Примечание.
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
Область применения:![]() SQL Server 2019 (15.x)
SQL Server 2019 (15.x)
Important
Кластеры больших данных Microsoft SQL Server 2019 прекращены. Поддержка кластеров больших данных SQL Server 2019 закончилась с 28 февраля 2025 г. Дополнительные сведения см. в записи блога объявлений и параметрах больших данных на платформе Microsoft SQL Server.
В этой статье описываются ресурсы, развернутые кластером больших данных SQL Server.
Кластер больших данных развертывает pods на основе профиля развертывания. Дополнительные сведения см. в конфигурациях по умолчанию.
В этой статье описываются модули, развернутые с помощью профиля aks-dev-test-ha и содержащие пул Spark. Запросите Kubernetes, чтобы просмотреть поды, развернутые в вашем кластере. В следующем примере возвращается список pod в определённом неймспейсе.
kubectl get pods -n <namespace>
Замените <namespace> именем кластера больших данных.
Дополнительные сведения см. в статье "Развертывание кластеров больших данных SQL Server в Kubernetes".
На следующей схеме показаны компоненты, развернутые в кластере больших данных:
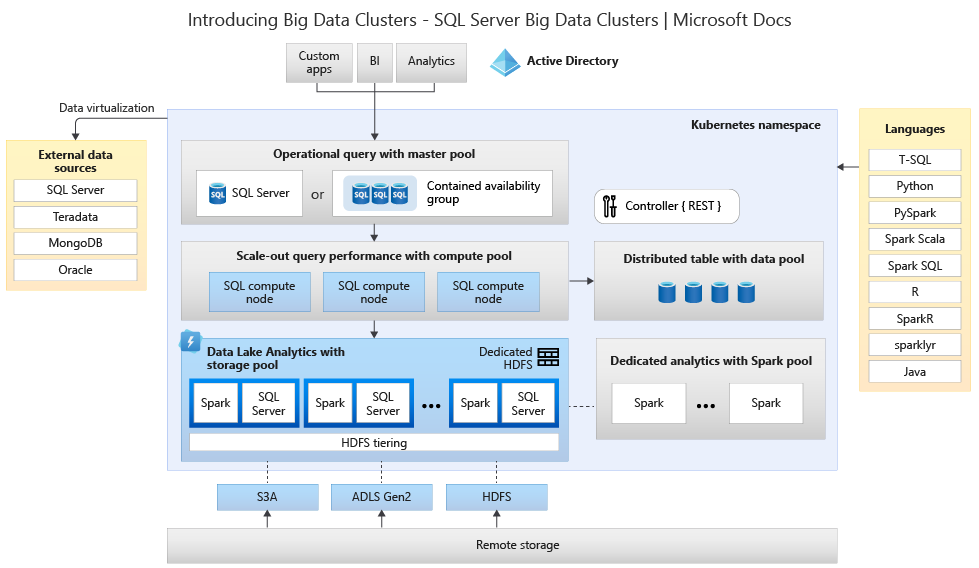
Сведения об архитектуре см. в разделе "Общие сведения о кластерах больших данных SQL Server".
Deployed pods
В следующей таблице перечислены модули pod, развернутые в кластере больших данных.
| Name | Area |
|---|---|
control-<nnnn> |
Control |
controldb-<#> |
Control |
controlwd-<nnnn> |
Control |
logsdb-<#> |
Control |
logsui-<nnnn> |
Control |
metricsdb-<#> |
Control |
metricsdc-<nnnn> |
Control |
metricsui-<nnnn> |
Control |
mgmtproxy-<nnnn> |
Control |
zookeeper-<#> |
Control |
dns-<nnnn> |
Control |
master-<#n> |
Master instance |
operator-<nnnn> |
Master instance |
compute-<#n>-<#m> |
Compute pool |
data-<#>-<#> |
Data pool |
storage-<#>-<#> |
Storage pool |
nmnode-<#>-<#> |
Storage pool |
sparkhead-<#> |
Storage pool |
appproxy-<#m> |
Application pool |
gateway-<#> |
Gateway service |
Не все pods входят в каждый кластер больших данных. Развертывания с высокой доступностью или интеграцией с Active Directory включают определенные поды.
Специфические высокодоступные модули.
operator-<nnnn>zookeeper-<#>
Специфичные поды Active Directory:
dns-<nnnn>
В следующих разделах описываются поды и перечисляются контейнеры в каждом поде.
Control
Модули pod управления предоставляют службу управления.
| Pod name | Count | Тип контроллера Kubernetes | Containers |
|---|---|---|---|
control-# |
1 | ReplicaSet | - controller- security-support- fluentbit |
controldb |
1 | StatefulSet | - mssql-server- fluentbit |
controlwd |
1 | ReplicaSet | - controlwatchdog |
logsdb-# |
1 | StatefulSet | - elasticsearch |
logsui |
1 | ReplicaSet | - kibana |
metricsdb-# |
1 | StatefulSet | - influxdb |
metricsdc |
1 на узел Kubernetes. | DaemonSet | - telegraf |
metricsui-nnnn |
1 | ReplicaSet | - grafana |
mgmtproxy-nnnn |
1 | ReplicaSet | - service-proxy- fluentbit |
dns-nnnn |
0 или 1 для интеграции Active Directory | ReplicaSet | - dns- fluentbit |
Master instance
master-<#n> — главный экземпляр SQL Server.
- Управляет пулом данных с помощью DDL
- Управление данными в пуле данных с помощью DML
- Переносит выполнение аналитических запросов на пул данных
| Pod name | Count | Тип контроллера Kubernetes | Containers |
|---|---|---|---|
master-<#n> |
1 или более для обеспечения высокой доступности. | StatefulSet | - mssql-server- fluentbit- collectd- mssql-ha-supervisor
*
|
operator* |
0 или 1 для обеспечения высокой доступности | ReplicaSet | - mssql-ha-operator |
* Только развертывания с высоким уровнем доступности. Оператор реализует и регистрирует пользовательское определение ресурсов для SQL Server и ресурсов группы доступности. При развертывании оператора он регистрируется в качестве прослушивателя уведомлений о ресурсах SQL Server, развертываемых в кластере Kubernetes.
mssql-ha-supervisor поддерживает группу доступности.
Каждый master модуль pod содержит один экземпляр SQL Server. Развертывание с высоким уровнем доступности включает 3 модуля pod. Каждый модуль pod включает экземпляр SQL Server с базами данных в группе доступности AlwaysOn SQL Server.
Включите дополнительные pod во время развертывания в зависимости от рабочей нагрузки.
Compute pool
Пул вычислений предоставляет экземпляр SQL Server для вычислений.
| Pod name | Count | Тип контроллера Kubernetes | Containers |
|---|---|---|---|
compute-<#n>-<#m> |
1 или более. | StatefulSet | - mssql-server- fluentbit- collectd |
-
#nопределяет пул вычислений. -
#mопределяет идентификатор экземпляра в пуле.
Экземпляры SQL Server пула вычислений не имеют состояния. Им требуется только место для хранения tempdb.
Включите дополнительные pod во время развертывания в зависимости от рабочей нагрузки.
Data pool
Пул данных предоставляет экземпляры SQL Server для хранения и вычислений.
| Pod name | Count | Тип контроллера Kubernetes | Containers |
|---|---|---|---|
data-<#n>-<#m> |
0 или более | StatefulSet | - mssql-server - fluentbit- collectd |
-
#nопределяет пул данных. -
#mопределяет идентификатор экземпляра в пуле.
Добавьте дополнительные контейнеры при развертывании, в зависимости от рабочей нагрузки.
Storage pool
Пул хранения данных поддерживает прием данных через Spark, хранение в HDFS, доступ к данным через конечные точки HDFS и SQL Server.
| Pod name | Count | Тип контроллера Kubernetes | Containers |
|---|---|---|---|
storage-0-# |
1 или более. Добавьте дополнительные контейнеры при развертывании, в зависимости от рабочей нагрузки. | StatefulSet | - hadoop- mssql-server- fluentbit |
nmnode-0-# |
1 или более для обеспечения высокой доступности | StatefulSet | - hadoop- fluentbit |
sparkehead-# |
1 или более для обеспечения высокой доступности | StatefulSet | - hadoop-yarn-jobhistory- hadoop-livy-sparkhistory- hadoop-hivemetastore-- fluentbit |
zookeeper |
0 или 3 для обеспечения высокой доступности. | StatefulSet | - zookeeper- fluentbit |
Application pool
Пул приложений включается в некоторые профили конфигурации тестов. Пул приложений размещает прокси-серверы службы приложений, которые определяются при развертывании приложений для кластеров больших данных.
appproxy — это веб-API, который располагается перед пулом приложений. Он проходит проверку подлинности пользователей, а затем направляет запросы в приложения.
| Pod name | Тип контроллера Kubernetes | Containers |
|---|---|---|
appproxy |
ReplicaSet | - app-service-proxy- fluentbit |
Дополнительные сведения см. в разделе "Знакомство с развертыванием приложений в кластере больших данных".
Добавьте дополнительные контейнеры при развертывании, в зависимости от рабочей нагрузки.
Gateway service
Службы шлюза предоставляют шлюз Knox для Spark, HDFS, Yarn, пользовательского интерфейса Yarn и пользовательского интерфейса Spark.
| Pod name | Тип контроллера Kubernetes | Containers |
|---|---|---|
gateway-<#> |
StatefulSet | - knox- fluentbit |
Поддерживается только один шлюз.
Ссылки на контейнеры с открытым кодом
Дополнительные сведения о конкретных проектах и версиях с открытым исходным кодом см. в справочнике по программному обеспечению с открытым кодом.
Next steps
Дополнительные сведения о кластерах больших данных SQL Server см. в следующих ресурсах: