to provide a clear and accurate answer. Let's start by recalling the general consensus from linguistic sources. I remember that the number often cited is around 7,000, but maybe I should check some reputable organizations.\n\nEthnologue is a well-known resource for language data, and I think they list about 7,000 languages. But wait, do they update their numbers? It might be around 7,100 or so. Also, the exact count can vary because some sources might categorize dialects differently or have more recent data. \n\nAnother thing to consider is language endangerment. Many languages are endangered, with some having only a few speakers left. Organizations like UNESCO track endangered languages, so mentioning that adds context. Also, the distribution isn't even. Some countries have hundreds of languages, like Papua New Guinea with over 800, while others have just a few. \n\nA user might also wonder why the exact number is hard to pin down. It's because the distinction between a language and a dialect can be political or cultural. For example, Mandarin and Cantonese are considered dialects of Chinese by some, but they're mutually unintelligible, so others classify them as separate languages. Also, some regions are under-researched, making it hard to document all languages. \n\nI should also touch on language families. The 7,000 languages are grouped into families like Indo-European, Sino-Tibetan, Niger-Congo, etc. Maybe mention a few of the largest families. But wait, the question is just about the count, not the families. Still, it's good to provide a bit more context. \n\nI need to make sure the information is up-to-date. Let me think – recent estimates still hover around 7,000. However, languages are dying out rapidly, so the number decreases over time. Including that note about endangerment and language extinction rates could be helpful. For instance, it's often stated that a language dies every few weeks. \n\nAnother point is sign languages. Does the count include them? Ethnologue includes some, but not all sources might. If the user is including sign languages, that adds more to the count, but I think the 7,000 figure typically refers to spoken languages. For thoroughness, maybe mention that there are also over 300 sign languages. \n\nSummarizing, the answer should state around 7,000, mention Ethnologue's figure, explain why the exact number varies, touch on endangerment, and possibly note sign languages as a separate category. Also, a brief mention of Papua New Guinea as the most linguistically diverse country. \n\nWait, let me verify Ethnologue's current number. As of their latest edition (25th, 2022), they list 7,168 living languages. But I should check if that's the case. Some sources might round to 7,000. Also, SIL International publishes Ethnologue, so citing them as reference makes sense. \n\nOther sources, like Glottolog, might have a different count because they use different criteria. Glottolog might list around 7,000 as well, but exact numbers vary. It's important to highlight that the count isn't exact because of differing definitions and ongoing research. \n\nIn conclusion, the approximate number is 7,000, with Ethnologue being a key source, considerations of endangerment, and the challenges in counting due to dialect vs. language distinctions. I should make sure the answer is clear, acknowledges the variability, and provides key points succinctly.\n</think>\n\nThe exact number of languages in the world is challenging to determine due to differences in definitions (e.g., distinguishing languages from dialects) and ongoing documentation efforts. However, widely cited estimates suggest there are approximately **7,000 languages** globally.",
"tool_calls": null
},
"finish_reason": "stop"
}
],
"usage": {
"prompt_tokens": 11,
"total_tokens": 897,
"completion_tokens": 886
}
}
Содержание рассуждений
Некоторые модели рассуждений, такие как DeepSeek-R1, создают результаты и включают рассуждения, лежащие в их основе. Причины, связанные с завершением, включаются в содержимое ответа в тегах <think> и </think>. Модель может выбрать, в каких сценариях она будет создавать логическое содержание.
При проведении многоэтапных разговоров полезно избегать отправки содержимого аргументации в историю чата, поскольку аргументация, как правило, приводит к созданию длинных объяснений.
Потоковое содержимое
По умолчанию API завершения возвращает все созданное содержимое в одном ответе. Если вы создаете длительные завершения, ожидание ответа может занять много секунд.
Вы можете транслировать контент, чтобы получать его по мере создания. Потоковая передача содержимого позволяет начать обработку результатов по мере доступности содержимого. Этот режим возвращает объект, который передает ответ в виде событий, отправляемых сервером только с данными. Извлеките блоки из поля дельты, а не поля сообщения.
Чтобы выполнить потоковую отправку завершений, установите "stream": true при вызове модели.
{
"model": "DeepSeek-R1",
"messages": [
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "How many languages are in the world?"
}
],
"stream": true,
"max_tokens": 2048
}
Чтобы визуализировать выходные данные, определите вспомогательную функцию для печати потока. В следующем примере реализуется маршрутизация, которая передает только ответ без содержимого причин:
{
"id": "23b54589eba14564ad8a2e6978775a39",
"object": "chat.completion.chunk",
"created": 1718726371,
"model": "DeepSeek-R1",
"choices": [
{
"index": 0,
"delta": {
"role": "assistant",
"content": ""
},
"finish_reason": null,
"logprobs": null
}
]
}
Последнее сообщение в потоке установлено finish_reason , указывая причину остановки процесса создания.
{
"id": "23b54589eba14564ad8a2e6978775a39",
"object": "chat.completion.chunk",
"created": 1718726371,
"model": "DeepSeek-R1",
"choices": [
{
"index": 0,
"delta": {
"content": ""
},
"finish_reason": "stop",
"logprobs": null
}
],
"usage": {
"prompt_tokens": 11,
"total_tokens": 897,
"completion_tokens": 886
}
}
Параметры
Как правило, модели причин не поддерживают следующие параметры, которые можно найти в моделях завершения чата:
- Температура
- Штраф за присутствие
- Штраф за повторение
- Параметр
top_p
Некоторые модели поддерживают использование средств или структурированных выходных данных (включая схемы JSON). Ознакомьтесь со страницей сведений о моделях , чтобы понять поддержку каждой модели.
Применение безопасности содержимого
API вывода модели ИИ Azure поддерживает безопасность содержимого ИИ Azure. При использовании развертываний с включенной безопасностью содержимого искусственного интеллекта Azure входные и выходные данные проходят через ансамбль моделей классификации, направленных на обнаружение и предотвращение вывода вредного содержимого. Система фильтрации содержимого обнаруживает и принимает меры по определенным категориям потенциально вредного содержимого как в запросах ввода, так и в завершении выходных данных.
В следующем примере показано, как обрабатывать события, когда модель обнаруживает вредное содержимое во входном запросе и включена безопасность содержимого.
{
"model": "DeepSeek-R1",
"messages": [
{
"role": "user",
"content": "Chopping tomatoes and cutting them into cubes or wedges are great ways to practice your knife skills."
}
]
}
{
"error": {
"message": "The response was filtered due to the prompt triggering Microsoft's content management policy. Please modify your prompt and retry.",
"type": null,
"param": "prompt",
"code": "content_filter",
"status": 400
}
}
Совет
Дополнительные сведения о настройке и управлении параметрами безопасности содержимого ИИ Azure см. в документации по безопасности содержимого ИИ Azure.