Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Il training dei modelli di Machine Learning è un processo iterativo e richiede una sperimentazione significativa. Con l'esperienza di processo interattiva di Azure Machine Learning, i data scientist possono usare Python SDK per Azure Machine Learning, l'interfaccia della riga di comando di Azure Machine Learning o Azure Studio per accedere al contenitore in cui è in esecuzione il processo. Dopo aver effettuato l'accesso al contenitore dei processi, gli utenti possono eseguire l'iterazione sugli script di training, monitorare lo stato di avanzamento del training o eseguire il debug del processo in remoto come fanno in genere nei computer locali. È possibile eseguire l'iterazione dei processi tramite diverse applicazioni di training, tra cui JupyterLab, TensorBoard, VS Code o connettendosi al contenitore dei processi direttamente tramite SSH.
Il training interattivo è supportato nei cluster dell'ambiente di calcolo di Azure Machine Learning e nel cluster Kubernetes abilitato per Azure Arc.
Prerequisiti
- Vedere l'introduzione al training su Azure Machine Learning.
- Per ulteriori informazioni, vedere questo collegamento per VS Code per configurare l'estensione di Azure Machine Learning.
- Assicurarsi che nell'ambiente del processo siano installati i pacchetti
openssh-servereipykernel ~=6.0(in tutti gli ambienti di training curati di Azure Machine Learning tali pacchetti sono installati per impostazione predefinita). - Le applicazioni interattive non possono essere abilitate nelle esecuzioni di training distribuite in cui il tipo di distribuzione è diverso da PyTorch, TensorFlow o MPI. La configurazione personalizzata del training distribuito (configurazione del training multinodo senza usare i framework di distribuzione precedenti) non è attualmente supportata.
- Per usare SSH, è necessaria una coppia di chiavi SSH. È possibile usare il comando
ssh-keygen -f "<filepath>"per generare una coppia di chiavi pubbliche e private.
Interagire con il contenitore di processi
Specificando applicazioni interattive durante la creazione del processo, è possibile connettersi direttamente al contenitore nel nodo di calcolo in cui è in esecuzione il processo. Dopo aver ottenuto l'accesso al contenitore dei processi, è possibile testare o eseguire il debug del processo nello stesso ambiente in cui verrebbe eseguito. È anche possibile usare VS Code per connettersi al processo in esecuzione ed eseguire il debug come si fa in locale.
Abilitare durante l'invio del processo
Creare un nuovo lavoro nel riquadro sinistro nel portale di "Studio".
Selezionare Cluster di elaborazione o Calcolo collegato (Kubernetes) come tipo di calcolo, scegliere la destinazione di calcolo e specificare il numero di nodi necessari in
Instance count.

Seguire la procedura guidata per scegliere l'ambiente desiderato per l'avvio del lavoro.
Nel passaggio Script di training aggiungere il codice di training (e i dati di input/output) e farvi riferimento nel comando per assicurarsi che sia montato nel processo.
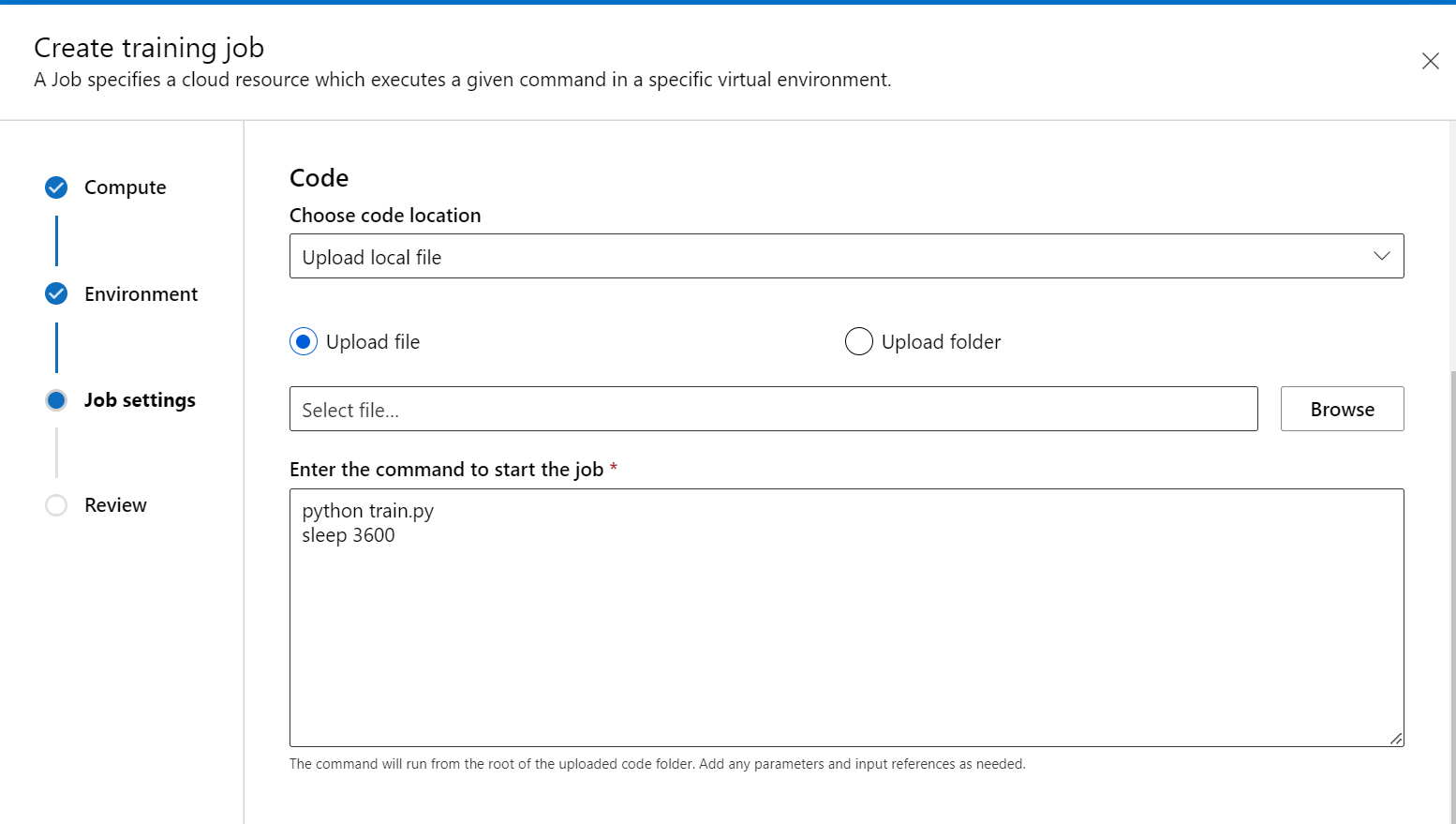
È possibile inserire sleep <specific time> alla fine del comando per specificare la quantità di tempo per cui si desidera riservare la risorsa di calcolo. Il formato è il seguente:
- dormire 1s
- dormire 1m
- dormire 1 ora
- dormire 1 giorno
È anche possibile usare il comando sleep infinity che manterrà il processo attivo per un periodo illimitato.
Nota
Se si usa sleep infinity, sarà necessario annullare manualmente il processo per consentire il passaggio della risorsa di calcolo (e arrestare la fatturazione).
- In impostazioni di Calcolo espandere l'opzione per Applicazioni di training. Selezionare almeno un'applicazione di training da usare per interagire con il processo. Se non si seleziona un'applicazione, la funzionalità di debug non sarà disponibile.
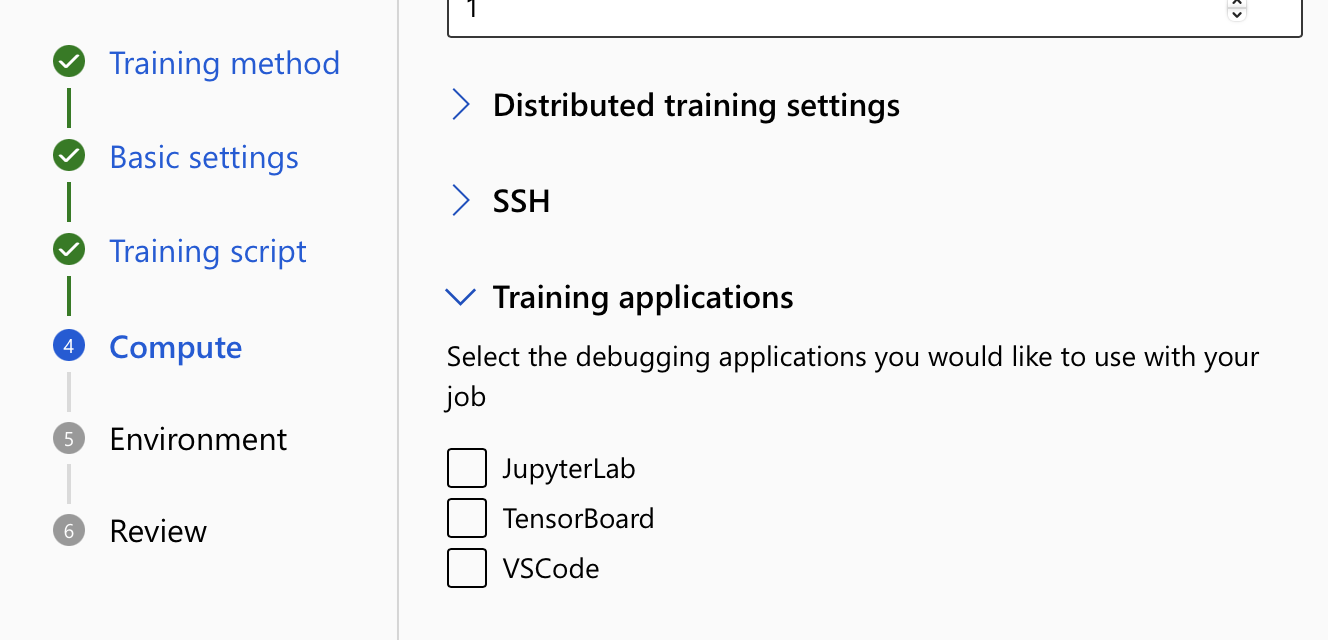
- Rivedere e creare il processo.
Connettersi agli endpoint
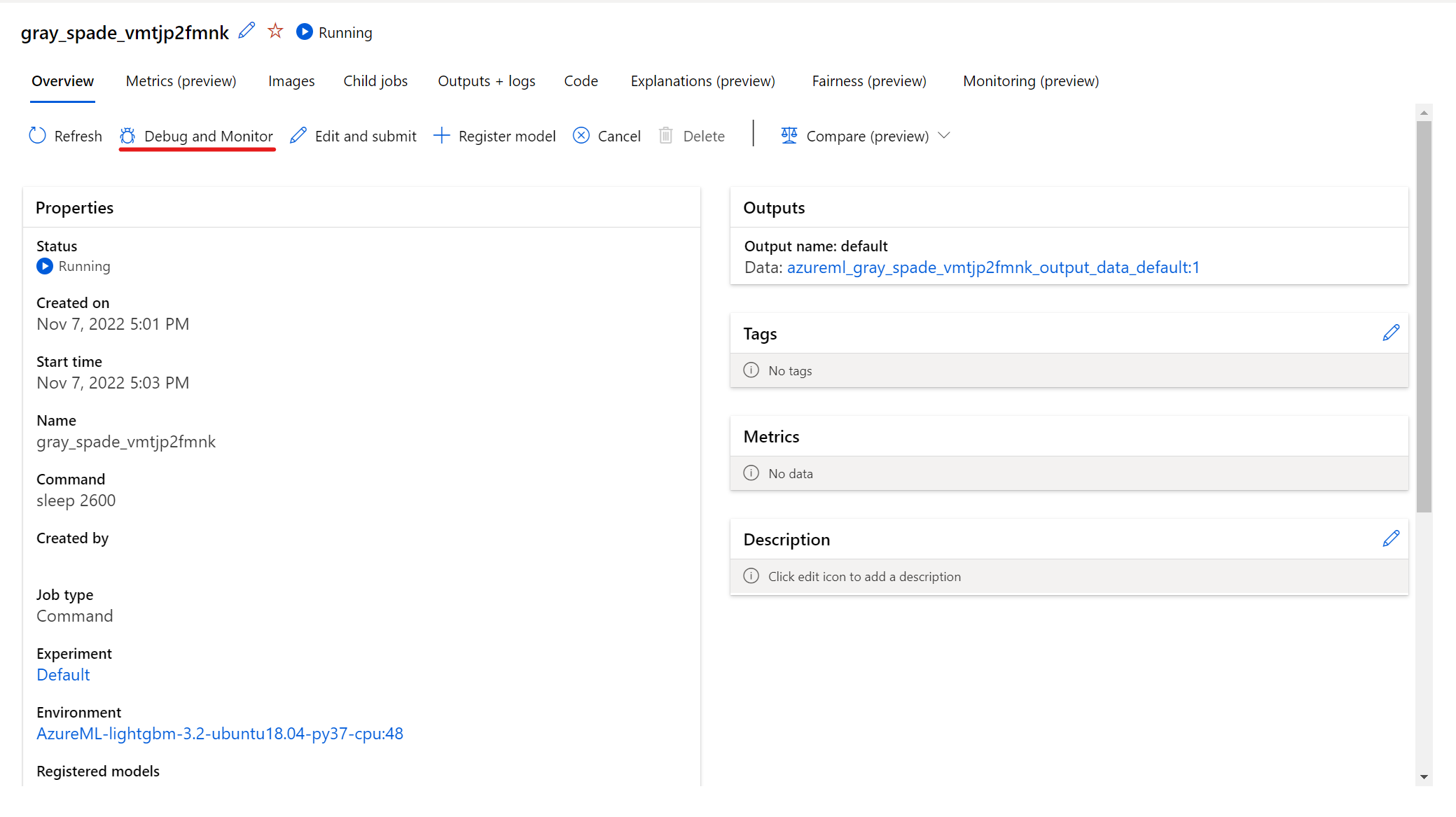
Per interagire con il processo in esecuzione, selezionare il pulsante Debug e monitoraggio nella pagina dei dettagli del processo.
Facendo clic sulle applicazioni nel pannello si apre una nuova scheda per le applicazioni. È possibile accedere alle applicazioni solo quando sono in stato In esecuzione e solo il proprietario del processo è autorizzato ad accedere alle applicazioni. Se si esegue il training su più nodi, è possibile selezionare il nodo specifico con cui si desidera interagire.
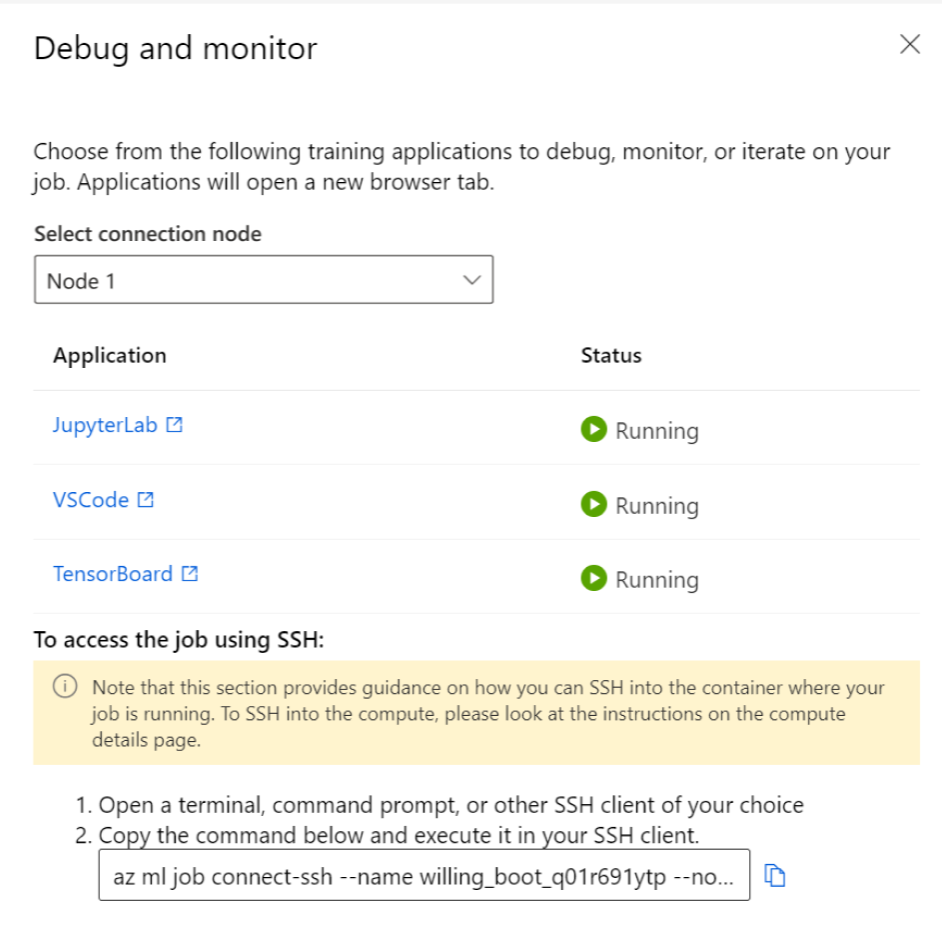
L'avvio del processo e delle applicazioni di training specificate durante la creazione del processo potrebbe richiedere alcuni minuti.
Interagire con le applicazioni
Quando si selezionano gli endpoint per interagire con il processo, si passa al contenitore utente nella directory di lavoro, in cui è possibile accedere al codice, agli input, agli output e ai log. Se si verificano problemi durante la connessione alle applicazioni, le funzionalità interattive e i registri delle applicazioni sono disponibili in system_logs-interactive_capability> nella scheda Output + log.
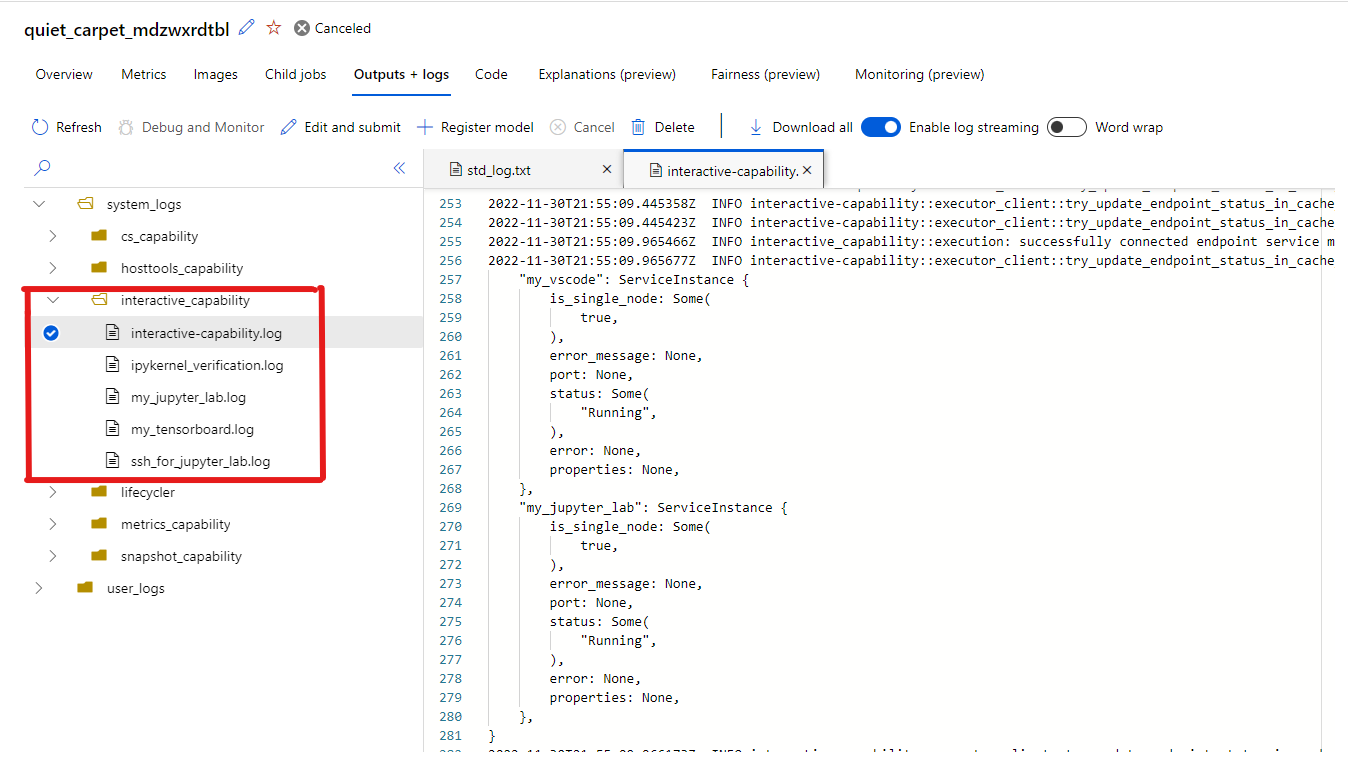
È possibile aprire un terminale da Jupyter Lab e iniziare a interagire all'interno del contenitore dei processi. È anche possibile eseguire direttamente l'iterazione sullo script di training con Jupyter Lab.

È anche possibile interagire con il contenitore dei processi all'interno di VS Code. Per collegare un debugger a un processo durante l'invio dello stesso e sospendere l'esecuzione, andare qui.
Nota
Le aree di lavoro abilitate per il collegamento privato non sono attualmente supportate durante l'interazione con il contenitore di processi con VS Code.

Se sono stati registrati eventi tensorflow per il processo, è possibile usare TensorBoard per monitorare le metriche quando il processo è in esecuzione.

Terminare un processo
Dopo aver completato il training interattivo, è anche possibile andare alla pagina dei dettagli del processo per annullare il suddetto; tale operazione rilascerà la risorsa di calcolo. In alternativa, usare az ml job cancel -n <your job name> nell'interfaccia della riga di comando o ml_client.job.cancel("<job name>") nell'SDK.

Collegare un debugger a un processo
Per inviare un processo con un debugger collegato e l'esecuzione sospesa, è possibile usare debugpy e VS Code (debugpy deve essere installato nell'ambiente del processo).
Nota
Le aree di lavoro abilitate per il collegamento privato non sono attualmente supportate quando si collega un debugger a un processo in VS Code.
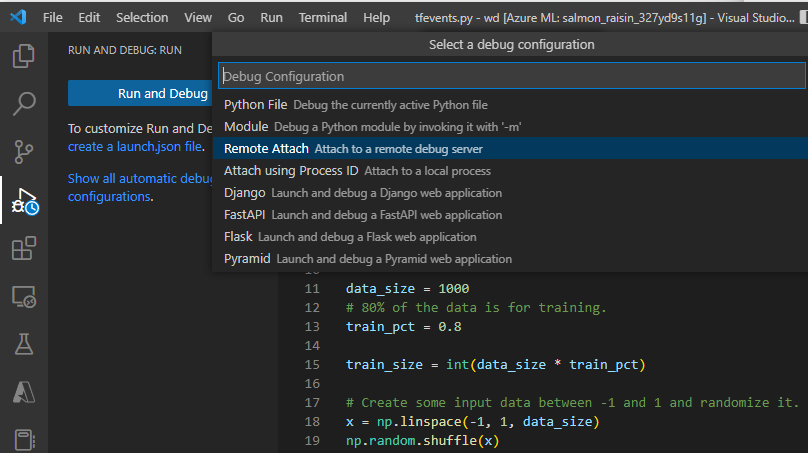
- Durante l'invio del processo (tramite l'interfaccia utente, l'interfaccia della riga di comando o l'SDK) usare il comando debugpy per eseguire lo script Python. Ad esempio, lo screenshot seguente mostra un comando di esempio che usa debugpy per collegare il debugger per uno script tensorflow (è possibile sostituire
tfevents.pycon il nome dello script di training).

Dopo l'invio del processo, connettersi al VS Code e selezionare il debugger integrato.

Usare la configurazione di debug "Collegamento remoto" per connettersi al processo inviato e passare il percorso e la porta configurati nel comando di invio del processo. È anche possibile trovare queste informazioni nella pagina dei dettagli del processo.

Impostare punti di interruzione e scorrere l'esecuzione del processo come si fa nel flusso di lavoro di debug locale.
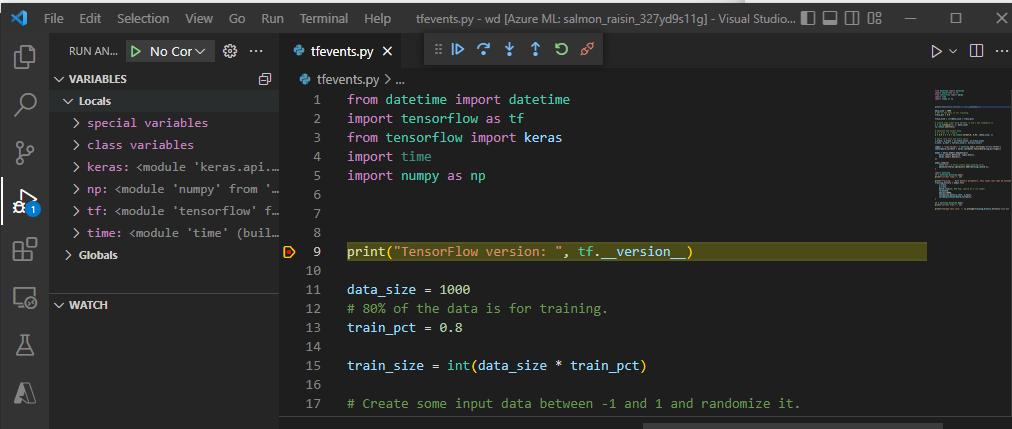
Nota
Se si usa debugpy per avviare il processo, il processo non verrà eseguito, a meno che non si alleghi il debugger in VS Code e si esegua lo script. Se questa operazione non viene eseguita, il calcolo verrà riservato fino all'annullamento del processo.
Passaggi successivi
- Altre informazioni su come e dove distribuire un modello.