Примечание
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
В этом руководство описано, как обнаружить и устранить проблемы, связанные с конфликтами кратковременных блокировок, которые возникают при работе приложений SQL Server в системах с высоким уровнем параллелизма с некоторыми рабочими нагрузками.
С увеличением количества ядер ЦП на серверах возрастает степень параллелизма, что может привести к появлению точек конфликтов в структурах данных, доступ к которым в ядре СУБД должен осуществляться последовательным образом. Это в особенности справедливо для рабочих нагрузок с обработкой транзакций с высокой пропускной способностью и высокой степенью параллелизма (OLTP). Существует несколько инструментов, методов и способов решения этих проблем, а также практики, которые можно использовать в разработке приложений, которые могут помочь избежать их в целом. В этой статье описывается определенный тип состязания по структурам данных, используюющим спинлоки для сериализации доступа к этим структурам данных.
Примечание.
Эта статья подготовлена группой консультантов по Microsoft SQL Server (SQLCAT) на основе принятого процесса определения и устранения проблем, связанных с конфликтами кратковременных блокировок страниц в приложениях SQL Server в системах с высоким уровнем параллелизма. Рекомендации и лучшие методики, описанные здесь, основаны на практическом опыте разработки и развертывания реальных систем OLTP.
Что такое конфликт кратковременных блокировок в SQL Server?
Кратковременные блокировки — это упрощенные примитивы синхронизации, используемые ядром SQL Server для обеспечения согласованности структур в памяти, включая следующие: индекс, страницы данных и внутренние структуры, такие как неконечные страницы в сбалансированном дереве. SQL Server использует кратковременные блокировки буфера для защиты страниц в буферном пуле и кратковременные блокировки ввода-вывода для защиты страниц, которые еще не загружены в буферный пул. При каждой операции записи или чтения данных страницы в буферном пуле SQL Server рабочий поток должен сначала наложить кратковременную блокировку на буфер для этой страницы. Существуют различные типы блокировок буфера, доступные для доступа к страницам в буферном пуле, включая монопольную блокировку (PAGELATCH_EX) и общую блокировку (PAGELATCH_SH). Когда SQL Server пытается получить доступ к странице, которая еще не присутствует в буферном пуле, выполняется асинхронный ввод-вывод для загрузки страницы в буферный пул. Если SQL Server должен ждать ответа от подсистемы ввода-вывода, он ожидает монопольной (PAGEIOLATCH_EX) или общей (PAGEIOLATCH_SH) блокировки ввода-вывода в зависимости от типа запроса; это делается для предотвращения загрузки другим рабочим потоком той же страницы в буферный пул с несовместимой блокировкой. Кратковременные блокировки также используются для защиты доступа к структурам во внутренней памяти, отличным от страниц буферного пула. В таких случаях применяются небуферные кратковременные блокировки.
Состязание на защёлках страниц является наиболее распространенным сценарием, встречающимся в системах с несколькими ЦП, поэтому большая часть этой статьи сосредоточена на рассмотрении этих ситуаций.
Конфликт кратковременных блокировок возникает, когда несколько потоков одновременно пытаются получить несовместимые кратковременные блокировки для одной и той же структуры в памяти. Поскольку кратковременная блокировка является механизмом внутреннего управления, ядро SQL автоматически определяет, когда ее использовать. Решения в ходе разработке приложений, включая проектирование схемы, могут влиять на поведение кратковременных блокировок ввиду его детерминированности. Эта статья содержит следующие сведения:
- Общие сведения об использовании кратковременных блокировок в SQL Server.
- Средства, используемые для анализа конфликтов кратковременных блокировок.
- Способы определения того, может ли наблюдаемое количество конфликтов привести к возникновению проблем.
Мы обсудим некоторые распространенные сценарии и способы лучшего их решения для облегчения конкуренции.
Как в SQL Server используются кратковременные блокировки?
Страница в SQL Server имеет размер 8 КБ и может содержать несколько строк. Чтобы увеличить степень параллелизма и производительность, кратковременные блокировки буфера накладываются только на время физической операции со страницей, в отличие от блокировок, которые действуют в ходе выполнения логической транзакции.
Кратковременные блокировки являются внутренним механизмом ядра SQL и обеспечивают согласованность памяти, тогда как блокировки используются в SQL Server для обеспечения логической согласованности транзакций. В таблице ниже сравниваются кратковременные блокировки и блокировки:
| Структура | Характер использования | Управление | Влияние на производительность | Предоставляется |
|---|---|---|---|---|
| Кратковременная блокировка | Обеспечивает согласованность структур в памяти. | Только ядро SQL Server. | Слабо влияет на производительность. Чтобы обеспечить максимальную степень параллелизма и производительность, кратковременные блокировки буфера накладываются только на время физической операции со структурой в памяти, в отличие от блокировок, которые действуют в ходе выполнения логической транзакции. |
sys.dm_os_wait_stats — предоставляет сведения о PAGELATCH, PAGEIOLATCH и LATCH типах ожидания (LATCH_EX и LATCH_SH используется для группировки всех ожиданий, не относящихся к захвату буфера).sys.dm_os_latch_stats — предоставляет подробные сведения о необуфферных задержках. sys.dm_db_index_operational_stats - Это динамическое административное представление предоставляет агрегированные задержки для каждого индекса, что полезно для устранения неполадок с производительностью, связанных с проблемами блокировки. |
| Заблокировать | Гарантирует согласованность транзакций. | Может управляться пользователем. | В связи с тем, что блокировки удерживаются во время выполнения транзакции, их влияние на производительность выше по сравнению с кратковременными блокировками. |
sys.dm_tran_locks. sys.dm_exec_sessions. |
Режимы кратковременных блокировок SQL Server и совместимость
Некоторые конфликты кратковременных блокировок являются неотъемлемой составляющей работы подсистемы SQL Server. Неизбежно, что в системе высокого параллелизма происходят несколько одновременных запросов на блокировку различных уровней совместимости. SQL Server обеспечивает совместимость кратковременных блокировок, помещая несовместимые запросы на кратковременную блокировку в очередь до завершения выполняющихся запросов на кратковременную блокировку.
Кратковременные блокировки накладываются в одном из пяти режимов, которые определяются уровнем доступа. Ниже приводится обобщенное описание режимов кратковременных блокировок в SQL Server:
KP: сохраняйте защелку. Гарантирует, что ссылаемая структура не может быть уничтожена. Используется в тех случаях, когда потоку требуется просмотреть структуру в буфере. Поскольку защелка KP совместима со всеми защелками, за исключением защелки уничтожения (DT), защелка KP считается маломощной, что означает минимальное влияние на производительность при ее использовании. Поскольку защелка КП несовместима с защелкой DT, это препятствует другим потокам уничтожить указанную структуру. Например, защелка KP предотвращает уничтожение структуры, на которую она ссылается, отложенным процессом записи. Дополнительные сведения о том, как используется процесс ленивой записи для управления буферными страницами в SQL Server, см. в разделе "Запись страниц" в ядре СУБД.SH: Общая блокировка. Требуется для чтения указанной структуры (например, для чтения страницы данных). Обращаться к ресурсу для чтения в рамках общей кратковременной блокировки могут несколько потоков одновременно.UP: обновите защёлку. Совместим сSH(общая блокировка) и KP, но не с другими, и поэтому не позволяетEXзаписывать в ссылочную структуру.EX: монопольная блокировка. Блокирует запись и чтение других потоков из указанной структуры. Например, она может использоваться для изменения содержимого страницы в целях защиты от ее разрыва.DT: уничтожить защелку. Перед уничтожением содержимого ссылочной структуры необходимо получить необходимые данные. Например, блокировка DT должна быть приобретена отложенным процессом записи, чтобы освободить чистую страницу перед добавлением ее в список свободных буферов, доступных для использования другими потоками.
Режимы защелки имеют разные уровни совместимости, например, общая защелка (SH) совместима с защелкой обновления (UP) или защелкой сохранения (KP), но несовместима с защелкой уничтожения (DT). На одну и ту же структуру могут накладываться одновременно несколько кратковременных блокировок при условии их совместимости. Когда поток пытается получить блокировку, удерживаемую в режиме, который не совместим, он помещается в очередь, чтобы ждать сигнала, указывающего, что ресурс доступен. Для защиты очереди используется спин-блокировка SOS_Task, которая принудительно реализует сериализованный доступ к очереди. Эту спин-блокировку необходимо накладывать для добавления элементов в очередь. Спин-блокировка SOS_Task также сигнализирует находящимся в очереди потокам о высвобождении несовместимых кратковременных блокировок, благодаря чему ожидающие потоки могут получить совместимую кратковременную блокировку и продолжить работу. Обработка очереди ожидания осуществляется в порядке поступления (FIFO) по мере высвобождения запросов на кратковременную блокировку. Соблюдение этого принципа обработки позволяет обеспечить равноправие потоков и исключить их нехватку.
Совместимость режима блокировки указана в следующей таблице (Да , указывает на совместимость, а не указывает на несовместимость):
| Режим кратковременной блокировки | кухонный наряд | SH | Вверх | EX | DT |
|---|---|---|---|---|---|
KP |
Да | Да | Да | Да | нет |
SH |
Да | Да | Да | нет | нет |
UP |
Да | Да | нет | нет | нет |
EX |
Да | нет | нет | нет | нет |
DT |
нет | нет | нет | нет | нет |
Суперзащелки и подзащелки SQL Server
С увеличением распространённости систем на основе NUMA с несколькими сокетами или многоядерных систем SQL Server 2005 ввёл суперзамки, также известные как подзамки, которые эффективны только на системах с 32 или более логическими процессорами. Суперзащёлки повышают эффективность в подсистеме SQL для определённых шаблонов использования в рабочих нагрузках OLTP с высокой степенью параллельности; например, если определённые страницы имеют шаблон интенсивного общего доступа только для чтения (SH), но записываются редко. Пример страницы с таким шаблоном доступа — это корневая страница дерева B (т. е. индекс); Обработчик SQL требует, чтобы общая блокировка удерживалась на корневой странице, когда разделение страницы происходит на любом уровне в дереве B.. В рабочей нагрузке OLTP с высокой нагрузкой вставки и высоким параллелизмом количество разбиения страниц значительно увеличивается параллельно с скоростью обработки, что может снизить производительность. Суперлэтчи могут обеспечить повышенную производительность для доступа к общим страницам, где для нескольких одновременных рабочих потоков требуется SH защёлка. Для этого движок SQL Server динамически повышает защелку на такой странице до суперзащелки. Superlatch разделяет одну защелку на массив субзащёлок, по одной субзащёлке на раздел на каждое ядро процессора, при этом основная защёлка становится прокси-перенаправителем, и глобальная синхронизация состояния не требуется для защёлок только для чтения. При этом работнику, который всегда назначается конкретному ЦП, необходимо получить только общий (SH) подзащеп, назначенный локальному планировщику.
Примечание.
В документации термин B-tree обычно используется в ссылке на индексы. В индексах rowstore ядро СУБД реализует дерево B+. Это не относится к индексам columnstore или индексам в таблицах, оптимизированных для памяти. Дополнительные сведения см. в руководстве по архитектуре и проектированию индексов SQL Sql Server и Azure.
Для получения совместимых кратковременных блокировок, таких как общая кратковременная блокировка superLatch, требуется меньше ресурсов, а доступ к активным страницам при этом масштабируется лучше, чем при использовании несекционированной общей кратковременной блокировки, поскольку отсутствие требования синхронизировать глобальные состояния значительно повышает производительность за счет доступа только к локальной памяти NUMA. И наоборот, получение монопольной (EX) суперблокировки дороже, чем приобретение обычной (EX) блокировки, так как SQL должен сигнализировать через все подблокировки. При наблюдении, что Superlatch использует шаблон интенсивного EX доступа, подсистема SQL может понизить его после удаления страницы из буферного пула. На следующей диаграмме показаны обычная защелка и сегментированная Superlatch:

Используйте объект SQL Server:Latches и связанные счетчики в мониторе производительности для сбора сведений о суперзакладках, включая количество суперзакладок, повышение уровня суперзакладки в секунду и понижение суперзакладки в секунду. Дополнительные сведения об объекте SQL Server:Latches и связанных счетчиках см. в разделе SQL Server, объект Latches.
Типы ожидания кратковременной блокировки
Накопительная информация о ожидании отслеживается SQL Server и может быть доступ к ней с помощью динамического административного представления (DMW). sys.dm_os_wait_stats SQL Server использует три типа времени ожидания для кратковременной блокировки, определяемых соответствующим параметром wait_type в динамическом административном представлении sys.dm_os_wait_stats:
Кратковременная блокировка буфера (BUF). Используется для обеспечения согласованности страниц индекса и данных для объектов-пользователей. Они также используются для защиты доступа к страницам данных, используемым SQL Server для системных объектов. Например, страницы, управляющие выделением, защищаются кратковременными блокировками буфера. К ним относятся страницы "Свободное пространство страницы" (PFS), "Глобальная карта выделения" (GAM), "Общая глобальная карта выделения" (SGAM) и страницы карты распределения индексов (IAM). Буферные защелки регистрируются в
sys.dm_os_wait_statsс помощьюwait_typeвPAGELATCH_*.Кратковременная блокировка без буферизации (не BUF). Используется для обеспечения согласованности любых структур в памяти, отличных от страниц буферного пула. Любые ожидания для не буферных защелок сообщаются как
wait_typeизLATCH_*.Кратковременная блокировка ввода-вывода. Подмножество кратковременных блокировок буфера, которые гарантируют согласованность тех же структур, которые защищаются кратковременными блокировками буфера, когда эти структуры нуждаются в загрузке в буферный пул с операцией ввода/вывода. Кратковременные блокировки ввода-вывода не позволяют другому потоку загружать одну и ту же страницу в буферный пул с несовместимой кратковременной блокировкой. Связан с
wait_typeизPAGEIOLATCH_*.Примечание.
Если вы видите значительные
PAGEIOLATCHожидания, это означает, что SQL Server ожидает подсистемы ввода-вывода. Хотя ожидается определенное количество ожиданийPAGEIOLATCHи нормальное поведение, если среднееPAGEIOLATCHвремя ожидания постоянно превышает 10 миллисекунд (мс), следует изучить, почему подсистема ввода-вывода находится под давлением.
Если при просмотре динамического административного представления sys.dm_os_wait_stats вы обнаружите кратковременные блокировки без буфера, необходимо проверить sys.dm_os_latch_stats, чтобы получить подробные сведения о совокупном ожидании для таких блокировок. Все ожидания блокировок буфера классифицируются в BUFFER классе блокировок, а остальные классифицируются как небуферные блокировки.
Симптомы и причины конфликтов кратковременных блокировок SQL Server
В загруженной системе с высоким уровнем параллелизма обычно наблюдается активное соревнование за структуры, к которым часто обращаются и которые защищены блокировками и другими механизмами управления в SQL Server. Это считается проблематичным, когда соперничество и время ожидания, связанные с захватом защелки для страницы, достаточно, чтобы уменьшить использование процессора (ЦП), что снижает производительность.
Пример конфликтов кратковременных блокировок
На следующей схеме синяя линия представляет пропускную способность в SQL Server, измеряемую транзакциями в секунду; черная линия представляет среднее время ожидания кратковременной блокировки страницы. В этом случае каждая транзакция выполняет INSERT в кластеризованный индекс с последовательным увеличением начального значения, например, при заполнении столбца данных типа bigint. По мере увеличения числа ЦП до 32 очевидно, что общая пропускная способность снизилась, и время ожидания блокировки страницы увеличилось до примерно 48 миллисекунд, как свидетельствует черная линия. Такое обратное отношение между пропускной способностью и временем ожидания кратковременной блокировки страницы является распространенным сценарием, который легко диагностировать.
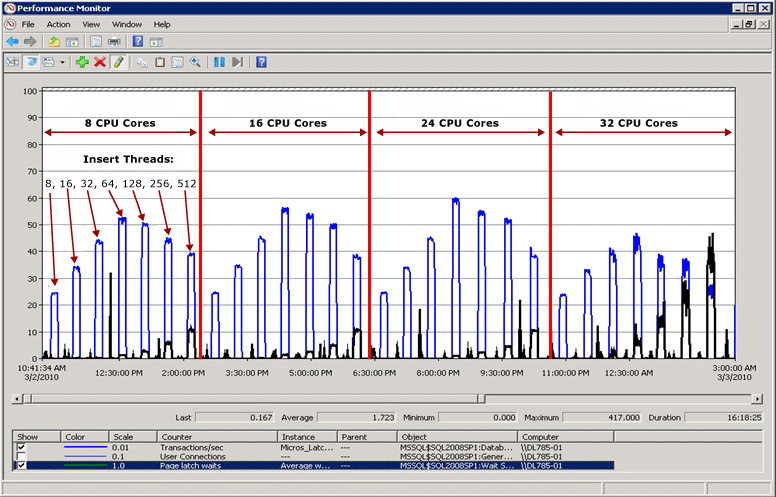
Производительность при разрешении конфликтов кратковременных блокировок
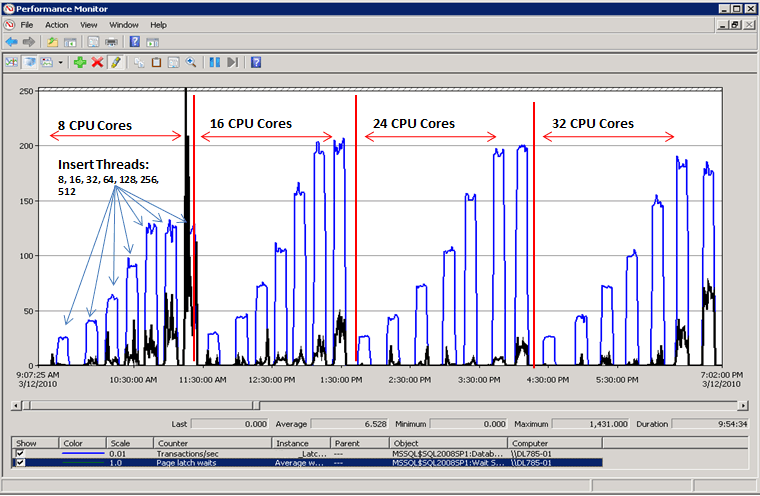
Как показано на следующей схеме, SQL Server больше не прослушивается в ожидании кратковременных блокировок страниц, а пропускная способность увеличивается на 300 %, измеряемую транзакциями в секунду. Это было достигнуто за счет метода использования хэш-секционирования с вычисляемым столбцом, описанного далее в этой статье. Это улучшение производительности используется системами с большим числом ядер и высоким уровнем параллелизма.
Факторы, влияющие на конфликты кратковременных блокировок
Конфликты кратковременных блокировок, которые негативно сказываются на производительности в средах OLTP, обычно вызываются высокой степенью параллелизма, связанной с одним или несколькими из следующих факторов.
| Множитель | Сведения |
|---|---|
| Большое число логических процессоров, используемых SQL Server | Конфликты кратковременных блокировок могут возникать в любой многоядерной системе. В опытах SQLCAT чрезмерное конкурирование за фиксаторы, что негативно влияет на производительность приложений, чаще всего наблюдается в системах с 16 и более ядрами процессора и может усугубляться по мере увеличения доступного числа ядер. |
| Конструкция схемы и шаблоны доступа | Глубина сбалансированного дерева, кластеризованного и некластеризованного индекса, размер и плотность строк на страницу, а также шаблоны доступа (операции чтения/записи и удаления) — все это факторы, которые могут повысить конкуренцию за кратковременные блокировки страниц. |
| Высокая степень параллелизма на уровне приложения | Чрезмерное состязание за кратковременные блокировки страниц обычно происходит вместе с высоким уровнем параллельных запросов от уровня приложения. Существуют определенные методики программирования, которые также могут познакомиться с большим количеством запросов к определенной странице. |
| Расположение логических файлов, используемых базами данных SQL Server | Макет логического файла может повлиять на уровень параметров блокировки страниц, вызванных структурами выделения, такими как свободное место страницы (PFS), глобальная карта выделения (GAM), общая глобальная карта выделения (SGAM) и карта распределения индексов (IAM). Дополнительные сведения см. в разделе "Мониторинг и устранение неполадок TempDB: узкие места выделения". |
| Производительность подсистемы ввода-вывода | Значительные PAGEIOLATCH ожидания указывают, что SQL Server ожидает подсистемы ввода-вывода. |
Диагностика конфликтов защелок в SQL Server
В этом разделе содержатся сведения о диагностике проблем с блокировкой SQL Server, чтобы определить, является ли это проблематичным для вашей среды.
Средства и методы для диагностики конфликтов кратковременных блокировок
Основные средства, используемые для диагностики конфликтов кратковременных блокировок:
Счетчик производительности для мониторинга загрузки ЦП и времени ожидания защелок в SQL Server, чтобы установить связь между загрузкой ЦП и временем ожидания защелок.
Динамические административные представления SQL Server, которые можно использовать для определения конкретного типа кратковременной блокировки, вызывающей проблемы и влияющей на ресурс.
В некоторых случаях дампы памяти процесса SQL Server необходимо получить и проанализировать с помощью средств отладки Windows.
Примечание.
Этот уровень расширенного устранения неполадок обычно требуется только при устранении конфликтов кратковременных блокировок, не связанных с буфером. Возможно, вы хотите привлечь службы поддержки продуктов Майкрософт для этого типа расширенного устранения неполадок.
Технический процесс диагностики конфликтов кратковременных блокировок можно получить, выполнив следующие действия.
Определите, что существует спор, который может быть связан с блокировкой.
Используйте представления DMV, представленные в приложении: скрипты конкуренции за блокировки SQL Server, чтобы определить тип затронутых блокировок и ресурсов.
Обойти конфликт можно с помощью одного из методов, описанных в разделе Обработка конфликтов кратковременных блокировок для различных табличных шаблонов.
Индикаторы конфликтов кратковременных блокировок
Как уже отмечалось ранее, конфликты кратковременных блокировок возникают только в том случае, если конфликт и время ожидания, связанные с получением кратковременных блокировок страниц, не допускают увеличения пропускной способности, когда доступны ресурсы ЦП. Для определения приемлемого объема конфликтов требуется целостный подход, который учитывает требования к производительности и пропускной способности вместе с доступными ресурсами ввода-вывода и ЦП. В этом разделе рассматривается, как определить влияние конфликта блокировок на рабочую нагрузку следующим образом.
- Измерьте общее время ожидания во время выполнения репрезентативного теста.
- Упорядочите их по порядку.
- Определите пропорцию времени ожидания, связанного с блокировками.
Совокупная информация о ожидании доступна из динамического административного sys.dm_os_wait_stats представления. Наиболее распространенный тип состязания за удержание блоков — это состязание за защелки буфера, которое проявляется как увеличение времени ожидания для защелок с wait_type из PAGELATCH_*. Не буферные защелки группируются по типу ожидания LATCH*. Как показано на следующем рисунке, сначала нужно оценить системные ожидания в целом, используя динамическое административное представление sys.dm_os_wait_stats, и определить процент совокупного времени ожидания, вызванного кратковременными блокировками с буфером или без. При обнаружении не буферных закладок sys.dm_os_latch_stats необходимо также проверить динамическое административное представление.
На следующей схеме описывается связь между сведениями, возвращаемыми динамическими административными представлениями sys.dm_os_wait_statssys.dm_os_latch_stats .

Дополнительные сведения о DMV sys.dm_os_wait_stats см. в справке по SQL Server sys.dm_os_wait_stats.
Для получения дополнительной информации о sys.dm_os_latch_stats DMV см. sys.dm_os_latch_stats в справке по SQL Server.
Следующие показатели времени ожидания кратковременных блокировок свидетельствуют о слишком большом количестве кратковременных блокировок, которые влияют на производительность приложения:
Среднее время ожидания блокировки страницы постоянно увеличивается с пропускной способностью: если среднее время ожидания блокировки страницы постоянно увеличивается с пропускной способностью и если среднее время ожидания буфера также увеличивается выше ожидаемого времени отклика на диск, следует изучить текущие задачи ожидания с помощью
sys.dm_os_waiting_tasksdmV. Средние показатели могут быть вводящими в заблуждение при анализе в изоляции, поэтому важно посмотреть на систему в реальном времени, когда это возможно, чтобы понять характеристики рабочей нагрузки. В частности, проверьте, есть ли высокие ожидания по запросамPAGELATCH_EXи (или)PAGELATCH_SHна любых страницах. Чтобы провести диагностику в случае роста среднего времени ожидания для кратковременных блокировок страниц с увеличением пропускной способности, выполните следующие действия.Используйте примеры скриптов Запрос к sys.dm_os_waiting_tasks с сортировкой по идентификатору сеанса или Вычисление ожиданий за период времени, чтобы проанализировать текущие ожидающие задачи и оценить среднее время ожидания для кратковременных блокировок.
Используйте пример скрипта Запрос дескрипторов буфера для определения объектов, вызывающих конфликты кратковременных блокировок, чтобы определить индекс и базовую таблицу, в которых возникают конфликты.
Измеряйте среднее время ожидания блокировки страницы с помощью счетчика Монитор производительности MSSQL%InstanceName%\Wait Statistics\Page Latch Waits\Average Waits или by running the
sys.dm_os_wait_statsDMV.
Примечание.
Чтобы вычислить среднее время ожидания для определенного типа ожидания (возвращаемого
sys.dm_os_wait_statsкакwt_:type), разделите общее время ожидания (возвращаемое какwait_time_ms) на количество ожидающих задач (возвращаемое какwaiting_tasks_count).Процент общего времени ожидания, затраченного на типы ожидания блокировки во время пиковой нагрузки: если среднее время ожидания блокировки в процентах от общего времени ожидания увеличивается в соответствии с нагрузкой приложения, то конфликты защелки могут повлиять на производительность и следует исследовать.
Измеряйте ожидания захвата страниц и ожидания нестраничных захватов с помощью счетчиков производительности объекта SQL Server, Wait Statistics. Затем сравните значения этих счетчиков производительности со счетчиками производительности, которые связаны с производительностью ЦП, операций ввода-вывода и памяти, а также с пропускной способностью сети. Например, для оценки использования ресурсов хорошо подходят такие показатели, как количество транзакций и пакетных запросов в секунду.
Примечание.
Относительное время ожидания для каждого типа ожидания не включено в
sys.dm_os_wait_statsDMV, так как эта DMV измеряет время ожидания с момента последнего запуска экземпляра SQL Server или сброса совокупной статистики ожидания с помощьюDBCC SQLPERF. Чтобы вычислить относительное время ожидания для каждого типа ожидания, сделайте моментальный снимокsys.dm_os_wait_statsдо пиковой нагрузки, после пиковой нагрузки, а затем вычислите разницу. Для этой цели можно использовать пример скрипта Вычисление ожиданий за период времени.Для непроизводственных сред снимите
sys.dm_os_wait_statsdmV с помощью следующей команды:DBCC SQLPERF ('sys.dm_os_wait_stats', 'CLEAR');Для очистки динамического административного
sys.dm_os_latch_statsпредставления можно выполнить аналогичную команду:DBCC SQLPERF ('sys.dm_os_latch_stats', 'CLEAR');Пропускная способность не увеличивается, а в некоторых случаях уменьшается, так как нагрузка приложения увеличивается, а количество ЦП, доступных ДЛЯ SQL Server, увеличивается: это было показано в примере latch Contention.
Использование ЦП не увеличивается по мере увеличения рабочей нагрузки приложения: если загрузка ЦП в системе не увеличивается, несмотря на рост пропускной способности приложения, это является индикатором того, что SQL Server чего-то ожидает, и симптоматикой блокировки защелки.
В таких случаях необходимо проанализировать возможные основные причины. Даже если каждое из предыдущих условий верно, возможно, что первопричина проблем с производительностью лежит в другом месте. В большинстве случаев неоптимальная загрузка ЦП вызвана другими типами ожиданий, например, блокировкой, ожиданиями, связанными с вводом-выводом или сетевыми ожиданиями. Как правило, всегда рекомендуется устранить ожидание ресурса, составляющее большую долю общего времени ожидания, прежде чем переходить к более подробному анализу.
Анализ текущих защелок буфера ожидания
Конкуренция за защелки буфера проявляется в виде увеличения времени ожидания для защелок с wait_type значением PAGELATCH_* или PAGEIOLATCH_*, как показано в динамическом административном представлении sys.dm_os_wait_stats. Чтобы просмотреть систему в режиме реального времени, выполните следующий запрос в системе для присоединения к динамическим административным представлениям и sys.dm_os_wait_stats динамическим sys.dm_exec_sessionssys.dm_exec_requests представлениям. Полученные результаты можно использовать, чтобы определить текущий тип ожидания для сеансов, выполняемых на сервере.
SELECT wt.session_id,
wt.wait_type,
er.last_wait_type AS last_wait_type,
wt.wait_duration_ms,
wt.blocking_session_id,
wt.blocking_exec_context_id,
resource_description
FROM sys.dm_os_waiting_tasks AS wt
INNER JOIN sys.dm_exec_sessions AS es
ON wt.session_id = es.session_id
INNER JOIN sys.dm_exec_requests AS er
ON wt.session_id = er.session_id
WHERE es.is_user_process = 1
AND wt.wait_type <> 'SLEEP_TASK'
ORDER BY wt.wait_duration_ms DESC;
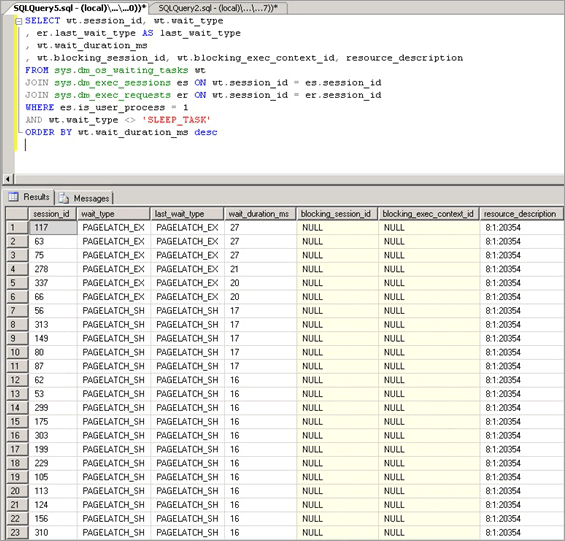
Статистика, предоставляемая этим запросом, описана ниже.
| Статистический показатель | Description |
|---|---|
session_id |
Идентификатор сеанса, связанного с этой задачей. |
wait_type |
Тип ожидания, которое записано в ядре SQL Server и препятствует выполнению текущего запроса. |
last_wait_type |
Если запрос был блокирован ранее, в столбце содержится тип последнего ожидания. Не допускает значение NULL. |
wait_duration_ms |
Общее время ожидания в миллисекундах, связанное с ожиданием этого типа, с момента запуска экземпляра SQL Server или сброса совокупной статистики ожидания. |
blocking_session_id |
Идентификатор сеанса, блокирующего данный запрос. |
blocking_exec_context_id |
Идентификатор контекста выполнения, связанного с этой задачей. |
resource_description |
В столбце resource_description приведена конкретная ожидаемая страница в следующем формате: <database_id>:<file_id>:<page_id>. |
Следующий запрос возвращает сведения для всех блокировок, отличных от буфера:
SELECT * FROM sys.dm_os_latch_stats
WHERE latch_class <> 'BUFFER'
ORDER BY wait_time_ms DESC;

Статистика, предоставляемая этим запросом, описана ниже.
| Статистический показатель | Description |
|---|---|
latch_class |
Тип кратковременной блокировки, которая записана в ядре SQL Server и препятствует выполнению текущего запроса. |
waiting_requests_count |
Количество ожиданий кратковременных блокировок этого класса с момента перезапуска SQL Server. Этот счетчик увеличивается в начале ожидания кратковременной блокировки. |
wait_time_ms |
Общее время ожидания в миллисекундах, связанное с ожиданием для этого типа кратковременной блокировки. |
max_wait_time_ms |
Максимальное время в миллисекундах, связанное с ожиданием для всех запросов для этого типа кратковременной блокировки. |
Это динамическое административное представление возвращает значения, которые накапливаются с момента последнего сброса представления или перезапуска ядра СУБД. Узнать время последнего запуска ядра СУБД можно в столбце sqlserver_start_time из sys.dm_os_sys_info. В системе, которая работает долгое время, это означает, что некоторые статистические данные, такие как max_wait_time_ms редко полезны. Чтобы сбросить статистику ожидания для этого динамического административного представления, можно использовать следующую команду:
DBCC SQLPERF ('sys.dm_os_latch_stats', CLEAR);
Сценарии конфликтов кратковременных блокировок в SQL Server
В следующих сценариях наблюдалось чрезмерное количество конфликтов кратковременных блокировок.
Конфликты вставки последней страницы
В OLTP часто создается кластеризованный индекс для столбца идентификаторов или дат. Благодаря этому поддерживается эффективная физическая организация индекса, что позволяет значительно повысить производительность связанных с ним операций чтения и записи. Тем не менее такая схема может привести к возникновению непредвиденных конфликтов кратковременных блокировок. Чаще всего эта проблема возникает при работе с большой таблицей с небольшими строками, когда выполняется вставка в индекс, содержащий последовательно увеличивающийся ключевой столбец, например возрастающий ключ, который задается целым числом или значением даты и времени. В этом сценарии в приложении крайне редко, за исключением операций архивирования, выполняются операции обновления или удаления.
В следующем примере первый и второй потоки пытаются одновременно выполнить вставку записи, которая будет храниться на странице 299. С точки зрения логической блокировки нет проблем, так как используются блокировки на уровне строк, и монопольные блокировки обеих записей на одной странице могут храниться одновременно. Тем не менее, чтобы обеспечить целостность физической памяти, накладывать монопольную блокировку может одновременно только один поток, в связи с чем доступ к странице сериализуется с целью исключить потерю обновлений в памяти. В этом случае поток 1 получает эксклюзивную защелку, а поток 2 ожидает, что регистрируется ожидание PAGELATCH_EX этого ресурса в статистике ожидания. Это отображается через wait_type значение в динамическом административном представлении sys.dm_os_waiting_tasks .
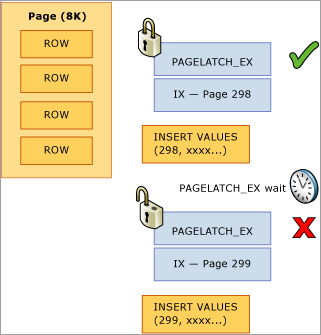
Такую ситуацию часто называют конфликтом вставки последней страницы, поскольку он возникает на крайней правой границе сбалансированного дерева, как показано на следующем рисунке:
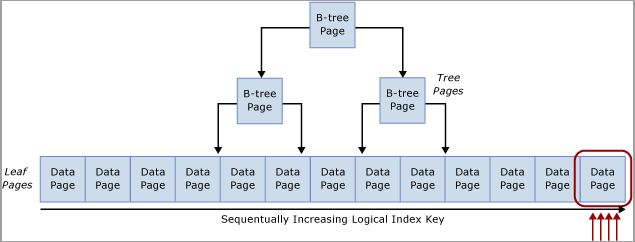
Возникновение конфликтов кратковременных блокировок этого типа можно объяснить следующим образом. При вставке новой строки в индекс SQL Server используется следующий алгоритм для выполнения изменения:
Выполняется просмотр сбалансированного дерева, чтобы найти нужную страницу для размещения новой записи.
Заблокируйте страницу с помощью
PAGELATCH_EX, чтобы предотвратить ее изменение другими пользователями, и установите общие блокировки (PAGELATCH_SH) на всех неконечных страницах.Примечание.
В некоторых случаях подсистема SQL требует, чтобы
EXзащелки были захвачены на внутренних страницах B-дерева. Например, когда происходит разделение страниц, все страницы, непосредственно затронутые, должны быть исключительно защеплены (PAGELATCH_EX).В журнал заносится запись об изменении страницы.
На страницу добавляется строка, а сама страница помечается как "грязная".
Со всех страниц снимаются кратковременные блокировки.
Если индекс таблицы основан на последовательно увеличивающемся ключе, каждая новая вставка переходит на ту же страницу в конце дерева B- до тех пор, пока эта страница не будет заполнена. В сценариях высокой конкурентности это может привести к возникновению конфликтов на правом краю B-дерева и может происходить на кластеризованных и некластеризованных индексах. Таблицы, затронутые этим типом состязания, в основном принимают INSERT запросы, и страницы для проблемных индексов обычно относительно плотны (например, размер строки ~ 165 байт (включая нагрузку на строку) равен ~49 строкам на страницу). В этом примере с большим количеством вставок ожидается, что произойдут PAGELATCH_EX/PAGELATCH_SH ожидания, и это является типичным наблюдением. Чтобы проверить ожидание блокировки страницы и ожиданий sys.dm_db_index_operational_stats блокировки на странице дерева, используйте dmV.
В следующей таблице перечислены основные факторы, которые наблюдались при этом типе конфликтов кратковременной блокировки.
| Множитель | Типичные наблюдения |
|---|---|
| Логические процессоры, используемые SQL Server | Такое состязание за кратковременные блокировки происходит в основном на системах с 16-ядерными и более процессорами, а чаще всего на системах с 32-ядерными и более процессорами. |
| Конструкция схемы и шаблоны доступа | Используется последовательно увеличивающееся значение идентификатора в качестве первого столбца в индексе в таблице для транзакционных данных. Индекс имеет увеличивающийся первичный ключ с большим количеством вставок. Индекс имеет по крайней мере одно последовательное увеличение значения столбца. Обычно размер небольшой строки с большим количеством строк на страницу. |
| Наблюдаемый тип ожидания | Многие потоки, претендующие на тот же ресурс с эксклюзивными (EX) или общими (SH) ожиданиями блокировки, связаны с тем же resource_description в динамическом административном представлении sys.dm_os_waiting_tasks, что отражается в запросе sys.dm_os_waiting_tasks, упорядоченный по длительности ожидания. |
| Конструктивные факторы, которые следует учитывать | Измените порядок столбцов индекса, как описано в стратегии устранения непоследовательных индексов, если вы можете гарантировать, что вставки распределяются по B-дереву равномерно и постоянно. Если используется стратегия хеширования для оптимизации, это исключает возможность использования секционирования для любых других целей, таких как архивация скользящих окон. Использование стратегии устранения рисков хэш-секций может привести к проблемам устранения секций для SELECT запросов, используемых приложением. |
Состязание за кратковременные блокировки в небольших таблицах с некластеризованным индексом и случайными вставками (таблица очередей)
Этот сценарий обычно рассматривается, когда таблица SQL используется в качестве временной очереди (например, в асинхронной системе обмена сообщениями).
В этом сценарии монопольные (EX) и общие (SH) конфликты блокировки могут возникать в следующих условиях:
- Операции вставки, выбора, обновления или удаления выполняются при высокой параллелизме.
- Размер строки относительно мал (что ведет к высокой плотности страниц).
- Число строк в таблице относительно мало; это ведет к неполному сбалансированному дереву, определяемому с глубиной индекса, равной двум или трем.
Примечание.
Даже в сбалансированных деревьях с более высокой глубиной, чем эта, могут возникать состязания с этим типом шаблона доступа, если частота языка обработки данных (DML) и параллелизма системы достаточно высоки. Уровень конфликтов с блокировкой может стать выраженным по мере увеличения параллелизма при наличии в системе 16 или более ядер ЦП.
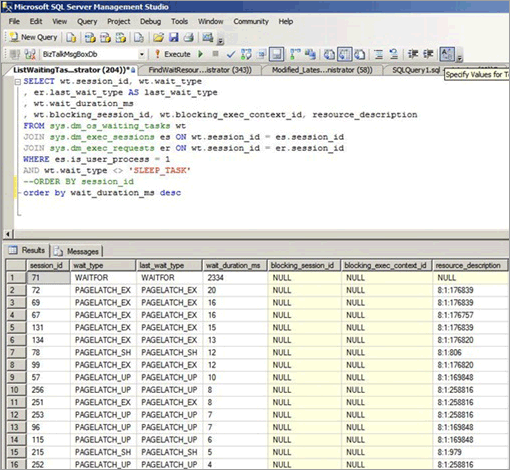
Состязание за кратковременные блокировки может возникать, даже если доступ осуществляется случайным образом через сбалансированное дерево, например, когда непоследовательный столбец является ведущим ключом в кластеризованном индексе. Следующий снимок экрана относится к системе с таким типом состязания. В этом примере состязание происходит из-за плотности страниц, вызываемых небольшим размером строки и относительно неглубокого сбалансированного дерева. При увеличении параллелизма конкуренция на страницах происходит, несмотря на то, что вставки происходят случайным образом по сбалансированному дереву, так как идентификатор GUID был первым столбцом в индексе.
На следующем снимке экрана ожидание происходит на страницах данных буфера и страницах свободного места (PFS). Даже при увеличении числа файлов данных состязание за кратковременные блокировки было распространено на страницах данных буфера.
В следующей таблице перечислены основные факторы, которые наблюдались при этом типе конфликтов кратковременной блокировки.
| Множитель | Типичные наблюдения |
|---|---|
| Логические процессоры, используемые SQL Server | Состязание за кратковременные блокировки происходит в основном на компьютерах с 16-ядерными ЦП. |
| Конструкция схемы и шаблоны доступа | Высокая частота операций вставки, выбора, обновления и удаления для небольших таблиц. Поверхностное сбалансированное дерево (глубина индекса, равная двум или трем). Малый размер строки (много записей на страницу). |
| Уровень параллелизма | Конфликты блокировки происходят только на высоком уровне параллельных запросов из уровня приложения. |
| Наблюдаемый тип ожидания | Наблюдайте за ожиданиями на буфер (PAGELATCH_EX и PAGELATCH_SH) и небуферной блокировкой ACCESS_METHODS_HOBT_VIRTUAL_ROOT из-за разделения корней. Также PAGELATCH_UP ожидается на страницах PFS. Дополнительные сведения о ожиданиях блокировки без буфера см. в sys.dm_os_latch_stats справке ПО SQL Server. |
Сочетание неполного сбалансированного дерева и случайных вставок по индексу может вызвать разбиение страниц в сбалансированном дереве. Чтобы выполнить разделение страниц, SQL Server должен получить разделяемые (SH) блокировки на всех уровнях, а затем получить эксклюзивные (EX) блокировки на страницах в дереве B, которые участвуют в разделении страниц. Кроме того, если параллелизм высок и данные постоянно вставляются и удаляются, может происходить разделение корня B-дерева. В этом случае другим вставкам может потребоваться ждать каких-либо не буферных защелок, приобретенных на B-дереве. Это проявляется в виде большого количества ожиданий на типе блокировки ACCESS_METHODS_HOBT_VIRTUAL_ROOT, наблюдаемом в динамическом административном представлении sys.dm_os_latch_stats.
Следующий скрипт можно изменить, чтобы определить глубину сбалансированного дерева для индексов в затронутой таблице.
SELECT
o.name AS [table],
i.name AS [index],
indexProperty(object_id(o.name), i.name, 'indexDepth') + indexProperty(object_id(o.name), i.name, 'isClustered') AS depth, --clustered index depth reported doesn't count leaf level
i.[rows] AS [rows],
i.origFillFactor AS [fillFactor],
CASE (indexProperty(object_id(o.name), i.name, 'isClustered'))
WHEN 1 THEN 'clustered'
WHEN 0 THEN 'nonclustered'
ELSE 'statistic'
END AS type
FROM sysIndexes AS i
INNER JOIN sysObjects AS o
ON o.id = i.id
WHERE o.type = 'u'
AND indexProperty(object_id(o.name), i.name, 'isHypothetical') = 0 --filter out hypothetical indexes
AND indexProperty(object_id(o.name), i.name, 'isStatistics') = 0 --filter out statistics
ORDER BY o.name;
Состязание за кратковременные блокировки на страницах свободного места (PFS)
PFS обозначает свободное место на странице, SQL Server выделяет одну страницу PFS для каждых 8088 страниц (начиная с PageID = 1) в каждом файле базы данных. Каждый байт на странице PFS записывает сведения о том, сколько свободного места находится на странице, если оно выделено или нет, а также хранит ли страница записи призраков. На странице PFS содержатся сведения о страницах, доступных для выделения, если для операции вставки или обновления требуется новая страница. Страница PFS должна обновляться в нескольких случаях, включая распределение или освобождение. Поскольку для защиты страницы PFS требуется использование кратковременной блокировки обновления (UP), состязание за кратковременные блокировки на страницах PFS может произойти, если в файловой группе имеется несколько файлов данных и большое количество ядер ЦП. Простой способ решения этой проблемы — увеличить число файлов в файловой группе.
Предупреждение
Увеличение числа файлов на файловую группу может отрицательно повлиять на производительность определенных нагрузок, например загрузку с большим количеством операций сортировки, которые сбрасывают память на диск.
Если в tempdb для страниц PFS или SGAM наблюдается много ожиданий PAGELATCH_UP, выполните следующие действия, чтобы устранить это узкое место:
Добавьте данные файлы в
tempdb, чтобы число файлов данных tempdb было равно количеству ядер процессора на сервере.Включите флаг трассировки SQL Server 1118.
Дополнительные сведения об узких местах выделения, вызванных конфликтами на системных страницах, см. в публикации блога Что такое узкие места выделения?
Функции с табличным значением и состязание за кратковременные блокировки в базе данных tempdb
Существуют и другие факторы, выходящие за рамки состязаний по распределению, которые могут вызвать блокировку на tempdb, например, при интенсивном использовании TVF в запросах.
Обработка конфликтов блокировок для разных шаблонов таблиц
В следующих разделах описываются методы, которые можно использовать для устранения или обхода проблем с производительностью, связанных с чрезмерным состязанием за кратковременные блокировки.
Использование непоследовательного ключа индекса в начале
Один из методов обработки состязаний за кратковременную блокировку — замена последовательного ключа индекса непоследовательным ключом, что позволяет равномерно распределить вставку данных в пределах индекса.
Обычно это делается путем наличия ведущего столбца в индексе, который распределяет рабочую нагрузку пропорционально. Существует несколько вариантов настройки.
Параметр. Использование столбца в таблице для распределения значений по диапазону ключей индекса
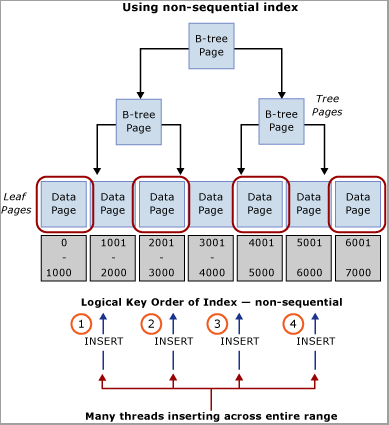
Определите в рабочей нагрузке естественное значение, которое можно использовать для распределения вставок по диапазону ключей. Например, рассмотрим сценарий банковского обслуживания банкоматов, где ATM_ID может быть хорошим кандидатом на распределение вставок в таблицу транзакций для снятия средств, так как один клиент может использовать только один банкомат за раз. Аналогичным образом, в системе точек продаж возможно Checkout_ID, или идентификатор магазина будет естественным выбором, который можно использовать для распределения вставок по диапазону ключей. Для этого метода требуется создать составной ключ индекса с ведущим ключевым столбцом либо значением определенного столбца, либо хэш этого значения в сочетании с одним или несколькими дополнительными столбцами, чтобы обеспечить уникальность. В большинстве случаев наилучших результатов можно достичь, используя хэширование значений, поскольку слишком много уникальных значений ухудшают физическую организацию. Например, в системе точек продаж можно создать хэш на основе идентификатора магазина, который представляет собой некоторый остаток от деления на количество ядер ЦП. Эта методика приведет к относительно небольшому числу диапазонов в таблице, однако этого будет достаточно для распространения вставок таким образом, чтобы избежать конфликтов кратковременных блокировок. Этот метод проиллюстрирован на следующем изображении.
Внимание
Этот шаблон противоречит традиционным рекомендациям по индексированию. Хотя этот метод помогает обеспечить равномерное распределение вставок по B-дереву, он также может потребовать изменения схемы на уровне приложения. Кроме того, этот шаблон может отрицательно повлиять на производительность запросов, требующих сканирования диапазона, использующих кластеризованный индекс. Некоторый анализ шаблонов рабочей нагрузки необходим, чтобы определить, хорошо ли работает этот подход к проектированию. Этот шаблон следует реализовать, если вы можете пожертвовать производительностью последовательного сканирования, чтобы увеличить пропускную способность вставок и масштабируемость.
Этот шаблон был реализован в лаборатории и разрешил конфликты кратковременных блокировок в системе с 32 физическими ядрами ЦП. Таблица использовалась для хранения баланса закрытия в конце транзакции; каждая бизнес-транзакция выполнила одну вставку в таблицу.
Определение исходной таблицы
При использовании исходного определения таблицы в pk_table1 кластеризованного индекса наблюдалось чрезмерное состязание за кратковременные блокировки:
CREATE TABLE table1
(
TransactionID BIGINT NOT NULL,
UserID INT NOT NULL,
SomeInt INT NOT NULL
);
GO
ALTER TABLE table1
ADD CONSTRAINT pk_table1 PRIMARY KEY CLUSTERED (TransactionID, UserID);
GO
Примечание.
Имена объектов в определении таблицы были изменены исходя из их исходных значений.
Определение переупорядоченного индекса
Переупорядочение ключевых столбцов индекса, используя UserID в качестве ведущего столбца в первичном ключе, обеспечило почти случайное распределение записей по страницам. Полученное распределение было не 100% случайным, так как не все пользователи в сети одновременно, но распределение было достаточно случайным, чтобы облегчить чрезмерную блокировку. Одна оговорка при изменении порядка определения индекса состоит в том, что любые запросы выбора к этой таблице должны быть изменены для использования как UserID, так и TransactionID в качестве предикатов равенства.
Внимание
Перед запуском в рабочей среде убедитесь, что вы тщательно протестировали все изменения в тестовой среде.
CREATE TABLE table1
(
TransactionID BIGINT NOT NULL,
UserID INT NOT NULL,
SomeInt INT NOT NULL
);
GO
ALTER TABLE table1
ADD CONSTRAINT pk_table1 PRIMARY KEY CLUSTERED (UserID, TransactionID);
GO
Использование хэш-значения в качестве первого столбца в первичном ключе
Следующее определение таблицы можно использовать для создания модуля, который соответствует количеству ЦП, HashValue создается с помощью последовательного увеличения значения TransactionID для обеспечения равномерного распределения по дереву B::
CREATE TABLE table1
(
TransactionID BIGINT NOT NULL,
UserID INT NOT NULL,
SomeInt INT NOT NULL
);
GO
-- Consider using bulk loading techniques to speed it up
ALTER TABLE table1
ADD [HashValue] AS (CONVERT (TINYINT, ABS([TransactionID]) % (32))) PERSISTED NOT NULL;
ALTER TABLE table1
ADD CONSTRAINT pk_table1 PRIMARY KEY CLUSTERED (HashValue, TransactionID, UserID);
GO
Вариант. Использование GUID в качестве ведущего ключевого столбца индекса
Если нет естественного разделителя, столбец GUID можно использовать в качестве ведущего ключевого столбца индекса, чтобы обеспечить равномерное распределение вставок. Использование идентификатора GUID в качестве первого столбца в подходе с применением индекса позволяет использовать секционирование для других функций, но эта методика также может привести к потенциальным недостаткам большего числа разбиений на страницы, низкой физической организации и низкой плотности страниц.
Примечание.
Использование идентификаторов GUID в качестве ведущих ключевых столбцов индексов — это отдельная тема для обсуждения. Подробное обсуждение достоинств и недостатков этого метода выходит за рамки этой статьи.
Использование хэш-секционирования с вычисляемым столбцом
Секционирование таблиц в SQL Server можно использовать для устранения чрезмерного состязания за кратковременные блокировки. Создание схемы хэш-секционирования с вычисляемым столбцом для секционированной таблицы — распространенный способ, реализуемый посредством следующих шагов.
Создайте новую файловую группу или используйте существующую файловую группу для хранения секций.
При использовании новой файловой группы равномерно распределите отдельные файлы по LUN, учитывая оптимальный макет. Если шаблон доступа включает большое количество вставок, создайте одинаковое число файлов, поскольку на компьютере SQL Server имеются физические ядра ЦП.
CREATE PARTITION FUNCTIONИспользуйте команду для секционирования таблиц на разделы X, где X — это количество физических ядер ЦП на компьютере SQL Server. (не менее чем до 32 секций).Примечание.
Выравнивание числа разделов в соотношении 1:1 с числом ядер ЦПУ не всегда необходимо. Во многих случаях это может быть меньше числа ядер ЦП. Наличие дополнительных секций может привести к дополнительным затратам на запросы, которые должны выполнять поиск всех разделов, и в этих случаях меньше секций может помочь. При тестировании SQLCAT на 64- и 128-разрядных логических системах ЦП с реальными рабочими нагрузками клиентов 32 секций достаточно для устранения чрезмерных конфликтов кратковременных блокировок и достижения целевых показателей масштабирования. В конечном итоге оптимальное количество секций должно быть определено с помощью тестирования.
Используйте команду
CREATE PARTITION SCHEME:- Привяжите функцию секционирования к файловым группам.
- Добавьте в таблицу хэш-столбец типа tinyint или smallint.
- Вычислите хорошее хэш-распределение. Например, используйте
HASHBYTESс модулем илиBINARY_CHECKSUM.
Следующий пример скрипта можно настроить с учетом вашей реализации:
--Create the partition scheme and function, align this to the number of CPU cores 1:1 up to 32 core computer
-- so for below this is aligned to 16 core system
CREATE PARTITION FUNCTION [pf_hash16](TINYINT)
AS RANGE LEFT
FOR VALUES (0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15);
CREATE PARTITION SCHEME [ps_hash16]
AS PARTITION [pf_hash16]
ALL TO ([ALL_DATA]);
-- Add the computed column to the existing table (this is an OFFLINE operation)
-- Consider using bulk loading techniques to speed it up
ALTER TABLE [dbo].[latch_contention_table]
ADD [HashValue] AS (CONVERT (TINYINT, ABS(BINARY_CHECKSUM([hash_col]) % (16)), (0))) PERSISTED NOT NULL;
--Create the index on the new partitioning scheme
CREATE UNIQUE CLUSTERED INDEX [IX_Transaction_ID]
ON [dbo].[latch_contention_table]([T_ID] ASC, [HashValue])
ON ps_hash16 (HashValue);
Этот скрипт можно использовать для хэширования таблицы, в которой возникли проблемы, вызванные конфликтом вставки первой/последней страницы. Этот метод перемещает состязание с последней страницы путем секционирования таблицы и распределения вставок между секциями таблицы с помощью операции модуля хэш-значения.
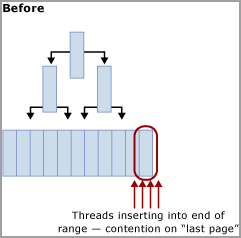
Что делает хэш-секционирование с вычисляемым столбцом
Как показано на схеме ниже, этот метод перемещает состязание с последней страницы путем перестроения индекса для хэш-функции и создания такого же количества секций, что и количество физических ядер ЦП на компьютере SQL Server. Вставки по-прежнему находятся в конце логического диапазона (последовательно увеличивающееся значение), но операция модуля хэш-значения обеспечивает разбиение вставок по разным сбалансированным деревьям, что сокращает количество узких мест. Это показано на приведенных ниже схемах.
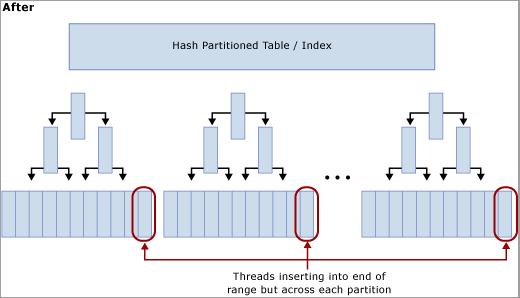
Компромиссы при использовании хэш-секционирования
Хотя хэш-секционирование может устранить конфликты при вставке, при принятии решения о необходимости использования этого метода следует учитывать несколько компромиссов.
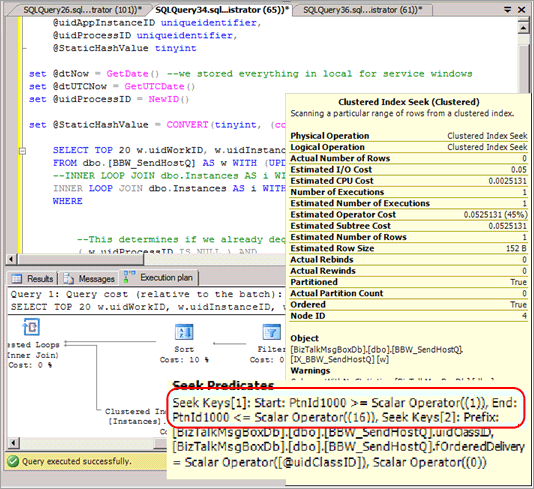
В большинстве случаев необходимо изменить запросы, чтобы включить хеш-раздел в предикат, что приводит к плану запроса, который не предусматривает устранение разделов при выполнении этих запросов. На следующем снимке экрана показан недопустимый план без удаления секции после реализации хэш-секционирования.
Он устраняет возможность удаления секций в некоторых других запросах, например в отчетах на основе диапазона.
При соединении хэш-секционированной таблицы с другой таблицей, для оптимизации секционирования, вторая таблица должна быть хэш-секционирована по тому же ключу, и этот хэш-ключ должен быть частью условий соединения.
Секционирование хэша предотвращает использование секционирования для других функций управления, таких как архивирование окон и функции переключения секций.
Хэш-секционирование — это эффективная стратегия устранения чрезмерного состязания за кратковременные блокировки, так как она увеличивает общую пропускную способность системы за счет уменьшения конкуренции при вставке. Поскольку существуют некоторые компромиссы, это может быть не оптимальным решением для некоторых шаблонов доступа.
Сводка по методам, используемым для устранения конфликтов кратковременных блокировок
В следующих двух разделах содержатся сводные сведения о приемах, которые можно использовать для устранения чрезмерных конфликтов кратковременных блокировок.
Непоследовательный ключ/индекс
Преимущества.
- Позволяет использовать другие функции секционирования, такие как архивирование данных с помощью схемы скользящих окон и функции переключения секций.
Недостатки.
- Возможные проблемы при выборе ключа или индекса, чтобы обеспечить достаточное равномерное распределения вставок все время.
- GUID в качестве начального столбца можно использовать для обеспечения равномерного распространения с той лишь оговоркой, что это может привести к чрезмерным операциям разбиения страниц.
- Случайные вставки в сбалансированном дереве могут привести к слишком большому числу операций разбиения на страницы и появлению конфликтов кратковременных блокировок на неконечных страницах.
Хэш-секционирование с помощью вычисляемого столбца
Преимущества.
- Прозрачность для вставок.
Недостатки.
- Секционирование нельзя использовать для предполагаемых функций управления, таких как архивация данных с помощью параметров переключения секций.
- Может вызвать проблемы с исключением секций для запросов, включая отдельные запросы и запросы выбора/обновления, основанные на диапазонах, а также запросы, выполняющие соединение.
- Добавление материализованных вычисляемых столбцов — это автономная операция.
Совет
Чтобы узнать больше методов, см. запись блога PAGELATCH_EX ожидания и тяжелые вставки.
Пошаговое руководство. Диагностика конфликтов с блокировкой
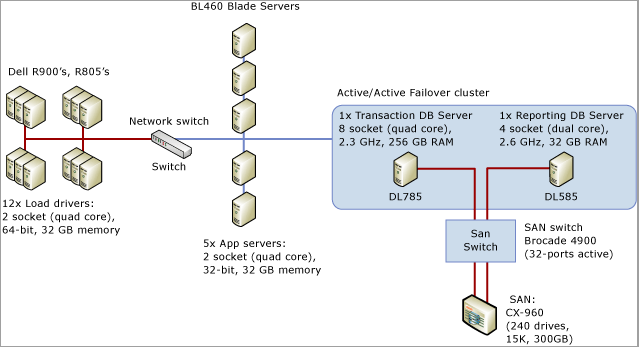
В следующем пошаговом руководстве демонстрируются средства и методы, описанные в разделах Диагностика конфликтов кратковременных блокировок SQL Server и Обработка конфликтов кратковременных блокировок для различных шаблонов таблиц для решения проблемы на примере реального использования. В этом сценарии описывается взаимодействие с клиентом для проведения нагрузочного тестирования системы точек продаж, которая имитировала приблизительно 8000 магазинов, выполняющих транзакции в приложении SQL Server, работающем на системе с 8 сокетами, 32 физическими ядрами и 256 ГБ памяти.
На следующей диаграмме показана конфигурация оборудования, используемая для тестирования системы точек продаж:
Симптом: горячие защелки
В этом случае мы наблюдали высокие ожидания для PAGELATCH_EX, где мы типично определяем высокую величину как среднее значение более 1 мс. В этом случае мы постоянно наблюдаем ожидания с превышением 20 мс.
После того как мы определили, что состязание за кратковременные блокировки было проблематичным, необходимо определить, что вызвало состязание за кратковременную блокировку.
Изоляция объекта, вызывающего конфликты с блокировкой
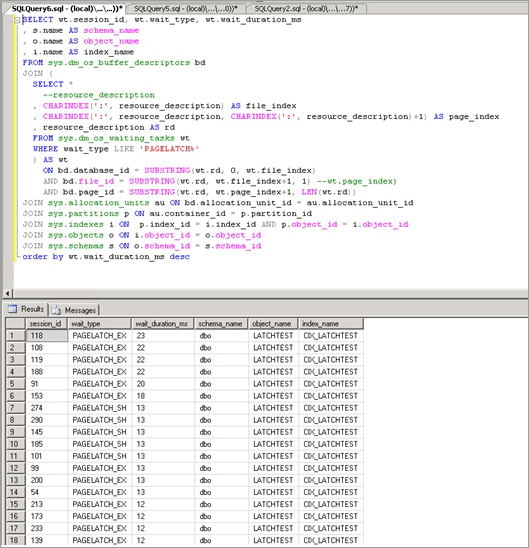
Следующий скрипт использует столбец resource_description для изоляции индекса, вызывающего PAGELATCH_EX спор:
Примечание.
Столбец resource_description, возвращаемый этим скриптом, предоставляет описание ресурса в формате <DatabaseID,FileID,PageID>, где имя базы данных, связанной с DatabaseID, можно определить путем передачи значения DatabaseID в функцию DB_NAME().
SELECT wt.session_id,
wt.wait_type,
wt.wait_duration_ms,
s.name AS schema_name,
o.name AS object_name,
i.name AS index_name
FROM sys.dm_os_buffer_descriptors AS bd
INNER JOIN (SELECT *,
--resource_description
CHARINDEX(':', resource_description) AS file_index,
CHARINDEX(':', resource_description, CHARINDEX(':', resource_description) + 1) AS page_index,
resource_description AS rd
FROM sys.dm_os_waiting_tasks AS wt
WHERE wait_type LIKE 'PAGELATCH%') AS wt
ON bd.database_id = SUBSTRING(wt.rd, 0, wt.file_index)
AND bd.file_id = SUBSTRING(wt.rd, wt.file_index + 1, 1) --wt.page_index)
AND bd.page_id = SUBSTRING(wt.rd, wt.page_index + 1, LEN(wt.rd))
INNER JOIN sys.allocation_units AS au
ON bd.allocation_unit_id = au.allocation_unit_id
INNER JOIN sys.partitions AS p
ON au.container_id = p.partition_id
INNER JOIN sys.indexes AS i
ON p.index_id = i.index_id
AND p.object_id = i.object_id
INNER JOIN sys.objects AS o
ON i.object_id = o.object_id
INNER JOIN sys.schemas AS s
ON o.schema_id = s.schema_id
ORDER BY wt.wait_duration_ms DESC;
Как показано здесь, конфликт находится в таблице LATCHTEST и индексе CIX_LATCHTEST. Обратите внимание, что имена были изменены для анонимизации рабочей нагрузки.
Для более продвинутого сценария, в котором опрос выполняется несколько раз и используется временная таблица для определения общего времени ожидания через настраиваемый период, обратитесь к разделу Дескрипторы буфера запросов для определения объектов, вызывающих конфликты кратковременных блокировок в приложении.
Альтернативный способ — изоляция объекта, вызывающего состязания за кратковременные блокировки
Иногда запрос может быть непрактичным sys.dm_os_buffer_descriptors. Так как память в системе, доступная для буферного пула, увеличивается, также увеличивается и время, необходимое для выполнения этого динамического административного представления. В системе размером 256 ГБ выполнение этого динамического административного представления может потребовать до 10 минут или более. Доступен альтернативный метод, который описан ниже и демонстрируется с другой рабочей нагрузкой, которая выполнялась в лаборатории.
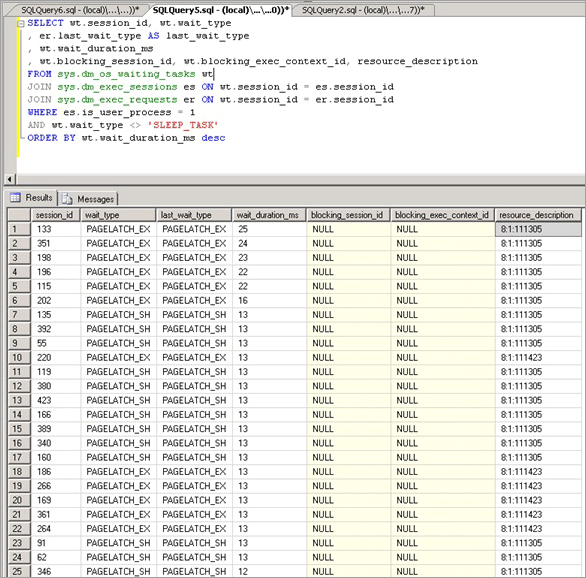
Запросите текущие ожидающие задачи, используя сценарий приложения Запрос sys.dm_os_waiting_tasks, упорядоченный по длительности ожидания.
Определите ключевую страницу, на которой наблюдалось сопровождение, что происходит, если несколько потоков будут выделены на одной странице. В этом примере потоки, выполняющие вставку, спорят за последнюю страницу в дереве B и ждут, пока не смогут получить блокировку
EX. Это указывается посредством resource_description в первом запросе, в нашем случае8:1:111305.Включите флаг трассировки 3604, который предоставляет дополнительные сведения о странице. Используйте следующий синтаксис, с помощью
DBCC PAGE, заменяя значение в скобках на значение, полученное через resource_description.Включите флаг трассировки 3604, чтобы включить вывод в консоль.
DBCC TRACEON (3604);Изучите сведения о странице:
DBCC PAGE (8, 1, 111305, -1);Изучите выходные данные DBCC. Должен быть связанный объект метаданных, в нашем случае —
78623323.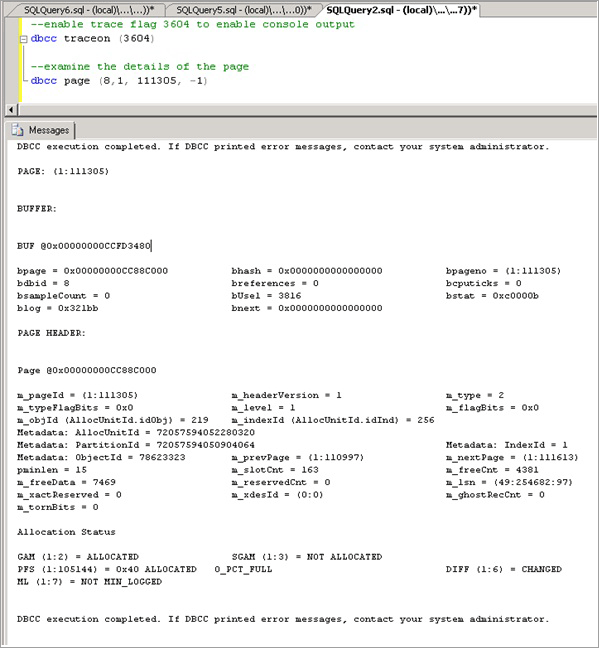
Теперь мы можем выполнить следующую команду, чтобы определить имя объекта, вызывающего спор, который, как ожидалось, .
LATCHTESTПримечание.
Убедитесь, что вы находитесь в правильном контексте базы данных, в противном случае возвращается
NULLзапрос.--get object name SELECT OBJECT_NAME(78623323);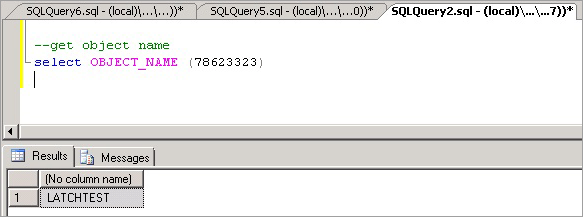
Сводка и результаты
Используя методы выше, мы смогли убедиться, что состязание происходило в кластеризованном индексе с последовательно увеличивающимся значением ключа в таблице, где было получено наибольшее число вставок. Этот тип конкуренции не является редкостью для индексов с последовательным увеличением ключевого значения, например datetime, идентификатор или созданного приложением ключа TransactionID.
Чтобы устранить эту проблему, мы использовали хэш-секционирование с использованием вычисляемого столбца и наблюдали повышение производительности на 690 %. В следующей таблице приведены сводные данные о производительности приложения до и после реализации хэш-секционирования с использованием вычисляемого столбца. После удаления узкого места, связанного с кратковременной блокировкой, использование ЦП значительно повышается вместе с пропускной способностью, как и ожидалось.
| Измерение | Перед хэш-секционированием | После хэш-секционирования |
|---|---|---|
| Бизнес-транзакций/с | 36 | 249 |
| Среднее время ожидания кратковременной блокировки страницы | 36 миллисекунд | 0,6 миллисекунд |
| Ожиданий кратковременных блокировок/с | 9,562 | 2,873 |
| Загруженность процессора SQL | 24 % | 78 % |
| Запросов пакетов SQL/с | 12,368 | 47,045 |
Как видно из предыдущей таблицы, правильное определение и устранение проблем с производительностью, вызванных чрезмерной блокировкой страницы, может оказать положительное влияние на общую производительность приложения.
Приложение. Альтернативный метод
Одна из возможных стратегий предотвращения чрезмерного несоответствия блокировок страниц заключается в заполнении строк с столбцом char , чтобы убедиться, что каждая строка использует полную страницу. Эта стратегия является вариантом, если общий размер данных мал, и вам нужно решить EX проблему блокировки страницы, вызванную следующим сочетанием факторов:
- малый размер строки;
- поверхностное сбалансированное дерево;
- шаблон доступа с высокой скоростью случайных операций вставки, выбора, обновления и удаления;
- небольшие таблицы, например временные таблицы очередей.
Заполняя строки до полной страницы, вы заставляете SQL выделить больше страниц, что делает их более доступными для вставок и уменьшает конфликты с блокировкой страниц EX.
Панели строк, чтобы гарантировать, что каждая строка занимает полную страницу
Для заполнения строк, чтобы они занимали всю страницу, можно использовать аналогичный приведенному ниже скрипт.
ALTER TABLE mytable ADD Padding CHAR(5000) DEFAULT NOT NULL ('X');
Примечание.
Используйте наименьший возможный символ, при котором одна строка занимает всю страницу, чтобы уменьшить требования к ЦП для значения заполнения и к дополнительному пространству, необходимому для записи строки в журнал. В высокопроизводительной системе на счету каждый байт.
Этот метод описан для полноты картины. На практике SQLCAT использует его только на небольшой таблице с 10 000 строками на одно задействование производительности. Этот метод имеет ограниченное применение из-за того, что он увеличивает нагрузку на память SQL Server для больших таблиц и может привести к состязанию кратковременных блокировок без буфера на неконечных страницах. Дополнительное давление на память может быть значительным ограничением для применения этого метода. С объемами памяти, доступными на современных серверах, большая часть рабочего набора для рабочих нагрузок OLTP обычно хранится в памяти. Когда набор данных увеличивается до размера, который больше не помещается в память, происходит значительное падение производительности. Таким образом, этот прием применим только к небольшим таблицам. Этот метод не используется SQLCAT для таких сценариев, как конкуренция при вставке на последней или завершающей странице для больших таблиц.
Внимание
Использование этой стратегии может привести к большому количеству ожиданий типа ACCESS_METHODS_HOBT_VIRTUAL_ROOT блокировки, так как эта стратегия может привести к большому количеству разбиений страниц, происходящих на неконечных уровнях дерева B. В этом случае SQL Server должен получить общие (SH) фиксаторы на всех уровнях, за которыми следует монопольная (EX) фиксация на страницах в дереве B, где возможно разделение страниц.
sys.dm_os_latch_stats Следует проверить ДАП на предмет большого количества ожиданий в ACCESS_METHODS_HOBT_VIRTUAL_ROOT типе защёлки после заполнения строк.
Приложение. Скрипты разрешения блокировок SQL Server
В этом разделе содержатся сценарии, которые можно использовать для диагностики и устранения проблем с блокировкой.
Запрос sys.dm_os_waiting_tasks упорядочен по идентификатору сеанса
Следующий пример скрипта запрашивает sys.dm_os_waiting_tasks, возвращает ожидания защелки, упорядоченные по идентификатору сеанса:
-- WAITING TASKS ordered by session_id
SELECT wt.session_id,
wt.wait_type,
er.last_wait_type AS last_wait_type,
wt.wait_duration_ms,
wt.blocking_session_id,
wt.blocking_exec_context_id,
resource_description
FROM sys.dm_os_waiting_tasks AS wt
INNER JOIN sys.dm_exec_sessions AS es
ON wt.session_id = es.session_id
INNER JOIN sys.dm_exec_requests AS er
ON wt.session_id = er.session_id
WHERE es.is_user_process = 1
AND wt.wait_type <> 'SLEEP_TASK'
ORDER BY session_id;
Запрос sys.dm_os_waiting_tasks упорядочен по длительности ожидания
Следующий скрипт выполняет запрос sys.dm_os_waiting_tasks, и возвращает ожидания защиты, упорядоченные по длительности.
-- WAITING TASKS ordered by wait_duration_ms
SELECT wt.session_id,
wt.wait_type,
er.last_wait_type AS last_wait_type,
wt.wait_duration_ms,
wt.blocking_session_id,
wt.blocking_exec_context_id,
resource_description
FROM sys.dm_os_waiting_tasks AS wt
INNER JOIN sys.dm_exec_sessions AS es
ON wt.session_id = es.session_id
INNER JOIN sys.dm_exec_requests AS er
ON wt.session_id = er.session_id
WHERE es.is_user_process = 1
AND wt.wait_type <> 'SLEEP_TASK'
ORDER BY wt.wait_duration_ms DESC;
Вычисление ожиданий за период времени
Следующий скрипт вычисляет и возвращает время ожидания кратковременных блокировок за период времени.
/* Snapshot the current wait stats and store so that this can be compared over a time period
Return the statistics between this point in time and the last collection point in time.
**This data is maintained in tempdb so the connection must persist between each execution**
**alternatively this could be modified to use a persisted table in tempdb. if that
is changed code should be included to clean up the table at some point.**
*/
USE tempdb;
GO
DECLARE @current_snap_time AS DATETIME;
DECLARE @previous_snap_time AS DATETIME;
SET @current_snap_time = GETDATE();
IF NOT EXISTS (SELECT name
FROM tempdb.sys.sysobjects
WHERE name LIKE '#_wait_stats%')
CREATE TABLE #_wait_stats
(
wait_type VARCHAR (128),
waiting_tasks_count BIGINT,
wait_time_ms BIGINT,
avg_wait_time_ms INT,
max_wait_time_ms BIGINT,
signal_wait_time_ms BIGINT,
avg_signal_wait_time INT,
snap_time DATETIME
);
INSERT INTO #_wait_stats (wait_type, waiting_tasks_count, wait_time_ms, max_wait_time_ms, signal_wait_time_ms, snap_time)
SELECT wait_type,
waiting_tasks_count,
wait_time_ms,
max_wait_time_ms,
signal_wait_time_ms,
getdate()
FROM sys.dm_os_wait_stats;
--get the previous collection point
SELECT TOP 1 @previous_snap_time = snap_time
FROM #_wait_stats
WHERE snap_time < (SELECT MAX(snap_time)
FROM #_wait_stats)
ORDER BY snap_time DESC;
--get delta in the wait stats
SELECT TOP 10 s.wait_type,
(e.waiting_tasks_count - s.waiting_tasks_count) AS [waiting_tasks_count],
(e.wait_time_ms - s.wait_time_ms) AS [wait_time_ms],
(e.wait_time_ms - s.wait_time_ms) / ((e.waiting_tasks_count - s.waiting_tasks_count)) AS [avg_wait_time_ms],
(e.max_wait_time_ms) AS [max_wait_time_ms],
(e.signal_wait_time_ms - s.signal_wait_time_ms) AS [signal_wait_time_ms],
(e.signal_wait_time_ms - s.signal_wait_time_ms) / ((e.waiting_tasks_count - s.waiting_tasks_count)) AS [avg_signal_time_ms],
s.snap_time AS [start_time],
e.snap_time AS [end_time],
DATEDIFF(ss, s.snap_time, e.snap_time) AS [seconds_in_sample]
FROM #_wait_stats AS e
INNER JOIN (SELECT *
FROM #_wait_stats
WHERE snap_time = @previous_snap_time) AS s
ON (s.wait_type = e.wait_type)
WHERE e.snap_time = @current_snap_time
AND s.snap_time = @previous_snap_time
AND e.wait_time_ms > 0
AND (e.waiting_tasks_count - s.waiting_tasks_count) > 0
AND e.wait_type NOT IN ('LAZYWRITER_SLEEP', 'SQLTRACE_BUFFER_FLUSH', 'SOS_SCHEDULER_YIELD',
'DBMIRRORING_CMD', 'BROKER_TASK_STOP', 'CLR_AUTO_EVENT',
'BROKER_RECEIVE_WAITFOR', 'WAITFOR', 'SLEEP_TASK',
'REQUEST_FOR_DEADLOCK_SEARCH', 'XE_TIMER_EVENT',
'FT_IFTS_SCHEDULER_IDLE_WAIT', 'BROKER_TO_FLUSH',
'XE_DISPATCHER_WAIT', 'SQLTRACE_INCREMENTAL_FLUSH_SLEEP')
ORDER BY (e.wait_time_ms - s.wait_time_ms) DESC;
--clean up table
DELETE FROM #_wait_stats
WHERE snap_time = @previous_snap_time;
Дескрипторы буфера запросов для определения объектов, вызывающих несоответствие блокировок
Следующий скрипт запрашивает дескрипторы буфера, чтобы определить, какие объекты связаны с наибольшим временем ожидания кратковременных блокировок.
IF EXISTS (SELECT *
FROM tempdb.sys.objects
WHERE [name] LIKE '#WaitResources%')
DROP TABLE #WaitResources;
CREATE TABLE #WaitResources
(
session_id INT,
wait_type NVARCHAR (1000),
wait_duration_ms INT,
resource_description sysname NULL,
db_name NVARCHAR (1000),
schema_name NVARCHAR (1000),
object_name NVARCHAR (1000),
index_name NVARCHAR (1000)
);
GO
DECLARE @WaitDelay AS VARCHAR (16), @Counter AS INT, @MaxCount AS INT, @Counter2 AS INT;
SELECT @Counter = 0, @MaxCount = 600, @WaitDelay = '00:00:00.100'; -- 600x.1=60 seconds
SET NOCOUNT ON;
WHILE @Counter < @MaxCount
BEGIN
INSERT INTO #WaitResources (session_id, wait_type, wait_duration_ms, resource_description)--, db_name, schema_name, object_name, index_name)
SELECT wt.session_id,
wt.wait_type,
wt.wait_duration_ms,
wt.resource_description
FROM sys.dm_os_waiting_tasks AS wt
WHERE wt.wait_type LIKE 'PAGELATCH%'
AND wt.session_id <> @@SPID;
-- SELECT * FROM sys.dm_os_buffer_descriptors;
SET @Counter = @Counter + 1;
WAITFOR DELAY @WaitDelay;
END
--SELECT * FROM #WaitResources;
UPDATE #WaitResources
SET db_name = DB_NAME(bd.database_id),
schema_name = s.name,
object_name = o.name,
index_name = i.name
FROM #WaitResources AS wt
INNER JOIN sys.dm_os_buffer_descriptors AS bd
ON bd.database_id = SUBSTRING(wt.resource_description, 0, CHARINDEX(':', wt.resource_description))
AND bd.file_id = SUBSTRING(wt.resource_description, CHARINDEX(':', wt.resource_description) + 1, CHARINDEX(':', wt.resource_description, CHARINDEX(':', wt.resource_description) + 1) - CHARINDEX(':', wt.resource_description) - 1)
AND bd.page_id = SUBSTRING(wt.resource_description, CHARINDEX(':', wt.resource_description, CHARINDEX(':', wt.resource_description) + 1) + 1, LEN(wt.resource_description) + 1)
-- AND wt.file_index > 0 AND wt.page_index > 0
INNER JOIN sys.allocation_units AS au
ON bd.allocation_unit_id = AU.allocation_unit_id
INNER JOIN sys.partitions AS p
ON au.container_id = p.partition_id
INNER JOIN sys.indexes AS i
ON p.index_id = i.index_id
AND p.object_id = i.object_id
INNER JOIN sys.objects AS o
ON i.object_id = o.object_id
INNER JOIN sys.schemas AS s
ON o.schema_id = s.schema_id;
SELECT * FROM #WaitResources
ORDER BY wait_duration_ms DESC;
GO
/*
--Other views of the same information
SELECT wait_type, db_name, schema_name, object_name, index_name, SUM(wait_duration_ms) [total_wait_duration_ms] FROM #WaitResources
GROUP BY wait_type, db_name, schema_name, object_name, index_name;
SELECT session_id, wait_type, db_name, schema_name, object_name, index_name, SUM(wait_duration_ms) [total_wait_duration_ms] FROM #WaitResources
GROUP BY session_id, wait_type, db_name, schema_name, object_name, index_name;
*/
--SELECT * FROM #WaitResources
--DROP TABLE #WaitResources;
Сценарий для хэш-секционирования
Использование этого скрипта описано в разделе Использование хэш-секционирования с вычисляемым столбцом и его необходимо настроить для целей вашей реализации.
--Create the partition scheme and function, align this to the number of CPU cores 1:1 up to 32 core computer
-- so for below this is aligned to 16 core system
CREATE PARTITION FUNCTION [pf_hash16](TINYINT)
AS RANGE LEFT
FOR VALUES (0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15);
CREATE PARTITION SCHEME [ps_hash16]
AS PARTITION [pf_hash16]
ALL TO ([ALL_DATA]);
-- Add the computed column to the existing table (this is an OFFLINE operation)
-- Consider using bulk loading techniques to speed it up
ALTER TABLE [dbo].[latch_contention_table]
ADD [HashValue] AS (CONVERT (TINYINT, ABS(BINARY_CHECKSUM([hash_col]) % (16)), (0))) PERSISTED NOT NULL;
--Create the index on the new partitioning scheme
CREATE UNIQUE CLUSTERED INDEX [IX_Transaction_ID]
ON [dbo].[latch_contention_table]([T_ID] ASC, [HashValue])
ON ps_hash16 (HashValue);