Примечание.
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
API запроса — это экспериментальный веб-API, который позволяет запрашивать модель SLM, встроенную в Microsoft Edge, из кода JavaScript веб-сайта или расширения браузера. Используйте API запросов для создания и анализа текста или логики приложения на основе введенных пользователем данных, а также для поиска инновационных способов интеграции возможностей разработки запросов в веб-приложение.
Подробное содержимое:
- Доступность API запроса
- Альтернативы и преимущества API запроса
- Модель Phi-4-mini
- Включение API запроса
- См. рабочий пример
- Использование API запроса
- Обратная связь
- См. также
Доступность API запроса
API запроса доступен в качестве предварительной версии для разработчиков в каналах Microsoft Edge Canary или Dev, начиная с версии 138.0.3309.2.
API запросов предназначен для выявления вариантов использования и выявления проблем, возникающих при использовании встроенных SMS. Ожидается, что этот API будет заменен другими экспериментальными API для конкретных задач на основе ИИ, таких как помощь в написании и перевод текста. Дополнительные сведения об этих других API см. в следующих разделах:
Суммирование, запись и перезапись текста с помощью API-интерфейсов помощи по написанию
Репозиторий webmachinelearning /translation-api .
Альтернативы и преимущества API запроса
Чтобы использовать возможности ИИ на веб-сайтах и расширениях браузера, можно также использовать следующие методы:
Отправка сетевых запросов в облачные службы ИИ, например Azure решения ИИ.
Запуск локальных моделей ИИ с помощью API веб-нейронной сети (WebNN) или среды выполнения ONNX для Интернета.
API запроса использует SLM, который выполняется на том же устройстве, где используются входные и выходные данные модели (то есть локально). Это имеет следующие преимущества по сравнению с облачными решениями:
Снижение стоимости: Использование облачной службы ИИ не связано с затратами.
Независимость сети: После начального скачивания модели при запросе модели не возникает задержки в сети, а также может использоваться, когда устройство находится в автономном режиме.
Улучшенная конфиденциальность: Входные данные для модели никогда не покидают устройство и не собираются для обучения моделей ИИ.
API запроса использует модель, предоставляемую Microsoft Edge и встроенную в браузер, которая обеспечивает дополнительные преимущества по сравнению с пользовательскими локальными решениями, такими как решения, основанные на WebGPU, WebNN или WebAssembly:
Общие одноразовые затраты: Модель, предоставляемая браузером, загружается при первом вызове API и совместном использовании на всех веб-сайтах, работающих в браузере, что снижает сетевые затраты для пользователя и разработчика.
Упрощенное использование веб-разработчиков: Встроенная модель может быть запущена с помощью простых веб-API и не требует опыта ИИ/ML или сторонних платформ.
Модель Phi-4-mini
API запросов позволяет запрашивать Phi-4-mini — мощную малоязычную модель, которая отличается от текстовых задач, встроенная в Microsoft Edge. Дополнительные сведения о Phi-4-mini и его возможностях см. в карта модели на странице microsoft/Phi-4-mini-instruct.
Заявление об отказе от ответственности
Как и другие языковые модели, семейство моделей Phi потенциально может вести себя несправедливо, ненадежно или оскорбительно. Дополнительные сведения о рекомендациях по ИИ модели см. в статье Рекомендации по ответственному использованию ИИ.
Требования к оборудованию
Предварительная версия API запроса предназначена для работы на устройствах с аппаратными возможностями, которые создают выходные данные SLM с прогнозируемым качеством и задержкой. Api запросов в настоящее время ограничен следующими:
Операционная система: Windows 10 или 11 и macOS 13.3 или более поздней версии.
Хранения: По крайней мере 20 ГБ доступно на томе, который содержит профиль Edge. Если доступное хранилище будет меньше 10 ГБ, модель будет удалена, чтобы другие функции браузера имели достаточно места для работы.
GPU: 5,5 ГБ виртуальной памяти или больше.
Сети: Неограниченный план данных или неограниченные подключения. Модель не загружается при использовании лимитного подключения.
Чтобы проверка, поддерживает ли ваше устройство предварительную версию API запроса, см. статью Включение API запроса ниже и проверка класс производительности устройства.
Из-за экспериментального характера API запроса вы можете столкнуться с проблемами на определенных конфигурациях оборудования. Если вы видите проблемы с определенными конфигурациями оборудования, отправьте отзыв, открыв новую проблему в репозитории MSEdgeExplainers.
Доступность модели
При первом вызове веб-сайта встроенного API ИИ потребуется начальное скачивание модели. Вы можете отслеживать скачивание модели с помощью параметра монитора при создании нового сеанса API запроса. Дополнительные сведения см. в разделе Мониторинг хода загрузки модели ниже.
Включение API запроса
Чтобы использовать API запросов в Microsoft Edge, выполните следующие действия:
Убедитесь, что используется последняя версия Microsoft Edge Canary или Dev (версия 138.0.3309.2 или более поздняя). См . статью Стать участником программы предварительной оценки Microsoft Edge.
В Microsoft Edge Canary или Dev откройте новую вкладку или окно и перейдите по адресу
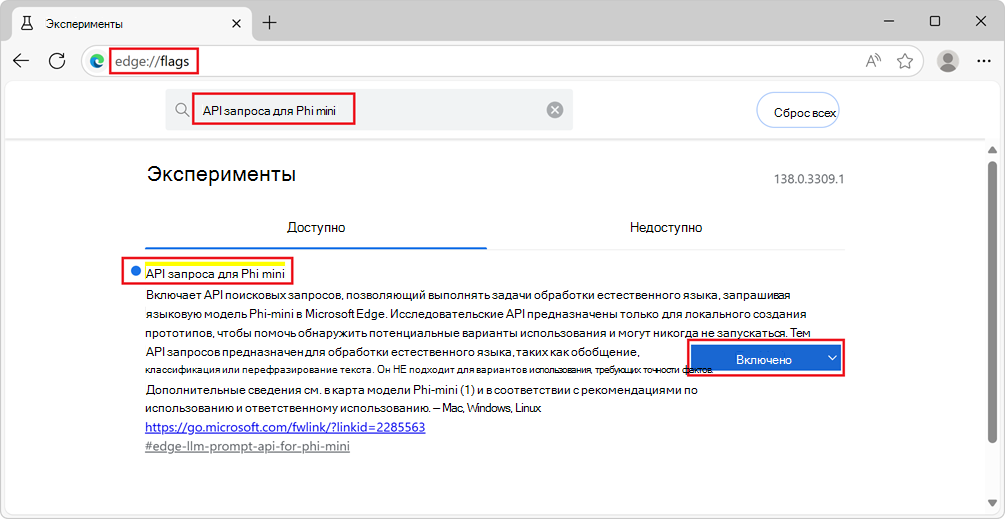
edge://flags/.В поле поиска в верхней части страницы введите API запроса для Phi mini.
Страница фильтруется для отображения соответствующего флага.
В разделе API запроса для Phi mini выберите Включено:
При необходимости, чтобы локально регистрировать сведения, которые могут быть полезны при отладке проблем, также включите флаг Включить журналы отладки модели ИИ устройства .
Перезапустите Microsoft Edge Canary или Dev.
Чтобы проверка, соответствует ли ваше устройство требованиям к оборудованию для предварительной версии разработчика Api командной строки, откройте новую вкладку, перейдите по адресу
edge://on-device-internalsи проверка значение класса производительности устройства.Если класс производительности устройства — Высокий или более высокий, на вашем устройстве должен поддерживаться API запроса. Если вы продолжаете замечать проблемы, создайте новую проблему в репозитории MSEdgeExplainers.
См. рабочий пример
Чтобы просмотреть API запроса в действии и просмотреть существующий код, использующий API, выполните следующие действия:
Включите API запроса, как описано выше.
В браузере Microsoft Edge Canary или Dev откройте вкладку или окно и перейдите на тестовую площадку API запроса.
В области навигации Встроенные игровые площадки ИИ слева выбран пункт Запрос .
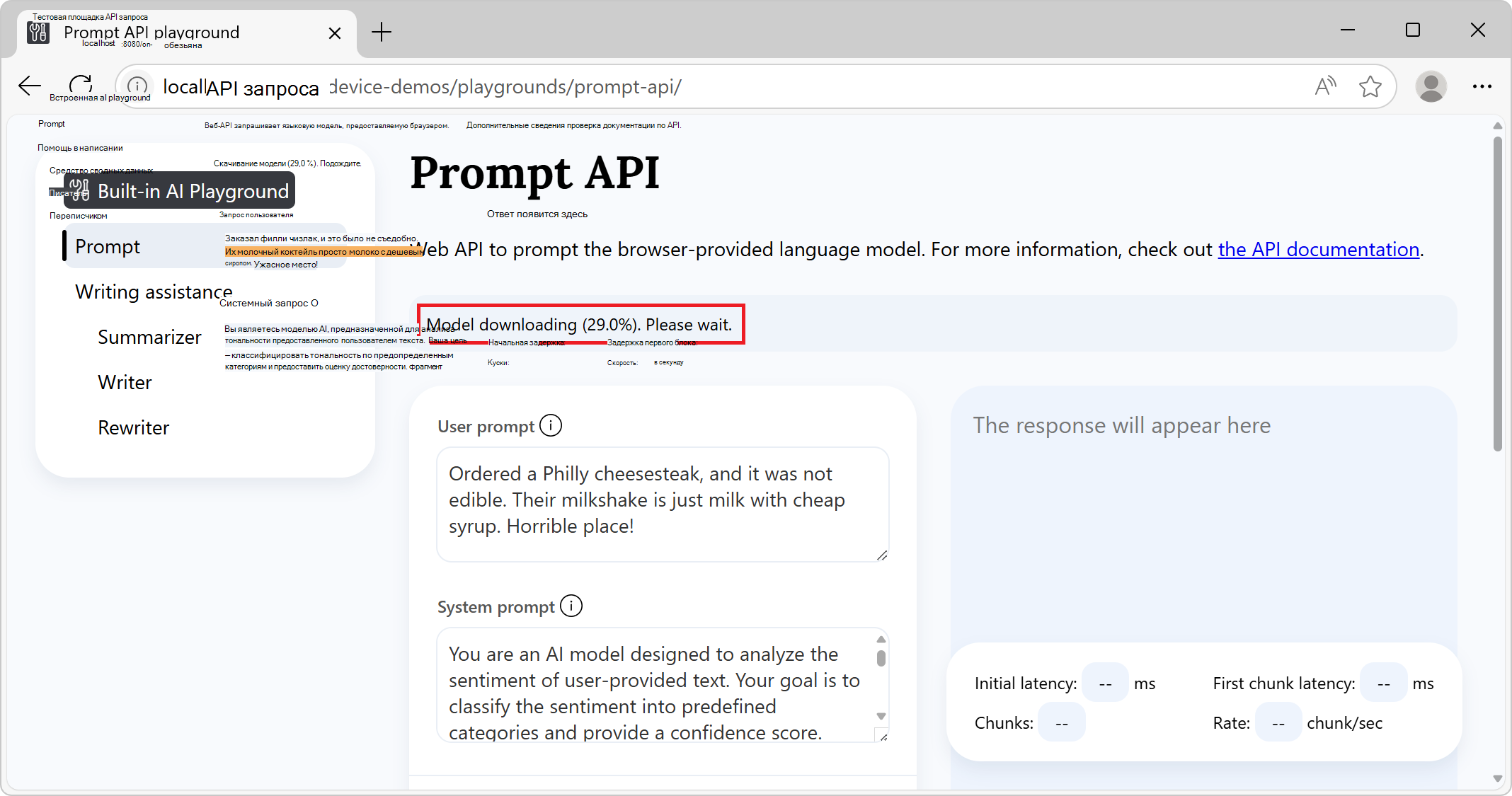
В информационном баннере в верхней части проверка состояние: сначала считывается скачивание модели, подождите:
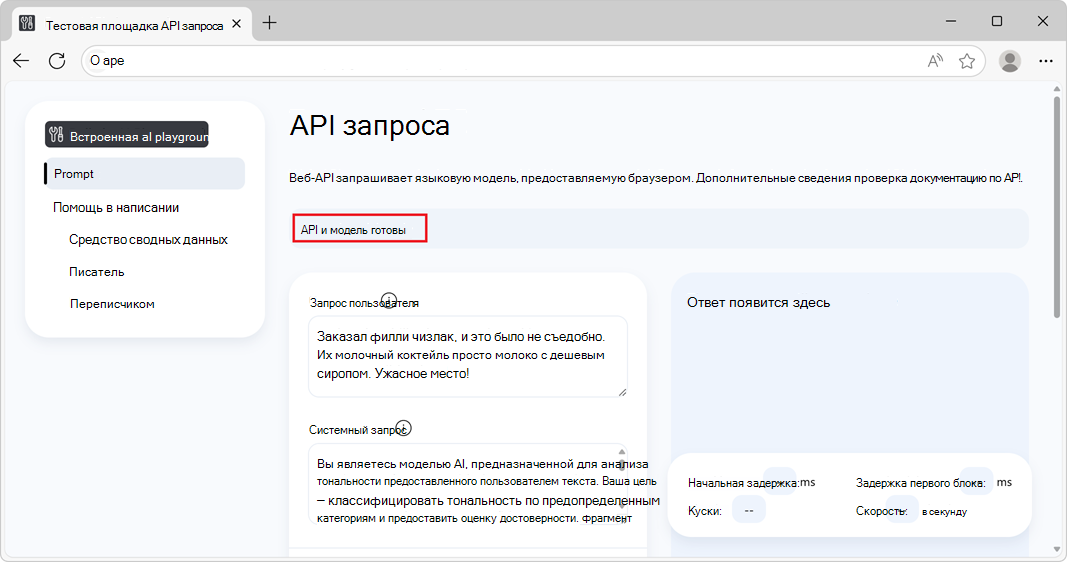
После скачивания модели информационный баннер считывает API и готово к модели, указывая, что API и модель можно использовать:
Если скачивание модели не запускается, перезапустите Microsoft Edge и повторите попытку.
API запроса поддерживается только на устройствах, которые соответствуют определенным требованиям к оборудованию. Дополнительные сведения см. в разделе Требования к оборудованию выше.
При необходимости измените значения параметров запроса, например:
- Запрос пользователя
- Системный запрос
- Схема ограничения ответа
- Дополнительные параметры>Инструкции по запросу N-выстрела
- TopK
- Температура
Нажмите кнопку Запрос в нижней части страницы.
Ответ создается в разделе ответа страницы:
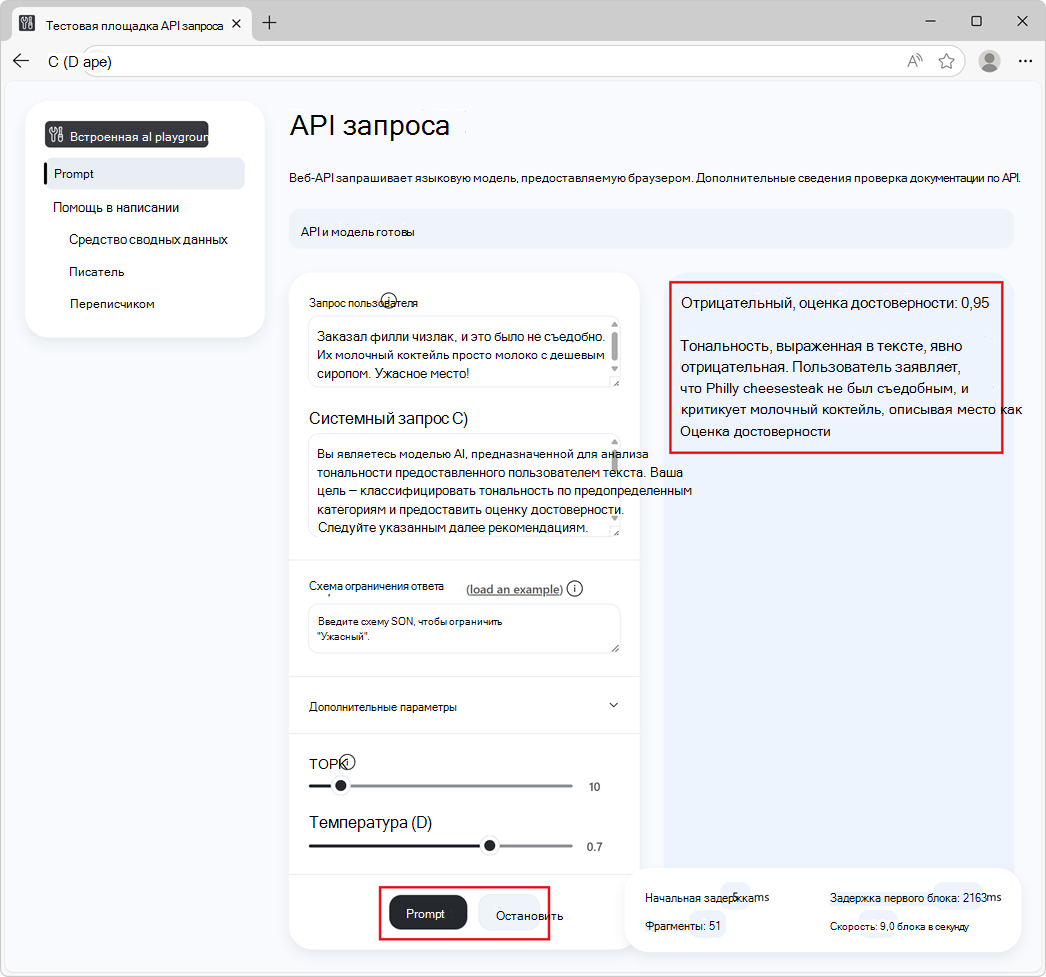
Чтобы остановить создание ответа, в любое время нажмите кнопку Остановить .
См. также:
- /built-in-ai/ — исходный код и файл сведений для встроенных игровых площадок ИИ, включая тестовую площадку API запроса.
Использование API запроса
Проверьте, включен ли API
Перед использованием API в коде веб-сайта или расширения проверка, что API включен, проверив наличие LanguageModel объекта:
if (!LanguageModel) {
// The Prompt API is not available.
} else {
// The Prompt API is available.
}
Проверьте, можно ли использовать модель
API запроса можно использовать только в том случае, если устройство поддерживает запуск модели и после загрузки языковой модели и среды выполнения модели Microsoft Edge.
Чтобы проверка, можно ли использовать API, используйте LanguageModel.availability() метод :
const availability = await LanguageModel.availability();
if (availability == "unavailable") {
// The model is not available.
}
if (availability == "downloadable" || availability == "downloading") {
// The model can be used, but it needs to be downloaded first.
}
if (availability == "available") {
// The model is available and can be used.
}
Создание нового сеанса
Создание сеанса позволяет браузеру загрузить языковую модель в память, чтобы ее можно было использовать. Прежде чем запрашивать языковую модель, создайте новый сеанс с помощью create() метода :
// Create a LanguageModel session.
const session = await LanguageModel.create();
Чтобы настроить сеанс модели, можно передать параметры в create() метод:
// Create a LanguageModel session with options.
const session = await LanguageModel.create(options);
Доступны следующие параметры:
monitor, чтобы отслеживать ход загрузки модели.initialPrompts, чтобы предоставить контекст модели о запросах, которые будут отправлены модели, и установить шаблон взаимодействия пользователя и помощник, которому модель должна следовать для будущих запросов.topKиtemperatureдля корректировки согласованности и детерминизма выходных данных модели.
Эти параметры описаны ниже.
Мониторинг хода загрузки модели
Ход загрузки модели можно отслеживать с помощью monitor параметра . Это полезно, если модель еще не была полностью загружена на устройство, где она будет использоваться, чтобы сообщить пользователям вашего веб-сайта, что они должны ждать.
// Create a LanguageModel session with the monitor option to monitor the model
// download.
const session = await LanguageModel.create({
monitor: m => {
// Use the monitor object argument to add an listener for the
// downloadprogress event.
m.addEventListener("downloadprogress", event => {
// The event is an object with the loaded and total properties.
if (event.loaded == event.total) {
// The model is fully downloaded.
} else {
// The model is still downloading.
const percentageComplete = (event.loaded / event.total) * 100;
}
});
}
});
Предоставление модели с помощью системного запроса
Чтобы определить системный запрос, который является способом предоставления инструкций модели для использования при создании текста в ответ на запрос, используйте initialPrompts параметр .
Системный запрос, который вы предоставляете при создании нового сеанса, сохраняется в течение всего существования сеанса, даже если окно контекста переполнено из-за слишком большого количества запросов.
// Create a LanguageModel session with a system prompt.
const session = await LanguageModel.create({
initialPrompts: [{
role: "system",
content: "You are a helpful assistant."
}]
});
Размещение запроса в { role: "system", content: "You are a helpful assistant." } любом месте, кроме 0-й позиции в, initialPrompts будет отклонено с TypeErrorпомощью .
Запрос N-выстрела с initialPrompts
Этот initialPrompts параметр также позволяет предоставить примеры взаимодействия пользователей и помощник, которые модель будет продолжать использовать при появлении запроса.
Этот метод также называется запросом N-выстрела и полезен для того, чтобы сделать ответы, создаваемые моделью, более детерминированными.
// Create a LanguageModel session with multiple initial prompts, for N-shot
// prompting.
const session = await LanguageModel.create({
initialPrompts: [
{ role: "system", content: "Classify the following product reviews as either OK or Not OK." },
{ role: "user", content: "Great shoes! I was surprised at how comfortable these boots are for the price. They fit well and are very lightweight." },
{ role: "assistant", content: "OK" },
{ role: "user", content: "Terrible product. The manufacturer must be completely incompetent." },
{ role: "assistant", content: "Not OK" },
{ role: "user", content: "Could be better. Nice quality overall, but for the price I was expecting something more waterproof" },
{ role: "assistant", content: "OK" }
]
});
Установка topK и температуры
topK и temperature называются параметрами выборки и используются моделью для влияния на создание текста.
Выборка TopK ограничивает количество слов, рассматриваемых для каждого последующего слова в созданном тексте, что может ускорить процесс создания и привести к более согласованным выходным данным, но также уменьшить разнообразие.
Выборка температуры определяет случайность выходных данных. Более низкая температура приводит к уменьшению случайных выходных данных, в пользу слов с более высокой вероятностью и, следовательно, к созданию более детерминированного текста.
topK Задайте параметры и temperature , чтобы настроить параметры выборки модели:
// Create a LanguageModel session and setting the topK and temperature options.
const session = await LanguageModel.create({
topK: 10,
temperature: 0.7
});
Клонирование сеанса, чтобы снова начать беседу с теми же параметрами
Клонируйте существующий сеанс, чтобы предложить модель без знаний из предыдущих взаимодействий, но с теми же параметрами сеанса.
Клонирование сеанса полезно, если вы хотите использовать параметры предыдущего сеанса, но без влияния на модель с предыдущими ответами.
// Create a first LanguageModel session.
const firstSession = await LanguageModel.create({
initialPrompts: [
role: "system",
content: "You are a helpful assistant."
],
topK: 10,
temperature: 0.7
});
// Later, create a new session by cloning the first session to start a new
// conversation with the model, but preserve the first session's settings.
const secondSession = await firstSession.clone();
Запрос модели
Чтобы заставить модель, после создания сеанса модели используйте session.prompt() методы или session.promptStreaming() .
Ожидание окончательного ответа
Метод prompt возвращает обещание, которое разрешается после завершения создания текста моделью в ответ на запрос:
// Create a LanguageModel session.
const session = await LanguageModel.create();
// Prompt the model and wait for the response to be generated.
const result = await session.prompt(promptString);
// Use the generated text.
console.log(result);
Отображение маркеров по мере их создания
Метод promptStreaming сразу же возвращает объект потока. Используйте поток для отображения маркеров ответа по мере их создания:
// Create a LanguageModel session.
const session = await LanguageModel.create();
// Prompt the model.
const stream = session.promptStreaming(myPromptString);
// Use the stream object to display tokens that are generated by the model, as
// they are being generated.
for await (const chunk of stream) {
console.log(chunk);
}
Методы и promptStreaming можно вызывать prompt несколько раз в одном объекте сеанса, чтобы продолжать создавать текст, основанный на предыдущих взаимодействиях с моделью в этом сеансе.
Ограничение выходных данных модели с помощью схемы JSON или регулярного выражения
Чтобы сделать формат ответов модели более детерминированным и простым для программного использования, используйте responseConstraint параметр при запросе модели.
Параметр responseConstraint принимает схему JSON или регулярное выражение:
Чтобы модель отвечала строкифицированным объектом JSON, который следует заданной схеме, задайте
responseConstraintсхему JSON, которую вы хотите использовать.Чтобы модель ответила строкой, которая соответствует регулярному выражению, задайте для этого
responseConstraintрегулярного выражения значение .
В следующем примере показано, как заставить модель отвечать на запрос с помощью объекта JSON, следующего за заданной схемой:
// Create a LanguageModel session.
const session = await LanguageModel.create();
// Define a JSON schema for the Prompt API to constrain the generated response.
const schema = {
"type": "object",
"required": ["sentiment", "confidence"],
"additionalProperties": false,
"properties": {
"sentiment": {
"type": "string",
"enum": ["positive", "negative", "neutral"],
"description": "The sentiment classification of the input text."
},
"confidence": {
"type": "number",
"minimum": 0,
"maximum": 1,
"description": "A confidence score indicating certainty of the sentiment classification."
}
}
}
;
// Prompt the model, by providing a system prompt and the JSON schema in the
// responseConstraints option.
const response = await session.prompt(
"Ordered a Philly cheesesteak, and it was not edible. Their milkshake is just milk with cheap syrup. Horrible place!",
{
initialPrompts: [
{
role: "system",
content: "You are an AI model designed to analyze the sentiment of user-provided text. Your goal is to classify the sentiment into predefined categories and provide a confidence score. Follow these guidelines:\n\n- Identify whether the sentiment is positive, negative, or neutral.\n- Provide a confidence score (0-1) reflecting the certainty of the classification.\n- Ensure the sentiment classification is contextually accurate.\n- If the sentiment is unclear or highly ambiguous, default to neutral.\n\nYour responses should be structured and concise, adhering to the defined output schema."
},
],
responseConstraint: schema
}
);
Выполнение приведенного выше кода возвращает ответ, содержащий строкифицированный объект JSON, например:
{"sentiment": "negative", "confidence": 0.95}
Затем вы можете использовать ответ в логике кода, проанализировав его с помощью JSON.parse() функции :
// Parse the JSON string generated by the model and extract the sentiment and
// confidence values.
const { sentiment, confidence } = JSON.parse(response);
// Use the values.
console.log(`Sentiment: ${sentiment}`);
console.log(`Confidence: ${confidence}`);
Дополнительные сведения см. в разделе Структурированные выходные данные со схемой JSON или ограничениями RegExp.
Отправка нескольких сообщений на запрос
Помимо строк, prompt методы и promptStreaming также принимают массив объектов, используемых для отправки нескольких сообщений с пользовательскими ролями. Отправляемые объекты должны быть в формате { role, content }, где role имеет значение user или assistant, а content — это сообщение.
Например, чтобы указать несколько сообщений пользователей и помощник сообщение в одном запросе:
// Create a LanguageModel session.
const session = await LanguageModel.create();
// Prompt the model by sending multiple messages at once.
const result = await session.prompt([
{ role: "user", content: "First user message" },
{ role: "user", content: "Second user message" },
{ role: "assistant", content: "The assistant message" }
]);
Прекращение создания текста
Чтобы прервать запрос до разрешения обещания, возвращаемого методом session.prompt() , или до завершения потока, возвращаемого session.promptStreaming()AbortController , используйте сигнал:
// Create a LanguageModel session.
const session = await LanguageModel.create();
// Create an AbortController object.
const abortController = new AbortController();
// Prompt the model by passing the AbortController object by using the signal
// option.
const stream = session.promptStreaming(myPromptString , {
signal: abortController.signal
});
// Later, perhaps when the user presses a "Stop" button, call the abort()
// method on the AbortController object to stop generating text.
abortController.abort();
Уничтожение сеанса
Уничтожьте сеанс, чтобы сообщить браузеру, что языковая модель больше не нужна, чтобы ее можно было выгрузить из памяти.
Вы можете уничтожить сеанс двумя разными способами:
- С помощью
destroy()метода . - С помощью
AbortController.
Уничтожение сеанса с помощью метода destroy()
// Create a LanguageModel session.
const session = await LanguageModel.create();
// Later, destroy the session by using the destroy method.
session.destroy();
Уничтожение сеанса с помощью abortController
// Create an AbortController object.
const controller = new AbortController();
// Create a LanguageModel session and pass the AbortController object by using
// the signal option.
const session = await LanguageModel.create({ signal: controller.signal });
// Later, perhaps when the user interacts with the UI, destroy the session by
// calling the abort() function of the AbortController object.
controller.abort();
Отправка отзывов
Предварительная версия API запроса предназначена для поиска вариантов использования языковых моделей, предоставляемых браузером. Мы очень заинтересованы в изучении ряда сценариев, в которых вы планируете использовать API запроса, о любых проблемах с API или языковыми моделями, а также о том, будут ли полезны новые API для конкретных задач, например для проверки правописания или перевода.
Чтобы отправить отзыв о своих сценариях и задачах, которые вы хотите выполнить, добавьте комментарий к проблеме обратной связи с API запроса.
Если вы заметили какие-либо проблемы при использовании API, сообщите об этом в репозитории.
Вы также можете принять участие в обсуждении структуры API запроса в репозитории рабочей группы веб-машинного обучения W3C.
См. также
- Объяснение API запроса в репозитории GitHub для веб-машинного обучения.
- Написание, перезапись и обобщение текста с помощью API помощи в написании
- Исправление ошибок грамматики, орфографии и препинания в тексте с помощью API Proofreader
- Перевод текста с помощью API переводчика
- /built-in-ai/ — исходный код и файл сведений для встроенных игровых площадок ИИ, включая тестовую площадку API запроса.