Примечание.
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
Этот модуль занимает около 25 минут. Вы создаете поток данных, применяете преобразования и перемещаете необработанные данные из таблицы слоя бронзовых данных в таблицу слоя данных gold .
С помощью необработанных данных, загруженных в таблицу Bronze Lakehouse из последнего модуля, вы можете дополнить ее. Вы объедините его с другой таблицей, содержащей скидки для каждого поставщика и их поездки в течение определенного дня. Затем эта окончательная таблица Gold Lakehouse загружается и готова к использованию.
Высокоуровневые шаги в потоке данных:
- Получение необработанных данных из таблицы Lakehouse , созданной заданием копирования в модуле 1: прием данных с помощью задания копирования.
- Преобразование данных, импортированных из таблицы Lakehouse.
- Подключитесь к CSV-файлу с данными о скидках.
- Преобразуйте данные скидок.
- Объединение данных о поездках и скидках.
- Загрузите выходной запрос в таблицу Gold Lakehouse.
Предпосылки
Модуль 1 из этой серии руководств: прием данных с заданием на копирование
Получение данных из таблицы Lakehouse
На боковой панели выберите рабочую область, выберите Новый элемент, а затем Dataflow Gen2, чтобы создать новый Dataflow Gen2.

В новом меню потока данных выберите Получить данные, а затем Еще....

Найдите и выберите соединитель Lakehouse.
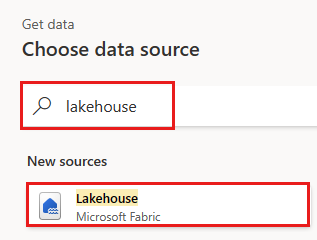
Откроется диалоговое окно Подключение к источнику данных, и новое подключение автоматически создается на основе входа текущего пользователя. Выберите Далее.

Откроется диалоговое окно Выбор данных. Используйте панель навигации, чтобы найти Lakehouse, созданную для назначения в предыдущем модуле. Он может находиться в папке "Моя рабочая область ". Выберите таблицу данных "Бронза ". Затем выберите Создать.

(необязательно) После заполнения холста данными можно задать информацию о профиле столбцов, что удобно для профилирования данных. Вы можете применить правильное преобразование и на его основе определить правильные значения данных.
Для этого выберите параметры на панели ленты, затем выберите первые три параметра во вкладке Профиль столбца, и затем выберите ОК.




Преобразование данных, импортированных из Lakehouse
Выберите значок типа данных в заголовке столбца второго столбца IpepPickupDatetime, чтобы отобразить раскрывающееся меню и выбрать тип данных из меню, чтобы преобразовать столбец из типа даты и времени в дату .

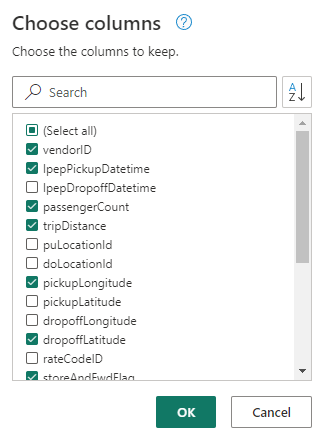
(необязательно) На вкладке Главная ленты выберите параметр Выбрать столбцы из группы Управление столбцами.

(необязательно) в диалоговом окне Выбор столбцов, отмените выбор некоторых столбцов, перечисленных здесь, а затем нажмите кнопку ОК.
- Идентификатор поставщика
- lpepPickupDatetime
- количествоПассажиров
- расстояние поездки
- picukupLongitude
- широтаМестаВысадки
- флагСохраненияИПересылки
- общаяСумма
Выберите фильтр столбца StoreAndFwdFlag и меню раскрывающегося списка сортировки. (Если список предупреждений может быть неполным, выберите "Загрузить больше ", чтобы просмотреть все данные.)

Выберите "Y", чтобы отобразить только строки, в которых была применена скидка, а затем нажмите кнопку ОК.

Дождитесь фильтрации данных.
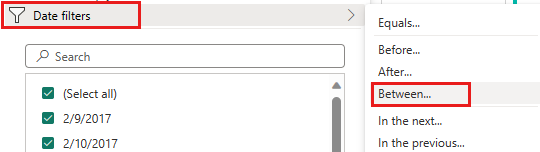
Выберите меню сортировки столбцов IpepPickupDatetime и раскрывающегося списка фильтров, а затем выберите фильтры даты и выберите фильтр "Между... ", указанный для типов даты и времени.
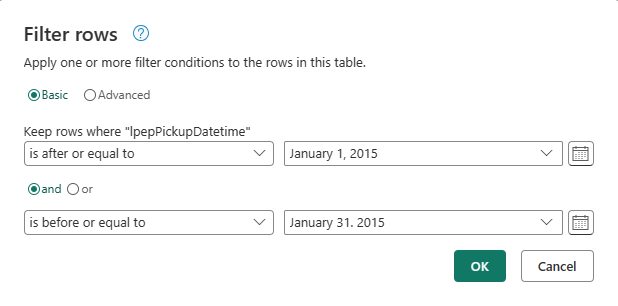
В диалоговом окне Фильтрация строк выберите даты между 1 января 2015 г. и 31 января 2015 г., а затем нажмите кнопку ОК.
Дождитесь фильтрации данных.

Подключитесь к CSV-файлу, содержащему данные о скидках
Используя данные из поездок, мы хотим загрузить информацию, содержащую соответствующие скидки для каждого дня и VendorID, и подготовить её перед объединением с данными о поездках.
На вкладке "Главная" в меню редактора потоков данных выберите параметр "Получить данные", а затем выберите text/CSV.
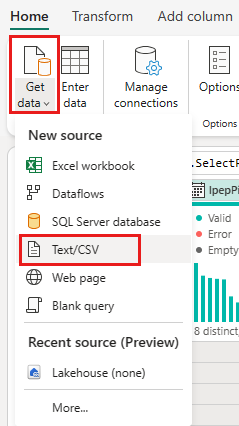
В диалоговом окне Подключение к источнику данных укажите следующие сведения:
-
пути к файлу или URL-адресу -
https://raw.githubusercontent.com/ekote/azure-architect/master/Generated-NYC-Taxi-Green-Discounts.csv - тип проверки подлинности — анонимный
Затем выберите Next.

-
пути к файлу или URL-адресу -
В диалоговом окне предварительного просмотра данных файла выберите Создать.



Преобразование данных скидки
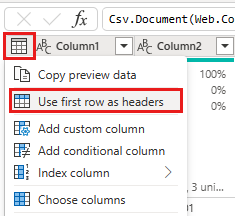
При просмотре данных, мы видим, что заголовки отображаются в первой строке. Повысьте их до заголовков, выбрав контекстное меню таблицы в левом верхнем углу области сетки предварительного просмотра, чтобы выбрать Использовать первую строку в качестве заголовков.
Заметка
После продвижения заголовков вы увидите новый шаг, представленный в области Примененные шаги в верхней части редактора потока данных, относящийся к типам данных ваших столбцов.
Щелкните правой кнопкой мыши на столбец VendorID и в появившемся контекстном меню выберите пункт Преобразовать другие столбцы. Это позволяет преобразовать столбцы в пары "атрибут-значение", где столбцы становятся строками.

Когда таблица развернута, переименуйте столбцы Атрибут и Значение, дважды щелкнув по ним и изменив Атрибут на Дата и Значение на Скидка.

Измените тип данных столбца Date, выбрав меню типа данных слева от имени столбца и выбрав date.

Выберите столбец скидки, а затем перейдите на вкладку преобразования. В разделе "Числовой столбец"выберите стандартные числовые преобразования из подменю и выберите "Разделить".

В диалоговом окне Деление введите значение 100.


Объединение данных о поездках и скидках
Следующим шагом является объединение обеих таблиц в одну таблицу с скидкой, которая должна применяться к поездке, и скорректированный итог.
Сначала переключите кнопку представления диаграммы в правом нижнем углу окна, чтобы просмотреть оба запроса.

Выберите исходный запрос данных (в нашем примере его называется Бронза) и на вкладке "Главная " в меню "Объединение " выберите запросы слияния, а затем запросы слияния в качестве новых.

В диалоговом окне Объединение выберите Левое внешнее объединение, затем выберите Сгенерированный-NYC-Taxi-Green-Discounts из раскрывающегося списка правую таблицу для объединения, и затем щелкните значок "лампочка" в правом верхнем углу диалогового окна, чтобы увидеть предлагаемое сопоставление столбцов между двумя таблицами.

Выберите предлагаемое сопоставление для сопоставления идентификатора поставщика и столбцов даты из обеих таблиц. При добавлении обоих сопоставлений в каждой таблице выделены соответствующие заголовки столбцов.
Отображается сообщение с запросом на объединение данных из нескольких источников данных для просмотра результатов. Нажмите ОК в диалоговом окне Слияние.

В области таблицы вы увидите предупреждение о том, что "Информация требуется о конфиденциальности данных". Нажмите кнопку "Продолжить", чтобы устранить предупреждение.

В этом руководстве выберите "Игнорировать проверки уровней конфиденциальности для этого документа", так как это образец данных, не содержащий конфиденциальной информации. Для собственных источников данных задайте соответствующие уровни конфиденциальности для защиты конфиденциальных данных.

Нажмите кнопку "Сохранить".
Обратите внимание, как в представлении диаграммы был создан новый запрос, показывающий связь нового запроса объединения с двумя ранее созданными запросами. Просматривая область таблицы редактора, прокрутите страницу справа от списка столбцов запроса слияния, чтобы увидеть новый столбец со значениями таблицы. Это столбец "Generated NYC Taxi-Green-Discounts", и его тип - [Таблица]. В заголовке столбца есть значок со двумя стрелками в противоположных направлениях, что позволяет выбирать столбцы из таблицы. Отмените выбор всех столбцов, кроме скидки, а затем нажмите кнопку ОК.

При значении скидки теперь на уровне строки можно создать новый столбец, чтобы вычислить общую сумму после скидки. Для этого выберите вкладку Добавить столбец в верхней части редактора и выберите Настраиваемый столбец из группы "Общие".
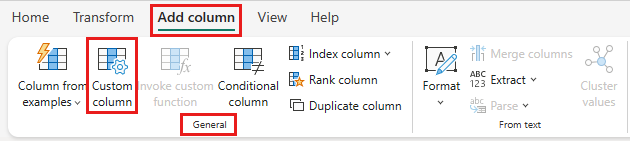
В диалоговом окне Custom column можно использовать язык формул Power Query (также известный как M) для определения способа вычисления нового столбца. Введите TotalAfterDiscount для имени нового столбца , выберите валюта для типа данных и укажите следующее выражение M для формулы пользовательского столбца .
, если [totalAmount] > 0, то [totalAmount] * ( 1 -[Скидка] ) иначе [totalAmount]
Затем нажмите кнопку ОК.
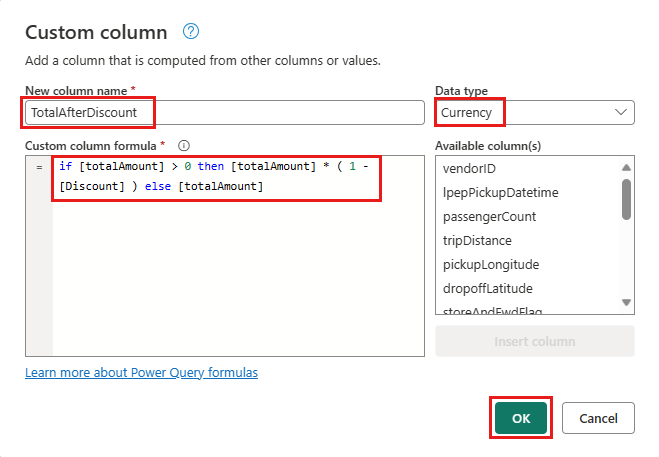
Выберите только что созданный столбец TotalAfterDiscount и перейдите на вкладку "Преобразование " в верхней части окна редактора. В группе столбец "Число" выберите раскрывающийся список "Округление", затем нажмите "Округлить...".

В диалоговом окне раундавведите 2 для числа десятичных разрядов, а затем нажмите кнопку ОК.

Измените тип данных IpepPickupDatetime с Date на Date/Time.

Наконец, разверните панель параметров запроса с правой стороны редактора, если она еще не развернута, и переименуйте запрос из Слияние в Output.







Загрузка выходного запроса в таблицу в Lakehouse
После полной подготовки и готовности к выводу выходных данных можно определить назначение выходных данных для запроса.
Выберите созданный ранее запрос на слияние выходных данных. Затем выберите вкладку Главная в редакторе и Добавить назначение данных в группировке Запрос, чтобы выбрать назначение Lakehouse.

В диалоговом окне Подключение к назначению данных подключение уже должно быть выбрано. Выберите Далее, чтобы продолжить.
В диалоговом окне Выбор целевого объекта перейдите в Lakehouse, где вы хотите загрузить данные и назовите новую таблицу nyc_taxi_with_discounts, затем снова нажмите кнопку Далее.
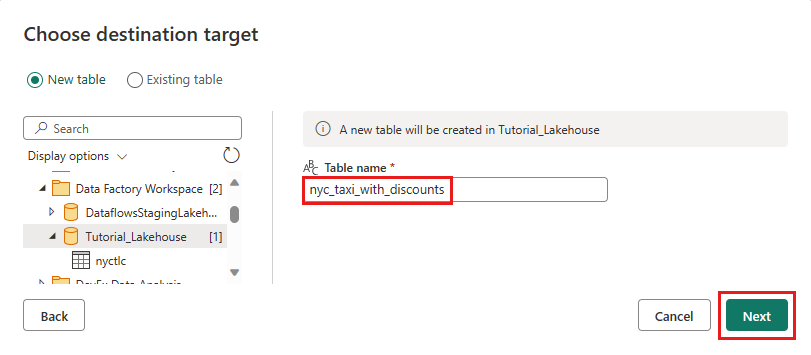
В диалоговом окне "Выбор параметров назначения" можно использовать автоматические параметры или отменить выбор автоматических параметров и оставить метод обновления замены по умолчанию, дважды проверьте правильность сопоставлений столбцов и нажмите кнопку "Сохранить".

В главном окне редактора убедитесь, что вы видите назначение выходных данных в параметрах запроса для таблицы выходных данных в назначении данных, а затем выберите Сохранить и запустить.
Важный
При создании первого Dataflow Gen2 в рабочей области элементы Lakehouse и Warehouse подготавливаются вместе с соответствующими конечными точками аналитики SQL и семантической моделью. Эти элементы разделяются всеми потоками данных в рабочей области и требуются для работы потока данных 2-го поколения, не следует удалять и не предназначены для непосредственного использования пользователями. Эти компоненты — это детали реализации Dataflow Gen2. Элементы не видны в рабочей среде, но могут быть доступны в других интерфейсах, таких как записная книжка, конечная точка SQL, Lakehouse и Warehouse. Элементы можно распознать по их префиксу в имени. Префикс элементов — DataflowsStaging.
(Необязательно) На странице рабочей области можно переименовать поток данных, выбрав многоточие справа от имени потока данных, которое отображается после выбора строки и выбора параметров. В этом примере мы переименуем его в nyc_taxi_with_discounts.
Выберите значок обновления для потока данных в меню Дополнительные параметры (многоточие), и по завершении вы увидите свою новую таблицу Lakehouse, созданную как задано в настройках Назначения данных.
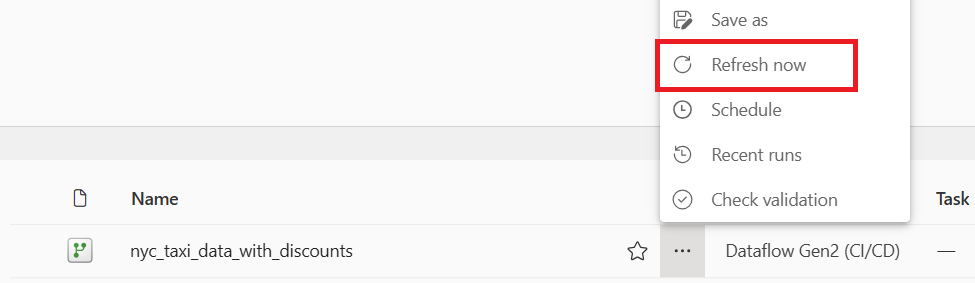
Проверьте Lakehouse, чтобы увидеть новую таблицу, загруженную туда.
