Примечание.
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
В предыдущем разделе Как система управления ресурсами сопоставляет и выбирает ресурсы приводятся общие сведения о сопоставлении квалификаторов. В данном разделе основное внимание уделяется сопоставлению языковых тегов.
Введение
Ресурсы с квалификаторами тегов языка сравниваются и оцениваются на основе списка языков среды выполнения приложения. Определения различных языковых списков см. в разделе "Общие сведения о языках профилей пользователей" и языках манифеста приложения. Сопоставление первого языка в списке происходит перед сопоставлением второго языка в списке, даже для других региональных вариантов. Например, ресурс для en-GB выбирается для ресурса fr-CA, если язык среды выполнения приложения является en-US. Только если для формы en нет ресурсов для выбранного fr-CA (обратите внимание, что язык по умолчанию приложения не может быть задан для любой формы en в этом случае).
Механизм оценки использует данные, включенные в реестр подтегов BCP-47 и другие источники данных. Он позволяет забить градиент с различными качествами соответствия и, когда несколько кандидатов доступны, он выбирает кандидата с лучшим показателем соответствия.
Таким образом, вы можете пометить языковое содержимое в универсальных терминах, но при необходимости можно указать определенное содержимое. Например, приложение может иметь множество английских строк, которые являются общими для США, Великобритании и других регионов. Метка этих строк как en (английский) экономит пространство и затраты на локализацию. Если необходимо сделать различия, например в строке, содержащей слово "цвет или цвет", США и британские версии можно помечать отдельно с помощью подтег языка и региона, как "en-US" и "en-GB", соответственно.
Теги языка
Языки определяются с помощью нормализованных, хорошо сформированных тегов языка BCP-47. Компоненты подтега определяются в реестре подтегов BCP-47. Обычная структура для тега языка BCP-47 состоит из одного или нескольких следующих элементов подтега.
- Подтег языка (обязательно).
- Подтег скрипта (который может быть выведен с помощью значения по умолчанию, указанного в реестре подтегов).
- Подтег региона (необязательно).
- Подтег Variant (необязательно).
Дополнительные элементы подтега могут присутствовать, но они будут иметь незначительное влияние на сопоставление языка. Нет диапазонов языков, определенных с помощью подстановочной карточки (""), например "en-".
Сопоставление двух языков
При сравнении двух языков Windows обычно выполняется в контексте более крупного процесса. Он может находиться в контексте оценки нескольких языков, таких как при создании списка языков приложений Windows (см. раздел " Общие сведения о языках профилей пользователей" и языках манифеста приложения). Windows делает это путем сопоставления нескольких языков из параметров пользователя с языками, указанными в манифесте приложения. Сравнение также может находиться в контексте оценки языка вместе с другими квалификаторами для определенного ресурса. Один из примеров заключается в том, что Windows разрешает определенный файловый ресурс в определенный контекст ресурса; с домашним расположением пользователя или текущим масштабом или dpi устройства в качестве других факторов (помимо языка), которые учитываются в выборе ресурсов.
При сравнении двух языковых тегов сравнение назначается оценка на основе близкости совпадения.
| Поиск совпадений (Match) | Балл | Пример |
|---|---|---|
| Точное совпадение | Наиболее высокий | en-AU : en-AU |
| Совпадение вариантов (язык, скрипт, регион, вариант) | en-AU-variant1: en-AU-variant1-t-ja | |
| Сопоставление регионов (язык, скрипт, регион) | en-AU: en-AU-variant1 | |
| Частичное совпадение (язык, скрипт) | ||
| — сопоставление макрорегионов | en-AU: en-053 | |
| — нейтральная область совпадения | en-AU : en | |
| — соответствие ортографических сопоставлений (ограниченная поддержка) | en-AU : en-GB | |
| — сопоставление предпочтительного региона | en-AU : en-US | |
| — любое соответствие региона | en-AU : en-CA | |
| Неопределенный язык (любое соответствие языка) | en-AU : und | |
| Нет совпадения (несоответствие скрипта или несоответствие тега основного языка) | Наиболее низкий | en-AU : fr-FR |
Точное совпадение
Теги равны (все элементы подтега совпадают). Сравнение может быть повышено до этого типа соответствия из варианта или сопоставления региона. Например, en-US соответствует en-US.
Совпадение вариантов
Теги соответствуют языку, скрипту, региону и подтегам вариантов, но они отличаются в некотором другом отношении.
Сопоставление регионов
Теги соответствуют подтегам языка, скрипта и региона, но они отличаются в другом отношении. Например, de-DE-1996 соответствует de-DE и en-US-x-Pirate совпадения en-US.
Частичные совпадения
Теги соответствуют подтегам языка и скрипта, но они отличаются в регионе или в другом подтеге. Например, совпадения en-US или en-US совпадают с en-*.
Сопоставление макрорегионов
Теги соответствуют подтегам языка и скрипта; оба тега имеют подтеги региона, один из которых обозначает макрос, охватывающий другой регион. Подтеги макрорегион всегда числовые и являются производными от кодов стран и областей Отдела статистики Организации Объединенных Наций M.49. Дополнительные сведения о охватывающих отношениях см. в разделе "Композиция географических географических (континентальных) регионов", географических подрегиов и выбранных экономических и других групп.
Обратите внимание , что коды ООН для "экономических групп" или "других групп" не поддерживаются в BCP-47.
Обратите внимание, что тег с подтегом макрорегион "001" считается эквивалентным тегу с нейтральным регионом. Например, "es-001" и "es" рассматриваются как синонимы.
Сопоставление с нейтральным регионом
Теги соответствуют подтегам языка и скрипта, а только один тег имеет тег региона. Родительское совпадение предпочтительнее для других частичных совпадений.
Соответствие ортографических сопоставлений
Теги соответствуют подтегам языка и скрипта, а подтеги региона имеют илитографическое сходство. Сходство зависит от данных, поддерживаемых в Windows, определяющих связанные с языком регионы, например en-IE и en-GB.
Сопоставление предпочтительных регионов
Теги соответствуют подтегам языка и скрипта, а один из подтегов региона — подтег региона по умолчанию для языка. Например, "fr-FR" — это регион по умолчанию для подтега fr. Таким образом, fr-FR лучше подходит для fr-BE, чем fr-CA. Это зависит от данных, поддерживаемых в Windows, определяющих регион по умолчанию для каждого языка, в котором локализована Windows.
Совпадение с братом
Теги совпадают с подтегами языка и скрипта, и оба имеют подтеги регионов, но между ними нет других связей. В случае нескольких совпадений, последний перечисленный брат будет победителем, в отсутствие более высокого соответствия.
Неопределенный язык
Ресурс может быть помечен как "und", чтобы указать, что он соответствует любому языку. Этот тег также можно использовать с тегом скрипта для фильтрации совпадений на основе скрипта. Например, "und-Latn" будет соответствовать любому тегу языка, использующего латинский скрипт. Дополнительные сведения см. ниже.
Несоответствие скрипта
Если теги совпадают только с тегом первичного языка, но не скриптом, пара считается не совпадать и оценивается ниже уровня допустимого совпадения.
Нет совпадения.
Несоответствие подтег первичного языка оценивается ниже уровня допустимого совпадения. Например, zh-Hant не соответствует zh-Hans.
Примеры
Язык пользователя "zh-Hans-CN" (китайский упрощенный (Китай)) соответствует следующим ресурсам в указанном порядке приоритета. X указывает, что совпадения не совпадают.
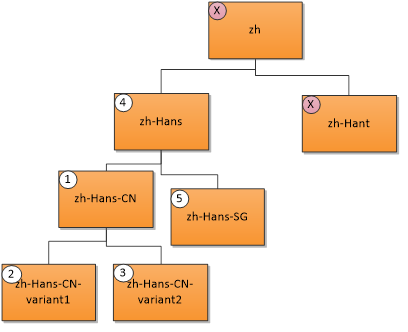
- Точное совпадение; 2. & 3. Соответствие региона; 4. Родительское совпадение; 5. Совпадение с братом.
Если подтег языка имеет значение Suppress-Script, определенное в реестре подтегов BCP-47, происходит соответствующее сопоставление, принимая значение отложенного кода скрипта. Например, en-Latn-US соответствует en-US. В следующем примере язык пользователя — en-AU (английский (Австралия)).
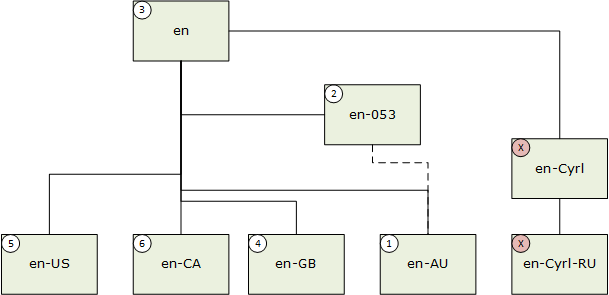
- Точное совпадение; 2. Сопоставление макросов; 3. Нейтральное по регионам совпадение; 4. Соответствие ортографических сопоставлений; 5. Сопоставление предпочтительного региона; 6. Совпадение с братом.
Сопоставление языка со списком языков
Иногда сопоставление происходит в рамках более крупного процесса сопоставления одного языка со списком языков. Например, может быть совпадение одного языкового ресурса со списком языков приложения. Оценка совпадения взвешна положением первого соответствующего языка в списке. Чем ниже язык находится в списке, тем ниже будет оценка.
Если список языков содержит два или более региональных вариантов с одинаковыми подтегами языка и скрипта, сравнения для первого тега языка оцениваются только для точных, вариантов и регионов. Оценка частичных матчей откладывается до последнего регионального варианта. Это позволяет пользователям точно управлять поведением сопоставления для списка языков. Поведение сопоставления может включать в себя разрешение точного совпадения для дополнительного элемента в списке, которое предпочтительнее, чем частичное совпадение для первого элемента в списке, если есть третий элемент, соответствующий языку и скрипту первого. Рассмотрим пример.
- Список языков (в порядке): "pt-PT" (португальский (Португалия)), "en-US" (английский (США)), "pt-BR" (португальский (Бразилия)).
- Ресурсы: en-US, pt-BR.
- Ресурс с более высокой оценкой: en-US.
- Описание. Сравнение начинается с "pt-PT", но не находит точного соответствия. Из-за наличия "pt-BR" в списке языков пользователя частичное сопоставление откладывается на сравнение с "pt-BR". Следующее сравнение языка — en-US, которое имеет точное совпадение. Таким образом, выигрышный ресурс является "en-US".
ИЛИ
- Список языков (в порядке): "es-MX" (испанский (Мексика)), "es-HO" (испанский (Гондурас)).
- Ресурсы: en-ES, es-HO.
- Ресурс с более высокой оценкой: "es-HO".
Неопределенный язык ("und")
Тег языка "und" может использоваться для указания ресурса, который будет соответствовать любому языку в отсутствие лучшего соответствия. Его можно считать похожим на диапазон языка BCP-47 "" или "-<script>". Рассмотрим пример.
- Список языков: en-US, "zh-Hans-CN".
- Ресурсы: "zh-Hans-CN", "und".
- Ресурс с более высокой оценкой: "und".
- Описание. Сравнение начинается с "en-US", но не находит совпадение на основе "en" (частично или лучше). Так как ресурс имеет тег "und", алгоритм сопоставления использует это.
Тег "und" позволяет нескольким языкам совместно использовать один ресурс и позволяет рассматривать отдельные языки как исключения. Например,
- Список языков: "zh-Hans-CN", "en-US".
- Ресурсы: "zh-Hans-CN", "und".
- Ресурс с более высокой оценкой: "zh-Hans-CN".
- Описание. Сравнение находит точное совпадение для первого элемента, поэтому он не проверяет наличие ресурса с меткой "und".
Вы можете использовать "und" с тегом скрипта для фильтрации ресурсов по скрипту. Например,
- Список языков: "ru".
- Ресурсы: "und-Latn", "und-Cyrl", "und-Arab".
- Ресурс с более высокой оценкой: "und-Cyrl".
- Описание. Сравнение не находит совпадение для "ru" (частично или лучше), поэтому соответствует тегу языка "und". Значение подавления скрипта "Cyrl", связанное с тегом языка "ru", соответствует ресурсу "und-Cyrl".
Ортографическое региональное сходство
При сопоставлении двух тегов языка с различиями подтегов региона определенные пары регионов могут иметь более высокое сходство друг с другом, чем другие. Для английского языка ("en") поддерживаются только поддерживаемые группы с сопоставлением. Подтеги региона "PH" (Филиппины) и "LR" (Либерия) имеют илитографическое сходство с подтегом региона "США". Все остальные подтеги региона совпадают с подтегом региона "GB" (Соединенное Королевство). Таким образом, если доступны ресурсы en-US и en-GB, список языков en-HK (английский (Гонконг САР)) получит более высокую оценку с ресурсами en-GB, чем с ресурсами en-US.
Обработка языков с множеством региональных вариантов
Некоторые языки имеют большие общины говорящего в разных регионах, которые используют различные разновидности этого языка, такие как английский, французский и испанский языки, которые наиболее часто поддерживаются в многоязычных приложениях. Региональные различия могут включать различия в ортографии (например, "цвет" и "цвет") или различия диалекта, такие как словарь (например, "грузовик" и "грузовик").
Эти языки со значительными региональными вариантами представляют определенные проблемы при создании приложения, готового к миру: "Сколько различных региональных вариантов следует поддерживать?" "Какие?" "Что является наиболее экономичным способом управления этими региональными вариантными ресурсами для моего приложения?" Это выходит за рамки этой статьи, чтобы ответить на все эти вопросы. Однако механизмы сопоставления языков в Windows предоставляют возможности, которые помогут вам в обработке региональных вариантов.
Приложения часто поддерживают только один вариант любого языка. Предположим, что приложение имеет ресурсы только для одного из различных языков, которые, как ожидается, будут использоваться английскими ораторами независимо от того, какой регион они есть. В этом случае тег "en" без подтега региона будет отражать это ожидание. Но приложения, возможно, исторически использовали тег, например en-US, который включает подтег региона. В этом случае приложение также будет работать: приложение использует только один ряд английского языка, и Windows обрабатывает сопоставление ресурса, помеченного для одного регионального варианта, с предпочтениями пользовательского языка для другого регионального варианта соответствующим образом.
Если будет поддерживаться два или более региональных разновидностей, однако разница, например en и en-US, может оказать значительное влияние на взаимодействие с пользователем, и важно учитывать, какие подтеги региона следует использовать.
Предположим, вы хотите предоставить отдельные французские локализации для французского языка, как используется в Канаде и европейском французском. Для канадского французского языка можно использовать "fr-CA". Для докладчиков из Европы локализация будет использовать французский (Франция), и поэтому для этого можно использовать "fr-FR". Но что делать, если данный пользователь из Бельгии, с предпочтением языка fr-BE; что они получат? Регион BE отличается от "FR" и "ЦС", предлагая совпадение "любой регион" для обоих. Тем не менее, Франция является предпочтительным регионом для французского, и поэтому "fr-FR" будет считаться лучшим матчем в этом случае.
Предположим, что вы сначала локализовали приложение только для одного из различных французских строк, используя французские строки (Франция), но квалифицируйте их как "fr", а затем хотите добавить поддержку канадского французского языка. Вероятно, для канадского французского языка необходимо повторно перевести только определенные ресурсы. Вы можете продолжать использовать все исходные ресурсы, сохраняя их как "fr", и просто добавить небольшой набор новых ресурсов с помощью fr-CA. Если предпочтительный язык пользователя — fr-CA, то ресурс fr-CA будет иметь более высокую оценку соответствия, чем ресурс fr. Но если предпочтительный язык пользователя предназначен для любого другого разнообразия французского языка, то ресурс fr с нейтральным регионом будет лучше, чем ресурс fr-CA.
В качестве другого примера предположим, что вы хотите предоставить отдельные локализации испанского языка для докладчиков из Испании и ораторов из Латинской Америки. Предположим, что переводы для Латинской Америки были предоставлены поставщиком в Мексике. Следует ли использовать "es-ES" (Испания) и "es-MX" (Мексика) для двух наборов ресурсов? Если бы вы сделали, это может создать проблемы для докладчиков из других латиноамериканских регионов, таких как Аргентина или Колумбия, так как они получат ресурсы "es-ES". В этом случае существует более эффективная альтернатива: вы можете использовать подтег макрорегион", "es-419", чтобы отразить, что ресурсы будут использоваться для докладчиков из любой части Латинской Америки или Карибского бассейна.
Теги языка, не зависящие от региона, и подтеги макрорегионов могут быть очень эффективными, если вы хотите поддерживать несколько региональных разновидностей. Чтобы свести к минимуму количество необходимых ресурсов, можно квалифицировать данный ресурс таким образом, чтобы отразить наиболее широкий охват, для которого он применим. Затем дополните широко применимый ресурс более конкретным вариантом по мере необходимости. Ресурс с квалификатором языка, нейтральным регионом, будет использоваться для пользователей любого регионального разнообразия, если нет другого ресурса с более региональным квалификатором, применяемым к пользователю. Например, ресурс en будет соответствовать австралийскому английскому пользователю, но актив с "en-053" (английский как используемый в Австралии или Новой Зеландии) будет лучше подходит для этого пользователя, а актив с "en-AU" будет лучшим совпадением.
Для английского языка требуется особое внимание. Если приложение добавляет локализацию для двух разновидностей английского языка, они, скорее всего, будут использоваться для английского языка США и великобритании или "международного", английского языка. Как отмечалось выше, некоторые регионы за пределами США следуют США соглашениям о правописании, и сопоставление языков Windows учитывает это. В этом сценарии не рекомендуется использовать нейтральный регион тега en для одного из вариантов; вместо этого используйте en-GB и en-US. (Если для заданного ресурса не требуются отдельные варианты, однако можно использовать "en".) Если "en-GB" или "en-US" заменяется на "en", то это будет мешать ортографической региональной сходство, предоставленной Windows. Если добавлена третья локализация на английском языке, используйте подтег конкретного или макроса для дополнительных вариантов (например, en-CA, en-AU или en-053), но продолжайте использовать en-GB и en-US.