События
Присоединение к вызову ИИ Навыков
8 апр., 15 - 28 мая, 07
Отточите свои навыки ИИ и введите подметки, чтобы выиграть бесплатный экзамен сертификации
Зарегистрируйтесь!Этот браузер больше не поддерживается.
Выполните обновление до Microsoft Edge, чтобы воспользоваться новейшими функциями, обновлениями для системы безопасности и технической поддержкой.
Примечание
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
Область применения:![]() SQL Server 2019 (15.x)
SQL Server 2019 (15.x)
Важно!
Надстройка "Кластеры больших данных Microsoft SQL Server 2019" будет прекращена. Поддержка кластеров больших данных SQL Server 2019 завершится 28 февраля 2025 г. Все существующие пользователи SQL Server 2019 с Software Assurance будут полностью поддерживаться на этой платформе, а программное обеспечение будет продолжать поддерживаться с помощью накопительных обновлений для SQL Server до этого времени. Для получения дополнительной информации см. запись блога об объявлении и параметры работы с большими данными на платформе Microsoft SQL Server.
SQL Server предоставляет расширение для Azure Data Studio, включающее записные книжки развертывания. Записная книжка развертывания содержит документацию и код, которые можно использовать в Azure Data Studio для создания кластера больших данных SQL Server.
Изначально реализованы как проект с открытым исходным кодом, записные книжки реализованы в Azure Data Studio. Вы можете использовать markdown для текста в текстовых ячейках и одном из доступных ядер для написания кода в ячейках кода.
Записные книжки можно использовать для развертывания кластеров больших данных SQL Server.
Для запуска записной книжки также требуются следующие предварительные требования:
Помимо выше, для развертывания кластера больших данных также требуется следующее:
Запустите Azure Data Studio.
На вкладке "Подключения" выберите многоточие (...), а затем выберите "Развернуть SQL Server...".
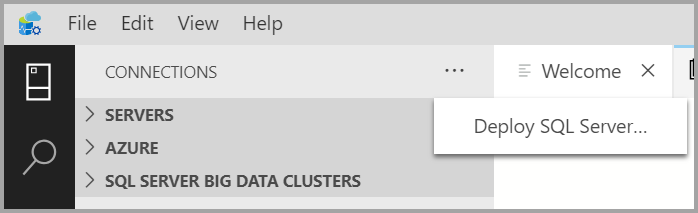
В параметрах развертывания выберите кластер больших данных SQL Server.
Из Цели развертывания, в разделе Параметры, выберите либо новый кластер Azure Kubernetes, либо существующий кластер службы Azure Kubernetes.
Примите условия конфиденциальности и лицензии.
Это диалоговое окно также проверяет, существуют ли необходимые средства для выбранного типа развертывания SQL на узле. Кнопка "Выбрать " не включена, пока проверка средств не будет выполнена успешно.
Выберите кнопку Выбрать. Это действие запускает процесс развертывания.
Параметры профиля развертывания можно настроить, следуя приведенным ниже инструкциям.
Выберите шаблон целевой конфигурации из доступных шаблонов. Доступные профили фильтруются в зависимости от типа целевого объекта развертывания, выбранного в предыдущем диалоговом окне.
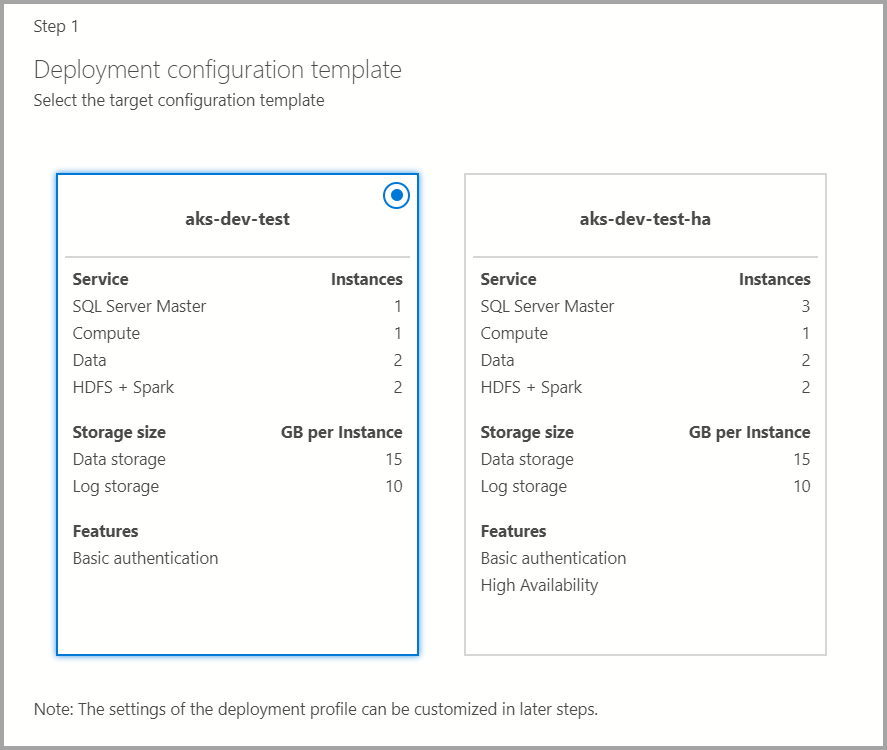
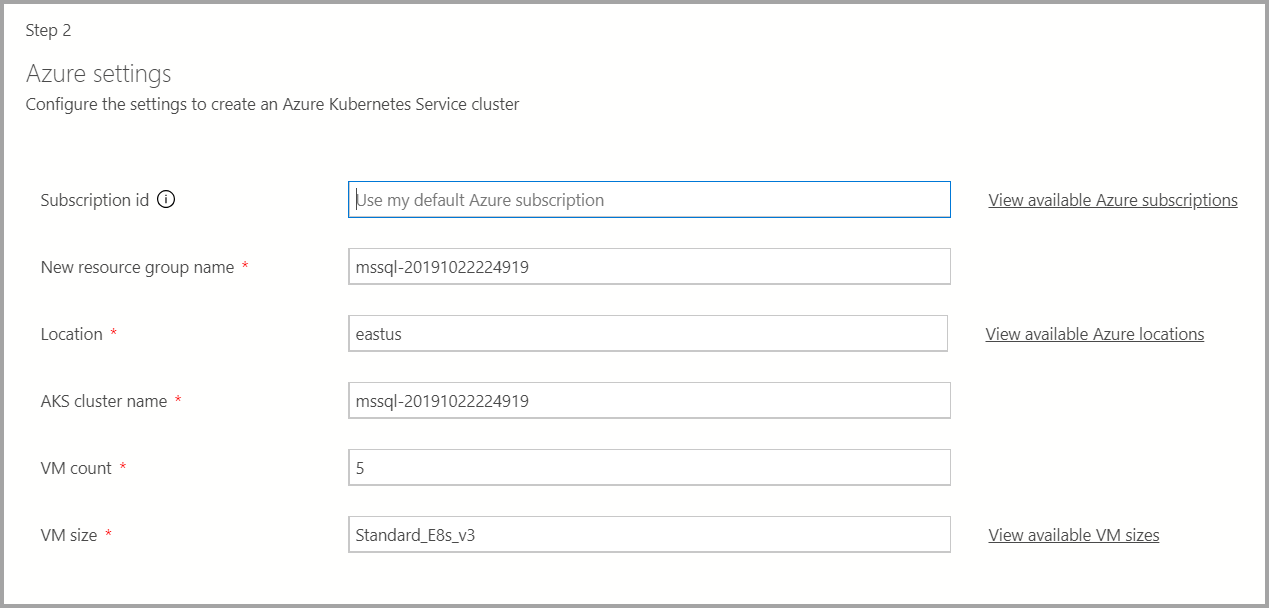
Если целевой объект развертывания является новой службой Azure Kubernetes (AKS), дополнительные сведения, такие как идентификатор подписки Azure, группа ресурсов, имя кластера AKS, количество виртуальных машин, размер и другие дополнительные сведения, необходимы для создания кластера AKS.
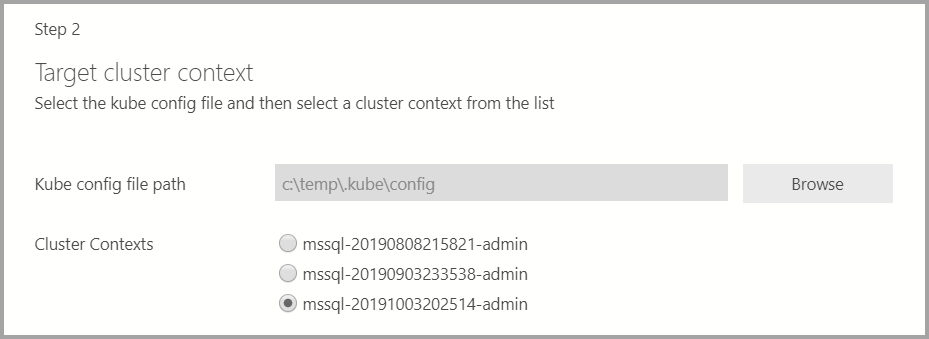
Если целевой объект развертывания является существующим кластером Kubernetes, мастер запросит путь к файлу конфигурации kube, чтобы импортировать настройки кластера Kubernetes. Убедитесь, что выбран соответствующий контекст кластера, в котором можно развернуть кластер больших данных SQL Server 2019.
Введите имя кластера больших данных, имя пользователя администратора и пароль. Эта же учетная запись используется для контроллера и SQL Server.
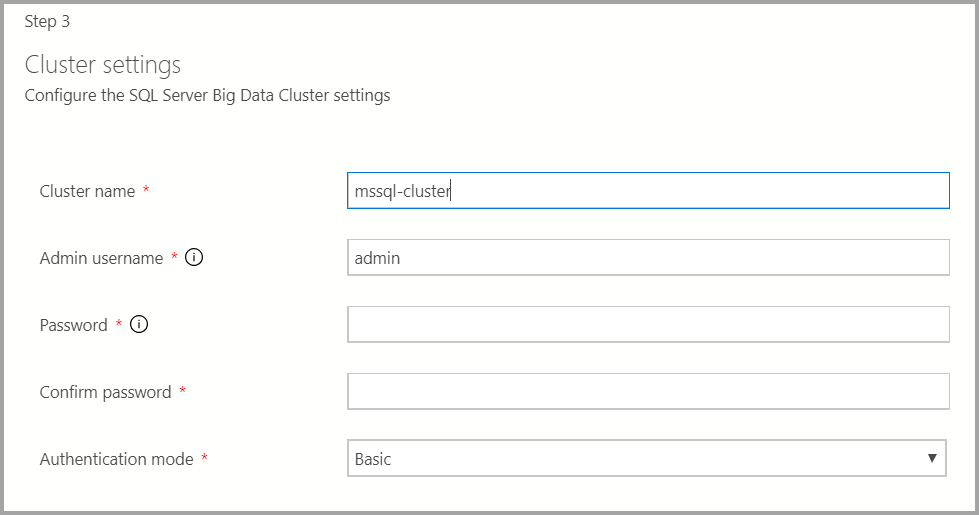
Введите параметры Docker, как необходимо.
Важно!
Убедитесь, что поле тега изображения является последним: 2019-CU13-ubuntu-20.04
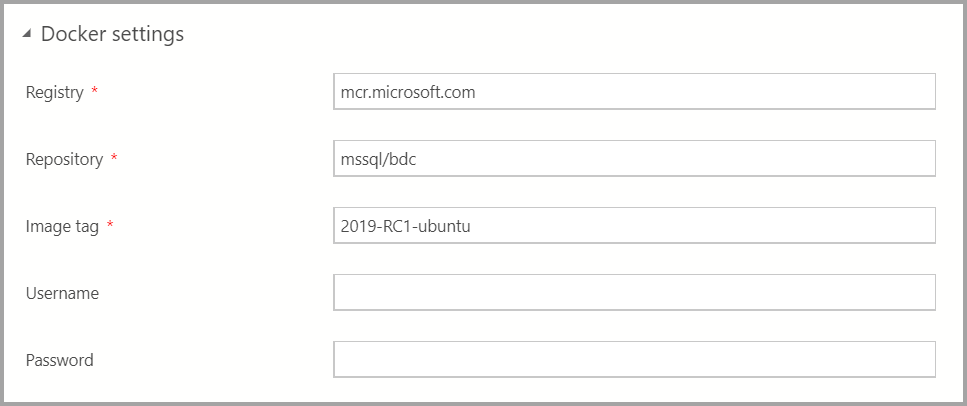
Если проверка подлинности AD доступна, введите параметры AD.
На этом экране есть входные данные для различных параметров, таких как масштабирование, конечные точки, хранилище и другие дополнительные параметры хранилища. Введите соответствующие значения и нажмите кнопку "Далее".
Введите количество экземпляров каждого компонента в кластере больших данных.
Экземпляр Spark можно добавить вместе с HDFS. Он включен в пул хранения или отдельно в пуле Spark.
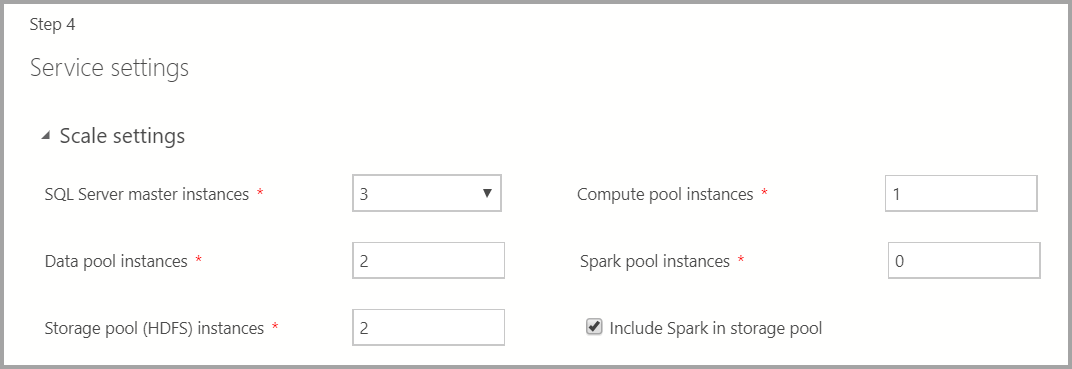
Дополнительные сведения о каждом из этих компонентов можно найти в главном экземпляре, пуле данных, пуле носителей или пуле вычислений.
Конечные точки по умолчанию были предварительно заполнены. Однако их можно изменить соответствующим образом.
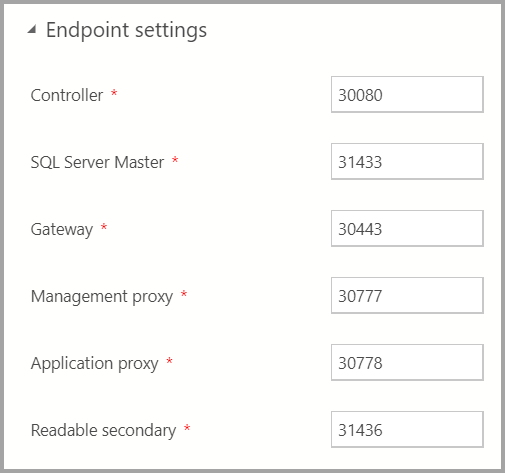
Параметры хранилища включают класс хранилища и размер требуемого хранилища для данных и журналов. Параметры можно применять в главном пуле хранилища, данных и SQL Server.

Дополнительные параметры хранилища можно добавить в разделе "Дополнительные параметры хранилища"
Пул хранения (HDFS)
Пул данных
Главный сервер SQL Server

На этом экране приведены все входные данные, предоставленные для развертывания кластера больших данных. Файлы конфигурации можно скачать с помощью кнопки "Сохранить файлы конфигурации ". Выберите "Скрипт в записную книжку", чтобы экспортировать всю конфигурацию развертывания в записную книжку. После открытия записной книжки выберите "Запустить ячейки ", чтобы начать развертывание кластера больших данных в выбранном целевом объекте.
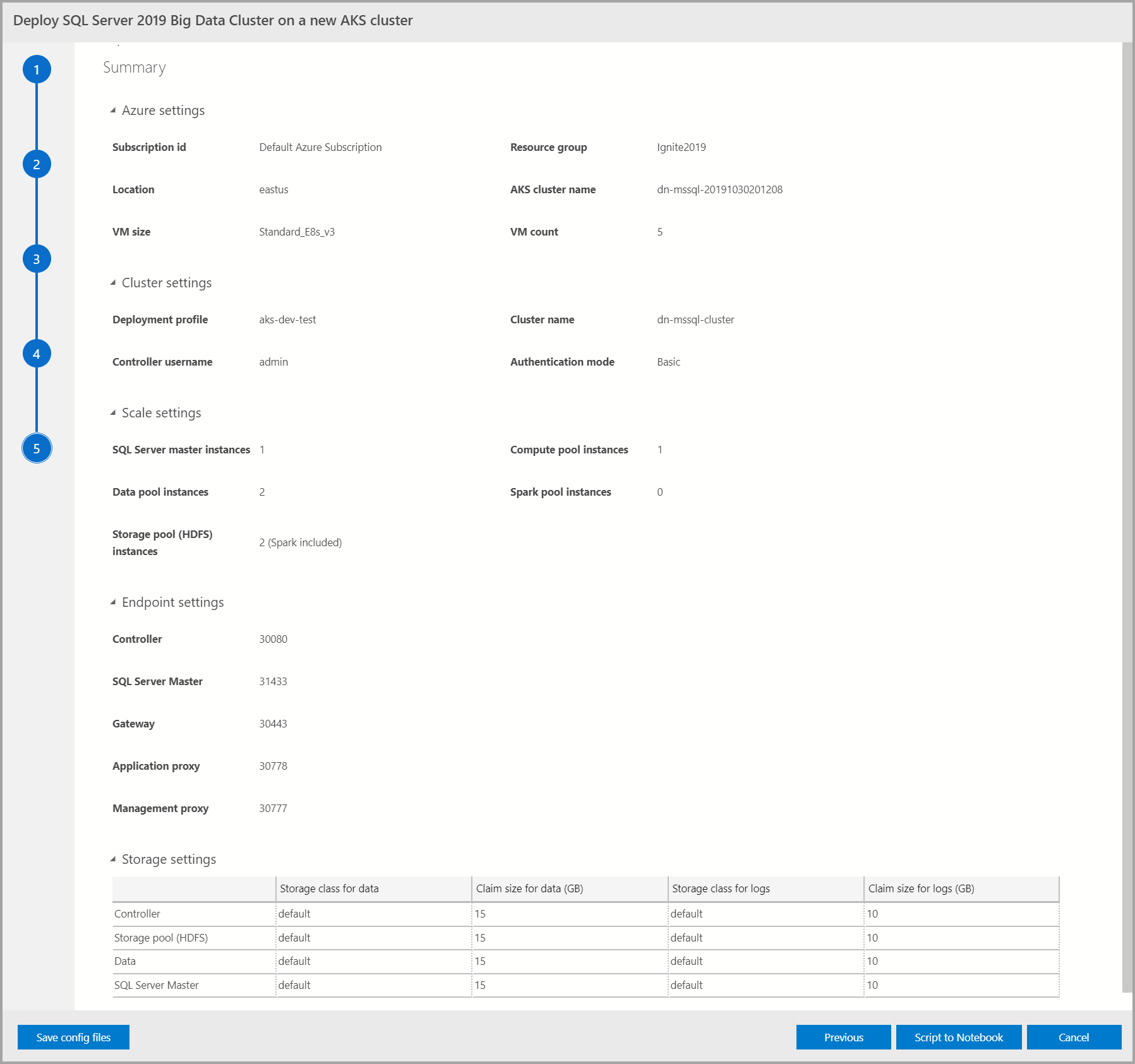
Дополнительные сведения о развертывании см. в руководстве по развертыванию кластеров больших данных SQL Server.
События
Присоединение к вызову ИИ Навыков
8 апр., 15 - 28 мая, 07
Отточите свои навыки ИИ и введите подметки, чтобы выиграть бесплатный экзамен сертификации
Зарегистрируйтесь!