Примечание.
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
Область применения: ✅ хранилище в Microsoft Fabric
В этой статье описаны методы миграции хранилища данных в выделенных пулах SQL Azure Synapse Analytics в хранилище Microsoft Fabric.
Подсказка
Дополнительные сведения о стратегии и планировании миграции см. в разделе "Планирование миграции: перенос выделенных пулов SQL сервиса Azure Synapse Analytics в хранилище данных Fabric".
Автоматизированная возможность для миграции из выделенных пулов SQL Azure Synapse Analytics доступна с использованием помощника по миграции Fabric для хранилища данных. Остальная часть этой статьи содержит дополнительные действия по миграции вручную.
В этой таблице приведены сведения о схемах данных (DDL), коде базы данных (DML) и методах миграции данных. Далее в этой статье мы подробнее рассмотрим каждый сценарий, ссылка на которые находится в столбце Option.
| Номер опции | Вариант | Что он делает | Навыки и предпочтения | Сценарий |
|---|---|---|---|---|
| 1 | Фабрика данных | Конвертация схемы (DDL) Извлечение данных Прием данных |
ADF/Пайплайн | Упрощена единая схема (DDL) и миграция данных. Рекомендуется для таблиц измерений. |
| 2 | Фабрика данных с разбивкой на разделы | Конвертация схемы (DDL) Извлечение данных Прием данных |
ADF/Пайплайн | Использование параметров секционирования для увеличения параллелизма чтения и записи, обеспечивающего в десять раз большую пропускную способность по сравнению с вариантом 1, рекомендуется для таблиц фактов . |
| 3 | Фабрика данных с ускоренным кодом | Конвертация схемы (DDL) | ADF/Пайплайн | Сначала преобразуйте и перенесите схему (DDL), затем используйте CETAS для извлечения, а COPY/Data Factory для загрузки данных для оптимальной общей производительности их обработки. |
| 4 | Ускоренный код хранимых процедур | Конвертация схемы (DDL) Извлечение данных Оценка кода |
T-SQL | Пользователь SQL, работающий в интегрированной среде разработки, имеет более детальный контроль над выбором задач, над которыми они хотят работать. Используйте COPY/Data Factory для поглощения данных. |
| 5 | Расширение проекта базы данных SQL для Visual Studio Code | Конвертация схемы (DDL) Извлечение данных Оценка кода |
Проект SQL | Проект базы данных SQL для развертывания с интеграцией варианта 4. Используйте COPY или Фабрику данных для приема данных. |
| 6 | Создать внешнюю таблицу как SELECT (CETAS) | Извлечение данных | T-SQL | Экономичное и высокопроизводительное извлечение данных в Azure Data Lake Storage (ADLS) поколения Gen2. Используйте COPY/Data Factory для поглощения данных. |
| 7 | Выполните миграцию с использованием dbt | Конвертация схемы (DDL) Преобразование кода базы данных (DML) |
dbt | Существующие пользователи dbt могут использовать адаптер dbt Fabric для преобразования DDL и DML. Затем необходимо перенести данные с помощью других параметров в этой таблице. |
Выбор рабочей нагрузки для начальной миграции
Когда вы решаете, с какого места начать работу с выделенным пулом SQL Synapse для проекта миграции хранилища Fabric, выберите рабочую нагрузку, в которой вы можете:
- Докажите жизнеспособность миграции в Fabric Warehouse, быстро демонстрируя преимущества новой среды. Начните с малого и простого, подготовьтесь к нескольким небольшим миграциям.
- Разрешите вашему техническому персоналу получить соответствующий опыт работы с процессами и инструментами, которые они используют при миграции в другие области.
- Создайте шаблон для дальнейших миграций, относящихся к исходной среде Synapse, а также средства и процессы, которые помогут вам.
Подсказка
Создайте инвентаризацию объектов, которые необходимо перенести, и задокументируйте процесс миграции с начала до конца, чтобы его можно было повторять для других выделенных пулов SQL или рабочих нагрузок.
Объем перенесенных данных в начальной миграции должен быть достаточно большим, чтобы продемонстрировать возможности и преимущества среды хранилища Fabric, но не слишком большой, чтобы быстро продемонстрировать значение. Как правило, такой объем составляет от 1 до 10 терабайт.
Миграция при помощи Fabric Data Factory
В этом разделе мы обсуждаем варианты использования Фабрика данных Azure для пользователей с низким уровнем программирования или без него, которые знакомы с Фабрика данных Azure и Synapse Pipeline. Этот элемент пользовательского интерфейса с возможностью перетаскивания предоставляет простой способ преобразования DDL и переноса данных.
Фабрика данных Fabric может выполнять следующие задачи:
- Преобразуйте схему (DDL) в синтаксис для Fabric Warehouse.
- Создайте схему (DDL) в хранилище Fabric.
- Перенос данных в хранилище Fabric.
Вариант 1. Миграция схемы и данных — мастер копирования и активность копирования ForEach
Этот метод использует помощник копирования Data Factory для подключения к исходному выделенному пулу SQL, преобразования синтаксиса DDL выделенного пула SQL в Fabric и копирования данных в хранилище Fabric. Вы можете выбрать одну или несколько целевых таблиц (для набора данных TPC-DS есть 22 таблицы). Он генерирует ForEach для обхода списка таблиц, выбранных через пользовательский интерфейс, и запускает 22 параллельных потока для действия копирования.
- 22 запроса SELECT (по одному для каждой выбранной таблицы) были созданы и выполнены в выделенном пуле SQL.
- Убедитесь, что у вас есть соответствующий DWU и класс ресурсов, чтобы запросы могли быть выполнены. В этом случае требуется минимум DWU1000 с
staticrc10, чтобы разрешить до 32 запросов для обработки 22 отправленных запросов. - Для прямого копирования данных из выделенного пула SQL в хранилище Fabric требуется промежуточный этап. Процесс приема состоит из двух этапов.
- Первый этап заключается в извлечении данных из выделенного пула SQL в ADLS и называется подготовкой данных.
- Второй этап состоит из загрузки данных из промежуточного хранения в хранилище Fabric. Большая часть времени на обработку данных приходится на этап подготовки. В итоге стадирование оказывает огромное влияние на производительность загрузки.
Рекомендуемое использование
Использование мастера копирования для генерации ForEach предоставляет простой пользовательский интерфейс для преобразования DDL и загрузки выбранных таблиц из выделенного пула SQL в Fabric Warehouse на одном шаге.
Однако это не оптимально с общей пропускной способностью. Требование к использованию промежуточной среды и необходимость параллелизации чтения и записи для шага "Источник на стадию" являются основными факторами задержки производительности. Этот параметр рекомендуется использовать только для таблиц измерений.
Вариант 2. Миграция DDL/Data — конвейер с опцией раздела
Чтобы повысить пропускную способность при загрузке больших таблиц фактов с использованием конвейера Fabric, рекомендуется использовать компонент Copy Activity для каждой таблицы фактов с параметром разбиения. Это обеспечивает наилучшую производительность с действием Copy.
У вас есть возможность использовать физическое разделение исходной таблицы, если оно доступно. Если таблица не имеет физического секционирования, необходимо указать столбец секционирования и указать минимальное или максимальное значение для использования динамического секционирования. На следующем снимке экрана параметры источника конвейера указывают динамический диапазон секций на основе столбца ws_sold_date_sk .
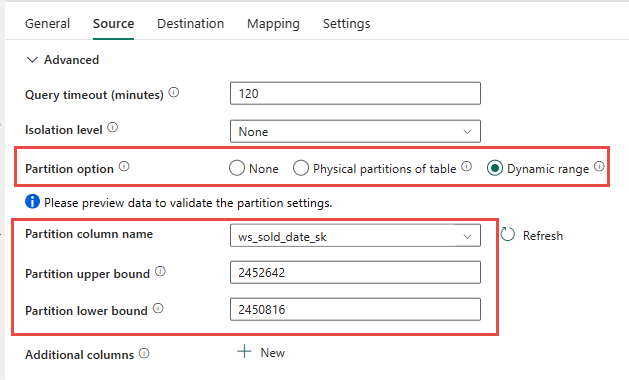
При использовании секции можно увеличить пропускную способность с промежуточным этапом, существуют рекомендации по внесению соответствующих изменений:
- В зависимости от диапазона партиций, это может использовать все слоты параллелизма, так как оно может генерировать более 128 запросов в выделенном SQL-пуле.
- Необходимо масштабировать до уровня не ниже DWU6000, чтобы разрешить выполнение всех запросов.
- Например, для таблицы TPC-DS
web_sales163 запросы были отправлены в выделенный пул SQL. В DWU6000 128 запросов выполнялись, а 35 запросов были помещены в очередь. - Динамическая секция автоматически выбирает секцию диапазона. В этом случае диапазон 11 дней для каждого запроса SELECT, отправленного в выделенный пул SQL. Например:
WHERE [ws_sold_date_sk] > '2451069' AND [ws_sold_date_sk] <= '2451080') ... WHERE [ws_sold_date_sk] > '2451333' AND [ws_sold_date_sk] <= '2451344')
Рекомендуемое использование
Для таблиц фактов рекомендуется использовать фабрику данных с параметром секционирования для повышения пропускной способности.
Однако увеличение параллелизированных операций чтения требует масштабирования выделенного пула SQL до более высокого уровня DWU, чтобы разрешить выполнение запросов извлечения. При использовании секционирования скорость увеличивается в десять раз по сравнению с вариантом без секционирования. Вы можете увеличить DWU, чтобы получить дополнительную пропускную способность через вычислительные ресурсы, но выделенный пул SQL разрешает не более 128 активных запросов.
Дополнительные сведения о сопоставлении Synapse DWU с Fabric см. в блоге: сопоставление выделенных пулов SQL Azure Synapse с вычислительными ресурсами хранилища данных Fabric.
Вариант 3. Миграция DDL — мастер копирования для каждой активности копирования
Два предыдущих варианта — отличные варианты миграции данных для небольших баз данных. Но если требуется более высокая пропускная способность, рекомендуется использовать альтернативный вариант:
- Извлеките данные из выделенного пула SQL в ADLS, чтобы уменьшить нагрузку на производительность этапа.
- Используйте фабрику данных или команду COPY для приема данных в хранилище Fabric.
Рекомендуемое использование
Вы можете продолжать использовать фабрику данных для преобразования схемы (DDL). С помощью мастера копирования можно выбрать определенную таблицу или все таблицы. По задумке это переносит схему и данные за один шаг, извлекая схему без строк, используя ложное условие TOP 0 в запросе.
В следующем примере кода рассматривается миграция схемы (DDL) с использованием Data Factory.
Пример кода: миграция схемы (DDL) с помощью Data Factory
Конвейеры Fabric можно использовать для простого переноса ваших DDL (схем) для объектов таблиц из любой исходной базы данных Azure SQL или выделенного пула SQL. Этот поток данных переносит схему (DDL) исходных таблиц выделенного пула SQL в Fabric Warehouse.
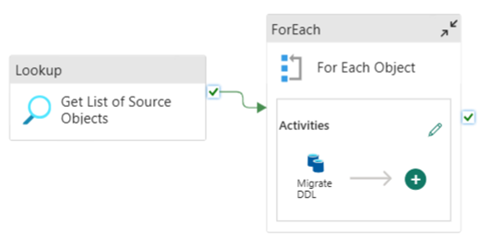
Проектирование конвейера: параметры
Этот конвейер принимает параметр SchemaName, который позволяет указать, какие схемы следует перенести. Схема dbo используется по умолчанию.
В поле "Значение по умолчанию" введите список с разделителями-запятыми таблицы, указывающий, какие схемы следует перенести: 'dbo','tpch' для предоставления двух схем dbo и tpch.
Снимок экрана из Data Factory, показывающий вкладку "Параметры" конвейера. В поле "Имя" указано 'SchemaName'. В поле "Значение по умолчанию" — 'dbo', 'tpch', указывая на то, что эти две схемы должны быть перенесены.
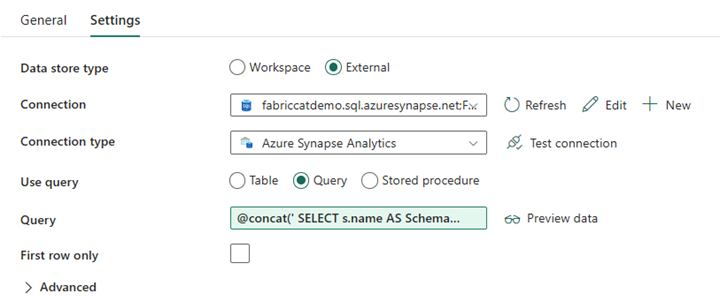
Проектирование конвейера: операция поиска
Создайте действие поиска и установите подключение к вашей исходной базе данных.
На вкладке Параметры сделайте следующее:
Установите тип хранилища данных на Внешний.
Соединение — это ваш выделенный пул SQL в Azure Synapse. Тип подключения — Azure Synapse Analytics.
Использование запроса установлено на Запрос.
Поле запроса необходимо создать с помощью динамического выражения, что позволяет использовать параметр SchemaName в запросе, который возвращает список целевых исходных таблиц. Выберите "Запрос", а затем выберите "Добавить динамическое содержимое".
Это выражение в действии LookUp создает инструкцию SQL для запроса системных представлений для получения списка схем и таблиц. Ссылается на параметр SchemaName, чтобы разрешить фильтрацию по схемам SQL. Результатом этого является массив схемы SQL и таблиц, которые будут использоваться в качестве входных данных в действие ForEach.
Используйте следующий код, чтобы вернуть список всех пользовательских таблиц с именем схемы.
@concat(' SELECT s.name AS SchemaName, t.name AS TableName FROM sys.tables AS t INNER JOIN sys.schemas AS s ON t.type = ''U'' AND s.schema_id = t.schema_id AND s.name in (',coalesce(pipeline().parameters.SchemaName, 'dbo'),') ')
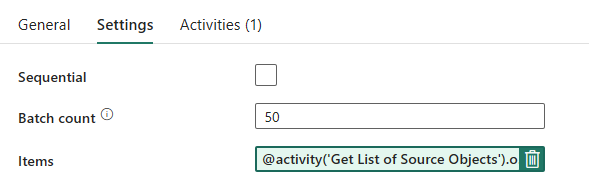
Проектирование конвейера: ForEach Loop
Для цикла ForEach настройте следующие параметры на вкладке "Параметры ".
- Отключите последовательную итерацию , чтобы разрешить одновременно выполнять несколько итераций.
- Установите число пакетов на
50для ограничения максимального числа одновременных итераций. - Поле "Элементы" должно использовать динамическое содержимое для ссылки на выходные данные действия LookUp. Используйте следующий фрагмент кода:
@activity('Get List of Source Objects').output.value
Проектирование конвейера: операция копирования внутри цикла ForEach
В действии ForEach добавьте действие копирования. Этот метод использует язык Dynamic Expression Language в конвейерах, чтобы создать SELECT TOP 0 * FROM <TABLE> для миграции только схемы без данных в хранилище Fabric.
На вкладке "Источник":
- Установите тип хранилища данных на Внешний.
- Соединение — это ваш выделенный пул SQL в Azure Synapse. Тип подключения — Azure Synapse Analytics.
- Установите Использовать запрос на Запрос.
-
В поле "Запрос" вставьте динамический запрос содержимого и используйте это выражение, которое возвращает нулевые строки, только схему таблицы:
@concat('SELECT TOP 0 * FROM ',item().SchemaName,'.',item().TableName)

На вкладке "Назначение ":
- Установите тип хранилища данных на «Рабочая область».
- Тип хранилища данных рабочей области — это Data Warehouse, и Data Warehouse установлен на использование Fabric Warehouse.
-
Схема целевой таблицы и имя таблицы определяются с помощью динамического содержимого.
- Схема ссылается на поле текущей итерации, SchemaName с фрагментом кода:
@item().SchemaName - Таблица ссылается на TableName с использованием фрагмента:
@item().TableName
- Схема ссылается на поле текущей итерации, SchemaName с фрагментом кода:

Конструктор конвейера: точка сбора
Для приемника укажите ваше хранилище и укажите исходные схему и имя таблицы.
После запуска этого конвейера вы увидите, что хранилище данных заполняется каждой таблицей в источнике с правильной схемой.
Миграция с помощью хранимых процедур в выделенном пуле SQL Synapse
Данная опция использует хранимые процедуры для выполнения миграции Fabric.
Примеры кода можно получить на GitHub.com microsoft/fabric-migration. Этот код предоставляется как открытый код, поэтому вы можете внести свой вклад в совместную работу и помочь сообществу.
Какие задачи могут выполнять хранимые процедуры для миграции:
- Преобразуйте схему (DDL) в синтаксис для Fabric Warehouse.
- Создайте схему (DDL) в хранилище Fabric.
- Извлеките данные из выделенного пула SQL Synapse в ADLS.
- Обозначьте неподдерживаемый синтаксис Fabric для кодов T-SQL (хранимые процедуры, функции, представления).
Рекомендуемое использование
Это отличный вариант для тех, кто:
- Знакомы с T-SQL.
- Хотите использовать интегрированную среду разработки, например SQL Server Management Studio (SSMS).
- Требуется более детализированный контроль над задачами, над которыми они хотят работать.
Для преобразования схемы (DDL), извлечения данных или оценки кода T-SQL можно выполнить определенную хранимую процедуру.
Для миграции данных необходимо использовать либо команду COPY INTO, либо Data Factory для загрузки данных в хранилище Fabric.
Миграция с помощью проектов базы данных SQL
Хранилище данных Microsoft Fabric поддерживается в расширении проектов баз данных SQL , доступном внутри Visual Studio Code.
Это расширение доступно в Visual Studio Code. Эта функция позволяет использовать возможности для управления версиями, тестирования баз данных и проверки схемы.
Дополнительные сведения об управлении версиями для хранилищ в Microsoft Fabric, включая конвейеры интеграции и развертывания Git, см. в статье "Управление версиями" с помощью хранилища.
Рекомендуемое использование
Это отличный вариант для тех, кто предпочитает использовать SQL Database Project для развертывания. Фактически эта опция интегрирует хранимые процедуры миграции Fabric в проект SQL Database для обеспечения бесшовной миграции.
Проект База данных SQL может:
- Преобразуйте схему (DDL) в синтаксис для Fabric Warehouse.
- Создайте схему (DDL) в хранилище Fabric.
- Извлеките данные из выделенного пула SQL Synapse в ADLS.
- Пометка неподдерживаемого синтаксиса для кодов T-SQL (хранимые процедуры, функции, представления).
Для миграции данных вы будете использовать COPY INTO или Фабрику данных для загрузки данных в хранилище Fabric.
Команда MICROSOFT Fabric CAT предоставила набор скриптов PowerShell для обработки извлечения, создания и развертывания схемы (DDL) и кода базы данных (DML) через проект базы данных SQL. Пошаговое руководство по использованию проекта База данных SQL с полезными скриптами PowerShell см. на GitHub в разделе microsoft/fabric-migration.
Дополнительные сведения о проектах базы данных SQL см. в статье "Начало работы с расширением "Проекты базы данных SQL " и создание проекта базы данных из командной строки.
Перенос данных с помощью CETAS
Команда T-SQL CREATE EXTERNAL TABLE AS SELECT (CETAS) предоставляет наиболее экономичный и оптимальный способ извлечения данных из выделенных пулов SQL Synapse в Azure Data Lake Storage (ADLS) 2-го поколения.
Что может сделать CETAS:
- Извлечение данных в ADLS.
- Этот параметр требует, чтобы пользователи создавали схему (DDL) в хранилище Fabric перед приемом данных. Рассмотрите варианты, приведенные в этой статье, для переноса схем (DDL).
Преимущества этого варианта:
- Только один запрос на таблицу отправляется в исходный выделенный пул SQL Synapse. Это не будет использовать все слоты параллельности, и поэтому не заблокирует одновременные ETL процессы/запросы клиентов.
- Масштабировать до DWU6000 не требуется, так как для каждой таблицы используется всего один слот параллелизма, поэтому клиенты могут использовать более низкие DWUs.
- Извлечение выполняется параллельно во всех вычислительных узлах, и это ключ к улучшению производительности.
Рекомендуемое использование
Используйте CETAS для извлечения данных в ADLS в виде файлов Parquet. Файлы Parquet обеспечивают преимущество эффективного хранилища данных с столбцовым сжатием, что потребует меньшей пропускной способности при передаче по сети. Более того, поскольку Fabric сохранял данные в формате Delta Parquet, поглощение данных будет в 2,5 раза быстрее по сравнению с текстовым форматом файла, так как во время приема не происходит накладных расходов на преобразование в Delta формат.
Чтобы увеличить пропускную способность CETAS, выполните приведенные действия.
- Добавьте параллельные операции CETAS, увеличивая использование слотов параллельности, одновременно обеспечивая большую пропускную способность.
- Масштабируйте DWU в выделенном SQL-пуле Synapse.
Миграция с помощью dbt
В этом разделе мы обсудим параметр dbt для тех клиентов, которые уже используют dbt в текущей среде выделенного пула SQL Synapse.
Что может сделать dbt:
- Преобразуйте схему (DDL) в синтаксис для Fabric Warehouse.
- Создайте схему (DDL) в хранилище Fabric.
- Преобразуйте код базы данных (DML) в синтаксис Fabric.
Платформа dbt создает DDL и DML (скрипты SQL) на лету с каждым выполнением. При использовании файлов модели, выраженных в инструкциях SELECT, DDL/DML можно мгновенно перевести на любую целевую платформу, изменив профиль (строка подключения) и тип адаптера.
Рекомендуемое использование
Платформа dbt — это подход с приоритетом на код. Данные необходимо перенести с помощью параметров, перечисленных в этом документе, таких как CETAS или COPY/Data Factory.
Адаптер dbt для хранилища данных Microsoft Fabric позволяет перенести существующие проекты dbt, предназначенные для различных платформ, таких как выделенные пулы SQL Synapse, Snowflake, Databricks, Google Big Query или Amazon Redshift, которые будут перенесены в хранилище Fabric с простым изменением конфигурации.
Сведения о начале работы с проектом dbt, предназначенным для хранилища Fabric, см. в руководстве по настройке dbt для хранилища данных Fabric. В этом документе также перечислены варианты перемещения между различными хранилищами и платформами.
Загрузка данных в хранилище Fabric
Для загрузки в хранилище Fabric используйте COPY INTO или Fabric Data Factory в зависимости от предпочтений. Оба метода являются рекомендуемыми и оптимальными вариантами, так как они имеют эквивалентную пропускную способность, при условии, что файлы уже извлечены в Azure Data Lake Storage (ADLS) Gen2.
Некоторые факторы, которые следует отметить, чтобы можно было разработать процесс для максимальной производительности:
- При использовании Fabric при одновременной загрузке нескольких таблиц из ADLS в хранилище Fabric отсутствует конкуренция за ресурсы. В результате при загрузке параллельных потоков нет снижения производительности. Максимальная пропускная способность ввода будет ограничена только вычислительной мощностью емкости Fabric.
- Управление рабочей нагрузкой Fabric обеспечивает разделение ресурсов, выделенных для загрузки и запроса. Выполнение запросов и загрузка данных могут происходить одновременно без конфликта ресурсов.
Связанный контент
- Ассистент по миграции Fabric для хранилищ данных
- Создание хранилища в Microsoft Fabric
- Рекомендации по производительности хранилища данных Fabric
- Безопасность хранения данных в Microsoft Fabric
- Блог. Сопоставление выделенных пулов SQL Azure Synapse с вычислительными ресурсами хранилища данных Fabric
- Обзор миграции Microsoft Fabric