Примечание.
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
- Точное профилирование Direct3D является сложной задачей
- Как точно профилировать последовательность отрисовки Direct3D
- Профилирование изменений состояния Direct3D
- Сводка
- Приложение
После того как у вас есть функциональное приложение Microsoft Direct3D и вы хотите повысить его производительность, вы обычно используете готовое средство профилирования или какие-либо специальные методы измерения, чтобы определить время, необходимое для выполнения одного или нескольких вызовов интерфейса программирования приложений (API). Если вы сделали это, но получаете результаты, которые отличаются от одной последовательности отрисовки к следующей, или вы делаете предположения, которые не подтверждаются фактическими результатами эксперимента, следующие сведения могут помочь вам понять, почему.
Приведенные здесь сведения основаны на предположении, что у вас есть знания и опыт работы со следующими сведениями:
- Программирование на C/C++
- Программирование API Direct3D
- Измерение времени API
- Видеокарта и его драйвер программного обеспечения
- Возможные необъяснимые результаты из предыдущего опыта профилирования
Точное профилирование Direct3D сложно
Профилировщик сообщает о времени, затраченном на каждый вызов API. Это делается для повышения производительности путем поиска и настройки горячих точек. Существуют различные виды профилировщиков и методов профилирования.
- Профилировщик выборки бездействует большую часть времени, просыпаясь через определенные интервалы для выборки (или записи) выполняемых функций. Он возвращает процент времени, затраченного на каждый вызов. Как правило, профилировщик выборки не является очень инвазивным для приложения и имеет минимальное влияние на издержки для приложения.
- Профилировщик инструментирования измеряет фактическое время, которое требуется для возврата вызова. Для этого требуется компиляция разделителей запуска и остановки в приложение. Профилировщик инструментирования является сравнительно более инвазивным для приложения, чем профилировщик выборки.
- Также можно использовать настраиваемый метод профилирования с высокопроизводительным таймером. Это дает результаты, аналогичные инструментальному профилировщику.
Используемый тип профилировщика или метода профилирования является лишь частью задачи получения точных измерений.
Профилирование дает ответы, которые помогут вам повысить производительность бюджета. Например, предположим, что вызов API в среднем составляет тысячу тактовых циклов для выполнения. Вы можете подтвердить некоторые выводы о производительности, например следующее:
- ЦП с тактовой частотой 2 ГГц (который тратит 50 процентов времени на отрисовку) ограничен вызовом этого API 1 миллион раз в секунду.
- Чтобы достичь 30 кадров в секунду, нельзя вызывать этот API более 33 000 раз за кадр.
- Вы можете отрисовать только 3,3K объектов за кадр (при условии 10 вызовов API на последовательность отрисовки каждого объекта).
Другими словами, если у вас было достаточно времени на вызов API, можно ответить на вопрос бюджетирования, например количество примитивов, которые можно отобразить в интерактивном режиме. Но необработанные числа, возвращаемые инструментальным профилировщиком, не дадут точных ответов на вопросы бюджета. Это связано с тем, что графический конвейер имеет сложные проблемы проектирования, такие как количество компонентов, необходимых для работы, количество процессоров, которые управляют потоками работы между компонентами и стратегиями оптимизации, реализованными в среде выполнения и в драйвере, который предназначен для повышения эффективности конвейера.
Каждый вызов API проходит через несколько компонентов
Каждый вызов обрабатывается несколькими компонентами по пути от приложения к видеокарте. Например, рассмотрим следующую последовательность отрисовки, содержащую два вызова для рисования одного треугольника:
SetTexture(...);
DrawPrimitive(D3DPT_TRIANGLELIST, 0, 1);
На следующей концептуальной схеме показаны различные компоненты, через которые должны проходить вызовы.

Приложение вызывает Direct3D, который управляет сценой, обрабатывает взаимодействие пользователей и определяет, как выполняется отрисовка. Все эти действия указываются в последовательности отрисовки, которая отправляется в среду выполнения с помощью вызовов API Direct3D. Последовательность отрисовки является практически аппаратно независимой (то есть вызовы API аппаратно независимы, но приложение знает, какие функции поддерживаются видеокартой).
Среда выполнения преобразует эти вызовы в независимый от устройства формат. Среда выполнения обрабатывает все взаимодействие между приложением и драйвером, чтобы приложение выполнялось на нескольких совместимых аппаратных компонентах (в зависимости от необходимых функций). При измерении вызова функции профилировщик инструментирования измеряет время, затраченное на функцию, а также время возврата функции. Ограничение профилировщика инструментирования состоит в том, что он может не учитывать время, которое требуется драйверу для отправки полученной задачи на видеокарту, а также время, необходимое видеокарте для обработки этой задачи. Другими словами, готовый инструментальный профилировщик не может правильно распределить всю работу, связанную с каждым вызовом функции.
Драйвер программного обеспечения использует аппаратные знания о видеокарте для преобразования независимых от устройств команд в последовательность команд видеокарты. Драйверы также могут оптимизировать последовательность команд, отправляемых на видеокарту, чтобы эффективно выполнять отрисовку на видеокарте. Эти оптимизации могут привести к проблемам профилирования, так как объем выполненных работ не является тем, что он, как представляется, (возможно, потребуется понять оптимизации для их учета). Драйвер обычно возвращает управление средой выполнения, прежде чем видеокарта завершит обработку всех команд.
Видеокарта выполняет большую часть отрисовки путем объединения данных из буферов вершин и индексов, текстур, сведений о состоянии отрисовки и графических команд. Когда видеокарта завершит отрисовку, работа, созданная в результате последовательности отрисовки, завершена.
Каждый вызов API Direct3D должен обрабатываться каждым компонентом (средой выполнения, драйвером и видеокартой), чтобы отобразить все.
Существует несколько процессоров, управляющих компонентами
Связь между этими компонентами еще более сложна, так как приложение, среда выполнения и драйвер управляются одним процессором, а видеокарта управляется отдельным процессором. На следующей схеме показаны два типа процессоров: центральный модуль обработки (ЦП) и графический модуль обработки (GPU).
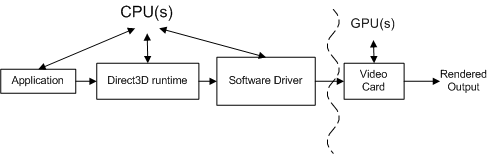
Компьютерные системы имеют по крайней мере один ЦП и один GPU, но могут иметь несколько из одного или обоих. Процессоры находятся на материнской плате, и GPU находятся либо на материнской плате, либо на видеокарте. Скорость ЦП определяется тактовой микросхемой на материнской плате, а скорость ГП определяется отдельной тактовой микросхемой. Часы ЦП управляют скоростью работы, выполняемой приложением, средой выполнения и драйвером. Приложение отправляет работу на GPU через среду выполнения и драйвер.
ЦП и GPU обычно выполняются на разных скоростях, независимо друг от друга. GPU может реагировать на работу, как только работа доступна (если GPU завершил обработку предыдущей работы). Работа с GPU выполняется параллельно с работой ЦП, как выделено кривой линией на рисунке выше. Профилировщик обычно измеряет производительность ЦП, а не GPU. Это затрудняет профилирование, так как измерения, сделанные инструментальным профилировщиком, включают время центрального процессора, но могут не включать время графического процессора.
Цель GPU — разгрузить обработку с ЦП на процессор, специально предназначенный для работы с графикой. На современных видеокартках GPU заменяет большую часть преобразования и освещения в конвейере от ЦП к GPU. Это значительно сокращает рабочую нагрузку ЦП, оставляя больше циклов ЦП доступными для другой обработки. Чтобы настроить графическое приложение для пиковой производительности, необходимо измерить производительность ЦП и GPU, а также сбалансировать работу между двумя типами процессоров.
В этом документе не рассматриваются разделы, связанные с измерением производительности GPU или балансировкой работы между ЦП и GPU. Если вы хотите лучше понять производительность GPU (или конкретной видеокарты), посетите веб-сайт поставщика, чтобы найти дополнительные сведения о производительности GPU. Вместо этого в этом документе основное внимание уделяется работе, выполняемой средой выполнения и драйвером, сокращая работу GPU до незначительной суммы. Это, в частности, на основе опыта, что приложения, испытывающие проблемы с производительностью, обычно ограничены ЦП.
Оптимизации в среде выполнения и драйверах могут маскировать показатели API.
Среда выполнения имеет механизм оптимизации производительности, который может существенно влиять на оценку выполнения отдельного вызова. Ниже приведен пример сценария, демонстрирующего эту проблему. Рассмотрим следующую последовательность отрисовки:
BeginScene();
...
SetTexture(...);
DrawPrimitive(D3DPT_TRIANGLELIST, 0, 1);
...
EndScene();
Present();
Пример 1. Простая последовательность отрисовки
Рассматривая результаты двух вызовов в последовательности отрисовки, инструментальный профилировщик может возвращать результаты, похожие на эти.
Number of cycles for SetTexture : 100
Number of cycles for DrawPrimitive : 950,500
Профилировщик возвращает количество циклов ЦП, необходимых для обработки работы, связанной с каждым вызовом (помните, что GPU еще не включен в эти числа, так как GPU еще не работал над этими командами). Поскольку IDirect3DDevice9::DrawPrimitive требуется почти миллион циклов для обработки, можно заключить, что это не очень эффективно. Однако вскоре вы увидите, почему это заключение неправильно и как можно создавать результаты, которые можно использовать для бюджетирования.
Для измерения изменений состояния требуются тщательные последовательности отрисовки
Все вызовы, отличные от IDirect3DDevice9::DrawPrimitive, DrawIndexedPrimitiveили Clear (например, SetTexture, SetVertexDeclarationи SetRenderState), вызывают изменение состояния. Каждое изменение состояния задает состояние конвейера, которое управляет выполнением отрисовки.
Оптимизации во время выполнения и (или) драйвер предназначены для ускорения отрисовки путем уменьшения объема необходимой работы. Ниже приведены несколько оптимизаций изменений состояния, которые могут загрязнять средние показатели профиля:
- Драйвер (или среда выполнения) может сохранить изменение состояния в качестве локального состояния. Поскольку драйвер может работать в "ленивом" режиме (откладывая выполнение работы до тех пор, пока это не станет абсолютно необходимым), работа, связанная с некоторыми изменениями состояния, может быть задержана.
- Среда выполнения (или драйвер) может удалять изменения состояния путем оптимизации. Примером этого может быть удаление избыточного изменения состояния, которое отключает освещение, так как освещение ранее было отключено.
Нет надежного способа, чтобы просмотреть последовательность отрисовки и определить, какие изменения состояния будут устанавливать грязные биты и откладывать работу, или просто будут удалены оптимизацией. Даже если вы можете определить оптимизированные изменения состояния в текущей среде выполнения или драйвере, завтрашняя среда выполнения или драйвер, скорее всего, будет обновлена. Вы также не знаете точно, каким было предыдущее состояние, поэтому сложно определить избыточные изменения состояния. Единственный способ проверить стоимость изменения состояния — измерить последовательность отрисовки, в которую включены изменения состояния.
Как вы видите, осложнения, вызванные несколькими процессорами, командами, обрабатываемыми несколькими компонентами, и оптимизациями, встроенными в компоненты, затрудняет прогнозирование профилирования. В следующем разделе будут рассмотрены все эти проблемы профилирования. Будут показаны примеры последовательностей отрисовки Direct3D с сопутствующими методами измерения. С помощью этих знаний вы сможете создавать точные повторяемые измерения при отдельных вызовах.
Как точно профилировать последовательность отрисовки Direct3D
Теперь, когда были выделены некоторые из проблем профилирования, в этом разделе показаны методы, которые помогут вам создать измерения профиля, которые можно использовать для бюджетирования. Точные повторяющиеся измерения профилирования возможны, если вы понимаете связь между компонентами, контролируемыми ЦП, и как избежать оптимизации производительности, реализованной средой выполнения и драйвером.
Чтобы начать, необходимо точно измерять время выполнения одного вызова API.
Выбор средства точного измерения, например QueryPerformanceCounter
Операционная система Microsoft Windows включает таймер высокого разрешения, который можно использовать для измерения прошедшего времени с высоким разрешением. Текущее значение одного такого таймера можно вернуть с помощью QueryPerformanceCounter. После вызова QueryPerformanceCounter для получения значений начала и окончания, разница между двумя значениями может быть преобразована в фактическое затраченное время (в секундах) с помощью QueryPerformanceCounter.
Преимущества использования QueryPerformanceCounter заключается в том, что он доступен в Windows и легко использовать. Просто оберните вызовы с помощью вызова QueryPerformanceCounter и сохраните значения начала и окончания. Поэтому в этой статье будет продемонстрировано, как использовать QueryPerformanceCounter для профилирования времени выполнения, аналогично тому, как это измерял бы инструментальный профилировщик. Ниже приведен пример внедрения QueryPerformanceCounter в исходный код:
BeginScene();
...
// Start profiling
LARGE_INTEGER start, stop, freq;
QueryPerformanceCounter(&start);
SetTexture(...);
DrawPrimitive(D3DPT_TRIANGLELIST, 0, 1);
QueryPerformanceCounter(&stop);
stop.QuadPart -= start.QuadPart;
QueryPerformanceFrequency(&freq);
// Stop profiling
...
EndScene();
Present();
Пример 2. Реализация пользовательского профилирования с помощью QPC
start и stop — это два больших целых числа, которые будут содержать значения начала и остановки, возвращаемые таймером высокой производительности. Обратите внимание, что QueryPerformanceCounter(&start) вызывается непосредственно перед вызовом SetTexture и QueryPerformanceCounter(&stop) сразу после DrawPrimitive. После получения значения остановки вызывается функция QueryPerformanceFrequency, возвращающая "freq", который является частотой таймера высокого разрешения. В этом гипотетическом примере предположим, что вы получите следующие результаты для запуска, остановки и freq:
| Локальная переменная | Количество галок |
|---|---|
| начало | 1792998845094 |
| остановка | 1792998845102 |
| Частота | 3579545 |
Эти значения можно преобразовать в число циклов, которые требуется для выполнения вызовов API следующим образом:
# ticks = (stop - start) = 1792998845102 - 1792998845094 = 8 ticks
# cycles = CPU speed * number of ticks / QPF
# 4568 = 2 GHz * 8 / 3,579,545
Другими словами, для обработки SetTexture и DrawPrimitive на этом компьютере с тактовой частотой 2 ГГц требуется около 4568 тактовых циклов. Эти значения можно преобразовать в фактическое время выполнения всех вызовов следующим образом:
(stop - start)/ freq = elapsed time
8 ticks / 3,579,545 = 2.2E-6 seconds or between 2 and 3 microseconds.
При использовании QueryPerformanceCounter необходимо добавить начальные и стоп-измерения в последовательность отрисовки и использовать QueryPerformanceFrequency для преобразования разницы (число тиков) в число циклов ЦП или в фактическое время. Определение метода измерения является хорошим началом для разработки пользовательской реализации профилирования. Прежде чем приступать к измерениям, необходимо знать, как обращаться с видеокартой.
Фокус на измерениях ЦП
Как упоминалось ранее, ЦП и GPU работают параллельно, чтобы обрабатывать работу, созданную вызовами API. Для реального приложения требуется профилирование обоих типов процессоров, чтобы узнать, ограничено ли приложение ЦП или GPU. Так как производительность GPU зависит от поставщика, было бы очень сложно создать результаты в этом документе, который охватывает различные доступные видеокарты.
Вместо этого в этом документе основное внимание будет сосредоточено только на профилировании работы, выполняемой ЦП, с помощью пользовательского метода измерения работы среды выполнения и драйвера. Работа GPU будет сокращена до незначительного объема, чтобы результаты ЦП были более видимыми. Одним из преимуществ этого подхода является то, что этот метод дает результаты в приложении, которое вы должны иметь возможность сопоставить с вашими измерениями. Чтобы уменьшить работу, выполняемую видеокартой, до уровня, который можно считать незначительным, просто сократите объем отрисовки до минимального. Это можно сделать путем ограничения вызовов рисования для отрисовки одного треугольника и может быть дополнительно ограничено, чтобы каждый треугольник содержал только один пиксель.
Единица измерения, используемая в этом документе для измерения работы ЦП, будет число циклов часов ЦП, а не фактического времени. Циклы тактового сигнала ЦП имеют преимущество в том, что они более переносимы (для приложений, ограниченных ЦП), чем затраченное фактическое время на устройствах с разными скоростями ЦП. Это можно легко преобразовать в фактическое время при необходимости.
В этом документе не рассматриваются разделы, связанные с балансировкой рабочей нагрузки между ЦП и GPU. Помните, что цель этого документа заключается не в том, чтобы оценить общую производительность приложения, но показать, как точно измерять время, затраченное средой выполнения и драйвером для обработки вызовов API. С помощью этих точных измерений можно взять на себя задачу бюджетирования ЦП, чтобы понять определенные сценарии производительности.
Управление оптимизацией среды выполнения и драйвера
После определения метода измерения и разработки стратегии сокращения работы GPU, следующим шагом будет понимание оптимизаций среды выполнения и драйвера, которые мешают при профилировании.
Работа ЦП может быть разделена на три сегмента: работа приложения, работа среды выполнения и работа драйвера. Игнорируйте работу приложения, так как это находится под контролем программиста. С точки зрения приложения среда выполнения и драйвер похожи на черные ящики, так как приложение не имеет контроля над тем, что реализовано в них. Ключ заключается в том, чтобы понять методы оптимизации, которые могут быть реализованы в среде выполнения и драйвере. Если вы не понимаете эти оптимизации, очень легко прийти к неправильному выводу о том, какой объём работы выполняется ЦП на основе измерений профиля. В частности, существует два раздела, связанные с чем-то, что называется буфером команд, и что это может сделать для маскирования профилирования. Ниже приведены следующие разделы:
- Оптимизация среды выполнения с помощью буфера команд. Буфер команд — это оптимизация среды выполнения, которая снижает влияние перехода в режиме. Чтобы управлять моментом перехода режима, см. Управление буфером команд.
- Отрицание эффектов времени буфера команд. Время, затраченное на переход между режимами, может оказать значительное влияние на методы профилирования. Стратегия заключается в том, чтобы сделать последовательность отрисовки большой по сравнению с переходом в режиме.
Управление буфером команд
Когда приложение делает вызов API, среда выполнения преобразует вызов API в независимый от устройства формат (который мы назовем командой) и сохраняет его в буфере команд. Буфер команд добавляется на следующую схему.
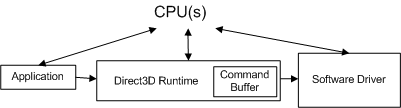
Каждый раз, когда приложение вызывает другой вызов API, среда выполнения повторяет эту последовательность и добавляет другую команду в буфер команд. В какой-то момент среда выполнения очищает буфер (отправляя команды драйверу). В Windows XP очистка командного буфера вызывает переход режима, так как операционная система переключается с режима выполнения (в пользовательский режим) на драйвер (работающий в режиме ядра), как показано на следующей схеме.
- режим пользователя — не привилегированный режим процессора, который выполняет код приложения. Приложения в режиме пользователя не могут получить доступ к системным данным, кроме системных служб.
- режим ядра — режим привилегированного процессора, в котором выполняется исполнительный код на основе Windows. Драйвер или поток, работающий в режиме ядра, имеет доступ ко всем системным памяти, прямой доступ к оборудованию и инструкциям ЦП для выполнения операций ввода-вывода с оборудованием.
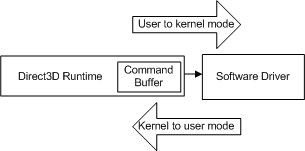
Переход происходит каждый раз, когда ЦП переключается с пользователя на режим ядра (и наоборот), а количество циклов, необходимых для него, большое по сравнению с отдельным вызовом API. Если бы среда выполнения отправляла каждый вызов API драйверу, когда он был вызван, каждый вызов API понес бы затраты на переход между режимами.
Вместо этого буфер команд — это оптимизация среды выполнения, предназначенная для снижения эффективной стоимости перехода в режиме. Буфер команд помещает в очередь множество команд драйвера в подготовке к переходу в один режим. Когда среда выполнения добавляет команду в буфер команд, элемент управления возвращается приложению. Профайлер не знает, что команды, вероятно, еще не были отправлены драйверу. В результате числа, возвращаемые стандартным инструментарием профилирования, вводят в заблуждение, так как он учитывает работу времени выполнения, но не связанную с этим работу драйвера.
Результаты профиля без перехода режима
С помощью последовательности отрисовки из примера 2 ниже приведены некоторые типичные измерения времени, иллюстрирующие величину перехода в режиме. Если вызовы SetTexture и DrawPrimitive не вызывают переход режима, стандартный инструментальный профилировщик может возвращать результаты, аналогичные следующим:
Number of cycles for SetTexture : 100
Number of cycles for DrawPrimitive : 900
Каждое из этих чисел — это время, необходимое для среды выполнения, чтобы добавить эти вызовы в буфер команд. Поскольку нет перехода режима, водитель еще не работал. Результаты профилировщика точны, но они не измеряют всю работу, которую процесс отрисовки со временем заставит выполнять ЦП.
Результаты профиля с переходом режима
Теперь ознакомьтесь с тем же примером, когда происходит переход в режиме. На этот раз предположим, что SetTexture и DrawPrimitive приводят к переходу режима. Еще раз профилировщик инструментирования из готовых решений может возвращать результаты, аналогичные следующим:
Number of cycles for SetTexture : 98
Number of cycles for DrawPrimitive : 946,900
Время, измеряемое для SetTexture, примерно одинаково, однако резкое увеличение времени, затраченного на DrawPrimitive, связано с переходом в режиме. Вот что происходит:
- Предположим, что буфер команд имеет место для одной команды перед запуском последовательности отрисовки.
- SetTexture преобразуется в независимый от устройства формат и добавляется в буфер команд. В этом сценарии этот вызов заполняет буфер команд.
- Среда выполнения пытается добавить DrawPrimitive в буфер команд, но не может, так как она заполнена. Вместо этого среда выполнения очищает буфер команд. Это приводит к переходу в режим ядра. Предположим, что переход занимает около 5000 циклов. Это время засчитывается во время, затраченное на DrawPrimitive.
- Затем драйвер обрабатывает работу, связанную со всеми командами, которые были очищены из буфера команд. Предположим, что время драйвера для обработки команд, почти заполненных буфером команд, составляет около 935 000 циклов. Предположим, что работа драйвера, связанная с SetTexture, составляет примерно 2750 циклов. Это время учитывается во времени, затраченном на DrawPrimitive.
- Когда драйвер завершит работу, переход в режим пользователя возвращает управление средой выполнения. Буфер команд теперь пуст. Предположим, что переход занимает около 5000 циклов.
- Последовательность отрисовки завершается преобразованием DrawPrimitive и добавлением её в буфер команд. Предположим, что это занимает около 900 циклов. Это время учитывается во времени, затраченном на DrawPrimitive.
Сводка результатов:
DrawPrimitive = kernel-transition + driver work + user-transition + runtime work
DrawPrimitive = 5000 + 935,000 + 2750 + 5000 + 900
DrawPrimitive = 947,950
Точно так же, как измерение для DrawPrimitive без перехода режима (900 циклов), измерение для DrawPrimitive с переходом режима (947 950 циклов) является точным, но бесполезным с точки зрения бюджетирования работы ЦП. Результат содержит правильную работу среды выполнения, драйвер работает для SetTexture, драйвер работает для всех команд, предшествующих SetTextureи двух режимов перехода. Однако в измерении отсутствует работа драйвера DrawPrimitive.
Переход в режиме может произойти в ответ на любой вызов. Он зависит от того, что было ранее в буфере команд. Для того чтобы понять, сколько работы ЦП (время выполнения и драйвер) связано с каждым вызовом, необходимо управлять переходом режима. Для этого требуется механизм управления буфером команд и временем перехода в режиме.
Механизм запроса
Механизм запросов в Microsoft Direct3D 9 был разработан, чтобы разрешить среде выполнения запрашивать GPU для выполнения и возвращать определенные данные из GPU. При профилировании, если работа GPU сведена к минимуму таким образом, что это оказывает незначительное влияние на производительность, можно вернуть статус из GPU, чтобы измерить работу драйвера. Работа драйвера завершается, когда GPU обработал команды драйвера. Кроме того, механизм запроса можно настроить на управление двумя характеристиками буфера команд, важными для профилирования: моментом, когда буфер команд очищается, и тем, сколько работы находится в буфере.
Ниже приведена та же последовательность отрисовки с помощью механизма запроса:
// 1. Create an event query from the current device
IDirect3DQuery9* pEvent;
m_pD3DDevice->CreateQuery(D3DQUERYTYPE_EVENT, &pEvent);
// 2. Add an end marker to the command buffer queue.
pEvent->Issue(D3DISSUE_END);
// 3. Empty the command buffer and wait until the GPU is idle.
while(S_FALSE == pEvent->GetData( NULL, 0, D3DGETDATA_FLUSH ))
;
// 4. Start profiling
LARGE_INTEGER start, stop;
QueryPerformanceCounter(&start);
// 5. Invoke the API calls to be profiled.
SetTexture(...);
DrawPrimitive(D3DPT_TRIANGLELIST, 0, 1);
// 6. Add an end marker to the command buffer queue.
pEvent->Issue(D3DISSUE_END);
// 7. Force the driver to execute the commands from the command buffer.
// Empty the command buffer and wait until the GPU is idle.
while(S_FALSE == pEvent->GetData( NULL, 0, D3DGETDATA_FLUSH ))
;
// 8. End profiling
QueryPerformanceCounter(&stop);
Пример 3. Использование запроса для управления буфером команд
Ниже приведено более подробное описание каждого из этих строк кода:
- Создайте запрос события, создав объект запроса с D3DQUERYTYPE_EVENT.
- Добавьте маркер события запроса в буфер команд, вызвав команду(D3DISSUE_END). Этот маркер указывает драйверу отслеживать, когда GPU завершит выполнение всех команд перед маркером.
- Первый вызов очищает буфер команд, так как вызов GetData с D3DGETDATA_FLUSH заставляет буфер команд очищаться. Каждый последующий вызов проверяет GPU, чтобы увидеть, когда он завершит обработку всех операций с буфером команд. Этот цикл не возвращает S_OK до простоя GPU.
- Пример времени начала.
- Вызов профилируемых вызовов API.
- Добавьте второй маркер события запроса в буфер команд. Этот маркер будет использоваться для отслеживания завершения вызовов.
- Первый вызов очищает буфер команд, так как вызов GetData с D3DGETDATA_FLUSH заставляет буфер команд очищаться. Когда GPU завершит обработку всех работ в буфере команд, GetData возвращает S_OK, и цикл завершается, так как GPU неактивен.
- Пример времени остановки.
Ниже приведены результаты, измеряемые с помощью QueryPerformanceCounter и QueryPerformanceFrequency:
| Локальная переменная | Количество галок |
|---|---|
| начало | 1792998845060 |
| остановка | 1792998845090 |
| Частота | 3579545 |
Преобразование галок в циклы снова (на компьютере с частотой 2 ГГц):
# ticks = (stop - start) = 1792998845090 - 1792998845060 = 30 ticks
# cycles = CPU speed * number of ticks / QPF
# 16,450 = 2 GHz * 30 / 3,579,545
Ниже приведена разбивка количества циклов для каждого вызова:
Number of cycles for SetTexture : 100
Number of cycles for DrawPrimitive : 900
Number of cycles for Issue : 200
Number of cycles for GetData : 16,450
Механизм запроса позволил нам управлять средой выполнения и работой драйвера, измеряемой. Чтобы понять каждое из этих чисел, вот что происходит в ответ на каждый из вызовов API, а также предполагаемые сроки:
Первый вызов очищает буфер команд, вызывая GetData с параметром D3DGETDATA_FLUSH. Когда GPU завершит обработку всех работ в буфере команд, GetData возвращает S_OK, и цикл завершается, так как GPU неактивен.
Последовательность отрисовки начинается путем преобразования SetTexture в независимый от устройства формат и добавление его в буфер команд. Предположим, что это занимает около 100 циклов.
DrawPrimitive преобразуется и добавляется в буфер команд. Предположим, что это занимает около 900 циклов.
добавляет маркер запроса в буфер команд. Предположим, что это занимает около 200 циклов.
GetData приводит к очистке буфера команд, который заставляет переход в режим ядра. Предположим, что это занимает около 5000 циклов.
Затем драйвер обрабатывает работу, связанную со всеми четырьмя вызовами. Предположим, что время обработки SetTexture составляет около 2964 циклов, DrawPrimitive составляет около 3600 циклов, а выполнение Issue — около 200 циклов. Таким образом, общее время драйвера для всех четырех команд составляет около 6450 циклов.
Заметка
Драйверу требуется немного времени, чтобы проверить статус GPU. Так как работа GPU является тривиальной, она должна быть уже выполнена. GetData возвращает S_OK на основе вероятности завершения GPU.
Когда драйвер завершит работу, переход в режим пользователя возвращает управление средой выполнения. Буфер команд теперь пуст. Предположим, что это занимает около 5000 циклов.
В число значений для GetData входят:
GetData = kernel-transition + driver work + user-transition
GetData = 5000 + 6450 + 5000
GetData = 16,450
driver work = SetTexture + DrawPrimitive + Issue =
driver work = 2964 + 3600 + 200 = 6450 cycles
Механизм запроса, используемый в сочетании с QueryPerformanceCounter, измеряет всю работу ЦП. Это делается с помощью сочетания маркеров запросов и сравнения состояния запроса. Маркеры запуска и остановки запросов, добавленные в буфер команд, используются для управления объемом работы в буфере. Дождавшись возвращения правильного кода возврата, начальное измерение выполняется непосредственно перед началом чистой последовательности отрисовки, а конечное измерение выполняется сразу после того, как драйвер завершит работу, связанную с содержимым буфера команды. Это эффективно фиксирует работу ЦП, выполняемую средой выполнения, а также драйвером.
Теперь, когда вы знаете о буфере команд и эффекте, который он может иметь при профилировании, следует знать, что существует несколько других условий, которые могут привести к тому, что среда выполнения пуста буфера команд. Необходимо следить за этими в последовательностях отрисовки. Некоторые из этих условий отвечают на вызовы API, другие находятся в ответ на изменения ресурсов в среде выполнения. Любое из следующих условий приведет к переходу в режиме:
- Если один из методов блокировки (блокировка) вызывается в буфере вершин, буфере индексов или текстуре (при определенных условиях с определенными флагами).
- При создании устройства или буфера вершин, буфера индексов или текстуры.
- Когда устройство или буфер вершин, буфер индекса или текстура уничтожаются последним выпуском.
- При вызове функции ValidateDevice.
- При вызове Present.
- Когда буфер команды переполняется.
- При вызове GetData с D3DGETDATA_FLUSH.
Внимательно следите за этими условиями в последовательностях отрисовки. Каждый раз, когда добавляется переход режима, к вашим измерениям профилирования прибавляется 10 000 циклов работы драйвера. Кроме того, буфер команд не имеет статического размера. Среда выполнения может изменить размер буфера в ответ на объем работы, создаваемой приложением. Это еще одна оптимизация, зависящая от последовательности отрисовки.
Поэтому внимательно следите за переходами в режиме управления во время профилирования. Механизм запроса предлагает надежный метод для очистки буфера команд, чтобы управлять временем перехода в режиме, а также объемом работы, содержащей буфер. Однако даже этот метод можно улучшить, уменьшая время перехода в режиме, чтобы сделать его незначительным в отношении измеряемого результата.
Сделать порядок отрисовки длиннее по сравнению с переходом между режимами.
В предыдущем примере переключение в режиме ядра и переключение в пользовательском режиме занимают около 10 000 циклов, которые не относятся к среде выполнения и работе драйвера. Так как переход в режиме встроен в операционную систему, он не может быть сокращен до нуля. Чтобы сделать переход в режим незначительным, последовательность отрисовки должна быть скорректирована таким образом, чтобы работа драйвера и среды выполнения была на порядок больше, чем переключения режимов. Вы можете попытаться произвести вычитание, чтобы убрать переходы, но распределение затрат на гораздо более обширную стоимость последовательности рендеринга будет более надежным.
Стратегия уменьшения переходов между режимами, пока они не станут незначительными, заключается в добавлении цикла в последовательность отрисовки. Например, давайте рассмотрим результаты профилирования, если будет добавлен цикл, который повторит последовательность отрисовки 1500 раз:
// Initialize the array with two textures, same size, same format
IDirect3DTexture* texArray[2];
CreateQuery(D3DQUERYTYPE_EVENT, pEvent);
pEvent->Issue(D3DISSUE_END);
while(S_FALSE == pEvent->GetData( NULL, 0, D3DGETDATA_FLUSH ))
;
LARGE_INTEGER start, stop;
// Now start counting because the video card is ready
QueryPerformanceCounter(&start);
// Add a loop to the render sequence
for(int i = 0; i < 1500; i++)
{
SetTexture(taxArray[i%2]);
DrawPrimitive(D3DPT_TRIANGLELIST, i*3, 1);
}
pEvent->Issue(D3DISSUE_END);
while(S_FALSE == pEvent->GetData( NULL, 0, D3DGETDATA_FLUSH ))
;
QueryPerformanceCounter(&stop);
Пример 4. Добавление цикла в последовательность отрисовки
Ниже приведены результаты, измеряемые с помощью QueryPerformanceCounter и QueryPerformanceFrequency:
| Локальная переменная | Число тиков |
|---|---|
| начало | 1792998845000 |
| остановка | 1792998847084 |
| Частота | 3579545 |
Использование QueryPerformanceCounter измеряет 2840 галок сейчас. Преобразование галок в циклы совпадает с тем, что мы уже показали:
# ticks = (stop - start) = 1792998847084 - 1792998845000 = 2840 ticks
# cycles = machine speed * number of ticks / QPF
# 6,900,000 = 2 GHz * 2840 / 3,579,545
Другими словами, для обработки 1500 вызовов в цикле отрисовки на этом устройстве с 2 ГГц требуется около 6,9 млн циклов. Из 6,9 миллиона циклов длительность времени, затраченного на переходы между режимами, составляет около 10 тысяч. Таким образом, результаты профилирования почти полностью отражают работу, связанную с SetTexture и DrawPrimitive.
Обратите внимание, что для примера кода требуется массив двух текстур. Чтобы избежать оптимизации среды выполнения, которая будет удалять SetTexture, если она устанавливает один и тот же указатель текстуры при каждом вызове, просто используйте массив двух текстур. Таким образом, каждый раз, когда выполняется цикл, изменяется указатель текстуры, и выполняется вся работа, связанная с SetTexture. Убедитесь, что обе текстуры имеют одинаковый размер и формат, так чтобы никакое другое состояние не изменялось, когда изменяется текстура.
Теперь у вас есть методика профилирования Direct3D. Он использует счетчик высокой производительности (QueryPerformanceCounter) для записи, сколько тиков требуется ЦП для выполнения задачи. Работа тщательно контролируется, чтобы среда выполнения и драйвер работали с вызовами API с помощью механизма запроса. Запрос предоставляет два средства управления: сначала очистить буфер команды перед запуском последовательности отрисовки, а во-вторых, чтобы вернуться после завершения работы GPU.
На данный момент в этой статье показано, как профилировать последовательность отрисовки. Каждая последовательность отрисовки была довольно простой и содержала один вызов DrawPrimitive и вызов SetTexture. Это было сделано, чтобы сосредоточиться на буфере команд и использовании механизма запроса для управления им. Ниже приведен краткий обзор того, как создать профиль для произвольной последовательности отрисовки.
- Используйте счетчик высокой производительности, например QueryPerformanceCounter, чтобы оценить время, необходимое для обработки каждого вызова API. Используйте QueryPerformanceFrequency и тактовую частоту ЦП для преобразования этого в количество циклов ЦП на вызов API.
- Свести к минимуму объем работы GPU путем отрисовки списков треугольников, где каждый треугольник содержит один пиксель.
- Используйте механизм запроса, чтобы очистить буфер команд до последовательности отрисовки. Это гарантирует, что профилирование будет фиксировать правильный объем времени работы среды выполнения и драйвера, ассоциированного с последовательностью отрисовки.
- Управление объемом работы, добавленной в буфер команд с помощью маркеров событий запроса. Этот же запрос обнаруживает, когда GPU завершит работу. Так как работа GPU является тривиальной, это практически эквивалентно измерению при завершении работы драйвера.
Все эти методы используются для профилирования изменений состояния. Если вы прочитали и поняли, как управлять буфером команд и успешно выполнили базовые измерения на DrawPrimitive, вы готовы добавить изменения состояния в последовательности рендеринга. При добавлении изменений состояния в последовательность отрисовки существует несколько дополнительных проблем профилирования. Если вы планируете добавить изменения состояния в последовательности отрисовки, обязательно перейдите к следующему разделу.
Профилирование изменений состояния Direct3D
Direct3D использует множество состояний отрисовки для управления почти каждым аспектом конвейера. API, вызывающие изменения состояния, включают любую функцию или метод, отличный от вызовов Draw*Primitive.
Изменения состояния могут быть сложны, поскольку вы можете не увидеть их стоимости без визуализации. Это результат работы ленивого алгоритма, который драйвер и GPU используют, чтобы отсрочить выполнение до тех пор, пока это не станет абсолютно необходимым. Как правило, следует выполнить следующие действия, чтобы измерить одно изменение состояния:
- Сначала профилирование DrawPrimitive.
- Добавьте одно изменение состояния в последовательность рендера и выполните профилирование новой последовательности.
- Вычтите разность между двумя последовательностями, чтобы получить стоимость изменения состояния.
Естественно, все, что вы узнали об использовании механизма запроса и помещении последовательности отрисовки в цикл для нивелирования стоимости перехода режима, по-прежнему применяется.
Профилирование простого изменения состояния
Начиная с последовательности отрисовки, содержащей DrawPrimitive, ниже приведена последовательность кода для измерения стоимости добавления SetTexture:
// Get the start counter value as shown in Example 4
// Initialize a texture array as shown in Example 4
IDirect3DTexture* texArray[2];
// Render sequence loop
for(int i = 0; i < 1500; i++)
{
SetTexture(0, texArray[i%2];
// Force the state change to propagate to the GPU
DrawPrimitive(D3DPT_TRIANGLELIST, i*3, 1);
}
// Get the stop counter value as shown in Example 4
Пример 5. Измерение одного вызова API изменения состояния
Обратите внимание, что цикл содержит два вызова, SetTexture и DrawPrimitive. Последовательность отрисовки повторяется циклом 1500 раз, и создает результаты, аналогичные следующим:
| Локальная переменная | Число тиков |
|---|---|
| начало | 1792998860000 |
| остановка | 1792998870260 |
| Частота | 3579545 |
Преобразование тиков в циклы снова дает:
# ticks = (stop - start) = 1792998870260 - 1792998860000 = 10,260 ticks
# cycles = machine speed * number of ticks / QPF
5,775,000 = 2 GHz * 10,260 / 3,579,545
Деление по количеству итераций в цикле дает:
5,775,000 cycles / 1500 iterations = 3850 cycles for one iteration
Каждая итерация цикла содержит изменение состояния и вызов рисования. Вычитание результата DrawPrimitive последовательности отрисовки оставляет:
3850 - 1100 = 2750 cycles for SetTexture
Это среднее количество циклов для добавления SetTexture в эту последовательность отрисовки. Этот же метод можно применить к другим изменениям состояния.
Почему SetTexture называется простым изменением состояния? Поскольку заданное состояние ограничено, чтобы конвейер выполнял одинаковый объем работы каждый раз при изменении состояния. Ограничение обоих текстур одинаковым размером и форматом обеспечивает одинаковый объем работы для каждого вызова SetTexture.
Профилирование изменения состояния, которое необходимо переключить
Существуют другие изменения состояния, которые приводят к изменению объема работы, выполняемой графическим конвейером для каждой итерации цикла отрисовки. Например, если z-тестирование включено, каждый цвет пикселя обновляет целевой объект отрисовки только после тестирования значения z нового пикселя в отношении z-значения для существующего пикселя. Если z-тестирование отключено, этот тест на пиксель не выполняется, и выходные данные записываются гораздо быстрее. Включение или отключение состояния z-теста значительно изменяет объем работы (ЦП, а также GPU) во время рендеринга.
SetRenderState требует определенного состояния отрисовки и значения состояния для включения или отключения z-тестирования. Конкретное значение состояния вычисляется во время выполнения, чтобы определить, сколько работы необходимо. Трудно измерить это изменение состояния в цикле отрисовки и подготовить состояние конвейера для его переключения. Единственным решением является переключение состояния во время последовательности отрисовки.
Например, метод профилирования должен повторяться дважды следующим образом:
- Начните с профилирования последовательности DrawPrimitive рендеринга. Назовите это основой.
- Профилирование второй последовательности отрисовки, которая переключает изменение состояния. Цикл последовательности отрисовки содержит следующее:
- Изменение состояния для установки его в "ложное" состояние.
- DrawPrimitive так же, как и исходная последовательность.
- Изменение состояния для установки его в состояние "истина".
- Второй DrawPrimitive используется, чтобы сделать второе изменение состояния реализацией.
- Найдите разницу между двумя последовательностями отрисовки. Это делается следующим образом:
- Умножьте базовую последовательность DrawPrimitive на 2, так как в новой последовательности есть два вызова DrawPrimitive.
- Вычтите результат новой последовательности из исходной последовательности.
- Разделите результат на 2, чтобы получить среднюю стоимость изменения состояния false и true.
При использовании цикла в последовательности рендеринга стоимость изменения состояния конвейера должна измеряться путем переключения состояния с истинного на ложное и обратно для каждой итерации в последовательности рендеринга. Значение "true" и "false" здесь не является литеральным, это просто означает, что состояние должно быть установлено в противоположных условиях. Это приводит к тому, что процесс измерения обоих изменений состояния осуществляется во время профилирования. Конечно, все, что вы узнали об использовании механизма запросов и о том, как помещать последовательность отрисовки в цикл, для снижения затрат на переход между режимами, по-прежнему актуально.
Например, ниже приведена последовательность кода для измерения стоимости переключения z-тестирования на включение и выключение.
// Get the start counter value as shown in Example 4
// Add a loop to the render sequence
for(int i = 0; i < 1500; i++)
{
// Precondition the pipeline state to the "false" condition
SetRenderState(D3DRS_ZENABLE, FALSE);
// Force the state change to propagate to the GPU
DrawPrimitive(D3DPT_TRIANGLELIST, (2*i + 0)*3, 1);
// Set the pipeline state to the "true" condition
SetRenderState(D3DRS_ZENABLE, TRUE);
// Force the state change to propagate to the GPU
DrawPrimitive(D3DPT_TRIANGLELIST, (2*i + 1)*3, 1);
}
// Get the stop counter value as shown in Example 4
Пример 5. Измерение переключающегося изменения состояния
Цикл переключает состояние путем выполнения двух вызовов SetRenderState. Первый вызов SetRenderState отключает z-testing, а второй SetRenderState включает z-testing. За каждым SetRenderState следует DrawPrimitive, чтобы работа, связанная с изменением состояния, обрабатывается драйвером, а не только заданием грязного бита в драйвере.
Эти числа являются разумными для этой последовательности отрисовки:
| Локальная переменная | Количество галок |
|---|---|
| начало | 1792998845000 |
| остановка | 1792998861740 |
| Частота | 3579545 |
Преобразование тиков в циклы снова дает:
# ticks = (stop - start) = 1792998861740 - 1792998845000 = 15,120 ticks
# cycles = machine speed * number of ticks / QPF
9,300,000 = 2 GHz * 16,740 / 3,579,545
Деление по количеству итераций в цикле дает:
9,300,000 cycles / 1500 iterations = 6200 cycles for one iteration
Каждая итерация цикла содержит два изменения состояния и два вызова рисования. Вычитание вызовов рисования (при условии 1100 циклов) оставляет:
6200 - 1100 - 1100 = 4000 cycles for both state changes
Это среднее число циклов для обоих изменений состояния, поэтому среднее время для каждого изменения состояния:
4000 / 2 = 2000 cycles for each state change
Поэтому среднее количество циклов для включения или отключения z-тестирования составляет 2000 циклов. Стоит отметить, что QueryPerformanceCounter измеряет z-enable и z-disable по половине времени каждый. Этот метод фактически измеряет среднее значение обоих изменений состояния. Другими словами, вы измеряете время переключения состояния. Используя этот метод, вы не можете знать, эквивалентно ли время включения и отключения, так как вы измеряли среднее значение обоих из них. Тем не менее, это разумное число, используемое при планировании бюджета для переключаемого состояния, поскольку приложение, которое приводит к изменению этого состояния, может сделать это только через переключение этого состояния.
Теперь вы можете применить эти методы и отслеживать все изменения состояния, которые вы хотите, верно? Не совсем. Вам по-прежнему необходимо внимательно следить за оптимизациями, которые предназначены для уменьшения объема работы, необходимой для выполнения. При проектировании последовательностей отрисовки следует учитывать два типа оптимизации.
Остерегайтесь оптимизации изменения состояния
В предыдущем разделе показано, как профилировать оба типа изменений состояния: простое изменение состояния, при котором объем работы ограничен и остаётся одинаковым для каждой итерации, и переключающее изменение состояния, которое значительно изменяет объем выполненной работы. Что произойдет, если вы принимаете предыдущую последовательность отрисовки и добавляете в нее другое изменение состояния? Например, этот пример принимает последовательность рендеринга z>-enable и добавляет к ней сравнение функции z.
// Add a loop to the render sequence
for(int i = 0; i < 1500; i++)
{
// Precondition the pipeline state to the opposite condition
SetRenderState(D3DRS_ZFUNC, D3DCMP_NEVER);
// Precondition the pipeline state to the opposite condition
SetRenderState(D3DRS_ZENABLE, FALSE);
// Force the state change to propagate to the GPU
DrawPrimitive(D3DPT_TRIANGLELIST, (2*i + 0)*3, 1);
// Now set the state change you want to measure
SetRenderState(D3DRS_ZFUNC, D3DCMP_ALWAYS);
// Now set the state change you want to measure
SetRenderState(D3DRS_ZENABLE, TRUE);
// Force the state change to propagate to the GPU
DrawPrimitive(D3DPT_TRIANGLELIST, (2*i + 1)*3, 1);
}
Состояние z-func задает уровень сравнения при записи в буфер z (между z-значением текущего пикселя с z-значением пикселя в буфере глубины). D3DCMP_NEVER отключает сравнение при z-тестировании, в то время как D3DCMP_ALWAYS включает его, чтобы сравнение выполнялось при каждом z-тестировании.
Профилирование одного из этих изменений состояния в последовательности отрисовки с помощью DrawPrimitive создает результаты, аналогичные следующим:
| Изменение одного состояния | Среднее число циклов |
|---|---|
| только D3DRS_ZENABLE | 2000 |
или
| Изменение одного состояния | Среднее число циклов |
|---|---|
| только D3DRS_ZFUNC | 600 |
Но если вы профилируете оба D3DRS_ZENABLE и D3DRS_ZFUNC в одной последовательности отрисовки, то сможете увидеть такие результаты:
| Оба изменения состояния | Среднее число циклов |
|---|---|
| D3DRS_ZENABLE + D3DRS_ZFUNC | 2000 |
Вы можете ожидать, что результат будет суммой циклов 2000 и 600 (или 2600), так как драйвер выполняет всю работу, связанную с настройкой обоих состояний отрисовки. Вместо этого среднее значение составляет 2000 циклов.
Этот результат отражает оптимизацию изменения состояния, реализованную в среде выполнения, драйвере или GPU. В этом случае драйвер может обнаружить первый SetRenderState и установить состояние "грязности", что отложит выполнение задачи на потом. Когда драйвер видит второй SetRenderState, то же несоответствующее состояние может быть повторно установлено избыточно, и та же работа будет отложена еще раз. Когда вызывается DrawPrimitive, работа, связанная с неочищенным состоянием, окончательно обрабатывается. Драйвер выполняет работу один раз, что означает, что первые два изменения состояния эффективно консолидируются драйвером. Аналогичным образом драйвер объединяет изменения третьего и четвёртого состояния в одно при вызове второго DrawPrimitive. Конечный результат заключается в том, что драйвер и GPU обрабатывают одно изменение состояния для каждого вызова функции отрисовки.
Это хороший пример оптимизации драйвера, зависящей от последовательности. Водитель отложил выполнение работы дважды, установив нечистое состояние, а затем выполнил работу один раз, чтобы очистить нечистое состояние. Это хороший пример улучшения эффективности, который может произойти, когда работа откладывается до абсолютной необходимости.
Как вы узнаёте, какие изменения состояния устанавливают грязное состояние внутри и, следовательно, откладывают выполнение работы на более поздний срок? Только путем тестирования последовательностей отрисовки (или общения с разработчиками драйверов). Драйверы периодически обновляются и улучшаются, поэтому список оптимизаций не является статическим. Существует только один способ точно знать, какова стоимость изменения состояния в заданной последовательности отрисовки, на конкретном наборе оборудования; и это – измерить.
Будьте внимательны с оптимизациями DrawPrimitive
Помимо оптимизации изменений состояния среда выполнения попытается оптимизировать количество вызовов рисования, которые должен обрабатывать драйвер. Например, рассмотрим эти обратные вызовы рисования:
DrawPrimitive(D3DPT_TRIANGLELIST, 0, 3); // Draw 3 primitives, vertices 0 - 8
DrawPrimitive(D3DPT_TRIANGLELIST, 9, 4); // Draw 4 primitives, vertices 9 - 20
Пример 5a: два вызова рисования
Эта последовательность содержит два вызова рисования, которые среда выполнения консолидирует в один вызов, эквивалентный:
DrawPrimitive(D3DPT_TRIANGLELIST, 0, 7); // Draw 7 primitives, vertices 0 - 20
Пример 5b: единый объединённый вызов функции рисования
Среда выполнения объединяет оба этих конкретных вызова рисования в один вызов, что сокращает работу драйвера на 50 процентов, так как драйвер теперь должен обрабатывать только один вызов рисования.
Как правило, среда выполнения объединяет два или более последовательно идущих вызова DrawPrimitive, когда:
- Примитивный тип — это список треугольников (D3DPT_TRIANGLELIST).
- Каждый последовательный вызов DrawPrimitive должен ссылаться на последовательные вершины в буфере вершин.
Аналогичным образом, правильные условия для объединения двух или более последовательных вызовов DrawIndexedPrimitive:
- Примитивный тип — это список треугольников (D3DPT_TRIANGLELIST).
- Каждый последовательный вызов DrawIndexedPrimitive должен ссылаться на последовательные индексы в буфере индексов.
- Каждый последовательный вызов DrawIndexedPrimitive должен использовать то же значение для BaseVertexIndex.
Чтобы предотвратить объединение во время профилирования, измените последовательность отрисовки таким образом, чтобы примитивный тип не был списком треугольников, или измените последовательность отрисовки таким образом, чтобы не было вызовов обратного рисования, использующих последовательные вершины (или индексы). В частности, среда выполнения также объединяет вызовы рисования, которые соответствуют обоим из следующих условий:
- Когда предыдущий вызов был DrawPrimitive, в случае если следующий вызов рисования:
- использует список треугольников, AND
- определяет StartVertex = предыдущий StartVertex + предыдущий PrimitiveCount * 3
- При использовании DrawIndexedPrimitive, если следующий draw call:
- использует список треугольников, AND
- указывает НачальныйИндекс = previous StartIndex + previous PrimitiveCount * 3, И
- указывает, что BaseVertexIndex равен предыдущему BaseVertexIndex.
Ниже приведен более тонкий пример объединения вызовов рисования, который легко игнорировать при профилировании. Предположим, что последовательность отрисовки выглядит следующим образом:
for(int i = 0; i < 1500; i++)
{
SetTexture(...);
DrawPrimitive(D3DPT_TRIANGLELIST, i*3, 1);
}
Пример 5c: Изменение состояния и один вызов рисования
Цикл выполняет итерации по 1500 треугольникам, устанавливая текстуру и отрисовывая каждый треугольник. Этот цикл отрисовки занимает около 2750 циклов для SetTexture и 1100 циклов для DrawPrimitive, как это было показано в предыдущих разделах. Вы можете интуитивно ожидать, что перемещение SetTexture за пределы цикла отрисовки должно уменьшить объем работы драйвера на 1500 * 2750 циклов, что является объемом работы, связанной с вызовом SetTexture 1500 раз. Фрагмент кода будет выглядеть следующим образом:
SetTexture(...); // Set the state outside the loop
for(int i = 0; i < 1500; i++)
{
// SetTexture(...);
DrawPrimitive(D3DPT_TRIANGLELIST, i*3, 1);
}
Пример 5d. Пример 5c с изменением состояния за пределами цикла
Перемещение SetTexture вне цикла отрисовки уменьшает объем работы, связанной с SetTexture, так как он вызывается один раз вместо 1500 раз. Менее очевидным вторичным эффектом является то, что работа для DrawPrimitive также уменьшается с 1500 вызовов до 1 вызова, так как все условия объединения вызовов рисования удовлетворены. При обработке последовательности отрисовки среда выполнения будет обрабатывать 1500 вызовов в один вызов драйвера. Переместив одну строку кода, объем работы драйвера значительно сократился:
total work done = runtime + driver work
Example 5c: with SetTexture in the loop:
runtime work = 1500 SetTextures + 1500 DrawPrimitives
driver work = 1500 SetTextures + 1500 DrawPrimitives
Example 5d: with SetTexture outside of the loop:
runtime work = 1 SetTexture + 1 DrawPrimitive + 1499 Concatenated DrawPrimitives
driver work = 1 SetTexture + 1 DrawPrimitive
Эти результаты полностью правильны, но очень вводят в заблуждение в контексте первоначального вопроса. Оптимизация вызова рисования привела к значительному сокращению объема работы драйвера. Это распространенная проблема при выполнении пользовательского профилирования. При устранении вызовов из последовательности отрисовки будьте осторожны, чтобы избежать объединения вызовов рисования. На самом деле, этот сценарий является мощным примером повышения производительности драйвера, возможного с помощью этой оптимизации среды выполнения.
Теперь вы знаете, как измерять изменения состояния. Начните с профилирования DrawPrimitive. Затем добавьте каждое дополнительное изменение состояния в последовательность (в некоторых случаях добавление одного вызова и в других случаях добавление двух вызовов) и измеряйте разницу между двумя последовательностями. Результаты можно преобразовать в галочки или циклы или время. Как и измерение последовательностей отрисовки с помощью QueryPerformanceCounter, измерение отдельных изменений состояния зависит от механизма запроса для управления буфером команд и размещения изменений состояния в цикле, чтобы свести к минимуму влияние переходов в режиме. Этот метод измеряет затраты на переключение состояния, поскольку профилировщик возвращает среднее значение времени включения и отключения состояния.
С помощью этой возможности можно начать создавать произвольные последовательности отрисовки и точно измерять связанную среду выполнения и работу драйвера. Затем цифры можно использовать для ответа на вопросы о бюджете, такие как "сколько ещё таких вызовов" можно сделать в последовательности отрисовки, сохраняя разумную частоту кадров, при условии, что сценарии с ограниченными ЦП.
Сводка
В этом документе показано, как управлять буфером команд, чтобы отдельные вызовы могли быть точно профилированы. Числа профилирования можно создать в галках, циклах или абсолютном времени. Они представляют объем работы среды выполнения и драйвера, связанного с каждым вызовом API.
Начните с профилирования вызова Draw*Primitive в процессе визуализации. Не забудьте:
- Используйте QueryPerformanceCounter для измерения количества тиков за вызов API. Используйте QueryPerformanceFrequency, чтобы преобразовать результаты в циклы или время, если вы хотите.
- Используйте механизм запроса, чтобы очистить буфер команд перед запуском.
- Включите последовательность отрисовки в цикл, чтобы свести к минимуму влияние перехода режима.
- Используйте механизм запроса, чтобы измерить, когда GPU завершил свою работу.
- Обратите внимание на конкатенацию во время выполнения, которая существенно повлияет на объем работы.
Это дает базовую производительность для DrawPrimitive, на основе которых можно строить. Чтобы профилировать одно изменение состояния, выполните следующие дополнительные советы.
- Добавьте изменение состояния в известный профиль последовательности отрисовки новой последовательности. Так как тестирование выполняется в цикле, для этого требуется дважды задавать состояние в противоположных значениях (например, включение и отключение).
- Сравните разницу в времени цикла между двумя последовательностями.
- Для изменений состояния, которые значительно изменяют конвейер (например, SetTexture), вычтите разницу между двумя последовательностями, чтобы получить время изменения состояния.
- Для изменений состояния, которые значительно изменяют конвейер (и поэтому требуют переключения состояний, таких как SetRenderState), вычтите разницу между последовательностями рендеринга и разделите на 2. Это вычислит среднее количество циклов для каждого изменения состояния.
Но будьте осторожны с оптимизациями, которые вызывают непредвиденные результаты при профилировании. Оптимизация изменений состояния может задать грязные состояния, которые приводят к отложению работы. Это может привести к результатам профиля, которые не так интуитивно понятны, как ожидалось. Объединенные вызовы рисования значительно сокращают работу драйвера, что может привести к вводящим в заблуждение выводам. Тщательно запланированные последовательности отрисовки используются для предотвращения изменения состояния и объединения вызовов рисования. Секрет в том, чтобы предотвратить оптимизацию во время профилирования, чтобы создаваемые вами числа соответствовали разумному бюджетированию.
Заметка
Дублирование этой стратегии профилирования в приложении без механизма запросов является более сложной задачей. До Direct3D 9 единственный прогнозируемый способ очистить буфер команд — заблокировать активную поверхность (например, целевой объект отрисовки), чтобы дождаться простоя GPU. Это связано с тем, что блокировка поверхности заставляет среду выполнения освободить буфер команд, если в нем присутствуют какие-либо команды отрисовки, которые должны обновить поверхность до ее блокировки, а также подождать завершения работы GPU. Этот метод является функциональным, хотя это более навязчиво, что использование механизма запроса, представленного в Direct3D 9.
Приложение
Числа в этой таблице представляют собой диапазон приближений для объема работы среды выполнения и драйвера, связанного с каждым из этих изменений состояния. Приблизительный показатель основан на фактических измерениях, сделанных на водителях с помощью методов, показанных в документе. Эти числа были созданы с помощью среды выполнения Direct3D 9 и зависят от драйвера.
Методы, описанные в этом документе, предназначены для измерения работы среды выполнения и драйвера. Как правило, нецелесообразно предоставлять результаты, соответствующие производительности ЦП и GPU в каждом приложении, так как для этого потребуется исчерпывающий массив последовательностей отрисовки. Кроме того, особенно трудно оценить производительность, так как она сильно зависит от настройки состояния в конвейере перед началом процесса отрисовки. Например, включение альфа-смешивания не влияет на объем необходимой работы ЦП, но может оказать большое влияние на объем работы, выполняемой GPU. Таким образом, методы, описанные в этом документе, ограничивают работу GPU до минимума, ограничивая объем данных, подлежащих визуализации. Это означает, что числа в таблице будут наиболее тесно соответствовать результатам, полученным из приложений, которые ограничены ЦП (в отличие от приложения, ограниченного GPU).
Вам рекомендуется использовать методы, представленные для покрытия сценариев и конфигураций, наиболее важных для вас. Значения в таблице можно использовать для сравнения с числами, которые вы создаете. Так как каждый драйвер зависит, единственным способом создания фактических чисел, которые вы увидите, является создание результатов профилирования с помощью сценариев.
| Вызов API | Среднее число циклов |
|---|---|
| SetVertexDeclaration | 6500 - 11250 |
| SetFVF | 6400 - 11200 |
| SetVertexShader | 3000 - 12100 |
| SetPixelShader | 6300 - 7000 |
| SPECULARENABLE | 1900 - 11200 |
| SetRenderTarget | 6000 - 6250 |
| SetPixelShaderConstant (1 Константа) | 1500 - 9000 |
| НОРМАЛИЗАЦИЯНОРМАЛЬНЫХ | 2200 - 8100 |
| LightEnable | 1300 - 9000 |
| SetStreamSource | 3700 - 5800 |
| ОСВЕЩЕНИЕ | 1700 - 7500 |
| ИСТОЧНИК ДИФФУЗНОГО МАТЕРИАЛА | 900 - 8300 |
| AMBIENTMATERIALSOURCE | 900 - 8200 |
| COLORVERTEX | 800 - 7800 |
| УстановитьОсвещение | 2200 - 5100 |
| SetTransform | 3200 - 3750 |
| УстановитьИндексы | 900 - 5600 |
| ОКРУЖАЮЩИЙ | 1150 - 4800 |
| SetTexture | 2500 - 3100 |
| SPECULARMATERIALSOURCE | 900 - 4600 |
| EMISSIVESOURCE | 900 - 4500 |
| SetMaterial | 1000 - 3700 |
| ZENABLE | 700 - 3900 |
| ОБОЛОЧКА0 | 1600 - 2700 |
| Минфильтр | 1700 - 2500 |
| MAGFILTER | 1700 - 2400 |
| SetVertexShaderConstant (1 константа) | 1000 - 2700 |
| КОЛОРОП | 1500 - 2100 |
| COLORARG2 | 1300 - 2000 |
| COLORARG1 | 1300 - 1980 |
| CULLMODE | 500 - 2570 |
| ВЫРЕЗКА | 500 - 2550 |
| DrawIndexedPrimitive | 1200 - 1400 |
| ADDRESSV | 1090 - 1500 |
| АДРЕС | 1070 - 1500 |
| DrawPrimitive | 1050 - 1150 |
| SRGBTEXTURE | 150 - 1500 |
| STENCILMASK | 570 - 700 |
| STENCILZFAIL | 500 - 800 |
| STENCILREF | 550 - 700 |
| ALPHABLENDENABLE | 550 - 700 |
| STENCILFUNC | 560 - 680 |
| STENCILWRITEMASK | 520 - 700 |
| STENCILFAIL | 500 - 750 |
| ZFUNC | 510 - 700 |
| ZWRITEENABLE | 520 - 680 |
| STENCILENABLE | 540 - 650 |
| STENCILPASS | 560 - 630 |
| SRCBLEND | 500 - 685 |
| Двухсторонний_ШаблонныйРежим | 450 - 590 |
| ALPHATESTENABLE | 470 - 525 |
| ALPHAREF | 460 - 530 |
| ALPHAFUNC | 450 - 540 |
| DESTBLEND | 475 - 510 |
| Включение записи цвета | 465 - 515 |
| CCW_STENCILFAIL | 340 - 560 |
| CCW_STENCILPASS | 340 - 545 |
| CCW_STENCILZFAIL | 330 - 495 |
| SCISSORTESTENABLE | 375 - 440 |
| CCW_STENCILFUNC | 250 - 480 |
| SetScissorRect | 150 - 340 |
Связанные разделы