Примечание.
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
В этом кратком руководстве вы узнаете, как работают потоки данных и конвейеры для создания мощного решения фабрики данных. Вы очистите данные с помощью потоков данных и переместите их с помощью конвейеров.
Необходимые условия
Перед началом работы вам потребуется:
- Учетная запись клиента с активной подпиской. Создайте бесплатную учетную запись.
- Рабочая область с поддержкой Microsoft Fabric: настройте рабочую область , которая не является моей рабочей областью по умолчанию.
- База данных SQL Azure с данными таблицы.
- учетная запись для хранения BLOB-объектов.
Сравнение потоков данных и конвейеров
Dataflow Gen2 предоставляет интерфейс без программирования с более чем 300 преобразованиями на основе данных и ИИ. Вы можете легко очищать, подготавливать и преобразовывать данные с гибкостью. Конвейеры предлагают широкие возможности оркестрации данных для создания гибких рабочих процессов данных, которые соответствуют вашим корпоративным потребностям.
В конвейере можно создать логические группировки действий, выполняющих задачу. Это может включать вызов потока данных для очистки и подготовки данных. Хотя между этими двумя функциями перекрываются некоторые функции, выбор зависит от того, нужны ли вам полные возможности конвейеров или можно использовать более простые возможности потоков данных. Дополнительные сведения см. в руководстве по принятию решений Fabric.
Преобразование данных с помощью потоков данных
Выполните следующие действия, чтобы настроить поток данных.
Создание потока данных
Выберите рабочую область с поддержкой Fabric, а затем нажмите кнопку "Создать" и выберите Dataflow 2-го поколения.
В редакторе потока данных выберите "Импорт из SQL Server".
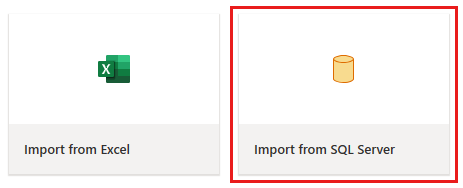


Получение данных
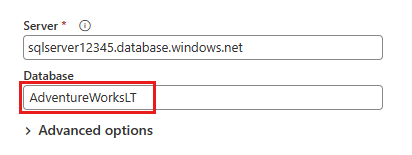
В диалоговом окне "Подключение к источнику данных" введите сведения о базе данных SQL Azure и нажмите кнопку "Далее". Используйте пример базы данных AdventureWorksLT из предварительных требований.
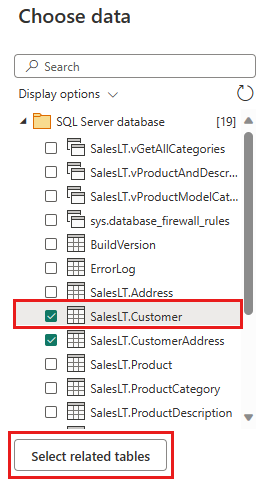
Выберите данные для преобразования, например SalesLT.Customer, и выберите связанные таблицы, чтобы включить связанные таблицы . Затем выберите Создать.


Преобразование данных
Выберите представление диаграммы в строке состояния или меню "Вид " в редакторе Power Query.
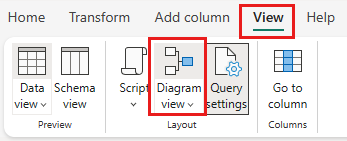
Щелкните правой кнопкой мыши запрос SalesLT Client или выберите вертикальное многоточие справа от запроса, а затем выберите Объединить запросы.
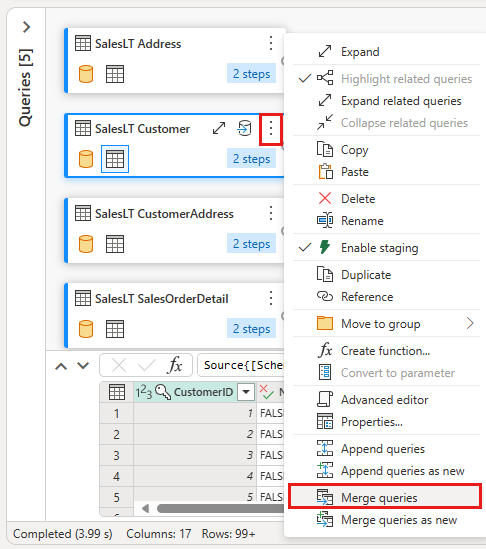
Настройте слияние с SalesLTOrderHeader в качестве правой таблицы, CustomerID в качестве столбца соединения и левое внешнее соединение в качестве типа соединения. Нажмите ОК.
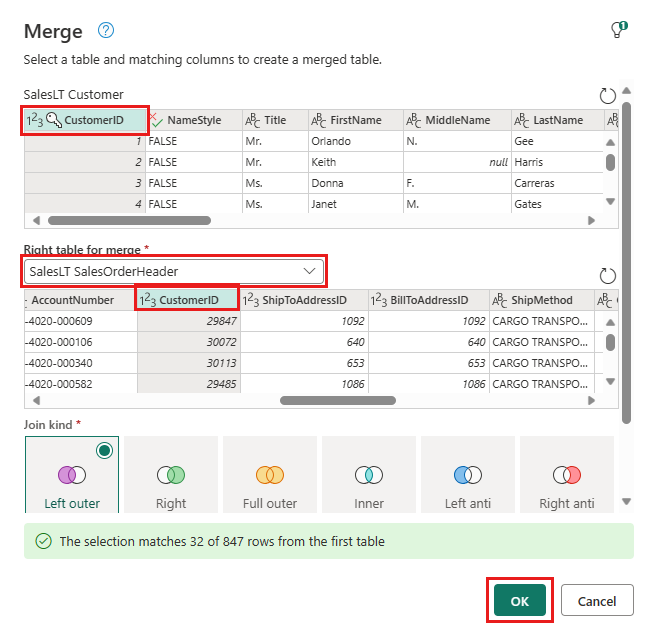
Добавьте назначение данных, выбрав символ базы данных со стрелкой. Выберите базу данных SQL Azure в качестве типа назначения.
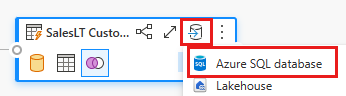
Укажите сведения о подключении к базе данных SQL Azure, где будет опубликован запрос слияния. В этом примере мы используем базу данных AdventureWorksLT и как источник данных, и как место назначения.
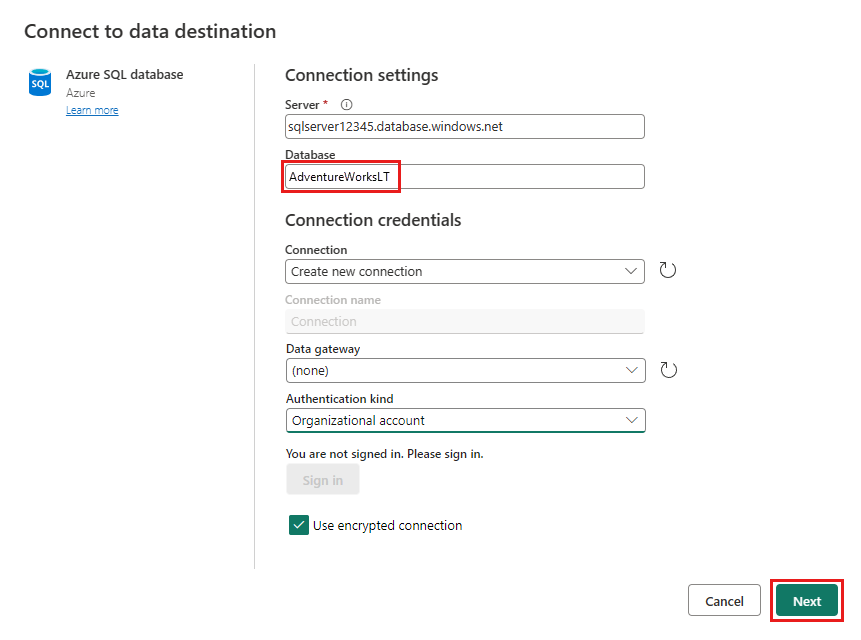
Выберите базу данных для хранения данных и укажите имя таблицы, а затем нажмите кнопку Далее.
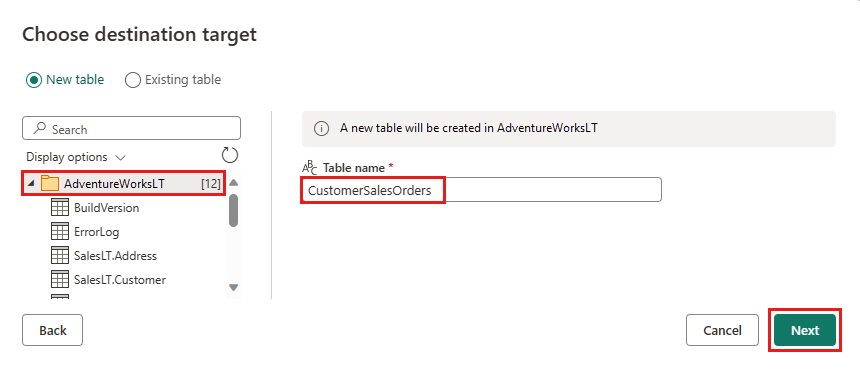
Примите параметры по умолчанию в диалоговом окне "Выбор параметров назначения " и нажмите кнопку "Сохранить параметры".
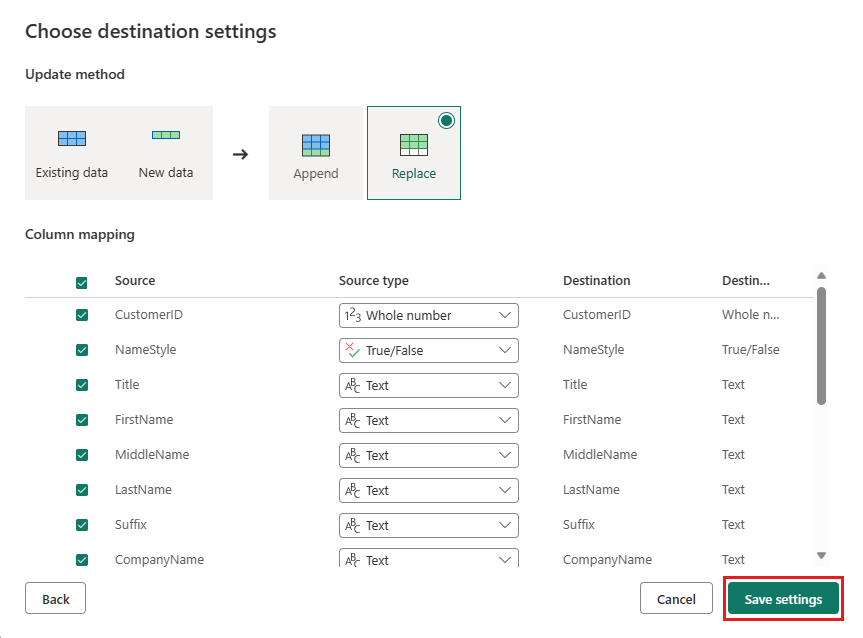
Выберите "Опубликовать " в редакторе потоков данных, чтобы опубликовать поток данных.



Перемещение данных с помощью конвейеров
Теперь, когда вы создали поток данных Gen2, вы можете работать с ним в конвейере обработки данных. В этом примере данные, созданные потоком данных, копируются в текстовый формат в учетную запись хранилища BLOB-объектов Azure.
Создание нового конвейера
В рабочей области выберите "Новый", а затем "Пайплайн".
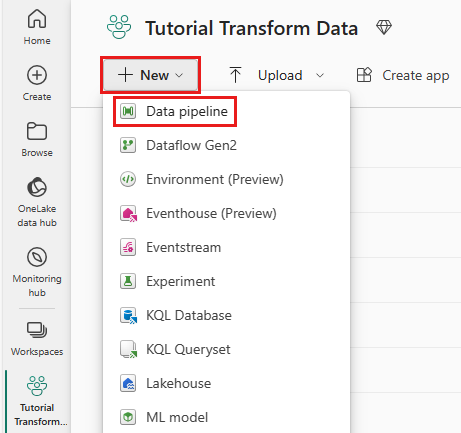
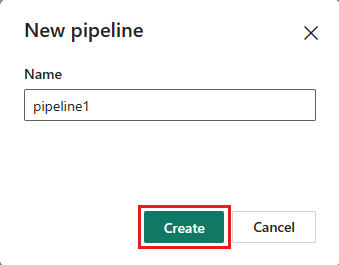
Присвойте конвейеру имя и нажмите кнопку "Создать".
Настройка потока данных
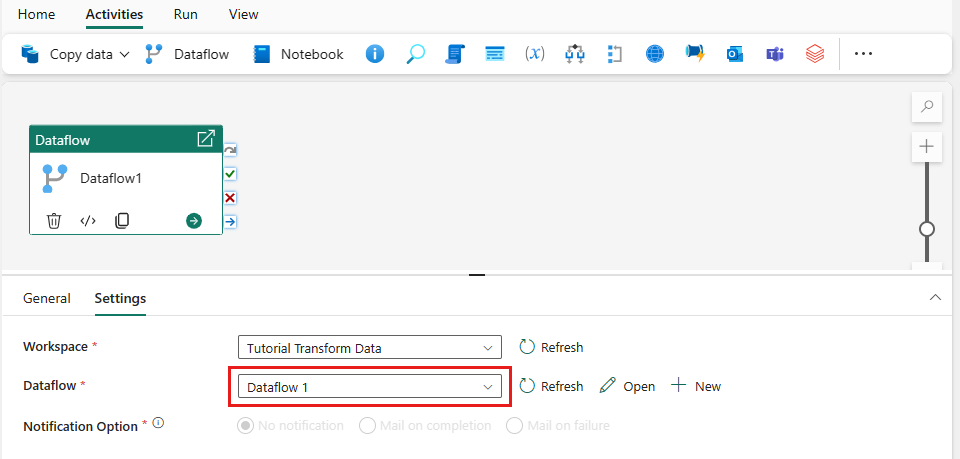
Добавьте действие потока данных в конвейер, выбрав поток данных на вкладке "Действия ".

Выберите поток данных на холсте конвейера, перейдите на вкладку "Параметры " и выберите созданный ранее поток данных.
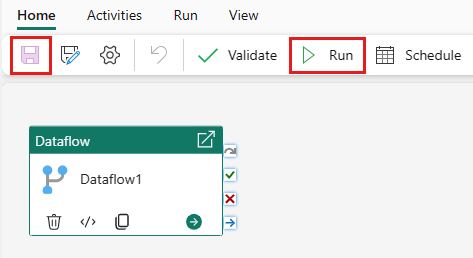
Нажмите кнопку "Сохранить", а затем выполните команду "Выполнить ", чтобы заполнить объединенную таблицу запросов.
Добавление действия копирования
Выберите " Копировать данные на холсте" или используйте помощник по копированию на вкладке "Действия ".
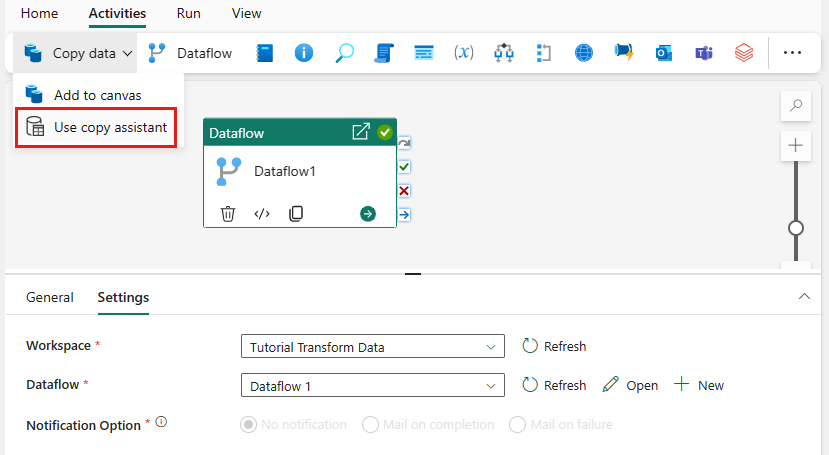
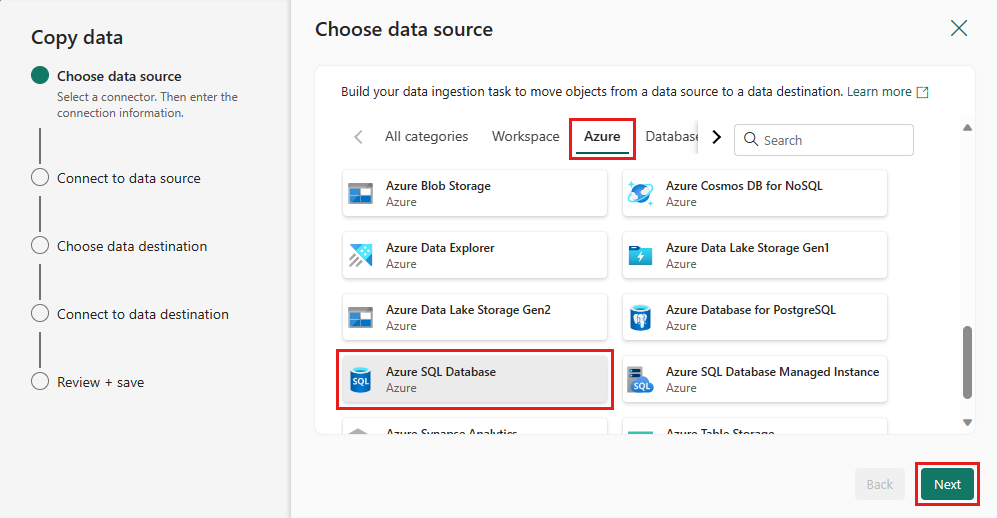
Выберите базу данных SQL Azure в качестве источника данных и нажмите кнопку "Далее".
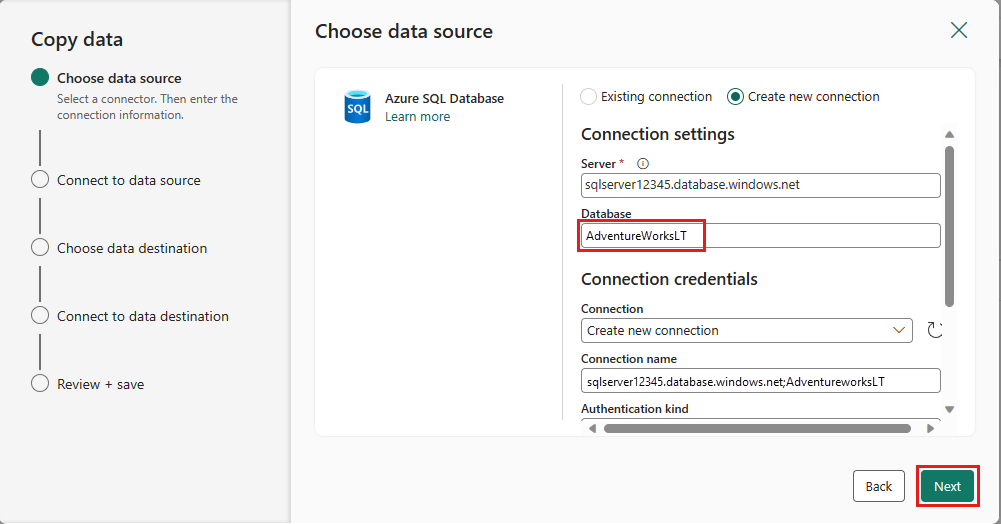
Создайте подключение к источнику данных, выбрав Создать новое подключение. Введите необходимые сведения о подключении на панели и введите AdventureWorksLT для базы данных, где мы создали запрос слияния в потоке данных. Затем выберите Далее.
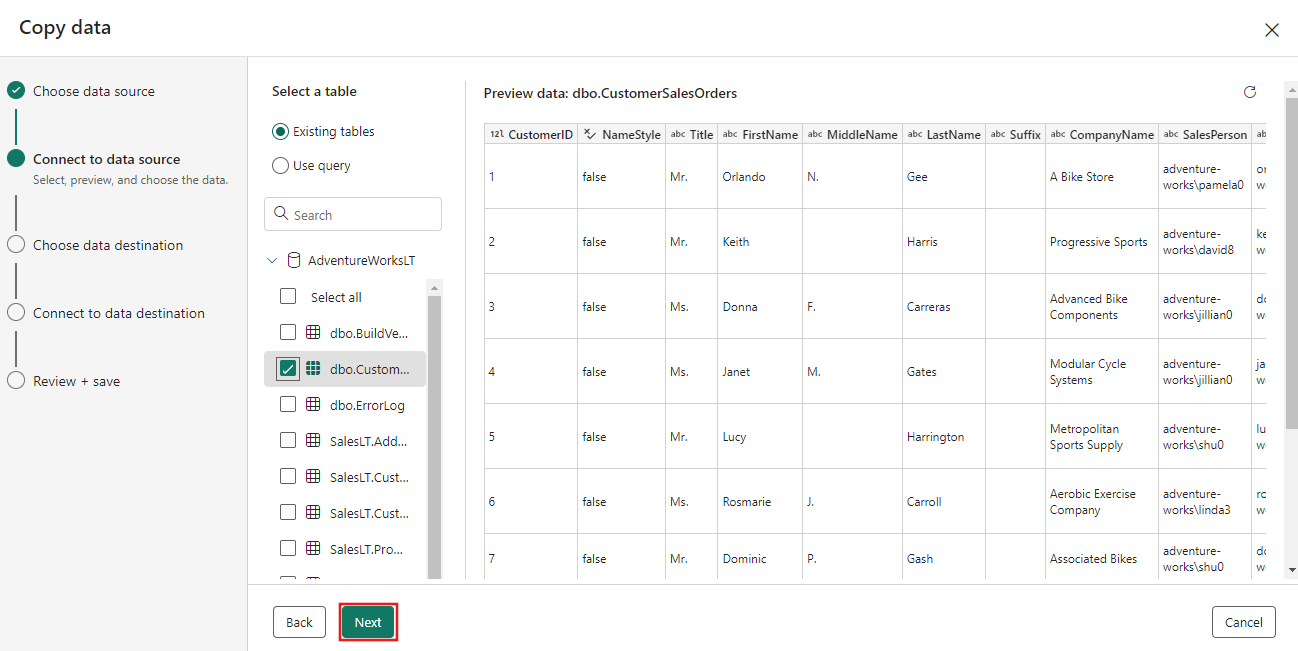
Выберите таблицу, созданную на шаге потока данных ранее, и нажмите кнопку Далее.
Для места назначения выберите хранилище BLOB-объектов Azure и выберите Далее.
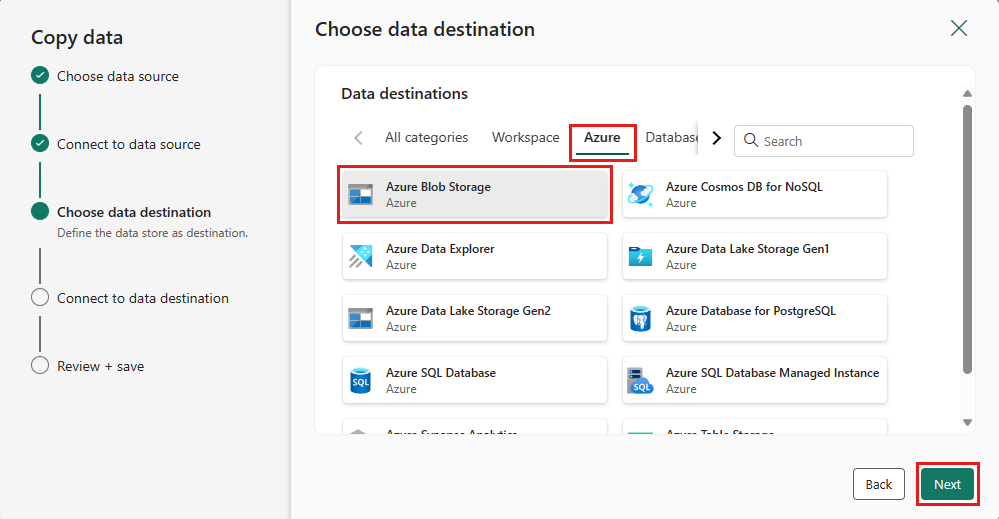
Создайте подключение к месту назначения, выбрав Создать новое подключение. Укажите сведения о подключении, а затем нажмите кнопку Далее.
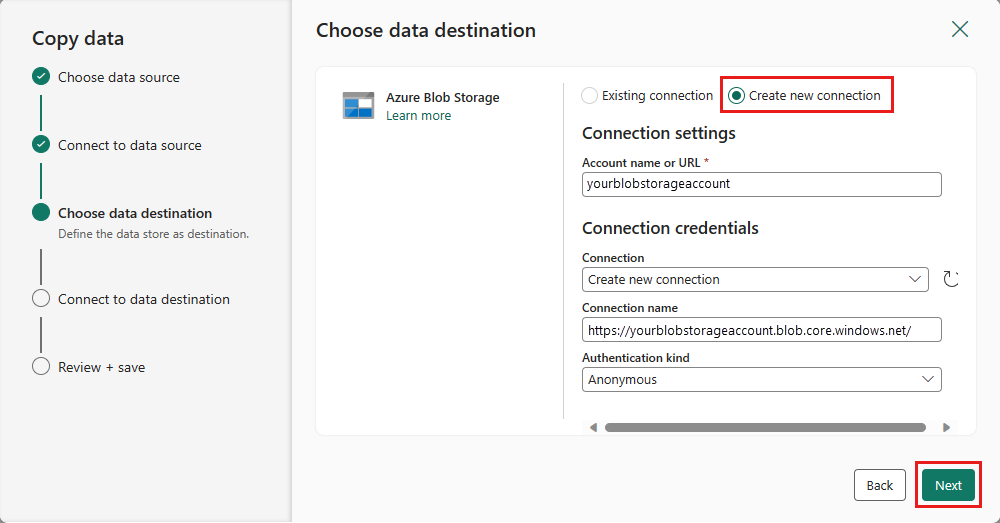
Выберите путь к папке и укажите имя файла, а затем нажмите кнопку Далее.
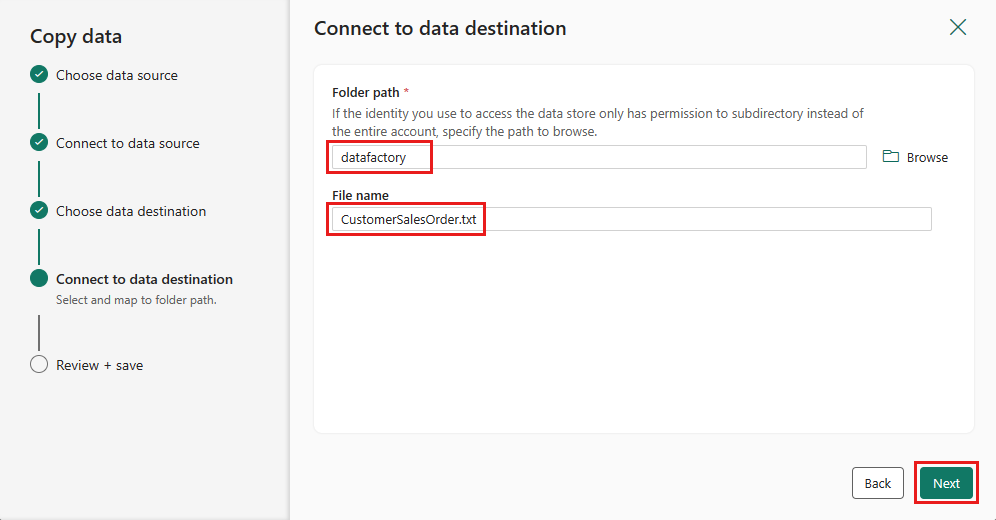
Нажмите кнопку "Далее" , чтобы принять формат файла по умолчанию, разделитель столбцов, разделитель строк и тип сжатия, при необходимости включая заголовок.
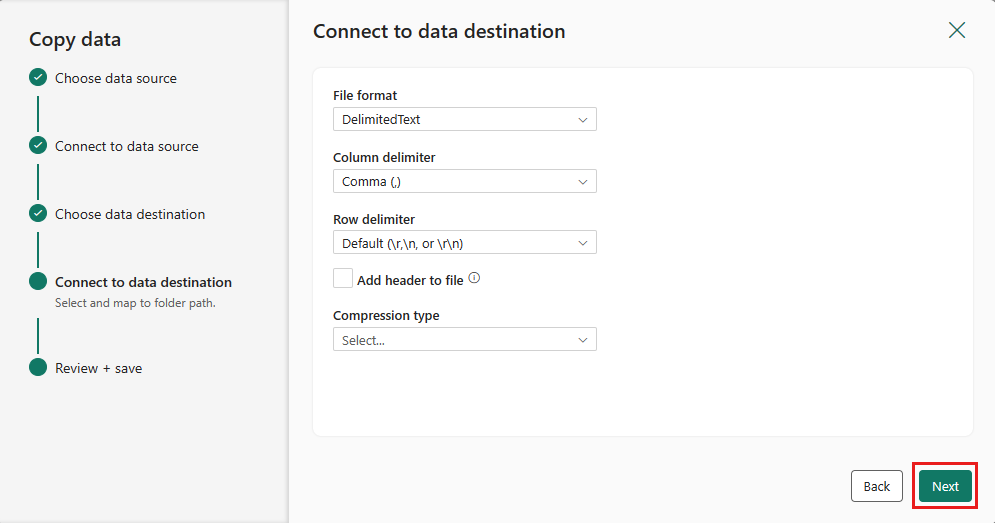
Завершите настройку параметров. Затем просмотрите и выберите Сохранить и запустить, чтобы завершить процесс.
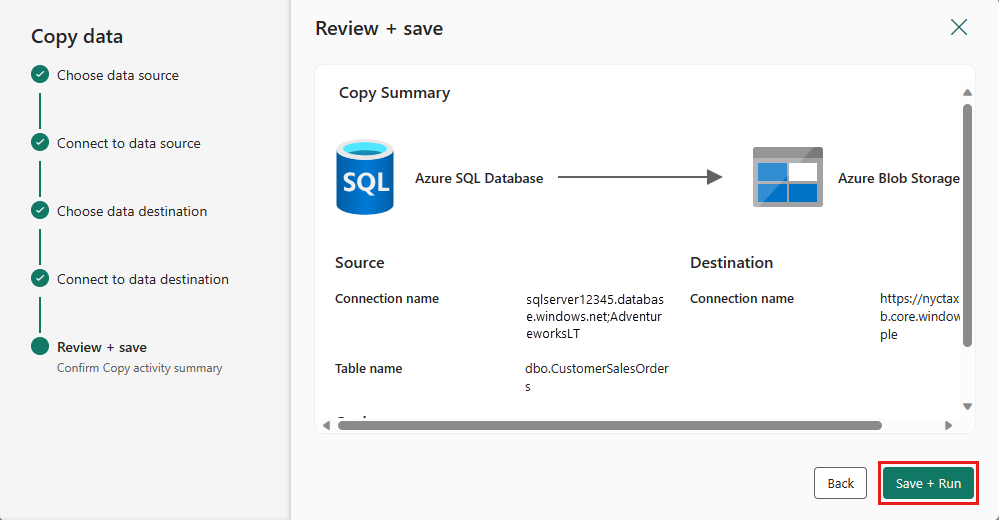
Разработайте ваш поток обработки данных и сохраните его для последующего запуска и загрузки данных
Чтобы запустить активность копирования после активности потока данных, перетащите из Успешно на активности потока данных в активность копирования. Действие копирования выполняется только после успешного выполнения действия потока данных.

Нажмите кнопку "Сохранить", чтобы сохранить конвейер. Затем выберите "Выполнить" , чтобы запустить конвейер и загрузить данные.
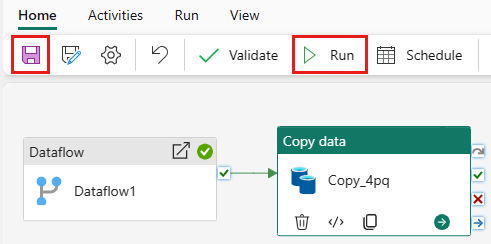
Планирование выполнения конвейера
После завершения разработки и тестирования конвейера его можно запланировать для автоматического запуска.
На вкладке Главная окна редактора конвейера выберите Расписание.
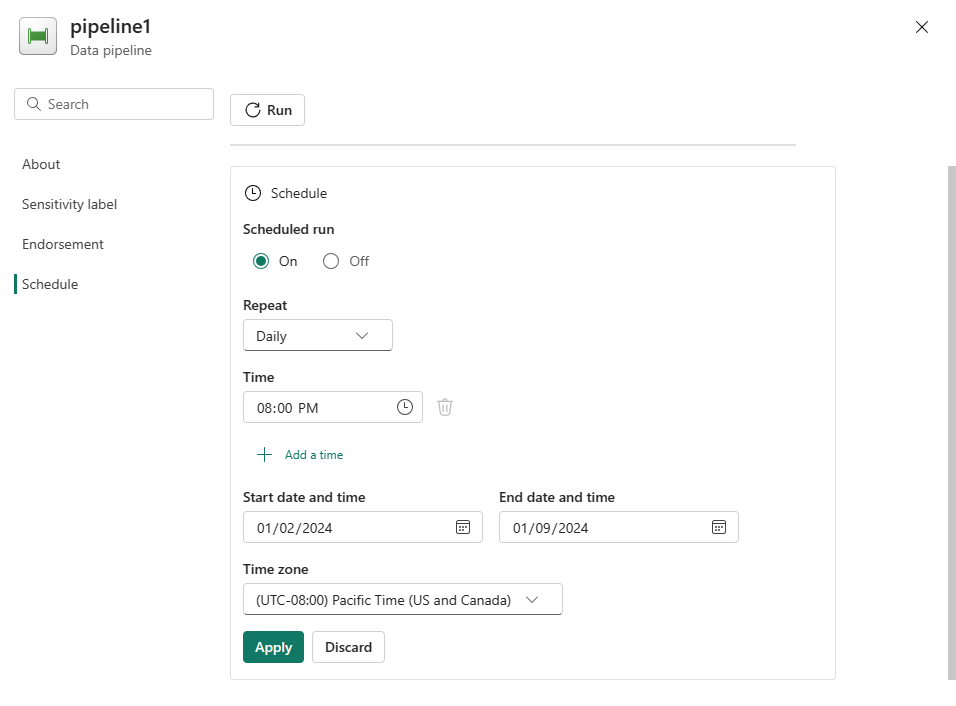
Настройте расписание по мере необходимости. Пример здесь настраивает запуск конвейера по расписанию ежедневно в 20:00 до конца года.
Связанное содержимое
В этом примере показано, как создать и настроить поток данных 2-го поколения, чтобы создать запрос слияния и сохранить его в базе данных SQL Azure, а затем скопировать данные из базы данных в текстовый файл в хранилище BLOB-объектов Azure. Вы узнали, как:
- Создайте поток данных.
- Преобразование данных с помощью потока данных.
- Создайте конвейер с помощью потока данных.
- Упорядочить выполнение шагов в конвейере.
- Скопируйте данные с помощью помощника по копированию.
- Запустите и запланируйте конвейер.
Затем узнайте больше о мониторинге запусков конвейера.