Примечание
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
Область применения:![]() SQL Server 2019 (15.x)
SQL Server 2019 (15.x)
Это важно
Надстройка "Кластеры больших данных Microsoft SQL Server 2019" будет прекращена. Поддержка кластеров больших данных SQL Server 2019 завершится 28 февраля 2025 г. Все существующие пользователи SQL Server 2019 с Software Assurance будут полностью поддерживаться на этой платформе, а программное обеспечение будет продолжать поддерживаться с помощью накопительных обновлений для SQL Server до этого времени. Для получения дополнительной информации см. запись блога об объявлении и параметры работы с большими данными на платформе Microsoft SQL Server.
В SQL Server 2019 (15.x) кластеры больших данных SQL Server позволяют развертывать масштабируемые кластеры КОНТЕЙНЕРОВ SQL Server, Spark и HDFS, работающих в Kubernetes. Эти компоненты работают параллельно, позволяя считывать, записывать и обрабатывать большие данные в Transact-SQL или Spark, благодаря чему вы можете с легкостью объединять и анализировать важные реляционные данные с объемными большими данными.
Начало работы
- Сначала см. статью "Начало работы с кластерами больших данных SQL Server"
- Сведения о новых функциях последнего выпуска см. в заметках о выпуске
- Часто задаваемые вопросы см. в разделе " Часто задаваемые вопросы о кластерах больших данных"
Архитектура кластеров больших данных
На следующей схеме показаны компоненты кластера больших данных SQL Server:

Контроллер
Контроллер обеспечивает управление и безопасность кластера. Она содержит службу управления, хранилище конфигураций и другие службы уровня кластера, такие как Kibana, Grafana и elastic Search.
Пул вычислений
Пул вычислений предоставляет вычислительные ресурсы кластеру. Он содержит узлы с SQL Server на подах Linux. Контейнеры в пуле вычислений делятся на экземпляры вычислений SQL для выполнения конкретных задач обработки.
Пул данных
Пул данных используется для сохранения данных. Пул данных состоит из одного или нескольких pod'ов, работающих под управлением SQL Server на Linux. Он используется для приема данных из запросов SQL или заданий Spark.
Пул хранения
Пул хранилища состоит из модулей, включающих SQL Server на Linux, Spark и HDFS. Все узлы хранилища в кластере больших данных SQL Server являются членами кластера HDFS.
Подсказка
Подробный обзор архитектуры и установки кластера больших данных см. в разделе "Семинар: Архитектура кластеров больших данных Microsoft SQL Server".
Пул приложений
Развертывание приложений позволяет развертывать приложения в кластерах больших данных SQL Server, предоставляя интерфейсы для создания, управления и запуска приложений.
Сценарии и компоненты
Кластеры больших данных SQL Server обеспечивают гибкость в взаимодействии с большими данными. Вы можете запрашивать внешние источники данных, хранить большие данные в HDFS, управляемые SQL Server, или запрашивать данные из нескольких внешних источников данных через кластер. Затем можно использовать данные для ИИ, машинного обучения и других задач анализа.
Использование кластеров больших данных SQL Server для:
- Развертывание масштабируемых кластеров SQL Server, Spark и контейнеров HDFS, выполняемых в Kubernetes.
- Чтение, запись и обработка больших данных из Transact-SQL или Spark.
- Простое объединение и анализ ценных реляционных данных и больших данных крупного объема.
- Запрос внешних источников данных.
- Хранение больших данных в HDFS под управлением SQL Server.
- Запрос данных из нескольких внешних источников данных через кластер.
- Использование данных для искусственного интеллекта, машинного обучения и других задач анализа.
- Развертывание и запуск приложений в Кластерах больших данных.
- Виртуализация данных с помощью PolyBase. Запрос данных из внешнего SQL Server, Oracle, Teradata, MongoDB и универсальных источников данных ODBC с внешними таблицами.
- Обеспечение высокой доступности для главного экземпляра SQL Server и всех баз данных с помощью технологии группы доступности AlwaysOn.
В следующих разделах приведены дополнительные сведения об этих сценариях.
Виртуализация данных
Используя PolyBase, кластеры больших данных SQL Server могут запрашивать внешние источники данных без перемещения или копирования данных. SQL Server 2019 (15.x) представляет новые соединители для источников данных, дополнительные сведения см. в статье "Новые возможности PolyBase 2019?".
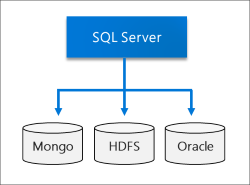
Озеро данных
Кластер больших данных SQL Server включает масштабируемый пул носителей HDFS. Это можно использовать для хранения больших данных, потенциально полученных из нескольких внешних источников. После хранения больших данных в HDFS в кластере больших данных можно анализировать и запрашивать данные и объединять их с реляционными данными.
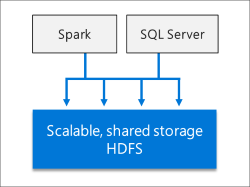
Интегрированный ИИ и машинное обучение
Кластеры больших данных SQL Server позволяют выполнять задачи искусственного интеллекта и машинного обучения для данных, хранящихся в пулах носителей HDFS и пулах данных. Вы можете использовать Spark, а также встроенные средства искусственного интеллекта в SQL Server с помощью R, Python, Scala или Java.

Управление и мониторинг
Управление и мониторинг предоставляются с помощью сочетания средств командной строки, API, порталов и динамических административных представлений.
Azure Data Studio можно использовать для выполнения различных задач в кластере больших данных:
- Встроенные фрагменты кода для распространенных задач управления.
- Возможность просмотра HDFS, отправки файлов, предварительных версий и создания каталогов.
- Возможность создавать, открывать и запускать записные книжки, совместимые с Jupyter.
- Мастер виртуализации данных для упрощения создания внешних источников данных (включено расширением Виртуализации данных).
Основные понятия Kubernetes
Кластер больших данных SQL Server — это кластер контейнеров Linux, управляемых Kubernetes.
Kubernetes — это оркестратор контейнеров с открытым исходным кодом, который может масштабировать развертывания контейнеров в соответствии с необходимостью. В следующей таблице определены некоторые важные терминологии Kubernetes:
| Срок | Описание |
|---|---|
| Гроздь | Кластер Kubernetes — это набор компьютеров, известных как узлы. Один узел управляет кластером и назначается главным узлом; Остальные узлы являются рабочими узлами. Главный мастер Kubernetes отвечает за распределение работы между работниками и мониторинг работоспособности кластера. |
| Узел | Узел запускает контейнерные приложения. Это может быть физическая машина или виртуальная машина. Кластер Kubernetes может содержать смесь физических машин и узлов виртуальных машин. |
| Стручок | Модуль pod — это единица атомарного развертывания Kubernetes. Pod — это логическая группа одного или нескольких контейнеров и связанных ресурсов, необходимых для запуска приложения. Каждый модуль pod выполняется на узле; узел может запускать один или несколько модулей pod. Главный узел Kubernetes автоматически назначает поды узлам в кластере. |
В кластерах больших данных SQL Server Kubernetes отвечает за состояние кластера. Kubernetes создает и настраивает узлы кластера, назначает поды узлам и контролирует работоспособность кластера.
Связанный контент
- Начало работы с развертыванием кластеров больших данных SQL Server
- Восстановление базы данных в главном экземпляре кластера больших данных SQL Server
- Отправка заданий Spark в кластерах больших данных SQL Server в Azure Data Studio
- Семинар по архитектуре кластеров больших данных
- Кластеры больших данных вкратце